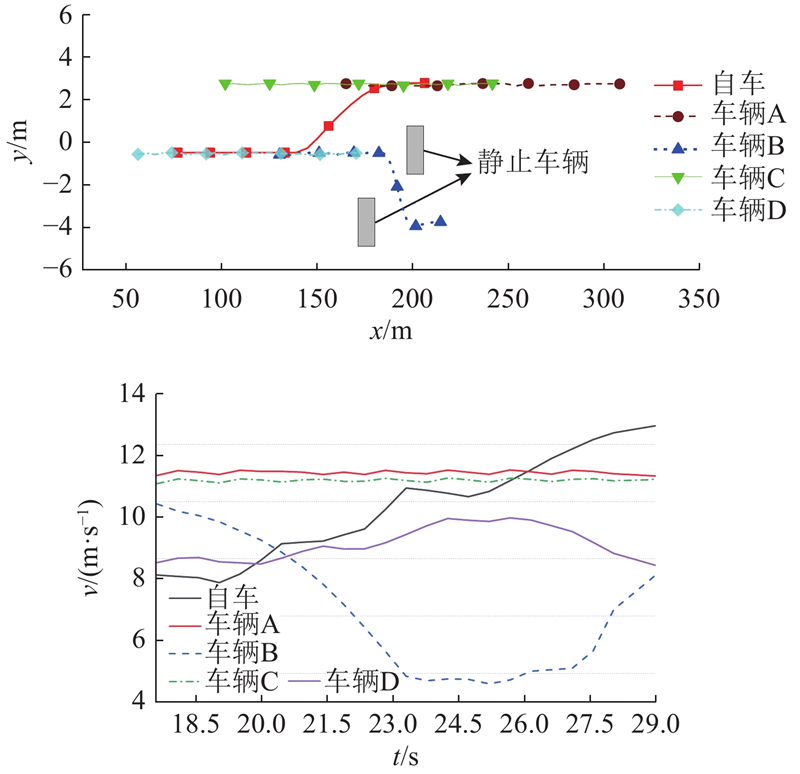
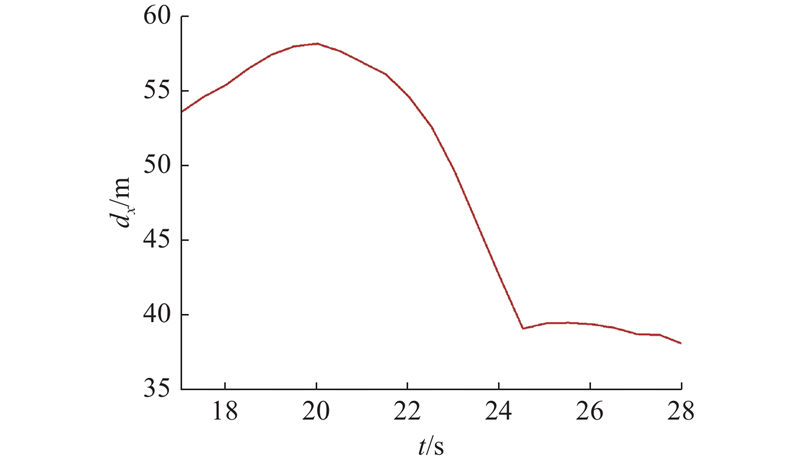
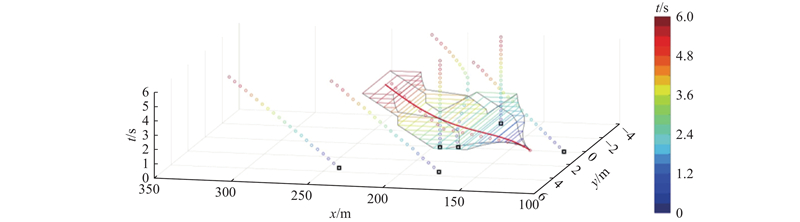
|
|
|
| Decision-making and planning of intelligent vehicle based on reachable set and reinforcement learning |
Hongwei GAO1( ),Bingxu SHANG1,Xinkang ZHANG2,Hongfeng WANG1,Wei HE2,Xiaofei PEI2,*() ),Bingxu SHANG1,Xinkang ZHANG2,Hongfeng WANG1,Wei HE2,Xiaofei PEI2,*() |
1. R&D Center, China FAW Group Corporation, Changchun 130011, China
2. School of Automotive Engineering, Wuhan University of Technology, Wuhan 430070, China |
|
|
|
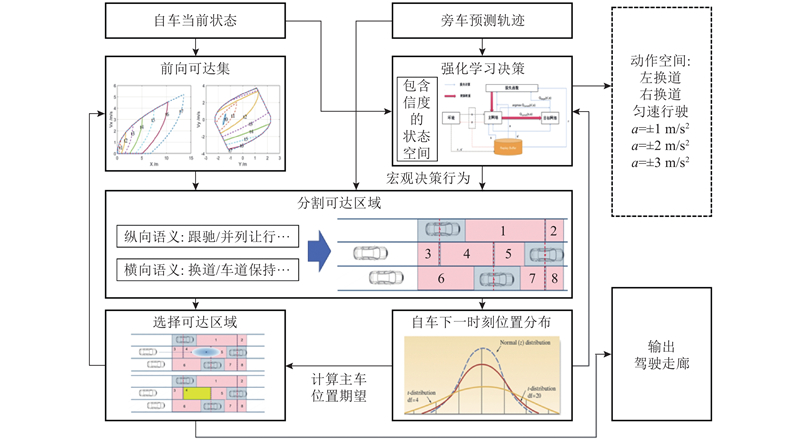
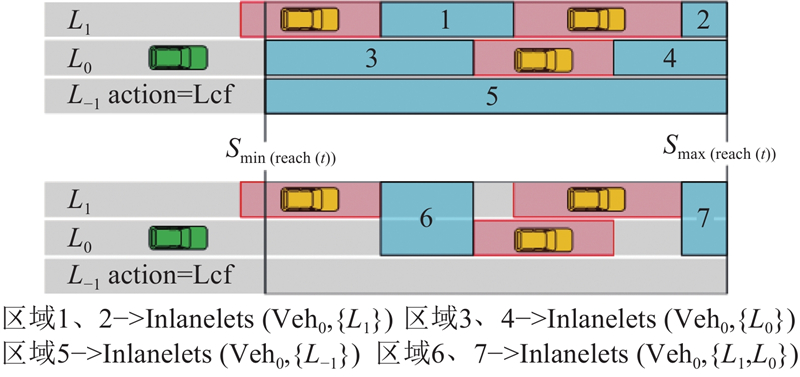
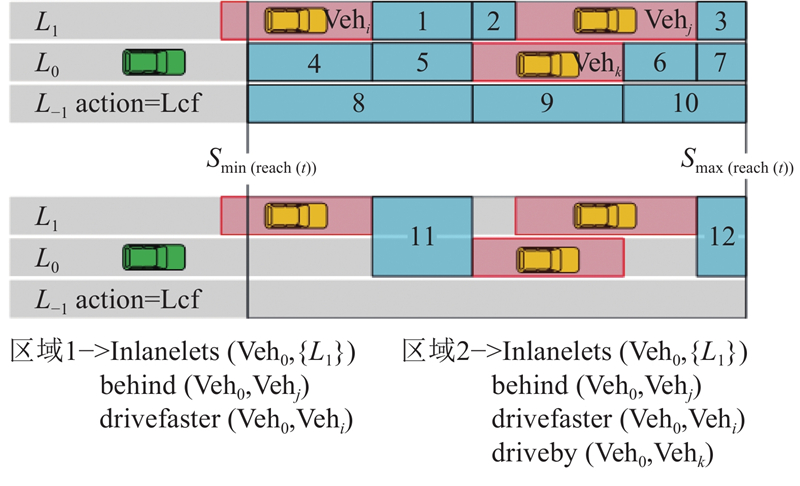
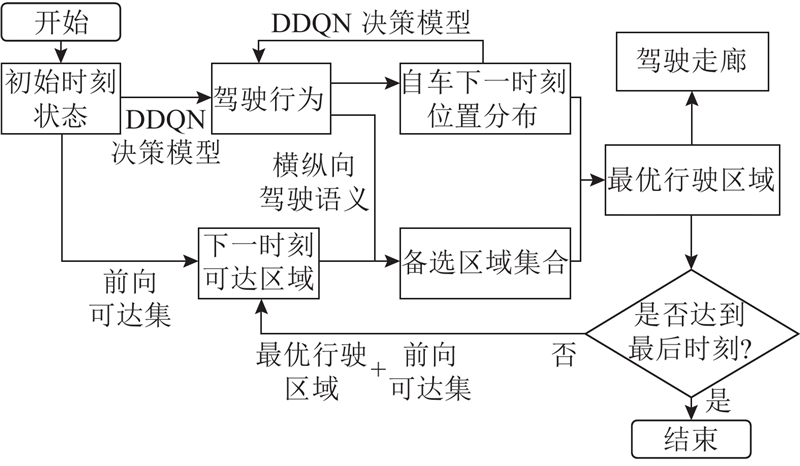
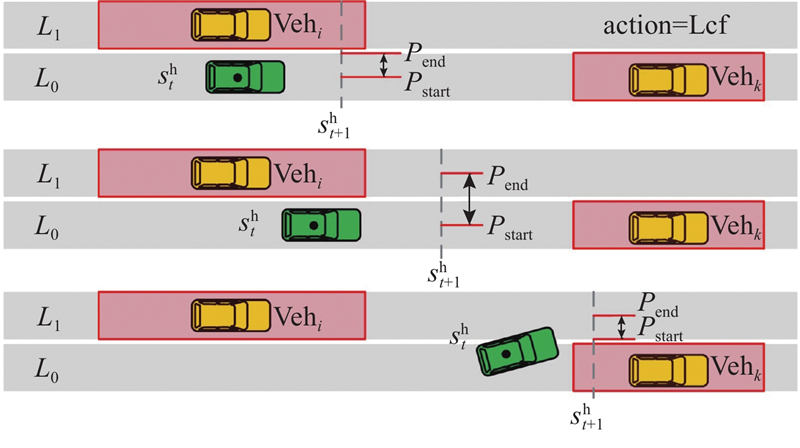
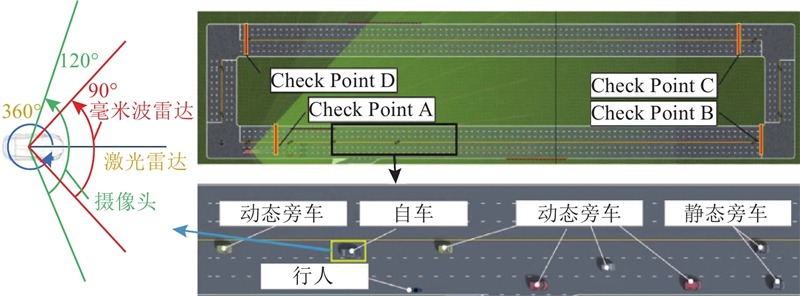
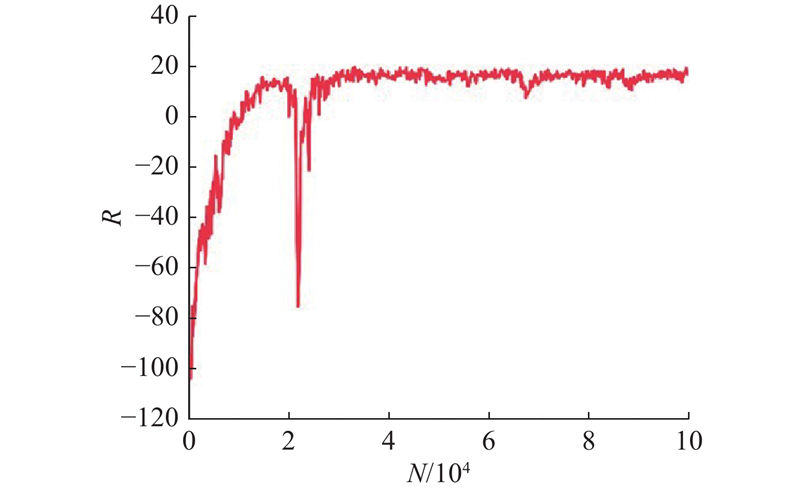
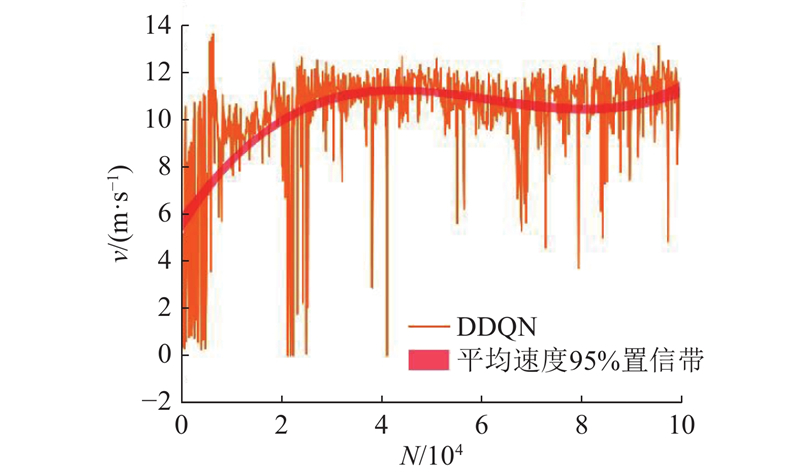
Abstract A decision-making and planning algorithm integrating reachable sets with reinforcement learning (RL) was proposed to address the limitations of traditional reachable sets in effectively handling behavioral interactions between intelligent vehicles and adjacent vehicles in dynamic and uncertain environments, as well as excessive computational complexity. An RL model was incorporated into the algorithm framework to guide multi-step decision-making, clearly defining continuous macro driving behaviors over the planning horizon. Firstly, a reinforcement learning decision model was established and formulated as a Markov decision process (MDP), with state space, action space, and reward function designed. Secondly, feasible driving regions were partitioned based on driving semantics. Lateral and longitudinal behavioral predicates were introduced to segment reachable regions at each time step into finite feasible areas via a two-stage (lateral-first, then longitudinal) segmentation. Finally, the ego vehicle’s position was predicted from RL model outputs to determine optimal driving regions and form a driving corridor. The proposed algorithm’s effectiveness was validated through long-duration cyclic tests in dynamic and uncertain scenarios and comparative analysis of typical cases. Experimental results demonstrated that, compared with existing reachable set algorithms, the proposed method achieved better overall performance in enhancing driving efficiency and ensuring safety, comfort, and real-time responsiveness.
|
|
Received: 27 August 2024
Published: 25 August 2025
|
|
|
| Fund: 国家自然科学基金资助项目(52272426). |
|
Corresponding Authors:
Xiaofei PEI
E-mail: gaohongwei@faw.com.cn;peixiaofei7@163.com
|
基于可达集和强化学习的智能汽车决策规划
针对传统可达集无法有效应对动态不确定场景下智能汽车与旁车之间的行为交互,且计算量过大的问题,提出结合可达集与强化学习的决策规划算法. 算法框架引入强化学习模型进行多步决策引导,明确规划时域内的连续宏观驾驶行为. 建立强化学习决策模型并进行马尔科夫决策过程(MDP)建模,设计状态空间、动作空间和奖励函数. 基于驾驶语义进行可行驶区域分割,引入横纵向行为谓词,通过先横向后纵向的二次分割将各时刻可达区域按照驾驶行为分割为有限个可行驶区域. 通过各时刻强化学习模型输出的动作推算自车位置确定最优行驶区域,形成驾驶走廊. 通过动态不确定场景下的长时循环测试统计和典型场景分析对比,验证所提出算法的有效性. 实验结果表明,与现有的可达集算法相比,所提算法在行驶效率、安全性、舒适性和实时性等方面综合性能更优.
关键词:
智能汽车,
轨迹规划,
可达集,
强化学习,
驾驶走廊
|
|
| [1] |
朱冰, 贾士政, 赵健, 等 自动驾驶车辆决策与规划研究综述[J]. 中国公路学报, 2024, 37 (1): 215- 240
ZHU Bing, JIA Shizheng, ZHAO Jian, et al Review of research on decision-making and planning for automated vehicles[J]. China Journal of Highway and Transport, 2024, 37 (1): 215- 240
|
|
|
| [2] |
NÉMETH B, GÁSPÁR P Hierarchical motion control strategies for handling interactions of automated vehicles[J]. Control Engineering Practice, 2023, 136: 105523
doi: 10.1016/j.conengprac.2023.105523
|
|
|
| [3] |
XIONG L, ZHANG Y, LIU Y, et al Integrated decision making and planning based on feasible region construction for autonomous vehicles considering prediction uncertainty[J]. IEEE Transactions on Intelligent Vehicles, 2023, 8 (11): 4515- 4523
doi: 10.1109/TIV.2023.3299845
|
|
|
| [4] |
XIN L, KONG Y, LI S E, et al Enable faster and smoother spatio-temporal trajectory planning for autonomous vehicles in constrained dynamic environment[J]. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering, 2021, 235 (4): 1101- 1112
doi: 10.1177/0954407020906627
|
|
|
| [5] |
MARTINEZ ROCAMORA B, PEREIRA G A S Parallel sensor-space lattice planner for real-time obstacle avoidance[J]. Sensors, 2022, 22 (13): 4770
doi: 10.3390/s22134770
|
|
|
| [6] |
MANZINGER S, PEK C, ALTHOFF M Using reachable sets for trajectory planning of automated vehicles[J]. IEEE Transactions on Intelligent Vehicles, 2021, 6 (2): 232- 248
doi: 10.1109/TIV.2020.3017342
|
|
|
| [7] |
HANG P, LV C, HUANG C, et al An integrated framework of decision making and motion planning for autonomous vehicles considering social behaviors[J]. IEEE Transactions on Vehicular Technology, 2020, 69 (12): 14458- 14469
doi: 10.1109/TVT.2020.3040398
|
|
|
| [8] |
ZHANG X, YANG B, PEI X, et al Trajectory planning based on spatio-temporal reachable set considering dynamic probabilistic risk[J]. Engineering Applications of Artificial Intelligence, 2023, 123: 106291
doi: 10.1016/j.engappai.2023.106291
|
|
|
| [9] |
SÖNTGES S, ALTHOFF M Computing the drivable area of autonomous road vehicles in dynamic road scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 19 (6): 1855- 1866
doi: 10.1109/TITS.2017.2742141
|
|
|
| [10] |
MASCETTA T, LIU E I, ALTHOFF M. Rule-compliant multi-agent driving corridor generation using reachable sets and combinatorial negotiations [C]// Proceedings of the IEEE Intelligent Vehicles Symposium. Jeju Island: IEEE, 2024: 1417–1423.
|
|
|
| [11] |
LERCHER F, ALTHOFF M. Specification-compliant reachability analysis for autonomous vehicles using on-the-fly model checking [C]// Proceedings of the IEEE Intelligent Vehicles Symposium. Jeju Island: IEEE, 2024: 1484–1491.
|
|
|
| [12] |
ZHU Z, ZHAO H A survey of deep RL and IL for autonomous driving policy learning[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23 (9): 14043- 14065
doi: 10.1109/TITS.2021.3134702
|
|
|
| [13] |
DUAN J, EBEN LI S, GUAN Y, et al Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data[J]. IET Intelligent Transport Systems, 2020, 14 (5): 297- 305
doi: 10.1049/iet-its.2019.0317
|
|
|
| [14] |
TRAUTH R, HOBMEIER A, BETZ J. A reinforcement learning-boosted motion planning framework: comprehensive generalization performance in autonomous driving [EB/OL]. (2024-02-02)[2025-06-16]. https://arxiv.org/abs/2402.01465v1.
|
|
|
| [15] |
YU J, ARAB A, YI J, et al Hierarchical framework integrating rapidly-exploring random tree with deep reinforcement learning for autonomous vehicle[J]. Applied Intelligence, 2023, 53 (13): 16473- 16486
doi: 10.1007/s10489-022-04358-7
|
|
|
| [16] |
JAFARI R, ASHARI A E, HUBER M. CHAMP: integrated logic with reinforcement learning for hybrid decision making for autonomous vehicle planning [C]// Proceedings of the American Control Conference. San Diego: IEEE, 2023: 3310–3315.
|
|
|
| [17] |
CHEN D, JIANG L, WANG Y, et al. Autonomous driving using safe reinforcement learning by incorporating a regret-based human lane-changing decision model [C]// Proceedings of the American Control Conference. Denver: IEEE, 2020: 4355–4361.
|
|
|
| [18] |
ZHOU H, PEI X, LIU Y, et al. Trajectory planning for autonomous vehicles at urban intersections based on reachable sets [C]// IEEE Intelligent Vehicle Symposium. Cluj Napoca: IEEE, 2025: 1101–1107.
|
|
|
| [19] |
李国法, 陈耀昱, 吕辰, 等 智能汽车决策中的驾驶行为语义解析关键技术[J]. 汽车安全与节能学报, 2019, 10 (4): 391- 412
LI Guofa, CHEN Yaoyu, LV Chen, et al Key techniques of semantic analysis of driving behavior in decision making of autonomous vehicles[J]. Journal of Automotive Safety and Energy, 2019, 10 (4): 391- 412
doi: 10.3969/j.issn.1674-8484.2019.04.001
|
|
|
| [20] |
QIAN L, XU X, ZENG Y, et al Synchronous maneuver searching and trajectory planning for autonomous vehicles in dynamic traffic environments[J]. IEEE Intelligent Transportation Systems Magazine, 2022, 14 (1): 57- 73
doi: 10.1109/MITS.2019.2953551
|
|
|
| [21] |
TREIBER M, HENNECKE A, HELBING D Congested traffic states in empirical observations and microscopic simulations[J]. Physical Review E, Statistical Physics, Plasmas, Fluids, and Related Interdisciplinary Topics, 2000, 62 (2A): 1805- 1824
|
|
|
| [22] |
周兴珍, 裴晓飞, 张鑫康 基于可达集优化的智能汽车轨迹规划研究[J]. 武汉理工大学学报, 2022, 44 (6): 39- 48
ZHOU Xingzhen, PEI Xiaofei, ZHANG Xinkang Trajectory planning of intelligent vehicle based on reachable set and optimization[J]. Journal of Wuhan University of Technology, 2022, 44 (6): 39- 48
doi: 10.3963/j.issn.1671-4431.2022.06.007
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|