|
|
|
| Two-stage audio-visual speech enhancement algorithm based on convolution and gated attention |
Panrong WANG1( ),Hairong JIA2,*(),Shufei DUAN2 ),Hairong JIA2,*(),Shufei DUAN2 |
1. College of Integrated Circuits, Taiyuan University of Technology, Taiyuan 030024, China
2. College of Electronic Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China |
|
|
|
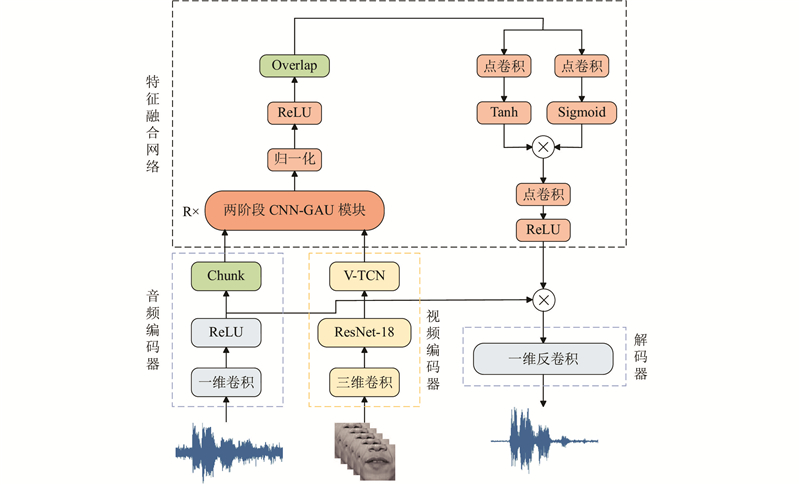
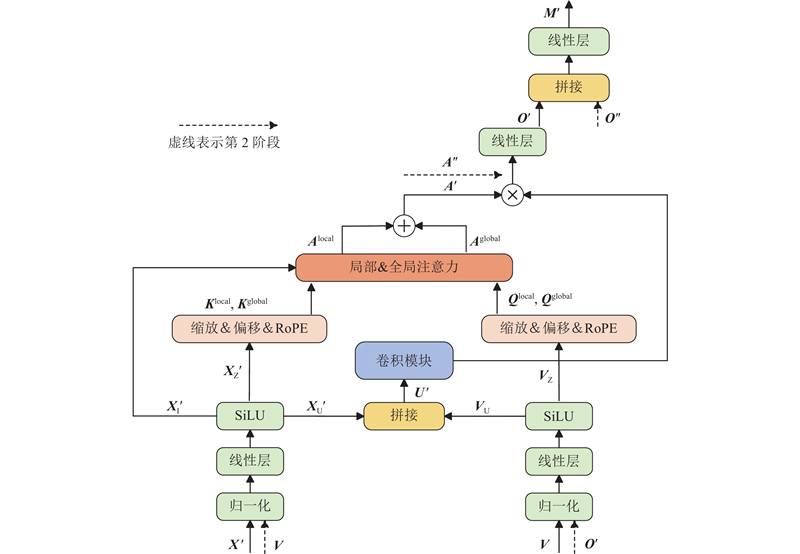
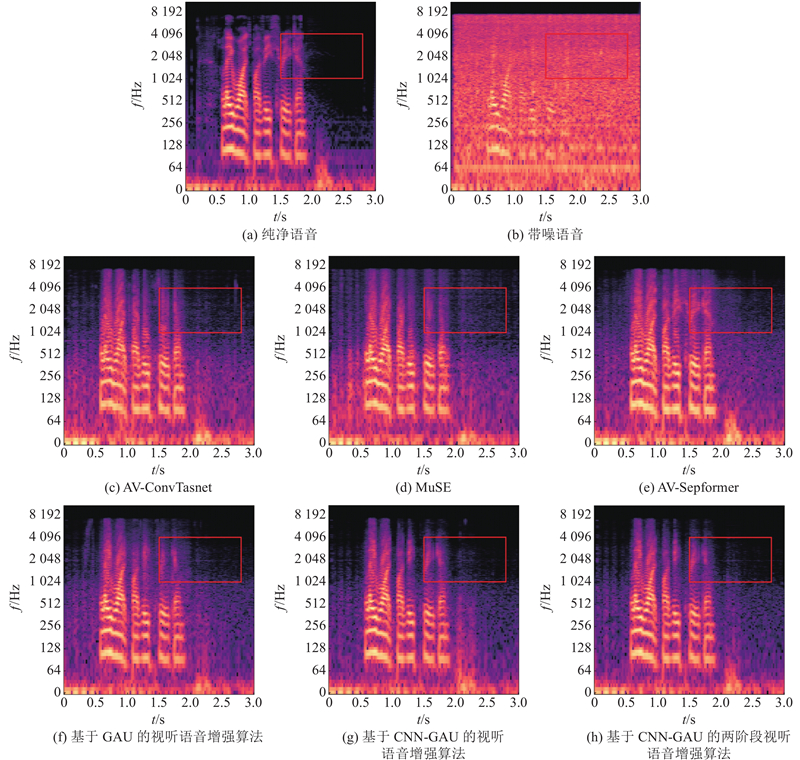
Abstract A two-stage audio-visual speech enhancement algorithm based on convolution and gated attention was proposed in order to solve the problem of high complexity and poor performance of audio-visual speech enhancement model. The block-mixed gated attention unit (GAU) was utilized as the backbone of feature fusion network by using a simplified single head attention mechanism and applying intra block quadratic-inter block linear attention in order to reduce complexity and capture global dependencies of audio-video sequences. Convolutional module was integrated into GAU. Depthwise convolution and pointwise convolution were used to extract local features within and between audio-video blocks in order to capture local dependencies of audio-video sequences. The combination of convolution and attention can significantly improve the performance of the model in processing audio-video sequences. A two-stage algorithm was adopted in order to utilize the speech information contained in the two modalities. Audio was used as the dominant modality and video was used as the conditional modality in the first stage. Video in the second stage was used as the dominant modality and audio extracted in the first stage was used as the conditional modality. The experimental results show that proposed model significantly improves both PESQ and SNR metrics compared with existing models, effectively reducing complexity.
|
|
Received: 15 July 2024
Published: 28 July 2025
|
|
|
| Fund: 国家自然科学基金资助项目(12004275);山西省自然科学基金资助项目(20210302123186);山西省回国留学人员科研资助项目(2024-060). |
|
Corresponding Authors:
Hairong JIA
E-mail: wangpanrong2021@163.com;helenjia722@163.com
|
基于卷积和门控注意的两阶段视听语音增强算法
针对视听语音增强模型复杂度高且性能不佳的问题,提出基于卷积和门控注意的两阶段视听语音增强算法. 采用分块混合的门控注意单元(GAU)为特征融合网络主干,使用简化的单头注意力机制及应用块内二次-块间线性注意力,降低复杂度并捕获音视频序列的全局依赖关系. 在GAU中融入卷积模块,利用逐深度卷积和点卷积对音视频块内-块间局部特征进行提取,捕获音视频序列的局部依赖关系. 卷积与注意力相结合,可以显著提升模型在处理音视频序列时的性能. 为了利用2种模态包含的语音信息,采用两阶段算法,第1阶段音频作为主导模态,视频作为条件模态. 第2阶段视频作为主导模态,第1阶段提取的音频作为条件模态. 实验结果表明,提出的模型较现有模型在PESQ和SNR指标上均有显著提高,有效降低了复杂度.
关键词:
语音增强,
卷积,
注意力,
门控注意单元(GAU),
多模态
|
|
| [1] |
张睿, 张鹏云, 孙超利 基于多域融合及神经架构搜索的语音增强方法[J]. 通信学报, 2024, 45 (2): 225- 239
ZHANG Rui, ZHANG Pengyun, SUN Chaoli Speech enhancement method based on multidomain fusion and neural architecture search[J]. Journal on Communications, 2024, 45 (2): 225- 239
doi: 10.11959/j.issn.1000-436x.2024018
|
|
|
| [2] |
纪鹏威, 全海燕 基于双生成器与频域判别器GAN语音增强算法[J]. 云南大学学报: 自然科学版, 2024, 46 (5): 871- 880
JI Pengwei, QUAN Haiyan GAN speech enhancement algorithm based on twin synthesizer and frequency domain discriminator[J]. Journal of Yunnan University: Natural Sciences Edition, 2024, 46 (5): 871- 880
|
|
|
| [3] |
AFOURAS T, CHUNG J S, ZISSERMAN A. The conversation: deep audio-visual speech enhancement [C]// Interspeech. Hyderabad: Curran Associates, 2018: 3244-3248.
|
|
|
| [4] |
AFOURAS T, CHUNG J S, ZISSERMAN A. My lips are concealed: audio-visual speech enhancement through obstructions [C]// Interspeech. Hyderabad: Curran Associates, 2019: 4295-4299.
|
|
|
| [5] |
MICHELSANTI D, TAN Z H, SIGURDSSON S, et al Deep-learning-based audio-visual speech enhancement in presence of Lombard effect[J]. Speech Communication, 2019, 115: 38- 50
doi: 10.1016/j.specom.2019.10.006
|
|
|
| [6] |
GOGATE M, DASHTIPOUR K, ADEEL A, et al CochleaNet: a robust language-independent audio-visual model for real-time speech enhancement[J]. Information Fusion, 2020, 63 (1): 273- 285
|
|
|
| [7] |
HOU J C, WANG S S, LAI Y H, et al Audio-visual speech enhancement using multimodal deep convolutional neural networks[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2018, 2 (2): 117- 128
doi: 10.1109/TETCI.2017.2784878
|
|
|
| [8] |
GABBAY A, SHAMIR A, PELEG S. Visual speech enhancement [C]// Interspeech. Hyderabad: Curran Associates, 2018: 1170-1174.
|
|
|
| [9] |
WU J, XU Y, ZHANG S X, et al. Time domain audio visual speech separation [C]//IEEE Automatic Speech Recognition and Understanding Workshop. Singapore: IEEE, 2019: 667-673.
|
|
|
| [10] |
PAN Z, TAO R, XU C, et al. Muse: multi-modal target speaker extraction with visual cues [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 6678-6682.
|
|
|
| [11] |
LIN J, CAI X, DINKEL H, et al. Av-Sepformer: cross-attention Sepformer for audio-visual target speaker extraction [C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Rhodes Island: IEEE, 2023: 1-5.
|
|
|
| [12] |
HUA W, DAI Z, LIU H, et al. Transformer quality in linear time [C]// International Conference on Machine Learning. Baltimore: [s. n. ], 2022: 9099-9117.
|
|
|
| [13] |
LUO Y, CHEN Z, YOSHIOKA T. Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Barcelona: IEEE, 2020: 46-50.
|
|
|
| [14] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [15] |
ZHAO S, MA B. Mossformer: pushing the performance limit of monaural speech separation using gated single-head transformer with convolution-augmented joint self-attentions [C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Rhodes Island: IEEE, 2023: 1-5.
|
|
|
| [16] |
VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need[J]. Advances in Neural Information Processing System, 2017, 30 (1): 261- 272
|
|
|
| [17] |
SHAZEER N. Glu variants improve transformer [EB/OL]. (2020-02-12)[2024-07-15]. https://arxiv.org/pdf/2002.05202.
|
|
|
| [18] |
SU J, AHMED M, LU Y, et al Roformer: enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063
doi: 10.1016/j.neucom.2023.127063
|
|
|
| [19] |
PENG Y, DALMIA S, LANE I, et al. Branchformer: parallel mlp-attention architectures to capture local and global context for speech recognition and understanding [C]// International Conference on Machine Learning. Baltimore: [s. n. ], 2022: 17627-17643.
|
|
|
| [20] |
MU Z, YANG X. Separate in the speech chain: cross-modal conditional audio-visual target speech extraction [EB/OL]. (2024-05-05)[2024-07-15]. https://arxiv.org/pdf/2404.12725.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|