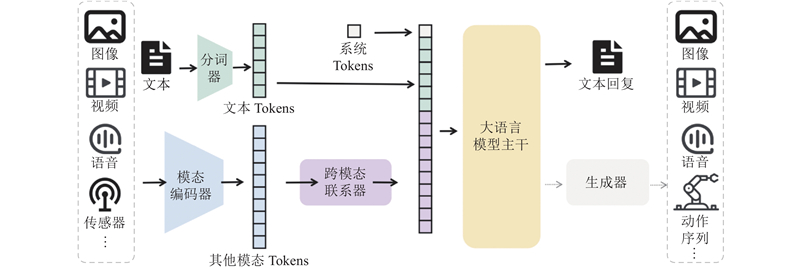
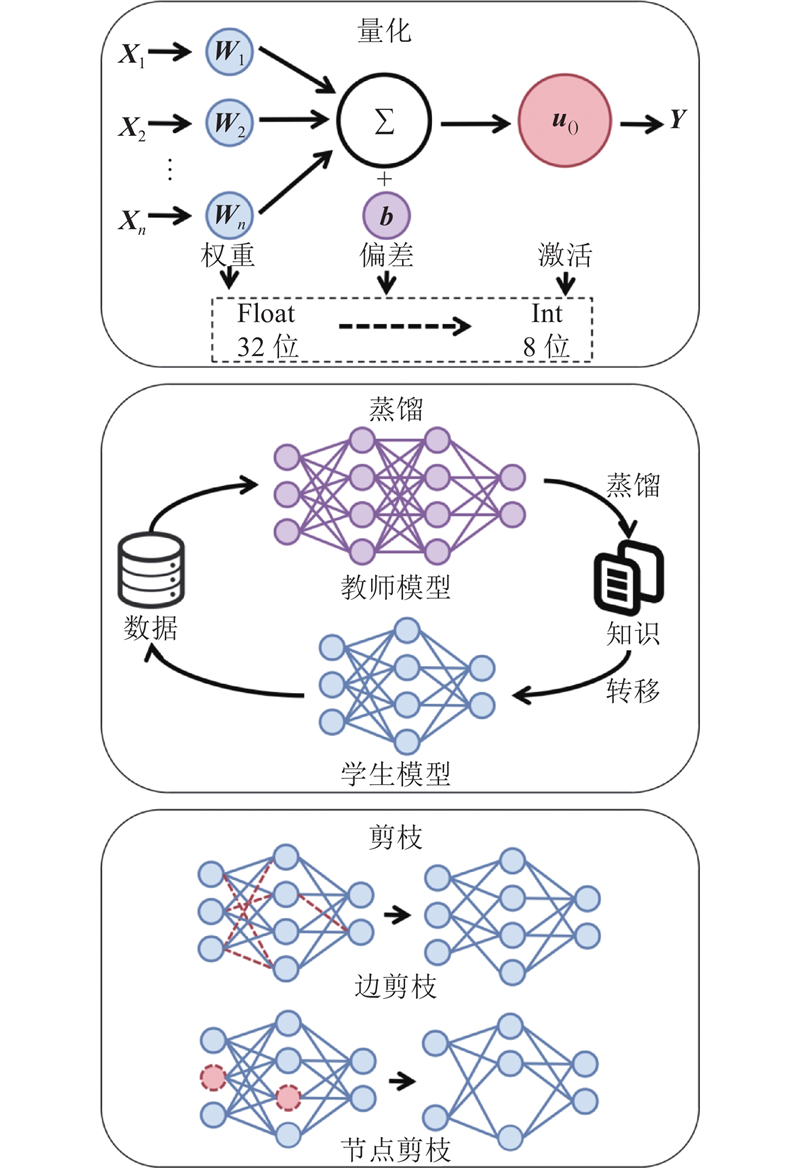
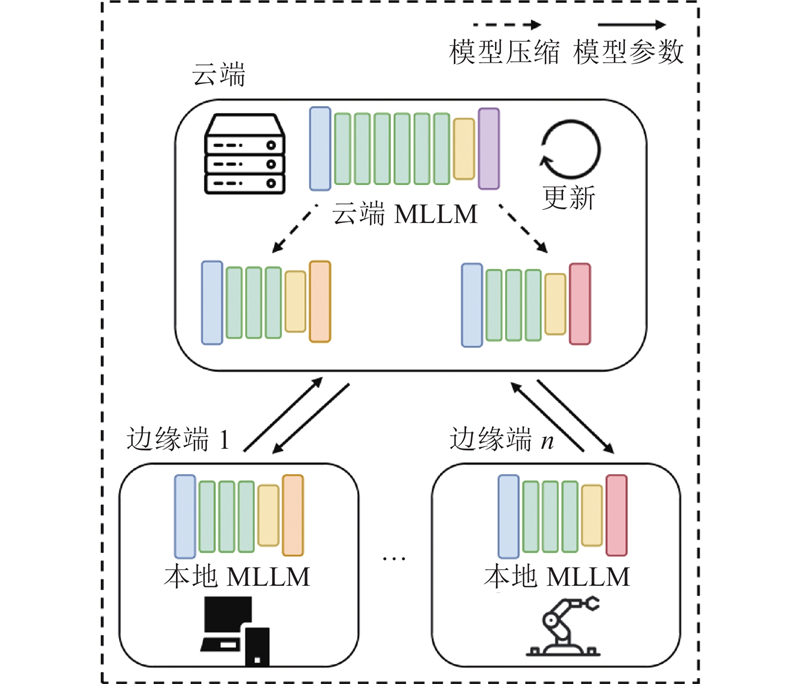
| 计算机技术 |
|

|
|
|
| 多模态大模型边缘部署与推理加速技术综述 |
陈思如( ),舒元超*() ),舒元超*() |
| 浙江大学 控制科学与工程学院,浙江 杭州 310027 |
|
| Survey on edge deployment and inference acceleration of multimodal large language models |
| Siru CHEN(),Yuanchao SHU*() |
| College of Control Science and Engineering, Zhejiang University, Hangzhou 310027, China |
| 1 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural information Processing Systems. Long Beach: Curran Associates, 2017: 5998−6008.
|
| 2 |
ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning [C]// Advances in Neural Information Processing Systems. New Orleans: Curran Associates, 2022: 23716−23736.
|
| 3 |
YANG Z, LI L, LIN K, et al. The dawn of lmms: Preliminary explorations with gpt-4v (ision) [EB/OL]. (2023−03−04) [2025−10−17]. https://arxiv.org/abs/2303.08774.
|
| 4 |
DOSOVITSKIY A. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021−06−04) [2025−10−17]. https://arxiv.org/abs/2010.11929.
|
| 5 |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Minneapolis: Association for Computational Linguistics, 2019: 4171−4186.
|
| 6 |
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. (2018−06−09) [2025−10−17]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
|
| 7 |
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: open and efficient foundation language models [EB/OL]. (2023−02−27) [2025−10−17]. https://arxiv.org/abs/2302.13971.
|
| 8 |
BAI J, BAI S, CHU Y, et al. Qwen technical report [EB/OL]. (2023−09−28) [2025−10−17]. https://arxiv.org/abs/2309.16609.
|
| 9 |
DRIESS D, XIA F, SAJJADI M S, et al. Palm-e: an embodied multimodal language model [EB/OL]. (2023−03−06) [2025−10−17]. https://arxiv.org/abs/2303.03378.
|
| 10 |
TEAM G, ANIL R, BORGEAUD S, et al. Gemini: a family of highly capable multimodal models [EB/OL]. (2025−05−09) [2025−10−17]. https://arxiv.org/abs/2312.11805.
|
| 11 |
CHU X, QIAO L, LIN X, et al. Mobilevlm: a fast, strong and open vision language assistant for mobile devices [EB/OL]. (2023−12−30) [2025−10−17]. https://arxiv.org/abs/2312.16886.
|
| 12 |
YUAN Z, LI Z, HUANG W, et al. Tinygpt-v: efficient multimodal large language model via small backbones [EB/OL]. (2024−01−21) [2025−10−17]. https://arxiv.org/abs/2312.16862.
|
| 13 |
JAVAHERIPI M, BUBECK S, ABDIN M, et al. Phi-2: the surprising power of small language models [EB/OL]. (2023−12−12) [2025−10−17]. https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/.
|
| 14 |
WEI H, KONG L, CHEN J, et al. Small language model meets with reinforced vision vocabulary [EB/OL]. (2024−01−23) [2025−10−17]. https://arxiv.org/abs/2401.12503.
|
| 15 |
CHU X, QIAO L, ZHANG X, et al. Mobilevlm v2: faster and stronger baseline for vision language model [EB/OL]. (2025−02−06) [2025−10−17]. https://arxiv.org/abs/2402.03766.
|
| 16 |
ZHU Y, ZHU M, LIU N, et al. Llava-phi: efficient multi-modal assistant with small language model [C]// Proceedings of the 1st International Workshop on Efficient Multimedia Computing under Limited. New York: Association for Computing Machinery, 2024: 18−22.
|
| 17 |
ZHAO H, ZHANG M, ZHAO W, et al. Cobra: extending mamba to multi-modal large language model for efficient inference [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Philadelphia: AAAI Press, 2025: 10421−10429.
|
| 18 |
GU A, DAO T. Mamba: linear-time sequence modeling with selective state spaces [C]// 1st Conference on Language Modeling. Philadelphia: [s. n. ], 2024.
|
| 19 |
ZHU M, ZHU Y, LIU X, et al. Mipha: a comprehensive overhaul of multimodal assistant with small language models [EB/OL]. (2024−03−25) [2025−10−17]. https://arxiv.org/abs/2403.06199.
|
| 20 |
HINCK M, OLSON M L, COBBLEY D, et al. Llava-gemma: accelerating multimodal foundation models with a compact language [EB/OL]. (2024−06−10) [2025−10−17]. https://arxiv.org/abs/2404.01331.
|
| 21 |
TEAM G, MESNARD T, HARDIN C, et al. Gemma: open models based on gemini research and technology [EB/OL]. (2024−04−16) [2025−10−17]. https://arxiv.org/abs/2403.08295.
|
| 22 |
SHAO Z, YU Z, YU J, et al Imp: highly capable large multimodal models for mobile devices[J]. IEEE Transactions on Multimedia, 2025, 27: 2961- 2974
doi: 10.1109/TMM.2025.3557680
|
| 23 |
HE M, LIU Y, WU B, et al. Efficient multimodal learning from data-centric perspective [EB/OL]. (2024−07−22) [2025−10−17]. https://arxiv.org/abs/2402.11530.
|
| 24 |
ABDIN M, ANEJA J, AWADALLA H, et al. Phi-3 technical report: a highly capable language model locally on your phone [EB/OL]. (2024−08−30) [2025−10−17]. https://arxiv.org/abs/2404.14219.
|
| 25 |
BEYER L, STEINER A, PINTO A S, et al. Paligemma: a versatile 3b vlm for transfer [EB/OL]. (2024−10−10) [2025−10−17]. https://arxiv.org/abs/2407.07726.
|
| 26 |
CHEN Z, WU J, WANG W, et al. Internvl: scaling up vision foundation models and aligning for generic visual-linguistic tasks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 24185−24198.
|
| 27 |
CAI Z, CAO M, CHEN H, et al. Internlm2 technical report [EB/OL]. (2024−03−26) [2025−10−17]. https://arxiv.org/abs/2403.17297.
|
| 28 |
YAO Y, YU T, ZHANG A, et al. MiniCPM-V 2.6: a GPT-4V level MLLM for single image, multi image and video on your phone [EB/OL]. (2024−08−06) [2025−10−17]. https://github.com/nuoan/MiniCPM-V2.6.
|
| 29 |
HU S, TU Y, HAN X, et al. Minicpm: unveiling the potential of small language models with scalable training strategies [EB/OL]. (2024−06−03) [2025−10−17]. https://arxiv.org/abs/2404.06395.
|
| 30 |
WANG P, BAI S, TAN S, et al. Qwen2-vl: enhancing vision-language model’s perception of the world at any resolution[EB/OL]. (2024−10−03) [2025−10−17]. https://arxiv.org/abs/2409.12191.
|
| 31 |
TEAM Q. Qwen2 technical report [EB/OL]. (2024−09−10) [2025−10−17]. https://arxiv.org/abs/2407.10671.
|
| 32 |
GLM series edge models [EB/OL]. (2025−06−12) [2025−10−17]. https://github.com/zai-org/GLM-Edge.
|
| 33 |
GLM T, ZENG A, XU B, et al. Chatglm: a family of large language models from glm-130b to glm-4 all tools [EB/OL]. (2024−07−30) [2025−10−17]. https://arxiv.org/abs/2406.12793.
|
| 34 |
ZHANG I, PENG W, JENNY N, et al. Ivy-VL: compact vision-language models achieving SOTA with optimal data [EB/OL]. (2024−12−01) [2025−10−17]. https://huggingface.co/AI-Safeguard/Ivy-VL-llava.
|
| 35 |
QWEN TEAM. Qwen2.5: a party of foundation models [EB/OL]. (2024−09−01) [2025−10−17]. https://qwenlm.github.io/blog/qwen2.5/.
|
| 36 |
CHEN Z, WANG W, CAO Y, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling [EB/OL]. (2025−09−26) [2025−10−17]. https://arxiv.org/abs/2412.05271.
|
| 37 |
STEINER A, PINTO A S, TSCHANNEN M, et al. Paligemma 2: a family of versatile vlms for transfer [EB/OL]. (2024−12−04) [2025−10−17]. https://arxiv.org/abs/2412.03555.
|
| 38 |
YAO Y, YU T, ZHANG A, et al. MiniCPM-o 2.6: a GPT-4o level MLLM for vision, speech and multimodal live streaming on your phone [EB/OL]. (2025−01−24) [2025−10−17]. https://github.com/shaneholloman/minicpm-o.
|
| 39 |
LI B, LI Y, LI Z, et al. Megrez-omni technical report [EB/OL]. (2025−02−19) [2025−10−17]. https://arxiv.org/abs/2502.15803.
|
| 40 |
TOUVRON H, MARTIN L, STONE K, et al. Llama 2: open foundation and fine-tuned chat models [EB/OL]. (2023−07−19) [2025−10−17]. https://arxiv.org/abs/2307.09288.
|
| 41 |
MARAFIOTI A, ZOHAR O, FARRÉ M, et al. Smolvlm: redefining small and efficient multimodal models [EB/OL]. (2025−04−07) [2025−10−17]. https://arxiv.org/abs/2504.05299.
|
| 42 |
ALLAL L B, LOZHKOV A, BAKOUCH E, et al. SmolLM2: when smol goes big--data-centric training of a small language model [EB/OL]. (2025−02−24) [2025−10−17]. https://arxiv.org/abs/2502.02737.
|
| 43 |
M87 LABS, INC. Moondream[EB/OL]. (2025−03−27) [2025−10−17]. https://moondream.ai/.
|
| 44 |
LI Y, BUBECK S, ELDAN R, et al. Textbooks are all you need ii: phi-1.5 technical report [EB/OL]. (2023−09−11) [2025−10−17]. https://arxiv.org/abs/2309.05463.
|
| 45 |
ZHU J, WANG W, CHEN Z, et al. Internvl3: exploring advanced training and test-time recipes for open-source multimodal models [EB/OL]. (2025−04−19) [2025−10−17]. https://arxiv.org/abs/2504.10479.
|
| 46 |
TEAM K, DU A, YIN B, et al. Kimi-vl technical report [EB/OL]. (2025−06−23) [2025−10−17]. https://arxiv.org/abs/2504.07491.
|
| 47 |
TEAM G, KAMATH A, FERRET J, et al. Gemma 3n model overview [EB/OL]. (2025−06−30) [2025−10−17]. https://ai.google.dev/gemma/docs/gemma-3n.
|
| 48 |
DEVVRIT F, KUDUGUNTA S, KUSUPATI A, et al. Matformer: nested transformer for elastic inference [C]// Advances in Neural Information Processing Systems. Vancouver: Curran Associates, 2024: 140535−140564.
|
| 49 |
XIONG B, CHEN B, WANG C, et al. BlueLM-2.5-3B technical report [EB/OL]. (2025−07−08) [2025−10−17]. https://arxiv.org/abs/2507.05934.
|
| 50 |
YU T, WANG Z, WANG C, et al. Minicpm-v 4.5: cooking efficient mllms via architecture, data, and training recipe[EB/OL]. (2025−09−16) [2025−10−17]. https://arxiv.org/abs/2509.18154.
|
| 51 |
LI J, LI D, SAVARESE S, et al. Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models [C]// International Conference on Machine Learning. Hawaii: JMLR, 2023: 19730−19742.
|
| 52 |
LIU H, LI C, WU Q, et al. Visual instruction tuning [C]// Advances in Neural Information Processing Systems. New Orleans: Curran Associates, 2023: 34892−34916.
|
| 53 |
ZHANG P, ZENG G, WANG T, et al. Tinyllama: an open-source small language model [EB/OL]. (2024−07−04) [2025−10−17]. https://arxiv.org/abs/2401.02385.
|
| 54 |
ZHANG S, FANG Q, YANG Z, et al. Llava-mini: efficient image and video large multimodal models with one vision token [EB/OL]. (2025−03−02) [2025−10−17]. https://arxiv.org/abs/2501.03895.
|
| 55 |
SHAO K, TAO K, ZHANG K, et al. When tokens talk too much: a survey of multimodal long-context token compression across images, videos, and audios [EB/OL]. (2025−08−28) [2025−10−17]. https://arxiv.org/abs/2507.20198.
|
| 56 |
GAO Z, CHEN Z, CUI E, et al Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% performance[J]. Visual Intelligence, 2024, 2 (1): 32
doi: 10.1007/s44267-024-00067-6
|
| 57 |
LI B, ZHANG Y, GUO D, et al. Llava-onevision: easy visual task transfer [EB/OL]. (2024−10−26) [2025−10−17]. https://arxiv.org/abs/2408.03326.
|
| 58 |
BAI S, CHEN K, LIU X, et al. Qwen2.5-vl technical report [EB/OL]. (2025−02−19) [2025−10−17]. https://arxiv.org/abs/2502.13923.
|
| 59 |
WANG H, YU Z, SPADARO G, et al. Folder: Accelerating multi-modal large language models with enhanced performance [EB/OL]. (2025−04−10) [2025−10−17]. https://arxiv.org/abs/2501.02430.
|
| 60 |
SUN B, ZHANG Y, JIANG S, et al. Hybrid pixel-unshuffled network for lightweight image super-resolution [C]// Proceedings of the AAAI conference on artificial intelligence. Washington DC: AAAI Press, 2023: 2375−2383.
|
| 61 |
CHEN L, ZHAO H, LIU T, et al. An image is worth 1/2 tokens after layer 2: plug-and-play inference acceleration for large vision-language models [C]// European Conference on Computer Vision. Milan: Springer Nature Switzerland, 2024: 19−35.
|
| 62 |
HAN Y, LIU X, DING P, et al. Rethinking token reduction in mllms: towards a unified paradigm for training-free acceleration [EB/OL]. (2024−12−04) [2025−10−17]. https://arxiv.org/html/2411.17686v2.
|
| 63 |
ZHAO Z, LI Y, LI Y. Learning free token reduction for multi-modal large language models [EB/OL]. (2025−09−30) [2025−10−17]. https://arxiv.org/abs/2501.17391.
|
| 64 |
HEO B, PARK S, HAN D, et al. Rotary position embedding for vision transformer [C]// European Conference on Computer Vision. Milan: Springer Nature Switzerland, 2024: 289−305.
|
| 65 |
LI W, ZHOU H, YU J, et al. Coupled mamba: enhanced multimodal fusion with coupled state space model [C]// Advances in Neural Information Processing Systems. Vancouver: Curran Associates, 2024: 59808−59832.
|
| 66 |
HU Y, FAN Z, WANG X, et al. TinyAlign: boosting lightweight vision-language models by mitigating modal alignment bottlenecks [EB/OL]. (2025−06−30) [2025−10−17]. https://arxiv.org/abs/2505.12884.
|
| 67 |
META. Llama 3.2: revolutionizing edge AI and vision with open, customizable models [EB/OL]. (2024−09−25) [2025−10−17]. https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/.
|
| 68 |
TEAM Q. Qwen1.5 [EB/OL]. (2024−02−05) [2025−10−17]. https://github.com/QwenLM/Qwen1.5.
|
| 69 |
YANG A, LI A, YANG B, et al. Qwen3 technical report [EB/OL]. (2025−05−14) [2025−10−17]. https://arxiv.org/abs/2505.09388.
|
| 70 |
CHIANG W L, LI Z, LIN Z, et al. Vicuna: an open-source chatbot impressing gpt-4 with 90%* chatgpt quality [EB/OL]. (2023−04−14) [2025−10−17]. https://vicuna. lmsys.org.
|
| 71 |
GUNASEKAR S, ZHANG Y, ANEJA J, et al. Textbooks are all you need [EB/OL]. (2023−10−02) [2025−10−17]. https://arxiv.org/abs/2306.11644.
|
| 72 |
WU Z, HUANG S, ZHOU Z, et al. InternLM2. 5-stepprover: advancing automated theorem proving via critic-guided search [C]// 2nd AI for Math Workshop@ ICML 2025. Vancouver: PmLR, 2025.
|
| 73 |
BELLAGENTE M, TOW J, MAHAN D, et al. Stable LM 2 1.6B technical report [EB/OL]. (2024−02−27) [2025−10−17]. https://arxiv.org/abs/2402.17834.
|
| 74 |
MATHEW M, KARATZAS D, JAWAHAR C V. Docvqa: a dataset for vqa on document images [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. [S. l.]: IEEE, 2021: 2200−2209.
|
| 75 |
KAZEMZADEH S, ORDONEZ V, MATTEN M, et al. Referitgame: referring to objects in photographs of natural scenes [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha: Association for Computational Linguistics, 2014: 787−798.
|
| 76 |
TEAM Q. Qwen-VL: a versatile vision-language model for understanding, localization, text reading, and beyond [EB/OL]. (2023−10−13) [2025−10−17]. https://arxiv.org/abs/2308.12966.
|
| 77 |
JIANG A Q, SABLAYROLLES A, ROUX A, et al. Mixtral of experts [EB/OL]. (2024−01−08) [2025−10−17]. https://arxiv.org/abs/2401.04088.
|
| 78 |
LIN B, TANG Z, YE Y, et al. Moe-llava: mixture of experts for large vision-language models [EB/OL]. (2024−12−23) [2025−10−17]. https://arxiv.org/abs/2401.15947.
|
| 79 |
YUE Y, WANG Y, KANG B, et al. Deer-vla: dynamic inference of multimodal large language models for efficient robot execution [C]// Advances in Neural Information Processing Systems. Vancouver: Curran Associates, 2024: 56619−56643.
|
| 80 |
FENG Q, LI W, LIN T, et al. Align-KD: distilling cross-modal alignment knowledge for mobile vision-language large model enhancement [C]// Proceedings of the Computer Vision and Pattern Recognition Conference. Nashville: IEEE, 2025: 4178−4188.
|
| 81 |
KOSKA B, HORVÁTH M. Towards multi-modal mastery: a 4.5 B parameter truly multi-modal small language model [C]// 2024 2nd International Conference on Foundation and Large Language Models (FLLM). [S. l.]: IEEE, 2024: 587−592.
|
| 82 |
LIN H, BAI H, LIU Z, et al. Mope-clip: structured pruning for efficient vision-language models with module-wise pruning error metric [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 27370−27380.
|
| 83 |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International conference on machine learning. [S. l.]: PmLR, 2021: 8748−8763.
|
| 84 |
NING Z, ZHAO J, JIN Q, et al. Inf-MLLM: efficient streaming inference of multimodal large language models on a single GPU [EB/OL]. (2024−09−11) [2025−10−17]. https://arxiv.org/abs/2409.09086.
|
| 85 |
HAN I, ZHANG Z, WANG Z, et al. CalibQuant: 1-Bit KV cache quantization for multimodal LLMs [EB/OL]. (2025−03−24) [2025−10−17]. https://arxiv.org/abs/2502.14882.
|
| 86 |
GAGRANI M, GOEL R, JEON W, et al. On speculative decoding for multimodal large language models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 8285−8289.
|
| 87 |
BAI K, YE L, HUANG R, et al. EdgeMM: multi-core CPU with heterogeneous AI-extension and activation-aware weight pruning for multimodal LLMs at edge [EB/OL]. (2025−05−16) [2025−10−17]. https://arxiv.org/abs/2505.10782.
|
| 88 |
Dimensity 9300 NPU [EB/OL]. (2024−12−23) [2025−10−17]. https://www.mediatek.com/products/smartphones/mediatek-dimensity-9300.
|
| 89 |
MLC TEAM. MLC LLM [EB/OL]. (2025−10−10) [2025−10−17]. https://github.com/mlc-ai/mlc-llm.
|
| 90 |
LV C, NIU C, GU R, et al. Walle: an end-to-end, general-purpose, and large-scale production system for device-cloud collaborative machine learning [C]// 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). Carlsbad: USENIX Association, 2022: 249−265.
|
| 91 |
KWON W, LI Z, ZHUANG S, et al. Efficient memory management for large language model serving with pagedattention [C]// Proceedings of the 29th symposium on operating systems principles. Koblenz: Association for Computing Machinery, 2023: 611−626.
|
| 92 |
GEORGI G. llama. cpp [EB/OL]. [2025−10−17]. https://github.com/ggml-org/llama.cpp.
|
| 93 |
NVIDIA DEVELOPER. Jetson modules, support, ecosystem, and lineup [EB/OL]. [2025−10−17]. https://developer.nvidia.com/embedded/jetson-modules.
|
| 94 |
TVM TEAM. Apache TVM [EB/OL]. (2025−10−10) [2025−10−17]. https://tvm.apache.ac.cn/.
|
| 95 |
ABID A, ABDALLA A, ABID A, et al. Gradio: Hassle-free sharing and testing of ml models in the wild [EB/OL]. (2019−06−06) [2025−10−17]. https://arxiv.org/abs/1906.02569.
|
| 96 |
RJOUB G, ELMEKKI H, ISLAM S, et al A hybrid swarm intelligence approach for optimizing Multimodal Large Language Models deployment in edge-cloud-based Federated Learning environments[J]. Computer Communications, 2025, 237 (C): 108152
doi: 10.1016/j.comcom.2025.108152
|
| 97 |
HU Y, YE D, KANG J, et al A cloud-edge collaborative architecture for multimodal LLMS-based advanced driver assistance systems in IOT networks[J]. IEEE Internet of Things Journal, 2025, 12 (10): 13208- 13221
doi: 10.1109/JIOT.2024.3509628
|
| 98 |
HONG W, WANG W, DING M, et al. Cogvlm2: visual language models for image and video understanding [EB/OL]. (2024−08−29) [2025−10−17]. https://arxiv.org/abs/2408.16500.
|
| 99 |
ACHIAM J, ADLER S, AGARWAL S, et al. Gpt-4 technical report[EB/OL]. (2024−03−04) [2025−10−17]. https://arxiv.org/abs/2303.08774.
|
| 100 |
GAO Z, ZHANG B, LI P, et al. Multi-modal agent tuning: Building a vlm-driven agent for efficient tool usage [C]// 2025 IEEE International Conference on Learning Representation. Singapore: IEEE, 2025.
|
| 101 |
ZIRUI S, YAOHANG L, MENG F, et al. Mmac-copilot: multi-modal agent collaboration operating system copilot [EB/OL]. (2025−03−23) [2025−10−17]. https://arxiv.org/abs/2404.18074.
|
| 102 |
ZHANG C, YANG Z, LIU J, et al. Appagent: Multimodal agents as smartphone users [C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. Yokohama: Association for Computing Machinery, 2025.
|
| 103 |
LI Y, ZHANG C, YANG W, et al. Appagent v2: advanced agent for flexible mobile interactions [EB/OL]. (2025−09−17) [2025−10−17]. https://arxiv.org/abs/2408.11824.
|
| 104 |
YI B, HU X, CHEN Y, et al. EcoAgent: an efficient edge-cloud collaborative multi-agent framework for mobile automation [EB/OL]. (2025−05−09) [2025−10−17]. https://arxiv.org/abs/2505.05440.
|
| 105 |
WANG J, XU H, YE J, et al. Mobile-agent: autonomous multi-modal mobile device agent with visual perception [EB/OL]. (2024−04−18) [2025−10−17]. https://arxiv.org/abs/2401.16158.
|
| 106 |
LIU S, ZENG Z, REN T, et al. Grounding DINO: marrying DINO with grounded pre-training for open-set object detection [C]// European Conference on Computer Vision. Milan: Springer Nature Switzerland, 2024: 38−55.
|
| 107 |
XU Z, ZHANG Y, XIE E, et al Drivegpt4: interpretable end-to-end autonomous driving via large language model[J]. IEEE Robotics and Automation Letters, 2024, 9 (10): 8186- 8193
doi: 10.1109/LRA.2024.3440097
|
| 108 |
XU Z, BAI Y, ZHANG Y, et al. DriveGPT4-V2: harnessing large language model capabilities for enhanced closed-loop autonomous driving [C]// Proceedings of the Computer Vision and Pattern Recognition Conference. Nashville: IEEE, 2025: 17261−17270.
|
| 109 |
ZHENG Y, XING Z, ZHANG Q, et al. Planagent: a multi-modal large language agent for closed-loop vehicle motion planning [EB/OL]. (2024−06−04) [2025−10−17]. https://arxiv.org/abs/2406.01587.
|
| 110 |
ONG X, DING P, FAN Y, et al. Quart-Online: Latency-Free Multimodal Large Language Model for Quadruped Robot Learning [C]// 2025 IEEE International Conference on Robotics and Automation (ICRA). Atlanta: IEEE, 2025: 9533−9539.
|
| 111 |
YAN F, LIU F, ZHENG L, et al. Robomm: all-in-one multimodal large model for robotic manipulation [EB/OL]. (2024−12−10) [2025−10−17]. https://arxiv.org/abs/2412.07215.
|
| 112 |
LIU J, LI C, WANG G, et al. Self-corrected multimodal large language model for end-to-end robot manipulation [EB/OL]. (2024−05−27) [2025−10−17]. https://arxiv.org/html/2405.17418v1.
|
| 113 |
TLUO G, YANG G, GONG Z, et al. Visual embodied brain: Let multimodal large language models see, think, and control in spaces [EB/OL]. (2025−05−30) [2025−10−17]. https://arxiv.org/abs/2506.00123.
|
| 114 |
CHEN J, LIANG H, DU L, et al. OWMM-Agent: open world mobile manipulation with multi-modal agentic data synthesis [EB/OL]. (2025−06−21) [2025−10−17]. https://arxiv.org/abs/2506.04217.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|