[1]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural information Processing Systems . Long Beach: Curran Associates, 2017: 5998−6008.
[本文引用: 1]
[2]
ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning [C]// Advances in Neural Information Processing Systems . New Orleans: Curran Associates, 2022: 23716−23736.
[本文引用: 1]
[3]
YANG Z, LI L, LIN K, et al. The dawn of lmms: Preliminary explorations with gpt-4v (ision) [EB/OL]. (2023−03−04) [2025−10−17]. https://arxiv.org/abs/2303.08774.
[本文引用: 1]
[4]
DOSOVITSKIY A. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021−06−04) [2025−10−17]. https://arxiv.org/abs/2010.11929.
[本文引用: 1]
[5]
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics . Minneapolis: Association for Computational Linguistics, 2019: 4171−4186.
[本文引用: 1]
[6]
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. (2018−06−09) [2025−10−17]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[本文引用: 1]
[7]
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: open and efficient foundation language models [EB/OL]. (2023−02−27) [2025−10−17]. https://arxiv.org/abs/2302.13971.
[本文引用: 3]
[8]
BAI J, BAI S, CHU Y, et al. Qwen technical report [EB/OL]. (2023−09−28) [2025−10−17]. https://arxiv.org/abs/2309.16609.
[本文引用: 5]
[9]
DRIESS D, XIA F, SAJJADI M S, et al. Palm-e: an embodied multimodal language model [EB/OL]. (2023−03−06) [2025−10−17]. https://arxiv.org/abs/2303.03378.
[本文引用: 1]
[10]
TEAM G, ANIL R, BORGEAUD S, et al. Gemini: a family of highly capable multimodal models [EB/OL]. (2025−05−09) [2025−10−17]. https://arxiv.org/abs/2312.11805.
[本文引用: 6]
[11]
CHU X, QIAO L, LIN X, et al. Mobilevlm: a fast, strong and open vision language assistant for mobile devices [EB/OL]. (2023−12−30) [2025−10−17]. https://arxiv.org/abs/2312.16886.
[本文引用: 5]
[12]
YUAN Z, LI Z, HUANG W, et al. Tinygpt-v: efficient multimodal large language model via small backbones [EB/OL]. (2024−01−21) [2025−10−17]. https://arxiv.org/abs/2312.16862.
[本文引用: 2]
[13]
JAVAHERIPI M, BUBECK S, ABDIN M, et al. Phi-2: the surprising power of small language models [EB/OL]. (2023−12−12) [2025−10−17]. https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/.
[本文引用: 7]
[14]
WEI H, KONG L, CHEN J, et al. Small language model meets with reinforced vision vocabulary [EB/OL]. (2024−01−23) [2025−10−17]. https://arxiv.org/abs/2401.12503.
[本文引用: 3]
[15]
CHU X, QIAO L, ZHANG X, et al. Mobilevlm v2: faster and stronger baseline for vision language model [EB/OL]. (2025−02−06) [2025−10−17]. https://arxiv.org/abs/2402.03766.
[本文引用: 2]
[16]
ZHU Y, ZHU M, LIU N, et al. Llava-phi: efficient multi-modal assistant with small language model [C]// Proceedings of the 1st International Workshop on Efficient Multimedia Computing under Limited . New York: Association for Computing Machinery, 2024: 18−22.
[本文引用: 5]
[17]
ZHAO H, ZHANG M, ZHAO W, et al. Cobra: extending mamba to multi-modal large language model for efficient inference [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Philadelphia: AAAI Press, 2025: 10421−10429.
[本文引用: 1]
[18]
GU A, DAO T. Mamba: linear-time sequence modeling with selective state spaces [C]// 1st Conference on Language Modeling . Philadelphia: [s. n. ], 2024.
[本文引用: 1]
[19]
ZHU M, ZHU Y, LIU X, et al. Mipha: a comprehensive overhaul of multimodal assistant with small language models [EB/OL]. (2024−03−25) [2025−10−17]. https://arxiv.org/abs/2403.06199.
[本文引用: 3]
[20]
HINCK M, OLSON M L, COBBLEY D, et al. Llava-gemma: accelerating multimodal foundation models with a compact language [EB/OL]. (2024−06−10) [2025−10−17]. https://arxiv.org/abs/2404.01331.
[本文引用: 2]
[21]
TEAM G, MESNARD T, HARDIN C, et al. Gemma: open models based on gemini research and technology [EB/OL]. (2024−04−16) [2025−10−17]. https://arxiv.org/abs/2403.08295.
[本文引用: 3]
[22]
SHAO Z, YU Z, YU J, et al Imp: highly capable large multimodal models for mobile devices
[J]. IEEE Transactions on Multimedia , 2025 , 27 : 2961 - 2974
DOI:10.1109/TMM.2025.3557680
[本文引用: 2]
[23]
HE M, LIU Y, WU B, et al. Efficient multimodal learning from data-centric perspective [EB/OL]. (2024−07−22) [2025−10−17]. https://arxiv.org/abs/2402.11530.
[本文引用: 1]
[24]
ABDIN M, ANEJA J, AWADALLA H, et al. Phi-3 technical report: a highly capable language model locally on your phone [EB/OL]. (2024−08−30) [2025−10−17]. https://arxiv.org/abs/2404.14219.
[本文引用: 3]
[25]
BEYER L, STEINER A, PINTO A S, et al. Paligemma: a versatile 3b vlm for transfer [EB/OL]. (2024−10−10) [2025−10−17]. https://arxiv.org/abs/2407.07726.
[本文引用: 1]
[26]
CHEN Z, WU J, WANG W, et al. Internvl: scaling up vision foundation models and aligning for generic visual-linguistic tasks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 24185−24198.
[本文引用: 1]
[27]
CAI Z, CAO M, CHEN H, et al. Internlm2 technical report [EB/OL]. (2024−03−26) [2025−10−17]. https://arxiv.org/abs/2403.17297.
[本文引用: 4]
[28]
YAO Y, YU T, ZHANG A, et al. MiniCPM-V 2.6: a GPT-4V level MLLM for single image, multi image and video on your phone [EB/OL]. (2024−08−06) [2025−10−17]. https://github.com/nuoan/MiniCPM-V2.6.
[本文引用: 2]
[29]
HU S, TU Y, HAN X, et al. Minicpm: unveiling the potential of small language models with scalable training strategies [EB/OL]. (2024−06−03) [2025−10−17]. https://arxiv.org/abs/2404.06395.
[本文引用: 3]
[30]
WANG P, BAI S, TAN S, et al. Qwen2-vl: enhancing vision-language model’s perception of the world at any resolution[EB/OL]. (2024−10−03) [2025−10−17]. https://arxiv.org/abs/2409.12191.
[本文引用: 1]
[31]
TEAM Q. Qwen2 technical report [EB/OL]. (2024−09−10) [2025−10−17]. https://arxiv.org/abs/2407.10671.
[本文引用: 3]
[32]
GLM series edge models [EB/OL]. (2025−06−12) [2025−10−17]. https://github.com/zai-org/GLM-Edge.
[本文引用: 2]
[33]
GLM T, ZENG A, XU B, et al. Chatglm: a family of large language models from glm-130b to glm-4 all tools [EB/OL]. (2024−07−30) [2025−10−17]. https://arxiv.org/abs/2406.12793.
[本文引用: 1]
[34]
ZHANG I, PENG W, JENNY N, et al. Ivy-VL: compact vision-language models achieving SOTA with optimal data [EB/OL]. (2024−12−01) [2025−10−17]. https://huggingface.co/AI-Safeguard/Ivy-VL-llava.
[本文引用: 1]
[35]
QWEN TEAM. Qwen2.5: a party of foundation models [EB/OL]. (2024−09−01) [2025−10−17]. https://qwenlm.github.io/blog/qwen2.5/.
[本文引用: 3]
[36]
CHEN Z, WANG W, CAO Y, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling [EB/OL]. (2025−09−26) [2025−10−17]. https://arxiv.org/abs/2412.05271.
[本文引用: 1]
[37]
STEINER A, PINTO A S, TSCHANNEN M, et al. Paligemma 2: a family of versatile vlms for transfer [EB/OL]. (2024−12−04) [2025−10−17]. https://arxiv.org/abs/2412.03555.
[本文引用: 1]
[38]
YAO Y, YU T, ZHANG A, et al. MiniCPM-o 2.6: a GPT-4o level MLLM for vision, speech and multimodal live streaming on your phone [EB/OL]. (2025−01−24) [2025−10−17]. https://github.com/shaneholloman/minicpm-o.
[本文引用: 4]
[39]
LI B, LI Y, LI Z, et al. Megrez-omni technical report [EB/OL]. (2025−02−19) [2025−10−17]. https://arxiv.org/abs/2502.15803.
[本文引用: 3]
[40]
TOUVRON H, MARTIN L, STONE K, et al. Llama 2: open foundation and fine-tuned chat models [EB/OL]. (2023−07−19) [2025−10−17]. https://arxiv.org/abs/2307.09288.
[本文引用: 3]
[41]
MARAFIOTI A, ZOHAR O, FARRÉ M, et al. Smolvlm: redefining small and efficient multimodal models [EB/OL]. (2025−04−07) [2025−10−17]. https://arxiv.org/abs/2504.05299.
[本文引用: 1]
[42]
ALLAL L B, LOZHKOV A, BAKOUCH E, et al. SmolLM2: when smol goes big--data-centric training of a small language model [EB/OL]. (2025−02−24) [2025−10−17]. https://arxiv.org/abs/2502.02737.
[本文引用: 1]
[43]
M87 LABS, INC. Moondream[EB/OL]. (2025−03−27) [2025−10−17]. https://moondream.ai/.
[本文引用: 1]
[44]
LI Y, BUBECK S, ELDAN R, et al. Textbooks are all you need ii: phi-1.5 technical report [EB/OL]. (2023−09−11) [2025−10−17]. https://arxiv.org/abs/2309.05463.
[本文引用: 3]
[45]
ZHU J, WANG W, CHEN Z, et al. Internvl3: exploring advanced training and test-time recipes for open-source multimodal models [EB/OL]. (2025−04−19) [2025−10−17]. https://arxiv.org/abs/2504.10479.
[本文引用: 1]
[46]
TEAM K, DU A, YIN B, et al. Kimi-vl technical report [EB/OL]. (2025−06−23) [2025−10−17]. https://arxiv.org/abs/2504.07491.
[本文引用: 3]
[47]
TEAM G, KAMATH A, FERRET J, et al. Gemma 3n model overview [EB/OL]. (2025−06−30) [2025−10−17]. https://ai.google.dev/gemma/docs/gemma-3n.
[本文引用: 3]
[48]
DEVVRIT F, KUDUGUNTA S, KUSUPATI A, et al. Matformer: nested transformer for elastic inference [C]// Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2024: 140535−140564.
[本文引用: 2]
[49]
XIONG B, CHEN B, WANG C, et al. BlueLM-2.5-3B technical report [EB/OL]. (2025−07−08) [2025−10−17]. https://arxiv.org/abs/2507.05934.
[本文引用: 6]
[50]
YU T, WANG Z, WANG C, et al. Minicpm-v 4.5: cooking efficient mllms via architecture, data, and training recipe[EB/OL]. (2025−09−16) [2025−10−17]. https://arxiv.org/abs/2509.18154.
[本文引用: 5]
[51]
LI J, LI D, SAVARESE S, et al. Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models [C]// International Conference on Machine Learning . Hawaii: JMLR, 2023: 19730−19742.
[本文引用: 1]
[52]
LIU H, LI C, WU Q, et al. Visual instruction tuning [C]// Advances in Neural Information Processing Systems . New Orleans: Curran Associates, 2023: 34892−34916.
[本文引用: 2]
[53]
ZHANG P, ZENG G, WANG T, et al. Tinyllama: an open-source small language model [EB/OL]. (2024−07−04) [2025−10−17]. https://arxiv.org/abs/2401.02385.
[本文引用: 3]
[54]
ZHANG S, FANG Q, YANG Z, et al. Llava-mini: efficient image and video large multimodal models with one vision token [EB/OL]. (2025−03−02) [2025−10−17]. https://arxiv.org/abs/2501.03895.
[本文引用: 2]
[55]
SHAO K, TAO K, ZHANG K, et al. When tokens talk too much: a survey of multimodal long-context token compression across images, videos, and audios [EB/OL]. (2025−08−28) [2025−10−17]. https://arxiv.org/abs/2507.20198.
[本文引用: 1]
[56]
GAO Z, CHEN Z, CUI E, et al Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% performance
[J]. Visual Intelligence , 2024 , 2 (1 ): 32
DOI:10.1007/s44267-024-00067-6
[本文引用: 1]
[57]
LI B, ZHANG Y, GUO D, et al. Llava-onevision: easy visual task transfer [EB/OL]. (2024−10−26) [2025−10−17]. https://arxiv.org/abs/2408.03326.
[本文引用: 1]
[58]
BAI S, CHEN K, LIU X, et al. Qwen2.5-vl technical report [EB/OL]. (2025−02−19) [2025−10−17]. https://arxiv.org/abs/2502.13923.
[本文引用: 2]
[59]
WANG H, YU Z, SPADARO G, et al. Folder: Accelerating multi-modal large language models with enhanced performance [EB/OL]. (2025−04−10) [2025−10−17]. https://arxiv.org/abs/2501.02430.
[本文引用: 1]
[60]
SUN B, ZHANG Y, JIANG S, et al. Hybrid pixel-unshuffled network for lightweight image super-resolution [C]// Proceedings of the AAAI conference on artificial intelligence . Washington DC: AAAI Press, 2023: 2375−2383.
[本文引用: 1]
[61]
CHEN L, ZHAO H, LIU T, et al. An image is worth 1/2 tokens after layer 2: plug-and-play inference acceleration for large vision-language models [C]// European Conference on Computer Vision . Milan: Springer Nature Switzerland, 2024: 19−35.
[本文引用: 1]
[62]
HAN Y, LIU X, DING P, et al. Rethinking token reduction in mllms: towards a unified paradigm for training-free acceleration [EB/OL]. (2024−12−04) [2025−10−17]. https://arxiv.org/html/2411.17686v2.
[本文引用: 1]
[63]
ZHAO Z, LI Y, LI Y. Learning free token reduction for multi-modal large language models [EB/OL]. (2025−09−30) [2025−10−17]. https://arxiv.org/abs/2501.17391.
[本文引用: 1]
[64]
HEO B, PARK S, HAN D, et al. Rotary position embedding for vision transformer [C]// European Conference on Computer Vision . Milan: Springer Nature Switzerland, 2024: 289−305.
[本文引用: 1]
[65]
LI W, ZHOU H, YU J, et al. Coupled mamba: enhanced multimodal fusion with coupled state space model [C]// Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2024: 59808−59832.
[本文引用: 1]
[66]
HU Y, FAN Z, WANG X, et al. TinyAlign: boosting lightweight vision-language models by mitigating modal alignment bottlenecks [EB/OL]. (2025−06−30) [2025−10−17]. https://arxiv.org/abs/2505.12884.
[本文引用: 1]
[67]
META. Llama 3.2: revolutionizing edge AI and vision with open, customizable models [EB/OL]. (2024−09−25) [2025−10−17]. https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/.
[本文引用: 2]
[68]
TEAM Q. Qwen1.5 [EB/OL]. (2024−02−05) [2025−10−17]. https://github.com/QwenLM/Qwen1.5.
[本文引用: 2]
[69]
YANG A, LI A, YANG B, et al. Qwen3 technical report [EB/OL]. (2025−05−14) [2025−10−17]. https://arxiv.org/abs/2505.09388.
[本文引用: 3]
[70]
CHIANG W L, LI Z, LIN Z, et al. Vicuna: an open-source chatbot impressing gpt-4 with 90%* chatgpt quality [EB/OL]. (2023−04−14) [2025−10−17]. https://vicuna. lmsys.org.
[本文引用: 1]
[71]
GUNASEKAR S, ZHANG Y, ANEJA J, et al. Textbooks are all you need [EB/OL]. (2023−10−02) [2025−10−17]. https://arxiv.org/abs/2306.11644.
[本文引用: 2]
[72]
WU Z, HUANG S, ZHOU Z, et al. InternLM2. 5-stepprover: advancing automated theorem proving via critic-guided search [C]// 2nd AI for Math Workshop@ ICML 2025 . Vancouver: PmLR, 2025.
[本文引用: 1]
[73]
BELLAGENTE M, TOW J, MAHAN D, et al. Stable LM 2 1.6B technical report [EB/OL]. (2024−02−27) [2025−10−17]. https://arxiv.org/abs/2402.17834.
[本文引用: 1]
[74]
MATHEW M, KARATZAS D, JAWAHAR C V. Docvqa: a dataset for vqa on document images [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . [S. l.]: IEEE, 2021: 2200−2209.
[本文引用: 1]
[75]
KAZEMZADEH S, ORDONEZ V, MATTEN M, et al. Referitgame: referring to objects in photographs of natural scenes [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) . Doha: Association for Computational Linguistics, 2014: 787−798.
[本文引用: 1]
[76]
TEAM Q. Qwen-VL: a versatile vision-language model for understanding, localization, text reading, and beyond [EB/OL]. (2023−10−13) [2025−10−17]. https://arxiv.org/abs/2308.12966.
[本文引用: 1]
[77]
JIANG A Q, SABLAYROLLES A, ROUX A, et al. Mixtral of experts [EB/OL]. (2024−01−08) [2025−10−17]. https://arxiv.org/abs/2401.04088.
[本文引用: 1]
[78]
LIN B, TANG Z, YE Y, et al. Moe-llava: mixture of experts for large vision-language models [EB/OL]. (2024−12−23) [2025−10−17]. https://arxiv.org/abs/2401.15947.
[本文引用: 1]
[79]
YUE Y, WANG Y, KANG B, et al. Deer-vla: dynamic inference of multimodal large language models for efficient robot execution [C]// Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2024: 56619−56643.
[本文引用: 1]
[80]
FENG Q, LI W, LIN T, et al. Align-KD: distilling cross-modal alignment knowledge for mobile vision-language large model enhancement [C]// Proceedings of the Computer Vision and Pattern Recognition Conference . Nashville: IEEE, 2025: 4178−4188.
[本文引用: 1]
[81]
KOSKA B, HORVÁTH M. Towards multi-modal mastery: a 4.5 B parameter truly multi-modal small language model [C]// 2024 2nd International Conference on Foundation and Large Language Models (FLLM) . [S. l.]: IEEE, 2024: 587−592.
[本文引用: 1]
[82]
LIN H, BAI H, LIU Z, et al. Mope-clip: structured pruning for efficient vision-language models with module-wise pruning error metric [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 27370−27380.
[本文引用: 1]
[83]
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International conference on machine learning . [S. l.]: PmLR, 2021: 8748−8763.
[本文引用: 1]
[84]
NING Z, ZHAO J, JIN Q, et al. Inf-MLLM: efficient streaming inference of multimodal large language models on a single GPU [EB/OL]. (2024−09−11) [2025−10−17]. https://arxiv.org/abs/2409.09086.
[本文引用: 1]
[85]
HAN I, ZHANG Z, WANG Z, et al. CalibQuant: 1-Bit KV cache quantization for multimodal LLMs [EB/OL]. (2025−03−24) [2025−10−17]. https://arxiv.org/abs/2502.14882.
[本文引用: 1]
[86]
GAGRANI M, GOEL R, JEON W, et al. On speculative decoding for multimodal large language models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 8285−8289.
[本文引用: 1]
[87]
BAI K, YE L, HUANG R, et al. EdgeMM: multi-core CPU with heterogeneous AI-extension and activation-aware weight pruning for multimodal LLMs at edge [EB/OL]. (2025−05−16) [2025−10−17]. https://arxiv.org/abs/2505.10782.
[本文引用: 1]
[88]
Dimensity 9300 NPU [EB/OL]. (2024−12−23) [2025−10−17]. https://www.mediatek.com/products/smartphones/mediatek-dimensity-9300.
[本文引用: 1]
[89]
MLC TEAM. MLC LLM [EB/OL]. (2025−10−10) [2025−10−17]. https://github.com/mlc-ai/mlc-llm.
[本文引用: 2]
[90]
LV C, NIU C, GU R, et al. Walle: an end-to-end, general-purpose, and large-scale production system for device-cloud collaborative machine learning [C]// 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) . Carlsbad: USENIX Association, 2022: 249−265.
[本文引用: 2]
[91]
KWON W, LI Z, ZHUANG S, et al. Efficient memory management for large language model serving with pagedattention [C]// Proceedings of the 29th symposium on operating systems principles . Koblenz: Association for Computing Machinery, 2023: 611−626.
[本文引用: 2]
[92]
GEORGI G. llama. cpp [EB/OL]. [2025−10−17]. https://github.com/ggml-org/llama.cpp.
[本文引用: 3]
[93]
NVIDIA DEVELOPER. Jetson modules, support, ecosystem, and lineup [EB/OL]. [2025−10−17]. https://developer.nvidia.com/embedded/jetson-modules.
[本文引用: 1]
[94]
TVM TEAM. Apache TVM [EB/OL]. (2025−10−10) [2025−10−17]. https://tvm.apache.ac.cn/.
[本文引用: 1]
[95]
ABID A, ABDALLA A, ABID A, et al. Gradio: Hassle-free sharing and testing of ml models in the wild [EB/OL]. (2019−06−06) [2025−10−17]. https://arxiv.org/abs/1906.02569.
[本文引用: 1]
[96]
RJOUB G, ELMEKKI H, ISLAM S, et al A hybrid swarm intelligence approach for optimizing Multimodal Large Language Models deployment in edge-cloud-based Federated Learning environments
[J]. Computer Communications , 2025 , 237 (C ): 108152
DOI:10.1016/j.comcom.2025.108152
[本文引用: 2]
[97]
HU Y, YE D, KANG J, et al A cloud-edge collaborative architecture for multimodal LLMS-based advanced driver assistance systems in IOT networks
[J]. IEEE Internet of Things Journal , 2025 , 12 (10 ): 13208 - 13221
DOI:10.1109/JIOT.2024.3509628
[本文引用: 1]
[98]
HONG W, WANG W, DING M, et al. Cogvlm2: visual language models for image and video understanding [EB/OL]. (2024−08−29) [2025−10−17]. https://arxiv.org/abs/2408.16500.
[本文引用: 1]
[99]
ACHIAM J, ADLER S, AGARWAL S, et al. Gpt-4 technical report[EB/OL]. (2024−03−04) [2025−10−17]. https://arxiv.org/abs/2303.08774.
[本文引用: 1]
[100]
GAO Z, ZHANG B, LI P, et al. Multi-modal agent tuning: Building a vlm-driven agent for efficient tool usage [C]// 2025 IEEE International Conference on Learning Representation . Singapore: IEEE, 2025.
[本文引用: 1]
[101]
ZIRUI S, YAOHANG L, MENG F, et al. Mmac-copilot: multi-modal agent collaboration operating system copilot [EB/OL]. (2025−03−23) [2025−10−17]. https://arxiv.org/abs/2404.18074.
[本文引用: 1]
[102]
ZHANG C, YANG Z, LIU J, et al. Appagent: Multimodal agents as smartphone users [C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems . Yokohama: Association for Computing Machinery, 2025.
[本文引用: 1]
[103]
LI Y, ZHANG C, YANG W, et al. Appagent v2: advanced agent for flexible mobile interactions [EB/OL]. (2025−09−17) [2025−10−17]. https://arxiv.org/abs/2408.11824.
[本文引用: 1]
[104]
YI B, HU X, CHEN Y, et al. EcoAgent: an efficient edge-cloud collaborative multi-agent framework for mobile automation [EB/OL]. (2025−05−09) [2025−10−17]. https://arxiv.org/abs/2505.05440.
[本文引用: 1]
[105]
WANG J, XU H, YE J, et al. Mobile-agent: autonomous multi-modal mobile device agent with visual perception [EB/OL]. (2024−04−18) [2025−10−17]. https://arxiv.org/abs/2401.16158.
[本文引用: 1]
[106]
LIU S, ZENG Z, REN T, et al. Grounding DINO: marrying DINO with grounded pre-training for open-set object detection [C]// European Conference on Computer Vision . Milan: Springer Nature Switzerland, 2024: 38−55.
[本文引用: 1]
[107]
XU Z, ZHANG Y, XIE E, et al Drivegpt4: interpretable end-to-end autonomous driving via large language model
[J]. IEEE Robotics and Automation Letters , 2024 , 9 (10 ): 8186 - 8193
DOI:10.1109/LRA.2024.3440097
[本文引用: 1]
[108]
XU Z, BAI Y, ZHANG Y, et al. DriveGPT4-V2: harnessing large language model capabilities for enhanced closed-loop autonomous driving [C]// Proceedings of the Computer Vision and Pattern Recognition Conference . Nashville: IEEE, 2025: 17261−17270.
[本文引用: 1]
[109]
ZHENG Y, XING Z, ZHANG Q, et al. Planagent: a multi-modal large language agent for closed-loop vehicle motion planning [EB/OL]. (2024−06−04) [2025−10−17]. https://arxiv.org/abs/2406.01587.
[本文引用: 1]
[110]
ONG X, DING P, FAN Y, et al. Quart-Online: Latency-Free Multimodal Large Language Model for Quadruped Robot Learning [C]// 2025 IEEE International Conference on Robotics and Automation (ICRA) . Atlanta: IEEE, 2025: 9533−9539.
[本文引用: 1]
[111]
YAN F, LIU F, ZHENG L, et al. Robomm: all-in-one multimodal large model for robotic manipulation [EB/OL]. (2024−12−10) [2025−10−17]. https://arxiv.org/abs/2412.07215.
[本文引用: 1]
[112]
LIU J, LI C, WANG G, et al. Self-corrected multimodal large language model for end-to-end robot manipulation [EB/OL]. (2024−05−27) [2025−10−17]. https://arxiv.org/html/2405.17418v1.
[本文引用: 1]
[113]
TLUO G, YANG G, GONG Z, et al. Visual embodied brain: Let multimodal large language models see, think, and control in spaces [EB/OL]. (2025−05−30) [2025−10−17]. https://arxiv.org/abs/2506.00123.
[本文引用: 1]
[114]
CHEN J, LIANG H, DU L, et al. OWMM-Agent: open world mobile manipulation with multi-modal agentic data synthesis [EB/OL]. (2025−06−21) [2025−10−17]. https://arxiv.org/abs/2506.04217.
[本文引用: 1]
[115]
YANG J, TAN R, WU Q, et al. Magma: a foundation model for multimodal AI agents [C]// Proceedings of the Computer Vision and Pattern Recognition Conference . Nashville: IEEE, 2025: 14203−14214.
[本文引用: 1]
1
... 随着人工智能技术的发展,基于Transformer[1 ] 架构的模型在自然语言处理和计算机视觉领域取得了显著突破,尤其是大语言模型(large language models, LLMs),其通过海量文本预训练和自回归生成机制,展现了强大的语言理解与推理能力. 随着LLMs技术的成熟,研究者将其扩展至多模态领域,推动了多模态大语言模型(multimodal large language models, MLLMs)的发展. 多模态大语言模型通过融合文本、图像、视频等模态,显著提升了跨模态任务的性能. ...
1
... 近年来,跨模态需求的增长推动了多模态大语言模型的快速发展. 这些模型能够深度融合和语义对齐不同模态,提升了图文问答、图像描述、视频理解等任务的表现. 随着模型向生成推理扩展,代表性模型如Flamingo[2 ] 和GPT-4V[3 ] ,具备了处理图像、语音、视频等多模态输入的能力,并具备高阶推理与多轮交互. 与此同时,边缘计算的崛起使得边缘侧设备具备了更多的计算能力,能够进行本地推理,减少云计算的延迟,提升数据隐私性和个性化服务. 然而,多模态大语言模型在边缘侧设备上的部署面临着计算资源和功耗的限制,尤其是大规模模型的计算需求与边缘侧设备能力之间的矛盾. 此外,边缘应用场景高度异构,任务类型和实时性要求各不相同,须对模型进行深度定制和优化. ...
1
... 近年来,跨模态需求的增长推动了多模态大语言模型的快速发展. 这些模型能够深度融合和语义对齐不同模态,提升了图文问答、图像描述、视频理解等任务的表现. 随着模型向生成推理扩展,代表性模型如Flamingo[2 ] 和GPT-4V[3 ] ,具备了处理图像、语音、视频等多模态输入的能力,并具备高阶推理与多轮交互. 与此同时,边缘计算的崛起使得边缘侧设备具备了更多的计算能力,能够进行本地推理,减少云计算的延迟,提升数据隐私性和个性化服务. 然而,多模态大语言模型在边缘侧设备上的部署面临着计算资源和功耗的限制,尤其是大规模模型的计算需求与边缘侧设备能力之间的矛盾. 此外,边缘应用场景高度异构,任务类型和实时性要求各不相同,须对模型进行深度定制和优化. ...
1
... 在当前的多模态模型中,视觉模态通常占据主导地位,因此,编码器部分的研究重点往往集中于视觉领域. 视觉数据,如图像和视频,通常蕴含着丰富的空间信息和细节,这使得编码器的设计必须充分考虑如何高效地从这些数据中提取有意义的特征. 现有研究倾向于采用视觉变换器(vision transformer, ViT[4 ] )之类的架构,以提升特征提取的质量和效率. ...
1
... 大语言模型主干网络(backbone network)是多模态大语言模型的核心部分,负责对从编码器提取的特征以及跨模态融合器融合后的特征进行进一步的处理与分析. 主干网络的设计对模型的整体性能至关重要,因为它将融合后的信息转换为最终的输出结果,直接决定了模型的表达能力和推理效果. 这一部分通常基于Transformer这一典型的自注意力机制架构,如BERT[5 ] 、GPT[6 ] 、LLaMA[7 ] 、Qwen[8 ] 、PaLM[9 ] 等,能够高效地处理和整合来自不同模态的复杂信息. BERT通过双向编码器专注于理解任务;GPT基于解码器在生成任务中表现突出;LLaMA优化了资源利用,适用于低资源环境;Qwen则在生成和推理任务中表现出色;PaLM具备跨任务的泛化能力. ...
1
... 大语言模型主干网络(backbone network)是多模态大语言模型的核心部分,负责对从编码器提取的特征以及跨模态融合器融合后的特征进行进一步的处理与分析. 主干网络的设计对模型的整体性能至关重要,因为它将融合后的信息转换为最终的输出结果,直接决定了模型的表达能力和推理效果. 这一部分通常基于Transformer这一典型的自注意力机制架构,如BERT[5 ] 、GPT[6 ] 、LLaMA[7 ] 、Qwen[8 ] 、PaLM[9 ] 等,能够高效地处理和整合来自不同模态的复杂信息. BERT通过双向编码器专注于理解任务;GPT基于解码器在生成任务中表现突出;LLaMA优化了资源利用,适用于低资源环境;Qwen则在生成和推理任务中表现出色;PaLM具备跨任务的泛化能力. ...
3
... 大语言模型主干网络(backbone network)是多模态大语言模型的核心部分,负责对从编码器提取的特征以及跨模态融合器融合后的特征进行进一步的处理与分析. 主干网络的设计对模型的整体性能至关重要,因为它将融合后的信息转换为最终的输出结果,直接决定了模型的表达能力和推理效果. 这一部分通常基于Transformer这一典型的自注意力机制架构,如BERT[5 ] 、GPT[6 ] 、LLaMA[7 ] 、Qwen[8 ] 、PaLM[9 ] 等,能够高效地处理和整合来自不同模态的复杂信息. BERT通过双向编码器专注于理解任务;GPT基于解码器在生成任务中表现突出;LLaMA优化了资源利用,适用于低资源环境;Qwen则在生成和推理任务中表现出色;PaLM具备跨任务的泛化能力. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
5
... 大语言模型主干网络(backbone network)是多模态大语言模型的核心部分,负责对从编码器提取的特征以及跨模态融合器融合后的特征进行进一步的处理与分析. 主干网络的设计对模型的整体性能至关重要,因为它将融合后的信息转换为最终的输出结果,直接决定了模型的表达能力和推理效果. 这一部分通常基于Transformer这一典型的自注意力机制架构,如BERT[5 ] 、GPT[6 ] 、LLaMA[7 ] 、Qwen[8 ] 、PaLM[9 ] 等,能够高效地处理和整合来自不同模态的复杂信息. BERT通过双向编码器专注于理解任务;GPT基于解码器在生成任务中表现突出;LLaMA优化了资源利用,适用于低资源环境;Qwen则在生成和推理任务中表现出色;PaLM具备跨任务的泛化能力. ...
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 9[8 ]作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... 大语言模型主干网络(backbone network)是多模态大语言模型的核心部分,负责对从编码器提取的特征以及跨模态融合器融合后的特征进行进一步的处理与分析. 主干网络的设计对模型的整体性能至关重要,因为它将融合后的信息转换为最终的输出结果,直接决定了模型的表达能力和推理效果. 这一部分通常基于Transformer这一典型的自注意力机制架构,如BERT[5 ] 、GPT[6 ] 、LLaMA[7 ] 、Qwen[8 ] 、PaLM[9 ] 等,能够高效地处理和整合来自不同模态的复杂信息. BERT通过双向编码器专注于理解任务;GPT基于解码器在生成任务中表现突出;LLaMA优化了资源利用,适用于低资源环境;Qwen则在生成和推理任务中表现出色;PaLM具备跨任务的泛化能力. ...
6
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
10 ]
1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 2024年底至2025年,边缘侧多模态大语言模型的设计已迈入原生端到端阶段,其核心特征在于采用统一架构处理多模态输入,从根本上打破了传统的模块边界. 代表性模型如Gemini Nano[10 ] 和Gemma 3n[47 ] ,均采用共享注意力或统一嵌入空间,使得图像、音频和文本在同一Transformer框架中进行协同建模. 而MiniCPM-V -4.5[50 ] 则将视觉与语言特征完全融合至单一解码器中,支持复杂场景理解与多任务协同. 这类模型真正实现了从输入到输出的一体化推理流程,摆脱了传统连接器和阶段式优化的约束,具备更高的运行紧凑性与能效比. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... [
10 ]
3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 低比特量化通过将模型参数和激活从高精度浮点数转换为固定的低位宽表示,降低存储占用和内存带宽开销. 常见的量化策略包括后训练量化、量化感知训练和混合精度量化,其中后者可以根据模态或网络层灵活分配位宽,以提高计算效率. 其中4位量化(INT4)是一种常见的低比特量化方法. 在实际应用中,MiniCPM-V 4.5[50 ] 通过采用4位量化实现了3倍的模型压缩. Gemini Nano[10 ] 系列则在低内存和高内存边缘侧设备上部署了4位量化模型,验证了低比特量化的可行性. 此外,EAGLE-A[81 ] 通过量化技术将18 GB的FP32模型压缩至3 GB,并在iPhone 15 Pro上实现了实时多模态交互,展示了低比特量化在边缘侧设备上的应用潜力. ...
5
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
11 ]
1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
11 ]
1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 随着边缘侧优化需求的提升,模型设计逐步向弱耦合端到端方向演化. 这一阶段的模型不再仅依赖模块替换,而是引入轻量化的跨模态融合机制,使得模态编码与语言生成能够在边缘侧实现联合优化. 典型策略包括利用轻量交叉注意力层或动态连接模块进行模态对齐,并通过小型语言模型主干(如Phi-2[13 ] 、TinyLlama[53 ] )实现整体推理效率与容量的平衡. 例如,TinyGPT-V[12 ] 和Vary-toy[14 ] 实现了端到端视觉-语言训练路线,LLaVA-Mini[54 ] 通过局部跨模态注意力实现轻融合,而MiniCPM-V 2.6[28 ] 则进一步引入动态配置搜索,使推理过程可根据边缘侧算力自适应调整. 这类模型在保持轻量特征的同时,实现了模态级的联合训练与解码一体化,为真正的端到端推理奠定了基础. ...
7
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
13 ]
3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
13 ]
3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
13 ]
3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 随着边缘侧优化需求的提升,模型设计逐步向弱耦合端到端方向演化. 这一阶段的模型不再仅依赖模块替换,而是引入轻量化的跨模态融合机制,使得模态编码与语言生成能够在边缘侧实现联合优化. 典型策略包括利用轻量交叉注意力层或动态连接模块进行模态对齐,并通过小型语言模型主干(如Phi-2[13 ] 、TinyLlama[53 ] )实现整体推理效率与容量的平衡. 例如,TinyGPT-V[12 ] 和Vary-toy[14 ] 实现了端到端视觉-语言训练路线,LLaVA-Mini[54 ] 通过局部跨模态注意力实现轻融合,而MiniCPM-V 2.6[28 ] 则进一步引入动态配置搜索,使推理过程可根据边缘侧算力自适应调整. 这类模型在保持轻量特征的同时,实现了模态级的联合训练与解码一体化,为真正的端到端推理奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 随着边缘侧优化需求的提升,模型设计逐步向弱耦合端到端方向演化. 这一阶段的模型不再仅依赖模块替换,而是引入轻量化的跨模态融合机制,使得模态编码与语言生成能够在边缘侧实现联合优化. 典型策略包括利用轻量交叉注意力层或动态连接模块进行模态对齐,并通过小型语言模型主干(如Phi-2[13 ] 、TinyLlama[53 ] )实现整体推理效率与容量的平衡. 例如,TinyGPT-V[12 ] 和Vary-toy[14 ] 实现了端到端视觉-语言训练路线,LLaVA-Mini[54 ] 通过局部跨模态注意力实现轻融合,而MiniCPM-V 2.6[28 ] 则进一步引入动态配置搜索,使推理过程可根据边缘侧算力自适应调整. 这类模型在保持轻量特征的同时,实现了模态级的联合训练与解码一体化,为真正的端到端推理奠定了基础. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 在硬件适配方面,传统的CPU/GPU混合调度往往存在高功耗和低能效问题,难以充分发挥硬件的潜力. 为此,研究者提出针对CPU、GPU、NPU以及系统级芯片(system on chip, SoC)的硬件适配优化. 例如,EdgeMM[87 ] 提出多核心CPU架构,集成了脉动阵列协处理器和存算一体宏单元,有效解决了计算密集型与内存密集型任务的瓶颈. GPU在处理多模态大语言模型中的批量计算任务时具有天然的并行计算优势,但传统的调度方式常常面临显存带宽瓶颈;MobileVLM V2[15 ] 通过深度定制CUDA,提升了LDPv2模块的计算效率. NPU作为专用AI计算硬件,在低功耗推理中发挥了重要作用,例如,BlueLM-2.5-3B[49 ] 在Dimensity 9300 NPU[88 ] 上采用动态资源匹配策略,提高了推理速度. SoC通过整合多个计算单元,在硬件资源的协调调度方面发挥重要作用. 例如,Imp[22 ] 方案针对骁龙8Gen3/888芯片,通过分辨率适配与硬件特性匹配协同方案,提高了推理效率并优化了能效. ...
5
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 线性投影层是最直接且轻量化的跨模态连接方式,它通过多层感知机(multi-layer perceptron, MLP)或全连接映射将视觉、音频、传感器序列等模态的特征压缩或投影到语言模型的输入嵌入空间. 这类方法具有较小的参数量和较低的推理延迟,特别适用于边缘侧实时性需求. 例如,Megrez-Omni[39 ] 通过2层MLP将语音特征映射到大语言模型的嵌入空间中,几乎不增加推理开销,并在30 s内完成实时语音问答. 在视觉模态中,LLaVA-Phi[16 ] 采用2层MLP作为投影层,简化了视觉-语言特征对齐的逻辑,降低了算力消耗,从而为边缘侧部署提供了有力支持. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 例如,LLaVA-Phi[16 ] 作为仅2.7×109 参数量的轻量化多模态助手,在边缘计算环境中能高效处理视觉文本协同任务,其核心功能须完全依赖用户指令触发(如解释解答图像中的数学问题),仅通过低延迟的多模态数据处理为用户提供任务支持. 目前部署在边缘侧的智能问答系统一般依赖这种范式. 类似地,T3-Agent[100 ] 也须用户主动提供查询内容及相关多模态数据(如图像和PDF),系统通过视觉分析、代码执行和多模态工具链辅助用户完成信息提取与多步骤推理. 其核心仍然是工具化辅助,属于典型的低自治水平任务. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 最后,多模态协同优化不足是另一个重要挑战. 虽然多模态大语言模型具有视觉和语言组件的交互能力,但许多研究过于聚焦于单一组件的优化,忽略了不同模态之间的适配性[20 ] . 这导致了多模态模型在推理阶段表现不稳定,尤其是在视觉注意力和语言理解之间的协同存在显著差距. 跨模态对齐误差问题依然突出,这直接影响了模型的准确性和效率. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
21 ]
3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
21 ]
3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
Imp: highly capable large multimodal models for mobile devices
2
2025
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 在硬件适配方面,传统的CPU/GPU混合调度往往存在高功耗和低能效问题,难以充分发挥硬件的潜力. 为此,研究者提出针对CPU、GPU、NPU以及系统级芯片(system on chip, SoC)的硬件适配优化. 例如,EdgeMM[87 ] 提出多核心CPU架构,集成了脉动阵列协处理器和存算一体宏单元,有效解决了计算密集型与内存密集型任务的瓶颈. GPU在处理多模态大语言模型中的批量计算任务时具有天然的并行计算优势,但传统的调度方式常常面临显存带宽瓶颈;MobileVLM V2[15 ] 通过深度定制CUDA,提升了LDPv2模块的计算效率. NPU作为专用AI计算硬件,在低功耗推理中发挥了重要作用,例如,BlueLM-2.5-3B[49 ] 在Dimensity 9300 NPU[88 ] 上采用动态资源匹配策略,提高了推理速度. SoC通过整合多个计算单元,在硬件资源的协调调度方面发挥重要作用. 例如,Imp[22 ] 方案针对骁龙8Gen3/888芯片,通过分辨率适配与硬件特性匹配协同方案,提高了推理效率并优化了能效. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
4
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
27 ]
1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
27 ]
1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 随着边缘侧优化需求的提升,模型设计逐步向弱耦合端到端方向演化. 这一阶段的模型不再仅依赖模块替换,而是引入轻量化的跨模态融合机制,使得模态编码与语言生成能够在边缘侧实现联合优化. 典型策略包括利用轻量交叉注意力层或动态连接模块进行模态对齐,并通过小型语言模型主干(如Phi-2[13 ] 、TinyLlama[53 ] )实现整体推理效率与容量的平衡. 例如,TinyGPT-V[12 ] 和Vary-toy[14 ] 实现了端到端视觉-语言训练路线,LLaVA-Mini[54 ] 通过局部跨模态注意力实现轻融合,而MiniCPM-V 2.6[28 ] 则进一步引入动态配置搜索,使推理过程可根据边缘侧算力自适应调整. 这类模型在保持轻量特征的同时,实现了模态级的联合训练与解码一体化,为真正的端到端推理奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
29 ]
8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
29 ]
8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 解码流程优化则旨在减少自回归解码中的串行计算瓶颈,降低生成延迟. 投机解码通过借助轻量级小模型生成候选Token序列,再由大模型批量验证与纠错,避免了逐Token的串行计算. 例如,GLM-Edge-1.5B-Chat[32 ] 模型在骁龙8 Elite平台上利用投机解码快速生成候选Token序列,并通过批量验证大幅降低了推理延迟. 此外,Gagrani等[86 ] 提出的方案在LLaVA-7B[52 ] 主模型和草稿模型之间引入并行验证,提升了推理速度. 在语音生成方面,MiniCPM-o 2.6[38 ] 模型通过流式解码策略与流式因果注意力掩码控制文本与音频Token的交互,成功实现了语音的实时增量生成. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
4
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
... 此外,针对语音模态,MiniCPM-o 2.6[38 ] 提出一种流式编码设计,基于1 s音频块分割与因果注意力范式,能够在保证在线实时处理的同时,最大限度地减少信息损失,从而提升语音模态的推理效率. 尽管语音模态的优化尚处于初步阶段,但这一方法为未来多模态模型中的语音处理提供了有益的思路. ...
... 解码流程优化则旨在减少自回归解码中的串行计算瓶颈,降低生成延迟. 投机解码通过借助轻量级小模型生成候选Token序列,再由大模型批量验证与纠错,避免了逐Token的串行计算. 例如,GLM-Edge-1.5B-Chat[32 ] 模型在骁龙8 Elite平台上利用投机解码快速生成候选Token序列,并通过批量验证大幅降低了推理延迟. 此外,Gagrani等[86 ] 提出的方案在LLaVA-7B[52 ] 主模型和草稿模型之间引入并行验证,提升了推理速度. 在语音生成方面,MiniCPM-o 2.6[38 ] 模型通过流式解码策略与流式因果注意力掩码控制文本与音频Token的交互,成功实现了语音的实时增量生成. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 线性投影层是最直接且轻量化的跨模态连接方式,它通过多层感知机(multi-layer perceptron, MLP)或全连接映射将视觉、音频、传感器序列等模态的特征压缩或投影到语言模型的输入嵌入空间. 这类方法具有较小的参数量和较低的推理延迟,特别适用于边缘侧实时性需求. 例如,Megrez-Omni[39 ] 通过2层MLP将语音特征映射到大语言模型的嵌入空间中,几乎不增加推理开销,并在30 s内完成实时语音问答. 在视觉模态中,LLaVA-Phi[16 ] 采用2层MLP作为投影层,简化了视觉-语言特征对齐的逻辑,降低了算力消耗,从而为边缘侧部署提供了有力支持. ...
... 基于Query的压缩器通过可学习的Query从大规模视觉Token中提取关键信息,显著降低 Token数量和计算开销. 在边缘侧推理中,LLaVA-Mini[54 ] 引入了基于查询向量的压缩模块,使每张图像仅需一个视觉Token表示,极大地减少了计算与显存需求. 此外,Megrez-Omni[39 ] 在视觉特征上引入64个可学习的Query,通过交叉注意力生成64个视觉摘要Token,实现了10×压缩,同时仍能保持较好的语义完整性. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
46 ]
A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 此外,基于混合专家模型(mixture of experts, MoE[77 ] )稀疏化设计,研究者通过引入稀疏激活机制,仅激活部分专家,从而减少计算开销. 例如,MoE-LLaVA[78 ] 将Transformer的前馈网络拆分为多个专家,在推理时仅激活部分专家,从而显著减少计算量. Kimi-VL[46 ] 通过稀疏MoE策略,将语言解码器的总参数量扩展至16.0×109 ,但在实际推理时仅激活2.8×109 专家参数,从而实现了推理加速. 未来,MoE的优化方向包括轻量化路由网络和专家裁剪机制,以进一步降低计算开销和存储负担,推动边缘侧推理效率的提升. ...
3
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 2024年底至2025年,边缘侧多模态大语言模型的设计已迈入原生端到端阶段,其核心特征在于采用统一架构处理多模态输入,从根本上打破了传统的模块边界. 代表性模型如Gemini Nano[10 ] 和Gemma 3n[47 ] ,均采用共享注意力或统一嵌入空间,使得图像、音频和文本在同一Transformer框架中进行协同建模. 而MiniCPM-V -4.5[50 ] 则将视觉与语言特征完全融合至单一解码器中,支持复杂场景理解与多任务协同. 这类模型真正实现了从输入到输出的一体化推理流程,摆脱了传统连接器和阶段式优化的约束,具备更高的运行紧凑性与能效比. ...
... 除了小语言模型和MoE设计外,研究者还对标准Transformer块进行了动态与自适应改进,以应对边缘侧算力有限的挑战. 这些方法通过层级跳过、早停退出或可变注意力机制,根据输入复杂度和上下文冗余度动态调整计算路径,从而实现按需推理,降低延迟和能耗. 例如,MatFormer[48 ] 通过将大模型拆分为多个嵌套的小模型,实现“一次训练,多级推理”的自适应加速,从而灵活选择计算路径以满足不同硬件条件下的需求. Gemma 3n[47 ] 利用MatFormer弹性主干架构,根据硬件条件激活不同深度的子模型,显著降低了计算开销和能耗. DeeR-VLA[79 ] 针对机器人任务优化了早停退出策略,在简单场景下仅激活部分Transformer块即可输出可靠动作,从而降低计算成本并满足边缘侧实时需求. ...
2
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 除了小语言模型和MoE设计外,研究者还对标准Transformer块进行了动态与自适应改进,以应对边缘侧算力有限的挑战. 这些方法通过层级跳过、早停退出或可变注意力机制,根据输入复杂度和上下文冗余度动态调整计算路径,从而实现按需推理,降低延迟和能耗. 例如,MatFormer[48 ] 通过将大模型拆分为多个嵌套的小模型,实现“一次训练,多级推理”的自适应加速,从而灵活选择计算路径以满足不同硬件条件下的需求. Gemma 3n[47 ] 利用MatFormer弹性主干架构,根据硬件条件激活不同深度的子模型,显著降低了计算开销和能耗. DeeR-VLA[79 ] 针对机器人任务优化了早停退出策略,在简单场景下仅激活部分Transformer块即可输出可靠动作,从而降低计算成本并满足边缘侧实时需求. ...
6
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... [
49 ]
2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
... 知识蒸馏通过将教师模型的知识传递给学生模型,显著降低模型规模和计算开销,同时保持多模态推理能力. 现有的蒸馏策略包括输出分数蒸馏、特征蒸馏和跨模态蒸馏,这些方法帮助学生模型在不同层级和模态上获得更全面的知识. 例如,BlueLM-2.5-3B[49 ] 通过蒸馏和剪枝,将7.0×109 教师模型缩减至3.0×109 ,并保持了与Qwen3-4B[69 ] 相当的性能. Align-KD[80 ] 则通过跨模态对齐知识蒸馏,显著提升了学生模型在多模态任务中的表现. ...
... 并行化通过跨模块和跨硬件资源的任务调度来提升推理效率. 流水线并行是一种典型策略,它将模型的多层级结构拆分为多个计算阶段,并将这些阶段分配给不同的硬件计算单元,利用多阶段计算的重叠执行提升资源利用率,降低推理延迟. 例如,BlueLM-2.5-3B[49 ] 模型在视觉处理阶段采用流水线并行策略,将卷积层任务分配给CPU,视觉Transformer层分配给NPU,避免了硬件资源的空闲,从而提升了整体算力利用率. ...
... 在硬件适配方面,传统的CPU/GPU混合调度往往存在高功耗和低能效问题,难以充分发挥硬件的潜力. 为此,研究者提出针对CPU、GPU、NPU以及系统级芯片(system on chip, SoC)的硬件适配优化. 例如,EdgeMM[87 ] 提出多核心CPU架构,集成了脉动阵列协处理器和存算一体宏单元,有效解决了计算密集型与内存密集型任务的瓶颈. GPU在处理多模态大语言模型中的批量计算任务时具有天然的并行计算优势,但传统的调度方式常常面临显存带宽瓶颈;MobileVLM V2[15 ] 通过深度定制CUDA,提升了LDPv2模块的计算效率. NPU作为专用AI计算硬件,在低功耗推理中发挥了重要作用,例如,BlueLM-2.5-3B[49 ] 在Dimensity 9300 NPU[88 ] 上采用动态资源匹配策略,提高了推理速度. SoC通过整合多个计算单元,在硬件资源的协调调度方面发挥重要作用. 例如,Imp[22 ] 方案针对骁龙8Gen3/888芯片,通过分辨率适配与硬件特性匹配协同方案,提高了推理效率并优化了能效. ...
5
... Multi-modal large language model on edge side
Tab.1 模型名字 输入模态 输出模态 大模型主干 总参数量/109 时间 1) 注:总参数量中A/E标注分别表示MoE模型激活参数量(如A3)与显存等效参数量(如E2),旨在说明模型在边缘侧的实际计算负载与资源占用 Gemini Nano[10 ] 文本、图像、音频、视频 文本 Gemini[10 ] 1.8/3.25 2023.12 MobileVLM[11 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0 2023.12 TinyGPT-V[12 ] 文本、图像 文本 Phi-2[13 ] 2.8 2023.12 Vary-toy[14 ] 文本、图像 文本 Qwen[8 ] 1.8 2024.01 MobileVLM V2[15 ] 文本、图像 文本 MobileLLaMA[11 ] 1.7/3.0/7.0 2024.02 LLaVA-Phi[16 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.02 Cobra[17 ] 文本、图像 文本 Mamba[18 ] 2.8 2024.03 Mipha[19 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.03 LLaVA-Gemma[20 ] 文本、图像 文本 Gemma[21 ] 2.0/7.0 2024.04 Imp[22 ] 文本、图像 文本 Phi-2[13 ] 3.0 2024.05 Bunny[23 ] 文本、图像 文本 Phi-3[24 ] 4.0 2024.07 PaliGemma[25 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.07 InternVL2[26 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.07 MiniCPM-V 2.6[28 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2024.08 Qwen2-VL[30 ] 文本、图像、视频 文本 Qwen2[31 ] 2.0 2024.09 GLM-Edge[32 ] 文本、图像 文本 GLM-4[33 ] 1.5/2.0/4.0/5.0 2024.11 Ivy-VL[34 ] 文本、图像 文本 Qwen2.5[35 ] 3.0 2024.12 InternVL2.5[36 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/4.0/8.0 2024.12 PaliGemma2[37 ] 文本、图像 文本 Gemma[21 ] 3.0 2024.12 MiniCPM-o 2.6[38 ] 文本、图像、音频、视频 文本、音频 MiniCPM[29 ] 8.0 2025.01 Megrez-Omni[39 ] 文本、图像、音频 文本 LLaMA2[40 ] 4.0 2025.02 SmolVLM2[41 ] 文本、图像 文本 SmolLM2[42 ] 0.256/0.5/2.2 2025.02 Moondream[43 ] 文本、图像 文本 Phi-1.5[44 ] 0.5/2.0 2025.03 InternVL3[45 ] 文本、图像、视频 文本 InternLM2[27 ] 1.0/2.0/8.0 2025.04 Kimi-VL[46 ] 文本、图像、视频 文本 Moonlight[46 ] A31) 2025.04 Gemma 3n[47 ] 文本、图像、音频、视频 文本 MatFormer[48 ] 5.0(E2)/8.0(E4) 2025.06 BlueLM-2.5[49 ] 文本、图像 文本 BlueLM[49 ] 2.9 2025.07 MiniCPM-V 4.5[50 ] 文本、图像、视频 文本 MiniCPM[29 ] 8.0 2025.09
早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 2024年底至2025年,边缘侧多模态大语言模型的设计已迈入原生端到端阶段,其核心特征在于采用统一架构处理多模态输入,从根本上打破了传统的模块边界. 代表性模型如Gemini Nano[10 ] 和Gemma 3n[47 ] ,均采用共享注意力或统一嵌入空间,使得图像、音频和文本在同一Transformer框架中进行协同建模. 而MiniCPM-V -4.5[50 ] 则将视觉与语言特征完全融合至单一解码器中,支持复杂场景理解与多任务协同. 这类模型真正实现了从输入到输出的一体化推理流程,摆脱了传统连接器和阶段式优化的约束,具备更高的运行紧凑性与能效比. ...
... 低比特量化通过将模型参数和激活从高精度浮点数转换为固定的低位宽表示,降低存储占用和内存带宽开销. 常见的量化策略包括后训练量化、量化感知训练和混合精度量化,其中后者可以根据模态或网络层灵活分配位宽,以提高计算效率. 其中4位量化(INT4)是一种常见的低比特量化方法. 在实际应用中,MiniCPM-V 4.5[50 ] 通过采用4位量化实现了3倍的模型压缩. Gemini Nano[10 ] 系列则在低内存和高内存边缘侧设备上部署了4位量化模型,验证了低比特量化的可行性. 此外,EAGLE-A[81 ] 通过量化技术将18 GB的FP32模型压缩至3 GB,并在iPhone 15 Pro上实现了实时多模态交互,展示了低比特量化在边缘侧设备上的应用潜力. ...
... 编译优化则通过深度绑定计算图与硬件架构,进一步提升运行效率. MiniCPM-V 4.5[50 ] 的研究表明,通过对模型进行编译优化,可以在低算力的网络边缘侧资源受限的设备上实现接近定制化硬件的执行效率,从而有效提升边缘侧推理性能. ...
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
1
... 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
2
... 早期的边缘侧多模态模型主要采用轻量化改造的思路,即在已有的云端多模态架构(如BLIP-2[51 ] 或LLaVA[52 ] )基础上进行模块化裁剪与结构蒸馏. 这类模型通常保留视觉编码器、连接器和语言模型的分层结构,通过引入Token池化、空间重排、块合并等压缩策略对视觉端进行优化,通过结构剪枝与量化感知训练对语言端进行压缩,并在跨模态层面简化投影器设计,从而显著降低计算量与存储开销. 典型代表如MobileVLM[11 ] 、LLaVA-Phi[16 ] 和Mipha[19 ] ,在保持主干架构不变的前提下完成边缘侧适配,实现了在边缘侧设备上的高效推理. 虽然推理路径仍具模块化特征,但这一阶段的研究首次验证了多模态大语言模型在边缘侧运行的可行性,为后续更深层次的融合探索奠定了基础. ...
... 解码流程优化则旨在减少自回归解码中的串行计算瓶颈,降低生成延迟. 投机解码通过借助轻量级小模型生成候选Token序列,再由大模型批量验证与纠错,避免了逐Token的串行计算. 例如,GLM-Edge-1.5B-Chat[32 ] 模型在骁龙8 Elite平台上利用投机解码快速生成候选Token序列,并通过批量验证大幅降低了推理延迟. 此外,Gagrani等[86 ] 提出的方案在LLaVA-7B[52 ] 主模型和草稿模型之间引入并行验证,提升了推理速度. 在语音生成方面,MiniCPM-o 2.6[38 ] 模型通过流式解码策略与流式因果注意力掩码控制文本与音频Token的交互,成功实现了语音的实时增量生成. ...
3
... 随着边缘侧优化需求的提升,模型设计逐步向弱耦合端到端方向演化. 这一阶段的模型不再仅依赖模块替换,而是引入轻量化的跨模态融合机制,使得模态编码与语言生成能够在边缘侧实现联合优化. 典型策略包括利用轻量交叉注意力层或动态连接模块进行模态对齐,并通过小型语言模型主干(如Phi-2[13 ] 、TinyLlama[53 ] )实现整体推理效率与容量的平衡. 例如,TinyGPT-V[12 ] 和Vary-toy[14 ] 实现了端到端视觉-语言训练路线,LLaVA-Mini[54 ] 通过局部跨模态注意力实现轻融合,而MiniCPM-V 2.6[28 ] 则进一步引入动态配置搜索,使推理过程可根据边缘侧算力自适应调整. 这类模型在保持轻量特征的同时,实现了模态级的联合训练与解码一体化,为真正的端到端推理奠定了基础. ...
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... 随着边缘侧优化需求的提升,模型设计逐步向弱耦合端到端方向演化. 这一阶段的模型不再仅依赖模块替换,而是引入轻量化的跨模态融合机制,使得模态编码与语言生成能够在边缘侧实现联合优化. 典型策略包括利用轻量交叉注意力层或动态连接模块进行模态对齐,并通过小型语言模型主干(如Phi-2[13 ] 、TinyLlama[53 ] )实现整体推理效率与容量的平衡. 例如,TinyGPT-V[12 ] 和Vary-toy[14 ] 实现了端到端视觉-语言训练路线,LLaVA-Mini[54 ] 通过局部跨模态注意力实现轻融合,而MiniCPM-V 2.6[28 ] 则进一步引入动态配置搜索,使推理过程可根据边缘侧算力自适应调整. 这类模型在保持轻量特征的同时,实现了模态级的联合训练与解码一体化,为真正的端到端推理奠定了基础. ...
... 基于Query的压缩器通过可学习的Query从大规模视觉Token中提取关键信息,显著降低 Token数量和计算开销. 在边缘侧推理中,LLaVA-Mini[54 ] 引入了基于查询向量的压缩模块,使每张图像仅需一个视觉Token表示,极大地减少了计算与显存需求. 此外,Megrez-Omni[39 ] 在视觉特征上引入64个可学习的Query,通过交叉注意力生成64个视觉摘要Token,实现了10×压缩,同时仍能保持较好的语义完整性. ...
1
... 作为多模态大语言模型的前端模块,模态编码器负责将不同类型的原始输入映射为统一的语义表示. 研究[55 ]表明,视觉编码器通常是推理延迟和计算开销的主要瓶颈. 因为高分辨率图像需要被划分为大量视觉Token进行处理,这显著增加了计算负担. 因此,优化视觉输入的表示成为当前研究的重点. 尽管视觉模态优化已经取得了显著进展,但对于其他模态(如语音)的编码器优化的研究仍相对较少. ...
Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% performance
1
2024
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
1
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
2
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
... 稀疏注意力机制在处理高分辨率图像时,传统视觉Transformer架构面临$ O({N}^{2}) $ [58 ] 采用窗口注意力机制减少计算复杂度,并引入二维旋转位置编码(2D rotational positional encoding, 2D-RoPE[64 ] )增强对多分辨率图像的处理能力. ...
1
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
1
... 在视觉输入的优化方面,视觉Token压缩成为提升推理效率的关键问题. 与文本领域不同,图像数据具有空间相关性、时序连续性、感知冗余等独特的冗余模式,因此须专门设计适应视觉特性的压缩策略. 主要的视觉Token压缩方法包括动态分辨率处理、空间下采样与聚合,以及渐进式上采样压缩等. 动态分辨率处理通过自适应控制输入 Token数量来平衡算力约束与视觉细节保留,例如Mini-InternVL[56 ] 和MiniCPM-o 2.6[38 ] . 空间下采样方法通过池化、卷积操作直接减少视觉Token数量,如LLaVA-OneVision[57 ] 和BlueLM-2.5-3B[49 ] . 语义聚合则在编码器的深层阶段进一步压缩Token,如Qwen2.5-VL[58 ] 和FOLDER[59 ] 通过语义驱动的聚合策略,分别实现了Token剪枝和推理加速. Pixel Unshuffle[60 ] 通过空间与通道维度的重排来压缩视觉Token,有效减轻了计算开销. ...
1
... Token丢弃策略通过在推理阶段动态剔除冗余视觉信息,减少计算和存储开销,同时保持较高的性能. 与结构重构方法不同,Token丢弃不需要修改模型权重,可以即插即用地嵌入推理流程,具有较高的实用性. 例如,FastV[61 ] 基于浅层与深层注意力分布的差异动态选择性丢弃冗余 Tokens,FiCoCo[62 ] 在视觉和解码阶段分别进行空间均匀丢弃和文本相关性优化,LFTR[63 ] 则通过视频场景下的冗余融合实现高效压缩. ...
1
... Token丢弃策略通过在推理阶段动态剔除冗余视觉信息,减少计算和存储开销,同时保持较高的性能. 与结构重构方法不同,Token丢弃不需要修改模型权重,可以即插即用地嵌入推理流程,具有较高的实用性. 例如,FastV[61 ] 基于浅层与深层注意力分布的差异动态选择性丢弃冗余 Tokens,FiCoCo[62 ] 在视觉和解码阶段分别进行空间均匀丢弃和文本相关性优化,LFTR[63 ] 则通过视频场景下的冗余融合实现高效压缩. ...
1
... Token丢弃策略通过在推理阶段动态剔除冗余视觉信息,减少计算和存储开销,同时保持较高的性能. 与结构重构方法不同,Token丢弃不需要修改模型权重,可以即插即用地嵌入推理流程,具有较高的实用性. 例如,FastV[61 ] 基于浅层与深层注意力分布的差异动态选择性丢弃冗余 Tokens,FiCoCo[62 ] 在视觉和解码阶段分别进行空间均匀丢弃和文本相关性优化,LFTR[63 ] 则通过视频场景下的冗余融合实现高效压缩. ...
1
... 稀疏注意力机制在处理高分辨率图像时,传统视觉Transformer架构面临$ O({N}^{2}) $ [58 ] 采用窗口注意力机制减少计算复杂度,并引入二维旋转位置编码(2D rotational positional encoding, 2D-RoPE[64 ] )增强对多分辨率图像的处理能力. ...
1
... 除了这2种主流的跨模态连接器,另一些探索性方法也在不断发展. 例如,Coupled Mamba[65 ] 是非传统的结构改造型跨模态连接器,它采用耦合状态空间模型来替代传统Transformer的跨模态融合器,从而显著提升推理效率并减少显存占用. 功能增强型方案如TinyAlign[66 ] ,通过在 MLP上插入RAG-Connector(retrieval-augmented generation, RAG)模块,将检索到的信息增强并拼接到输出中,从而提升模型的准确性. ...
1
... 除了这2种主流的跨模态连接器,另一些探索性方法也在不断发展. 例如,Coupled Mamba[65 ] 是非传统的结构改造型跨模态连接器,它采用耦合状态空间模型来替代传统Transformer的跨模态融合器,从而显著提升推理效率并减少显存占用. 功能增强型方案如TinyAlign[66 ] ,通过在 MLP上插入RAG-Connector(retrieval-augmented generation, RAG)模块,将检索到的信息增强并拼接到输出中,从而提升模型的准确性. ...
2
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
2
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
3
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 知识蒸馏通过将教师模型的知识传递给学生模型,显著降低模型规模和计算开销,同时保持多模态推理能力. 现有的蒸馏策略包括输出分数蒸馏、特征蒸馏和跨模态蒸馏,这些方法帮助学生模型在不同层级和模态上获得更全面的知识. 例如,BlueLM-2.5-3B[49 ] 通过蒸馏和剪枝,将7.0×109 教师模型缩减至3.0×109 ,并保持了与Qwen3-4B[69 ] 相当的性能. Align-KD[80 ] 则通过跨模态对齐知识蒸馏,显著提升了学生模型在多模态任务中的表现. ...
1
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
2
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... LLMs backbone for edge-side deployment
Tab.2 模型系列 模型名称 参数量/109 LLaMA LLaMA[7 ] 7.0 LLaMA2[40 ] 7.0 LLaMA3.2[67 ] 1.0/3.0 Qwen Qwen[8 ] 1.8/7.0 Qwen1.5[68 ] 0.5/1.8/4.0/7.0 Qwen2[31 ] 0.5/1.5/7.0 Qwen2.5[35 ] 0.5/1.5/3.0/7.0 Qwen3[69 ] 0.6/1.7/4.0/8.0 Vicuna Vicuna[70 ] 7.0 MobileLLaMA MobileLLaMA[11 ] 1.3/3.1 Gemini Gemini Nano1[10 ] 1.8 Gemini Nano2[10 ] 3.25 Phi Phi-1[71 ] 1.3 Phi-1.5[44 ] 1.3 Phi-2[13 ] 2.7 Phi-3[24 ] 3.8/7.0 InternLM InternLM2[27 ] 1.8 InternLM2.5[72 ] 7.0 TinyLlama TinyLlama[53 ] 1.1
为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... 为此,已有研究引入小参数大语言模型(small language models, SLM). 小语言模型作为一种轻量级的模型设计方案,通常采用较小的参数规模(通常为1×109 ~3×109 参数量),突破传统依赖大模型的范式. 常见小语言模型包Phi系列[13 , 24 , 44 , 71 ] 、TinyLlama[53 ] 、StableLM2[73 ] 和Qwen[8 , 31 , 35 , 68 , 69 ] 等,这些模型在保留较高性能的同时,有效降低了计算开销和显存需求,确保边缘侧设备能够高效运行. 例如,LLaVA-Phi[16 ] 采用了2.7×109 参数量的Phi-2作为主干,并经过微调后,在多模态任务中达到了接近大模型的效果. 类似的,Mipha[19 ] 利用Phi-2模型,结合高效的预训练特性和适配多模态输入的接口,在小参数规模下实现了超越部分大模型的表现. Vary-toy[14 ] 模型采用Qwen-1.8×109[8 ] 作为基础语言模型,在DocVQA[74 ] 和RefCOCO[75 ] 任务上表现出与7×109 级Qwen-VL-chat[76 ] 相当的性能. 这些小语言模型的设计展示了在边缘侧推理任务中的巨大潜力,为资源受限的边缘侧设备提供了高效的解决方案. ...
1
... 此外,基于混合专家模型(mixture of experts, MoE[77 ] )稀疏化设计,研究者通过引入稀疏激活机制,仅激活部分专家,从而减少计算开销. 例如,MoE-LLaVA[78 ] 将Transformer的前馈网络拆分为多个专家,在推理时仅激活部分专家,从而显著减少计算量. Kimi-VL[46 ] 通过稀疏MoE策略,将语言解码器的总参数量扩展至16.0×109 ,但在实际推理时仅激活2.8×109 专家参数,从而实现了推理加速. 未来,MoE的优化方向包括轻量化路由网络和专家裁剪机制,以进一步降低计算开销和存储负担,推动边缘侧推理效率的提升. ...
1
... 此外,基于混合专家模型(mixture of experts, MoE[77 ] )稀疏化设计,研究者通过引入稀疏激活机制,仅激活部分专家,从而减少计算开销. 例如,MoE-LLaVA[78 ] 将Transformer的前馈网络拆分为多个专家,在推理时仅激活部分专家,从而显著减少计算量. Kimi-VL[46 ] 通过稀疏MoE策略,将语言解码器的总参数量扩展至16.0×109 ,但在实际推理时仅激活2.8×109 专家参数,从而实现了推理加速. 未来,MoE的优化方向包括轻量化路由网络和专家裁剪机制,以进一步降低计算开销和存储负担,推动边缘侧推理效率的提升. ...
1
... 除了小语言模型和MoE设计外,研究者还对标准Transformer块进行了动态与自适应改进,以应对边缘侧算力有限的挑战. 这些方法通过层级跳过、早停退出或可变注意力机制,根据输入复杂度和上下文冗余度动态调整计算路径,从而实现按需推理,降低延迟和能耗. 例如,MatFormer[48 ] 通过将大模型拆分为多个嵌套的小模型,实现“一次训练,多级推理”的自适应加速,从而灵活选择计算路径以满足不同硬件条件下的需求. Gemma 3n[47 ] 利用MatFormer弹性主干架构,根据硬件条件激活不同深度的子模型,显著降低了计算开销和能耗. DeeR-VLA[79 ] 针对机器人任务优化了早停退出策略,在简单场景下仅激活部分Transformer块即可输出可靠动作,从而降低计算成本并满足边缘侧实时需求. ...
1
... 知识蒸馏通过将教师模型的知识传递给学生模型,显著降低模型规模和计算开销,同时保持多模态推理能力. 现有的蒸馏策略包括输出分数蒸馏、特征蒸馏和跨模态蒸馏,这些方法帮助学生模型在不同层级和模态上获得更全面的知识. 例如,BlueLM-2.5-3B[49 ] 通过蒸馏和剪枝,将7.0×109 教师模型缩减至3.0×109 ,并保持了与Qwen3-4B[69 ] 相当的性能. Align-KD[80 ] 则通过跨模态对齐知识蒸馏,显著提升了学生模型在多模态任务中的表现. ...
1
... 低比特量化通过将模型参数和激活从高精度浮点数转换为固定的低位宽表示,降低存储占用和内存带宽开销. 常见的量化策略包括后训练量化、量化感知训练和混合精度量化,其中后者可以根据模态或网络层灵活分配位宽,以提高计算效率. 其中4位量化(INT4)是一种常见的低比特量化方法. 在实际应用中,MiniCPM-V 4.5[50 ] 通过采用4位量化实现了3倍的模型压缩. Gemini Nano[10 ] 系列则在低内存和高内存边缘侧设备上部署了4位量化模型,验证了低比特量化的可行性. 此外,EAGLE-A[81 ] 通过量化技术将18 GB的FP32模型压缩至3 GB,并在iPhone 15 Pro上实现了实时多模态交互,展示了低比特量化在边缘侧设备上的应用潜力. ...
1
... 剪枝通过移除冗余的权重或算子结构来降低计算量和存储需求. 其中,结构化剪枝通过删除整个网络结构单元(如注意力头或MLP层)来减少计算复杂度;而非结构化剪枝则通过对权重矩阵进行稀疏化来减少存储需求,不过这需要硬件对稀疏计算的支持. 此外,模态特异性剪枝则专门针对不同模态的冗余性进行选择性剪枝,例如减少视觉塔的计算量,以优化视觉模态的计算效率. 在实践中,MoPE-CLIP[82 ] 通过结构化剪枝和蒸馏优化了CLIP[83 ] 模型的双塔结构,不仅减少了计算开销,还保留了多模态表示能力. ...
1
... 剪枝通过移除冗余的权重或算子结构来降低计算量和存储需求. 其中,结构化剪枝通过删除整个网络结构单元(如注意力头或MLP层)来减少计算复杂度;而非结构化剪枝则通过对权重矩阵进行稀疏化来减少存储需求,不过这需要硬件对稀疏计算的支持. 此外,模态特异性剪枝则专门针对不同模态的冗余性进行选择性剪枝,例如减少视觉塔的计算量,以优化视觉模态的计算效率. 在实践中,MoPE-CLIP[82 ] 通过结构化剪枝和蒸馏优化了CLIP[83 ] 模型的双塔结构,不仅减少了计算开销,还保留了多模态表示能力. ...
1
... KV-Cache优化是提升推理效率的重要技术之一. 在Transformer模型中,解码器需要根据输入的Token序列生成一系列的查询(Query, Q)、键(Key, K)和值(Value, V)向量,这些向量用于计算注意力权重并生成输出. 当输入序列较长时,解码器需要重复计算这些向量. KV-Cache技术通过将历史的键向量与值向量缓存下来,避免了对历史Token的重复计算,从而提高了推理效率. 由于边缘侧设备的存储限制,KV-Cache优化主要集中在稀疏化和量化2个方面. 稀疏化技术通过压缩缓存槽位的数量,减少冗余信息,从而降低存储占用和计算量;量化技术则通过将数据格式从FP16转换为INT8或INT4等低精度格式,减少内存带宽需求并加速低精度计算,提升推理速度. 例如,Inf-MLLM[84 ] 通过注意力鞍点淘汰机制筛选出重要Tokens,在边缘侧设备上实现流式推理,显著提高了推理效率;而CalibQuant[85 ] 通过1-bit量化技术与KV缓存的后缩放与校准,提升了存储压缩率,并几乎没有损失推理精度. ...
1
... KV-Cache优化是提升推理效率的重要技术之一. 在Transformer模型中,解码器需要根据输入的Token序列生成一系列的查询(Query, Q)、键(Key, K)和值(Value, V)向量,这些向量用于计算注意力权重并生成输出. 当输入序列较长时,解码器需要重复计算这些向量. KV-Cache技术通过将历史的键向量与值向量缓存下来,避免了对历史Token的重复计算,从而提高了推理效率. 由于边缘侧设备的存储限制,KV-Cache优化主要集中在稀疏化和量化2个方面. 稀疏化技术通过压缩缓存槽位的数量,减少冗余信息,从而降低存储占用和计算量;量化技术则通过将数据格式从FP16转换为INT8或INT4等低精度格式,减少内存带宽需求并加速低精度计算,提升推理速度. 例如,Inf-MLLM[84 ] 通过注意力鞍点淘汰机制筛选出重要Tokens,在边缘侧设备上实现流式推理,显著提高了推理效率;而CalibQuant[85 ] 通过1-bit量化技术与KV缓存的后缩放与校准,提升了存储压缩率,并几乎没有损失推理精度. ...
1
... 解码流程优化则旨在减少自回归解码中的串行计算瓶颈,降低生成延迟. 投机解码通过借助轻量级小模型生成候选Token序列,再由大模型批量验证与纠错,避免了逐Token的串行计算. 例如,GLM-Edge-1.5B-Chat[32 ] 模型在骁龙8 Elite平台上利用投机解码快速生成候选Token序列,并通过批量验证大幅降低了推理延迟. 此外,Gagrani等[86 ] 提出的方案在LLaVA-7B[52 ] 主模型和草稿模型之间引入并行验证,提升了推理速度. 在语音生成方面,MiniCPM-o 2.6[38 ] 模型通过流式解码策略与流式因果注意力掩码控制文本与音频Token的交互,成功实现了语音的实时增量生成. ...
1
... 在硬件适配方面,传统的CPU/GPU混合调度往往存在高功耗和低能效问题,难以充分发挥硬件的潜力. 为此,研究者提出针对CPU、GPU、NPU以及系统级芯片(system on chip, SoC)的硬件适配优化. 例如,EdgeMM[87 ] 提出多核心CPU架构,集成了脉动阵列协处理器和存算一体宏单元,有效解决了计算密集型与内存密集型任务的瓶颈. GPU在处理多模态大语言模型中的批量计算任务时具有天然的并行计算优势,但传统的调度方式常常面临显存带宽瓶颈;MobileVLM V2[15 ] 通过深度定制CUDA,提升了LDPv2模块的计算效率. NPU作为专用AI计算硬件,在低功耗推理中发挥了重要作用,例如,BlueLM-2.5-3B[49 ] 在Dimensity 9300 NPU[88 ] 上采用动态资源匹配策略,提高了推理速度. SoC通过整合多个计算单元,在硬件资源的协调调度方面发挥重要作用. 例如,Imp[22 ] 方案针对骁龙8Gen3/888芯片,通过分辨率适配与硬件特性匹配协同方案,提高了推理效率并优化了能效. ...
1
... 在硬件适配方面,传统的CPU/GPU混合调度往往存在高功耗和低能效问题,难以充分发挥硬件的潜力. 为此,研究者提出针对CPU、GPU、NPU以及系统级芯片(system on chip, SoC)的硬件适配优化. 例如,EdgeMM[87 ] 提出多核心CPU架构,集成了脉动阵列协处理器和存算一体宏单元,有效解决了计算密集型与内存密集型任务的瓶颈. GPU在处理多模态大语言模型中的批量计算任务时具有天然的并行计算优势,但传统的调度方式常常面临显存带宽瓶颈;MobileVLM V2[15 ] 通过深度定制CUDA,提升了LDPv2模块的计算效率. NPU作为专用AI计算硬件,在低功耗推理中发挥了重要作用,例如,BlueLM-2.5-3B[49 ] 在Dimensity 9300 NPU[88 ] 上采用动态资源匹配策略,提高了推理速度. SoC通过整合多个计算单元,在硬件资源的协调调度方面发挥重要作用. 例如,Imp[22 ] 方案针对骁龙8Gen3/888芯片,通过分辨率适配与硬件特性匹配协同方案,提高了推理效率并优化了能效. ...
2
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
... Comparison of typical end-to-end efficient inference frameworks on edge
Tab.3 框架 描述 MLC-LLM[89 ] 基于多层次计算的语言模型,采用优化的硬件加速方案,致力于在多种平台上实现高效且高性能的推理 MNN-M[90 ] MNN框架中的一个模块,专注于模型优化和加速,特别是在移动端和嵌入式设备上,具有较低的资源占用和较快的推理速度 vLLM[91 ] 专为大语言模型优化的推理框架,旨在提高推理效率并降低内存使用,同时支持多种硬件平台的加速 llama.cpp[92 ] 基于LLaMA模型的C++实现,优化了推理性能,适用于低资源环境中的高效推理,并支持多种硬件加速技术
通过这些集成了多种优化技术的系统级框架,边缘侧推理系统能够在保证高效能的同时,兼顾低资源占用,推动边缘侧多模态大语言模型的应用. ...
2
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
... Comparison of typical end-to-end efficient inference frameworks on edge
Tab.3 框架 描述 MLC-LLM[89 ] 基于多层次计算的语言模型,采用优化的硬件加速方案,致力于在多种平台上实现高效且高性能的推理 MNN-M[90 ] MNN框架中的一个模块,专注于模型优化和加速,特别是在移动端和嵌入式设备上,具有较低的资源占用和较快的推理速度 vLLM[91 ] 专为大语言模型优化的推理框架,旨在提高推理效率并降低内存使用,同时支持多种硬件平台的加速 llama.cpp[92 ] 基于LLaMA模型的C++实现,优化了推理性能,适用于低资源环境中的高效推理,并支持多种硬件加速技术
通过这些集成了多种优化技术的系统级框架,边缘侧推理系统能够在保证高效能的同时,兼顾低资源占用,推动边缘侧多模态大语言模型的应用. ...
2
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
... Comparison of typical end-to-end efficient inference frameworks on edge
Tab.3 框架 描述 MLC-LLM[89 ] 基于多层次计算的语言模型,采用优化的硬件加速方案,致力于在多种平台上实现高效且高性能的推理 MNN-M[90 ] MNN框架中的一个模块,专注于模型优化和加速,特别是在移动端和嵌入式设备上,具有较低的资源占用和较快的推理速度 vLLM[91 ] 专为大语言模型优化的推理框架,旨在提高推理效率并降低内存使用,同时支持多种硬件平台的加速 llama.cpp[92 ] 基于LLaMA模型的C++实现,优化了推理性能,适用于低资源环境中的高效推理,并支持多种硬件加速技术
通过这些集成了多种优化技术的系统级框架,边缘侧推理系统能够在保证高效能的同时,兼顾低资源占用,推动边缘侧多模态大语言模型的应用. ...
3
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
... [92 ]结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
... Comparison of typical end-to-end efficient inference frameworks on edge
Tab.3 框架 描述 MLC-LLM[89 ] 基于多层次计算的语言模型,采用优化的硬件加速方案,致力于在多种平台上实现高效且高性能的推理 MNN-M[90 ] MNN框架中的一个模块,专注于模型优化和加速,特别是在移动端和嵌入式设备上,具有较低的资源占用和较快的推理速度 vLLM[91 ] 专为大语言模型优化的推理框架,旨在提高推理效率并降低内存使用,同时支持多种硬件平台的加速 llama.cpp[92 ] 基于LLaMA模型的C++实现,优化了推理性能,适用于低资源环境中的高效推理,并支持多种硬件加速技术
通过这些集成了多种优化技术的系统级框架,边缘侧推理系统能够在保证高效能的同时,兼顾低资源占用,推动边缘侧多模态大语言模型的应用. ...
1
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
1
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
1
... 在此基础上,框架集成成为了进一步提升性能的关键,如表3 所示. 集成部署框架通过结合硬件适配、编译优化、内存带宽管理等多个技术,提供了一套完整的端到端推理解决方案. 这些框架与单纯依赖硬件或量化策略不同,能够在统一的平台上实现多方面优化,显著降低了系统的复杂性,并提高了推理效率. llama.cpp[92 ] 框架通过深度优化LLaMA系列模型[7 , 40 , 67 ] ,支持CPU/GPU加速,并实现了在Jetson Orin平台[93 ] 上65 ms的端到端延迟. MiniCPM-V 4.5[50 ] 结合自动参数搜索和硬件优化,进一步提升了解码吞吐量. MLC-LLM[89 ] 基于TVM框架[94 ] ,支持多模态模型在移动端和嵌入式设备上的跨平台编译和优化,提升了移植性和灵活性. MNN-M框架[90 ] 则通过硬件感知编译优化,在特定硬件平台上实现了高效推理,适应不同芯片架构. vLLM框架[91 ] 虽然原本并非专为边缘侧设计,但在与量化技术和llama.cpp[92 ] 结合后,在边缘侧设备上展现了较好的推理速度和精度,适配了如Gradio[95 ] 的工具,方便本地网页用户界面的快速部署. ...
A hybrid swarm intelligence approach for optimizing Multimodal Large Language Models deployment in edge-cloud-based Federated Learning environments
2
2025
... 云边协同架构能够将边缘侧设备的轻量化任务与云端的重计算任务进行分工合作,提升推理效率,云边协同架构示意图如图3 所示. 例如,Rjoub等[96 ] 提出的云边协同框架通过优化边缘侧设备选择和模型更新路径,减少了30%的通信成本,显著提高了全局模型的精度. 此外,Hu等[97 ] 采用云边协同架构,在边缘侧设备上部署轻量化的CogVLM2[98 ] 进行实时感知任务,云端利用ChatGPT-4o[99 ] 实现复杂推理,平衡了推理效率与功能精度. ...
... 1)自动驾驶车辆与无人机方面. DriveGPT4[107 ] 作为可解释端到端自动驾驶系统,可接收前视单目RGB相机的视频序列及文本查询之类的多模态输入,自主完成驾驶环境感知、行为推理与下一步速度和转向角之类控制信号的预测. DriveGPT4-V2[108 ] 在此基础上进一步扩展至闭环端到端自动驾驶场景,通过多视图视觉Tokenizer、带特权信息的专家LLM在线模仿学习及专用决策头优化,实现了更全面的环境感知、更稳健的误差修正与更高效的数值决策预测. PlanAgent [109 ] 进一步实现了多模态推理与运动规划的闭环整合. 该模型能够自主处理多模态环境及车辆状态数据,独立完成从感知、推理到安全性验证的全流程任务,无需人类介入即可输出车辆控制所需的运动规划方案. 而Rjoub等[96 ] 提出的混合群智能框架,可自主优化多模态大模型在边缘与云环境中的部署,支撑无人车之类的自主系统独立处理多模态数据并完成导航、避障之类的任务,在保证高准确率的同时降低通信成本. ...
A cloud-edge collaborative architecture for multimodal LLMS-based advanced driver assistance systems in IOT networks
1
2025
... 云边协同架构能够将边缘侧设备的轻量化任务与云端的重计算任务进行分工合作,提升推理效率,云边协同架构示意图如图3 所示. 例如,Rjoub等[96 ] 提出的云边协同框架通过优化边缘侧设备选择和模型更新路径,减少了30%的通信成本,显著提高了全局模型的精度. 此外,Hu等[97 ] 采用云边协同架构,在边缘侧设备上部署轻量化的CogVLM2[98 ] 进行实时感知任务,云端利用ChatGPT-4o[99 ] 实现复杂推理,平衡了推理效率与功能精度. ...
1
... 云边协同架构能够将边缘侧设备的轻量化任务与云端的重计算任务进行分工合作,提升推理效率,云边协同架构示意图如图3 所示. 例如,Rjoub等[96 ] 提出的云边协同框架通过优化边缘侧设备选择和模型更新路径,减少了30%的通信成本,显著提高了全局模型的精度. 此外,Hu等[97 ] 采用云边协同架构,在边缘侧设备上部署轻量化的CogVLM2[98 ] 进行实时感知任务,云端利用ChatGPT-4o[99 ] 实现复杂推理,平衡了推理效率与功能精度. ...
1
... 云边协同架构能够将边缘侧设备的轻量化任务与云端的重计算任务进行分工合作,提升推理效率,云边协同架构示意图如图3 所示. 例如,Rjoub等[96 ] 提出的云边协同框架通过优化边缘侧设备选择和模型更新路径,减少了30%的通信成本,显著提高了全局模型的精度. 此外,Hu等[97 ] 采用云边协同架构,在边缘侧设备上部署轻量化的CogVLM2[98 ] 进行实时感知任务,云端利用ChatGPT-4o[99 ] 实现复杂推理,平衡了推理效率与功能精度. ...
1
... 例如,LLaVA-Phi[16 ] 作为仅2.7×109 参数量的轻量化多模态助手,在边缘计算环境中能高效处理视觉文本协同任务,其核心功能须完全依赖用户指令触发(如解释解答图像中的数学问题),仅通过低延迟的多模态数据处理为用户提供任务支持. 目前部署在边缘侧的智能问答系统一般依赖这种范式. 类似地,T3-Agent[100 ] 也须用户主动提供查询内容及相关多模态数据(如图像和PDF),系统通过视觉分析、代码执行和多模态工具链辅助用户完成信息提取与多步骤推理. 其核心仍然是工具化辅助,属于典型的低自治水平任务. ...
1
... 例如,MMAC-Copilot[101 ] 多模态协作框架接收用户模糊目标指令(如在音乐平台播放指定音乐),其可自主拆解任务并分工协作,同时实时解析手机图形用户界面(graphical user interface,GUI)状态获取环境反馈,动态修正操作策略,实现对复杂数字环境的稳定操控. AppAgent[102 ] 仅需用户给出模糊目标指令(如编辑图片、设置闹钟),即可自主拆解任务,实时感知GUI界面并动态调整点击、滑动、文本输入等操作. AppAgent v2[103 ] 在此基础上进一步强化了协作能力,通过结构化知识库与检索增强生成(retrieval-augmented generation,RAG)技术提升环境适配性,支持跨应用任务执行与视觉特征精准识别,敏感操作时还会触发安全校验并需用户手动介入. 相似地,EcoAgent[104 ] 运行于Android移动设备并通过GUI交互实现操作,仅需用户提供初始指令(如添加联系人、地图标记)即可自主完成任务分解、执行、结果验证及失败重规划,独立覆盖20个APP的116项复杂程序任务. 而Mobile-Agent[105 ] 结合光学字符识别(OCR)技术与Grounding DINO[106 ] 工具(一种视觉语言模型工具),进一步增强了任务执行的稳健性,不仅给出指令即可自主拆解任务步骤、动态捕捉环境GUI变化,还能动态调整点击、输入、应用软件切换等操作,遇到无效或错误操作时还能自我反思修正,无需用户细化步骤. ...
1
... 例如,MMAC-Copilot[101 ] 多模态协作框架接收用户模糊目标指令(如在音乐平台播放指定音乐),其可自主拆解任务并分工协作,同时实时解析手机图形用户界面(graphical user interface,GUI)状态获取环境反馈,动态修正操作策略,实现对复杂数字环境的稳定操控. AppAgent[102 ] 仅需用户给出模糊目标指令(如编辑图片、设置闹钟),即可自主拆解任务,实时感知GUI界面并动态调整点击、滑动、文本输入等操作. AppAgent v2[103 ] 在此基础上进一步强化了协作能力,通过结构化知识库与检索增强生成(retrieval-augmented generation,RAG)技术提升环境适配性,支持跨应用任务执行与视觉特征精准识别,敏感操作时还会触发安全校验并需用户手动介入. 相似地,EcoAgent[104 ] 运行于Android移动设备并通过GUI交互实现操作,仅需用户提供初始指令(如添加联系人、地图标记)即可自主完成任务分解、执行、结果验证及失败重规划,独立覆盖20个APP的116项复杂程序任务. 而Mobile-Agent[105 ] 结合光学字符识别(OCR)技术与Grounding DINO[106 ] 工具(一种视觉语言模型工具),进一步增强了任务执行的稳健性,不仅给出指令即可自主拆解任务步骤、动态捕捉环境GUI变化,还能动态调整点击、输入、应用软件切换等操作,遇到无效或错误操作时还能自我反思修正,无需用户细化步骤. ...
1
... 例如,MMAC-Copilot[101 ] 多模态协作框架接收用户模糊目标指令(如在音乐平台播放指定音乐),其可自主拆解任务并分工协作,同时实时解析手机图形用户界面(graphical user interface,GUI)状态获取环境反馈,动态修正操作策略,实现对复杂数字环境的稳定操控. AppAgent[102 ] 仅需用户给出模糊目标指令(如编辑图片、设置闹钟),即可自主拆解任务,实时感知GUI界面并动态调整点击、滑动、文本输入等操作. AppAgent v2[103 ] 在此基础上进一步强化了协作能力,通过结构化知识库与检索增强生成(retrieval-augmented generation,RAG)技术提升环境适配性,支持跨应用任务执行与视觉特征精准识别,敏感操作时还会触发安全校验并需用户手动介入. 相似地,EcoAgent[104 ] 运行于Android移动设备并通过GUI交互实现操作,仅需用户提供初始指令(如添加联系人、地图标记)即可自主完成任务分解、执行、结果验证及失败重规划,独立覆盖20个APP的116项复杂程序任务. 而Mobile-Agent[105 ] 结合光学字符识别(OCR)技术与Grounding DINO[106 ] 工具(一种视觉语言模型工具),进一步增强了任务执行的稳健性,不仅给出指令即可自主拆解任务步骤、动态捕捉环境GUI变化,还能动态调整点击、输入、应用软件切换等操作,遇到无效或错误操作时还能自我反思修正,无需用户细化步骤. ...
1
... 例如,MMAC-Copilot[101 ] 多模态协作框架接收用户模糊目标指令(如在音乐平台播放指定音乐),其可自主拆解任务并分工协作,同时实时解析手机图形用户界面(graphical user interface,GUI)状态获取环境反馈,动态修正操作策略,实现对复杂数字环境的稳定操控. AppAgent[102 ] 仅需用户给出模糊目标指令(如编辑图片、设置闹钟),即可自主拆解任务,实时感知GUI界面并动态调整点击、滑动、文本输入等操作. AppAgent v2[103 ] 在此基础上进一步强化了协作能力,通过结构化知识库与检索增强生成(retrieval-augmented generation,RAG)技术提升环境适配性,支持跨应用任务执行与视觉特征精准识别,敏感操作时还会触发安全校验并需用户手动介入. 相似地,EcoAgent[104 ] 运行于Android移动设备并通过GUI交互实现操作,仅需用户提供初始指令(如添加联系人、地图标记)即可自主完成任务分解、执行、结果验证及失败重规划,独立覆盖20个APP的116项复杂程序任务. 而Mobile-Agent[105 ] 结合光学字符识别(OCR)技术与Grounding DINO[106 ] 工具(一种视觉语言模型工具),进一步增强了任务执行的稳健性,不仅给出指令即可自主拆解任务步骤、动态捕捉环境GUI变化,还能动态调整点击、输入、应用软件切换等操作,遇到无效或错误操作时还能自我反思修正,无需用户细化步骤. ...
1
... 例如,MMAC-Copilot[101 ] 多模态协作框架接收用户模糊目标指令(如在音乐平台播放指定音乐),其可自主拆解任务并分工协作,同时实时解析手机图形用户界面(graphical user interface,GUI)状态获取环境反馈,动态修正操作策略,实现对复杂数字环境的稳定操控. AppAgent[102 ] 仅需用户给出模糊目标指令(如编辑图片、设置闹钟),即可自主拆解任务,实时感知GUI界面并动态调整点击、滑动、文本输入等操作. AppAgent v2[103 ] 在此基础上进一步强化了协作能力,通过结构化知识库与检索增强生成(retrieval-augmented generation,RAG)技术提升环境适配性,支持跨应用任务执行与视觉特征精准识别,敏感操作时还会触发安全校验并需用户手动介入. 相似地,EcoAgent[104 ] 运行于Android移动设备并通过GUI交互实现操作,仅需用户提供初始指令(如添加联系人、地图标记)即可自主完成任务分解、执行、结果验证及失败重规划,独立覆盖20个APP的116项复杂程序任务. 而Mobile-Agent[105 ] 结合光学字符识别(OCR)技术与Grounding DINO[106 ] 工具(一种视觉语言模型工具),进一步增强了任务执行的稳健性,不仅给出指令即可自主拆解任务步骤、动态捕捉环境GUI变化,还能动态调整点击、输入、应用软件切换等操作,遇到无效或错误操作时还能自我反思修正,无需用户细化步骤. ...
1
... 例如,MMAC-Copilot[101 ] 多模态协作框架接收用户模糊目标指令(如在音乐平台播放指定音乐),其可自主拆解任务并分工协作,同时实时解析手机图形用户界面(graphical user interface,GUI)状态获取环境反馈,动态修正操作策略,实现对复杂数字环境的稳定操控. AppAgent[102 ] 仅需用户给出模糊目标指令(如编辑图片、设置闹钟),即可自主拆解任务,实时感知GUI界面并动态调整点击、滑动、文本输入等操作. AppAgent v2[103 ] 在此基础上进一步强化了协作能力,通过结构化知识库与检索增强生成(retrieval-augmented generation,RAG)技术提升环境适配性,支持跨应用任务执行与视觉特征精准识别,敏感操作时还会触发安全校验并需用户手动介入. 相似地,EcoAgent[104 ] 运行于Android移动设备并通过GUI交互实现操作,仅需用户提供初始指令(如添加联系人、地图标记)即可自主完成任务分解、执行、结果验证及失败重规划,独立覆盖20个APP的116项复杂程序任务. 而Mobile-Agent[105 ] 结合光学字符识别(OCR)技术与Grounding DINO[106 ] 工具(一种视觉语言模型工具),进一步增强了任务执行的稳健性,不仅给出指令即可自主拆解任务步骤、动态捕捉环境GUI变化,还能动态调整点击、输入、应用软件切换等操作,遇到无效或错误操作时还能自我反思修正,无需用户细化步骤. ...
Drivegpt4: interpretable end-to-end autonomous driving via large language model
1
2024
... 1)自动驾驶车辆与无人机方面. DriveGPT4[107 ] 作为可解释端到端自动驾驶系统,可接收前视单目RGB相机的视频序列及文本查询之类的多模态输入,自主完成驾驶环境感知、行为推理与下一步速度和转向角之类控制信号的预测. DriveGPT4-V2[108 ] 在此基础上进一步扩展至闭环端到端自动驾驶场景,通过多视图视觉Tokenizer、带特权信息的专家LLM在线模仿学习及专用决策头优化,实现了更全面的环境感知、更稳健的误差修正与更高效的数值决策预测. PlanAgent [109 ] 进一步实现了多模态推理与运动规划的闭环整合. 该模型能够自主处理多模态环境及车辆状态数据,独立完成从感知、推理到安全性验证的全流程任务,无需人类介入即可输出车辆控制所需的运动规划方案. 而Rjoub等[96 ] 提出的混合群智能框架,可自主优化多模态大模型在边缘与云环境中的部署,支撑无人车之类的自主系统独立处理多模态数据并完成导航、避障之类的任务,在保证高准确率的同时降低通信成本. ...
1
... 1)自动驾驶车辆与无人机方面. DriveGPT4[107 ] 作为可解释端到端自动驾驶系统,可接收前视单目RGB相机的视频序列及文本查询之类的多模态输入,自主完成驾驶环境感知、行为推理与下一步速度和转向角之类控制信号的预测. DriveGPT4-V2[108 ] 在此基础上进一步扩展至闭环端到端自动驾驶场景,通过多视图视觉Tokenizer、带特权信息的专家LLM在线模仿学习及专用决策头优化,实现了更全面的环境感知、更稳健的误差修正与更高效的数值决策预测. PlanAgent [109 ] 进一步实现了多模态推理与运动规划的闭环整合. 该模型能够自主处理多模态环境及车辆状态数据,独立完成从感知、推理到安全性验证的全流程任务,无需人类介入即可输出车辆控制所需的运动规划方案. 而Rjoub等[96 ] 提出的混合群智能框架,可自主优化多模态大模型在边缘与云环境中的部署,支撑无人车之类的自主系统独立处理多模态数据并完成导航、避障之类的任务,在保证高准确率的同时降低通信成本. ...
1
... 1)自动驾驶车辆与无人机方面. DriveGPT4[107 ] 作为可解释端到端自动驾驶系统,可接收前视单目RGB相机的视频序列及文本查询之类的多模态输入,自主完成驾驶环境感知、行为推理与下一步速度和转向角之类控制信号的预测. DriveGPT4-V2[108 ] 在此基础上进一步扩展至闭环端到端自动驾驶场景,通过多视图视觉Tokenizer、带特权信息的专家LLM在线模仿学习及专用决策头优化,实现了更全面的环境感知、更稳健的误差修正与更高效的数值决策预测. PlanAgent [109 ] 进一步实现了多模态推理与运动规划的闭环整合. 该模型能够自主处理多模态环境及车辆状态数据,独立完成从感知、推理到安全性验证的全流程任务,无需人类介入即可输出车辆控制所需的运动规划方案. 而Rjoub等[96 ] 提出的混合群智能框架,可自主优化多模态大模型在边缘与云环境中的部署,支撑无人车之类的自主系统独立处理多模态数据并完成导航、避障之类的任务,在保证高准确率的同时降低通信成本. ...
1
... 2)具身智能方面. QUART-Online[110 ] 控制的四足机器人能基于初始自然语言指令和实时RGB视觉感知,端到端自主生成与底层控制器50 Hz同步的连续动作轨迹,无需用户实时干预,即可独立完成导航、避障、爬行等任务,还能适配未见过的视觉元素和语言指令场景. RoboMM[111 ] 模型驱动的机械臂能基于初始自然语言指令和多视角视觉数据、相机参数,自主生成6D位姿变化与夹爪动作的连续轨迹,无需用户实时干预即可独立完成抓取、堆叠之类的复杂操作任务,且具有泛化性能. SC-MLLM模型[112 ] ,可依托机器人载体自主完成物体拉动、开关控制之类的操作,还能自动检测操作失败原因并针对性纠正,通过持续学习适配不同场景. VeBrain框架[113 ] 可赋能腿式机器人、机械臂、无人巡检车等具身设备,自主完成目标寻找、避障运输、开关抽屉、物品抓取投放等任务,还能自动适配视角变化、处理执行中的突发情况. OWMM-Agent[114 ] 可让移动操作机器人接收自然语言指令后,自主感知环境、规划动作并完成拾取、放置之类的开放世界任务,展现出强泛化能力. ...
1
... 2)具身智能方面. QUART-Online[110 ] 控制的四足机器人能基于初始自然语言指令和实时RGB视觉感知,端到端自主生成与底层控制器50 Hz同步的连续动作轨迹,无需用户实时干预,即可独立完成导航、避障、爬行等任务,还能适配未见过的视觉元素和语言指令场景. RoboMM[111 ] 模型驱动的机械臂能基于初始自然语言指令和多视角视觉数据、相机参数,自主生成6D位姿变化与夹爪动作的连续轨迹,无需用户实时干预即可独立完成抓取、堆叠之类的复杂操作任务,且具有泛化性能. SC-MLLM模型[112 ] ,可依托机器人载体自主完成物体拉动、开关控制之类的操作,还能自动检测操作失败原因并针对性纠正,通过持续学习适配不同场景. VeBrain框架[113 ] 可赋能腿式机器人、机械臂、无人巡检车等具身设备,自主完成目标寻找、避障运输、开关抽屉、物品抓取投放等任务,还能自动适配视角变化、处理执行中的突发情况. OWMM-Agent[114 ] 可让移动操作机器人接收自然语言指令后,自主感知环境、规划动作并完成拾取、放置之类的开放世界任务,展现出强泛化能力. ...
1
... 2)具身智能方面. QUART-Online[110 ] 控制的四足机器人能基于初始自然语言指令和实时RGB视觉感知,端到端自主生成与底层控制器50 Hz同步的连续动作轨迹,无需用户实时干预,即可独立完成导航、避障、爬行等任务,还能适配未见过的视觉元素和语言指令场景. RoboMM[111 ] 模型驱动的机械臂能基于初始自然语言指令和多视角视觉数据、相机参数,自主生成6D位姿变化与夹爪动作的连续轨迹,无需用户实时干预即可独立完成抓取、堆叠之类的复杂操作任务,且具有泛化性能. SC-MLLM模型[112 ] ,可依托机器人载体自主完成物体拉动、开关控制之类的操作,还能自动检测操作失败原因并针对性纠正,通过持续学习适配不同场景. VeBrain框架[113 ] 可赋能腿式机器人、机械臂、无人巡检车等具身设备,自主完成目标寻找、避障运输、开关抽屉、物品抓取投放等任务,还能自动适配视角变化、处理执行中的突发情况. OWMM-Agent[114 ] 可让移动操作机器人接收自然语言指令后,自主感知环境、规划动作并完成拾取、放置之类的开放世界任务,展现出强泛化能力. ...
1
... 2)具身智能方面. QUART-Online[110 ] 控制的四足机器人能基于初始自然语言指令和实时RGB视觉感知,端到端自主生成与底层控制器50 Hz同步的连续动作轨迹,无需用户实时干预,即可独立完成导航、避障、爬行等任务,还能适配未见过的视觉元素和语言指令场景. RoboMM[111 ] 模型驱动的机械臂能基于初始自然语言指令和多视角视觉数据、相机参数,自主生成6D位姿变化与夹爪动作的连续轨迹,无需用户实时干预即可独立完成抓取、堆叠之类的复杂操作任务,且具有泛化性能. SC-MLLM模型[112 ] ,可依托机器人载体自主完成物体拉动、开关控制之类的操作,还能自动检测操作失败原因并针对性纠正,通过持续学习适配不同场景. VeBrain框架[113 ] 可赋能腿式机器人、机械臂、无人巡检车等具身设备,自主完成目标寻找、避障运输、开关抽屉、物品抓取投放等任务,还能自动适配视角变化、处理执行中的突发情况. OWMM-Agent[114 ] 可让移动操作机器人接收自然语言指令后,自主感知环境、规划动作并完成拾取、放置之类的开放世界任务,展现出强泛化能力. ...
1
... 2)具身智能方面. QUART-Online[110 ] 控制的四足机器人能基于初始自然语言指令和实时RGB视觉感知,端到端自主生成与底层控制器50 Hz同步的连续动作轨迹,无需用户实时干预,即可独立完成导航、避障、爬行等任务,还能适配未见过的视觉元素和语言指令场景. RoboMM[111 ] 模型驱动的机械臂能基于初始自然语言指令和多视角视觉数据、相机参数,自主生成6D位姿变化与夹爪动作的连续轨迹,无需用户实时干预即可独立完成抓取、堆叠之类的复杂操作任务,且具有泛化性能. SC-MLLM模型[112 ] ,可依托机器人载体自主完成物体拉动、开关控制之类的操作,还能自动检测操作失败原因并针对性纠正,通过持续学习适配不同场景. VeBrain框架[113 ] 可赋能腿式机器人、机械臂、无人巡检车等具身设备,自主完成目标寻找、避障运输、开关抽屉、物品抓取投放等任务,还能自动适配视角变化、处理执行中的突发情况. OWMM-Agent[114 ] 可让移动操作机器人接收自然语言指令后,自主感知环境、规划动作并完成拾取、放置之类的开放世界任务,展现出强泛化能力. ...
1
... 此外,Magma[115 ] 作为支持跨越数字与物理双环境的多模态基础模型,仅需用户给出模糊目标指令,基于统一多模态推理能力,即可在数字界面与真实物理场景中自主完成任务规划、环境感知与动作调整. ...


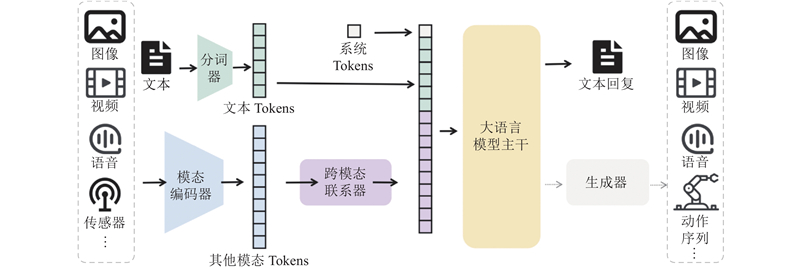
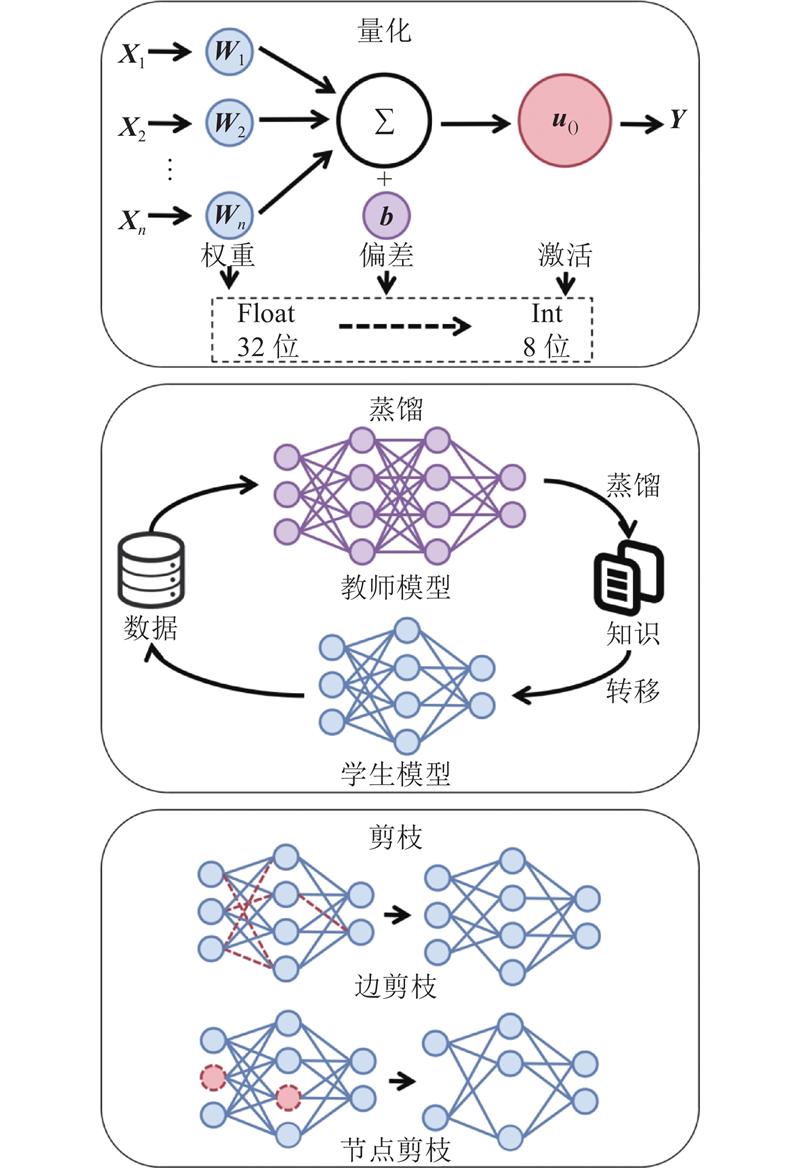
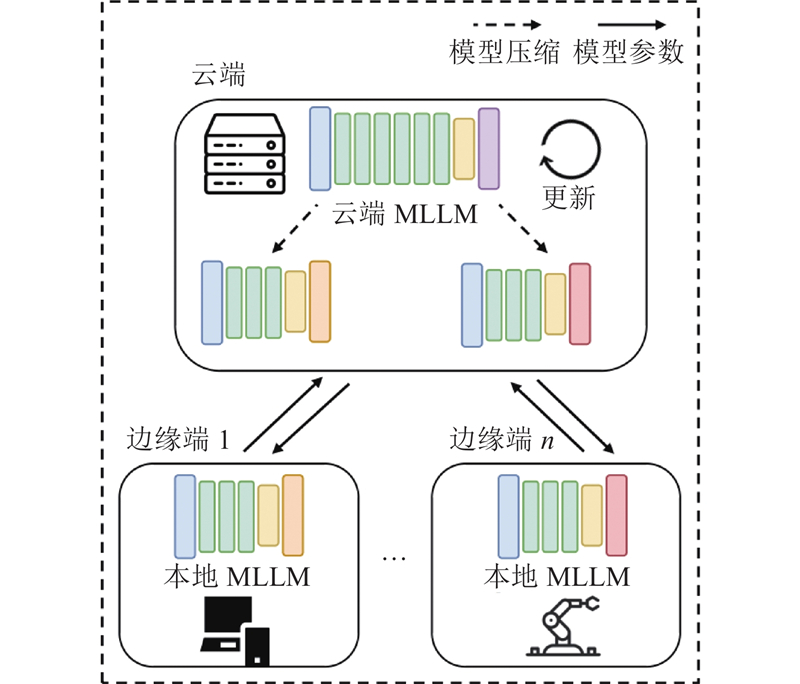

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}