环境感知作为自动驾驶系统的关键组成部分,其准确性与可靠性直接关乎行驶安全。在众多感知任务中,车道线检测占据关键地位,它不仅为车辆提供道路几何结构信息,也为定位、路径规划与决策控制提供重要依据。高精度的车道线检测有助于车辆准确理解道路拓扑、预测可行驶区域,从而在复杂的交通环境中实现安全、可靠的自主决策。当前车道线检测的主流方法可以归纳为传统图像处理方法与基于深度学习的方法两大类[1 ] 。
传统图像处理方法通常先利用边缘检测、滤波等方法分割车道线区域,然后结合霍夫变换、卡尔曼滤波等进行车道线拟合[2 -3 ] 。这类算法高度依赖手工特征与先验规则,并需借助复杂的后处理技术来剔除误检、聚类车道线结构,因而其复杂度高、人工干预较多,在复杂环境下的鲁棒性不高。
随着卷积神经网络的发展,车道线检测研究逐步转向基于深度学习的方法。该类方法依托大规模标注数据,借助神经网络实现车道线特征的自动化学习与高效表达,其检测的鲁棒性与准确性得到了显著提升[4 ] 。当前主流的深度学习方法包括基于分割、基于锚、基于关键点和参数式方法等4类[5 ] 。
基于分割的方法通过逐像素分类实现检测,即为每个像素分配一个二进制标签,以区分车道线与非车道线区域。相关研究对空间关系建模、双分支融合、注意力机制和多尺度上下文建模等方面进行了改进,有效缓解了车道线模糊、不连续和多实例区分困难等状况[6 -8 ] 。该类方法虽然在检测精度上表现出较大优势,但其计算开销较大,并且在细长目标的连续性、多车道实例区分、复杂场景下的鲁棒性与部署效率等方面存在不足。
基于锚的方法利用线形锚对采样点和预定义的锚点间的偏移量进行回归,然后通过非极大值抑制选择具有高置信度的车道线。相关研究通过借助轴注意力及行列锚融合机制提升了方法的特征提取与定位能力。该类方法先验强、速度快,但表示离散,对锚设计敏感,在复杂场景下易产生定位误差和细节丢失[9 -10 ] 。
部分研究将车道线检测转化为关键点检测与关联问题。通常通过关键点预测、特征嵌入以及空间感知增强等提升对车道线形状与实例关系的刻画能力,从而在复杂形态车道线的局部几何建模方面表现出一定优势。该类方法普遍依赖后续的点集关联与聚类处理,因此后处理阶段的效率相对较低[11 -12 ] 。
相较之下,参数式方法具有后处理轻量、检测帧率高和整体曲线约束强等优势,能够在一定程度上减少阴影、裂缝及反光区域导致的碎片化误检。该类方法将车道线建模为可参数化曲线,通过网络直接回归曲线参数,从而实现车道几何的低维表示。部分研究在DETR(DEtection TRansformer,检测变换器)框架[13 ] 的基础上进行了拓展,摒弃了锚点生成与非极大值抑制等手工组件,实现了端到端的目标检测。其代表性方法包括PolyLaneNetDet[14 ] 、LSTR[15 ] 和LPCNet[16 ] 等。其中:PolyLaneNetDet通过多项式回归实现了效率与曲线表达能力的平衡;LSTR基于DETR构建端到端的车道线检测框架;LPCNet在LSTR的基础上对模型的参数量进行了压缩,同时保持了较好的检测精度。然而,该类方法对急弯等复杂路况的拟合能力有限,且在证据信息较弱时易受先验信息误导而产生误检。因此,在复杂环境以及弱证据情况下该类方法的检测精度有待进一步提升。
针对上述问题,本文提出了一种面向车道线视觉检测的DETR式端到端框架,旨在降低复杂场景下的误检率。该方法用GNN-Transformer架构直接回归曲线参数:利用GNN(graph neural network,图神经网络)模块对特征点间的关系进行建模,以增强结构约束,并通过Transformer编解码器捕获全局上下文;引入可学习位置编码强化纵向位置信息。在损失函数设计方面,基于六参数车道线形状模型构建车道曲线几何损失,以增强预测车道线与真实车道线之间的整体形状一致性,并设置纵向感知范围的边界损失来刻画细长目标的上下边界。整体训练过程基于匈牙利匹配来实现预测与标注的最优对应。最后,在TuSimple数据集[17 ] 、CULane数据集[18 ] 以及CARLA模拟器[19 ] 验证所提方法的有效性,并通过消融实验分析重要模块对车道线检测结果的影响。
1 车道线检测方法
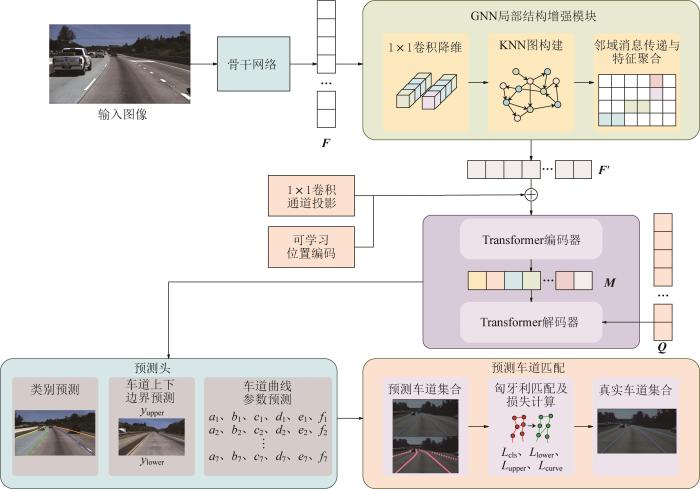
本节将介绍对DETR车道线检测模型的改进方案。首先,保留DETR的整体检测框架,包括骨干网络的选择与Transformer编解码器的通道配置,以保证其基础检测性能。为提升车道线检测精度,在Transformer架构前引入GNN模块,构建k-近邻(k-nearest neighbor,KNN)图来增强特征点之间的局部结构约束,使编码阶段获得几何一致且拓扑更明确的特征输入[20 ] 。在此基础上,引入可学习位置编码,以增强车道线几何连续性表征能力。模型的输出端不再预测边界框,而是直接回归车道线六维曲线的参数及其上下边界。最后,在损失函数中引入基于有效长度的加权策略,使较长车道线对梯度贡献更大,从而强化长距离车道线的学习效果。车道线检测流程如图1 所示。图中:F F ' M Q
图1
图1
基于GNN-Transformer 模型的车道线检测流程
Fig.1
Lane line detection process based on GNN-Transformer model
1.1 骨干网络
骨干网络采用ResNet风格[13 ] 的卷积特征提取架构。输入的三通道图像首先经过7×7卷积进行初始下采样,随后依次通过冻结的批量归一化、非线性激活与最大池化操作,获得浅层特征表征,之后依次经过4个残差阶段实现特征逐级抽象。各阶段的残差块形式、堆叠深度、通道规模及下采样步长均可通过配置设置,从而在网络容量与特征分辨率之间实现可控平衡。当空间尺度或通道数发生变化时,采用由1×1卷积与批量归一化构成的下采样分支进行维度匹配。最终,输出高层特征图,并通过1×1卷积投影将通道映射为后续注意力与图推理模块所需的统一特征维度。
1.2 GNN 模块
在基于Transformer模型的车道线检测方法中,自注意力机制虽能有效建模全局关系,但将输入特征展平为序列后,局部空间的邻域结构信息易被弱化。车道线具有细长、连续以及几何约束强的特点,其完整形态高度依赖局部点之间的连贯性与拓扑关系。若直接将卷积神经网络提取的特征输入Transformer模型虽可建立长程关联,但对局部几何一致性的显式约束不足,可能导致在弯道、大曲率或遮挡场景下的连续性下降。为此,本文在Transformer之前引入GNN模块,通过基于特征相似度的KNN图构建与消息传递,实现对局部一致性与结构先验的增强,从而为后续全局建模提供更稳定、结构更清晰的输入表示[21 ] 。
GNN模块以骨干网络输出的高层特征图为输入。设输入特征为:
F ∈ R B × C × H f × W f (1)
式中:B C H f 、W f 分别为特征图的高与宽。
对于单一样本,本研究将特征图中每一个空间位置对应的特征向量视为一个图节点,因此节点总数N v = H f × W f X
X ∈ R N v × C (2)
第i x i ∈ R C G = V , ε V ε
在KNN图构建过程中,本研究并不直接采用原始高维节点特征来生成其邻接关系,而是先通过1×1卷积对节点特征矩阵X Z
Z = C o n v 1 × 1 X , Z ∈ R N v × D (3)
随后,对Z i k N k ( i ) j ∈ N k ( i ) i j
A i j = 1 , j ∈ N k i 0 , 其他 (4)
该建图方式能够根据当前样本的特征分布自适应地生成局部连接关系,使空间上可能相距较远但在特征空间较接近的节点建立联系,从而增强车道线局部结构的一致性。
完成KNN图构建后,对每个节点执行邻域消息传递。首先,根据邻接索引收集节点i
z ¯ i = 1 k ∑ j ∈ N k ( i ) z j (5)
式中:z ¯ i i z j j
随后,分别对中心节点特征与邻域聚合特征进行线性映射,并将两者相加得到中间更新表示。与特征拼接、多层感知机融合的实现方式不同,本研究采用中心节点线性变换和邻域特征线性变换的方式完成融合,其表达式为:
o i = W s z i + W n z ¯ i (6)
式中:o i i W s W n
该设计在保持简洁的同时,能够同时保留节点自身的判别信息和邻域上下文补充信息。
为了进一步提高训练稳定性并缓解图特征传播中的过平滑状况,本研究在节点更新阶段引入层归一化、非线性激活、随机失活与残差连接机制,即先对中间更新表示o i z ' i
F ' ∈ R B × C × H f × W f (7)
因此,GNN模块并不改变特征图的空间分辨率与通道数,而是在保持张量形状不变的前提下进行局部结构增强。
总体而言,本研究所引入的GNN模块通过“投影降维—动态KNN图构建—邻域均值聚合—线性融合—层归一化与残差更新”过程,实现对局部相似特征的有效传播与增强,可在一定程度上弥补展平操作带来的局部结构信息弱化的不足,使特征在局部层面具有更强的一致性与稳定性。经GNN处理后的高层特征随后输入Transformer编解码器,以进一步建模全局依赖关系并完成实例级预测。
1.3 Transformer 编解码器
经过GNN模块对局部结构进行增强之后,进一步采用Transformer编解码器对全局上下文依赖关系进行建模。GNN-Transformer模型整体采用串联映射结构,即:骨干网络首先提取高层特征,随后由GNN向局部相似邻域进行消息传递和特征更新,最后将增强后的特征送入Transformer编解码器进行全局关系建模与实例级解码。因此,GNN与Transformer之间并非为并联关系,而是一种局部增强—全局建模的逐级串联模式。
由于Transformer的多头注意力模块要求统一的隐藏维度,本研究通过一个1×1卷积对GNN输出特征进行通道投影,将其映射到注意力通道维度C a
F ˜ = C o n v 1 × 1 F ' , F ˜ ∈ R B × C a × H f × W f (8)
GNN输出与Transformer输入之间不存在额外的分支拼接操作,在其连接过程中二维特征图的组织形式保持不变,仅通过通道投影完成从卷积/图特征空间到注意力特征空间的映射。
在Transformer内部,输入特征F ˜ 式(9)所示。
S = F l a t t e n F ˜ , S ∈ R B × C a × H f × W f (9)
式中:S H f × W f
位置编码也采用相同的方式展平并重排,以保持与输入序列维度一致。可学习查询向量在批量维度上进行复制,作为解码器的查询位置向量,与其同形状的全零张量则作为解码器的初始输入。由此,Transformer的输入准备过程可概括为:二维特征图在输入编码器前被序列化为长度为H f × W f
在编码阶段,Transformer编码器对输入序列执行多层自注意力建模。每层编码器均由多头自注意力与前馈网络构成,通过残差连接和层归一化逐层更新特征表示。自注意力机制能够在全图范围内建立任意两个空间位置之间的依赖关系,从而弥补仅依赖局部聚合操作在长程上下文建模方面的不足。编码完成后,所得记忆特征既保留了局部结构增强后的几何信息,又融入了全局范围内的上下文关系。随后,编码器输出的记忆特征被传递至解码器。
在解码阶段,采用查询驱动的并行解码策略。解码器以预设数量的可学习查询向量为基础,通过查询自注意力机制建模各候选车道实例之间的关系,并利用编码-解码交叉注意力从编码器输出的全局记忆特征中检索与当前查询相关的结构信息。各层解码器的输出逐层堆叠,用于支持辅助监督并提高深层训练的稳定性。最终,解码器输出被整理为多层查询特征,供后续类别预测和曲线参数回归分支使用。
总体而言,在结构上采用GNN负责局部结构增强、Transformer负责全局依赖建模与实例级解码的串联式设计。前者通过动态KNN图构建与邻域消息传递强化车道线局部几何的连续性;后者通过编码-解码注意力机制,对跨区域长距离依赖进行建模,并完成实例级预测。该设计首先在局部层面增强车道线结构的稳定性,然后在全局层面完成上下文整合与目标解码,从而提高复杂场景下车道线检测的完整性与鲁棒性。
1.4 车道线拟合模型
车道线形状模型定义为多项式形式,如式(10)所示。
x y = a y - b 2 + c y - b + d + e y - f (10)
式中:y x ( y ) a、b、c、d、e、f 为网络预测的6个参数,用于控制曲率、平移及视角畸变等几何属性。
采用形如a/ (y-b )2 和c/ (y-b )的多项式形式,能够更有效地拟合透视效应显著、曲率较大的车道线。
在三维空间中,高速公路上的2条车道线为平行直线。而在成像平面上,近距离的车道线几乎平行且间距较大;远距离的车道线则迅速汇聚于消失点,间距逐渐减小,呈现显著的透视形变。根据理想针孔模型进行推理,可得到如式(11)所示的关系。
x ( y ) ≈ u 0 + c y - b (11)
式中:u 0
像平面上的直线以及曲线天然呈现1/(y -b )形式的分布规律。在车道线拟合过程中,将该结构显式地嵌入函数表达式,仅需微调预测参数,即可有效刻画远距离强烈收缩与弯曲的透视效果。
1.5 损失函数
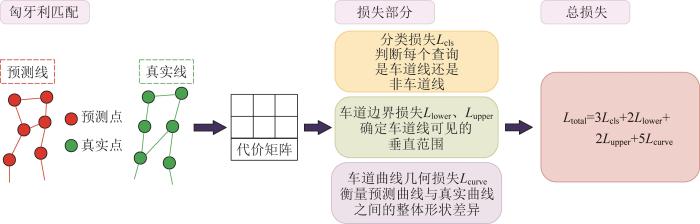
本节系统地介绍模型在训练阶段所采用的损失函数框架。该框架首先通过匈牙利匹配对预测车道线与真实车道线建立一一对应关系,随后在匹配后的查询中分别计算分类损失、车道边界损失与车道曲线几何损失,并通过加权求和得到总损失。该设计充分利用了车道线的几何结构特性,使网络能够直接学习完整车道线的全局形态。损失函数框架如图2 所示。
图2
图2
损失函数框架
Fig.2
Loss function framework
匈牙利匹配用于匹配每条预测车道线与对应的真实车道线;在此对应关系上,分别计算分类损失L cls ,车道下边界损失L lower 、车道上边界损失L upper 以及车道曲线几何损失L curve ,并按预设权重加权求和,得到最终损失L total 。损失函数如式(12)所示。
L t o t a l = 3 L c l s + 2 L l o w e r + 2 L u p p e r + 5 L c u r v e (12)
1.5.1 匈牙利匹配
对于每张输入图像,模型固定输出Q 个车道线查询。每个查询y ^ q N GT 条车道标注y g
C q g = λ c l s L c l s q , g + λ l o w e r L l o w e r q , g + λ u p p e r L u p p e r q , g + λ c u r v e L c u r v e q , g (13)
式中:(q , g )表示第q g λ
随后,通过匈牙利算法得到最优匹配集合,将预测查询与真实车道进行一一对应。该匹配策略确保无论真实车道标注的数量如何变化,模型均可稳定完成对齐和监督。
1.5.2 分类损失
匈牙利匹配完成后,每个查询将获得一个目标类别,未匹配的查询则被视为背景类别。分类损失采用标准交叉熵形式:
L c l s = 1 B Q ∑ n = 1 B ∑ q = 1 Q C E p ^ n , q , c n , q (14)
式中:C E p ^ n , q n q c n , q
通过分类损失的计算,可确保模型能够正确判断当前查询是否对应实际车道,并识别其类型。
1.5.3 车道上下边界损失
真实车道具有可见区域,模型预测的车道包含可见的下边界y l o w e r y u p p e r ( q , g ) ∈ Ω
L l o w e r = 1 | Ω | ∑ q , g ∈ Ω α g | y ^ q , l o w e r - y g , l o w e r | (15)
L u p p e r = 1 | Ω | ∑ q , g ∈ Ω α g | y ^ q , u p p e r - y g , u p p e r | (16)
式中:权重α g
车道下边界损失用于衡量模型预测车道起始位置与真实位置的偏差,上边界损失则反映模型在远距离区域的预测稳定性。
1.5.4 车道曲线几何损失
为了精确建模车道线的全局几何结构,模型输出六维参数化曲线θ a 0 , a 1 , a 2 , a 3 , a 4 , a 5 y l l = 1 L
x ^ q y l = a 0 y l - a 1 2 + a 2 y l - a 1 + a 3 + a 4 y l - a 5 (17)
真实车道在每个采样点均对应横坐标x g , l
L c u r v e = 1 | Ω | ∑ q , g ∈ Ω ∑ l ∈ V g β g , l | x ^ q y l - x g , l | (18)
式中:V g β g , l
该损失在几何层面直接衡量预测曲线与真实曲线之间的整体形状差异,在整个损失函数体系中占据核心地位。
1.5.5 总损失函数
总损失函数由上述三部分组成,并根据经验设置不同的权重,以平衡分类准确性与几何精度。总损失函数为:
L t o t a l = λ c l s L c l s + λ l o w e r L l o w e r + λ u p p e r L u p p e r + λ c u r v e L c u r v e (19)
式中权重部分设置为:(λ cls , λ lower, λ upper , λ curve )=(3, 2, 2, 5),反映了车道曲线几何损失在整体损失中的核心地位。
2 实验研究
2.1 车道线检测实验
2.2.1 实验平台
TuSimple数据集为主要面向高速公路场景的车道线检测基准数据集。数据采集于美国高速路段,通常包含2~4条车道,涵盖不同交通密度与不同时段,整体以良好天气和相对简单的场景为主。原始数据约包含7 000段短视频(每段20帧),通常仅对每段中的单帧(常见为最后一帧)提供车道线标注,用于训练与测试。数据集共包含6 408张标注图像(分辨率为(1 280×720)像素),其中3 626张用于训练,2 782张用于测试。
CULane数据集是一个面向城市道路场景的大规模车道线检测数据集。数据采集于北京,由安装于6辆不同车上的摄像头摄取,涵盖多种交通状况和时段。共收集了超过55 h的视频,提取了133 235张图像(分辨率为(1 640×590)像素),划分为训练集(88 880张)、验证集(9 675张)和测试集(34 680张)。
CARLA模拟器是一个基于Unreal Engine、面向自动驾驶研究的开源驾驶模拟器。采用客户端-服务器架构,并提供Python API用于场景生成、车辆控制与传感器数据采集,适用于感知、决策、控制及强化学习等自动驾驶技术研究的可重复实验。
2.2.2 参数设置
在TuSimple数据集的各组实验均采用相同的超参数设置。输入分辨率为(360×640)像素,训练阶段采用随机缩放、裁剪、旋转、颜色变化与水平翻转等数据增强策略;初始学习率设为1 × 10 - 4
CULane数据集主要用于模型在复杂道路场景下泛化性能的验证,其图像与车道线标注在数据读取阶段统一转换至模型输入尺度,并采用与TuSimple实验一致的预处理流程和超参数。
在CARLA模拟器的实验采用固定时间步长运行。由车辆前向安装的RGB相机采集道路图像,采集的图像输入已训练好的模型进行在线推理,以验证模型的实时检测能力与工程应用能力。
2.2.3 实验结果
a) 在TuSimple数据集的实验结果
本文方法在TuSimple数据集的车道线检测结果如图3 所示。结果表明,本文方法在车道线形状推理与遮挡补全方面表现较好。主要原因在于:1)引入KNN图增强了特征点之间的局部关联,提升了几何连续性;2)注意力机制能够捕获非局部上下文信息,对缺失区域进行有效补充,从而更利于细长结构的整体建模。
图3
图3
本文方法在TuSimple 数据集的车道线检测结果
Fig.3
Lane line detection results of proposed method on TuSimple dataset
为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] 。对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较。
各方法在TuSimple测试集的性能对比如表1 所示。由表可知,与现有方法相比,本文方法在保持较高准确率的前提下具有较快的运行速度,并取得最低的假阳性率。在实际应用中,较高的误检率易引发误报警及不必要的控制响应,进而带来更高的安全风险。综合来看,本文方法兼具实时性与可靠性,具备较大的移动端部署潜力。
b) 在CULane数据集的实验结果
为了验证本文方法对复杂场景的适配能力,在CULane数据集进行车道线检测,结果如图4 所示。结果表明,在暗光和遮挡场景下本文方法仍具有良好的推理与检测性能。将本文方法与UFSA[27 ] 、PINet[11 ] 、STLNet[28 ] 、E-CLRNet[29 ] 、LaneATT[30 ] 等5种方法在CULane数据集进行测试,其性能对比如表2 所示。表中:“F1@50”指在交并比阈值为0.5条件下的F1值(其计算公式为:2×准确率×召回率/(准确率+召回率)),用于衡量车道线检测结果与真实标注之间的匹配程度,数值越高表示检测性能越好;“总分数”表示模型在CULane测试集的总体F1@50计算结果;“正常、拥挤、炫光、阴影、无线、箭头、曲线、夜间”表示不同道路场景类别;“十字路口假阳性数”表示十字路口场景下的假阳性数,数值越低表示误检车道线数量越少。由表可知,本文方法在较为复杂的场景下保持了一定的准确率,拥有较强的复杂场景适配能力。
图4
图4
本文方法在CULane 数据集的车道线检测结果
Fig.4
Lane line detection results of proposed method on CULane dataset
c) 在CARLA模拟器的实验结果
为了验证本文方法的工程应用能力,在CARLA仿真环境中采用固定时间步长(默认为20 Hz)进行在线验证,连续运行2 000个tick(时钟节拍)完成一次测试。车辆前向安装RGB相机(分辨率为(640×360)像素,视场角为90°),相机俯仰角固定为-6°,以满足道路平面观测需求;车辆运动由Traffic Manager接管并启用自动驾驶,速度差设为-10%,跟车距离设为2.0 m,每20个tick保存一次推理结果,用于离线分析。实验测得推理帧率为109.3帧/s。本文方法在CARLA模拟器的检测结果如图5 所示。实验结果表明本文方法具有较好的工程应用能力。
图5
图5
本文方法在CARLA 模拟器的车道线检测结果
Fig.5
Lane line detection results of proposed method on CARLA simulator
2.2 消融实验
2.2.1 KNN图对几何连续性的影响
为了定量评估KNN图在整体框架中的作用,设计如下消融实验:基线模型不包含KNN模块;KNN-GNN模型仅在骨干网络输出特征与Transformer编码器之间引入基于特征相似度的KNN动态邻接,并执行一次消息传递;除上述差异外,其余训练策略和网络超参数均保持一致。实验结果如表3 所示。由表可知,引入KNN后假阳性率和假阴性率均有所降低,模型鲁棒性得到增强。其原因为:KNN图在特征空间构建跨区域关联,使同一车道线的响应在进入注意力机制前已完成信息传播与一致性增强,从而缓解因遮挡和磨损导致的局部断裂,并降低假阴性率;同时,基于相似度构建的邻域聚合对随机纹理和高光反射等非结构噪声具有抑制作用,有助于降低假阳性率并提升输出的几何连续性。综上,该消融实验验证了KNN图在提升车道线检测连贯性与稳定性方面的关键作用。
2.2.2 注意力机制对车道线特征建模的影响
为了考察注意力机制对车道线特征建模的影响,对不同层数编码器的检测性能进行了对比,结果如表4 所示。由表可知,当编码器层数降至1时,假阳性率显著上升。当编码器层数为1和2时,相应的可视化结果如图6 所示。结果显示,注意力减弱导致上下文信息捕获能力下降,预测车道线出现局部缺失。然而,增加编码器层数并不必然带来性能提升。当编码器层数增加至3时,假阳性率同样明显上升,反而降低了模型的泛化能力。这表明当模型容量接近数据表达能力上限时,注意力机制可能被过度使用并诱发过拟合现象。
图6
图6
不同编码器层数时车道线检测结果
Fig.6
Lane line detection results under different numbers of encoder layers
3 实车部署
在部署阶段,通过模型迁移技术完成从仿真到实车的部署验证,确保经过深度学习训练的模型能够在实际场景中高效运行。实验基于乐知行(重庆)科技有限公司生产的RTRC4pro智能小车以及智慧沙盘平台开展,如图7 所示。该平台以Jetson Orin NX为主控制器,配备16 GB内存并具备1014 次/s的算力,能够满足实时图像处理与深度学习推理需求。道路图像通过智能小车搭载的Intel RealSense D35i相机实时采集,本文模型对采集到的图像进行推理并输出车道线预测结果。智慧沙盘的尺寸为4 m×
图7
图7
RTRC4pro 智能小车和智慧沙盘平台
Fig.7
RTRC4pro intelligent vehicle and smart sandbox platform
将本文所提出的车道线检测模型部署于RTRC4pro智能小车,并在沙盘道路环境中进行检测。部署流程严格遵循训练—导出—推理的工程化标准范式:在推理阶段仅需加载导出的模型权重,复用统一的预处理与推理接口以保证训练与推理的一致性(包括输入尺寸处理、归一化与张量构建等),即可在实时相机图像流输入下实现稳定的车道线在线预测。该流程未对原网络结构进行任何侵入式修改,且对外部依赖与环境配置要求较低,具有良好的可迁移与可复现特性。
车道线检测结果图8 所示。实验结果表明,本文方法在实车与沙盘场景中展现了良好的工程可部署性:预测车道线较好地复现了道路几何结构与车道边界形态,帧输出具备一定的稳定性与连续性。然而,实验中也发现预测结果未与真实车道线完全重合,局部区域存在横向偏移及边界贴合不足等现象,这在透视压缩显著的远距离区域或曲率变化较快的路段更为突出。
图8
图8
RTRC4pro 智能小车车道线检测结果
Fig.8
Lane line detection results of RTRC4pro intelligent vehicle
未来工作将围绕拟合一致性、对齐精度以及鲁棒性等3条主线开展,包括采取几何一致性约束与边界细化策略、引入时序平滑与一致性约束以抑制抖动与漂移,并通过数据增强或域适配提升模型在不同沙盘纹理与光照条件下的泛化能力。
4 结论与展望
1)误检率是车道线检测的重要评价指标之一。本研究通过GNN模块中KNN图的构建,对基于DETR目标识别的车道线检测框架进行了改进。所构建的GNN-Transformer网络通过局部结构建模与全局上下文融合,有效降低了误检率。
2)为验证KNN图以及注意力机制对车道线检测结果的影响,开展了消融实验。实验结果表明:引入KNN图后,误检率降低了16%;采用二层编码器相较于一层编码器,误检率降低了19%。与部分模型相比,本文方法的误检率降低了35%以上,同时帧率达到了110 帧/s。本文方法在保持实时性的同时有效降低了误检率。
3)在实车部署方面,本文提出的车道线检测模型展现了良好的可迁移性与可复现性,输出帧具备一定的稳定性与连续性。然而,在当前条件下,还不能实现预测曲线与真实车道线完全重合,且透视环境对模型检测结果的影响较为显著。未来工作将重点提升模型面对多样化沙盘纹理及在不同部署设备中的泛化能力。
本文链接: http://www.zjujournals.com/gcsjxb/CN/10.3785/j.issn.1006-754X.2026.06.114
参考文献
View Option
[8]
GU X HUANG Q W DU C N Lane detection based on ECBAM_ASPP model
[J]. Sensors , 2024 , 24 (24 ): 8098 .
[本文引用: 1]
[9]
罗鑫 , 黄影平 , 梁振明 轴注意力引导的锚点分类车道线检测
[J]. 光电工程 , 2023 , 50 (7 ): 230079 .
[本文引用: 1]
LUO X HUANG Y P LIANG Z M Axial attention-guided anchor classification lane detection
[J]. Opto-Electronic Engineering , 2023 , 50 (7 ): 230079 .
[本文引用: 1]
[11]
KO Y , LEE Y AZAM S et al Key points estimation and point instance segmentation approach for lane detection
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (7 ): 8949 -8958 .
[本文引用: 3]
[12]
王耀琦 , 卢亚琦 , 王小鹏 结合增强空间感知的远距离车道线检测方法
[J]. 华南理工大学学报(自然科学版) , 2026 , 54 (2 ): 62 -76 .
[本文引用: 1]
WANG Y Q LU Y Q WANG X P A long-range lane detection method with enhanced spatial perception
[J]. Journal of South China University of Technology (Natural Science Edition) , 2026 , 54 (2 ): 62 -76 .
[本文引用: 1]
[1]
DORJ B HOSSAIN S LEE D J Highly curved lane detection algorithms based on Kalman filter
[J]. Applied Sciences , 2020 , 10 (7 ): 2372 .
[本文引用: 1]
[2]
罗胜 , 赵丽 , 王慕抽 基于道路特征信息的车道结构化解析
[J]. 北京航空航天大学学报 , 2020 , 46 (9 ): 1643 -1649 .
[本文引用: 1]
[13]
ZHANG G J LUO Z P HUANG J X et al Semantic-aligned matching for enhanced DETR convergence and multi-scale feature fusion
[J]. International Journal of Computer Vision , 2024 , 132 (8 ): 2825 -2844 .
[本文引用: 2]
[14]
KIM J CHOI H PolyLaneDet: lane detection with free-form polyline
[J]. International Journal of Fuzzy Logic and Intelligent Systems , 2024 , 24 (2 ): 105 -113 .
[本文引用: 1]
[2]
LUO S ZHAO L WANG M C Lane semantic analysis based on road feature information
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2020 , 46 (9 ): 1643 -1649 .
[本文引用: 1]
[3]
MEGALINGAM R K PRADEEP N C REGHU A et al Lane detection using Hough transform and Kalman filter
[C]//2024 International Conference on E-mobility, Power Control and Smart Systems , Thiruvananthapuram, India, Apr. 18 -20 , 2024 .
[本文引用: 1]
[4]
ZHAO J Y WU Y Y DENG R et al A survey of autonomous driving from a deep learning perspective
[J]. ACM Computing Surveys , 2025 , 57 (10 ): 1 -60 .
[本文引用: 1]
[5]
王淑琴 , 李兆发 , 景悦洲 , 等 基于计算机视觉的车道线检测方法研究进展
[J]. 天津师范大学学报(自然科学版) , 2025 , 45 (6 ): 1 -8 , 12 .
[本文引用: 1]
WANG S Q LI Z F JING Y Z et al Research progress of lane line detection methods based on computer vision
[J]. Journal of Tianjin Normal University (Natural Science Edition) , 2025 , 45 (6 ): 1 -8 , 12 .
[本文引用: 1]
[6]
[本文引用: 1]
SHI J P ZHANG X Multi-lane line detection and tracking network based on spatial semantics segmentation
[J]. Optics and Precision Engineering , 2023 , 31 (9 ): 1357 -1365 .
DOI:10.37188/ope.20233109.1357
[本文引用: 1]
[7]
YU F X WU Y F SUO Y N et al Shallow detail and semantic segmentation combined bilateral network model for lane detection
[J]. IEEE Transactions on Intelligent Transportation Systems , 2023 , 24 (8 ): 8617 -8627 .
[15]
LIU R J YUAN Z J LIU T et al End-to-end lane shape prediction with transformers
[C]//2021 IEEE Winter Conference on Applications of Computer Vision , Waikoloa, HI, USA, Jan. 5 -9 , 2021 .
[本文引用: 1]
[16]
LU F F SUN G X YU H Q et al LPCNet: End-to-end lane detection with PnP compression and condition DETR
[J]. Displays , 2025 , 87 : 102902 .
[本文引用: 1]
[17]
Tusimple benchmark
[EB/OL]. [2026-02-25 ]. .
URL
[本文引用: 1]
[18]
PAN X G SHI J P LUO P et al Spatial as deep: spatial CNN for traffic scene understanding
[J/OL]// Proceedings of the AAAI Conference on Artificial Intelligence, 2018 . (2018-04-27 ) [2026-02-25 ]. .
URL
[本文引用: 1]
[19]
DOSOVITSKIY A ROS G , CODEVILLA F et al CARLA: an open urban driving simulator
[C]//Conference on Robot Learning , Mountain View, California, Nov. 13 -5 , 2017 .
[本文引用: 1]
[20]
LIU X Y CHEN J WEN Q A survey on graph classification and link prediction based on GNN
[EB/OL]. 2023 : arXiv : 2307 .00865 . [2026-02-25 ].
URL
[本文引用: 1]
[21]
GUO J Y HAN K TANG Y H et al Vision GNN: an image is worth graph of nodes
[C]//Advances in Neural Information Processing Systems 35 . New York : Curran Associates , 2022 : 8291 -8303 .
[本文引用: 1]
[22]
LI X LI J HU X L et al Line-CNN: end-to-end traffic line detection with line proposal unit
[J]. IEEE Transactions on Intelligent Transportation Systems , 2020 , 21 (1 ): 248 -258 .
[本文引用: 1]
[23]
ZHANG L JIANG F L YANG J et al A real-time lane detection network using two-directional separation attention
[J]. Computer-Aided Civil and Infrastructure Engineering , 2024 , 39 (1 ): 86 -101 .
[本文引用: 1]
[24]
NAN Z X XU W Y CHEN S et al Lane detection with vanishing box based dynamic anchor generation mechanism
[J]. Neurocomputing , 2026 , 665 : 132110 .
[本文引用: 1]
[25]
CHAI Y X WANG S X ZHANG Z J A fast and accurate lane detection method based on row anchor and transformer structure
[J]. Sensors , 2024 , 24 (7 ): 2116 .
[本文引用: 1]
[26]
ZHANG B Y ZHANG L C WANG T B et al Omni-refinement attention network for lane detection
[J]. Sensors , 2025 , 25 (19 ): 6150 .
[本文引用: 1]
[27]
QIN Z Q WANG H Y LI X Ultra fast structure-aware deep lane detection
[C]//Computer Vision-ECCV 2020 . Cham : Springer , 2020 : 276 -291 .
[本文引用: 1]
[28]
DU Y F ZHANG R Y SHI P C et al ST-LaneNet: lane line detection method based on swin transformer and LaneNet
[J]. Chinese Journal of Mechanical Engineering , 2024 , 37 (1 ): 14 .
[本文引用: 1]
[29]
DAI W L LI Z Y XU X F et al Enhanced cross layer refinement network for robust lane detection across diverse lighting and road conditions
[J]. Engineering Applications of Artificial Intelligence , 2025 , 139 : 109473 .
[本文引用: 1]
[30]
CAO X LIU W WANG Z Adaptive ROI optimization pyramid network: lane detection for FSD under data uncertainty
[J]. Engineering Letters , 2025 , 33 (2 ): 282 .
[本文引用: 1]
Lane detection based on ECBAM_ASPP model
1
2024
... 基于分割的方法通过逐像素分类实现检测,即为每个像素分配一个二进制标签,以区分车道线与非车道线区域.相关研究对空间关系建模、双分支融合、注意力机制和多尺度上下文建模等方面进行了改进,有效缓解了车道线模糊、不连续和多实例区分困难等状况[6 -8 ] .该类方法虽然在检测精度上表现出较大优势,但其计算开销较大,并且在细长目标的连续性、多车道实例区分、复杂场景下的鲁棒性与部署效率等方面存在不足. ...
轴注意力引导的锚点分类车道线检测
1
2023
... 基于锚的方法利用线形锚对采样点和预定义的锚点间的偏移量进行回归,然后通过非极大值抑制选择具有高置信度的车道线.相关研究通过借助轴注意力及行列锚融合机制提升了方法的特征提取与定位能力.该类方法先验强、速度快,但表示离散,对锚设计敏感,在复杂场景下易产生定位误差和细节丢失[9 -10 ] . ...
轴注意力引导的锚点分类车道线检测
1
2023
... 基于锚的方法利用线形锚对采样点和预定义的锚点间的偏移量进行回归,然后通过非极大值抑制选择具有高置信度的车道线.相关研究通过借助轴注意力及行列锚融合机制提升了方法的特征提取与定位能力.该类方法先验强、速度快,但表示离散,对锚设计敏感,在复杂场景下易产生定位误差和细节丢失[9 -10 ] . ...
基于行列锚点融合的车道线检测方法研究
1
2024
... 基于锚的方法利用线形锚对采样点和预定义的锚点间的偏移量进行回归,然后通过非极大值抑制选择具有高置信度的车道线.相关研究通过借助轴注意力及行列锚融合机制提升了方法的特征提取与定位能力.该类方法先验强、速度快,但表示离散,对锚设计敏感,在复杂场景下易产生定位误差和细节丢失[9 -10 ] . ...
基于行列锚点融合的车道线检测方法研究
1
2024
... 基于锚的方法利用线形锚对采样点和预定义的锚点间的偏移量进行回归,然后通过非极大值抑制选择具有高置信度的车道线.相关研究通过借助轴注意力及行列锚融合机制提升了方法的特征提取与定位能力.该类方法先验强、速度快,但表示离散,对锚设计敏感,在复杂场景下易产生定位误差和细节丢失[9 -10 ] . ...
Key points estimation and point instance segmentation approach for lane detection
3
2022
... 部分研究将车道线检测转化为关键点检测与关联问题.通常通过关键点预测、特征嵌入以及空间感知增强等提升对车道线形状与实例关系的刻画能力,从而在复杂形态车道线的局部几何建模方面表现出一定优势.该类方法普遍依赖后续的点集关联与聚类处理,因此后处理阶段的效率相对较低[11 -12 ] . ...
... 为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] .对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较. ...
... 为了验证本文方法对复杂场景的适配能力,在CULane数据集进行车道线检测,结果如图4 所示.结果表明,在暗光和遮挡场景下本文方法仍具有良好的推理与检测性能.将本文方法与UFSA[27 ] 、PINet[11 ] 、STLNet[28 ] 、E-CLRNet[29 ] 、LaneATT[30 ] 等5种方法在CULane数据集进行测试,其性能对比如表2 所示.表中:“F1@50”指在交并比阈值为0.5条件下的F1值(其计算公式为:2×准确率×召回率/(准确率+召回率)),用于衡量车道线检测结果与真实标注之间的匹配程度,数值越高表示检测性能越好;“总分数”表示模型在CULane测试集的总体F1@50计算结果;“正常、拥挤、炫光、阴影、无线、箭头、曲线、夜间”表示不同道路场景类别;“十字路口假阳性数”表示十字路口场景下的假阳性数,数值越低表示误检车道线数量越少.由表可知,本文方法在较为复杂的场景下保持了一定的准确率,拥有较强的复杂场景适配能力. ...
结合增强空间感知的远距离车道线检测方法
1
2026
... 部分研究将车道线检测转化为关键点检测与关联问题.通常通过关键点预测、特征嵌入以及空间感知增强等提升对车道线形状与实例关系的刻画能力,从而在复杂形态车道线的局部几何建模方面表现出一定优势.该类方法普遍依赖后续的点集关联与聚类处理,因此后处理阶段的效率相对较低[11 -12 ] . ...
结合增强空间感知的远距离车道线检测方法
1
2026
... 部分研究将车道线检测转化为关键点检测与关联问题.通常通过关键点预测、特征嵌入以及空间感知增强等提升对车道线形状与实例关系的刻画能力,从而在复杂形态车道线的局部几何建模方面表现出一定优势.该类方法普遍依赖后续的点集关联与聚类处理,因此后处理阶段的效率相对较低[11 -12 ] . ...
Highly curved lane detection algorithms based on Kalman filter
1
2020
... 环境感知作为自动驾驶系统的关键组成部分,其准确性与可靠性直接关乎行驶安全.在众多感知任务中,车道线检测占据关键地位,它不仅为车辆提供道路几何结构信息,也为定位、路径规划与决策控制提供重要依据.高精度的车道线检测有助于车辆准确理解道路拓扑、预测可行驶区域,从而在复杂的交通环境中实现安全、可靠的自主决策.当前车道线检测的主流方法可以归纳为传统图像处理方法与基于深度学习的方法两大类[1 ] . ...
基于道路特征信息的车道结构化解析
1
2020
... 传统图像处理方法通常先利用边缘检测、滤波等方法分割车道线区域,然后结合霍夫变换、卡尔曼滤波等进行车道线拟合[2 -3 ] .这类算法高度依赖手工特征与先验规则,并需借助复杂的后处理技术来剔除误检、聚类车道线结构,因而其复杂度高、人工干预较多,在复杂环境下的鲁棒性不高. ...
Semantic-aligned matching for enhanced DETR convergence and multi-scale feature fusion
2
2024
... 相较之下,参数式方法具有后处理轻量、检测帧率高和整体曲线约束强等优势,能够在一定程度上减少阴影、裂缝及反光区域导致的碎片化误检.该类方法将车道线建模为可参数化曲线,通过网络直接回归曲线参数,从而实现车道几何的低维表示.部分研究在DETR(DEtection TRansformer,检测变换器)框架[13 ] 的基础上进行了拓展,摒弃了锚点生成与非极大值抑制等手工组件,实现了端到端的目标检测.其代表性方法包括PolyLaneNetDet[14 ] 、LSTR[15 ] 和LPCNet[16 ] 等.其中:PolyLaneNetDet通过多项式回归实现了效率与曲线表达能力的平衡;LSTR基于DETR构建端到端的车道线检测框架;LPCNet在LSTR的基础上对模型的参数量进行了压缩,同时保持了较好的检测精度.然而,该类方法对急弯等复杂路况的拟合能力有限,且在证据信息较弱时易受先验信息误导而产生误检.因此,在复杂环境以及弱证据情况下该类方法的检测精度有待进一步提升. ...
... 骨干网络采用ResNet风格[13 ] 的卷积特征提取架构.输入的三通道图像首先经过7×7卷积进行初始下采样,随后依次通过冻结的批量归一化、非线性激活与最大池化操作,获得浅层特征表征,之后依次经过4个残差阶段实现特征逐级抽象.各阶段的残差块形式、堆叠深度、通道规模及下采样步长均可通过配置设置,从而在网络容量与特征分辨率之间实现可控平衡.当空间尺度或通道数发生变化时,采用由1×1卷积与批量归一化构成的下采样分支进行维度匹配.最终,输出高层特征图,并通过1×1卷积投影将通道映射为后续注意力与图推理模块所需的统一特征维度. ...
PolyLaneDet: lane detection with free-form polyline
1
2024
... 相较之下,参数式方法具有后处理轻量、检测帧率高和整体曲线约束强等优势,能够在一定程度上减少阴影、裂缝及反光区域导致的碎片化误检.该类方法将车道线建模为可参数化曲线,通过网络直接回归曲线参数,从而实现车道几何的低维表示.部分研究在DETR(DEtection TRansformer,检测变换器)框架[13 ] 的基础上进行了拓展,摒弃了锚点生成与非极大值抑制等手工组件,实现了端到端的目标检测.其代表性方法包括PolyLaneNetDet[14 ] 、LSTR[15 ] 和LPCNet[16 ] 等.其中:PolyLaneNetDet通过多项式回归实现了效率与曲线表达能力的平衡;LSTR基于DETR构建端到端的车道线检测框架;LPCNet在LSTR的基础上对模型的参数量进行了压缩,同时保持了较好的检测精度.然而,该类方法对急弯等复杂路况的拟合能力有限,且在证据信息较弱时易受先验信息误导而产生误检.因此,在复杂环境以及弱证据情况下该类方法的检测精度有待进一步提升. ...
基于道路特征信息的车道结构化解析
1
2020
... 传统图像处理方法通常先利用边缘检测、滤波等方法分割车道线区域,然后结合霍夫变换、卡尔曼滤波等进行车道线拟合[2 -3 ] .这类算法高度依赖手工特征与先验规则,并需借助复杂的后处理技术来剔除误检、聚类车道线结构,因而其复杂度高、人工干预较多,在复杂环境下的鲁棒性不高. ...
Lane detection using Hough transform and Kalman filter
1
20
... 传统图像处理方法通常先利用边缘检测、滤波等方法分割车道线区域,然后结合霍夫变换、卡尔曼滤波等进行车道线拟合[2 -3 ] .这类算法高度依赖手工特征与先验规则,并需借助复杂的后处理技术来剔除误检、聚类车道线结构,因而其复杂度高、人工干预较多,在复杂环境下的鲁棒性不高. ...
A survey of autonomous driving from a deep learning perspective
1
2025
... 随着卷积神经网络的发展,车道线检测研究逐步转向基于深度学习的方法.该类方法依托大规模标注数据,借助神经网络实现车道线特征的自动化学习与高效表达,其检测的鲁棒性与准确性得到了显著提升[4 ] .当前主流的深度学习方法包括基于分割、基于锚、基于关键点和参数式方法等4类[5 ] . ...
基于计算机视觉的车道线检测方法研究进展
1
2025
... 随着卷积神经网络的发展,车道线检测研究逐步转向基于深度学习的方法.该类方法依托大规模标注数据,借助神经网络实现车道线特征的自动化学习与高效表达,其检测的鲁棒性与准确性得到了显著提升[4 ] .当前主流的深度学习方法包括基于分割、基于锚、基于关键点和参数式方法等4类[5 ] . ...
基于计算机视觉的车道线检测方法研究进展
1
2025
... 随着卷积神经网络的发展,车道线检测研究逐步转向基于深度学习的方法.该类方法依托大规模标注数据,借助神经网络实现车道线特征的自动化学习与高效表达,其检测的鲁棒性与准确性得到了显著提升[4 ] .当前主流的深度学习方法包括基于分割、基于锚、基于关键点和参数式方法等4类[5 ] . ...
基于空间语义分割的多车道线检测跟踪网络
1
2023
... 基于分割的方法通过逐像素分类实现检测,即为每个像素分配一个二进制标签,以区分车道线与非车道线区域.相关研究对空间关系建模、双分支融合、注意力机制和多尺度上下文建模等方面进行了改进,有效缓解了车道线模糊、不连续和多实例区分困难等状况[6 -8 ] .该类方法虽然在检测精度上表现出较大优势,但其计算开销较大,并且在细长目标的连续性、多车道实例区分、复杂场景下的鲁棒性与部署效率等方面存在不足. ...
基于空间语义分割的多车道线检测跟踪网络
1
2023
... 基于分割的方法通过逐像素分类实现检测,即为每个像素分配一个二进制标签,以区分车道线与非车道线区域.相关研究对空间关系建模、双分支融合、注意力机制和多尺度上下文建模等方面进行了改进,有效缓解了车道线模糊、不连续和多实例区分困难等状况[6 -8 ] .该类方法虽然在检测精度上表现出较大优势,但其计算开销较大,并且在细长目标的连续性、多车道实例区分、复杂场景下的鲁棒性与部署效率等方面存在不足. ...
Shallow detail and semantic segmentation combined bilateral network model for lane detection
0
2023
End-to-end lane shape prediction with transformers
1
9
... 相较之下,参数式方法具有后处理轻量、检测帧率高和整体曲线约束强等优势,能够在一定程度上减少阴影、裂缝及反光区域导致的碎片化误检.该类方法将车道线建模为可参数化曲线,通过网络直接回归曲线参数,从而实现车道几何的低维表示.部分研究在DETR(DEtection TRansformer,检测变换器)框架[13 ] 的基础上进行了拓展,摒弃了锚点生成与非极大值抑制等手工组件,实现了端到端的目标检测.其代表性方法包括PolyLaneNetDet[14 ] 、LSTR[15 ] 和LPCNet[16 ] 等.其中:PolyLaneNetDet通过多项式回归实现了效率与曲线表达能力的平衡;LSTR基于DETR构建端到端的车道线检测框架;LPCNet在LSTR的基础上对模型的参数量进行了压缩,同时保持了较好的检测精度.然而,该类方法对急弯等复杂路况的拟合能力有限,且在证据信息较弱时易受先验信息误导而产生误检.因此,在复杂环境以及弱证据情况下该类方法的检测精度有待进一步提升. ...
LPCNet: End-to-end lane detection with PnP compression and condition DETR
1
2025
... 相较之下,参数式方法具有后处理轻量、检测帧率高和整体曲线约束强等优势,能够在一定程度上减少阴影、裂缝及反光区域导致的碎片化误检.该类方法将车道线建模为可参数化曲线,通过网络直接回归曲线参数,从而实现车道几何的低维表示.部分研究在DETR(DEtection TRansformer,检测变换器)框架[13 ] 的基础上进行了拓展,摒弃了锚点生成与非极大值抑制等手工组件,实现了端到端的目标检测.其代表性方法包括PolyLaneNetDet[14 ] 、LSTR[15 ] 和LPCNet[16 ] 等.其中:PolyLaneNetDet通过多项式回归实现了效率与曲线表达能力的平衡;LSTR基于DETR构建端到端的车道线检测框架;LPCNet在LSTR的基础上对模型的参数量进行了压缩,同时保持了较好的检测精度.然而,该类方法对急弯等复杂路况的拟合能力有限,且在证据信息较弱时易受先验信息误导而产生误检.因此,在复杂环境以及弱证据情况下该类方法的检测精度有待进一步提升. ...
Tusimple benchmark
1
... 针对上述问题,本文提出了一种面向车道线视觉检测的DETR式端到端框架,旨在降低复杂场景下的误检率.该方法用GNN-Transformer架构直接回归曲线参数:利用GNN(graph neural network,图神经网络)模块对特征点间的关系进行建模,以增强结构约束,并通过Transformer编解码器捕获全局上下文;引入可学习位置编码强化纵向位置信息.在损失函数设计方面,基于六参数车道线形状模型构建车道曲线几何损失,以增强预测车道线与真实车道线之间的整体形状一致性,并设置纵向感知范围的边界损失来刻画细长目标的上下边界.整体训练过程基于匈牙利匹配来实现预测与标注的最优对应.最后,在TuSimple数据集[17 ] 、CULane数据集[18 ] 以及CARLA模拟器[19 ] 验证所提方法的有效性,并通过消融实验分析重要模块对车道线检测结果的影响. ...
Spatial as deep: spatial CNN for traffic scene understanding
1
2018
... 针对上述问题,本文提出了一种面向车道线视觉检测的DETR式端到端框架,旨在降低复杂场景下的误检率.该方法用GNN-Transformer架构直接回归曲线参数:利用GNN(graph neural network,图神经网络)模块对特征点间的关系进行建模,以增强结构约束,并通过Transformer编解码器捕获全局上下文;引入可学习位置编码强化纵向位置信息.在损失函数设计方面,基于六参数车道线形状模型构建车道曲线几何损失,以增强预测车道线与真实车道线之间的整体形状一致性,并设置纵向感知范围的边界损失来刻画细长目标的上下边界.整体训练过程基于匈牙利匹配来实现预测与标注的最优对应.最后,在TuSimple数据集[17 ] 、CULane数据集[18 ] 以及CARLA模拟器[19 ] 验证所提方法的有效性,并通过消融实验分析重要模块对车道线检测结果的影响. ...
CARLA: an open urban driving simulator
1
5
... 针对上述问题,本文提出了一种面向车道线视觉检测的DETR式端到端框架,旨在降低复杂场景下的误检率.该方法用GNN-Transformer架构直接回归曲线参数:利用GNN(graph neural network,图神经网络)模块对特征点间的关系进行建模,以增强结构约束,并通过Transformer编解码器捕获全局上下文;引入可学习位置编码强化纵向位置信息.在损失函数设计方面,基于六参数车道线形状模型构建车道曲线几何损失,以增强预测车道线与真实车道线之间的整体形状一致性,并设置纵向感知范围的边界损失来刻画细长目标的上下边界.整体训练过程基于匈牙利匹配来实现预测与标注的最优对应.最后,在TuSimple数据集[17 ] 、CULane数据集[18 ] 以及CARLA模拟器[19 ] 验证所提方法的有效性,并通过消融实验分析重要模块对车道线检测结果的影响. ...
A survey on graph classification and link prediction based on GNN
1
2023
... 本节将介绍对DETR车道线检测模型的改进方案.首先,保留DETR的整体检测框架,包括骨干网络的选择与Transformer编解码器的通道配置,以保证其基础检测性能.为提升车道线检测精度,在Transformer架构前引入GNN模块,构建k-近邻(k-nearest neighbor,KNN)图来增强特征点之间的局部结构约束,使编码阶段获得几何一致且拓扑更明确的特征输入[20 ] .在此基础上,引入可学习位置编码,以增强车道线几何连续性表征能力.模型的输出端不再预测边界框,而是直接回归车道线六维曲线的参数及其上下边界.最后,在损失函数中引入基于有效长度的加权策略,使较长车道线对梯度贡献更大,从而强化长距离车道线的学习效果.车道线检测流程如图1 所示.图中:F F ' M Q
Vision GNN: an image is worth graph of nodes
1
2022
... 在基于Transformer模型的车道线检测方法中,自注意力机制虽能有效建模全局关系,但将输入特征展平为序列后,局部空间的邻域结构信息易被弱化.车道线具有细长、连续以及几何约束强的特点,其完整形态高度依赖局部点之间的连贯性与拓扑关系.若直接将卷积神经网络提取的特征输入Transformer模型虽可建立长程关联,但对局部几何一致性的显式约束不足,可能导致在弯道、大曲率或遮挡场景下的连续性下降.为此,本文在Transformer之前引入GNN模块,通过基于特征相似度的KNN图构建与消息传递,实现对局部一致性与结构先验的增强,从而为后续全局建模提供更稳定、结构更清晰的输入表示[21 ] . ...
Line-CNN: end-to-end traffic line detection with line proposal unit
1
2020
... 为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] .对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较. ...
A real-time lane detection network using two-directional separation attention
1
2024
... 为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] .对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较. ...
Lane detection with vanishing box based dynamic anchor generation mechanism
1
2026
... 为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] .对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较. ...
A fast and accurate lane detection method based on row anchor and transformer structure
1
2024
... 为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] .对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较. ...
Omni-refinement attention network for lane detection
1
2025
... 为了全面评估模型性能,进一步将它与其他几种代表性方法进行对比,包括PINet[11 ] 、Line-CNN[22 ] 、LNet[23 ] 、DAG[24 ] 、LD-RAT[25 ] 和ORANet[26 ] .对比实验遵循既有工作设置,均利用TuSimple训练集进行训练,并将帧率作为推理速度指标进行比较. ...
Ultra fast structure-aware deep lane detection
1
2020
... 为了验证本文方法对复杂场景的适配能力,在CULane数据集进行车道线检测,结果如图4 所示.结果表明,在暗光和遮挡场景下本文方法仍具有良好的推理与检测性能.将本文方法与UFSA[27 ] 、PINet[11 ] 、STLNet[28 ] 、E-CLRNet[29 ] 、LaneATT[30 ] 等5种方法在CULane数据集进行测试,其性能对比如表2 所示.表中:“F1@50”指在交并比阈值为0.5条件下的F1值(其计算公式为:2×准确率×召回率/(准确率+召回率)),用于衡量车道线检测结果与真实标注之间的匹配程度,数值越高表示检测性能越好;“总分数”表示模型在CULane测试集的总体F1@50计算结果;“正常、拥挤、炫光、阴影、无线、箭头、曲线、夜间”表示不同道路场景类别;“十字路口假阳性数”表示十字路口场景下的假阳性数,数值越低表示误检车道线数量越少.由表可知,本文方法在较为复杂的场景下保持了一定的准确率,拥有较强的复杂场景适配能力. ...
ST-LaneNet: lane line detection method based on swin transformer and LaneNet
1
2024
... 为了验证本文方法对复杂场景的适配能力,在CULane数据集进行车道线检测,结果如图4 所示.结果表明,在暗光和遮挡场景下本文方法仍具有良好的推理与检测性能.将本文方法与UFSA[27 ] 、PINet[11 ] 、STLNet[28 ] 、E-CLRNet[29 ] 、LaneATT[30 ] 等5种方法在CULane数据集进行测试,其性能对比如表2 所示.表中:“F1@50”指在交并比阈值为0.5条件下的F1值(其计算公式为:2×准确率×召回率/(准确率+召回率)),用于衡量车道线检测结果与真实标注之间的匹配程度,数值越高表示检测性能越好;“总分数”表示模型在CULane测试集的总体F1@50计算结果;“正常、拥挤、炫光、阴影、无线、箭头、曲线、夜间”表示不同道路场景类别;“十字路口假阳性数”表示十字路口场景下的假阳性数,数值越低表示误检车道线数量越少.由表可知,本文方法在较为复杂的场景下保持了一定的准确率,拥有较强的复杂场景适配能力. ...
Enhanced cross layer refinement network for robust lane detection across diverse lighting and road conditions
1
2025
... 为了验证本文方法对复杂场景的适配能力,在CULane数据集进行车道线检测,结果如图4 所示.结果表明,在暗光和遮挡场景下本文方法仍具有良好的推理与检测性能.将本文方法与UFSA[27 ] 、PINet[11 ] 、STLNet[28 ] 、E-CLRNet[29 ] 、LaneATT[30 ] 等5种方法在CULane数据集进行测试,其性能对比如表2 所示.表中:“F1@50”指在交并比阈值为0.5条件下的F1值(其计算公式为:2×准确率×召回率/(准确率+召回率)),用于衡量车道线检测结果与真实标注之间的匹配程度,数值越高表示检测性能越好;“总分数”表示模型在CULane测试集的总体F1@50计算结果;“正常、拥挤、炫光、阴影、无线、箭头、曲线、夜间”表示不同道路场景类别;“十字路口假阳性数”表示十字路口场景下的假阳性数,数值越低表示误检车道线数量越少.由表可知,本文方法在较为复杂的场景下保持了一定的准确率,拥有较强的复杂场景适配能力. ...
Adaptive ROI optimization pyramid network: lane detection for FSD under data uncertainty
1
2025
... 为了验证本文方法对复杂场景的适配能力,在CULane数据集进行车道线检测,结果如图4 所示.结果表明,在暗光和遮挡场景下本文方法仍具有良好的推理与检测性能.将本文方法与UFSA[27 ] 、PINet[11 ] 、STLNet[28 ] 、E-CLRNet[29 ] 、LaneATT[30 ] 等5种方法在CULane数据集进行测试,其性能对比如表2 所示.表中:“F1@50”指在交并比阈值为0.5条件下的F1值(其计算公式为:2×准确率×召回率/(准确率+召回率)),用于衡量车道线检测结果与真实标注之间的匹配程度,数值越高表示检测性能越好;“总分数”表示模型在CULane测试集的总体F1@50计算结果;“正常、拥挤、炫光、阴影、无线、箭头、曲线、夜间”表示不同道路场景类别;“十字路口假阳性数”表示十字路口场景下的假阳性数,数值越低表示误检车道线数量越少.由表可知,本文方法在较为复杂的场景下保持了一定的准确率,拥有较强的复杂场景适配能力. ...











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}