

船舶碰撞是威胁海上交通安全最突出的因素之一,往往是火灾、泄漏类型海事事故的直接原因. 2013—2023年以来,全球年均船舶碰撞事故约198起,发生频度在各类海事事故中居第二位[1]. 2009年以来,国际航标协会与国际海事组织联合推出E-航海计划[2],通过传感与通信技术的增强促进船-岸、船-船之间的协同工作,减少人为失误,提升应急响应能力. 航线交换(route exchange, RE)作为E-航海的核心功能之一,通过播发未来航行计划,为多船避碰提供了新思路[3]. 研究表明,80%以上的海事事故源于人为失误[4],尤其在多船会遇场景中,船舶难以准确判断彼此意图,导致碰撞风险加剧. RE机制通过提升航行意图的可知性,降低了误判带来的碰撞风险.
船舶避碰一直是海事研究领域的热点问题. 现有的船舶避碰方法可分为4类:1)几何关系分析,依据船舶相对位置与运动状态评估碰撞风险并制定策略. 吴建军等[5]结合最近会遇距离(distance closest point of approach, DCPA)与最近会遇时间(time closest point of approach, TCPA),提出基于钟形灰云模型的转向方法;Huang等[6]将速度障碍法(velocity obstacle, VO)应用于海上自主水面船舶(maritime autonomous surface ships, MASS),构建符合实际操控需求的避碰模型. 2)优化与启发式算法,利用群智能算法求解动态约束下的多目标问题. Wang等[7]融合人工势场法与船舶领域(ship domain, SD),在遵循《国际海上避碰规则》(international regulations for preventing collisions at sea, COLREGs)的基础上实现多船动态避碰;Ning等[8]基于遗传算法考虑碰撞风险、航行经济性与COLREGs约束,确保避碰决策的合理性. 3)博弈论与意图推断,通过推测船舶决策动机动态优化策略. Wang等[9]提出基于观测-推测-预测-决策(observation-inference-prediction-decision, OIPD)框架的分布式避碰方案,欧阳旭东等[10]建立多船非零和动态博弈模型,崔浩等[11]引入船员驾驶偏好优化策略. 4)数据驱动与人工智能方法,利用历史航行数据与实时信息,通过机器学习生成策略. Zhang等[12]基于COLREGs划分会遇场景,结合深度Q学习生成策略;黄仁贤等[13]采用多智能体框架实现多船协同避碰;Wang等[14]通过去中心化训练增强多船协同决策能力.
现有研究存在以下局限性:1)多依赖于单向观测和推断,未充分考虑船舶间的信息交互与协同,难以适应E-航海、船舶智能化的发展趋势;2)博弈框架多聚焦避碰场景中各个本船视角下的即时决策,缺乏对场景变迁的预见;3)多智能体系统在复杂场景中的交互行为在多船协同避碰中未能有效体现. 本研究提出基于多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法的多船避碰博弈模型,通过RE机制实现船舶间的信息共享与协同决策. 具体内容包括:1)基于RE构建碰撞风险评估模型,采用三次样条插值生成连续时空航线,以最近时空距离(closest spatio-temporal distance, CSTD)量化碰撞风险;2)融合COLREGs构建基于航行意图的直航/让行关系(stand-on/give-way relationship, SGR)矩阵,明确避让责任;3)设计多船协同博弈模型,确保安全与合规的同时,最小化航线偏移;4)采用集中训练-分布执行(centralized training with decentralized execution, CTDE)框架优化联合策略,依据局部观测输出最优避碰决策.
1. 问题描述与建模
随着船舶智能化水平的提高,多船会遇场景日趋复杂,传统的单船独立决策难以有效化解多船航线在时空上的冲突. 在E-航海框架下,避碰模式正从单船独立决策转向多船协同机制. 2019年,液化天然气船Aseem与油轮Shinyo Ocean发生碰撞事故[15]. 尽管两船通过甚高频协调避让,但因第三艘船舶Silva驶入航道,迫使Shinyo Ocean改变航向,最终与Aseem相撞. 这一案例表明,船舶间缺乏协商机制是多船碰撞的重要致因. 因此,构建RE机制以支持协同决策,将为智能船舶避碰创造更有利条件.
1.1. 基于航线交换的碰撞风险评估
1.1.1. 航线表示与插值
通过RE克服船舶间单向决策与缺乏协同的问题,相关基本记号与方法如下. 设某水域内有
式中:
式中:
图 1
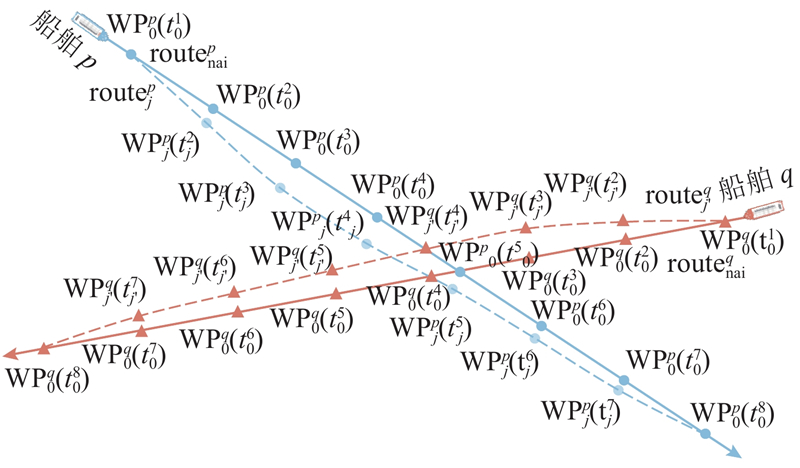
1.1.2. 基于航线交换机制评估碰撞风险
每艘船舶通过三次样条插值将离散航点插值为连续航线函数. 任意2条船航线
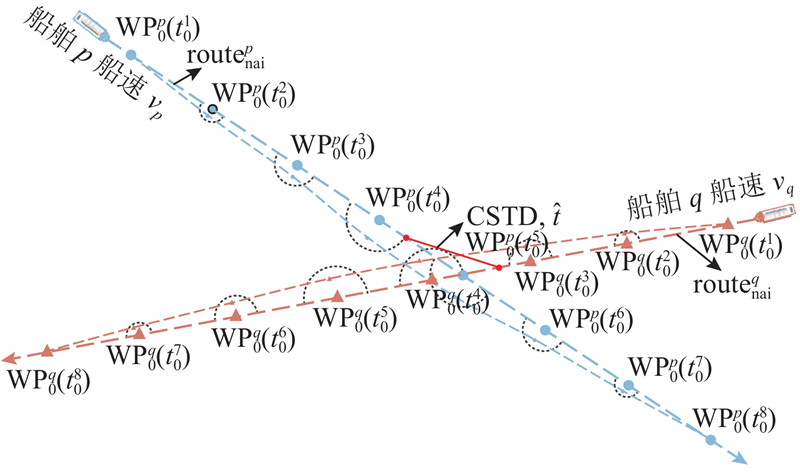
定义CSTD为两船在预测时间窗口内可能达到的最小距离,作为量化动态碰撞风险的核心指标,如图2所示.
图 2

安全会遇距离
1.2. 多船会遇中的避让关系矩阵
图 3
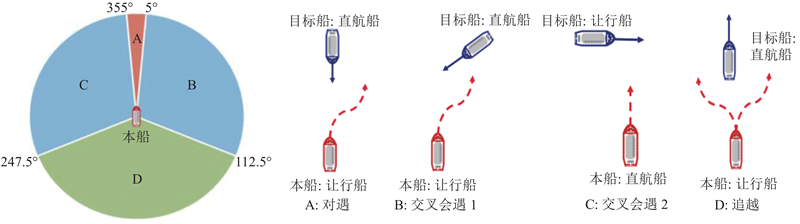
图 3 典型会遇场景的船舶避让行动
Fig.3 Avoidance actions of ships in typical encounter scenarios
如图4所示,SGR有两层含义. 在即时意义下,两船的瞬时位置、航向和航速决定了彼此在当前时刻的SGR,可以由TCPA、DCPA以及在最近会遇点的船舶位置和航向定义[18]. 在航线意义下,SGR由两船到达航线空间交汇点的先后顺序定义. 本研究关注RE机制下的协同避碰算法,以航线意义下的SGR为基础. 事实上,航线意义下的SGR由船舶即时SGR积累而成. 如图4(b)所示,2条航线之间的虚线段AB为两船间的CSTD. 此时,船舶q已驶过两船航线的交汇点,而船舶p尚未到达,因此船舶p为让行船,船舶q为直航船. 在多船会遇中,SGR矩阵通过记录每对船舶的避让关系明确责任. 矩阵元素
图 4
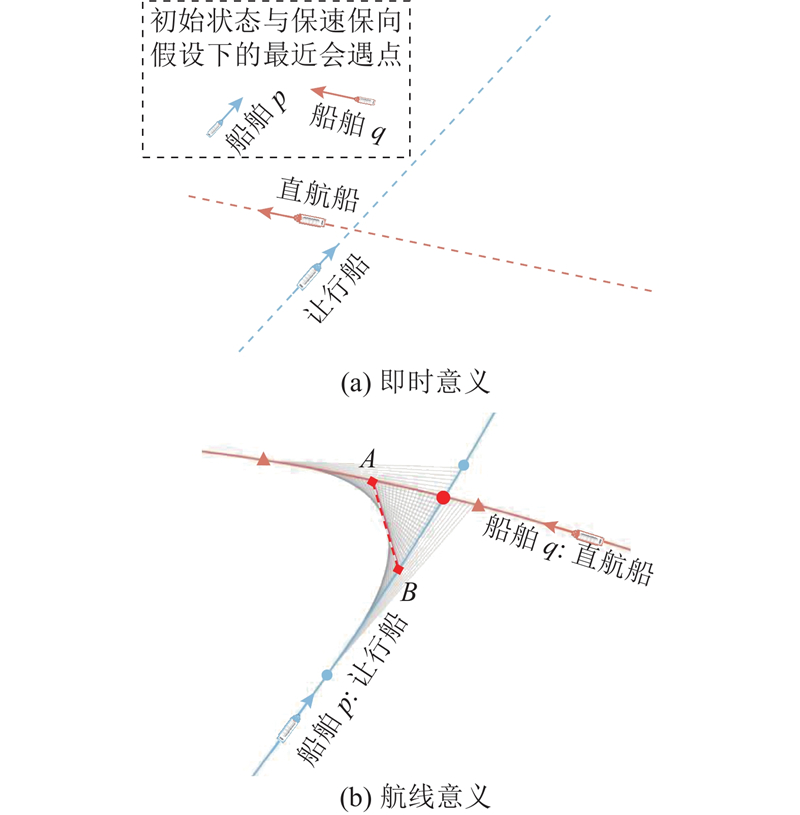
图 4 船舶会遇直航/让行关系的解读
Fig.4 Interpretations of stand-on/give-way relationship in ship encounters
1.3. 多船避碰博弈模型
为了解决多船避碰问题,构建多阶段重复博弈模型,采用MADDPG算法求解. 船舶通过RE机制播发航行计划,并按离散时隙
动作空间生成遵循以下规则. 1)航点固定:船舶i播发的起始航点
式中:
图 5
式中:
1.4. 不利工况条件下的直观偏差分析
1.4.1. 数据交换报文丢失
考虑到海上通信环境的不稳定性,RE过程中可能出现报文丢失,导致船舶无法获取完整的航点信息,进而影响避碰航线规划的准确性. 进行3种不同曲率条件下的实验,分析偶发报文丢失对碰撞风险评估的影响. 在典型两船交叉会遇场景中,在典型两船交叉会遇场景中计算完整航点信息条件下的CSTD,即
若
图 6

图 6 不同航线曲率下航点信息丢失对最近时空距离的影响
Fig.6 Impact of waypoint loss on closest spatio-temporal distance under different route curvature conditions
1.4.2. 船舶工况影响
为了刻画船舶操纵特性,采用经典的一阶Nomoto舵控模型,通过船舶偏航运动微分方程线性化得到
式中:
图 7
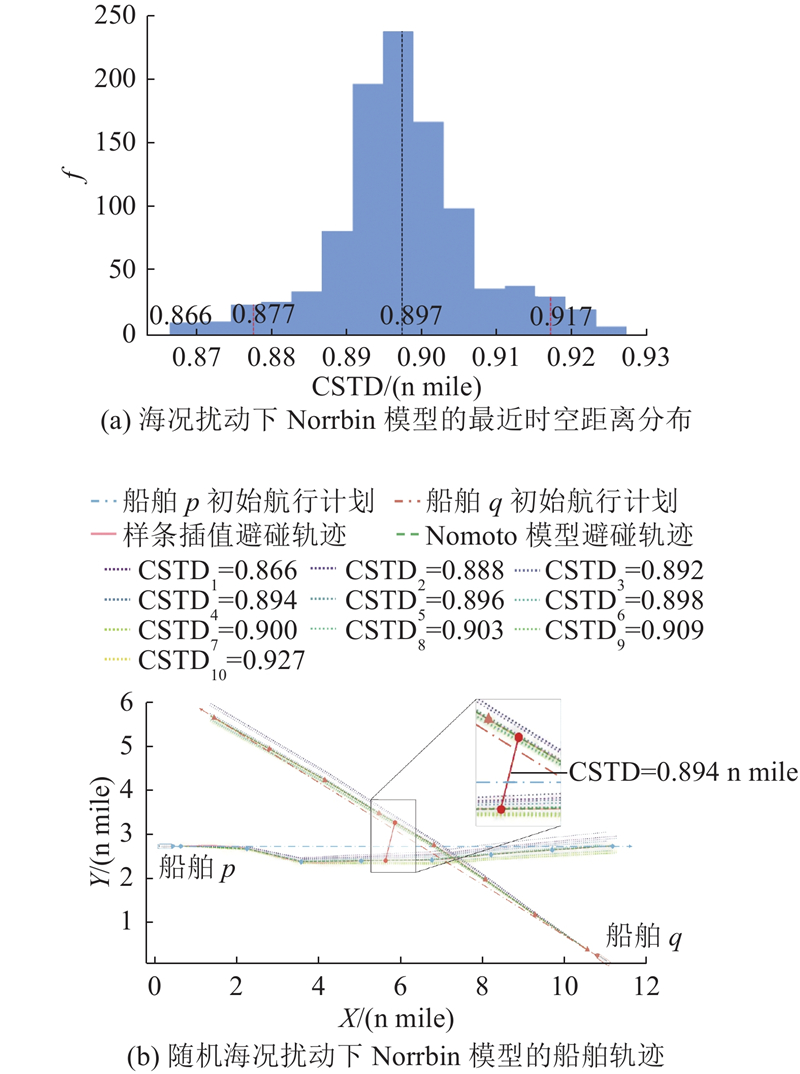
2. 基于多智能体强化学习的多船避碰决策
2.1. 多船避碰强化学习算法
2.1.1. 船舶的状态空间与动作空间
在多船避碰深度强化学习框架中,采用马尔可夫决策过程将多船避碰问题建模为多智能体随机博弈模型[21]:
其关键组成部分如下. 1)状态空间
记
所有船舶的联合动作空间为
4)奖励函数
式中:
式中:
式中:
2.1.2. 多船避碰的奖励函数
奖励函数
2.1.3. 多船避碰博弈的Pareto最优解表征
船舶i的状态值函数
式中:
式中:
2.2. 所提多船避碰算法框架
MADDPG算法基于MARL的CTDE框架,通过全局协同训练与局部自主决策,解决多船动态交互中的非稳定性与协同问题,算法框架如图8所示. MADDPG算法通过扩展深度确定性策略梯度算法,构建MARL联合策略优化范式. 船舶i的策略参数为高维向量
图 8
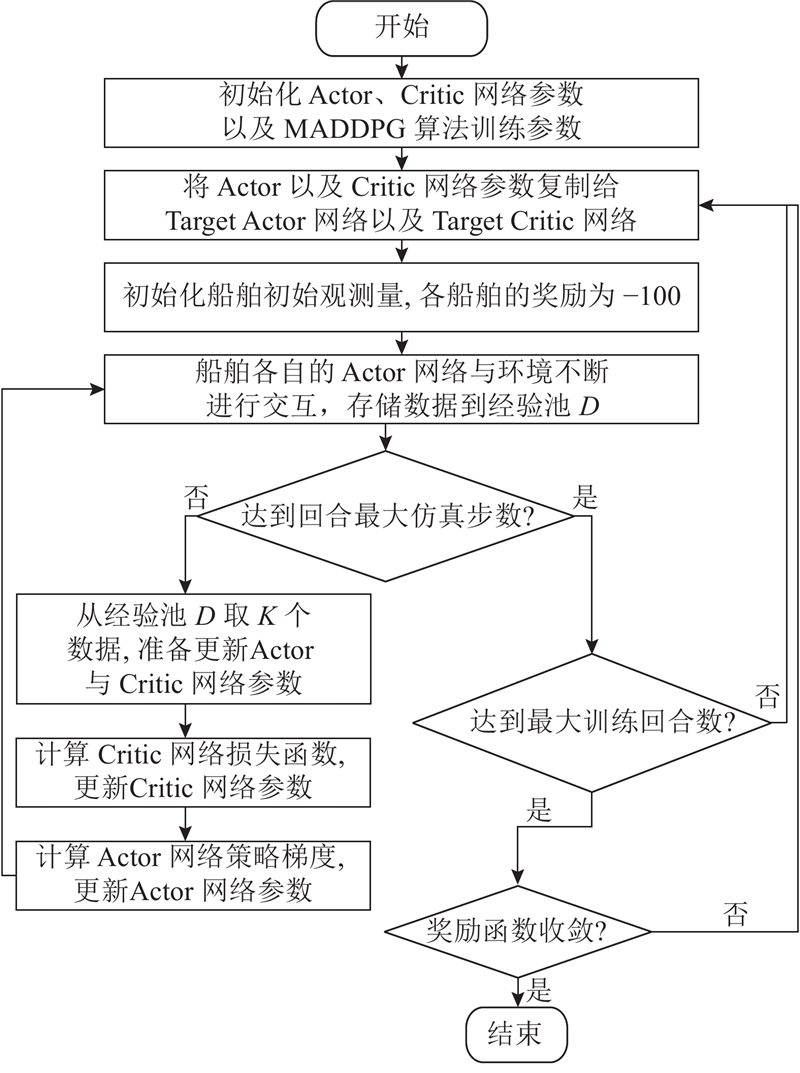
图 8 多智能体深度确定性策略梯度算法框架
Fig.8 Framework of multi-agent deep deterministic policy gradient algorithm
MADDPG算法能有效应对环境不稳定性的原因:若所有智能体策略已知,即使个别策略变化,环境的稳定性不受影响. 多智能体系统动力学模型为
当
式中:
Actor网络基于局部观测进行决策,目标函数
式中:
通过软更新对目标网络参数进行更新:
式中:
3. 仿真实验与分析
3.1. 实验环境与训练参数
船舶避碰决策仿真实验基于PyCharm开发,采用PyTorch框架与OpenAI Gym平台,运行硬件环境为i9-12900KS CPU、RTX4090 GPU.
3.1.1. 船舶避碰决策参数设置
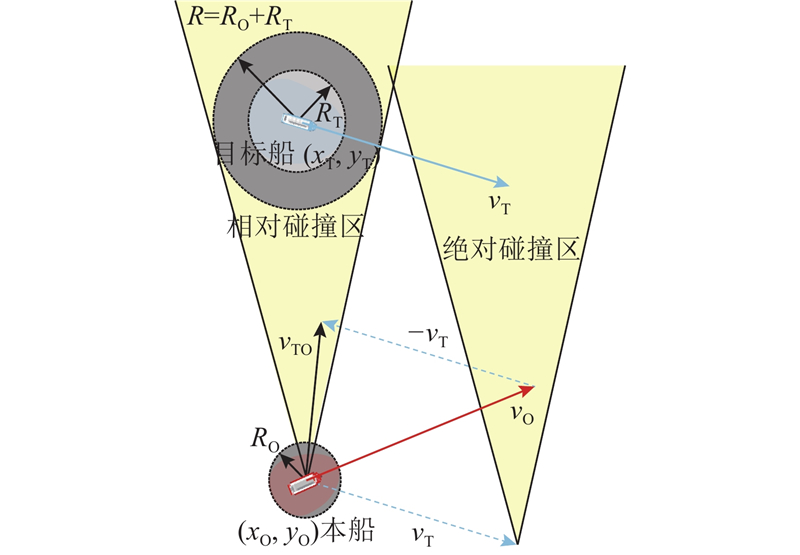
为了保障多船避碰决策的有效性,须明确SD、安全会遇距离及航点调整范围等参数. 采用四元SD模型[22],通过前、后、左、右4个方向的半径综合反映船舶尺寸、航速与操纵特性:
式中:
文献[22]以船长175 m、航速15节进行模拟,得到
3.1.2. 奖励函数权重
为了确定奖励函数权重,在两船交叉会遇场景中进行敏感性分析. 基于CTDE框架,采用MADDPG算法训练不同权重组合的避碰策略. 固定其他参数,以步长0.1构建21组权重组合,并统计各组合的CSTD均值与平均航线偏移量
图 9
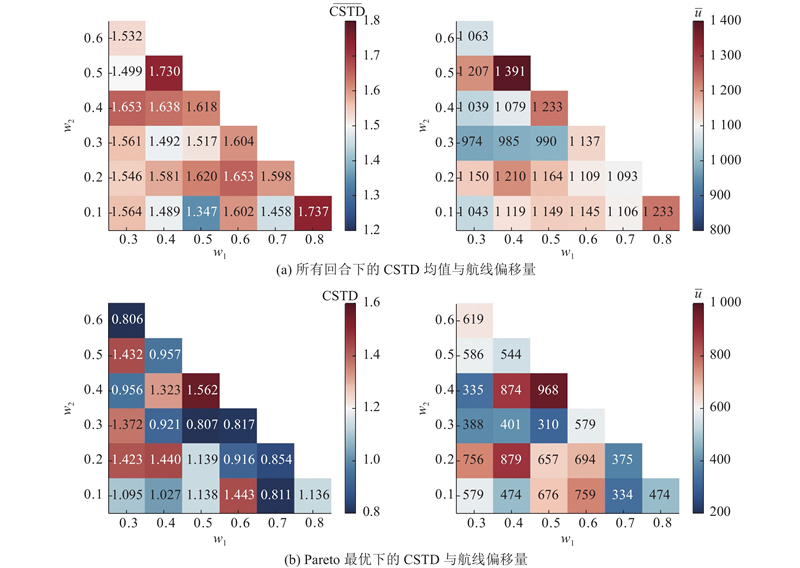
图 9 奖励权重组合对避碰决策关键参数的影响
Fig.9 Effect of reward weight combination on key parameters for collision avoidance decision-making
3.1.3. 所提多船避碰算法参数设置
表 1 多智能体深度确定性策略梯度算法参数
Tab.1
| 参数 | 数值 | 参数 | 数值 | |
| 训练最大回合数 | 104 | 经验池大小 | 106 | |
| 最大时间步长Step | 500 | 网络学习率 | ||
| 采样样本数 | 256 | 奖励折扣系数 | 0.98 | |
| 软更新系数 | — | — |
图 10
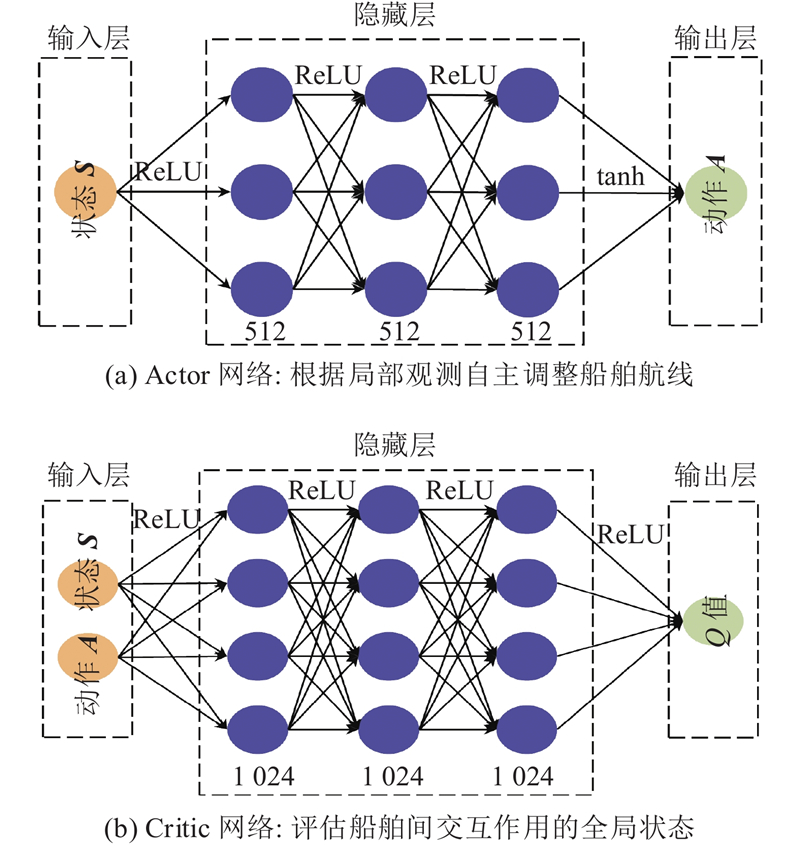
图 10 多智能体深度确定性策略梯度算法网络设计
Fig.10 Network design of multi-agent deep deterministic policy gradient algorithm
3.2. 实验结果与分析
为了评估MADDPG算法的多船避碰决策性能,在OpenAI Gym中搭建四船会遇仿真场景,通过奖励值与航线偏移量评估算法有效性与稳定性. 实验假设会遇场景位于开阔水域,所有船舶均配备AIS,可实时共享动态与航线信息.
3.2.1. 四船会遇初始场景设置
表 2 四船航点信息
Tab.2
| 船1 | 船2 | 船3 | 船4 | |||||||||||
| 时间 | 位置 | 时间 | 位置 | 时间 | 位置 | 时间 | 位置 | |||||||
| 13:30:00 | (7.40,3.62) | 13:30:00 | (1.56,11.81) | 13:30:00 | (11.73,10.87) | 13:30:00 | (4.49,14.25) | |||||||
| 13:36:52 | (7.40,5.12) | 13:37:19 | (2.93,11.21) | 13:36:03 | (10.57,9.92) | 13:36:34 | (4.79,12.78) | |||||||
| 13:43:44 | (7.40,6.62) | 13:44:38 | (4.31,10.61) | 13:42:05 | (9.40,8.97) | 13:43:08 | (5.08,11.31) | |||||||
| 13:50:37 | (7.40,8.12) | 13:51:57 | (5.68,10.01) | 13:48:07 | (8.24,8.03) | 13:49:43 | (5.38,9.84) | |||||||
| 13:57:29 | (7.40,9.62) | 13:59:16 | (7.05,9.41) | 13:54:10 | (7.07,7.08) | 13:56:17 | (5.68,8.37) | |||||||
| 14:04:21 | (7.40,11.12) | 14:06:35 | (8.43,8.81) | 14:00:12 | (5.91,6.14) | 14:02:51 | (5.98,6.90) | |||||||
| 14:11:13 | (7.40,12.62) | 14:13:54 | (9.80,8.21) | 14:06:15 | (4.74,5.19) | 14:09:25 | (6.28,5.43) | |||||||
| 14:18:05 | (7.40,14.12) | 14:21:13 | (11.18,7.60) | 14:12:17 | (3.58,4.25) | 14:15:58 | (6.57,3.96) | |||||||
图 11
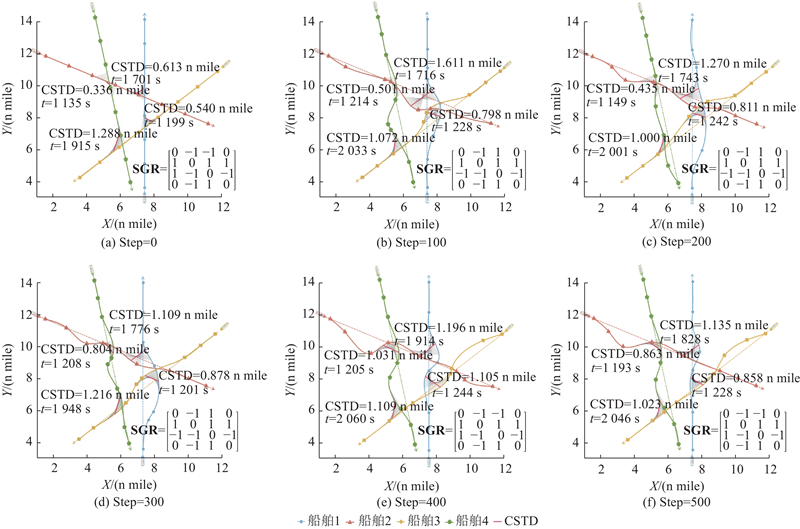
图 11 多智能体深度确定性策略梯度算法下不同时间步长的航线规划方案
Fig.11 Routing schemes at different time steps under multi-agent deep deterministic policy gradient algorithm
3.2.2. 避碰效果与航线优化效果分析
图 12
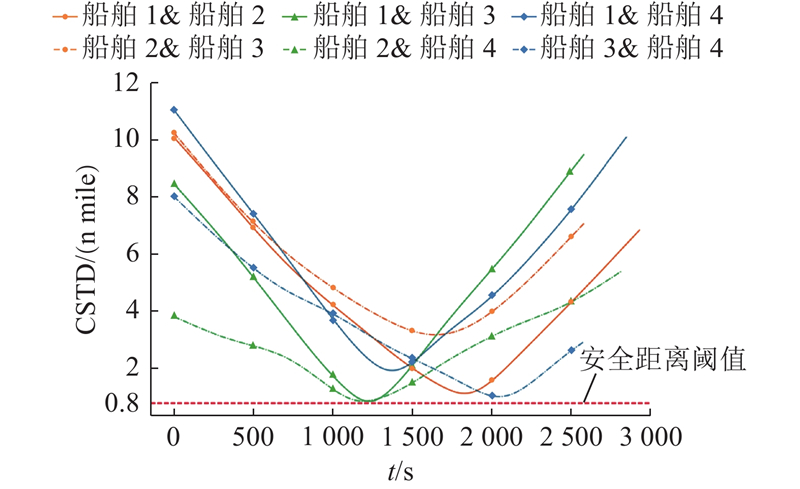
3.2.3. 所提多船避碰算法训练效果分析
通过观察奖励值的收敛趋势与航线偏移量的变化,分析MADDPG算法在多船协同避碰中的有效性与稳定性. 训练过程中总奖励Ra与平均航线偏移量
图 13
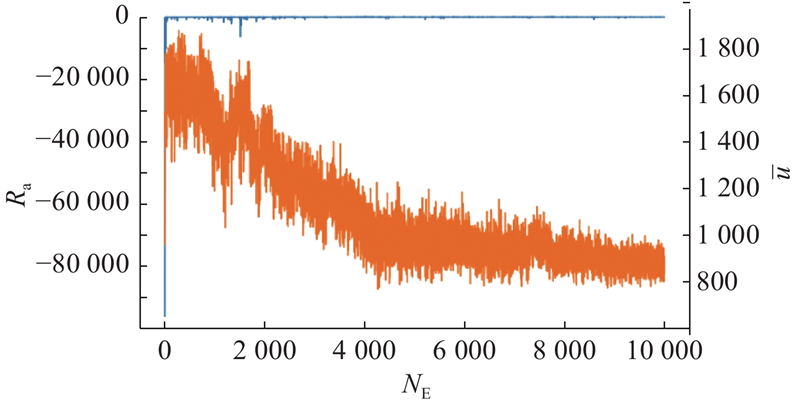
图 13 总奖励与平均航线偏移随训练回合的变化
Fig.13 Variation of total reward and average route deviation with training episodes
3.3. 算法性能评估
3.3.1. 观测-推测-预测-决策算法对比分析
图 14
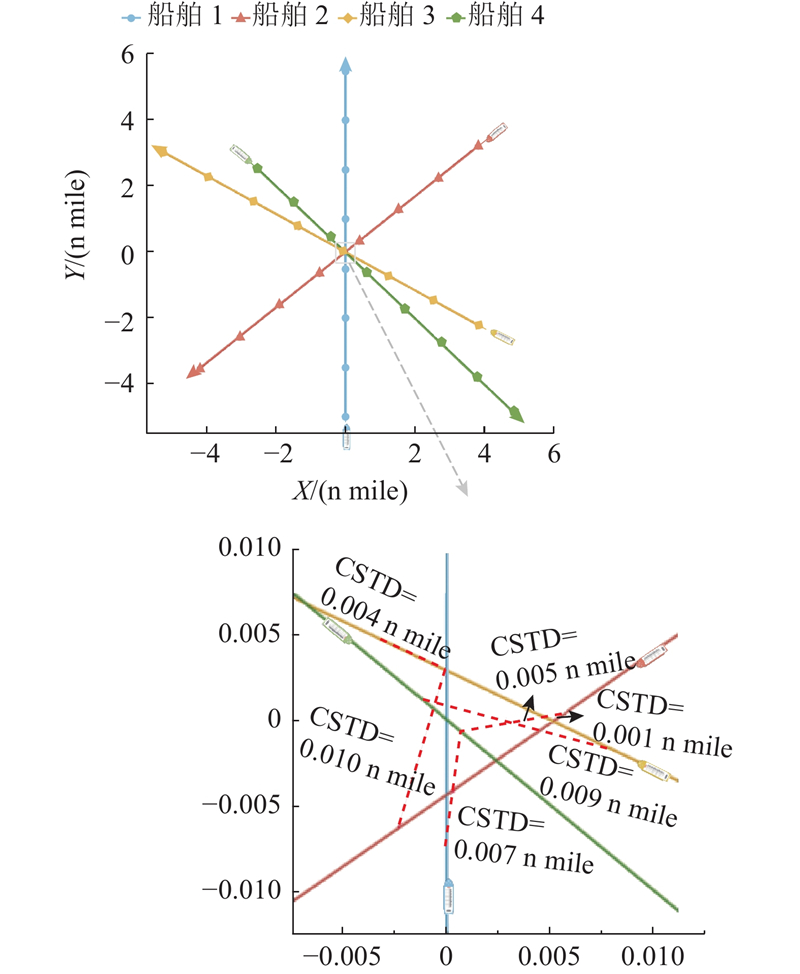
图 15
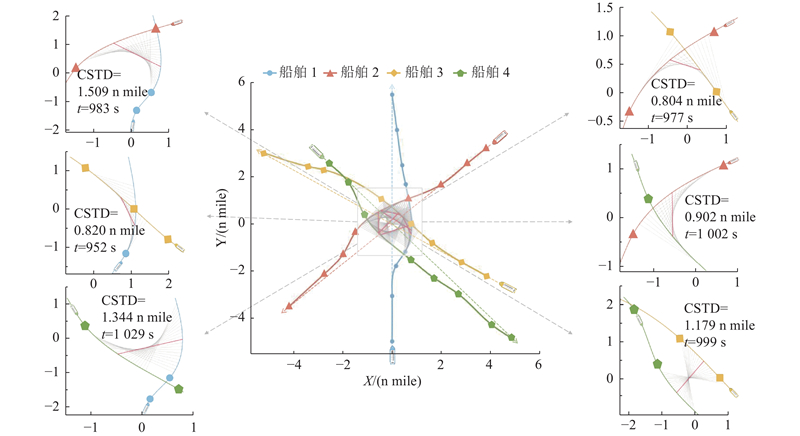
图 15 多智能体深度确定性策略梯度算法求解的Pareto最优航线
Fig.15 Pareto-optimal routes solved by multi-agent deep deterministic policy gradient algorithm
对比2种算法在额外航行距离、船舶对最近距离以及避碰响应时间的不同,结果如图16所示. 为了检验差异显著性,对额外航行距离进行配对t检验. 定义OIPD与MADDPG算法的观测向量分别为
图 16
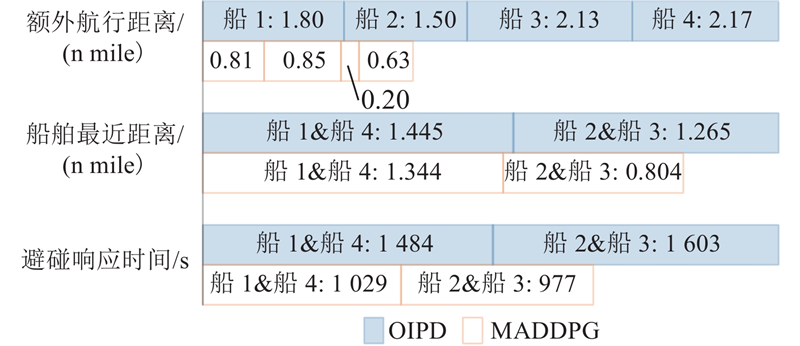
图 16 不同避碰算法的性能对比
Fig.16 Performance comparison of different collision avoidance algorithms
式中:
3.3.2. 速度障碍算法对比分析
图 17
MADDPG算法(M算法)与VO算法(V算法)在避碰决策上生成航线的对比如图18所示. VO算法在静态场景下策略过于保守,致使航行成本较高. VO算法虽能应对静态条件,但在他船协同调整航线后,仍存在碰撞风险. 相比之下,MADDPG算法通过模拟多船动态交互,能同时保障安全、优化路径并减少成本.
图 18
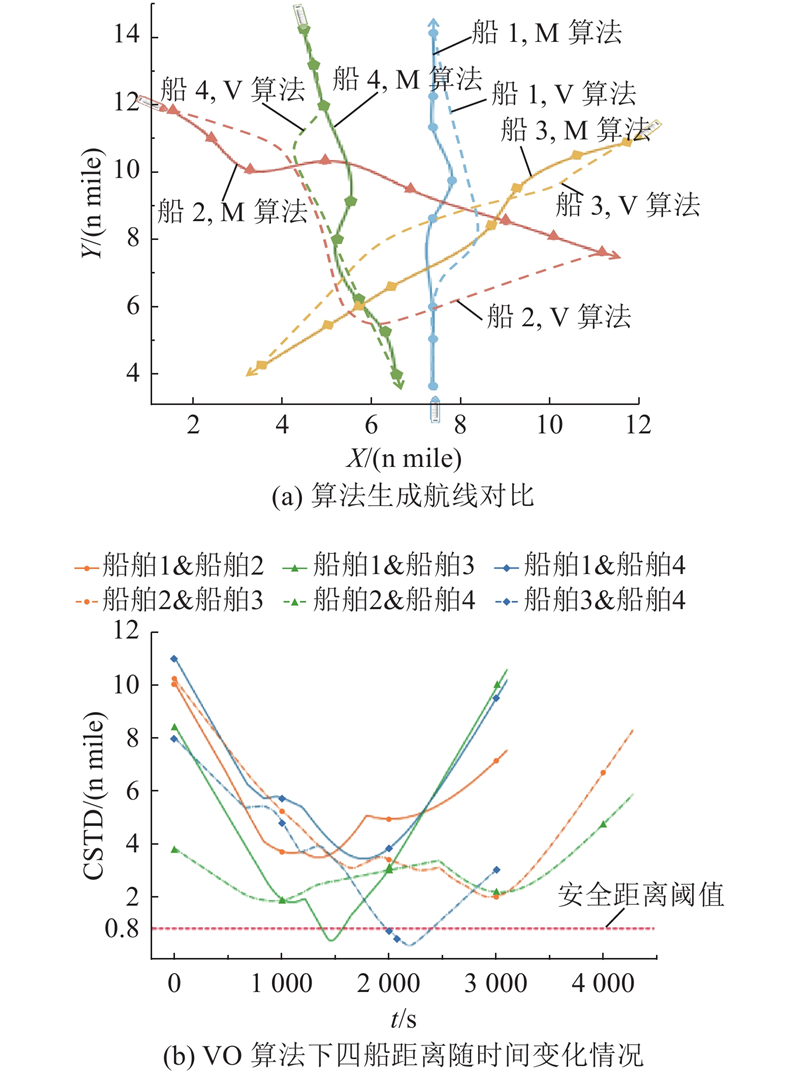
图 18 不同避碰算法生成的航线对比
Fig.18 Comparison of routes generated by different collision avoidance algorithms
4. 结 语
本研究围绕RE机制下的多船避碰问题,构建并验证基于MADDPG算法的协同决策框架. 将多船避碰决策建模为多阶段重复博弈过程,借助RE机制共享航行计划,并结合三次样条插值构建连续航线函数,通过CSTD与SGR矩阵量化碰撞风险与避让责任. 在此基础上,构建兼顾安全、合规与经济的多目标奖励函数,采用CTDE架构训练Actor-Critic网络,驱动策略收敛至Pareto最优. 四船会遇场景的仿真结果表明,所提算法在确保CSTD高于安全阈值的同时,相比典型算法能够减少额外航程,并在当事船舶互知彼此避碰决策的过程中从容实现避碰. 尽管所提算法在原理上可行,但在实施过程中仍须考虑如下因素:1)航线交换需要周密的船间通信协议支持,需要在各个船舶之间达成共识;2)航线交换的尺度须根据当前的船舶交通流密度等交通态势特征进行优化,即在多大的时间和空间范围进行航线交换;3)需要有激励机制遏制船舶滥用航线交换,如船舶在航线设计上发生“出尔反尔”的现象. 这些问题将在后续研究中逐步涉及.
参考文献
河口深槽可航宽度变化水域航行决策方法
[J].DOI:10.16183/j.cnki.jsjtu.2023.356 [本文引用: 1]
Navigation decision method in estuary deep trough with varying width of navigable waters
[J].DOI:10.16183/j.cnki.jsjtu.2023.356 [本文引用: 1]
紧迫危险威胁下交叉相遇局面应急操船方法
[J].DOI:10.16265/j.cnki.issn1003-3033.2024.05.0910 [本文引用: 1]
Emergency ship maneuvering method for crossing encounter situation under immediate danger threat
[J].DOI:10.16265/j.cnki.issn1003-3033.2024.05.0910 [本文引用: 1]
Velocity obstacle algorithms for collision prevention at sea
[J].DOI:10.1016/j.oceaneng.2018.01.001 [本文引用: 2]
Ship domain model for multi-ship collision avoidance decision-making with COLREGs based on artificial potential field
[J].DOI:10.12716/1001.11.01.09 [本文引用: 1]
COLREGs-compliant unmanned surface vehicles collision avoidance based on multi-objective genetic algorithm
[J].DOI:10.1109/ACCESS.2020.3030262 [本文引用: 1]
Autonomous decision-making scheme for multi-ship collision avoidance with iterative observation and inference
[J].DOI:10.1016/j.oceaneng.2019.106873 [本文引用: 2]
基于扩展式动态博弈的多船避碰决策模型
[J].DOI:10.16265/j.cnki.issn1003-3033.2020.01.020 [本文引用: 1]
Antensive form game theory based multi-ship collision avoidance scheme
[J].DOI:10.16265/j.cnki.issn1003-3033.2020.01.020 [本文引用: 1]
自主船舶与有人驾驶船舶动态博弈避碰决策
[J].
Dynamic game collision avoidance decision-making for autonomous and manned ships
[J].
Decision-making for the autonomous navigation of maritime autonomous surface ships based on scene division and deep reinforcement learning
[J].DOI:10.3390/s19184055 [本文引用: 1]
基于多智能体深度强化学习的多船协同避碰策略
[J].DOI:10.13196/j.cims.2023.0382 [本文引用: 1]
Multi-ship collaborative collision avoidance strategy based on multi-agent deep reinforcement learning
[J].DOI:10.13196/j.cims.2023.0382 [本文引用: 1]
Collaborative collision avoidance approach for USVs based on multi-agent deep reinforcement learning
[J].DOI:10.1109/TITS.2025.3547775 [本文引用: 1]
基于Vondrak滤波和三次样条插值的船舶轨迹修复研究
[J].DOI:10.3963/j.issn1674-4861.2015.04.016 [本文引用: 1]
A study of ship trajectory restoration based on Vondrak filtering and cubic spline interpolation
[J].DOI:10.3963/j.issn1674-4861.2015.04.016 [本文引用: 1]
Nash bargaining strategy in autonomous decision making for multi-ship collision avoidance based on route exchange
[J].DOI:10.1049/itr2.70025 [本文引用: 1]
A spatial-temporal forensic analysis for inland-water ship collisions using AIS data
[J].
A real-time multi-ship collision avoidance decision-making system for autonomous ships considering ship motion uncertainty
[J].DOI:10.1016/j.oceaneng.2023.114205 [本文引用: 1]
Research on the influence of wind, waves, and tidal current on ship turning ability based on Norrbin model
[J].DOI:10.1016/j.oceaneng.2022.111875 [本文引用: 1]
基于DE-MADDPG的多无人机协同追捕策略
[J].
Cooperative pursuit strategy for multi-UAVs based on DE-MADDPG algorithm
[J].
An intelligent spatial collision risk based on the quaternion ship domain
[J].DOI:10.1017/S0373463310000202 [本文引用: 2]
Deep reinforcement learning model for multi-ship collision avoidance decision making design implementation and performance analysis
[J].DOI:10.1038/s41598-025-05636-3 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}