

近年来,深度学习技术[1]发展迅速,推动了边缘设备的快速发展. 自2021年低空经济[2-3]被首次写入规划纲要以来,这一领域便受到了大力推动. 2023年,低空经济被列为战略性新兴产业,在2024年更是被写入政府工作报告,相关政策明确鼓励推动低空经济发展. 作为低空经济的核心应用载体之一,无人机可以弥补低空观测、区域监测、场景勘察等任务中因天气、空域等限制造成的信息损失. 然而,无人机航拍图像存在视角高度高、目标小和背景复杂的问题,导致其检测过程中特征提取难度大,以及目标之间互相遮挡,容易出现漏检、误检情况. 因此,基于深度学习技术设计适用于复杂场景的无人机视角下的小目标检测算法具有重要的现实意义.
为了克服这些难题,学者们不断优化算法,以提升对复杂场景下小目标的识别和定位能力,实现更高效、准确的无人机应用. 宋耀莲等[9]通过在特征提取部分引入双级路由注意力机制,提出损失函数FPIoU,并采用结合注意力机制的动态目标检测头,提出基于YOLOv5的无人机小目标检测算法FDB-YOLO,但是检测精度仍然有待提高. 韩俊等[10]对特征提取模型进行重新设计,丰富了目标特征信息,设计混合域注意力机制以抑制背景干扰,但是模型复杂度过高. 针对无人机小目标背景复杂、目标重叠的问题,杨智能等[11]通过在主干网络的C2f模块中融合可变性卷积,在颈部网络中引入GC注意力机制,在头部设计动态检测头,检测精度得到了一定的提升,但是检测速度较慢. 向征等[12]利用SPDConv处理P2层特征,结合OmniKernel模块的多分支设计SOEP模块,均衡获取上下文信息,并使用解耦头输出检测结果,在主干部分引入C2f-MDCNv2以整合多尺度信息;相比于原算法,其mAP50值提高了3.6个百分点,但是精度仍然有待提升. 针对无人机图像的高分辨率特征、复杂背景和目标重叠带来的挑战,Sun等[13]提出双向增长网络来区分复杂背景中的小目标,提出空间信道增强模块来解决采样过程中小目标信息丢失的问题,并采用多尺度特征提取模块对C2f模块进行改进,从而优化YOLOv8;改进后的模型相较于基线模型在mAP50上提升了4.1个百分点. 为了解决城市背景特征对无人机检测带来的误检、漏检问题,Liu等[14]提出覆盖型最小点距离边界框损失函数,优化小目标回归精度,同时设计更多空间信息特征金字塔网络来增强特征提取,并利用高效多尺度注意力改进模型的颈部网络,以提升对小目标的检测性能. 为了解决无人机小目标检测模型参数量大、计算复杂度高的问题,Yang等[15]构建用于小目标检测的轻量级多维特征提取网络,通过神经架构搜索选择模型结构,以降低模型的计算复杂度,但是模型的参数量仍然需要进一步的降低.
针对以上问题,以YOLOv11[16]为基础模型做出改进. 相较于之前的YOLO版本,YOLOv11模型在特征提取、效率和速度、准确性以及环境适应性方面均有显著提升. 提出复杂场景下无人机小目标检测算法DLSRF-Net,旨在通过改进模型的特征融合和特征提取阶段,降低模型负载,提升模型在复杂场景中的小目标检测精度. 提出自适应深度可分离感受野注意力卷积(adaptive depthwise separative receptive field attention convolution, DSRFAConv)模块,采用感受野注意力卷积(receptive-field attention convolution, RFAConv)[17],关注更多的感受野空间特征,并使用深度可分离卷积(depthwise separable convolution, DSConv)[18]在特征维度上分组卷积,再通过逐点卷积(pointwise convolution, PConv)将所有通道合并为输出特征图,从而达到减小计算量、提升计算效率的目的,提升模型对小目标检测和识别的准确性. 设计全新的轻量化多尺度线性注意力(lightweight multi-scale linear attention, LMLA)机制,以解决模型在高分辨率复杂场景中检测密集小目标时计算复杂度高的问题,并在一定程度上提升对密集小目标的关注度,提升模型在小目标检测中的整体性能;设计深度可分离感受野多层次特征融合模块(receptive-field semantic cross-level depthwise-separable feature fusion, RSCDI),深度整合DSRFAConv、上采样模块、空间注意力和通道注意力机制,实现不同尺度特征的深度融合,并通过融合多尺度特征信息来增强模型的特征表示能力,使模型更适配于复杂场景下的小目标检测任务.
1. 无人机小目标检测算法
1.1. 模型整体结构
DLSRF-Net的整体结构如图1所示,由骨干网络、颈部网络以及检测头3个部分组成. 其主要作用分别为特征提取、特征融合和检测结果输出. 由于无人机视角下的小目标缺乏感受野特征,且传统卷积带来了参数量较大的问题,使用DSRFAConv提升模型对小目标感受野特征的提取能力,并优化模型的运算过程. 无人机视角下的小目标容易被遮挡,且多目标呈现多尺度特征,因此设计多分支轻量化多尺度线性注意力机制,提升模型对小目标的关注度. 原模型的上采样层和全连接层容易造成信息损失且加大了计算成本,为此引入新设计的上采样层和全连接层,更大限度地保留模型提取的目标特征信息,提升模型对小目标的检测精确度及其鲁棒性和泛化能力.
图 1
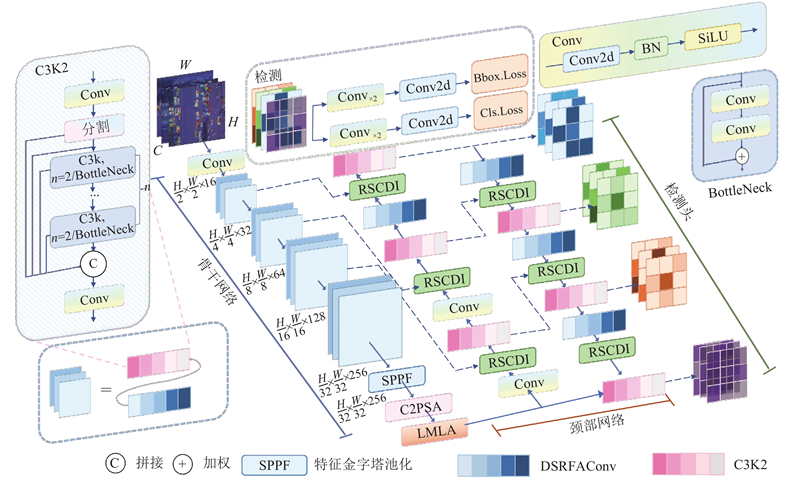
图 1 重构YOLOv11的无人机小目标检测算法的整体结构
Fig.1 Overall structure of UAV small target detection algorithm based on reconstruction of YOLOv11
1.2. 深度可分离感受野注意力卷积
在传统卷积运算过程中,感受野特征存在重叠,且每个感受野都采用相同的感受野特征,导致目标注意力权重会在所有感受野特征中被共享,不同位置的信息差异无法被明显区分,从而限制了模型的性能. RFAConv通过关注感受野的空间特征来提升模型的检测效果,能够有效解决传统卷积在参数共享上的问题.
RFAConv的整体处理流程如图2所示. 对于输入特征X,RFAConv首先通过分组卷积将输入的空间特征转换为感受野特征,其中每一个感受野对应1个感应窗口;通过调整形状将每个感应窗口调整为原来的k倍,并对每个输入的感受野特征进行平均池化处理,将其压缩为常数. 然后使用分组卷积增强每个感受野之间的特征联系,通过Softmax操作生成每个特征的注意力权重. 最后,将注意力权重与感受野特征相乘,根据特征的重要程度进行加权,得到输出. RFAConv的计算过程表示为
图 2
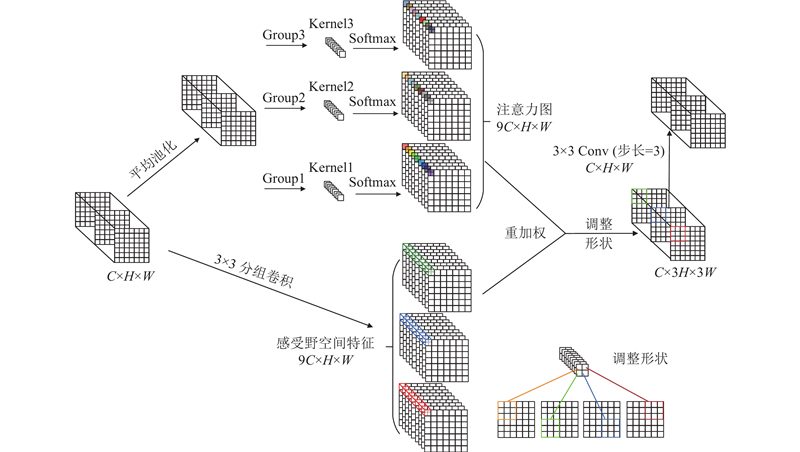
图 2 感受野注意力卷积动态提取感受野空间特征的整体流程
Fig.2 Overall process of receptive-field attention convolution for dynamically extracting receptive-field spatial features
式中:
由于无人机视角下的航拍图像像素低,模型在特征提取过程中缺乏明显的感受野,导致其对小目标的位置信息不敏感,从而限制了模型在小目标检测任务中的性能. 此外,更多的感受野提取操作会增加模型的计算量. 相比于常规的卷积操作,深度可分离卷积不需要在所有输入通道上使用相同的卷积核,因此其参数量和运算成本较低,使模型更适合在移动设备或资源受限的环境中运行. 据此,提出DSRFAConv,其结构如图3所示. 使用DSRFAConv替换骨干层的基础卷积模块,提升模型对小目标感受野特征的提取能力,从而提升模型在复杂场景下对小目标的检测性能.
图 3
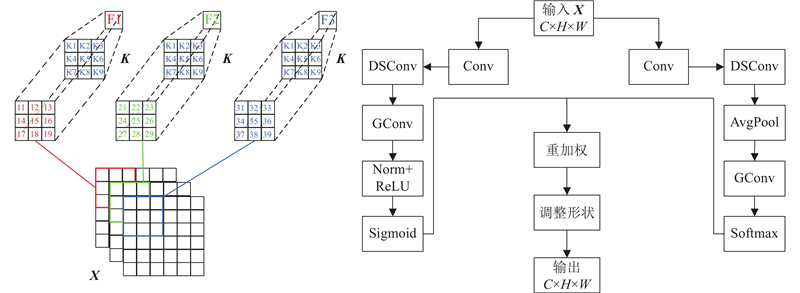
图 3 自适应深度可分离感受野注意力卷积模块结构
Fig.3 Structure of adaptive depthwise separative receptive field attention convolution module
1.3. 多分支轻量化多尺度线性注意力机制
注意力机制能够增强模型对小目标特征的关注度,减少对复杂背景的处理. 多尺度线性注意力(multi-scale linear attention, MLA)机制[19]通过聚合来自小目标特征附近的Q、K、V令牌信息,获得多尺度Tokens. 在聚合过程中,Q、K、V令牌相互独立,仅使用小卷积核的DSConv进行分离,以避免硬件效率的损失. 在GPU训练过程中,将所有DSConv聚合为1个DSConv,并将所有的1×1卷积聚合为单个1×1分组卷积,提升模型对多尺度特征的聚合能力.
此外,MLA利用矩阵乘法的关联特性,将计算复杂度和内存占用从二次减少到线性,并保留了原有性能. 该过程可以表示为
式中:
与Softmax注意力机制相比,线性注意力机制将Softmax函数解耦为2个独立的函数,从而能够将注意力的计算顺序从
图 4
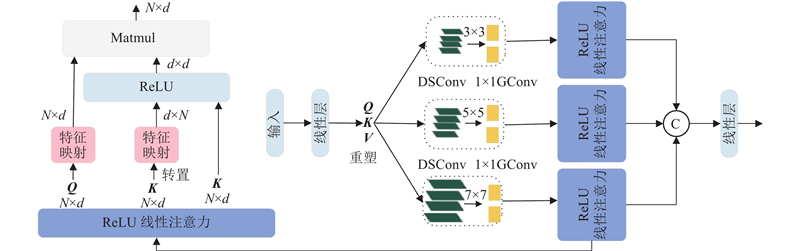
图 4 多分支轻量化多尺度线性注意力模块结构
Fig.4 Structure of multi-branch lightweight multi-scale linear attention module
1.4. 深度可分离感受野多层次特征融合
在YOLOv11中,上采样操作用于恢复特征图的分辨率,传递并突出上下文信息,使模型更好地理解图像内容. 拼接(Concat)操作出现在网络的不同层次之间,用于特征图之间的融合,将多个小特征图融合为大特征图,但是该操作会显著增加模型的计算量.
图 5
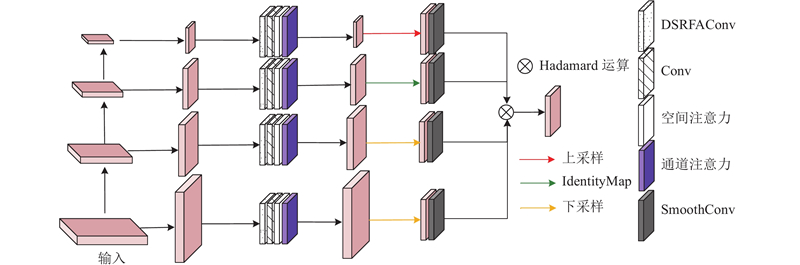
图 5 深度可分离感受野多层次特征融合模块结构
Fig.5 Structure of receptive-field semantic cross-level depthwise-separable feature fusion module
RSCDI模块首先根据通道数列表将输入特征分为不同层次的特征图,并针对不同层次的特征图分别进行DSRFAConv处理. 随即采用1×1Conv进行传递,对传递的特征图分别进行空间注意力和通道注意力处理,融合特征图的局部空间信息和全局通道信息. 然后,将不同层次的特征图调整为相同的分辨率,并进行如下调整:如果当前特征图的分辨率低于目标分辨率,则通过上采样将其调整到目标分辨率;如果当前特征图分辨率高于目标分辨率,则通过下采样调整至目标分辨率;如果当前特征图分辨率等于目标分辨率,则直接使用当前特征图. 使用SmoothConv(3×3Conv)对调整后的特征图进行平滑处理,去除噪声并保留细节信息. 最后,通过Hadamard运算(逐元素相乘)得到融合后的特征图,最大限度地整合局部空间信息和全局通道信息,突出小目标的关键特征,抑制无效信息,使模型更关注于小目标,从而提升模型在复杂场景下对小目标的检测效果.
2. 实验验证
2.1. 数据集
采用公开数据集VisDrone2021,该数据集由天津大学机器学习和数据挖掘实验室AISKYEY收集和发布. 基准数据集包括288个视频片段,由多种型号的无人机摄像头捕获,覆盖不同的位置、环境、物体和目标密度,且数据收集过程涵盖不同的天气和光照条件. 采集到的图像中,训练集包含6 471张图像,验证集包含548张图像,测试集包含1 610张图像. 图像类别包括行人、人、自行车、汽车、面包车、卡车、三轮车、遮阳篷三轮车、公共汽车和摩托车10类. 该数据集中待检测目标数量庞大,且多数以小目标或模糊物体的形态存在,对无人机场景下的目标检测研究具有重要的参考意义,能够有效支撑模型在实际小目标检测中的性能评估和鲁棒性验证,符合本研究的实验要求.
2.2. 实验环境以及评价指标
实验环境:采用Ubuntu 20.04操作系统(内核版本为3.10)、2.3.0版本的Pytorch以及12.1版本的CUDA,CPU为Intel(R) Xeon(R) Gold 6154 CPU @ 3.00 GHz,GPU为NVIDIA GeForce RTX3090@24G. 相关参数配置:优化器采用SGD,权重衰减系数为
为了评价模型在小目标检测上的准确性和可用性,采用3种评价指标,包括精确率(P)、召回率(R)、平均精度均值(mAP50、mAP50-90).
1)精确率用于评估模型预测为正样本的样本中预测正确的样本比例. 在目标检测中,如果模型预测的边界框与真实的边界框重合,则认为预测正确. 精确率的计算公式为
式中:TP为真正例的数量,即模型正确预测为正类的样本数;FP为假正例的数量,即模型错误预测为正类的样本数.
2)召回率用于评估模型能够找出的所有真实正样本与实际正样本的比例. 在目标检测中,如果真实的边界框与预测的边界框重合,则认为该样本被正确召回. 召回率的计算公式为
式中:FN为假负例的数量,即模型错误预测为负类的正类样本数.
3)平均精度均值用于综合衡量模型在多类别目标检测任务中的整体性能. mAP50表示在50%的IoU阈值下的mAP值;mAP50-95为更严格的评价指标,需要计算在50%~95%内不同IoU阈值下的mAP值,然后取平均值,因此能够更准确地评估模型在不同IoU阈值下的性能. 平均精度均值的计算公式为
式中:n为类别数.
2.3. 消融实验结果及分析
为了验证所提方法的有效性,以YOLOv11为基准模型,在VisDrone2021数据集上进行消融实验. 实验结果如表1所示. 其中,Np为模型参数量;FPS为每秒帧数,用于衡量模型的实时性能;FLOP为每秒浮点运算次数,用于衡量模型的计算量.
表 1 所提模块在VisDrone数据集上的消融实验结果
Tab.1
| 模块 | P/% | R/% | mAP50/% | mAP50-90/% | Np/106 | FPS/(帧·s−1) | FLOP/(109·s−1) |
| — | 42.7 | 33.0 | 32.9 | 18.8 | 2.6 | 82.3 | 6.3 |
| RFAConv | 44.5 | 33.5 | 33.6 | 19.7 | 2.6 | 61.4 | 6.7 |
| MLA | 43.4 | 34.1 | 33.5 | 19.6 | 2.5 | 69.7 | 7.1 |
| SDI | 45.4 | 33.9 | 34.3 | 20.2 | 3.3 | 74.4 | 12.8 |
| DSRFAConv | 44.9 | 34.1 | 34.4 | 19.9 | 2.4 | 66.6 | 6.6 |
| LMLA | 43.9 | 34.7 | 33.9 | 19.2 | 2.5 | 73.6 | 6.1 |
| RSCDI | 46.1 | 35.6 | 35.4 | 21.2 | 2.6 | 77.8 | 9.7 |
| DSRFAConv+LMLA | 45.4 | 36.2 | 35.1 | 20.9 | 2.5 | 80.1 | 6.9 |
| DSRFAConv+RSCDI | 46.6 | 36.1 | 36.4 | 21.7 | 2.6 | 83.7 | 8.7 |
| LMLA+RSCDI | 47.7 | 36.3 | 36.8 | 22.7 | 2.4 | 73.6 | 9.1 |
| DSRFAConv+LMLA+RSCDI | 49.9 | 38.1 | 40.1 | 24.2 | 2.8 | 109.8 | 11.9 |
相较于RFAConv,改进后的DSRFAConv使模型的FPS等各项指标均得到了一定提升,并且降低了计算成本. 相较于MLA,改进后的DSRFAConv由于多分支的设计,有效降低了模型的计算量. 相较于原始SDI模块,改进后RSCDI模块不仅使模型的参数量降低了21%,而且提升了模型的综合检测性能. 将颈部结构的Conv模块替换为DSRFAConv后,模型的mAP50和mAP50-90均有一定提升,说明模型能够更好地提取小目标的感受野特征. 将LMLA引入基本模型后,不仅降低了模型的参数量,而且提升了模型的整体性能,说明LMLA能够有效提升模型对小目标的关注度,降低模型的计算量. 当模型使用RSCDI时,各项指标均得到了较大的提升,说明RSCDI使小目标的上下文信息得到了有效保留. 将DSRFAConv和LMLA加入模型后,由于LMLA中使用ReLU函数,解决了Softmax操作在硬件环境下导致模型训练效率低的问题,模型的整体性能在仅采用DSRFAConv模块的基础上得到了进一步的提升. 将DSRFAConv和RSCDI加入模型后,模型的检测性能得到了提升,这是因为RSCDI融合了DSRFAConv、Conv、上采样以及SDI模块,其中DSRFAConv在整合上下文信息和连接不同的特征图方面同样起到了作用. 将LMLA和RSCDI加入模型后,模型的参数量降低了7.7%,并且模型的综合性能得到了大幅度的提升,这得益于LMLA的轻量化设计和RSCDI对无效信息的抑制. 将3个模块均加入模型后,模型取得了最好的结果,综合性能达到最高;虽然模型的参数量和计算量相较于基础模型略有增加,但是模型的P、R、mAP50以及mAP50-90指标均得到了较大的提升,分别提升了7.2、5.1、7.2和5.4个百分点,且模型的检测速度提升明显,FPS指标相较于基础模型提升了27.5帧/s. 消融实验结果表明,提出的各模块对算法检测性能的提升均有不同程度的贡献;相较于基础算法,提出的算法在复杂场景中无人机视角下的小目标检测任务中,检测性能有明显提升.
2.4. 对比实验结果及分析
为了验证所提算法的有效性,将所提算法与其他优秀算法进行比较. 根据模型参数量和计算量大小,将模型尺寸分为基础尺寸N(Np<4.5×106且FLOP<1.5×1010/s)和稍大尺寸M(Np>4.5×106且FLOP>1.5×1010/s). 此举是为了让模型能够更好地适应不同负载量的平台,以满足实时检测要求. 对模型进行200轮次训练后的测试集实验结果如表2所示.
表 2 VisDrone2021数据集上不同算法的性能对比实验结果
Tab.2
| 模型尺寸 | 算法 | P/% | R/% | mAP50/% | mAP50-90/% | Np/106 | FPS/(帧·s−1) | FLOP/(109·s−1) |
| N | Drone-YOLO | 46.5 | 35.6 | 36.1 | 21.3 | 3.0 | 79.4 | 12.4 |
| YOLOv5n | 42.8 | 32.0 | 32.3 | 18.2 | 2.2 | 96.6 | 5.8 | |
| YOLOv6n | 39.8 | 31.2 | 30.3 | 17.5 | 4.2 | 97.8 | 11.8 | |
| YOLOv8n | 44.2 | 31.9 | 32.4 | 19.0 | 3.0 | 101.5 | 8.1 | |
| YOLOv8-Ghostp2 | 44.0 | 32.3 | 32.6 | 18.8 | 1.6 | 66.8 | 7.3 | |
| YOLOv9t | 44.0 | 33.1 | 33.3 | 19.3 | 2.0 | 71.8 | 7.6 | |
| YOLOv10n | 43.0 | 32.4 | 32.5 | 18.7 | 2.7 | 70.2 | 8.2 | |
| YOLOv11n | 42.7 | 33.0 | 32.9 | 18.8 | 2.6 | 82.3 | 6.3 | |
| YOLOv12n | 41.7 | 31.4 | 30.9 | 17.8 | 2.5 | 46.7 | 6.0 | |
| DLSRF-Net | 49.9 | 38.1 | 40.1 | 24.2 | 2.8 | 109.8 | 11.9 | |
| M | YOLOv8s | 49.5 | 36.9 | 37.8 | 22.6 | 11.2 | 98.6 | 28.5 |
| YOLOv9s | 50.0 | 38.7 | 39.4 | 23.4 | 7.2 | 36.7 | 26.7 | |
| YOLOv10s | 48.0 | 37.5 | 37.9 | 22.5 | 8.1 | 68.9 | 24.5 | |
| YOLOv11s | 48.2 | 37.7 | 37.9 | 22.7 | 9.4 | 79.6 | 21.3 | |
| YOLOv12s | 48.5 | 36.8 | 36.9 | 22.0 | 9.1 | 47.8 | 19.3 | |
| RT-DETR | 54.4 | 42.7 | 45.3 | 27.5 | 19.8 | 44.8 | 36.7 | |
| DLSRF-Net | 60.1 | 45.6 | 47.3 | 28.6 | 7.1 | 103.1 | 25.5 |
在模型尺寸为N的类别中,所提算法在P、R、mAP50和mAP50-90指标上均达到了最好的效果,相较于基础模型YOLOv11n分别提升了7.2、5.1、7.2和5.4个百分点. 虽然YOLOv8-Ghostp2在这些优秀算法中参数量最低,但是其检测性能仍然有待提高. 在模型尺寸为M的类别中,所提算法的各项指标均取得了最好的效果,相较于基础模型YOLOv11s,P、R、mAP50和mAP50-90指标分别提升了11.9、7.9、9.4、5.9个百分点. 虽然所提方法在N和M尺寸下FLOP指标均略有增加,但是其FPS指标优于其他优秀算法,在参数量、计算量、检测精度和检测速度之间达到了平衡. 此外,所提算法的整体性能超越了参数量巨大的RT-DETR算法,而参数量仅为RT-DETR的35.9%. 综上所述,所提算法在提升对小目标感受野特征的提取能力的同时,能够增强对小目标的关注度,有效整合上下文信息,抑制无用信息;实验结果验证了所提算法对复杂场景中无人机视角下小目标检测的有效性,在基础尺寸和稍大尺寸的模型中都取得了较好的性能.
2.5. 实验可视化结果
图 6
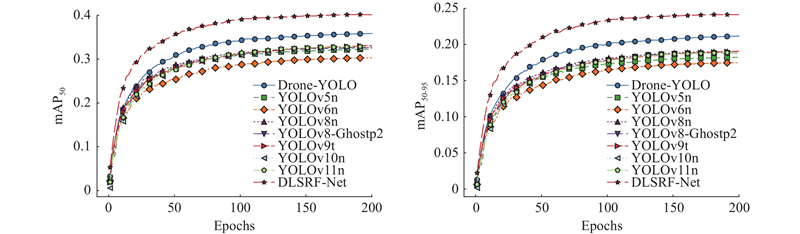
图 6 N类别下不同模型的mAP50和mAP50-90对比
Fig.6 Comparison of mAP50 and mAP50-90 of different models under N category
图 7
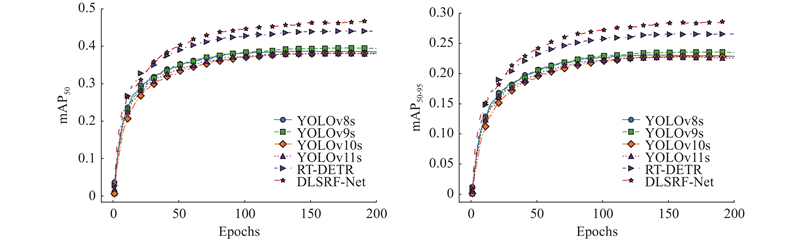
图 7 M类别下不同模型的mAP50和mAP50-90对比
Fig.7 Comparison of mAP50 and mAP50-90 of different models under M category
为了直观地比较模型对VisDrone2021数据集中每一类目标的检测精度提升效果,基于模型尺寸为N和M的基础模型与所提模型的检测结果,绘制分类目标的精度对比图,如图8所示. 在N和M模型尺寸下,所提算法对VisDrone2021数据集中每一类目标的检测精度均有提升,尤其对行人、自行车、摩托车等微小目标的检测精度提升幅度较大,说明了所提算法对小目标检测的有效性.
图 8
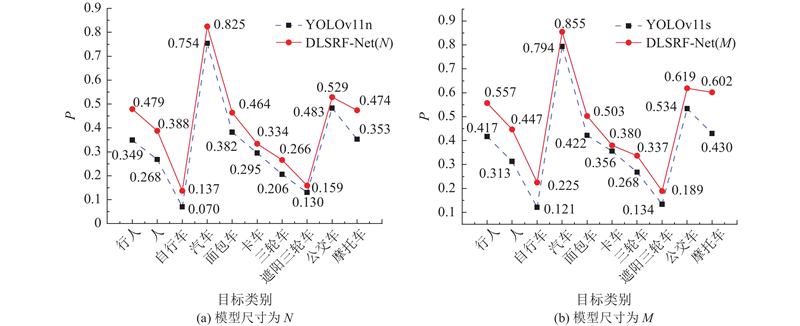
图 8 不同模型尺寸下所提模型与基准模型对VisDrone2021数据集中各类目标的检测精度对比
Fig.8 Comparison of detection precision of proposed model and baseline under model sizes for various targets in VisDrone2021 dataset
图 9

图 9 基准模型与所提模型的热图生成结果对比
Fig.9 Comparison of heatmap generation results of benchmark model and proposed model
2.6. 泛化能力验证
为了验证所提方法在其他无人机视角的小目标数据集上的泛化能力,选取DOTA和SSDD数据集开展实验. 其中,DOTA数据集中的无人机航拍图像来自不同传感器和平台,包含16个类别的不同大小、方向和形状的物体;SSDD数据集中的图像涉及多种不同的海况、光照条件、舰船类型及尺寸. 将2个数据集按照模型尺寸N和M分别进行实验,结果如表3所示. 对于DOTA数据集,改进后的模型在P、R、mAP50和mAP50-90指标上提升较为明显. 对于SSDD数据集,改进后的模型在FPS上提升较为明显. 由实验结果可得,在不同的模型尺寸下,所提算法在2个数据集上的检测性能都优于其他先进算法. 相较于基线模型YOLOv11,改进方法在2种模型尺寸下对2个数据集进行检测的各项指标均有不同程度的提升,证明了改进方法的泛化能力.
表 3 模型在DOTA、SSDD数据集上的泛化实验结果
Tab.3
| 数据集 | 模型尺寸 | 模型 | P/% | R/% | mAP50/% | mAP50-90/% | Np/106 | FPS/(帧·s−1) | FLOP/(109·s−1) |
| DOTA | N | YOLOv10n | 55.7 | 34.0 | 35.0 | 20.9 | 2.7 | 62.7 | 8.2 |
| YOLOv11n | 64.6 | 35.8 | 38.3 | 22.9 | 2.5 | 77.1 | 6.3 | ||
| YOLOv12n | 65.1 | 35.5 | 37.3 | 22.1 | 2.5 | 49.3 | 6.0 | ||
| DLSRF-Net | 66.2 | 39.6 | 42.9 | 24.9 | 2.8 | 99.3 | 11.9 | ||
| M | YOLOv10s | 61.7 | 37.6 | 39.7 | 24.0 | 8.1 | 62.5 | 24.5 | |
| YOLOv11s | 69.5 | 39.3 | 43.3 | 26.5 | 9.4 | 70.4 | 21.3 | ||
| YOLOv12s | 68.9 | 39.7 | 44.2 | 25.9 | 9.1 | 48.8 | 19.3 | ||
| DLSRF-Net | 71.7 | 42.2 | 46.2 | 28.3 | 7.1 | 94.6 | 25.2 | ||
| SSDD | N | YOLOv10n | 94.9 | 92.7 | 97.2 | 72.2 | 2.7 | 61.1 | 8.2 |
| YOLOv11n | 95.9 | 93.4 | 98.1 | 72.2 | 2.6 | 75.2 | 6.3 | ||
| YOLOv12n | 96.6 | 92.7 | 97.4 | 71.0 | 2.5 | 50.3 | 6.0 | ||
| DLSRF-Net | 97.9 | 95.6 | 98.7 | 74.8 | 2.8 | 101.7 | 11.9 | ||
| M | YOLOv10s | 94.2 | 94.9 | 98.1 | 74.1 | 8.1 | 62.4 | 24.5 | |
| YOLOv11s | 95.7 | 95.4 | 98.2 | 74.6 | 9.4 | 80.3 | 21.3 | ||
| YOLOv12s | 97.1 | 94.3 | 98.3 | 74.2 | 9.1 | 49.8 | 19.3 | ||
| DLSRF-Net | 98.1 | 96.7 | 98.9 | 74.6 | 7.1 | 99.6 | 25.5 |
3. 结 语
针对无人机视角下目标尺寸小、背景复杂导致检测过程中特征提取困难的问题,提出面向复杂环境、无人机视角下的目标检测算法DLSRF-Net. 首先,通过设计DSRFAConv来增大模型的感受野,提升模型对小目标的检测能力并降低模型计算量. 其次,设计多分支轻量化多尺度线性注意力机制,提升模型对小目标的关注度. 最后,设计RSCDI模块,最大限度地保留特征信息,突出小目标的关键特征,抑制无效信息. 将模型尺寸分为N和M,以应对不同的检测需求. 在N类尺寸下,mAP50和mAP50-90分别达到了40.1%和24.2%,相较于同类尺寸的基准网络分别提升了7.2、5.4个百分点. 在M类尺寸下mAP50和mAP50-90分别达到了47.3%和28.6%,相较于同类尺寸的基准网络分别提升了9.4、5.9个百分点. 经过实验验证,在N和M尺寸下,所提模型相较于基准模型均取得了较大提升;尤其在M尺寸下,所提模型以较少的参数量(7.1×106)达到了超过参数量巨大(19.8×106)的RT-DETR的性能. 除此之外,使用DOTA和SSDD数据集进行泛化实验,经验证,所提方法对无人机视角下的小目标检测具有良好的泛化性能. 综上所述,所提方法对无人机视角下的小目标具有较好的检测效果,在参数量较少的情况下达到了良好的检测性能. 未来的优化方向是更轻量化的设计和检测速度的进一步提升,以便将模型部署在轻量型无人机上,更好地适应低空经济发展背景下的各类无人机应用场景.
参考文献
基于深度学习的EEG数据分析技术综述
[J].
Survey of deep learning based EEG data analysis technology
[J].
Faster R-CNN: towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031 [本文引用: 1]
基于改进YOLOv5s的无人机小目标检测算法
[J].
UAV small target detection algorithm based on improved YOLOv5s
[J].
基于YOLOv5s的无人机密集小目标检测算法
[J].
UAV dense small target detection algorithm based on YOLOv5s
[J].
基于SM-YOLOv8n的无人机航拍目标检测
[J].
UAV aerial target detection based on SM-YOLOv8n
[J].
Ldstd: low-altitude drone aerial small target detector
[J].DOI:10.1007/s11227-025-06950-3 [本文引用: 1]
Design of UAV target detection network based on deep feature fusion and optimization with small targets in complex contexts
[J].DOI:10.1016/j.neucom.2025.130207 [本文引用: 1]
A lightweight multidimensional feature network for small object detection on UAVs
[J].DOI:10.1007/s10044-024-01389-3 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}