[1]
KO H, LEE S, PARK Y, et al A survey of recommendation systems: recommendation models, techniques, and application fields
[J]. Electronics , 2022 , 11 (1 ): 141
DOI:10.3390/electronics11010141
[本文引用: 1]
[2]
秦川, 祝恒书, 庄福振, 等 基于知识图谱的推荐系统研究综述[J]. 中国科学: 信息科学, 2020, 50(7): 937–956.
[本文引用: 5]
QIN Chuan, ZHU Hengshu, ZHUANG Fuzhen, et al. A survey on knowledge graph-based recommender systems [J]. Scientia Sinica: Informationis , 2020, 50(7): 937–956.
[本文引用: 5]
[3]
ABDUL HUSSIEN F T, RAHMA A M S, ABDUL WAHAB H B Recommendation systems for E-commerce systems an overview
[J]. Journal of Physics: Conference Series , 2021 , 1897 (1 ): 12024
DOI:10.1088/1742-6596/1897/1/012024
[本文引用: 1]
[4]
DELDJOO Y, SCHEDL M, CREMONESI P, et al Recommender systems leveraging multimedia content
[J]. ACM Computing Surveys , 2021 , 53 (5 ): 1 - 38
[本文引用: 1]
[5]
郭向星, 周魏, 杨正益, 等 基于自监督图卷积和注意力机制实现隐式反馈降噪的社交推荐
[J]. 电子学报 , 2025 , 53 (1 ): 151 - 162
[本文引用: 1]
GUO Xiangxing, ZHOU Wei, YANG Zhengyi, et al Denoising implicit feedback with self-supervised graph convolution network and attention mechanism for social recommendation
[J]. Acta Electronica Sinica , 2025 , 53 (1 ): 151 - 162
[本文引用: 1]
[6]
王文虎, 张德祥, 李晓鹏 基于移动互联网的大型仪器设备推荐系统的研究
[J]. 信息与电脑: 理论版 , 2021 , 33 (20 ): 128 - 132
[本文引用: 1]
WANG Wenhu, ZHANG Dexiang, LI Xiaopeng Research on large-scale instrument and equipment recommendation system based on mobile Internet
[J]. China Computer & Communication , 2021 , 33 (20 ): 128 - 132
[本文引用: 1]
[8]
SEDHAIN S, MENON A K, SANNER S, et al. AutoRec: autoencoders meet collaborative filtering [C]// Proceedings of the 24th International Conference on World Wide Web . Florence: ACM, 2015: 111–112.
[本文引用: 1]
[9]
CHEN J, ZHANG H, HE X, et al. Attentive collaborative filtering: multimedia recommendation with item-and component-level attention [C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval . Tokyo: ACM, 2017: 335–344.
[10]
HE X, DENG K, WANG X, et al. LightGCN: simplifying and powering graph convolution network for recommendation [C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval . [S.l.]: ACM, 2020: 639–648.
[本文引用: 2]
[11]
WU L, HE X, WANG X, et al A survey on accuracy-oriented neural recommendation: from collaborative filtering to information-rich recommendation
[J]. IEEE Transactions on Knowledge and Data Engineering , 2023 , 35 (5 ): 4425 - 4445
[本文引用: 1]
[12]
HUANG C, XU H, XU Y, et al. Knowledge-aware coupled graph neural network for social recommendation [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence . [S.l.]: AAAI Press, 2021: 4115–4122.
[本文引用: 1]
[13]
赵晔辉, 柳林, 王海龙, 等 知识图谱推荐系统研究综述
[J]. 计算机科学与探索 , 2023 , 17 (4 ): 771 - 791
DOI:10.3778/j.issn.1673-9418.2205052
[本文引用: 2]
ZHAO Yehui, LIU Lin, WANG Hailong, et al Survey of knowledge graph recommendation system research
[J]. Journal of Frontiers of Computer Science and Technology , 2023 , 17 (4 ): 771 - 791
DOI:10.3778/j.issn.1673-9418.2205052
[本文引用: 2]
[14]
SANG L, XU M, QIAN S, et al Knowledge graph enhanced neural collaborative recommendation
[J]. Expert Systems with Applications , 2021 , 164 : 113992
DOI:10.1016/j.eswa.2020.113992
[本文引用: 1]
[15]
BORDES A, USUNIER N, GARCIA-DURÁN A, et al. Translating embeddings for modeling multi-relational data [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Lake Tahoe: Curran Associates Inc, 2013: 2787–2795.
[本文引用: 1]
[16]
YU X, REN X, SUN Y, et al. Personalized entity recommendation: a heterogeneous information network approach [C]// Proceedings of the 7th ACM International Conference on Web Search and Data Mining . New York: ACM, 2014: 283–292.
[本文引用: 2]
[17]
HU B, SHI C, ZHAO W X, et al. Leveraging meta-path based context for top-N recommendation with a neural co-attention model [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . London: ACM, 2018: 1531–1540.
[本文引用: 1]
[18]
ZHAO H, YAO Q, LI J, et al. Meta-graph based recommendation fusion over heterogeneous information networks [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Halifax: ACM, 2017: 635–644.
[本文引用: 1]
[19]
HUANG L, GUAN C R, HUANG Z W, et al Broad recommender system: an efficient nonlinear collaborative filtering approach
[J]. IEEE Transactions on Emerging Topics in Computational Intelligence , 2024 , 8 (4 ): 2843 - 2857
DOI:10.1109/TETCI.2024.3378599
[本文引用: 1]
[20]
YANG D, GUO Z, WANG Z, et al. A knowledge-enhanced deep recommendation framework incorporating GAN-based models [C]// Proceedings of the IEEE International Conference on Data Mining . Singapore: IEEE, 2018: 1368–1373.
[21]
DONG Y, CHAWLA N V, SWAMI A. Metapath2vec: scalable representation learning for heterogeneous networks [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Halifax: ACM, 2017: 135–144.
[22]
WANG H, ZHANG F, WANG J, et al. RippleNet: propagating user preferences on the knowledge graph for recommender systems [C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management . Torino: ACM, 2018: 417–426.
[23]
MA W, ZHANG M, CAO Y, et al. Jointly learning explainable rules for recommendation with knowledge graph [C]// Proceedings of the World Wide Web Conference . San Francisco: ACM, 2019: 1210–1221.
[本文引用: 1]
[24]
GAO C, ZHENG Y, LI N, et al A survey of graph neural networks for recommender systems: challenges, methods, and directions
[J]. ACM Transactions on Recommender Systems , 2023 , 1 (1 ): 1 - 51
[本文引用: 1]
[25]
WANG H, ZHAO M, XIE X, et al. Knowledge graph convolutional networks for recommender systems [C]// Proceedings of the World Wide Web Conference . San Francisco: ACM, 2019: 3307–3313.
[本文引用: 2]
[26]
WANG X, HE X, CAO Y, et al. KGAT: knowledge graph attention network for recommendation [C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . Anchorage: ACM, 2019: 950–958.
[本文引用: 4]
[27]
WANG X, HUANG T, WANG D, et al. Learning intents behind interactions with knowledge graph for recommendation [C]// Proceedings of the Web Conference 2021 . Ljubljana: ACM, 2021: 878–887.
[本文引用: 5]
[28]
WANG Z, LIN G, TAN H, et al. CKAN: collaborative knowledge-aware attentive network for recommender systems [C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval . [S.l.]: ACM, 2020: 219–228.
[本文引用: 4]
[29]
HU J, HOOI B, QIAN S, et al MGDCF: distance learning via Markov graph diffusion for neural collaborative filtering
[J]. IEEE Transactions on Knowledge and Data Engineering , 2024 , 36 (7 ): 3281 - 3296
DOI:10.1109/TKDE.2023.3348537
[本文引用: 4]
[30]
MA T, HUANG L, LU Q, et al KR-GCN: knowledge-aware reasoning with graph convolution network for explainable recommendation
[J]. ACM Transactions on Information Systems , 2023 , 41 (1 ): 1 - 27
[本文引用: 1]
[31]
YU J, YIN H, XIA X, et al Self-supervised learning for recommender systems: a survey
[J]. IEEE Transactions on Knowledge and Data Engineering , 2024 , 36 (1 ): 335 - 355
DOI:10.1109/TKDE.2023.3282907
[本文引用: 1]
[32]
YANG Y, HUANG C, XIA L, et al. Knowledge graph contrastive learning for recommendation [C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval . Madrid: ACM, 2022: 1434–1443.
[本文引用: 5]
[33]
WU J, WANG X, FENG F, et al. Self-supervised graph learning for recommendation [C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval . [S.l.]: ACM, 2021: 726–735.
[本文引用: 1]
[34]
XIE X, SUN F, LIU Z, et al. Contrastive learning for sequential recommendation [C]// Proceedings of the IEEE 38th International Conference on Data Engineering . Kuala Lumpur: IEEE, 2022: 1259–1273.
[本文引用: 2]
[35]
XIA L, HUANG C, XU Y, et al. Hypergraph contrastive collaborative filtering [C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval . Madrid: ACM, 2022: 70–79.
[本文引用: 1]
[36]
LIN Z, TIAN C, HOU Y, et al. Improving graph collaborative filtering with neighborhood-enriched contrastive learning [C]// Proceedings of the ACM Web Conference . Lyon: ACM, 2022: 2320–2329.
[本文引用: 1]
[37]
YU J, XIA X, CHEN T, et al XSimGCL: towards extremely simple graph contrastive learning for recommendation
[J]. IEEE Transactions on Knowledge and Data Engineering , 2024 , 36 (2 ): 913 - 926
[本文引用: 1]
A survey of recommendation systems: recommendation models, techniques, and application fields
1
2022
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
5
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... [2 ,13 ],从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... [2 ,16 -17 ]为代表的方法. ...
... 基于知识图谱的推荐方法主要包括3类:基于路径的方法、基于嵌入的方法和基于图神经网络的方法. 基于路径的方法[16 -18 ] 通过提取知识图谱中的元路径来挖掘实体间的潜在关联性,从而推断用户偏好. 但是该方法通常高度依赖于特定的元路径定义,且难以提取知识图谱中的高阶语义信息.基于嵌入的方法[2 ,19 -23 ] 主要利用知识图谱来获得实体向量表示,以丰富用户或物品的语义表征并发掘用户偏好,生成既高效又具备可解释性的推荐结果. ...
5
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... [2 ,13 ],从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... [2 ,16 -17 ]为代表的方法. ...
... 基于知识图谱的推荐方法主要包括3类:基于路径的方法、基于嵌入的方法和基于图神经网络的方法. 基于路径的方法[16 -18 ] 通过提取知识图谱中的元路径来挖掘实体间的潜在关联性,从而推断用户偏好. 但是该方法通常高度依赖于特定的元路径定义,且难以提取知识图谱中的高阶语义信息.基于嵌入的方法[2 ,19 -23 ] 主要利用知识图谱来获得实体向量表示,以丰富用户或物品的语义表征并发掘用户偏好,生成既高效又具备可解释性的推荐结果. ...
Recommendation systems for E-commerce systems an overview
1
2021
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
Recommender systems leveraging multimedia content
1
2021
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
基于自监督图卷积和注意力机制实现隐式反馈降噪的社交推荐
1
2025
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
基于自监督图卷积和注意力机制实现隐式反馈降噪的社交推荐
1
2025
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
基于移动互联网的大型仪器设备推荐系统的研究
1
2021
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
基于移动互联网的大型仪器设备推荐系统的研究
1
2021
... 随着互联网的快速发展,数据量呈爆炸式增长,用户面临着严重的信息过载问题. 如何从海量信息中筛选出用户感兴趣的需求内容,已成为当前在线信息平台亟待解决的难题. 推荐系统作为解决信息过载并提高用户体验的关键技术,得到了国内外学者的广泛关注[1 -2 ] . 推荐系统旨在利用机器学习、数据挖掘和人工智能技术,根据用户历史行为、偏好和上下文信息,帮助用户过滤掉不相关的信息,自动匹配用户可能感兴趣的内容或服务. 该技术被广泛应用于电子商务[3 ] 、个性化广告[4 ] 、社交媒体[5 ] 以及仪器设备等创新资源推荐[6 ] 等众多领域,极大地提升了用户体验和平台的商业价值. ...
Federated neural collaborative filtering
1
2022
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
1
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
2
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... 为了对用户和物品节点进行有效编码,模型采用高效且轻量级的图神经网络LightGCN作为编码器,学习用户-项目交互图的节点表征. 该模型的消息传递过程[10 ] 定义为 ...
A survey on accuracy-oriented neural recommendation: from collaborative filtering to information-rich recommendation
1
2023
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
1
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
知识图谱推荐系统研究综述
2
2023
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
知识图谱推荐系统研究综述
2
2023
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
Knowledge graph enhanced neural collaborative recommendation
1
2021
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
1
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
2
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
... 基于知识图谱的推荐方法主要包括3类:基于路径的方法、基于嵌入的方法和基于图神经网络的方法. 基于路径的方法[16 -18 ] 通过提取知识图谱中的元路径来挖掘实体间的潜在关联性,从而推断用户偏好. 但是该方法通常高度依赖于特定的元路径定义,且难以提取知识图谱中的高阶语义信息.基于嵌入的方法[2 ,19 -23 ] 主要利用知识图谱来获得实体向量表示,以丰富用户或物品的语义表征并发掘用户偏好,生成既高效又具备可解释性的推荐结果. ...
1
... 推荐系统的核心是个性化推荐算法. 目前常用的推荐算法主要包括基于协同过滤的推荐、基于内容的推荐和混合推荐3类[2 ] . 其中,协同过滤算法[7 ] 从相似性度量出发,利用用户历史行为数据对用户进行建模以预测用户的偏好,因而在推荐领域中被广泛应用. 近年来,协同过滤技术从矩阵分解转向神经网络实体嵌入[8 -10 ] ,但是仍然面临数据稀疏性的挑战[11 ] . 为此,知识图谱(knowledge graph, KG)作为辅助信息被整合到推荐系统中,通过编码项目间的语义相关性来增强用户和项目表示[12 ] . 大量基于知识图谱的推荐方法涌现出来[2 ,13 ] ,从早期的基于转换的实体嵌入方法(如TransE[14 ] 、TransR[15 ] )逐步发展到了以基于路径的模型[2 ,16 -17 ] 为代表的方法. ...
1
... 基于知识图谱的推荐方法主要包括3类:基于路径的方法、基于嵌入的方法和基于图神经网络的方法. 基于路径的方法[16 -18 ] 通过提取知识图谱中的元路径来挖掘实体间的潜在关联性,从而推断用户偏好. 但是该方法通常高度依赖于特定的元路径定义,且难以提取知识图谱中的高阶语义信息.基于嵌入的方法[2 ,19 -23 ] 主要利用知识图谱来获得实体向量表示,以丰富用户或物品的语义表征并发掘用户偏好,生成既高效又具备可解释性的推荐结果. ...
Broad recommender system: an efficient nonlinear collaborative filtering approach
1
2024
... 基于知识图谱的推荐方法主要包括3类:基于路径的方法、基于嵌入的方法和基于图神经网络的方法. 基于路径的方法[16 -18 ] 通过提取知识图谱中的元路径来挖掘实体间的潜在关联性,从而推断用户偏好. 但是该方法通常高度依赖于特定的元路径定义,且难以提取知识图谱中的高阶语义信息.基于嵌入的方法[2 ,19 -23 ] 主要利用知识图谱来获得实体向量表示,以丰富用户或物品的语义表征并发掘用户偏好,生成既高效又具备可解释性的推荐结果. ...
1
... 基于知识图谱的推荐方法主要包括3类:基于路径的方法、基于嵌入的方法和基于图神经网络的方法. 基于路径的方法[16 -18 ] 通过提取知识图谱中的元路径来挖掘实体间的潜在关联性,从而推断用户偏好. 但是该方法通常高度依赖于特定的元路径定义,且难以提取知识图谱中的高阶语义信息.基于嵌入的方法[2 ,19 -23 ] 主要利用知识图谱来获得实体向量表示,以丰富用户或物品的语义表征并发掘用户偏好,生成既高效又具备可解释性的推荐结果. ...
A survey of graph neural networks for recommender systems: challenges, methods, and directions
1
2023
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
2
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
... [25 ]将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
4
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
... 1) KGAT[26 ] :该模型设计了知识感知协作图注意力机制,可以在传播过程中区分相邻节点之间的相关性. ...
... Performance comparison of recommendation algorithms based on Recall@
K metrics
Tab.2 模型 Recall@10 Recall@20 Recall@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.036 5 0.089 2 0.051 8 0.067 5 0.139 0 0.090 7 0.082 7 0.163 8 0.120 3 KGIN[27 ] 0.043 5 0.106 2 0.065 2 0.071 2 0.143 6 0.104 4 0.094 9 0.177 4 0.134 3 CKAN[28 ] 0.039 1 0.087 8 0.059 7 0.068 9 0.138 0 0.099 1 0.085 3 0.162 2 0.128 5 KGCL[32 ] 0.045 5 0.098 9 0.067 6 0.075 6 0.149 6 0.107 3 0.099 9 0.179 5 0.135 9 MGDCF[29 ] 0.041 2 0.104 6 0.067 1 0.079 1 0.155 0 0.106 6 0.102 9 0.181 3 0.136 9 本研究方法 0.051 9 0.115 2 0.071 9 0.085 8 0.169 1 0.115 1 0.112 3 0.203 7 0.141 2
表 3 基于NDCG@K 指标的推荐算法性能比较 ...
... Performance comparison of recommendation algorithms based on NDCG@
K metrics
Tab.3 模型 NDCG@10 NDCG@20 NDCG@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.035 7 0.061 5 0.031 7 0.043 2 0.073 9 0.044 2 0.051 8 0.081 5 0.051 6 KGIN[27 ] 0.036 8 0.062 4 0.039 5 0.046 2 0.074 8 0.052 7 0.053 4 0.082 9 0.059 1 CKAN[28 ] 0.036 4 0.060 8 0.036 8 0.044 1 0.072 0 0.049 9 0.052 6 0.081 2 0.056 5 KGCL[32 ] 0.038 5 0.063 2 0.042 5 0.049 3 0.079 3 0.055 1 0.057 3 0.087 4 0.062 0 MGDCF[29 ] 0.035 1 0.068 5 0.042 2 0.051 6 0.083 1 0.056 4 0.061 8 0.091 2 0.062 4 本研究方法 0.044 1 0.074 8 0.055 1 0.056 3 0.091 9 0.070 1 0.065 0 0.100 6 0.077 3
由表2 可以看出,在3个基准数据集上,所提方法的召回率Recall@10、Recall@20、Recall@30相对于KGAT模型分别平均提高了36.7%、25.2%和25.8%,且所提方法的性能始终优于其他基于图神经网络的基线模型. 在基于知识图谱的推荐方法中,KGCL模型的表现也相当具有竞争力. 这归因于KGCL利用对比学习方法增强了知识图谱的嵌入表示,进而提升了推荐效果. 但是KGCL的表现仍然不如直接作用于用户交互图的对比学习方法,这是由于知识图谱本身包含较多噪声,直接使用知识图谱的不同视图进行对比学习存在一定的局限性. 因此,所提方法克服了这一缺陷,有效提升了性能. ...
5
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
... 对于推荐任务,采用贝叶斯个性化排名(BPR)损失[27 ] 作为推荐损失函数: ...
... 4) KGIN[27 ] :该模型是增强的知识图谱感知推荐模型,旨在识别用户的潜在意图,并利用关系路径感知聚合机制进一步聚合用户意图-项目元组和知识图谱三元组之间的关系路径. ...
... Performance comparison of recommendation algorithms based on Recall@
K metrics
Tab.2 模型 Recall@10 Recall@20 Recall@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.036 5 0.089 2 0.051 8 0.067 5 0.139 0 0.090 7 0.082 7 0.163 8 0.120 3 KGIN[27 ] 0.043 5 0.106 2 0.065 2 0.071 2 0.143 6 0.104 4 0.094 9 0.177 4 0.134 3 CKAN[28 ] 0.039 1 0.087 8 0.059 7 0.068 9 0.138 0 0.099 1 0.085 3 0.162 2 0.128 5 KGCL[32 ] 0.045 5 0.098 9 0.067 6 0.075 6 0.149 6 0.107 3 0.099 9 0.179 5 0.135 9 MGDCF[29 ] 0.041 2 0.104 6 0.067 1 0.079 1 0.155 0 0.106 6 0.102 9 0.181 3 0.136 9 本研究方法 0.051 9 0.115 2 0.071 9 0.085 8 0.169 1 0.115 1 0.112 3 0.203 7 0.141 2
表 3 基于NDCG@K 指标的推荐算法性能比较 ...
... Performance comparison of recommendation algorithms based on NDCG@
K metrics
Tab.3 模型 NDCG@10 NDCG@20 NDCG@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.035 7 0.061 5 0.031 7 0.043 2 0.073 9 0.044 2 0.051 8 0.081 5 0.051 6 KGIN[27 ] 0.036 8 0.062 4 0.039 5 0.046 2 0.074 8 0.052 7 0.053 4 0.082 9 0.059 1 CKAN[28 ] 0.036 4 0.060 8 0.036 8 0.044 1 0.072 0 0.049 9 0.052 6 0.081 2 0.056 5 KGCL[32 ] 0.038 5 0.063 2 0.042 5 0.049 3 0.079 3 0.055 1 0.057 3 0.087 4 0.062 0 MGDCF[29 ] 0.035 1 0.068 5 0.042 2 0.051 6 0.083 1 0.056 4 0.061 8 0.091 2 0.062 4 本研究方法 0.044 1 0.074 8 0.055 1 0.056 3 0.091 9 0.070 1 0.065 0 0.100 6 0.077 3
由表2 可以看出,在3个基准数据集上,所提方法的召回率Recall@10、Recall@20、Recall@30相对于KGAT模型分别平均提高了36.7%、25.2%和25.8%,且所提方法的性能始终优于其他基于图神经网络的基线模型. 在基于知识图谱的推荐方法中,KGCL模型的表现也相当具有竞争力. 这归因于KGCL利用对比学习方法增强了知识图谱的嵌入表示,进而提升了推荐效果. 但是KGCL的表现仍然不如直接作用于用户交互图的对比学习方法,这是由于知识图谱本身包含较多噪声,直接使用知识图谱的不同视图进行对比学习存在一定的局限性. 因此,所提方法克服了这一缺陷,有效提升了性能. ...
4
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
... 2) CKAN[28 ] :该模型通过协作传播明确编码协作信号,并将其与知识关联信息相结合,以解决基于知识图谱的推荐系统中的稀疏性和冷启动问题. ...
... Performance comparison of recommendation algorithms based on Recall@
K metrics
Tab.2 模型 Recall@10 Recall@20 Recall@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.036 5 0.089 2 0.051 8 0.067 5 0.139 0 0.090 7 0.082 7 0.163 8 0.120 3 KGIN[27 ] 0.043 5 0.106 2 0.065 2 0.071 2 0.143 6 0.104 4 0.094 9 0.177 4 0.134 3 CKAN[28 ] 0.039 1 0.087 8 0.059 7 0.068 9 0.138 0 0.099 1 0.085 3 0.162 2 0.128 5 KGCL[32 ] 0.045 5 0.098 9 0.067 6 0.075 6 0.149 6 0.107 3 0.099 9 0.179 5 0.135 9 MGDCF[29 ] 0.041 2 0.104 6 0.067 1 0.079 1 0.155 0 0.106 6 0.102 9 0.181 3 0.136 9 本研究方法 0.051 9 0.115 2 0.071 9 0.085 8 0.169 1 0.115 1 0.112 3 0.203 7 0.141 2
表 3 基于NDCG@K 指标的推荐算法性能比较 ...
... Performance comparison of recommendation algorithms based on NDCG@
K metrics
Tab.3 模型 NDCG@10 NDCG@20 NDCG@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.035 7 0.061 5 0.031 7 0.043 2 0.073 9 0.044 2 0.051 8 0.081 5 0.051 6 KGIN[27 ] 0.036 8 0.062 4 0.039 5 0.046 2 0.074 8 0.052 7 0.053 4 0.082 9 0.059 1 CKAN[28 ] 0.036 4 0.060 8 0.036 8 0.044 1 0.072 0 0.049 9 0.052 6 0.081 2 0.056 5 KGCL[32 ] 0.038 5 0.063 2 0.042 5 0.049 3 0.079 3 0.055 1 0.057 3 0.087 4 0.062 0 MGDCF[29 ] 0.035 1 0.068 5 0.042 2 0.051 6 0.083 1 0.056 4 0.061 8 0.091 2 0.062 4 本研究方法 0.044 1 0.074 8 0.055 1 0.056 3 0.091 9 0.070 1 0.065 0 0.100 6 0.077 3
由表2 可以看出,在3个基准数据集上,所提方法的召回率Recall@10、Recall@20、Recall@30相对于KGAT模型分别平均提高了36.7%、25.2%和25.8%,且所提方法的性能始终优于其他基于图神经网络的基线模型. 在基于知识图谱的推荐方法中,KGCL模型的表现也相当具有竞争力. 这归因于KGCL利用对比学习方法增强了知识图谱的嵌入表示,进而提升了推荐效果. 但是KGCL的表现仍然不如直接作用于用户交互图的对比学习方法,这是由于知识图谱本身包含较多噪声,直接使用知识图谱的不同视图进行对比学习存在一定的局限性. 因此,所提方法克服了这一缺陷,有效提升了性能. ...
MGDCF: distance learning via Markov graph diffusion for neural collaborative filtering
4
2024
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
... 5) MGDCF[29 ] :该模型将GNN简化为马尔可夫过程,通过马尔可夫过程平衡节点间的距离,进而构建图模型的上下文特征. ...
... Performance comparison of recommendation algorithms based on Recall@
K metrics
Tab.2 模型 Recall@10 Recall@20 Recall@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.036 5 0.089 2 0.051 8 0.067 5 0.139 0 0.090 7 0.082 7 0.163 8 0.120 3 KGIN[27 ] 0.043 5 0.106 2 0.065 2 0.071 2 0.143 6 0.104 4 0.094 9 0.177 4 0.134 3 CKAN[28 ] 0.039 1 0.087 8 0.059 7 0.068 9 0.138 0 0.099 1 0.085 3 0.162 2 0.128 5 KGCL[32 ] 0.045 5 0.098 9 0.067 6 0.075 6 0.149 6 0.107 3 0.099 9 0.179 5 0.135 9 MGDCF[29 ] 0.041 2 0.104 6 0.067 1 0.079 1 0.155 0 0.106 6 0.102 9 0.181 3 0.136 9 本研究方法 0.051 9 0.115 2 0.071 9 0.085 8 0.169 1 0.115 1 0.112 3 0.203 7 0.141 2
表 3 基于NDCG@K 指标的推荐算法性能比较 ...
... Performance comparison of recommendation algorithms based on NDCG@
K metrics
Tab.3 模型 NDCG@10 NDCG@20 NDCG@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.035 7 0.061 5 0.031 7 0.043 2 0.073 9 0.044 2 0.051 8 0.081 5 0.051 6 KGIN[27 ] 0.036 8 0.062 4 0.039 5 0.046 2 0.074 8 0.052 7 0.053 4 0.082 9 0.059 1 CKAN[28 ] 0.036 4 0.060 8 0.036 8 0.044 1 0.072 0 0.049 9 0.052 6 0.081 2 0.056 5 KGCL[32 ] 0.038 5 0.063 2 0.042 5 0.049 3 0.079 3 0.055 1 0.057 3 0.087 4 0.062 0 MGDCF[29 ] 0.035 1 0.068 5 0.042 2 0.051 6 0.083 1 0.056 4 0.061 8 0.091 2 0.062 4 本研究方法 0.044 1 0.074 8 0.055 1 0.056 3 0.091 9 0.070 1 0.065 0 0.100 6 0.077 3
由表2 可以看出,在3个基准数据集上,所提方法的召回率Recall@10、Recall@20、Recall@30相对于KGAT模型分别平均提高了36.7%、25.2%和25.8%,且所提方法的性能始终优于其他基于图神经网络的基线模型. 在基于知识图谱的推荐方法中,KGCL模型的表现也相当具有竞争力. 这归因于KGCL利用对比学习方法增强了知识图谱的嵌入表示,进而提升了推荐效果. 但是KGCL的表现仍然不如直接作用于用户交互图的对比学习方法,这是由于知识图谱本身包含较多噪声,直接使用知识图谱的不同视图进行对比学习存在一定的局限性. 因此,所提方法克服了这一缺陷,有效提升了性能. ...
KR-GCN: knowledge-aware reasoning with graph convolution network for explainable recommendation
1
2023
... 图神经网络(graph neural network, GNN)[24 ] 作为新兴的图表示学习技术备受关注. 基于GNN的推荐方法通常利用图中多跳节点,以递归方式执行信息传播并捕获长距离关系,来推断用户对特定物品的偏好,典型模型包括KGCN[25 ] 、KGAT[26 ] 和KGIN[27 ] 等. 其主要优势在于:能够通过显式反馈(如评分)和隐式反馈(如浏览历史)建模用户和物品之间的交互,同时捕捉物品之间的相似性及用户社交关系. Wang等[25 ] 将图卷积网络(GCN)扩展到知识图谱推荐系统中,提出知识图谱卷积模型KGCN,通过聚合知识图谱中的项目邻域信息来更新项目特征表示并扩展用户的长期偏好. 为了突出用户-项目交互中的协作信号,Wang等[28 ] 提出协作知识感知注意力模型,通过异构传播策略结合协作信号与知识关联,以提高推荐系统的性能. Hu等[29 ] 将GCN等价为Markov过程,提出Markov图扩散协同过滤模型来泛化基于GCN的推荐模型. 为了提高推荐性能并保证解释的多样性,Ma等[30 ] 提出将用户-项目交互图和知识图谱集成到异质图中,并利用GCN进行实体表征学习,解决了知识图中多跳路径可能导致的错误传播问题. 该类方法结合了基于路径和基于嵌入的方法的优点,在推荐系统中能够进行更精准的个性化推荐. 图神经网络提升了知识图谱推荐的质量和可解释性,但是其有效性依赖于高质量的知识图谱,且容易受到噪声干扰[13 ] . 在真实场景中,知识图谱往往是稀疏且充满噪声的,表现为长尾实体分布. 此外,基于图神经网络的推荐模型大多采用监督学习范式,通常需要大量标记数据进行模型训练. ...
Self-supervised learning for recommender systems: a survey
1
2024
... 对于监督信号稀缺的问题,自监督学习技术是一种高效的解决方案[31 ] . 在推荐系统中,自监督对比学习可以通过对比正、负样本对来学习用户和物品的嵌入表示,并通过最大化正样本对之间的相似性并最小化负样本对之间的相似性,学习到更加具有区分性的嵌入表示. 基于对比式自监督学习的推荐模型[32 -34 ] 通过预设自监督任务学习数据内在的监督信号,提升推荐系统的性能和泛化能力. 例如,Wu等[33 ] 采用节点丢弃、边丢弃及随机游走等多种图增强策略来生成用户-项目图的多个视图,通过最大化目标节点的不同视图间的一致性来增强实体嵌入表示. 类似地,Xie等[34 ] 提出3种不同的数据增强方法,包括裁剪、掩码和重排,以构建用户序列的不同视图,并将对比学习模型引入序列推荐任务. ...
5
... 对于监督信号稀缺的问题,自监督学习技术是一种高效的解决方案[31 ] . 在推荐系统中,自监督对比学习可以通过对比正、负样本对来学习用户和物品的嵌入表示,并通过最大化正样本对之间的相似性并最小化负样本对之间的相似性,学习到更加具有区分性的嵌入表示. 基于对比式自监督学习的推荐模型[32 -34 ] 通过预设自监督任务学习数据内在的监督信号,提升推荐系统的性能和泛化能力. 例如,Wu等[33 ] 采用节点丢弃、边丢弃及随机游走等多种图增强策略来生成用户-项目图的多个视图,通过最大化目标节点的不同视图间的一致性来增强实体嵌入表示. 类似地,Xie等[34 ] 提出3种不同的数据增强方法,包括裁剪、掩码和重排,以构建用户序列的不同视图,并将对比学习模型引入序列推荐任务. ...
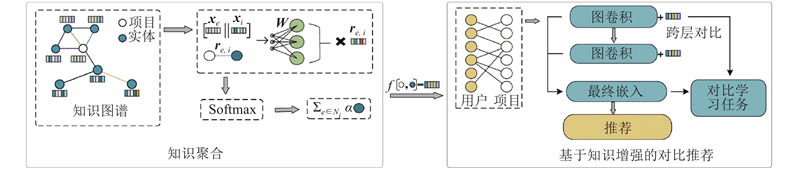
... 式中:$ {\boldsymbol{x}}_{i}\in {\mathbf{R}}^{d} $ $ {\boldsymbol{x}}_{e}\in {\mathbf{R}}^{d} $ i 和实体e 的嵌入向量,$ {\boldsymbol{r}}_{e,i} $ $ {N}_{i} $ i 在知识图谱G 中相邻实体的集合,$ \alpha (e,{\boldsymbol{r}}_{e,i},i) $ $ \alpha (e,{\boldsymbol{r}}_{e,i},i) $ $ {\boldsymbol{W}}\in {\mathbf{R}}^{d\times 2d} $ [32 ] . 最后,将得到的向量乘以$ {\boldsymbol{r}}_{e,i}^{\mathrm{T}} $
... 3) KGCL[32 ] :该模型通过降低知识图谱噪声和改进知识感知表示来提高推荐系统的质量. ...
... Performance comparison of recommendation algorithms based on Recall@
K metrics
Tab.2 模型 Recall@10 Recall@20 Recall@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.036 5 0.089 2 0.051 8 0.067 5 0.139 0 0.090 7 0.082 7 0.163 8 0.120 3 KGIN[27 ] 0.043 5 0.106 2 0.065 2 0.071 2 0.143 6 0.104 4 0.094 9 0.177 4 0.134 3 CKAN[28 ] 0.039 1 0.087 8 0.059 7 0.068 9 0.138 0 0.099 1 0.085 3 0.162 2 0.128 5 KGCL[32 ] 0.045 5 0.098 9 0.067 6 0.075 6 0.149 6 0.107 3 0.099 9 0.179 5 0.135 9 MGDCF[29 ] 0.041 2 0.104 6 0.067 1 0.079 1 0.155 0 0.106 6 0.102 9 0.181 3 0.136 9 本研究方法 0.051 9 0.115 2 0.071 9 0.085 8 0.169 1 0.115 1 0.112 3 0.203 7 0.141 2
表 3 基于NDCG@K 指标的推荐算法性能比较 ...
... Performance comparison of recommendation algorithms based on NDCG@
K metrics
Tab.3 模型 NDCG@10 NDCG@20 NDCG@30 Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND Yelp2018 Amazon-Book MIND KGAT[26 ] 0.035 7 0.061 5 0.031 7 0.043 2 0.073 9 0.044 2 0.051 8 0.081 5 0.051 6 KGIN[27 ] 0.036 8 0.062 4 0.039 5 0.046 2 0.074 8 0.052 7 0.053 4 0.082 9 0.059 1 CKAN[28 ] 0.036 4 0.060 8 0.036 8 0.044 1 0.072 0 0.049 9 0.052 6 0.081 2 0.056 5 KGCL[32 ] 0.038 5 0.063 2 0.042 5 0.049 3 0.079 3 0.055 1 0.057 3 0.087 4 0.062 0 MGDCF[29 ] 0.035 1 0.068 5 0.042 2 0.051 6 0.083 1 0.056 4 0.061 8 0.091 2 0.062 4 本研究方法 0.044 1 0.074 8 0.055 1 0.056 3 0.091 9 0.070 1 0.065 0 0.100 6 0.077 3
由表2 可以看出,在3个基准数据集上,所提方法的召回率Recall@10、Recall@20、Recall@30相对于KGAT模型分别平均提高了36.7%、25.2%和25.8%,且所提方法的性能始终优于其他基于图神经网络的基线模型. 在基于知识图谱的推荐方法中,KGCL模型的表现也相当具有竞争力. 这归因于KGCL利用对比学习方法增强了知识图谱的嵌入表示,进而提升了推荐效果. 但是KGCL的表现仍然不如直接作用于用户交互图的对比学习方法,这是由于知识图谱本身包含较多噪声,直接使用知识图谱的不同视图进行对比学习存在一定的局限性. 因此,所提方法克服了这一缺陷,有效提升了性能. ...
1
... 对于监督信号稀缺的问题,自监督学习技术是一种高效的解决方案[31 ] . 在推荐系统中,自监督对比学习可以通过对比正、负样本对来学习用户和物品的嵌入表示,并通过最大化正样本对之间的相似性并最小化负样本对之间的相似性,学习到更加具有区分性的嵌入表示. 基于对比式自监督学习的推荐模型[32 -34 ] 通过预设自监督任务学习数据内在的监督信号,提升推荐系统的性能和泛化能力. 例如,Wu等[33 ] 采用节点丢弃、边丢弃及随机游走等多种图增强策略来生成用户-项目图的多个视图,通过最大化目标节点的不同视图间的一致性来增强实体嵌入表示. 类似地,Xie等[34 ] 提出3种不同的数据增强方法,包括裁剪、掩码和重排,以构建用户序列的不同视图,并将对比学习模型引入序列推荐任务. ...
2
... 对于监督信号稀缺的问题,自监督学习技术是一种高效的解决方案[31 ] . 在推荐系统中,自监督对比学习可以通过对比正、负样本对来学习用户和物品的嵌入表示,并通过最大化正样本对之间的相似性并最小化负样本对之间的相似性,学习到更加具有区分性的嵌入表示. 基于对比式自监督学习的推荐模型[32 -34 ] 通过预设自监督任务学习数据内在的监督信号,提升推荐系统的性能和泛化能力. 例如,Wu等[33 ] 采用节点丢弃、边丢弃及随机游走等多种图增强策略来生成用户-项目图的多个视图,通过最大化目标节点的不同视图间的一致性来增强实体嵌入表示. 类似地,Xie等[34 ] 提出3种不同的数据增强方法,包括裁剪、掩码和重排,以构建用户序列的不同视图,并将对比学习模型引入序列推荐任务. ...
... [34 ]提出3种不同的数据增强方法,包括裁剪、掩码和重排,以构建用户序列的不同视图,并将对比学习模型引入序列推荐任务. ...
1
... 图随机增强策略可能会丢弃重要信息,加剧不活跃用户的数据稀疏问题. 因此,一些基于对比学习的推荐系统替代方案,如HCCF[35 ] 和NCL[36 ] ,设计启发式策略来构建嵌入对比的视图. 尽管上述方法有效,但是在很大程度上依赖于视图生成器,难以适应不同的推荐任务. 此外,Yu等[37 ] 深入分析对比学习中的多种数据增强策略,发现优化对比损失的过程是影响对比推荐模型性能的关键,而非图结构增强,进而提出基于噪声增强的对比推荐模型. 然而,随机噪声的引入可能会对推荐系统的鲁棒性产生不利影响. ...
1
... 图随机增强策略可能会丢弃重要信息,加剧不活跃用户的数据稀疏问题. 因此,一些基于对比学习的推荐系统替代方案,如HCCF[35 ] 和NCL[36 ] ,设计启发式策略来构建嵌入对比的视图. 尽管上述方法有效,但是在很大程度上依赖于视图生成器,难以适应不同的推荐任务. 此外,Yu等[37 ] 深入分析对比学习中的多种数据增强策略,发现优化对比损失的过程是影响对比推荐模型性能的关键,而非图结构增强,进而提出基于噪声增强的对比推荐模型. 然而,随机噪声的引入可能会对推荐系统的鲁棒性产生不利影响. ...
XSimGCL: towards extremely simple graph contrastive learning for recommendation
1
2024
... 图随机增强策略可能会丢弃重要信息,加剧不活跃用户的数据稀疏问题. 因此,一些基于对比学习的推荐系统替代方案,如HCCF[35 ] 和NCL[36 ] ,设计启发式策略来构建嵌入对比的视图. 尽管上述方法有效,但是在很大程度上依赖于视图生成器,难以适应不同的推荐任务. 此外,Yu等[37 ] 深入分析对比学习中的多种数据增强策略,发现优化对比损失的过程是影响对比推荐模型性能的关键,而非图结构增强,进而提出基于噪声增强的对比推荐模型. 然而,随机噪声的引入可能会对推荐系统的鲁棒性产生不利影响. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}