[1]
于明鑫, 王长龙, 张玉华, 等 复杂环境下视觉目标跟踪研究现状及发展
[J]. 航空兵器 , 2024 , 31 (3 ): 40 - 50
DOI:10.12132/ISSN.1673-5048.2023.0112
[本文引用: 1]
YU Mingxin, WANG Changlong, ZHANG Yuhua, et al Survey of visual tracking algorithms in the complex scenarios
[J]. Aero Weaponry , 2024 , 31 (3 ): 40 - 50
DOI:10.12132/ISSN.1673-5048.2023.0112
[本文引用: 1]
[2]
侯志强, 赵佳鑫, 陈语, 等 用于长时视觉跟踪的级联目标漂移判定网络
[J]. 北京航空航天大学学报 , 2025 , 51 (7 ): 2240 - 2252
[本文引用: 1]
HOU Zhiqiang, ZHAO Jiaxin, CHEN Yu, et al Cascaded object drift determination network for long-term visual tracking
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2025 , 51 (7 ): 2240 - 2252
[本文引用: 1]
[3]
马庆禄, 王伟, 孙枭, 等 隧道火灾的视觉跟踪算法
[J]. 东南大学学报: 自然科学版 , 2025 , 55 (1 ): 255 - 265
[本文引用: 1]
MA Qinglu, WANG Wei, SUN Xiao, et al Visual tracking algorithm for tunnel fire
[J]. Journal of Southeast University: Natural Science Edition , 2025 , 55 (1 ): 255 - 265
[本文引用: 1]
[4]
魏超, 吴西涛, 朱耿霆, 等 基于视觉相机和激光雷达融合的无人车障碍物检测与跟踪研究
[J]. 机械工程学报 , 2025 , 61 (2 ): 296 - 309
[本文引用: 1]
WEI Chao, WU Xitao, ZHU Gengting, et al Research on obstacle detection and tracking of autonomous vehicles based on the fusion of vision camera and LiDAR
[J]. Journal of Mechanical Engineering , 2025 , 61 (2 ): 296 - 309
[本文引用: 1]
[5]
DANELLJAN M, HÄGER G, KHAN F S, et al. Convolutional features for correlation filter based visual tracking [C]// Proceedings of the IEEE International Conference on Computer Vision Workshop . Santiago: IEEE, 2015: 621–629.
[本文引用: 1]
[6]
DANELLJAN M, HÄGER G, KHAN F S, et al. Learning spatially regularized correlation filters for visual tracking [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 4310–4318.
[本文引用: 1]
[7]
BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional Siamese networks for object tracking [C]// Proceedings of the European Conference on Computer Vision . Amsterdam: Springer, 2016: 850–865.
[本文引用: 1]
[8]
CHEN X, YAN B, ZHU J, et al. Transformer tracking [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8122–8131.
[本文引用: 1]
[9]
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 1316–1324.
[本文引用: 1]
[10]
ZHU M, ZHANG H, ZHANG J, et al Multi-level prediction Siamese network for real-time UAV visual tracking
[J]. Image and Vision Computing , 2020 , 103 : 104002
DOI:10.1016/j.imavis.2020.104002
[本文引用: 1]
[11]
YUAN Y, WANG D, WANG Q. Memory-augmented temporal dynamic learning for action recognition [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Honolulu: AAAI Press, 2019: 9167–9175.
[本文引用: 1]
[12]
WANG Q, ZHANG L, BERTINETTO L, et al. Fast online object tracking and segmentation: a unifying approach [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1328–1338.
[本文引用: 1]
[13]
LI B, YAN J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8971–8980.
[本文引用: 1]
[14]
YE B, CHANG H, MA B, et al. Joint feature learning and relation modeling for tracking: a one-stream framework [C]// Proceedings of the European Conference on Computer Vision . Tel Aviv: Springer, 2022: 341–357.
[本文引用: 1]
[15]
YU Y, XIONG Y, HUANG W, et al. Deformable Siamese attention networks for visual object tracking [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 6727–6736.
[本文引用: 2]
[16]
雷帮军, 丁奇帅, 牟乾西, 等. 基于模板更新和双特征增强的视觉跟踪算法[J/OL]. 北京航空航天大学学报, 2024: 1–15. (2024-02-27). https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0020.
[本文引用: 1]
LEI Bangjun, DING Qishuai, MOU Qianxi, et al. Visual tracking algorithm based on template updating and dual feature enhancement [J/OL]. Journal of Beijing University of Aeronautics and Astronautics , 2024: 1–15. (2024-02-27). https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0020.
[本文引用: 1]
[17]
黄煜杰, 陈凯, 王子源, 等 多目视觉下基于融合特征的密集行人跟踪方法
[J]. 北京航空航天大学学报 , 2025 , 51 (7 ): 2513 - 2525
[本文引用: 1]
HUANG Yujie, CHEN Kai, WANG Ziyuan, et al A dense pedestrian tracking method based on fusion features under multi-vision
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2025 , 51 (7 ): 2513 - 2525
[本文引用: 1]
[18]
侯志强, 王卓, 马素刚, 等 长时视觉跟踪中基于双模板Siamese结构的目标漂移判定网络
[J]. 电子与信息学报 , 2024 , 46 (4 ): 1458 - 1467
DOI:10.11999/JEIT230496
[本文引用: 1]
HOU Zhiqiang, WANG Zhuo, MA Sugang, et al Target drift discriminative network based on dual-template Siamese structure in long-term tracking
[J]. Journal of Electronics & Information Technology , 2024 , 46 (4 ): 1458 - 1467
DOI:10.11999/JEIT230496
[本文引用: 1]
[19]
侯志强, 陈茂林, 马靖媛, 等 基于二阶注意力的Siamese网络视觉跟踪算法
[J]. 北京航空航天大学学报 , 2024 , 50 (3 ): 739 - 747
[本文引用: 1]
HOU Zhiqiang, CHEN Maolin, MA Jingyuan, et al Siamese network visual tracking algorithm based on second-order attention
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2024 , 50 (3 ): 739 - 747
[本文引用: 1]
[20]
罗彪, 欧阳志华, 易昕宁, 等 基于自适应动态规划的移动机器人视觉伺服跟踪控制
[J]. 自动化学报 , 2023 , 49 (11 ): 2286 - 2296
[本文引用: 1]
LUO Biao, OUYANG Zhihua, YI Xinning, et al Adaptive dynamic programming based visual servoing tracking control for mobile robots
[J]. Acta Automatica Sinica , 2023 , 49 (11 ): 2286 - 2296
[本文引用: 1]
[21]
侯志强, 马靖媛, 韩若雪, 等 基于深度学习的快速长时视觉跟踪算法
[J]. 北京航空航天大学学报 , 2024 , 50 (8 ): 2391 - 2403
[本文引用: 1]
HOU Zhiqiang, MA Jingyuan, HAN Ruoxue, et al A fast long-term visual tracking algorithm based on deep learning
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2024 , 50 (8 ): 2391 - 2403
[本文引用: 1]
[22]
华夏, 王新晴, 芮挺, 等 视觉感知的无人机端到端目标跟踪控制技术
[J]. 浙江大学学报: 工学版 , 2022 , 56 (7 ): 1464 - 1472
[本文引用: 1]
HUA Xia, WANG Xinqing, RUI Ting, et al Vision-driven end-to-end maneuvering object tracking of UAV
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (7 ): 1464 - 1472
[本文引用: 1]
[23]
甘耀东, 郑玲, 张志达, 等. 融合毫米波雷达与深度视觉的多目标检测与跟踪[J]. 汽车工程, 2021, 43(7): 1022–1029.
[本文引用: 1]
GAN Yaodong, ZHENG Ling, ZHANG Zhida, et al. Multi-target detection and tracking with fusion of millimeter-wave radar and deep vision [J]. Automotive Engineering , 2021, 43(7): 1022–1029.
[本文引用: 1]
[24]
仇祝令, 查宇飞, 吴敏, 等 基于注意力学习的正则化相关滤波跟踪算法
[J]. 电子学报 , 2020 , 48 (9 ): 1762 - 1768
DOI:10.3969/j.issn.0372-2112.2020.09.014
[本文引用: 1]
QIU Zhuling, ZHA Yufei, WU Min, et al Learning attentional regularized correlation filter for visual tracking
[J]. Acta Electronica Sinica , 2020 , 48 (9 ): 1762 - 1768
DOI:10.3969/j.issn.0372-2112.2020.09.014
[本文引用: 1]
[25]
FAN H, LIN L, YANG F, et al. LaSOT: a high-quality benchmark for large-scale single object tracking [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5369–5378.
[本文引用: 1]
[26]
HUANG L, ZHAO X, HUANG K GOT-10k: a large high-diversity benchmark for generic object tracking in the wild
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (5 ): 1562 - 1577
DOI:10.1109/TPAMI.2019.2957464
[本文引用: 1]
[27]
WU Y, LIM J, YANG M H. Online object tracking: a benchmark [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Portland: IEEE, 2013: 2411–2418.
[本文引用: 1]
[28]
CAI W, LIU Q, WANG Y. HIPTrack: visual tracking with historical prompts [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 19258–19267.
[本文引用: 2]
[29]
XIE J, ZHONG B, MO Z, et al. Autoregressive queries for adaptive tracking with spatio-temporal transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 19300–19309.
[本文引用: 1]
[30]
ZHENG Y, ZHONG B, LIANG Q, et al ODTrack: online dense temporal token learning for visual tracking
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2024 , 38 (7 ): 7588 - 7596
DOI:10.1609/aaai.v38i7.28591
[本文引用: 1]
[31]
LIN L, FAN H, ZHANG Z, et al. Tracking meets LoRA: faster training, larger model, stronger performance [C]//Proceedings of the European Conference on Computer Vision . Milan: Springer, 2024: 300–318.
[本文引用: 1]
[32]
LI B, WU W, WANG Q, et al. SiamRPN: evolution of Siamese visual tracking with very deep networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4277–4286.
[本文引用: 1]
[33]
DANELLJAN M, VAN GOOL L, TIMOFTE R. Probabilistic regression for visual tracking [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 7181–7190.
[本文引用: 1]
复杂环境下视觉目标跟踪研究现状及发展
1
2024
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
复杂环境下视觉目标跟踪研究现状及发展
1
2024
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
用于长时视觉跟踪的级联目标漂移判定网络
1
2025
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
用于长时视觉跟踪的级联目标漂移判定网络
1
2025
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
隧道火灾的视觉跟踪算法
1
2025
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
隧道火灾的视觉跟踪算法
1
2025
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
基于视觉相机和激光雷达融合的无人车障碍物检测与跟踪研究
1
2025
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
基于视觉相机和激光雷达融合的无人车障碍物检测与跟踪研究
1
2025
... 视觉目标跟踪(visual object tracking, VOT)技术在智能驾驶领域具有重要的应用价值,其核心目标是通过摄像头捕获的视频序列,基于初始目标(如车辆、行人或障碍物的边界框)实时追踪目标在后续帧中的运动轨迹[1 ] . 面向汽车场景的VOT技术可以分为3类:基于判别模型的车辆运动预测、基于生成模型的动态目标特征建模,以及基于深度学习的协同跟踪[2 ] . 在复杂交通场景中,例如城市道路中密集车流高速交互、隧道出入口处光照突变等,现有算法容易出现目标丢失或轨迹漂移的问题[3 -4 ] . 因此,需要研发面向智能驾驶场景的鲁棒视觉跟踪模型,该模型须具备抗遮挡能力和运动突变适应能力,从而确保自动驾驶系统在动态交通环境中的感知可靠性和决策实时性. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
Multi-level prediction Siamese network for real-time UAV visual tracking
1
2020
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
1
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
2
... 近年来,基于深度学习的视觉跟踪方法得到了快速发展. Danelljan等[5 ] 结合浅层卷积特征与SRDCF跟踪模型[6 ] 提出DeepSRDCF跟踪算法,结合深度学习和稀疏相关判别滤波器,实现了更强的特征表达能力和高效的目标匹配,但是仍然无法很好地处理长时间的目标遮挡和快速运动导致的遮挡问题. Bertinetto等[7 ] 提出SiamFC算法,基于孪生神经网络架构实现了高效的视觉跟踪,但是该方法在长时间的目标跟踪中容易受到背景干扰的影响. Chen等[8 ] 提出TransT算法,采用Transformer架构增强全局上下文建模能力,但是计算复杂度显著增加. Xu等[9 ] 提出AttnGAN算法,采用注意力机制优化目标特征的提取,使得模型更加关注目标的关键区域,但是在多目标跟踪任务中存在计算资源消耗过多的问题. Zhu等[10 ] 提出层级化互相关结构,融合多尺度特征以增强尺度鲁棒性,然而计算量随着层级数线性增长. 针对复杂遮挡场景,Yuan等[11 ] 引入记忆增强模块存储历史目标特征,通过注意力机制实现动态模板更新,但是长期记忆容易引入噪声干扰. Wang等[12 ] 提出联合跟踪与分割的算法SiamMask,提升了目标边界定位精度,然而该方法在目标快速运动时依然存在跟踪漂移现象. Li等[13 ] 提出SiamRPN系列算法,引入区域建议网络实现端到端检测与跟踪联合优化,能够在大量标注数据上学习到适合目标跟踪的特征表示,且能够应对目标被部分遮挡时的跟踪任务,但是在目标被完全遮挡的场景中性能下降. Ye等[14 ] 提出OSTrack算法,采用无解码器架构提升推理速度,结合在线学习和长短时网络,根据新的视频帧来自适应更新模型,但是当目标出现变形、与历史特征有较大差异时,算法会出现跟踪失误和目标丢失的情况. Yu等[15 ] 提出动态卷积核生成策略,通过目标感知的特征调制提升匹配精度,但未考虑背景干扰的影响,当背景与目标相似时容易出现漏检的问题. 现有算法对目标遮挡、变形等方面有相关研究,但是仅针对目标被部分遮挡和变形程度不大的情况,对于目标被完全遮挡和目标变形特征与历史特征不一致的情况,上述算法会出现跟踪不到的问题. ...
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
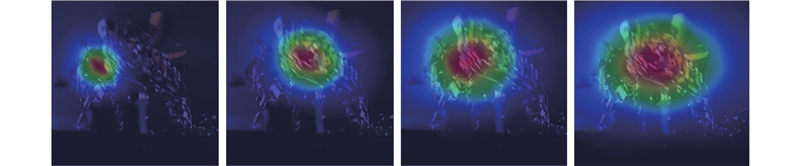
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...
1
... 综上所述,当目标被遮挡、变形或者快速移动时,跟踪目标的特征会发生较大变化,甚至出现零样本画面,即目标被完全遮挡并短暂地从画面中消失[16 ] . 现有的视觉跟踪模型倾向于优先考虑外观相似性而非空间和时间的一致性,忽略了运动线索,会使得后续帧的掩码预测不准确,从而导致跟踪错误[17 ] . 为此提出零样本视觉跟踪模型,该模型考虑空间和时间的一致性,结合目标物体运动线索和历史特征信息,能够在目标被遮挡、变形等低质量场景中进行精准预测,减少预测失误. 针对其他方法运算复杂度高的问题,为了优化计算复杂度,设计轻量化记忆库,通过先进先出(first in first out, FIFO)队列限制历史帧数,显著降低存储与检索开销,并通过并行计算构建混合评分系统;在记忆交叉注意力模块中,采用稀疏注意力机制,以减少冗余计算. ...
1
... 综上所述,当目标被遮挡、变形或者快速移动时,跟踪目标的特征会发生较大变化,甚至出现零样本画面,即目标被完全遮挡并短暂地从画面中消失[16 ] . 现有的视觉跟踪模型倾向于优先考虑外观相似性而非空间和时间的一致性,忽略了运动线索,会使得后续帧的掩码预测不准确,从而导致跟踪错误[17 ] . 为此提出零样本视觉跟踪模型,该模型考虑空间和时间的一致性,结合目标物体运动线索和历史特征信息,能够在目标被遮挡、变形等低质量场景中进行精准预测,减少预测失误. 针对其他方法运算复杂度高的问题,为了优化计算复杂度,设计轻量化记忆库,通过先进先出(first in first out, FIFO)队列限制历史帧数,显著降低存储与检索开销,并通过并行计算构建混合评分系统;在记忆交叉注意力模块中,采用稀疏注意力机制,以减少冗余计算. ...
多目视觉下基于融合特征的密集行人跟踪方法
1
2025
... 综上所述,当目标被遮挡、变形或者快速移动时,跟踪目标的特征会发生较大变化,甚至出现零样本画面,即目标被完全遮挡并短暂地从画面中消失[16 ] . 现有的视觉跟踪模型倾向于优先考虑外观相似性而非空间和时间的一致性,忽略了运动线索,会使得后续帧的掩码预测不准确,从而导致跟踪错误[17 ] . 为此提出零样本视觉跟踪模型,该模型考虑空间和时间的一致性,结合目标物体运动线索和历史特征信息,能够在目标被遮挡、变形等低质量场景中进行精准预测,减少预测失误. 针对其他方法运算复杂度高的问题,为了优化计算复杂度,设计轻量化记忆库,通过先进先出(first in first out, FIFO)队列限制历史帧数,显著降低存储与检索开销,并通过并行计算构建混合评分系统;在记忆交叉注意力模块中,采用稀疏注意力机制,以减少冗余计算. ...
多目视觉下基于融合特征的密集行人跟踪方法
1
2025
... 综上所述,当目标被遮挡、变形或者快速移动时,跟踪目标的特征会发生较大变化,甚至出现零样本画面,即目标被完全遮挡并短暂地从画面中消失[16 ] . 现有的视觉跟踪模型倾向于优先考虑外观相似性而非空间和时间的一致性,忽略了运动线索,会使得后续帧的掩码预测不准确,从而导致跟踪错误[17 ] . 为此提出零样本视觉跟踪模型,该模型考虑空间和时间的一致性,结合目标物体运动线索和历史特征信息,能够在目标被遮挡、变形等低质量场景中进行精准预测,减少预测失误. 针对其他方法运算复杂度高的问题,为了优化计算复杂度,设计轻量化记忆库,通过先进先出(first in first out, FIFO)队列限制历史帧数,显著降低存储与检索开销,并通过并行计算构建混合评分系统;在记忆交叉注意力模块中,采用稀疏注意力机制,以减少冗余计算. ...
长时视觉跟踪中基于双模板Siamese结构的目标漂移判定网络
1
2024
... 无人驾驶车辆在处理视觉目标跟踪任务时,在目标快速移动或出现变形以及长短时遮挡的复杂场景中,尤其是在拥挤场景中面对快速移动或被遮挡的物体时,会出现目标丢失的情况[18 ] . 考虑到下一帧图像的预测质量,将时间运动线索与运动感知记忆选择机制相结合,创建理想掩码记忆库,调节记忆特征的质量. 针对低质量场景下的预测任务,利用运动线索并结合历史线索,动态选择最合适的掩码,有效预测目标的未来运动,实现复杂跟踪场景下稳定、准确的跟踪,提高模型在动态环境中的适应性. 图1 为零样本视觉跟踪模型的流程图. ...
长时视觉跟踪中基于双模板Siamese结构的目标漂移判定网络
1
2024
... 无人驾驶车辆在处理视觉目标跟踪任务时,在目标快速移动或出现变形以及长短时遮挡的复杂场景中,尤其是在拥挤场景中面对快速移动或被遮挡的物体时,会出现目标丢失的情况[18 ] . 考虑到下一帧图像的预测质量,将时间运动线索与运动感知记忆选择机制相结合,创建理想掩码记忆库,调节记忆特征的质量. 针对低质量场景下的预测任务,利用运动线索并结合历史线索,动态选择最合适的掩码,有效预测目标的未来运动,实现复杂跟踪场景下稳定、准确的跟踪,提高模型在动态环境中的适应性. 图1 为零样本视觉跟踪模型的流程图. ...
基于二阶注意力的Siamese网络视觉跟踪算法
1
2024
... 在零样本视觉跟踪模型中,记忆注意力模块对输入图像提取高层次特征,捕捉图像中的关键信息,如边缘、纹理、形状等. 记忆注意力模块首先利用帧嵌入执行自注意力机制[19 ] ,然后在图像嵌入和记忆库内容之间执行交叉注意力机制,处理跨帧的上下文信息,以维持长期跟踪. 因此,无条件的图像嵌入会与之前的输出掩码、输入提示和对象指针联系起来. 在记忆解码器中,将记忆注意力层产生的记忆条件图像嵌入和原始图像的稀疏提示符(如点、边界框)作为输入,生成1组掩码、相应的掩码亲和力得分和目标出现分数. 对于第1帧$ {t}_{0} $ $ {\boldsymbol{M}}_{t-1} $
基于二阶注意力的Siamese网络视觉跟踪算法
1
2024
... 在零样本视觉跟踪模型中,记忆注意力模块对输入图像提取高层次特征,捕捉图像中的关键信息,如边缘、纹理、形状等. 记忆注意力模块首先利用帧嵌入执行自注意力机制[19 ] ,然后在图像嵌入和记忆库内容之间执行交叉注意力机制,处理跨帧的上下文信息,以维持长期跟踪. 因此,无条件的图像嵌入会与之前的输出掩码、输入提示和对象指针联系起来. 在记忆解码器中,将记忆注意力层产生的记忆条件图像嵌入和原始图像的稀疏提示符(如点、边界框)作为输入,生成1组掩码、相应的掩码亲和力得分和目标出现分数. 对于第1帧$ {t}_{0} $ $ {\boldsymbol{M}}_{t-1} $
基于自适应动态规划的移动机器人视觉伺服跟踪控制
1
2023
... 式中:$ {\boldsymbol{C}} $ $ {\boldsymbol{M}}_{i} $ ( $i\in \mathbf{Z} $ ) 为生成的掩码,掩码指示每个像素是否属于某个特定的物体或类别,其中1表示该像素属于目标区域,0表示不属于目标区域;$ {s}_{\mathrm{m}\mathrm{a}\mathrm{s}\mathrm{k}} $ [20 ] ,通过交叉熵损失进行监督,判断掩码是否出现在帧中. ...
基于自适应动态规划的移动机器人视觉伺服跟踪控制
1
2023
... 式中:$ {\boldsymbol{C}} $ $ {\boldsymbol{M}}_{i} $ ( $i\in \mathbf{Z} $ ) 为生成的掩码,掩码指示每个像素是否属于某个特定的物体或类别,其中1表示该像素属于目标区域,0表示不属于目标区域;$ {s}_{\mathrm{m}\mathrm{a}\mathrm{s}\mathrm{k}} $ [20 ] ,通过交叉熵损失进行监督,判断掩码是否出现在帧中. ...
基于深度学习的快速长时视觉跟踪算法
1
2024
... 在零样本视觉跟踪框架中,使用基于卡尔曼滤波的方法增强边界框的位置和维度,预测目标的运动,从而在拥挤、目标快速移动或变形、被遮挡等复杂场景中提高跟踪的准确性和鲁棒性[21 ] . 因此,在经典卡尔曼滤波的基础上进行改进,建立混合评分系统,包含多掩码选择的运动建模、亲和力分数、目标出现分数和KF-IoU运动分数. 对于基于卡尔曼滤波的运动建模,考虑历史运动线索,并结合该混合评分系统,从预测掩码M n 个候选者中选出置信度最高的掩码,提高模型在复杂视频场景中准确跟踪目标的能力. 将状态向量X
基于深度学习的快速长时视觉跟踪算法
1
2024
... 在零样本视觉跟踪框架中,使用基于卡尔曼滤波的方法增强边界框的位置和维度,预测目标的运动,从而在拥挤、目标快速移动或变形、被遮挡等复杂场景中提高跟踪的准确性和鲁棒性[21 ] . 因此,在经典卡尔曼滤波的基础上进行改进,建立混合评分系统,包含多掩码选择的运动建模、亲和力分数、目标出现分数和KF-IoU运动分数. 对于基于卡尔曼滤波的运动建模,考虑历史运动线索,并结合该混合评分系统,从预测掩码M n 个候选者中选出置信度最高的掩码,提高模型在复杂视频场景中准确跟踪目标的能力. 将状态向量X
视觉感知的无人机端到端目标跟踪控制技术
1
2022
... 式中:x 、y 为边界框的中心坐标,w 、h 分别为边界框的宽度和高度,$ \dot{x}\mathrm{、}\dot{y}、\dot{w}\mathrm{、}\dot{h} $ x 分量)、纵坐标变化率(即速度的y 分量)、边界框宽度变化率、边界框高度变化率[22 ] . ...
视觉感知的无人机端到端目标跟踪控制技术
1
2022
... 式中:x 、y 为边界框的中心坐标,w 、h 分别为边界框的宽度和高度,$ \dot{x}\mathrm{、}\dot{y}、\dot{w}\mathrm{、}\dot{h} $ x 分量)、纵坐标变化率(即速度的y 分量)、边界框宽度变化率、边界框高度变化率[22 ] . ...
1
... 对于每个掩码的状态向量,卡尔曼滤波器在预测-更新循环中运行[23 ] : ...
1
... 对于每个掩码的状态向量,卡尔曼滤波器在预测-更新循环中运行[23 ] : ...
基于注意力学习的正则化相关滤波跟踪算法
1
2020
... 式中:$ {\boldsymbol{z}}_{t} $ $ {\boldsymbol{K}}_{t} $ H [24 ] . 此外,为了确保运动模型跟踪的准确性,只有当跟踪目标在过去的$ {N}_{\mathrm{m}\mathrm{a}\mathrm{x}} $
基于注意力学习的正则化相关滤波跟踪算法
1
2020
... 式中:$ {\boldsymbol{z}}_{t} $ $ {\boldsymbol{K}}_{t} $ H [24 ] . 此外,为了确保运动模型跟踪的准确性,只有当跟踪目标在过去的$ {N}_{\mathrm{m}\mathrm{a}\mathrm{x}} $
1
... LaSOT数据集[25 ] 包含大约1 400个视频序列,总共有超过1 400 000帧的标注数据,涵盖了70多种不同的场景和目标类型. 视频中的目标包括人物、动物、车辆等,展示了多样的目标外观变化、运动模式以及遮挡情况,适合用于研究目标遮挡、变化等对跟踪算法的挑战. ...
GOT-10k: a large high-diversity benchmark for generic object tracking in the wild
1
2021
... GOT-10k数据集[26 ] 包含约10 000个视频序列,涉及大约560个不同的物体类别,从常见物体到复杂物体,种类丰富. 数据集包含广泛的场景,涵盖室内和室外环境、不同的光照条件、目标姿态以及尺度变化、遮挡、背景复杂等情况. ...
1
... OTB100数据集[27 ] 包含100个视频序列. 这些视频具有多个不同的来源和背景,涵盖大量的现实场景和多样的目标类型,目标的运动、形态背景等特点在不同视频中均不相同. 此外,该数据集中有平稳运动、快速运动以及目标局部变形、部分遮挡、完全遮挡等情况. ...
2
... 实验代码基于Pytorch框架开发,模型编程语言为Python. 用于训练和测试的实验平台搭载NVIDIA GeForce GTX 4060 Ti显卡和酷睿i5-12490F CPU. 在多个数据集上定量分析所提模型的有效性,并在背景复杂、目标被完全遮挡和部分遮挡的场景下,对其与HIPTrack算法[28 ] 进行可视化对比,定性分析算法的跟踪准确性. ...
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...
1
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...
ODTrack: online dense temporal token learning for visual tracking
1
2024
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...
1
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...
1
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...
1
... Comparison of visual object tracking results of various algorithms on different datasets
Tab.1 算法 LaSOT GOT-10k OTB100 $ {P}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}} $ AUC/% P /%AO/% $ {\mathrm{O}\mathrm{P}}_{0.50} $ $ {\mathrm{O}\mathrm{P}}_{0.75} $ $ {S}_{\mathrm{r}\mathrm{a}\mathrm{t}\mathrm{e}} $ AUC/% P /%HIPTrack-B384 [28 ] 82.9 72.7 79.5 77.4 88.0 74.5 79.2 71.0 80.2 AQATrack-B256 [29 ] 81.9 71.4 78.6 73.8 83.2 72.1 76.4 72.8 83.1 ODTrack-B384 [30 ] 83.2 73.2 80.6 77.0 87.9 75.1 75.6 73.0 81.8 LoRAT-B224 [31 ] 80.9 71.7 77.3 72.1 84.9 75.0 80.4 72.3 82.5 OSTrack384 [15 ] 81.1 71.1 77.6 73.7 83.2 70.8 77.6 55.9 75.8 SiamPRN++[32 ] 56.9 49.6 49.1 51.7 61.6 32.5 72.9 69.2 77.6 DiMP288 [33 ] 64.1 56.3 56.0 61.1 71.7 49.2 66.4 74.3 78.4 Zero-shot 82.7 75.3 82.8 79.6 90.8 79.2 81.7 74.8 84.9
为了直观验证零样本视觉跟踪模型在不同场景中的适应性和跟踪稳定性,使用HIPTrack-B384 算法和所提算法,在目标背景复杂、目标被完全遮挡以及存在不同程度遮挡的拥挤场景下进行可视化对比分析,以证明零样本视觉跟踪模型的跟踪准确性和环境适应性. 结果如图2 所示. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}