

近年来,随着无人机技术的快速发展,无人机航拍图像以高分辨率、低成本的优势成为航拍研究领域的重要图像来源. 无人机航拍图像往往具有目标尺度小、特征信息量少和相邻物体间难以区分的特点,因此对无人机航拍图像进行实时检测具有相当的挑战性. 此外,受制于无人机有限的计算资源,如何实现模型轻量化以完成算法在无人机上的部署,同样成为了当前无人机航拍图像目标检测领域中亟待解决的问题.
针对航拍图像中密集小目标检测困难的问题,已有一些研究成果. Zhu等[1]提出TPH-YOLOv5算法,增加小目标检测头以应对目标尺度的剧烈变化,利用Transformer检测头(TPH)替换原检测头,以准确地在高密度场景中定位对象,同时融入卷积注意力模块(convolutional block attention module, CBAM),帮助网络在覆盖大范围区域的图像中找到感兴趣的区域. Luo等[2]对YOLOv5模型进行改进,采用不对称卷积增强骨干网络的特征提取能力,并加入改进后的高效通道注意力模块,使网络更好地关注特定的局部信息,最后提出EIoU-NMS方法,从而更有效地抑制冗余预测框. 宋耀莲等[3]基于YOLOv5模型提出FDB-YOLO算法,通过添加小目标检测层优化特征融合网络,提高了浅层特征的利用率,其次构建新的损失函数FPIoU,通过四点定位方式显著提升损失函数的收敛速度和定位精度,最后在特征提取网络中加入双向路由注意力机制,以提升模型对重点特征的关注度并有效过滤无关特征. 邓天民等[4]基于YOLOv8模型提出一种自适应复合卷积模块,摒弃背景信息,自适应调节有效特征的输出,并利用空间上下文金字塔(SCP)的子分支替换空间金字塔池化(SPPF)模块,减少冗余信息的生成,最后提出轻量化T型感知检测头,采用参数共享的方式,在保持对多尺度特征信息敏感的同时降低模型计算开销.
为了在无人机设备上进行部署,许多学者针对模型轻量化问题开展相应研究. Cao等[5]提出基于GhostConv模块的骨干网络,相较于YOLOv4的骨干网络CSP-Darknet53,可以在不损失检测精度的情况下将网络参数量减少一半,并添加了浅层特征融合层和小目标检测头以精确预测高密度小目标的位置,同时移除大目标检测头,进一步减少了网络参数量. Wang等[6]提出YOLOv8-QSD算法,通过在YOLOv8模型中引入Q-blocks模块,实现了更高效的轻量化设计. 具体而言,Q-blocks模块接收P2层的特征作为输入,通过生成查询(query)、键(key)和值(value)组进行查询操作,生成稀疏的特征图. P3和P4层的特征被转换为查询、键和值,与P2层的特征交互,最终生成的稀疏特征图被用于在适当的层和关键位置以适当的比例预测检测框. Feng[7]等通过将坐标注意力机制集成到主干网络的C2f模块中,设计C2f_CA模块,增强模型对关键信息的关注,并保证了更丰富的梯度信息流动,从而提高了模型效率;引入多尺度注意力特征融合模块,以合并浅层和深层特征;引入动态检测头策略,进一步统一模型对尺度、空间和任务的感知,增强了其对小目标的检测能力.
以YOLOv8网络为基础,设计自适应细节增强模块,对C2f模块进行改进,减少冗余信息的生成,同时实现大尺度特征图浅层特征的复用,提出平衡检测精度与计算开销的航拍图像小目标检测算法.
1. 多尺度特征增强小目标检测算法
受制于无人机应用场景中有限的计算资源,以及VisDrone 2019数据集所呈现的高检测难度,在采用YOLOv8n模型进行检测时,检测精度mAP0.5仅为0.329. 采用更大规模的模型虽然能够在一定程度上提升检测效果,但随之而来的是计算复杂度和参数量的大幅提升. 在综合考量模型性能与计算开销后,最终选定YOLOv8s作为基准模型.
现有的目标检测算法在目标小、排列密集、背景复杂等情况下缺乏足够的检测性能. 因此,以YOLOv8s为基准模型,做出以下4个方面的改进,并构建兼顾检测精度与资源消耗的航拍小目标检测算法. 1)提出自适应细节增强模块(adaptive detail-enhanced module, ADEM),替换C2f的Bottleneck部分,构成C2f-ADEM模块. 在ADEM中引入条件卷积(conditional convolution, CondConv),针对不同样本动态地生成卷积核,以提升模型容量,增强模型泛化性. 将特征通道分割为双支,其中一条分支通过细节增强卷积(detail-enhanced convolution, DEConv)加强对高频信息的关注,并利用逐点卷积增强各通道间的信息交流,另一分支保持原有特征的恒等映射,最后通过特征拼接及通道混洗实现跨通道的信息交流. 2)基于路径聚合-特征金字塔网络(path aggregation network with feature pyramid network, PAN-FPN)架构对特征融合网络进行改进,对B2与P3层进行融合,加强对浅层特征的关注. 使用空间到深度卷积(space-to-depth convolution, SPDConv)对B2层进行下采样,在匹配P3层输出特征图尺度的同时避免细粒度信息丢失. 加入多尺度特征提取模块,通过全局分支、大尺度分支以及局部分支在多个尺度上提取特征,加强对小目标上下文信息的关注. 3)构建Nin-IoU来替换传统IoU,通过引入可调参数解决传统IoU灵活性、泛化性不足的问题;利用Nin-IoU替换CIoU中的传统IoU,构建Nin-CIoU损失函数,通过调整参数以适应小目标检测任务的需求;同时针对航拍图像中目标密集、重叠的问题,引入Soft-NMS策略[8],利用Nin-CIoU算法筛选预选框,构建Nin-NMS算法,采用权值衰减策略优化漏检问题. 4)提出一种轻量化检测头,利用局部卷积(partial convolution,PConv)[9]并结合逐点卷积(pointwise convolution, PWconv)代替原检测头的标准卷积层,通过通道调制减少冗余特征图的生成,降低计算开销,同时引入细节增强卷积以保证语义及空间信息提取能力. 改进后算法的整体结构如图1所示. 其中,S为卷积移动的步长,K为卷积核大小,n为模块重复出现的次数.
图 1
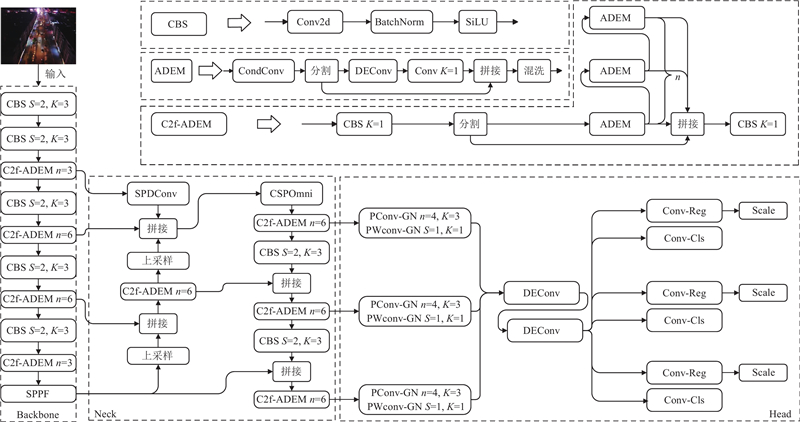
图 1 多尺度特征增强小目标检测算法的整体网络结构
Fig.1 Overall network architecture of small object detection algorithm based on multi-scale feature enhancement
1.1. 自适应细节增强模块
标准卷积在推理阶段对每个样本应用相同的卷积核进行特征提取,这种标准化卷积操作难以捕捉不同样本中的细微特征和复杂关系. 增大卷积核尺寸或数量虽然可以提升特征提取能力,但是会显著增加参数量和计算开销. 另外,标准卷积实质上对输入特征所进行的加权平均操作不可避免地造成了高频细节特征的缺失,这对于航拍小目标检测任务而言是难以忍受的.
针对上述问题,提出自适应细节增强模块ADEM,其结构如图2所示. 条件卷积CondConv[10]通过为每个输入样本生成条件向量,并利用该向量动态地调整多个基础卷积核的权重组合,使卷积层能够适应不同样本对特征的需求,提升模型的灵活性和表达能力. 随后,输入特征映射被分割为2条分支,每条分支的通道数是原来的一半. 细节增强卷积DEConv[11]通过引入差分卷积捕捉像素之间的差异,提升对高频信息的关注,从而更好地提取图像细节和纹理特征. 为了降低细节增强卷积的参数量,采用深度卷积的思想,分别为标准卷积和差分卷积的每个通道应用不同的卷积核,以减少计算复杂度. 在通过逐点卷积融合各通道信息后,将2条分支合并,利用通道混洗增强各分支间的信息流动,进一步提升模块的特征学习能力和计算效率.
图 2
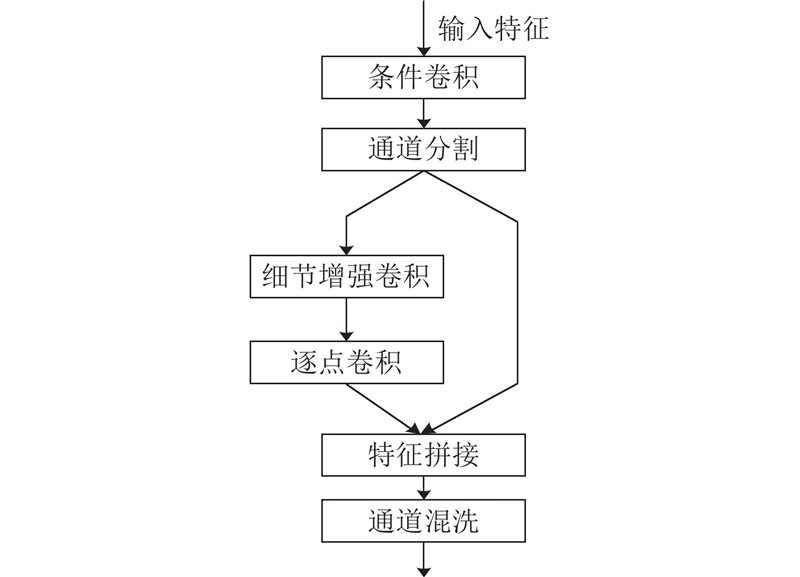
1.1.1. 条件卷积模块
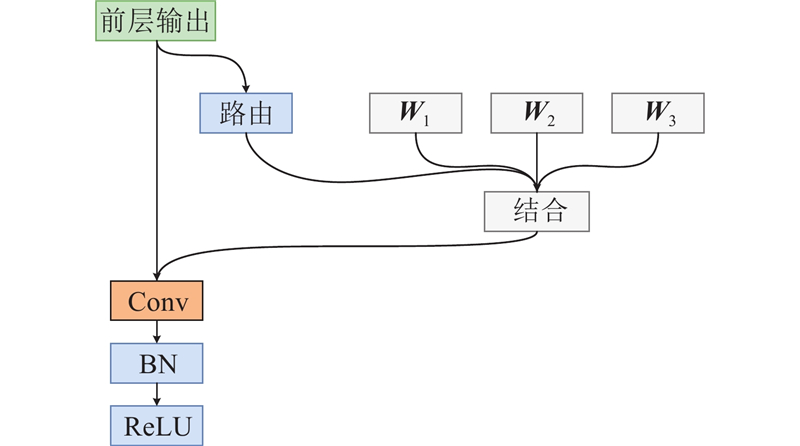
在深度学习网络中,特征图的学习对模型精度的提升至关重要. 然而,若在推理阶段对所有样本均使用相同的卷积核进行特征提取,则会限制模型的泛化性和灵活性,模型容量即模型所能捕捉的特征的复杂程度也会受到较大制约. 常规的通过增大卷积核尺寸或增加卷积核数量来提升模型容量的方式都不可避免地引入了更大的参数量与计算量. 鉴于此,条件卷积CondConv设置了多个基础卷积核,并计算每个输入样本的路由函数,以动态调整各卷积核的参数权重,具体计算方式为
式中:Sigmoid为激活函数;GAP(
式中:
图 3
1.1.2. 细节增强卷积模块
标准卷积在训练初期的权重通过随机或某种特定的初始化方式产生,使得其需要更多的时间和数据学习如何提取高频特征. 因此,在训练初期,标准卷积可能会在卷积过程中丢失高频信息,从而使模型无法充分提取小目标的纹理特征. 细节增强卷积DEConv通过预先设定初始权重的差分卷积(difference convolution, DC)计算相邻像素间的差异以捕捉高频信息,进而加强特征的边缘信息. 将差分卷积和标准卷积经过训练得到的权重和偏置相融合,并将不同方向的高频特征集成到标准卷积中,弥补了标准卷积在处理高频信息方面的不足. 通过引入DEConv,模型能够有效提取小目标的边缘和纹理特征,从而提升小目标检测的精度和可靠性.
细节增强卷积DEConv包含2个主要步骤:1)通过差分卷积增强高频信息的捕获;2)通过标准卷积提取低频特征. 结构如图4所示. DEConv并行采用4个差分卷积来提取高频信息. 训练开始时,4种差分卷积设定的权重更新方式为
图 4
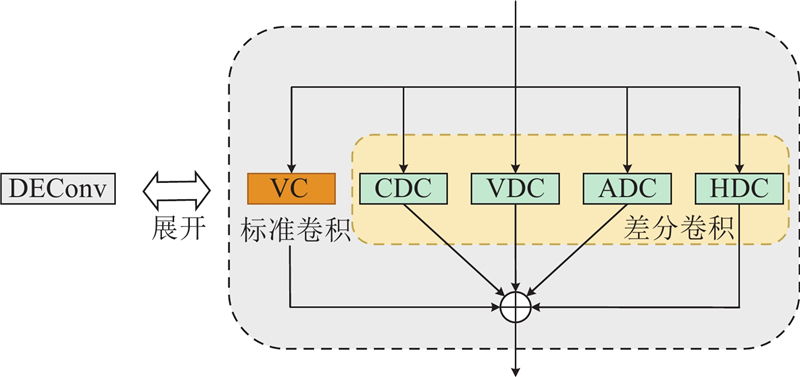
式中:以
式中:
1.2. 多尺度特征融合网络
YOLOv8采用的PAN-FPN结构结合了特征金字塔网络(FPN)[12]和路径聚合网络(PANet)[13]的优势. FPN通过自顶向下的策略整合多层级的特征,增强了上下文信息捕捉能力,而PANet进一步引入自底向上的路径聚合机制,提升了浅层特征的利用效率,并加强了信息流动,使网络能够高效地捕获不同尺度的目标细节信息. 然而,PAN-FPN 结构在小目标检测任务中仍然存在一定的局限性. 一方面,在对航拍图像小目标和遮挡目标进行检测时,更加需要依赖于大尺度特征图包含的丰富的语义信息,而YOLOv8对大尺度特征图的关注不足;另一方面,YOLOv8中大量采用
图 5

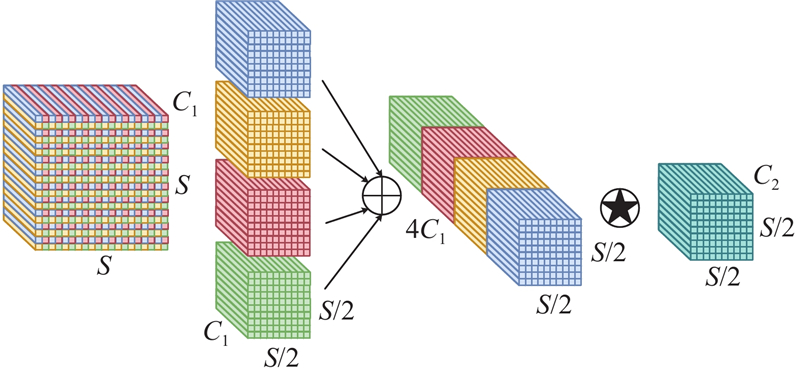
大尺度特征图具有更高的分辨率和更多的细节信息,但是PAN-FPN的结构设计可能导致这些特征在信息传递和融合过程中被压缩或忽略,导致小目标的细节信息丢失. 针对这个问题,对YOLOv8模型中B2和P3层级进行深度融合,以加强模型对大尺度特征图的利用. 为了统一B2与P3层的特征图尺度,实现B2-P3的融合,需要在B2层之后进行下采样处理. 采用步长为2的标准卷积进行下采样容易导致细粒度信息的丢失,从而影响特征表示. 为此,引入SPDConv模块[14],该模块由空间到深度(space-to-depth, SPD)层和非跨行卷积(non-strided convolution)层构成. 当下采样倍数为2时,SPDConv下采样过程如图6所示. 其中,C1、C2分别为输入特征和输出特征的通道数,S为输入特征的尺度大小. SPD层将特征映射的空间维度信息重排并在通道维度相加,完整保留了通道维度中的所有信息,从而实现无损下采样.图中星号表示SPDConv在每个SPD层之后加入非跨行卷积,能够在不改变特征图分辨率的情况下,灵活调整通道数量,从而实现对特征的高效压缩或扩展. 这种设计不仅保留了特征的判别性信息,还在下采样过程中维持了特征的丰富性和多样性.
图 6
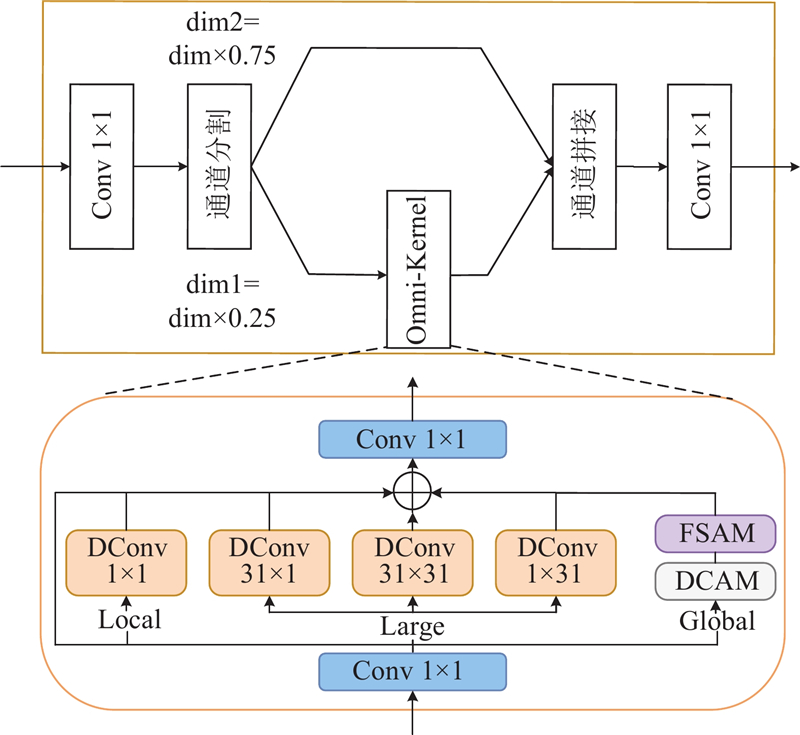
OKM通过3条分支实现了高效的多尺度特征学习,但其巨大的参数量以及高昂的计算开销同样不容忽视. 因此,在大尺寸深度卷积核的基础上引入空洞卷积,构成深度空洞卷积,在保证原接受域的同时,减少参数量及计算开销. 最后,基于跨阶段局部(cross stage partial, CSP)连接结构设计CSPOmni模块,将输入特征在通道维度上分割为2部分. 一条分支通过OKM进行处理,另一分支保持原特征的恒等映射. 将各分支的输出结果在通道维度上进行拼接,并通过标准卷积增强各通道之间的信息交流. CSPOmni的结构如图7所示,其中,dim为原始通道数,dim1和dim2为分割后的通道数.
图 7
1.3. 参数可调的Nin-IoU
作为目标检测的基本任务之一,边框回归在近年来的研究中大多基于
式中:
上述改进在一定程度上提升了边界框的回归效果,但是并未考虑到
N-IoU[16]首次将
式中:
作为可调参数,
通过改变
图 8
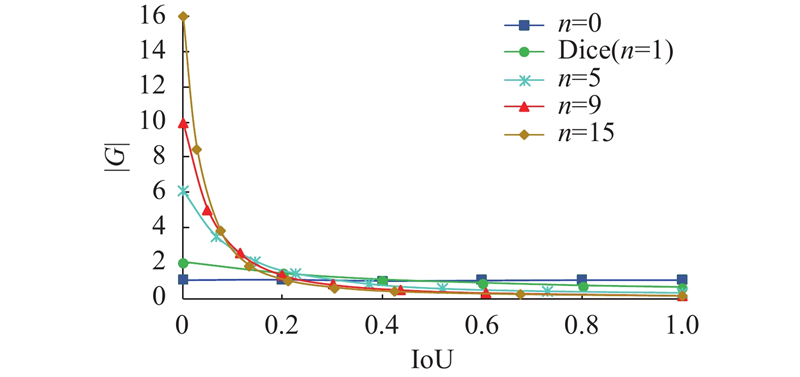
图 8
回归损失梯度与
Fig.8 Relationship between regression loss gradient and IoU
当
Inner-IoU[17]提出利用辅助边界框来计算
式中:
借鉴N-IoU的思想,将Dice系数引入Inner-IoU,对
Nin-IoU结合N-IoU与Inner-IoU的优点,进一步优化了边界框回归过程中的梯度更新. 令L1、L2分别表示使用
式中:
YOLOv8使用传统的非极大值抑制(NMS)算法作为后处理步骤,在进行计算时,若待检测框与置信度最高的检测框之间的
式中:
1.4. 轻量化T型感知检测头
YOLOv8检测头采用解耦头结构,将分类和回归任务分开处理,允许每个任务进行专门的特征学习和优化,从而提高模型的性能和准确性. 然而,小目标检测需要更细致的联合特征信息来准确地进行分类和定位. 此外,解耦检测头对分类和回归任务进行独立优化,不可避免地会带来更大的计算开销以及更高的参数量. 基于上述YOLOv8检测头的优缺点,改进的检测头在降低参数量与计算量的同时,进一步增强对小目标特征的提取能力,寻求性能与资源消耗上的相对平衡.
轻量化T型感知检测头(lightweight T-shaped perception detection head, LTDH)在接收P2~P4层级输入的特征后,首先通过T型感知域特征融合模块增强各通道之间的信息流动和交互效率,其结构如图9所示. T型感知域特征融合模块由局部卷积PConv和逐点卷积PWconv组成. PConv通过通道分割将输入特征划分为2条分支,对一条分支进行卷积操作,提取特征信息,并通过恒等映射保留另一分支的特征. 此举优化了计算冗余,有效降低了模型复杂度. 对于经过PConv整合的特征信息,再通过逐点卷积PWconv处理和整合不同通道的信息,帮助模型捕捉跨通道的复杂特征关系,从而提升模型的表达能力. Tian等[18]证明了组归一化(group normalization, GN)可以提升检测头定位和分类的能力,因此改进的检测头在卷积层中将原检测头使用的BN均替换为GN. 假定输入特征
图 9
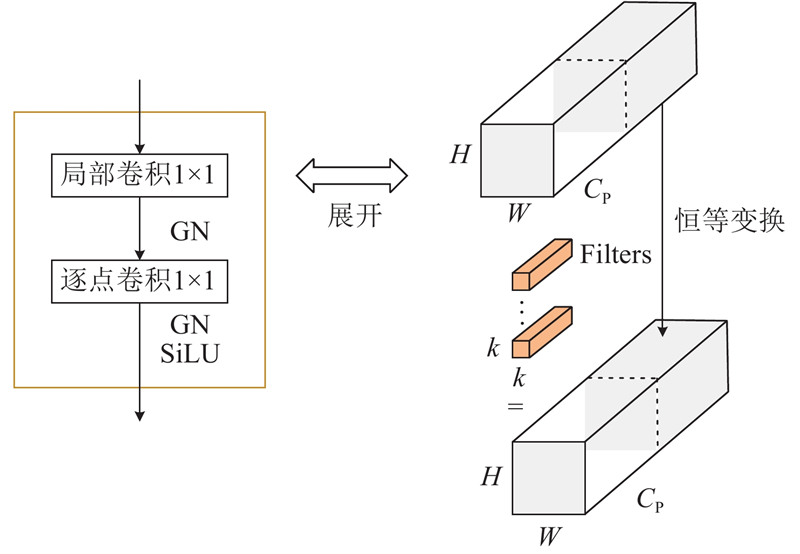
图 9 T型感知域特征融合模块结构
Fig.9 T-shaped perceptual field feature fusion module architecture
为了进一步整合各层级间丰富的空间及语义信息,在T型感知域特征融合模块后使用2个
2. 实 验
2.1. 数据集
实验采用天津大学发布的VisDrone2019数据集[19],共计
2.2. 实验环境及参数配置
硬件配置与实验环境如下:处理器为Inter core i7-14650HX,内存为16 G,显卡为NVIDIA GeForce RTX4060,显存为8 G,采用CUDA 11.6、CUDNN v8.0作为显卡加速库. 采用Pytorch深度学习框架,操作系统为Windows11. 为了保证实验结果的公平性,实验中涉及的模型均未使用预训练权重. 模型训练所设置的图片尺寸为
2.3. 消融实验
为了检验Nin-IoU的不同参数设定对检测结果产生的影响,同时确定针对小目标检测任务最佳的参数组合,进行消融实验. 分别将式(19)中
表 1 Nin-IoU消融实验结果
Tab.1
| N | ratio | P | R | mAP0.5 | mAP0.5∶0.95 |
| 0 | 1.1 | 0.603 | 0.375 | 0.494 | 0.321 |
| 0 | 1.2 | 0.607 | 0.375 | 0.495 | 0.322 |
| 0 | 1.3 | 0.610 | 0.375 | 0.496 | 0.322 |
| 0 | 1.4 | 0.613 | 0.375 | 0.497 | 0.323 |
| 0 | 1.5 | 0.614 | 0.375 | 0.498 | 0.323 |
| 1 | 1.1 | 0.628 | 0.373 | 0.502 | 0.325 |
| 1 | 1.2 | 0.629 | 0.372 | 0.502 | 0.326 |
| 1 | 1.3 | 0.630 | 0.372 | 0.502 | 0.326 |
| 1 | 1.4 | 0.631 | 0.372 | 0.503 | 0.326 |
| 1 | 1.5 | 0.632 | 0.372 | 0.503 | 0.326 |
| 5 | 1.1 | 0.636 | 0.369 | 0.503 | 0.327 |
| 5 | 1.2 | 0.637 | 0.368 | 0.503 | 0.326 |
| 5 | 1.3 | 0.637 | 0.367 | 0.503 | 0.326 |
| 5 | 1.4 | 0.637 | 0.367 | 0.502 | 0.326 |
| 5 | 1.5 | 0.637 | 0.366 | 0.502 | 0.326 |
| 9 | 1.1 | 0.637 | 0.366 | 0.502 | 0.326 |
| 9 | 1.2 | 0.638 | 0.365 | 0.502 | 0.326 |
| 9 | 1.3 | 0.638 | 0.364 | 0.501 | 0.326 |
| 9 | 1.4 | 0.637 | 0.362 | 0.500 | 0.325 |
| 9 | 1.5 | 0.638 | 0.361 | 0.500 | 0.325 |
| 15 | 1.1 | 0.638 | 0.363 | 0.501 | 0.326 |
| 15 | 1.2 | 0.638 | 0.361 | 0.500 | 0.325 |
| 15 | 1.3 | 0.638 | 0.359 | 0.499 | 0.325 |
| 15 | 1.4 | 0.639 | 0.358 | 0.498 | 0.324 |
| 15 | 1.5 | 0.639 | 0.356 | 0.497 | 0.324 |
采取N=5、ratio=1.1,对IoU、N-IoU、Inner-IoU以及Nin-IoU进行横向对比. 由表2可知,N-IoU通过引入Dice系数有效提升了边框回归的细粒度. Inner-IoU利用辅助边界框加快了低IoU样本的回归速度,相较于IoU,检测精度有所提升. Nin-IoU通过结合N-IoU与Inner-IoU,进一步提升了检测精度,验证了Nin-IoU改进的有效性.
表 2 损失函数对比实验结果
Tab.2
| 模型 | P | R | mAP0.5 | mAP0.5∶0.95 |
| IoU | 0.599 | 0.376 | 0.492 | 0.320 |
| N-IoU | 0.634 | 0.370 | 0.500 | 0.324 |
| Inner-IoU | 0.603 | 0.375 | 0.494 | 0.321 |
| Nin-IoU | 0.636 | 0.369 | 0.503 | 0.326 |
利用空洞卷积并结合原结构中的大尺寸深度卷积构成深度空洞卷积,初步降低了模块参数量和计算开销. 深度空洞卷积的卷积核
表 3 CSPOmni消融实验结果
Tab.3
| 模块 | FLOPs/109 | ||
| OKM | 2.11 | 9.57 | 36.6 |
| OKM+DC | 1.62 | 9.08 | 30.3 |
| OKM+CSP | 0.76 | 8.21 | 25.4 |
| CSPOmni | 0.64 | 8.08 | 23.6 |
为了探究自适应细节增强模块、多尺度特征融合网络、轻量化T型感知检测头以及Nin-IoU对模型的贡献,在VisDrone2019数据集上进行各模块的消融实验. 表4中,(a)~(d)分别表示仅对YOLOv8s添加自适应细节增强模块(ADEM)、多尺度特征融合网络(MFFN)、轻量化T型感知检测头(LTDH)或Nin-IoU,(e)表示在(a)的基础上添加多尺度特征融合网络,(f)表示在(e)的基础上加入Nin-IoU,(g)表示完整的改进模型. Pre为检测精确度,Para为模型参数量,F为每秒钟可以检测的图片数. 由表4可知,各项改进均起到了前文说明的作用. 自适应细节增强模块通过通道调制,减少冗余特征图的生成,并利用DEConv增强模型对高频细节特征的关注,在保证精度的同时使参数量减少了3.28×106,说明加强模型对浅层特征的关注,有助于捕获检测小目标所需的细粒度信息. 多尺度特征融合网络在参数量增加0.94×106的代价下,实现了mAP0.5值5.0个百分点的提升,说明引入大尺度卷积核可以帮助模型更好地确定目标位置信息. 在前两者的基础上加入轻量化T型感知检测头后,mAP0.5提高了0.9个百分点,同时参数量减少了0.71×106. 加入Nin-IoU后mAP0.5提高了5.9个百分点,其中Nin-IoU的应用包括构建Nin-CIoU损失函数,利用Nin-CIoU改进Soft-NMS,以及构建Nin-NMS算法. 说明经过针对性参数调整后的Nin-CIoU损失函数能够更好地适应小目标检测任务,并且引入Soft-NMS策略有效缓解了预选框误删的问题,提升了遮挡重叠目标的检测效果. 此外,加入COCO指标中针对小目标的评价指标APsmall0.5∶0.95,用以直观体现各改进部分对小目标检测的作用.
表 4 多尺度特征增强小目标检测算法的总体消融实验结果
Tab.4
| 模型 | ADEM | MFFN | LTDH | Nin-IoU | mAP0.5/% | mAP0.5∶0.95/% | APsmall0.5∶0.95/% | Pre/% | Para/106 | FLOPs/109 | F/(帧 |
| YOLOv8s | — | — | — | — | 38.8 | 23.2 | 12.4 | 49.9 | 11.13 | 28.5 | 117.3 |
| (a) | √ | — | — | — | 38.5 | 22.9 | 11.7 | 49.7 | 7.85 | 19.2 | 117.6 |
| (b) | — | √ | — | — | 43.8 | 26.6 | 14.5 | 53.1 | 12.07 | 40.1 | 102.1 |
| (c) | — | — | √ | — | 39.6 | 23.9 | 12.7 | 52.1 | 10.41 | 21.2 | 114.9 |
| (d) | — | — | — | √ | 44.9 | 29.1 | 13.7 | 58.4 | 11.13 | 28.5 | 80.9 |
| (e) | √ | √ | — | — | 43.5 | 26.1 | 13.8 | 52.8 | 8.79 | 31.1 | 105.7 |
| (f) | √ | √ | √ | — | 44.4 | 27.4 | 14.7 | 56.2 | 8.08 | 23.6 | 93.5 |
| (g) | √ | √ | √ | √ | 50.3 | 32.7 | 15.7 | 63.6 | 8.08 | 23.6 | 57.3 |
2.4. 对比实验
为了进一步验证所提算法的优越性,在保证训练环境相同的条件下,在VisDrone 2019数据集上将其与其他检测算法进行比较,包括YOLO系列算法与当前较先进的小目标检测算法. 评价指标选用AP、mAP0.5、F和Para,兼顾模型的检测精度与复杂程度,其中AP为单个类别的平均精度. 结果如表5所示. 对比其他算法,所提模型在行人、自行车、三轮车等8类目标上的检测性能最佳,在汽车、卡车2类纵横比较大的类别中,同样取得了较高的检测精度,AP分别为81.3%、49.3%. YOLOv5s、YOLOv7-tiny虽然在参数量方面更具优势,然而过低的检测精度使其难以满足实际应用需求. 提出的模型以8.08×106的参数量在mAP0.5上超过了参数量为60.42×106的TPH-YOLOv5算法,证明其在检测精度与计算开销之间实现了良好的平衡,能够在航拍图像目标检测任务中取得较好的效果.
表 5 不同算法在VisDrone数据集上的平均精度和参数量对比
Tab.5
| 模型 | AP/% | mAP0.5/% | F/(帧 | Para/106 | |||||||||
| 行人 | 人 | 自行车 | 汽车 | 面包车 | 卡车 | 三轮车 | 遮阳棚三轮车 | 巴士 | 摩托车 | ||||
| Faster R-CNN[20] | 20.9 | 14.8 | 7.3 | 51.0 | 29.7 | 19.5 | 14.0 | 8.8 | 30.5 | 21.2 | 21.8 | 14.4 | — |
| YOLOv5s | 39.0 | 31.3 | 11.2 | 73.5 | 35.4 | 29.5 | 20.5 | 11.1 | 43.1 | 37.0 | 33.2 | 118.0 | 7.03 |
| TPH-YOLOv5[1] | 53.3 | 42.1 | 21.1 | 83.7 | 45.2 | 42.5 | 33.0 | 16.3 | 61.1 | 51.0 | 44.9 | 34.0 | 60.42 |
| YOLOv7-tiny[21] | 37.9 | 34.6 | 9.4 | 76.1 | 36.3 | 29.8 | 20.1 | 10.6 | 43.2 | 41.8 | 34.0 | 89.0 | 6.03 |
| YOLOv8s | 42.0 | 32.8 | 12.5 | 79.4 | 44.7 | 35.5 | 26.9 | 17.1 | 54.0 | 43.3 | 38.8 | 17.3 | 11.13 |
| YOLOv8l | 51.1 | 39.8 | 21.9 | 82.9 | 49.3 | 45.4 | 38.1 | 20.4 | 67.0 | 52.3 | 46.8 | 59.0 | 43.69 |
| YOLOv9-C[22] | 34.0 | 18.4 | 15.4 | 77.5 | 45.2 | 54.1 | 24.8 | 24.1 | 64.9 | 38.3 | 39.7 | — | 50.90 |
| YOLOv11s | 41.6 | 31.8 | 11.2 | 79.5 | 45.4 | 35.5 | 26.1 | 15.5 | 55.1 | 43.3 | 38.5 | 121.8 | 9.46 |
| 本研究模型 | 53.9 | 48.3 | 27.5 | 81.3 | 53.6 | 49.3 | 40.0 | 24.5 | 71.9 | 52.8 | 50.3 | 57.3 | 8.08 |
2.5. 可视化分析
为了充分验证提出的算法在面对不同场景时的检测性能,选取VisDrone 2019数据集中遮挡情况、高空视野、夜间环境等不同场景的航拍图像,同时对YOLOv8s以及本研究算法进行测试,结果如图10所示. 对比可知,本研究算法在小目标识别方面展现出更为优越的性能. 通过计算准确率和召回率,进一步定量分析检测效果. 图10(a)中P=0.897、R=0.667,图10(d)中P=0.903、R=0.737;图10(b) 中P=0.739、R=1.000,图10(e) 中P=0.811、R=1.000;图10(c)中P=1.000、R=0.108,图10(f)中P=1.000、R=0.270. 实验结果表明,本研究算法在不同检测场景下具有更好的鲁棒性及实用价值.
图 10

图 10 复杂场景中YOLOv8s和所提算法的目标检测效果对比
Fig.10 Comparison of YOLOv8s and proposed algorithm on target detection performance in complex scenes
利用可视化技术Grad-CAM[23]为YOLOv8s和本研究模型生成热力图,从而更直观地分析模型在进行决策时所关注的区域. Grad-CAM利用网络最后一层卷积层的特征图及其对应目标类别输出的梯度信息进行加权,生成类别热图,如图11所示. 其中高亮区域为对目标分类结果贡献较大的区域. 图11(b)表明YOLOv8s过分关注繁杂的背景信息,对检测对象的关注较为分散;图11(e)中,YOLOv8s对目标的关注较为分散,影响了边界框预测的准确度;图11(h)显示YOLOv8s对远景小目标的关注度不足,难以对远景小目标起到有效的检测作用. 综合分析表明,本研究算法相较于YOLOv8s模型加强了对小目标的关注度,同时减少了复杂背景对检测的干扰,在复杂场景特别是远视距场景中检测性能有显著提升.
图 11

图 11 不同场景中YOLOv8s与所提算法的热力图可视化结果
Fig.11 Heatmap visualization results of YOLOv8s and proposed algorithm in different scenarios
2.6. 泛化性实验
表 6 不同场景下的泛化性实验结果
Tab.6
| 模型 | DIOR | DOTA | |||||
| P/% | R/% | mAP0.5/% | P/% | R/% | mAP0.5/% | ||
| YOLOv8s | 81.5 | 71.9 | 73.7 | 71.6 | 40.8 | 44.0 | |
| 本研究模型 | 81.0 | 74.1 | 77.1 | 73.6 | 40.1 | 56.7 | |
图 12

图 12 不同场景中YOLOv8s与所提算法的泛化性实验效果对比
Fig.12 Comparison of generalization performance between YOLOv8s and proposed algorithm in different scenarios
3. 结 语
针对航拍图像小目标检测中存在的检测精度低和模型参数量大的问题,提出兼顾性能与资源消耗的航拍小目标检测算法. 在特征提取方面,提出自适应细节增强模块,在调整输入特征通道的同时加强对高频信息的关注,并集成C2f模块以构建C2f-ADEM. 实验结果显示,该设计在保证特征提取效果的同时有效降低了参数量及计算复杂度. 在特征融合方面,基于PAN-FPN 架构对YOLOv8特征融合网络进行改进. 采用SPDConv对B2层进行下采样,将输出结果与P3层融合,以增强对浅层特征信息的关注. 引入多尺度卷积模块,增强模型对全局信息的捕获. 热力图结果显示,改进模型有效优化了目标上下文语义信息感知,使模型更加关注目标的中心位置,有效提高了航拍图像检测精度. 在损失函数方面,针对传统IoU灵活性、泛化性不足的问题,结合N-IoU与Inner-IoU提出参数可调的Nin-IoU,以适应不同检测任务的需求. 针对航拍小目标检测中密集重叠目标的检测难题,引入Soft-NMS策略,利用Nin-CIoU算法筛选预选框,并构建Nin-NMS算法. 由实验结果可知,相较于基准算法,引入Nin-NMS后的模型在整体上的漏检率更低,对高重叠的对象簇具有更好的检测效果. 此外,提出轻量化T型感知检测头,旨在减少计算开销并加强不同尺度信息之间的交融,以适应小目标检测任务的需求. 在VisDrone2019数据集上的实验结果表明,本研究模型的mAP0.5值由38.8%提升至50.3%,参数量由11.13×106降低至8.08×106,表明本研究算法对航拍图像有较好的检测效果.
提出的模型在提升检测精度与减少参数量方面取得了一定成果,但由于Soft-NMS策略的引入增加了模型的后处理时间,模型检测速度有所下降. 下一步计划通过模型剪枝或蒸馏技术提升模型的整体性能,或对Soft-NMS策略进行进一步的改进,以满足实际应用需求.
参考文献
FCOS: a simple and strong anchor-free object detector
[J].
Grad-CAM: visual explanations from deep networks via gradient-based localization
[J].DOI:10.1007/s11263-019-01228-7 [本文引用: 1]
Target detection method of UAV aerial imagery based on improved YOLOv5
[J].DOI:10.3390/rs14195063 [本文引用: 1]
基于改进YOLOv5s的无人机小目标检测算法
[J].
UAV small target detection algorithm based on improved YOLOv5s
[J].
Object detection in optical remote sensing images: a survey and a new benchmark
[J].
GCL-YOLO: a GhostConv-based lightweight YOLO network for UAV small object detection
[J].DOI:10.3390/rs15204932 [本文引用: 1]
YOLOv8-QSD: an improved small object detection algorithm for autonomous vehicles based on YOLOv8
[J].
Improved YOLOv8 algorithms for small object detection in aerial imagery
[J].DOI:10.1016/j.jksuci.2024.102113 [本文引用: 1]
DEA-net: single image dehazing based on detail-enhanced convolution and content-guided attention
[J].DOI:10.1109/TIP.2024.3354108 [本文引用: 1]
Omni-kernel network for image restoration
[J].DOI:10.1609/aaai.v38i2.27907 [本文引用: 1]
N-IoU: better IoU-based bounding box regression loss for object detection
[J].DOI:10.1007/s00521-023-09133-4 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}