[1]
ZHAO Q, XU D, LI J, et al Knowledge guided distance supervision for biomedical relation extraction in Chinese electronic medical records
[J]. Expert Systems with Applications , 2022 , 204 : 117606
DOI:10.1016/j.eswa.2022.117606
[本文引用: 1]
[2]
HEIST N, PAULHEIM H. Language-agnostic relation extraction from wikipedia abstracts [C]// International Semantic Web Conference . Vienna: Springer, 2017: 383–399.
[本文引用: 1]
[3]
ZENG D, LIU K, LAI S, et al. Relation classification via convolutional deep neural network [C]// International Conference on Computational Linguistics . Dublin: ACL, 2014: 2335–2344.
[4]
ZHANG Y, QI P, MANNING C D. Graph convolution over pruned dependency trees improves relation extraction [C]// Conference on Empirical Methods in Natural Language Processing . Brussels: ACL, 2018: 2205–2215.
[本文引用: 1]
[5]
YAO Y, YE D, LI P, et al. DocRED: a large-scale document-level relation extraction dataset [C]// Annual Meeting of the Association for Computational Linguistics . Florence: ACL, 2019: 764–777.
[本文引用: 1]
[6]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2016-09-09). https://arxiv.org/abs/1609.02907.
[本文引用: 1]
[7]
WANG D, HU W, CAO E, et al. Global-to-local neural networks for document-level relation extraction [C]// Conference on Empirical Methods in Natural Language Processing . [S.l.]: ACL, 2020: 3711–3721.
[本文引用: 3]
[8]
LIU H, KANG Z, ZHANG L, et al. Document-level relation extraction with cross-sentence reasoning graph [C]// Pacific-Asia Conference on Knowledge Discovery and Data Mining . Osaka: Springer, 2023: 316–328.
[本文引用: 2]
[9]
ZHOU H, XU Y, YAO W, et al. Global context-enhanced graph convolutional networks for document-level relation extraction [C]// International Conference on Computational Linguistics . Barcelona: ICCL, 2020: 5259–5270.
[本文引用: 3]
[10]
VRANDEČIĆ D, KRÖTZSCH M Wikidata: a free collaborative knowledgebase
[J]. Communications of the ACM , 2014 , 57 (10 ): 78 - 85
DOI:10.1145/2629489
[本文引用: 1]
[11]
AUER S, BIZER C, KOBILAROV G, et al. DBpedia: a nucleus for a web of open data [C]// International Semantic Web Conference . Busan: Springer, 2007: 722–735.
[12]
BASTOS A, NADGERI A, SINGH K, et al. RECON: relation extraction using knowledge graph context in a graph neural network [C]// International World Wide Web Conference . Ljubljana: ACM, 2021: 1673–1685.
[13]
FERNÀNDEZ-CAÑELLAS D, MARCO RIMMEK J, ESPADALER J, et al. Enhancing online knowledge graph population with semantic knowledge [C]// International Semantic Web Conference . Athens: Springer, 2020: 183–200.
[14]
PAN J, ZHANG M, SINGH K, et al. Entity enabled relation linking [C]// International Semantic Web Conference . Auckland: Springer, 2019: 523–538.
[15]
WANG X, WANG Z, SUN W, et al. Enhancing document-level relation extraction by entity knowledge injection [C]// International Semantic Web Conference . [S.l.]: Springer, 2022: 39–56.
[本文引用: 3]
[16]
WANG H, QIN K, LU G, et al Document-level relation extraction using evidence reasoning on RST-GRAPH
[J]. Knowledge-Based Systems , 2021 , 228 : 107274
DOI:10.1016/j.knosys.2021.107274
[本文引用: 3]
[17]
SOUSA D, COUTO F M Biomedical relation extraction with knowledge graph-based recommendations
[J]. IEEE Journal of Biomedical and Health Informatics , 2022 , 26 (8 ): 4207 - 4217
DOI:10.1109/JBHI.2022.3173558
[本文引用: 2]
[18]
CHEN J, HU B, PENG W, et al Biomedical relation extraction via knowledge-enhanced reading comprehension
[J]. BMC Bioinformatics , 2022 , 23 (1 ): 20
DOI:10.1186/s12859-021-04534-5
[本文引用: 2]
[19]
ZHANG B, LI L, SONG D, et al Biomedical event causal relation extraction based on a knowledge-guided hierarchical graph network
[J]. Soft Computing , 2023 , 27 (22 ): 17369 - 17386
DOI:10.1007/s00500-023-08882-7
[本文引用: 3]
[20]
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [EB/OL]. (2018-10-11). https://arxiv.org/abs/1810.04805v2.
[本文引用: 2]
[21]
WANG H, FOCKE C, SYLVESTER R, et al. Fine-tune BERT for DocRED with two-step process [EB/OL]. (2019-09-26). https://arxiv.org/abs/1909.11898v1.
[本文引用: 1]
[22]
ZHOU W, HUANG K, MA T, et al. Document-level relation extraction with adaptive thresholding and localized context pooling [C]// AAAI Conference on Artificial Intelligence. [S.l.]: AAAI Press, 2021: 14612–14620.
[本文引用: 1]
[23]
XU B, WANG Q, LYU Y, et al. Entity structure within and throughout: modeling mention dependencies for document-level relation extraction [C]// AAAI Conference on Artificial Intelligence . [S.l.]: AAAI Press, 2021: 14149–14157.
[本文引用: 2]
[24]
QUIRK C, POON H. Distant supervision for relation extraction beyond the sentence boundary [C]// Conference of the European Chapter of the Association for Computational Linguistics . Valencia: ACL, 2017: 1171–1182.
[本文引用: 1]
[25]
PENG N, POON H, QUIRK C, et al Cross-sentence N -ary relation extraction with graph LSTMs
[J]. Transactions of the Association for Computational Linguistics , 2017 , 5 : 101 - 115
DOI:10.1162/tacl_a_00049
[本文引用: 1]
[26]
VERGA P, STRUBELL E, MCCALLUM A. Simultaneously self-attending to all mentions for full-abstract biological relation extraction [C]// Conference of the North American Chapter of the Association for Computational Linguistics . New Orleans: ACL, 2018: 872–884.
[本文引用: 1]
[27]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// International Conference on Neural Information Processing Systems . Long Beach: NeurIPS Foundation, 2017: 6000–6010.
[本文引用: 1]
[28]
NAN G, GUO Z, SEKULIC I, et al. Reasoning with latent structure refinement for document-level relation extraction [C]// Annual Meeting of the Association for Computational Linguistics . [S.l.]: ACL, 2020: 1546–1557.
[本文引用: 1]
[29]
ZENG S, XU R, CHANG B, et al. Double graph based reasoning for document-level relation extraction [C]// Conference on Empirical Methods in Natural Language Processing . [S.l.]: ACL, 2020: 1630–1640.
[本文引用: 1]
[30]
LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26). https://arxiv.org/abs/1907.11692.
[本文引用: 2]
[31]
ZENG A, XU B, WANG B, et al. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools. (2024-07-30). https://arxiv.org/abs/2406.12793.
[本文引用: 2]
[32]
OUYANG L, WU J, XU J, et al. Training language models to follow instructions with human feedback [C]// International Conference on Neural Information Processing Systems . New Orleans: NeurIPS Foundation, 2022: 27730–27744.
[本文引用: 1]
[33]
DUBEY A, JAUHR A, PANDEY A, et al. The Llama 3 herd of models [EB/OL]. (2024-07-31). https://arxiv.org/abs/2407.21783.
[本文引用: 2]
[34]
HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. (2021-10-16). https://arxiv.org/abs/2106.09685.
[本文引用: 1]
[35]
VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks [EB/OL]. (2017-10-30). https://arxiv.org/abs/1710.10903.
[本文引用: 1]
[36]
BAI J, BAI S, CHU Y, et al. Qwen technical report [EB/OL]. (2023-09-28). https://arxiv.org/abs/2309.16609.
[本文引用: 1]
Knowledge guided distance supervision for biomedical relation extraction in Chinese electronic medical records
1
2022
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
1
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
1
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
1
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
1
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
3
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
2
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
3
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
Wikidata: a free collaborative knowledgebase
1
2014
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
3
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
... 此外,一些工作研究如何将外部知识注入到RE任务中以进一步提高性能. Wang等[16 ] 试图在新的文档级图RST-GRAPH上选择合适的证据并展示推理过程. RST-GRAPH通过修辞结构理论(rhetorical structure theory, RST)揭示多个文本单元之间的有效语义关联,并整合一系列推理模块来捕获有效证据. Sousa等[17 ] 通过添加基于知识图谱的推荐机制,来提高系统识别基线深度RE模型无法从文本中提取的真实关系的能力. Wang等[15 ] 提出KIRE架构,通过引入共指蒸馏来注入共指知识,赋予RE模型更广泛的共指推理能力,并通过表示协调来注入事实知识,将知识图谱表示和文档表示聚合到统一的空间中. Chen等[18 ] 提出利用阅读理解和先验知识进行生物医学关系抽取的方法. 实验结果显示,开放领域的阅读理解数据和知识表示有助于提高医学关系抽取能力. 为了更好地融合知识,Zhang等[19 ] 在因果方向的指导下有效地聚合了上下文和层次知识语义,提出GECANet架构,并证实融合外部知识可以有效地引导模型识别事件之间的因果关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
Document-level relation extraction using evidence reasoning on RST-GRAPH
3
2021
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
... 此外,一些工作研究如何将外部知识注入到RE任务中以进一步提高性能. Wang等[16 ] 试图在新的文档级图RST-GRAPH上选择合适的证据并展示推理过程. RST-GRAPH通过修辞结构理论(rhetorical structure theory, RST)揭示多个文本单元之间的有效语义关联,并整合一系列推理模块来捕获有效证据. Sousa等[17 ] 通过添加基于知识图谱的推荐机制,来提高系统识别基线深度RE模型无法从文本中提取的真实关系的能力. Wang等[15 ] 提出KIRE架构,通过引入共指蒸馏来注入共指知识,赋予RE模型更广泛的共指推理能力,并通过表示协调来注入事实知识,将知识图谱表示和文档表示聚合到统一的空间中. Chen等[18 ] 提出利用阅读理解和先验知识进行生物医学关系抽取的方法. 实验结果显示,开放领域的阅读理解数据和知识表示有助于提高医学关系抽取能力. 为了更好地融合知识,Zhang等[19 ] 在因果方向的指导下有效地聚合了上下文和层次知识语义,提出GECANet架构,并证实融合外部知识可以有效地引导模型识别事件之间的因果关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
Biomedical relation extraction with knowledge graph-based recommendations
2
2022
... 此外,一些工作研究如何将外部知识注入到RE任务中以进一步提高性能. Wang等[16 ] 试图在新的文档级图RST-GRAPH上选择合适的证据并展示推理过程. RST-GRAPH通过修辞结构理论(rhetorical structure theory, RST)揭示多个文本单元之间的有效语义关联,并整合一系列推理模块来捕获有效证据. Sousa等[17 ] 通过添加基于知识图谱的推荐机制,来提高系统识别基线深度RE模型无法从文本中提取的真实关系的能力. Wang等[15 ] 提出KIRE架构,通过引入共指蒸馏来注入共指知识,赋予RE模型更广泛的共指推理能力,并通过表示协调来注入事实知识,将知识图谱表示和文档表示聚合到统一的空间中. Chen等[18 ] 提出利用阅读理解和先验知识进行生物医学关系抽取的方法. 实验结果显示,开放领域的阅读理解数据和知识表示有助于提高医学关系抽取能力. 为了更好地融合知识,Zhang等[19 ] 在因果方向的指导下有效地聚合了上下文和层次知识语义,提出GECANet架构,并证实融合外部知识可以有效地引导模型识别事件之间的因果关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
Biomedical relation extraction via knowledge-enhanced reading comprehension
2
2022
... 此外,一些工作研究如何将外部知识注入到RE任务中以进一步提高性能. Wang等[16 ] 试图在新的文档级图RST-GRAPH上选择合适的证据并展示推理过程. RST-GRAPH通过修辞结构理论(rhetorical structure theory, RST)揭示多个文本单元之间的有效语义关联,并整合一系列推理模块来捕获有效证据. Sousa等[17 ] 通过添加基于知识图谱的推荐机制,来提高系统识别基线深度RE模型无法从文本中提取的真实关系的能力. Wang等[15 ] 提出KIRE架构,通过引入共指蒸馏来注入共指知识,赋予RE模型更广泛的共指推理能力,并通过表示协调来注入事实知识,将知识图谱表示和文档表示聚合到统一的空间中. Chen等[18 ] 提出利用阅读理解和先验知识进行生物医学关系抽取的方法. 实验结果显示,开放领域的阅读理解数据和知识表示有助于提高医学关系抽取能力. 为了更好地融合知识,Zhang等[19 ] 在因果方向的指导下有效地聚合了上下文和层次知识语义,提出GECANet架构,并证实融合外部知识可以有效地引导模型识别事件之间的因果关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
Biomedical event causal relation extraction based on a knowledge-guided hierarchical graph network
3
2023
... 关系抽取(relation extraction,RE)旨在识别文本中实体之间的语义关系[1 ] . 早期的方法主要处理句子级关系抽取[2 -4 ] ,然而,许多关系分布在不同句子中[5 ] ,因此需要采用文档级关系抽取(document-level relation extraction,DRE)方法. 为了充分利用文档中复杂的语义信息(如词、句、依赖关系等),近期一些研究设计了文档级图,并提出基于图卷积神经网络(graph convolutional network,GCN)[6 ] 的模型[7 -9 ] . 此外,大规模领域知识库,如Wikidata、DBpedia、知识图谱等,也日渐成为信息提取的宝贵资源[10 -15 ] . 领域知识的注入为DRE预测增加了更多可用特征,进一步推动了DRE技术的发展[16 -19 ] . 尽管这些研究在DRE上的成果已十分显著,但2个主要问题限制了它们的发展. 1)对各类语义信息内部特征的重要性差异区分不足. 具体来说,这些方法通常只对文档中各个句子或提及内的词嵌入进行简单的数学运算(例如求和、求平均或池化),以获得实体的嵌入表示,而没有考虑不同词汇的贡献权重. 其次,GCN对文档级图中的全部节点平等对待,无法聚焦到更具指示性的特征. 2)知识资源的规模通常是有限且难以扩充的. 对于现有的知识库、知识图谱等知识表示形式而言,内容通常是静态固化的;知识扩展涉及到一系列复杂的知识整合流程(如实体消歧、知识对齐等),这使得模型在面对新的数据或知识域时泛化能力受限. ...
... 此外,一些工作研究如何将外部知识注入到RE任务中以进一步提高性能. Wang等[16 ] 试图在新的文档级图RST-GRAPH上选择合适的证据并展示推理过程. RST-GRAPH通过修辞结构理论(rhetorical structure theory, RST)揭示多个文本单元之间的有效语义关联,并整合一系列推理模块来捕获有效证据. Sousa等[17 ] 通过添加基于知识图谱的推荐机制,来提高系统识别基线深度RE模型无法从文本中提取的真实关系的能力. Wang等[15 ] 提出KIRE架构,通过引入共指蒸馏来注入共指知识,赋予RE模型更广泛的共指推理能力,并通过表示协调来注入事实知识,将知识图谱表示和文档表示聚合到统一的空间中. Chen等[18 ] 提出利用阅读理解和先验知识进行生物医学关系抽取的方法. 实验结果显示,开放领域的阅读理解数据和知识表示有助于提高医学关系抽取能力. 为了更好地融合知识,Zhang等[19 ] 在因果方向的指导下有效地聚合了上下文和层次知识语义,提出GECANet架构,并证实融合外部知识可以有效地引导模型识别事件之间的因果关系. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
2
... 基于序列的模型采用BERT[20 ] 之类的神经编码器来隐式地捕获文档中的依赖关系. Wang等[21 ] 使用BERT对文档进行编码,设计两步管道,预测2个实体之间是否存在关系,进而预测具体的关系类型. Zhou等[22 ] 提出本地化上下文池,将注意力从预训练的语言模型和自适应阈值转移到多标签和多实体问题. Xu等[23 ] 修改了BERT中的注意力机制,对实体之间的共指和共现结构进行建模,以更好地捕获上下文中的语义信息. ...
... 首先需要对语料库中的数据进行清洗,以去除无关信息,如页眉、页脚、图片说明等. 然后,对文档进行分句,为模型的输入做准备. 由于RoBERTa与BERT的整体结构基本相似,微调RoBERTa-base模型时借鉴Devlin等[20 ] 采用的技巧,以精化嵌入表示,进而更好地表示医学文档. ...
1
... 基于序列的模型采用BERT[20 ] 之类的神经编码器来隐式地捕获文档中的依赖关系. Wang等[21 ] 使用BERT对文档进行编码,设计两步管道,预测2个实体之间是否存在关系,进而预测具体的关系类型. Zhou等[22 ] 提出本地化上下文池,将注意力从预训练的语言模型和自适应阈值转移到多标签和多实体问题. Xu等[23 ] 修改了BERT中的注意力机制,对实体之间的共指和共现结构进行建模,以更好地捕获上下文中的语义信息. ...
1
... 基于序列的模型采用BERT[20 ] 之类的神经编码器来隐式地捕获文档中的依赖关系. Wang等[21 ] 使用BERT对文档进行编码,设计两步管道,预测2个实体之间是否存在关系,进而预测具体的关系类型. Zhou等[22 ] 提出本地化上下文池,将注意力从预训练的语言模型和自适应阈值转移到多标签和多实体问题. Xu等[23 ] 修改了BERT中的注意力机制,对实体之间的共指和共现结构进行建模,以更好地捕获上下文中的语义信息. ...
2
... 基于序列的模型采用BERT[20 ] 之类的神经编码器来隐式地捕获文档中的依赖关系. Wang等[21 ] 使用BERT对文档进行编码,设计两步管道,预测2个实体之间是否存在关系,进而预测具体的关系类型. Zhou等[22 ] 提出本地化上下文池,将注意力从预训练的语言模型和自适应阈值转移到多标签和多实体问题. Xu等[23 ] 修改了BERT中的注意力机制,对实体之间的共指和共现结构进行建模,以更好地捕获上下文中的语义信息. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
1
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
Cross-sentence N -ary relation extraction with graph LSTMs
1
2017
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
1
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
1
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
1
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
1
... 基于图的模型通过构建文档级图来捕获文档中的语义信息,并设计各种神经网络对构建的文档级图进行推理. Quirk等[24 ] 将文档中的单词建模为节点,将句子内/间的依赖关系建模为边. 基于这一思路,Peng等[25 ] 使用图长短期记忆模型,而Verga等[26 ] 使用Transformer[27 ] 对文档级图进行编码. 最近,关系抽取模型LSR[28 ] 、GLRE[7 ] 、GAIN[29 ] 和GCGCN[9 ] 定义更复杂的文档级图,以便在文档中保留更多的依赖信息. 与之不同的是,GRACR模型[8 ] 建立实体级图,并通过关系图卷积神经网络(relational GCNs, R-GCNs)实现实体节点之间的交互,以发现长距离跨句实体对的潜在关系. ...
2
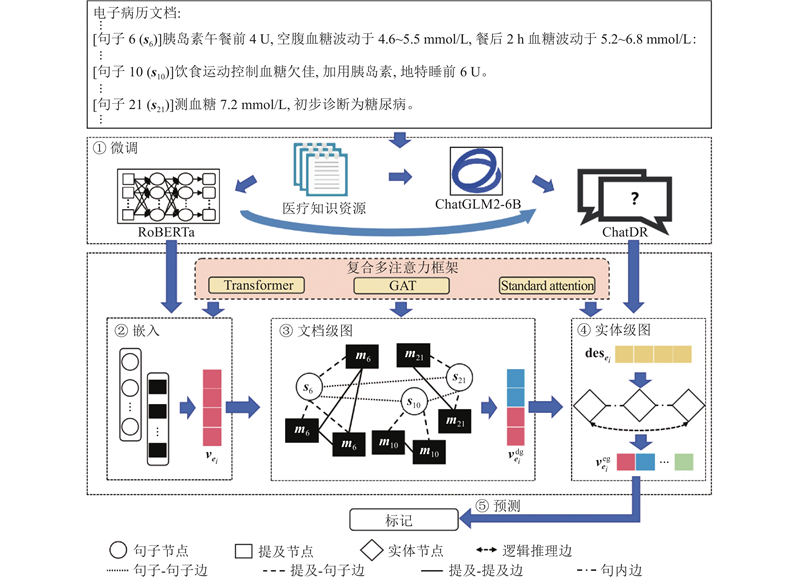
... 微调模块旨在将医学领域知识资源归纳到语言模型中,使其更好地适应医学相关任务,如图1 中①所示. 在本研究中,微调过程涉及RoBERTa[30 ] 语言模型微调和ChatGLM2-6B[31 ] 大语言模型微调2个部分. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
2
... 微调模块旨在将医学领域知识资源归纳到语言模型中,使其更好地适应医学相关任务,如图1 中①所示. 在本研究中,微调过程涉及RoBERTa[30 ] 语言模型微调和ChatGLM2-6B[31 ] 大语言模型微调2个部分. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
1
... ChatGLM2-6B是清华大学提出的大语言模型,相比于ChatGPT[32 ] 、LLaMA[33 ] 等超大规模大语言模型,其参数规模较小,支持本地离线指令微调. 此外,离线操作不涉及联网环节,有效避免了敏感数据在公网传输时可能出现的隐私泄露问题. 因此,ChatGLM2-6B更适用于本研究面向的真实医学文本相关任务. ChatGLM2-6B模型的微调数据是带有标签的中文医学数据,来自于公开数据以及合作医院提供的由专业医学团队标注的真实数据,涉及约3 682个文档,共计49 172个标准医学实体. 这些标准医学实体的背景知识描述信息由合作医院提供或通过百度百科检索获得. ...
2
... ChatGLM2-6B是清华大学提出的大语言模型,相比于ChatGPT[32 ] 、LLaMA[33 ] 等超大规模大语言模型,其参数规模较小,支持本地离线指令微调. 此外,离线操作不涉及联网环节,有效避免了敏感数据在公网传输时可能出现的隐私泄露问题. 因此,ChatGLM2-6B更适用于本研究面向的真实医学文本相关任务. ChatGLM2-6B模型的微调数据是带有标签的中文医学数据,来自于公开数据以及合作医院提供的由专业医学团队标注的真实数据,涉及约3 682个文档,共计49 172个标准医学实体. 这些标准医学实体的背景知识描述信息由合作医院提供或通过百度百科检索获得. ...
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...
1
... ChatGLM2-6B指令微调方法采用LoRA[34 ] 微调方法. 具体的指令微调过程涉及2个步骤. ...
1
... 对于给定的文档级图$ {\boldsymbol{G}}_{\mathrm{d}}=({\boldsymbol{V}}_{\mathrm{d}},{\boldsymbol{E}}_{\mathrm{d}}) $ [35 ] 对其进行学习. 与GCN相比,GAT集成的注意力机制能够更好地分辨特征的重要性差异,因而更适合对具有各种类型节点和边的图进行建模. 具体来说,GAT的计算过程如下: ...
1
... 对比实验结果如表1 所示. 可以看出,在所有评估指标下,LKCM模型的表现最好. 在13个基线模型中,对比多种基于序列、图结构、知识以及大语言模型的文档级关系抽取模型. 基于序列的方法RoBERTa-base[30 ] 和SSAN[23 ] 在捕捉局部上下文信息方面表现较好,但由于缺乏有效的全局信息整合能力,在处理跨句长距离关系方面,特别是当文档包含复杂的语义依赖时,其性能有所下降. 相比之下,基于图的方法(包括GCGCN[9 ] 、GLRE[7 ] 和GRACR[8 ] )通过构建文档级和实体级的图结构,有效地整合了文档中的全局信息,包括词特征、句特征、提及特征、依赖关系特征等各类语义特征,能够更好地推理实体之间的长距离关系,从而在预测跨句实体关系时表现较好. 其中, GLRE和GRACR通过使用异质图结构和关系图卷积网络(R-GCN)来捕捉各类语义特征,在复杂语义关系预测上取得了显著的效果. 然而,这些模型在特征提取方面存在一定的局限性,即没有充分区分各类语义信息内部特征间的重要性差异. 基于知识的方法(包括DISCO[16 ] 、K-BiOnt[17 ] 、KIRE[15 ] 、KRC[18 ] 和GECANet[19 ] )除了通过构建文档级图聚合数据内部的全局信息外,还引入外部知识资源(如知识库、知识图谱等)为模型注入更具指示性的信息,因此相比于其他通用模型,其表现得更为出色. 然而,由于知识库的规模限制和动态更新的困难,这些模型在处理新数据时面临一定的挑战. 基于大语言模型的方法(包括ChatGLM2-6B[31 ] ,LLaMA3-8B[33 ] 和Qwen-32B[36 ] )在所有基线模型中表现最差,主要原因可以归结为2点:1)架构差异. 其他基线模型均属于较小规模的模型,其网络结构是针对特定医学文档级关系抽取任务精心设计的. 相比之下,ChatGLM2-6B、 LLaMA3-8B和Qwen-32B由于网络结构复杂,很难集中研究与特定医学文档级关系抽取任务相关的特征. 此外,更少的参数和更紧凑的网络结构使得小模型更容易在有限的数据集上收敛. 大语言模型参数规模相对较大,虽然它可以通过指令微调来适应特定领域的文档级关系抽取任务,但这通常需要极为庞大的标注数据集,而这种数据集很难获得. 2)特定领域知识的差异. 小模型如DISCO、K-BiOnt、KIRE、KRC和GECANet,集成了来自外部医学资源的特定领域知识. 这些知识往往是丰富而广泛的,因此通过设计更精细的损失函数来充分利用这些知识,模型可以学习到更多有价值的信息和独特的见解,从而有效地提高准确率. 相比之下,初始大语言模型的知识通常来自于通用领域,缺乏深入、专业的特定领域知识,很难分辨特征之间的细微差别. LKCM模型结合了图结构和大语言模型的优势,在DRE任务中达到了87.47%的最高F1分数,这主要得益于两个方面:一方面,通过设计复合多注意力机制,显著提升了模型对各类语义信息内部特征重要性差异的区分能力. 另一方面,通过引入ChatGLM2-6B大语言模型作为动态领域知识库组件,能够在模型学习过程中动态地提供特定领域知识来指导模型学习,从而提高了模型的适应能力和预测精度. ...



{kind=link}
{kind=link}