[1]
张冬冬, 王春平, 付强 伪装目标检测研究进展
[J]. 激光杂志 , 2024 , 45 (3 ): 1 - 13
[本文引用: 1]
ZHANG Dongdong, WANG Chunping, FU Qiang Research developments in camouflage object detection
[J]. Laser Journal , 2024 , 45 (3 ): 1 - 13
[本文引用: 1]
[2]
SUN Y, CHEN G, ZHOU T, et al. Context-aware cross-level fusion network for camouflaged object detection [EB/OL]. [2025-05-29]. https://arxiv.org/abs/2105.12555.
[本文引用: 3]
[3]
REN J, HU X, ZHU L, et al Deep texture-aware features for camouflaged object detection
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2021 , 33 (3 ): 1157 - 1167
[本文引用: 1]
[4]
JI G P, FAN D P, CHOU Y C, et al Deep gradient learning for efficient camouflaged object detection
[J]. Machine Intelligence Research , 2023 , 20 (1 ): 92 - 108
DOI:10.1007/s11633-022-1365-9
[本文引用: 3]
[5]
SUN Y, WANG S, CHEN C, et al. Boundary-guided camouflaged object detection [C]// International Joint Conference on Artificial Intelligence . Shenzhen: Morgan Kaufmann, 2022: 335-1341.
[本文引用: 3]
[6]
CHEN Tianrun, ZHU Lanyun, DENG Chaotao, et al. SAM2-Adapter: evaluating and adapting segment anything 2 in downstream tasks: camouflage, shadow, medical image segmentation, and more [EB/OL]. [2024-10-19]. https://arxiv.org/abs/2408.04579.
[本文引用: 1]
[7]
NIKHILA R, VALENTIN G, HU Y, et al. SAM 2: segment anything in images and videos [EB/OL]. [2024-10-19]. https://arxiv.org/abs/2408.00714.
[本文引用: 1]
[8]
CHEN G, WANG H, CHEN K, et al A survey of the four pillars for small object detection: multiscale representation, contextual information, super-resolution, and region proposal
[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems , 2020 , 52 (2 ): 936 - 953
[本文引用: 1]
[9]
LIU Y, LI H, CHENG J, et al MSCAF-net: a general framework for camouflaged object detection via learning multi-scale context-aware features
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2023 , 33 (9 ): 4934 - 4947
DOI:10.1109/TCSVT.2023.3245883
[本文引用: 3]
[10]
WOO S, DEBNATH S, HU R, et al. Convnext v2: co-designing and scaling convnets with masked autoencoders [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 16133-16142.
[本文引用: 1]
[11]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[12]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. [2025-05-29]. https://arxiv.org/abs/2010.11929.
[本文引用: 1]
[13]
WU Z, SU L, HUANG Q. Cascaded partial decoder for fast and accurate salient object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3907-3916.
[本文引用: 1]
[14]
ZHAO J X, LIU J J, FAN D P, et al. EGNet: edge guidance network for salient object detection [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 8779-8788.
[本文引用: 1]
[15]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// European Conference on Computer Vision . Munich: Springer, 2018: 3-19.
[本文引用: 1]
[16]
MILLETARI F, NAVAB N, AHMADI S A. V-net: fully convolutional neural networks for volumetric medical image segmentation [C]// International Conference on 3D Vision. California: IEEE, 2016: 565-571.
[本文引用: 1]
[17]
LE T N, NGUYEN T V, NIE Z, et al Anabranch network for camouflaged object segmentation
[J]. Computer Vision and Image Understanding , 2019 , 184 : 45 - 56
DOI:10.1016/j.cviu.2019.04.006
[本文引用: 1]
[18]
FAN D P, JI G P, SUN G, et al. Camouflaged object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2777-2787.
[本文引用: 3]
[19]
LV Y, ZHANG J, DAI Y, et al. Simultaneously localize, segment and rank the camouflaged objects [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 11591-11601.
[本文引用: 1]
[20]
FAN D P, JI G P, CHENG M M, et al Concealed object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 44 (10 ): 6024 - 6042
[本文引用: 2]
[21]
XING H, GAO S, WANG Y, et al Go closer to see better: camouflaged object detection via object area amplification and figure-ground conversion
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2023 , 33 (10 ): 5444 - 5457
DOI:10.1109/TCSVT.2023.3255304
[本文引用: 1]
[22]
JIA Q, YAO S, LIU Y, et al. Segment, magnify and reiterate: detecting camouflaged objects the hard way [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 4713-4722.
[本文引用: 1]
[23]
SONG Z, KANG X, WEI X, et al Fsnet: focus scanning network for camouflaged object detection
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 2267 - 2278
DOI:10.1109/TIP.2023.3266659
[本文引用: 1]
[24]
HU X, WANG S, QIN X, et al. High-resolution iterative feedback network for camouflaged object detection [C]// AAAI Conference on Artificial Intelligence . Washington: AAAI, 2023, 37(1): 881-889.
[本文引用: 1]
[25]
PANG Y, ZHAO X, XIANG T Z, et al. Zoom in and out: a mixed-scale triplet network for camouflaged object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 2160-2170.
[本文引用: 2]
伪装目标检测研究进展
1
2024
... 近年来,伪装目标检测(camouflage object detection, COD)与识别研究得到了飞速发展,该任务旨在识别视觉上“完美”嵌入周围环境的目标[1 ] . 当前该任务主要面临的挑战如下:如何在复杂环境中准确地识别伪装对象;当面临遮挡时,如何判断遮挡物是物体的一部分;如何处理多尺度、多视角、多模态的图像数据等. ...
伪装目标检测研究进展
1
2024
... 近年来,伪装目标检测(camouflage object detection, COD)与识别研究得到了飞速发展,该任务旨在识别视觉上“完美”嵌入周围环境的目标[1 ] . 当前该任务主要面临的挑战如下:如何在复杂环境中准确地识别伪装对象;当面临遮挡时,如何判断遮挡物是物体的一部分;如何处理多尺度、多视角、多模态的图像数据等. ...
3
... 针对这些问题,Sun等[2 ] 利用注意力引导特征融合,设计C2F-Net模型,基于上下文感知跨层融合网络,用于伪装目标检测. Ren等[3 ] 提出TANet,通过计算协方差矩阵来提取纹理信息,放大伪装目标与周围环境之间的纹理差异性,然而网络在学习的过程中忽略了上下文信息,网络的性能有待提高. Ji等[4 ] 基于置信感知学习策略,提出DGNet深度梯度学习模型,可以在抑制背景噪声的同时检测纹理模式,进而检测伪装目标. 缺少边缘信息的引导会导致在边缘干扰或者目标轮廓处于伪装时,难以完整地识别目标的结构和细节,尤其是在小目标区域中难以提取到足够的纹理信息,导致预测出来的目标具有模糊的边界. Sun等[5 ] 提出边界引导网络BGNet,该网络通过探索有价值和额外与目标边界相关的语义信息来指导COD表征学习,生成凸显目标结构的特征来定位伪装目标的边界. Chen等[6 ] 通过研究SAM2[7 ] (segment anything, SAM)在一些复杂的低层级分割任务中的表现,提出新的适配器SAM2-Adapter. 这种适配器通过在大模型训练时注入预先设计的Adapter的方式,提升其针对特定任务的性能. 由于Adapter需要在训练时单独设计,导致模型的复杂程度增加,还对模型的使用者提出了较高的要求. ...
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
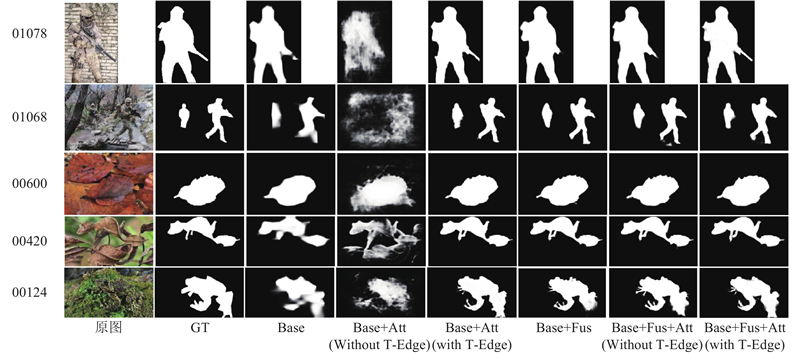
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
Deep texture-aware features for camouflaged object detection
1
2021
... 针对这些问题,Sun等[2 ] 利用注意力引导特征融合,设计C2F-Net模型,基于上下文感知跨层融合网络,用于伪装目标检测. Ren等[3 ] 提出TANet,通过计算协方差矩阵来提取纹理信息,放大伪装目标与周围环境之间的纹理差异性,然而网络在学习的过程中忽略了上下文信息,网络的性能有待提高. Ji等[4 ] 基于置信感知学习策略,提出DGNet深度梯度学习模型,可以在抑制背景噪声的同时检测纹理模式,进而检测伪装目标. 缺少边缘信息的引导会导致在边缘干扰或者目标轮廓处于伪装时,难以完整地识别目标的结构和细节,尤其是在小目标区域中难以提取到足够的纹理信息,导致预测出来的目标具有模糊的边界. Sun等[5 ] 提出边界引导网络BGNet,该网络通过探索有价值和额外与目标边界相关的语义信息来指导COD表征学习,生成凸显目标结构的特征来定位伪装目标的边界. Chen等[6 ] 通过研究SAM2[7 ] (segment anything, SAM)在一些复杂的低层级分割任务中的表现,提出新的适配器SAM2-Adapter. 这种适配器通过在大模型训练时注入预先设计的Adapter的方式,提升其针对特定任务的性能. 由于Adapter需要在训练时单独设计,导致模型的复杂程度增加,还对模型的使用者提出了较高的要求. ...
Deep gradient learning for efficient camouflaged object detection
3
2023
... 针对这些问题,Sun等[2 ] 利用注意力引导特征融合,设计C2F-Net模型,基于上下文感知跨层融合网络,用于伪装目标检测. Ren等[3 ] 提出TANet,通过计算协方差矩阵来提取纹理信息,放大伪装目标与周围环境之间的纹理差异性,然而网络在学习的过程中忽略了上下文信息,网络的性能有待提高. Ji等[4 ] 基于置信感知学习策略,提出DGNet深度梯度学习模型,可以在抑制背景噪声的同时检测纹理模式,进而检测伪装目标. 缺少边缘信息的引导会导致在边缘干扰或者目标轮廓处于伪装时,难以完整地识别目标的结构和细节,尤其是在小目标区域中难以提取到足够的纹理信息,导致预测出来的目标具有模糊的边界. Sun等[5 ] 提出边界引导网络BGNet,该网络通过探索有价值和额外与目标边界相关的语义信息来指导COD表征学习,生成凸显目标结构的特征来定位伪装目标的边界. Chen等[6 ] 通过研究SAM2[7 ] (segment anything, SAM)在一些复杂的低层级分割任务中的表现,提出新的适配器SAM2-Adapter. 这种适配器通过在大模型训练时注入预先设计的Adapter的方式,提升其针对特定任务的性能. 由于Adapter需要在训练时单独设计,导致模型的复杂程度增加,还对模型的使用者提出了较高的要求. ...
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
3
... 针对这些问题,Sun等[2 ] 利用注意力引导特征融合,设计C2F-Net模型,基于上下文感知跨层融合网络,用于伪装目标检测. Ren等[3 ] 提出TANet,通过计算协方差矩阵来提取纹理信息,放大伪装目标与周围环境之间的纹理差异性,然而网络在学习的过程中忽略了上下文信息,网络的性能有待提高. Ji等[4 ] 基于置信感知学习策略,提出DGNet深度梯度学习模型,可以在抑制背景噪声的同时检测纹理模式,进而检测伪装目标. 缺少边缘信息的引导会导致在边缘干扰或者目标轮廓处于伪装时,难以完整地识别目标的结构和细节,尤其是在小目标区域中难以提取到足够的纹理信息,导致预测出来的目标具有模糊的边界. Sun等[5 ] 提出边界引导网络BGNet,该网络通过探索有价值和额外与目标边界相关的语义信息来指导COD表征学习,生成凸显目标结构的特征来定位伪装目标的边界. Chen等[6 ] 通过研究SAM2[7 ] (segment anything, SAM)在一些复杂的低层级分割任务中的表现,提出新的适配器SAM2-Adapter. 这种适配器通过在大模型训练时注入预先设计的Adapter的方式,提升其针对特定任务的性能. 由于Adapter需要在训练时单独设计,导致模型的复杂程度增加,还对模型的使用者提出了较高的要求. ...
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
1
... 针对这些问题,Sun等[2 ] 利用注意力引导特征融合,设计C2F-Net模型,基于上下文感知跨层融合网络,用于伪装目标检测. Ren等[3 ] 提出TANet,通过计算协方差矩阵来提取纹理信息,放大伪装目标与周围环境之间的纹理差异性,然而网络在学习的过程中忽略了上下文信息,网络的性能有待提高. Ji等[4 ] 基于置信感知学习策略,提出DGNet深度梯度学习模型,可以在抑制背景噪声的同时检测纹理模式,进而检测伪装目标. 缺少边缘信息的引导会导致在边缘干扰或者目标轮廓处于伪装时,难以完整地识别目标的结构和细节,尤其是在小目标区域中难以提取到足够的纹理信息,导致预测出来的目标具有模糊的边界. Sun等[5 ] 提出边界引导网络BGNet,该网络通过探索有价值和额外与目标边界相关的语义信息来指导COD表征学习,生成凸显目标结构的特征来定位伪装目标的边界. Chen等[6 ] 通过研究SAM2[7 ] (segment anything, SAM)在一些复杂的低层级分割任务中的表现,提出新的适配器SAM2-Adapter. 这种适配器通过在大模型训练时注入预先设计的Adapter的方式,提升其针对特定任务的性能. 由于Adapter需要在训练时单独设计,导致模型的复杂程度增加,还对模型的使用者提出了较高的要求. ...
1
... 针对这些问题,Sun等[2 ] 利用注意力引导特征融合,设计C2F-Net模型,基于上下文感知跨层融合网络,用于伪装目标检测. Ren等[3 ] 提出TANet,通过计算协方差矩阵来提取纹理信息,放大伪装目标与周围环境之间的纹理差异性,然而网络在学习的过程中忽略了上下文信息,网络的性能有待提高. Ji等[4 ] 基于置信感知学习策略,提出DGNet深度梯度学习模型,可以在抑制背景噪声的同时检测纹理模式,进而检测伪装目标. 缺少边缘信息的引导会导致在边缘干扰或者目标轮廓处于伪装时,难以完整地识别目标的结构和细节,尤其是在小目标区域中难以提取到足够的纹理信息,导致预测出来的目标具有模糊的边界. Sun等[5 ] 提出边界引导网络BGNet,该网络通过探索有价值和额外与目标边界相关的语义信息来指导COD表征学习,生成凸显目标结构的特征来定位伪装目标的边界. Chen等[6 ] 通过研究SAM2[7 ] (segment anything, SAM)在一些复杂的低层级分割任务中的表现,提出新的适配器SAM2-Adapter. 这种适配器通过在大模型训练时注入预先设计的Adapter的方式,提升其针对特定任务的性能. 由于Adapter需要在训练时单独设计,导致模型的复杂程度增加,还对模型的使用者提出了较高的要求. ...
A survey of the four pillars for small object detection: multiscale representation, contextual information, super-resolution, and region proposal
1
2020
... Chen等[8 ] 的研究表明,上下文信息对于提高小目标检测、外观模糊目标检测和遮挡目标检测的准确性具有重要意义,这同样适用于伪装目标检测问题. 在关注纹理信息的同时,要重视上下文和边缘信息. 在此背景下,结合Convnext能够通过具有不同尺度和深度的卷积层来捕获图像中的不同特征,更好地适应复杂图像场景,能够更准确地识别图像和背景的优势. ...
MSCAF-net: a general framework for camouflaged object detection via learning multi-scale context-aware features
3
2023
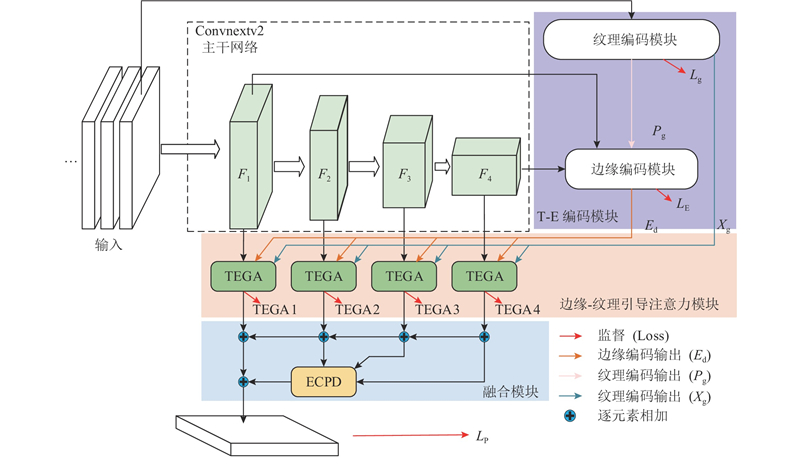
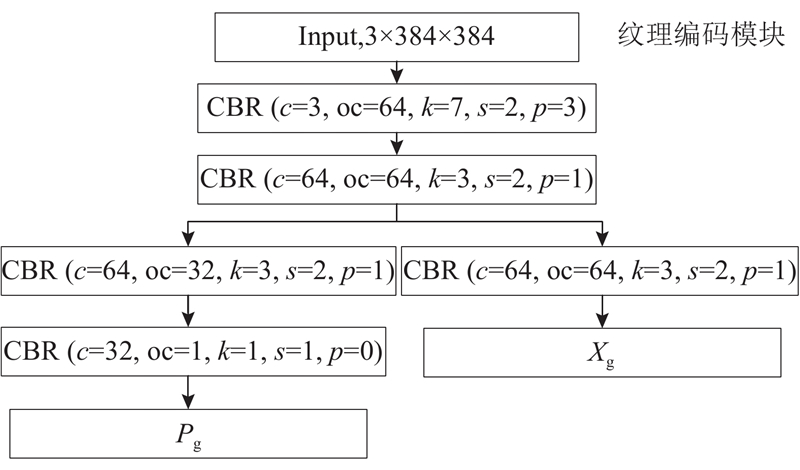
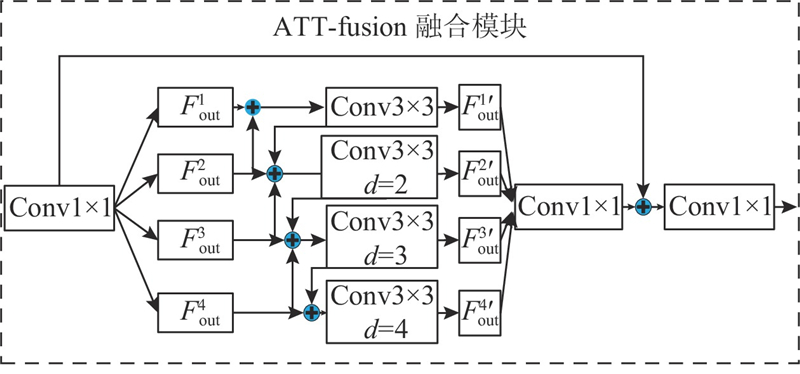
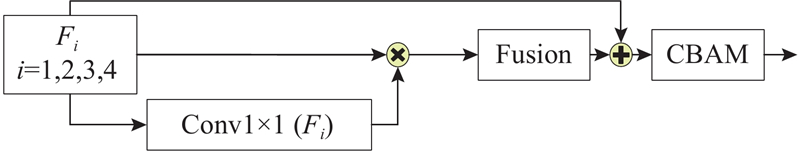
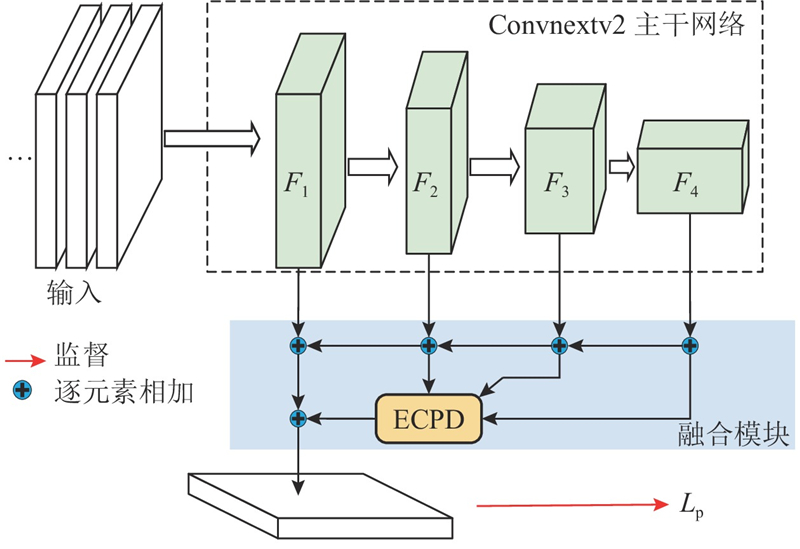
... 提出基于Convnextv2与纹理边缘引导特征融合的伪装目标检测算法,整体结构如图1 所示. 给定的输入为原始图像,图像采用3通道输入,高、宽分别为H 和W . 对于纹理-边缘特征的提取部分,受DGNet与MSCSF[9 ] 算法的启发,设计融合边缘信息与图片纹理特征的纹理边缘编码器(texture-edge encoder). 将提取到的图片纹理特征与边缘特征进行融合,得到带有边缘增强后的图片特征. 将增强后的图片特征作为辅助特征融入到边缘注意力机制中,使得网络在目标所在区域具有更高的关注度. CTEGAFNet网络主要由4个部分组成,主干部分的多级特征提取采用Convnextv2[10 ] . Convnext网络是在CNN和transform结构的基础上,通过将ResNet[11 ] 重新构建得到纯卷积神经网络. Convnext在取得与VisionTransformer[12 ] 相当的准确性和可扩展性的同时,保持了标准卷积神经网络的简洁性和高效性. 对主干网络Convnextv2中特定层次的多级特征与纹理边缘编码器处理后,输出至纹理-边缘引导注意力融合模块(texture-edge guided attention,TEGA)进行预测区域的引导. 通过扩展联级解码器[13 ] (extend cascaded partial decoder,ECPD),将ECPD得到的初步预测图与纹理-边缘引导注意力模块输出的特征相加进行多层次特征融合,输出最终的目标预测结果. ...
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
1
... 提出基于Convnextv2与纹理边缘引导特征融合的伪装目标检测算法,整体结构如图1 所示. 给定的输入为原始图像,图像采用3通道输入,高、宽分别为H 和W . 对于纹理-边缘特征的提取部分,受DGNet与MSCSF[9 ] 算法的启发,设计融合边缘信息与图片纹理特征的纹理边缘编码器(texture-edge encoder). 将提取到的图片纹理特征与边缘特征进行融合,得到带有边缘增强后的图片特征. 将增强后的图片特征作为辅助特征融入到边缘注意力机制中,使得网络在目标所在区域具有更高的关注度. CTEGAFNet网络主要由4个部分组成,主干部分的多级特征提取采用Convnextv2[10 ] . Convnext网络是在CNN和transform结构的基础上,通过将ResNet[11 ] 重新构建得到纯卷积神经网络. Convnext在取得与VisionTransformer[12 ] 相当的准确性和可扩展性的同时,保持了标准卷积神经网络的简洁性和高效性. 对主干网络Convnextv2中特定层次的多级特征与纹理边缘编码器处理后,输出至纹理-边缘引导注意力融合模块(texture-edge guided attention,TEGA)进行预测区域的引导. 通过扩展联级解码器[13 ] (extend cascaded partial decoder,ECPD),将ECPD得到的初步预测图与纹理-边缘引导注意力模块输出的特征相加进行多层次特征融合,输出最终的目标预测结果. ...
1
... 提出基于Convnextv2与纹理边缘引导特征融合的伪装目标检测算法,整体结构如图1 所示. 给定的输入为原始图像,图像采用3通道输入,高、宽分别为H 和W . 对于纹理-边缘特征的提取部分,受DGNet与MSCSF[9 ] 算法的启发,设计融合边缘信息与图片纹理特征的纹理边缘编码器(texture-edge encoder). 将提取到的图片纹理特征与边缘特征进行融合,得到带有边缘增强后的图片特征. 将增强后的图片特征作为辅助特征融入到边缘注意力机制中,使得网络在目标所在区域具有更高的关注度. CTEGAFNet网络主要由4个部分组成,主干部分的多级特征提取采用Convnextv2[10 ] . Convnext网络是在CNN和transform结构的基础上,通过将ResNet[11 ] 重新构建得到纯卷积神经网络. Convnext在取得与VisionTransformer[12 ] 相当的准确性和可扩展性的同时,保持了标准卷积神经网络的简洁性和高效性. 对主干网络Convnextv2中特定层次的多级特征与纹理边缘编码器处理后,输出至纹理-边缘引导注意力融合模块(texture-edge guided attention,TEGA)进行预测区域的引导. 通过扩展联级解码器[13 ] (extend cascaded partial decoder,ECPD),将ECPD得到的初步预测图与纹理-边缘引导注意力模块输出的特征相加进行多层次特征融合,输出最终的目标预测结果. ...
1
... 提出基于Convnextv2与纹理边缘引导特征融合的伪装目标检测算法,整体结构如图1 所示. 给定的输入为原始图像,图像采用3通道输入,高、宽分别为H 和W . 对于纹理-边缘特征的提取部分,受DGNet与MSCSF[9 ] 算法的启发,设计融合边缘信息与图片纹理特征的纹理边缘编码器(texture-edge encoder). 将提取到的图片纹理特征与边缘特征进行融合,得到带有边缘增强后的图片特征. 将增强后的图片特征作为辅助特征融入到边缘注意力机制中,使得网络在目标所在区域具有更高的关注度. CTEGAFNet网络主要由4个部分组成,主干部分的多级特征提取采用Convnextv2[10 ] . Convnext网络是在CNN和transform结构的基础上,通过将ResNet[11 ] 重新构建得到纯卷积神经网络. Convnext在取得与VisionTransformer[12 ] 相当的准确性和可扩展性的同时,保持了标准卷积神经网络的简洁性和高效性. 对主干网络Convnextv2中特定层次的多级特征与纹理边缘编码器处理后,输出至纹理-边缘引导注意力融合模块(texture-edge guided attention,TEGA)进行预测区域的引导. 通过扩展联级解码器[13 ] (extend cascaded partial decoder,ECPD),将ECPD得到的初步预测图与纹理-边缘引导注意力模块输出的特征相加进行多层次特征融合,输出最终的目标预测结果. ...
1
... 提出基于Convnextv2与纹理边缘引导特征融合的伪装目标检测算法,整体结构如图1 所示. 给定的输入为原始图像,图像采用3通道输入,高、宽分别为H 和W . 对于纹理-边缘特征的提取部分,受DGNet与MSCSF[9 ] 算法的启发,设计融合边缘信息与图片纹理特征的纹理边缘编码器(texture-edge encoder). 将提取到的图片纹理特征与边缘特征进行融合,得到带有边缘增强后的图片特征. 将增强后的图片特征作为辅助特征融入到边缘注意力机制中,使得网络在目标所在区域具有更高的关注度. CTEGAFNet网络主要由4个部分组成,主干部分的多级特征提取采用Convnextv2[10 ] . Convnext网络是在CNN和transform结构的基础上,通过将ResNet[11 ] 重新构建得到纯卷积神经网络. Convnext在取得与VisionTransformer[12 ] 相当的准确性和可扩展性的同时,保持了标准卷积神经网络的简洁性和高效性. 对主干网络Convnextv2中特定层次的多级特征与纹理边缘编码器处理后,输出至纹理-边缘引导注意力融合模块(texture-edge guided attention,TEGA)进行预测区域的引导. 通过扩展联级解码器[13 ] (extend cascaded partial decoder,ECPD),将ECPD得到的初步预测图与纹理-边缘引导注意力模块输出的特征相加进行多层次特征融合,输出最终的目标预测结果. ...
1
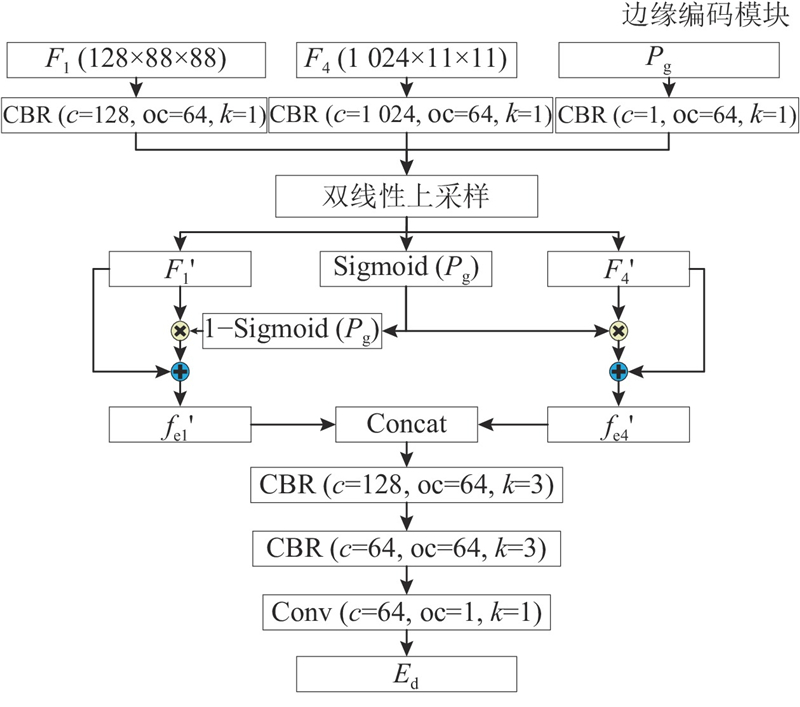
... 边缘特征提取是通过边缘编码模块,使用Convnextv2主干网络中的F 1 、F 4 特征层来生成图片的边缘. 选择这两层的原因是第1层次的特征层中包含更多的边缘信息,第4层特征包含较高的语义信息[14 ] . 通过结合这2个层次的特征,能够更有效地捕捉与目标边界相关的边缘语义信息. 在融合了纹理特征后,能够帮助网络更好地定位和分割伪装目标,过程如下所示. ...
1
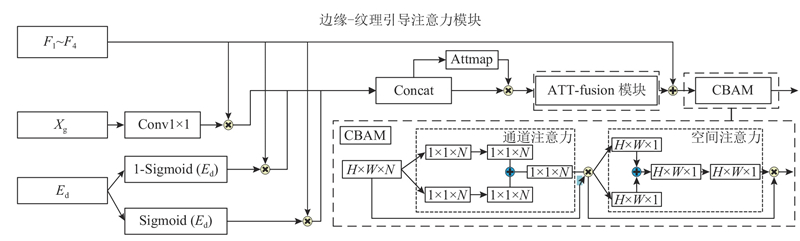
... 为了增强这些关键信息来辅助网络对识别伪装目标区域的定位和分割,引入新的纹理边缘引导注意力模块(texture-edge guide attention, TEGA). 该模块在纹理-边缘辅助模块和Convnext骨干网络所提取的特征路径间运行. 将Convnextv2主干网络的多级特征X i 、纹理编码模块学习到的纹理特征X g 与预测的边缘E d 作为该模块的输入. 采用双线性插值,将纹理特征和边缘特征的大小调整至主干网络对应特征的大小. 将边缘特征经过归一化处理后,分别与主干特征相乘得到一组前景、背景和边缘的注意力特征图. 纹理特征与主干特征进行逐元素相乘后,得到增强纹理的主干特征. 将这3个增强特征拼接起来得到注意力图,经过残差结构后进行融合增强操作,再将主干特征与注意力特征图求和. 使用卷积块注意力模块(convolutional block attention module, CBAM[15 ] )处理输出,过程如下所示. ...
1
... 在边缘检测部分,采用Dice损失函数,对Canny边缘算子处理得到的基准真实值(ground truth,GT)和边缘图像进行监督,构成L d [16 ] , ...
Anabranch network for camouflaged object segmentation
1
2019
... 针对伪装目标检测,在以下3个常用的基准数据集上进行实验:CAMO[17 ] 、COD10K[18 ] 和NC4K[19 ] . 在试验中,将CAMO和COD10K的训练集组合作为训练样本,共4 040张图像. 将CAMO的测试集作为验证样本,图片数量为250张. 将CAMO、COD10K、NC4K的测试集作为测试样本. 在针对迷彩人员的目标检测实验中,将CPD1k数据集和Kaggle上的ACD1K数据集进行融合. 由于CPD1k没有进行数据集的划分,将CPD1K数据集图片按照7︰3的比例划分为训练集和验证集,并将其与ACD1K结合,得到MICAI数据集. MICAI训练集的图片数量为2 568张,验证集的图片数量为1 110张. ...
3
... 针对伪装目标检测,在以下3个常用的基准数据集上进行实验:CAMO[17 ] 、COD10K[18 ] 和NC4K[19 ] . 在试验中,将CAMO和COD10K的训练集组合作为训练样本,共4 040张图像. 将CAMO的测试集作为验证样本,图片数量为250张. 将CAMO、COD10K、NC4K的测试集作为测试样本. 在针对迷彩人员的目标检测实验中,将CPD1k数据集和Kaggle上的ACD1K数据集进行融合. 由于CPD1k没有进行数据集的划分,将CPD1K数据集图片按照7︰3的比例划分为训练集和验证集,并将其与ACD1K结合,得到MICAI数据集. MICAI训练集的图片数量为2 568张,验证集的图片数量为1 110张. ...
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
1
... 针对伪装目标检测,在以下3个常用的基准数据集上进行实验:CAMO[17 ] 、COD10K[18 ] 和NC4K[19 ] . 在试验中,将CAMO和COD10K的训练集组合作为训练样本,共4 040张图像. 将CAMO的测试集作为验证样本,图片数量为250张. 将CAMO、COD10K、NC4K的测试集作为测试样本. 在针对迷彩人员的目标检测实验中,将CPD1k数据集和Kaggle上的ACD1K数据集进行融合. 由于CPD1k没有进行数据集的划分,将CPD1K数据集图片按照7︰3的比例划分为训练集和验证集,并将其与ACD1K结合,得到MICAI数据集. MICAI训练集的图片数量为2 568张,验证集的图片数量为1 110张. ...
Concealed object detection
2
2021
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
Go closer to see better: camouflaged object detection via object area amplification and figure-ground conversion
1
2023
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
1
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
Fsnet: focus scanning network for camouflaged object detection
1
2023
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
1
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...
2
... 为了保证实验的公平性,在COD数据集上参与对比的11种算法(网络)[2 ,4 ,5 ,9 ,18 ,20 -25 ] 均采用笔者所提供的图像结果,在同一设备上进行对比,而缺少图像结果的算法将按照笔者提供的开源源码进行训练后再测试性能的结果. 对于缺少图像结果的网络,在重新训练后不作视觉结果的展示. 在迷彩伪装目标检测任务中,统一在MICAI数据集上进行训练,并在验证集上进行验证. 由于目前COD领域的研究没有考虑伪装对象的类别信息,该模型没有分类输出. 评价指标采用COD常用的4个指标:结构度量${S_\alpha }$ ${E_\phi }$ ${F_\beta ^{\omega}}$
... 挑选的11种主流的伪装目标检测分别是经典算法SINet[18 ] 、SINetV2[20 ] 、采用注意力系数丰富全局上下文信息的算法C2FNet[2 ] 、采用交替关注前景与背景信息的算法SARNet[21 ] 、采用多阶段迭代框架的算法SegMaR[22 ] 、在预测区域捕捉结构细节的算法FSNet[23 ] 、采用高分辨率迭代反馈的算法HitNet[24 ] 、采用边缘引导的算法BGNet[5 ] 、关注待测目标纹理的轻量化算法 DGNet[4 ] 、采用三元联合学习策略的 ZoomNet[25 ] 、关注纹理和上下文特征融合的算法 MSCAF[9 ] . 为了公平起见,所有数据均采用相同的评估代码进行评估. 最终的定量对比结果如表1 、2 所示. 其中,N p 为参数量,黑色加粗字体表示最优结果. 为了能够说明算法之间结果的差异性,采用检测结果视觉比较的方式进行展示,如图6 所示. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}