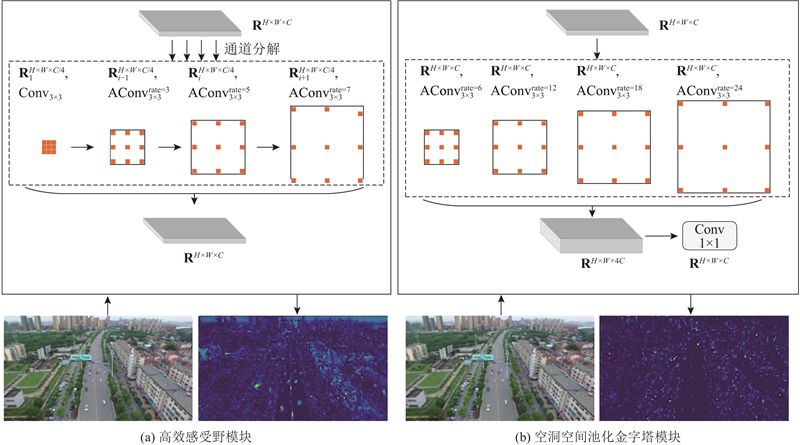
一方面,较大的扩张率可以确保感受野充分地扩展,另一方面过大的扩张率会加剧网格效应,对无人机图像中的一些小目标特征提取不利. 本研究分析扩张率大小对分割结果的影响. 扩张率的大小参考文献[21 ],Liu等使用扩张率为{1,3,5}的卷积组并结合不同大小的卷积核扩展感受野. 在数据集UAVid中对基于堆叠连接的ERFB使用扩张率为{1,3,5}、{3,5,7}、{5,7,9}的卷积组进行消融研究,mIoU分别为70.1%、70.6%和70.4%,由此可知,ERFB的扩张率设置为{3,5,7}时效果较好.
[1]
LI R, ZHENG S, DUAN C, et al Land cover classification from remote sensing images based on multi-scale fully convolutional network
[J]. Geo-spatial Information Science , 2022 , 25 (2 ): 278 - 294
DOI:10.1080/10095020.2021.2017237
[本文引用: 1]
[2]
SHI W, ZHANG M, KE H, et al Landslide recognition by deep convolutional neural network and change detection
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2021 , 59 (6 ): 4654 - 4672
DOI:10.1109/TGRS.2020.3015826
[本文引用: 1]
[3]
GRIFFITHS D, BOEHM J Improving public data for building segmentation from convolutional neural networks (CNNs) for fused airborne lidar and image data using active contours
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2019 , 154 : 70 - 83
DOI:10.1016/j.isprsjprs.2019.05.013
[本文引用: 1]
[4]
刘毅, 陈一丹, 高琳, 等 基于多尺度特征融合的轻量化道路提取模型
[J]. 浙江大学学报: 工学版 , 2024 , 58 (5 ): 951 - 959
[本文引用: 2]
LIU Yi, CHEN Yidan, GAO Lin, et al Lightweight road extraction model based on multi-scale feature fusion
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (5 ): 951 - 959
[本文引用: 2]
[5]
ZHU X X, TUIA D, MOU L, et al Deep learning in remote sensing: a comprehensive review and list of resources
[J]. IEEE Geoscience and Remote Sensing Magazine , 2017 , 5 (4 ): 8 - 36
DOI:10.1109/MGRS.2017.2762307
[本文引用: 1]
[6]
吴泽康, 赵姗, 李宏伟, 等 遥感图像语义分割空间全局上下文信息网络
[J]. 浙江大学学报: 工学版 , 2022 , 56 (4 ): 795 - 802
[本文引用: 1]
WU Zekang, ZHAO Shan, LI Hongwei, et al Spatial global context information network for semantic segmentation of remote sensing image
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (4 ): 795 - 802
[本文引用: 1]
[8]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431–3440.
[本文引用: 2]
[9]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6230–6239.
[本文引用: 3]
[10]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 40 (4 ): 834 - 848
DOI:10.1109/TPAMI.2017.2699184
[本文引用: 1]
[11]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 833–851.
[本文引用: 2]
[12]
SHI X, HUANG H, PU C, et al CSA-UNet: channel-spatial attention-based encoder–decoder network for rural blue-roofed building extraction from UAV imagery
[J]. IEEE Geoscience and Remote Sensing Letters , 2022 , 19 : 6514405
[本文引用: 1]
[13]
XU R, WANG C, ZHANG J, et al RSSFormer: foreground saliency enhancement for remote sensing land-cover segmentation
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 1052 - 1064
DOI:10.1109/TIP.2023.3238648
[本文引用: 2]
[14]
YU C, WANG J, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 334–349.
[本文引用: 3]
[15]
YU C, GAO C, WANG J, et al BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation
[J]. International Journal of Computer Vision , 2021 , 129 (11 ): 3051 - 3068
DOI:10.1007/s11263-021-01515-2
[本文引用: 1]
[16]
WANG L, LI R, ZHANG C, et al UNetFormer: a UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2022 , 190 : 196 - 214
DOI:10.1016/j.isprsjprs.2022.06.008
[本文引用: 4]
[17]
WADEKAR S N, CHAURASIA A. MobileViTv3: mobile-friendly vision transformer with simple and effective fusion of local, global and input features [EB/OL]. (2022–10–06) [2024–08–31]. https://arxiv.org/abs/2209.15159.
[本文引用: 2]
[18]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[19]
LYU Y, VOSSELMAN G, XIA G S, et al UAVid: a semantic segmentation dataset for UAV imagery
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2020 , 165 : 108 - 119
DOI:10.1016/j.isprsjprs.2020.05.009
[本文引用: 1]
[20]
WANG J, ZHENG Z, MA A, et al. LoveDA: a remote sensing land-cover dataset for domain adaptive semantic segmentation [EB/OL]. (2021–10–17)[2024–08–31]. https://arxiv.org/abs/2110.08733.
[本文引用: 1]
[21]
LIU S, HUANG D, WANG Y. Receptive field block net for accurate and fast object detection [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 404–419.
[本文引用: 1]
[22]
WANG L, LI R, WANG D, et al Transformer meets convolution: a bilateral awareness network for semantic segmentation of very fine resolution urban scene images
[J]. Remote Sensing , 2021 , 13 (16 ): 3065
DOI:10.3390/rs13163065
[本文引用: 1]
[23]
XU W, XU Y, CHANG T, et al. Co-scale conv-attentional image transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 9961–9970.
[本文引用: 1]
[24]
STRUDEL R, GARCIA R, LAPTEV I, et al. Segmenter: transformer for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 7242–7252.
[本文引用: 1]
[25]
WANG L, LI R, DUAN C, et al A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images
[J]. IEEE Geoscience and Remote Sensing Letters , 2022 , 19 : 6506105
[本文引用: 1]
Land cover classification from remote sensing images based on multi-scale fully convolutional network
1
2022
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
Landslide recognition by deep convolutional neural network and change detection
1
2021
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
Improving public data for building segmentation from convolutional neural networks (CNNs) for fused airborne lidar and image data using active contours
1
2019
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
基于多尺度特征融合的轻量化道路提取模型
2
2024
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
基于多尺度特征融合的轻量化道路提取模型
2
2024
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
Deep learning in remote sensing: a comprehensive review and list of resources
1
2017
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
遥感图像语义分割空间全局上下文信息网络
1
2022
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
遥感图像语义分割空间全局上下文信息网络
1
2022
... 无人机技术的广泛运用使得遥感图像的获取手段更加多样化. 利用装载相机的无人机既可实现高空大范围全局监测,也可实现低空小范围精确监测,推进了土地资源管理[1 ] 、环境监测[2 ] 、道路检测[3 ] 、城市规划[4 ] 等城市相关应用的发展. 从无人机遥感图像数据[5 ] 分析图像内容并得到关键目标信息的过程称为无人机遥感影像的解译,图像语义分割是实现解译的关键技术. 语义分割旨在通过图像中的光谱、纹理、形状等信息,得到图像中每个像素的类别信息[6 ] . 传统语义分割方法通过提取图像阈值、区域、边缘等形态学的方式实现对图像中不同物体的分割. 无人机遥感影像成像范围灵活,图像分辨率高、信息量大,传统的语义分割方法很难充分提取影像中的信息. ...
Deep learning
1
2015
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
2
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
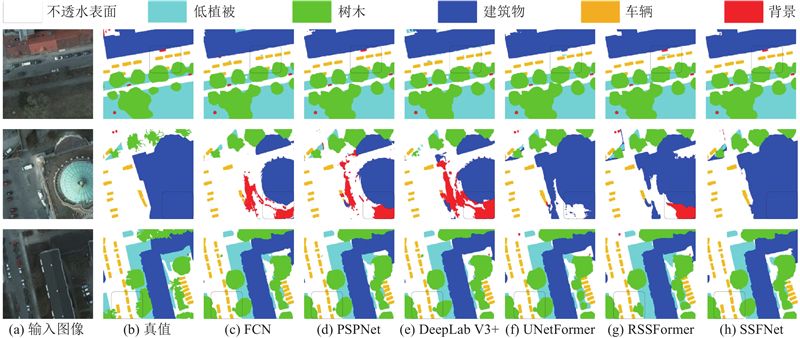
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
3
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
... 参考PSPNet[9 ] 和UNetFormer[16 ] 的设计,设定常量$ \alpha $
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
1
2018
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
2
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
CSA-UNet: channel-spatial attention-based encoder–decoder network for rural blue-roofed building extraction from UAV imagery
1
2022
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
RSSFormer: foreground saliency enhancement for remote sensing land-cover segmentation
2
2023
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
3
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
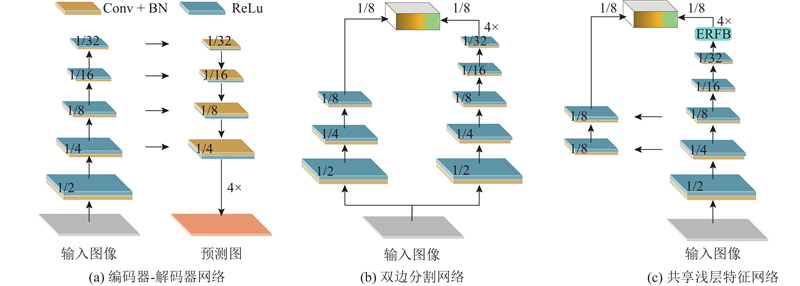
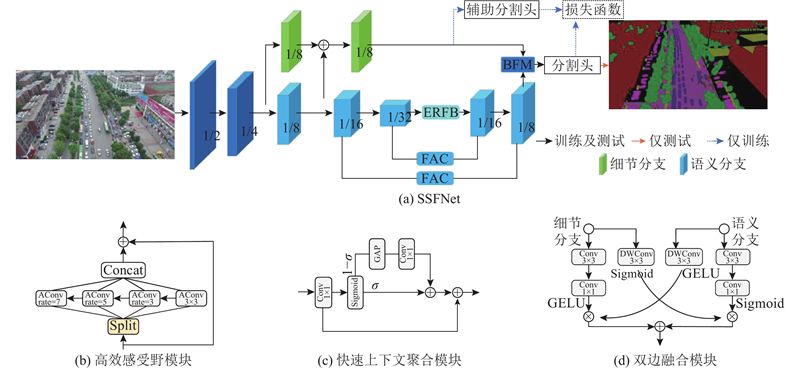
... FCN的发展促进了图像语义分割发展,特别是在推理效率上,基于CNN的模型比其他方法效率高. 这些模型的效率差别与它们的网络结构相关. 编码器-解码器网络和双边分割网络是2种常用的语义分割网络结构类型. 在编码器-解码器网络中,通过添加横向连接来恢复高分辨率特征图[16 ] ,这会导致高昂的访问成本和过度处理冗余信息. 编码器-解码器网络是单流网络,它们连续地从单个图像中提取特征,没有充分考虑图像中的两级特征及其融合. 为了实现高效的语义分割并较好地融合图像中的多级特征,双边分割网络被提出[14 ] . 该架构主要由2个分支组成:一个是具有浅层结构用于提取低级细节的细节分支,另一个是具有深层结构用于捕获高级语义信息的语义分支. 双分支网络以并行的方式提取特征,可以实现较快的推理速度,但在初始下采样阶段仍存在冗余. 本研究提出共享浅层特征的双分支分割网络,能够促进细节分支和语义分支之间的特征融合,形成更紧凑的结构. 具体来说,语义分支下采样时采用ResNet18[18 ] 作为主干网络,细节分支共享语义分支1/4和1/8位置的特征. 共享的特征使得2个分支之间的联系更紧密,减少了双边网络的参数量,提高了推理效率. 3种语义分割网络的架构如图1 所示. ...
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation
1
2021
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
UNetFormer: a UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery
4
2022
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
... FCN的发展促进了图像语义分割发展,特别是在推理效率上,基于CNN的模型比其他方法效率高. 这些模型的效率差别与它们的网络结构相关. 编码器-解码器网络和双边分割网络是2种常用的语义分割网络结构类型. 在编码器-解码器网络中,通过添加横向连接来恢复高分辨率特征图[16 ] ,这会导致高昂的访问成本和过度处理冗余信息. 编码器-解码器网络是单流网络,它们连续地从单个图像中提取特征,没有充分考虑图像中的两级特征及其融合. 为了实现高效的语义分割并较好地融合图像中的多级特征,双边分割网络被提出[14 ] . 该架构主要由2个分支组成:一个是具有浅层结构用于提取低级细节的细节分支,另一个是具有深层结构用于捕获高级语义信息的语义分支. 双分支网络以并行的方式提取特征,可以实现较快的推理速度,但在初始下采样阶段仍存在冗余. 本研究提出共享浅层特征的双分支分割网络,能够促进细节分支和语义分支之间的特征融合,形成更紧凑的结构. 具体来说,语义分支下采样时采用ResNet18[18 ] 作为主干网络,细节分支共享语义分支1/4和1/8位置的特征. 共享的特征使得2个分支之间的联系更紧密,减少了双边网络的参数量,提高了推理效率. 3种语义分割网络的架构如图1 所示. ...
... 参考PSPNet[9 ] 和UNetFormer[16 ] 的设计,设定常量$ \alpha $
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
2
... 随着图形处理器(graphics processing unit,GPU)的性能大幅度提升,基于深度学习[7 ] 的语义分割方法在计算机视觉领域大放异彩. Long等[8 ] 提出的全卷积网络(fully convolutional network,FCN)将传统卷积神经网络(convolutional neural network,CNN)中的全连接层替换成卷积层,显著提高了语义分割的准确性. Zhao等[9 ] 设计金字塔场景解析网络(pyramid scene parsing network,PSPNet),通过并联多个不同尺度的池化层实现金字塔池化模块,提高了对不同尺度目标的分割效果. Chen等[10 -11 ] 提出DeepLab系列网络,设计出空洞空间池化金字塔(atrous spatial pyramid pooling,ASPP)模块,利用不同采样率的空洞卷积(atrous convolution,AConv)提取多尺度特征. Shi等[12 ] 基于编码器-解码器网络,将空间和通道注意力用于提取无人机图像中的建筑物,改善了特征信息丢失的问题. Xu等[13 ] 提出基于Transformer的自适应融合模块,这种自适应融合模块在融合多尺度特征时可以自适应地抑制背景噪声并增强目标显著性. 诸多学者在语义分割网络的运行效率方面进行探索,Yu等[14 -15 ] 提出BiSeNet系列算法,使用并行的双分支网络结构分别提取图像的空间细节信息和语义上下文信息,实现了高效的语义分割. Wang等[16 ] 提出UNetFormer算法,通过压缩解码器通道的数量来提升推理效率. Wadekar等[17 ] 提出MobileViT系列算法,将倒残差结构的CNN加入Transformer,以减少Transformer模型的大小和计算需求. 刘毅等[4 ] 提出基于多尺度特征融合的轻量化道路提取模型,在ASPP中引入深度可分离卷积,不仅减少了ASPP的参数量,而且降低了计算复杂度. ...
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
1
... FCN的发展促进了图像语义分割发展,特别是在推理效率上,基于CNN的模型比其他方法效率高. 这些模型的效率差别与它们的网络结构相关. 编码器-解码器网络和双边分割网络是2种常用的语义分割网络结构类型. 在编码器-解码器网络中,通过添加横向连接来恢复高分辨率特征图[16 ] ,这会导致高昂的访问成本和过度处理冗余信息. 编码器-解码器网络是单流网络,它们连续地从单个图像中提取特征,没有充分考虑图像中的两级特征及其融合. 为了实现高效的语义分割并较好地融合图像中的多级特征,双边分割网络被提出[14 ] . 该架构主要由2个分支组成:一个是具有浅层结构用于提取低级细节的细节分支,另一个是具有深层结构用于捕获高级语义信息的语义分支. 双分支网络以并行的方式提取特征,可以实现较快的推理速度,但在初始下采样阶段仍存在冗余. 本研究提出共享浅层特征的双分支分割网络,能够促进细节分支和语义分支之间的特征融合,形成更紧凑的结构. 具体来说,语义分支下采样时采用ResNet18[18 ] 作为主干网络,细节分支共享语义分支1/4和1/8位置的特征. 共享的特征使得2个分支之间的联系更紧密,减少了双边网络的参数量,提高了推理效率. 3种语义分割网络的架构如图1 所示. ...
UAVid: a semantic segmentation dataset for UAV imagery
1
2020
... 选择UAVid数据集[19 ] 、LoveDA[20 ] 和Postdam数据集来验证网络的性能. ...
1
... 选择UAVid数据集[19 ] 、LoveDA[20 ] 和Postdam数据集来验证网络的性能. ...
1
... 一方面,较大的扩张率可以确保感受野充分地扩展,另一方面过大的扩张率会加剧网格效应,对无人机图像中的一些小目标特征提取不利. 本研究分析扩张率大小对分割结果的影响. 扩张率的大小参考文献[21 ],Liu等使用扩张率为{1,3,5}的卷积组并结合不同大小的卷积核扩展感受野. 在数据集UAVid中对基于堆叠连接的ERFB使用扩张率为{1,3,5}、{3,5,7}、{5,7,9}的卷积组进行消融研究,mIoU分别为70.1%、70.6%和70.4%,由此可知,ERFB的扩张率设置为{3,5,7}时效果较好. ...
Transformer meets convolution: a bilateral awareness network for semantic segmentation of very fine resolution urban scene images
1
2021
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
1
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
1
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...
A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images
1
2022
... 将SSFNet与其他先进的分割算法在3数据集上进行性能对比,这些算法包括FCN[8 ] 、BiSeNet[14 ] 、PSPNet[9 ] 、DeepLab V3+[11 ] 、BANet[22 ] 、CoaT[23 ] 、SegFormer[24 ] 、DC- Swin[25 ] 、UNetFormer[16 ] 、MobileViT V3[17 ] 和RSSFormer[13 ] . 分析不同算法的规模及推理速度,测试时的输入分辨率为1 024×1 024像素,测试设备为RTX 3090 GPU,结果如表4 所示. SSFNet的参数量为13.1×106 ,规模较其他算法小;与BiSeNet、BANet、SegFormer、UNetFormer和MobileViT V3等规模相似的模型相比,SSFNet的推理速度最快. 该结果表明SSFNet的网络架构紧凑. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}