

当前目标检测领域的主流算法包括两阶段的R-CNN[3]和Fast R-CNN[4]算法,和一阶段的SSD[5]、YOLO[6]算法以及基于Transformer的目标检测算法DETR[7]. 其中两阶段目标检测算法首先产生候选框,然后对其内容进行特征提取,最后对区域内容进行目标回归,具有较高的检测精度,但对候选框的筛选过程导致检测速度较慢. 一阶段目标检测算法采用基于回归的算法,将分类和定位任务进行合并,以获得较快的检测速度,但检测精度较低. Transformer的目标检测算法DETR是基于对象查询的方法,可一次性对整张图像中的目标进行检测,避免了传统滑动窗口方法的低速问题. 然而在钢材表面缺陷领域,因终端设备计算能力有限,深度学习算法在实际部署上仍然面临巨大挑战.
为了解决上述挑战,一些研究者提出了轻量级钢材表面缺陷检测模型. 例如,Zhou等[8]提出YOLOv5s-GCE轻量级钢材表面缺陷检测模型,通过引入鬼影模块和坐标注意力机制来优化模型的计算量和参数量,然而该模型对于小目标的检测精度较低. Qin等[9]将EfficientNet网络作为骨干特征提取网络,设计EDDNet模型,有效减少了计算开销. Yang等[10]构建CBAM-MobilenetV2-YOLOv5模型,利用MobilenetV2模块和卷积块注意力模块使模型更加轻量化. 张政超等[11]改进YOLOv5模型,使用轻量化ShuffleNetv2作为骨干网络,大大降低模型的复杂度,并在检测速度方面具有优势. 蔡剑锋等[12]将MobileNet引入Mask RCNN目标检测框架,作为骨干特征提取网络,成功降低了模型的参数量和计算量. 此外,卷积操作的局部性限制了CNN获取全局上下文信息的能力,而Transformer可以全局关注不同区域图像特征之间的关系,并通过自注意力机制来提取充分的特征信息. 因此,研究者尝试将Transformer应用于钢材表面缺陷图像目标检测. 例如,阎馨等[13]引入Involution算子和Transformer多头注意力模块,提升模型的检测精度并降低计算资源的使用. 上述研究优化了计算量较大的目标检测算法,但在钢材表面缺陷检测领域,仍须在满足终端设备部署的同时平衡检测精度和速度.
鉴于上述研究的局限性,以YOLOv8s为基线模型,提出轻量化的钢材缺陷检测算法SDB-YOLOv8s(S-C2f+DilateFormer+BS-ShuffleNetV2, SDB). 本研究主要创新点如下:1)对数据集进行增强处理;2)结合S-C2f模块、DilateFormer (Dilated Transformer)模块和BS-ShuffleNetV2骨干网络构建SDB-YOLOv8s算法;3)在NEU-DET和Severstal数据集对上对SDB-YOLOv8s算法进行实验验证.
1. YOLOv8s模型
YOLOv8是YOLO系列目标检测模型的最新版本,由Ultralyticsgongs团队于2023年发布. 该算法是YOLO系列算法的集大成者,在以前YOLO系列的成功基础上进行创新和改进,改进主要包括:1)创建新的主干网络,将YOLOv5中的C3结构换成梯度流更丰富的C2f模块;2)使用新的Ancher-Free作为检测头,采用主流的解耦头结构将分类与检测头分离;3)采用新的Distribution Focal Loss作为损失函数,并使用TaskAlignedAssigner的动态正态样本分配策略. YOLOv8提供了5种不同尺寸的模型:纳米、小型、中型、大型和超大型,为了平衡检测精度和速度,选用YOLOv8s作为钢材缺陷检测的基线模型. 该网络由输入端、骨干网络、特征融合网络和预测网络4部分组成,分别用于特征输入、特征提取、特征融合和预测输出.
2. 本研究模型
2.1. SDB-YOLOv8s模型
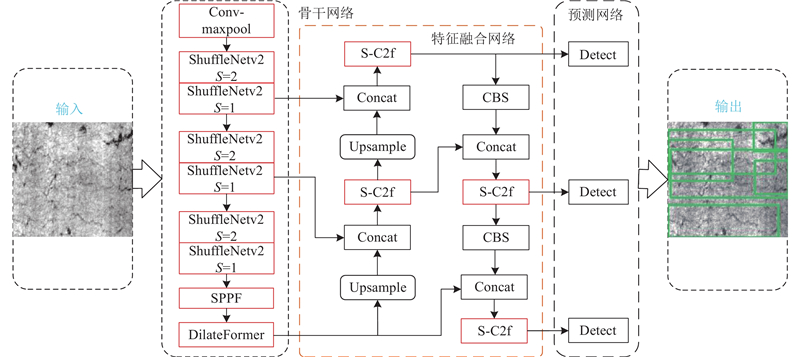
提出轻量级的SDB-YOLOv8s检测模型,用于快速准确地检测钢材表面形态多样、结构复杂的缺陷. SDB-YOLOv8s模型首先设计S-C2f模块代替原Neck网络的C2f模块,抑制空间和通道维度上的冗余信息,提升网络检测精度;此外,特征图经过主干网络多次下采样操作后,分辨率降低,为了避免细节信息丢失,在骨干网络的最底端添加空洞TransFormer,使网络具备滑动稀疏采样特性,减少细粒度信息损失,保持较高的特征分辨率,并更好地利用前面层次提取到的多尺度特征信息,从而提高网络的特征提取能力;最后设计轻量级BS-ShuffleNetV2网络替代原始YOLOv8s的主干网络,在维持较高精度的同时极大优化模型的参数量和计算复杂度. 改进部分在图中用红框部分表示,SDB-YOLOv8s的网络结构如图1所示.
图 1
2.2. S-C2f模块
C2f是一种特征图转换模块,旨在将低层次的特征图转换成高层次的特征图. 然而,该模块使用较大的卷积核进行下采样,导致部分细节语义信息丢失,从而降低检测性能. 此外,C2f模块采用深层网络结构,导致计算复杂度较高,使模型的训练和推理速度变慢. 为了解决这个问题,Li等[14]提出空间和通道重建卷积(spatial and channel reconstruction convolution, ScConv),通过重建特征图的空间和通道信息,更好地捕获不同位置和不同通道之间的相关性,从而抑制冗余信息,提高检测能力. 受文献[14]启发,在C2f模块中融入ScConv,重新设计特征交互模块(S-C2f). 该模块可以更好地捕获特征之间的相关性,抑制冗余信息,并提高检测能力. 此外,S-C2f模块采用轻量级的操作和特征重建方式,降低计算复杂度,使模型的训练和推理速度更快,S-C2f和ScConv结构如图2所示.
图 2
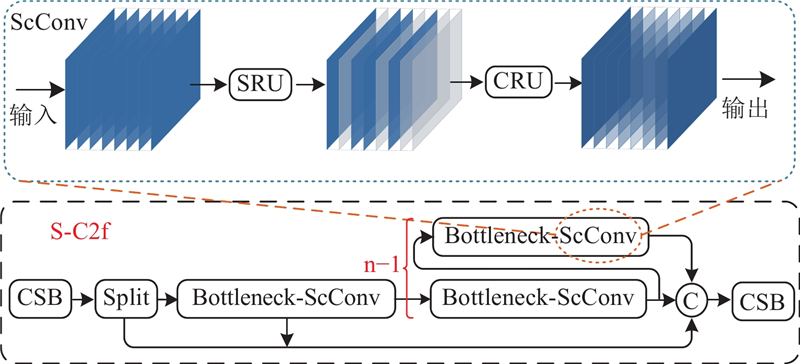
ScConv主要包含空间重组单元(spatial reconstruction unit, SRU)和通道重组单元(channel reconstruction unit, CRU) 2个结构. SRU网络结构如图3所示,该单元采用分离-重构操作.
图 3
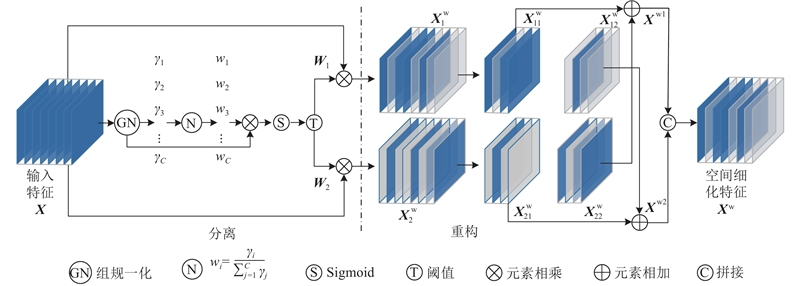
分离过程首先通过组归一化(group normalization,GN)中的缩放因子对不同特征图中的信息含量进行评估,将信息量大的特征从信息量的小的特征中进行分离;然后经
式中:
在经分离操作后,得到2个加权特征
式中:
CRU单元主要用于优化通道维度上
图 4
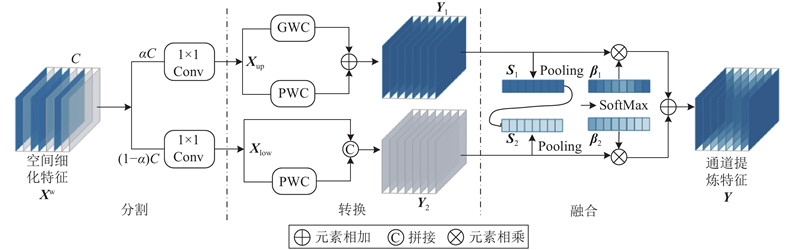
分割操作:首先将SRU生成的空间细化特征
转换操作:首先将压缩后的特征
式中:
融合操作:采用简化的SKNet方法对
式中:
2.3. Dilated Transformer
图 5
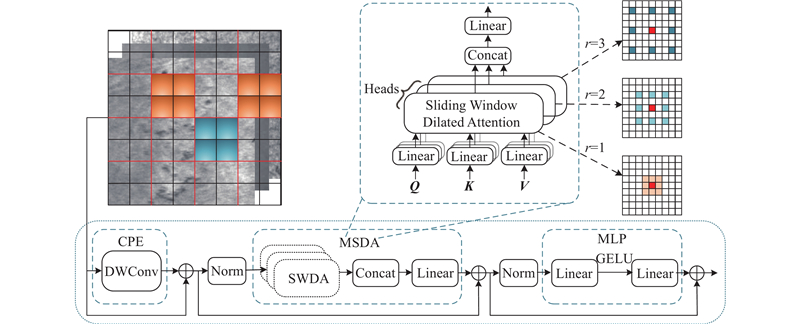
MSDA采用滑动窗口注意力(sliding window dilated attention, SWDA)进行设计,SWDA中的键(key)和值(value)通过以查询补丁为中心的滑动窗口稀疏选择,然后对代表性补丁进行自注意力计算,在数学上可表示为
式中:
式中:
式中:
MSDA首先将特征图在通道维度上分成多个头,在不同头中使用不同的空洞系数对query周围的patch进行采样;然后将不同头的计算结果进行拼接;最后采用线性层对其进行计算,在数学可表示为
式中:
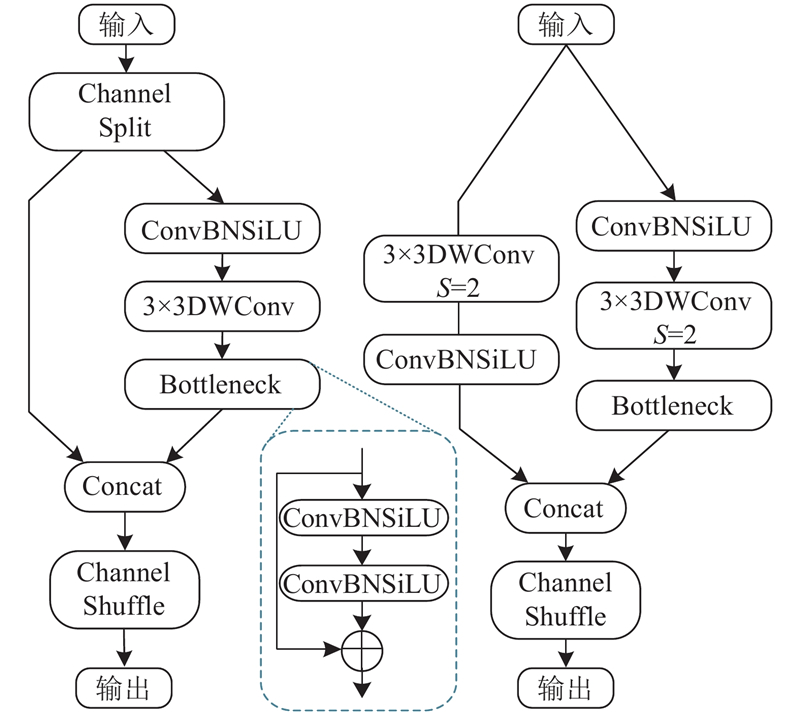
2.4. BS-ShuffleNetV2网络
YOLOv8采用DarkNet-53作为主干网络,该网络由一系列卷积层和残差模块堆叠而成. 然而,DarkNet-53参数量和计算复杂度过高,限制了训练和推理速度,不适合边缘设备部署.
图 6
3. 实验结果及分析
3.1. 数据集
图 7

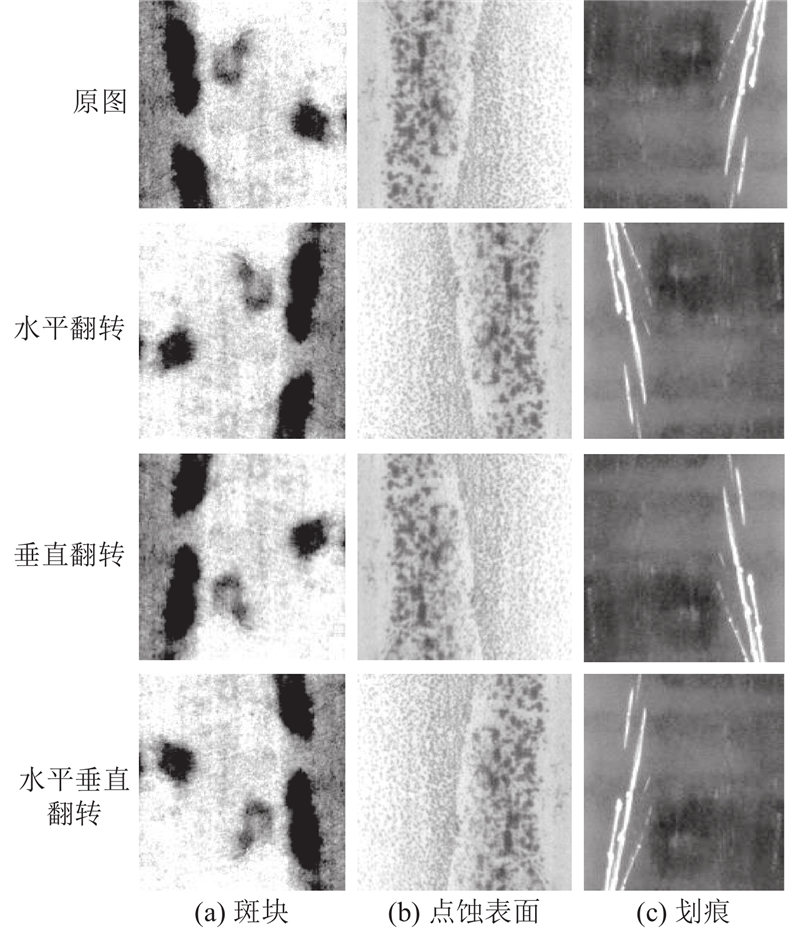
3.2. 数据增强
为了增强模型的泛化性能和鲁棒性,减少过拟合的影响,对Severstal数据集进行数据增强,包括水平翻转、垂直翻转和水平垂直翻转. 原数据集和扩充后数据集比例为1∶3. 如图8所示展示了部分原图和增强后的图像示例. 对于训练集和验证集,2个数据集均采用6∶2∶2的比例进行随机划分.
图 8
3.3. 实验环境与参数设置
在Windows11操作系统下进行实验,采用Pytorch1.11.0作为深度学习框架,CPU为Intel Core i7-12700H,GPU为RTX4060,显卡为8 GB. 在训练阶段,采用Adam作为优化器,初始学习率为0.01,动量为0.973,权重衰减因子为
3.4. 评价指标
采用6个指标对网络性能进行评估,包括平均精度(average precision, AP)、平均精度均值(mean AP, mAP)、每秒检测帧数(frames per second, FPS)、参数量(params)和浮点操作次数(floating-point operations, FLOPs),上述指标的定义式如下:
式中:AP表示P-R曲线与坐标轴围成的面积;mAP为对所有类别的AP求平均值所得;
3.5. 改进模块实验
3.5.1. S-C2f模块实验
针对SsConv模块中SRU单元的阈值权重进行门控调节,在NEU-DET数据集上,通过调节9个阈值(0.1~0.9),验证对指标提升效果最佳的权重,实验结果如表1所示,其中加粗表示最优值. 表中,Params为参数量,FLOPs为计算开销. 可以看出,当SUR单元的权重阈值在(0,1.0)进行门控时,9种情况所带来的参数量和计算开销一致,相比于基线模型均降低了0.8×106和1.9×109,表明SUR单元能有效抑制空间维度冗余信息并提高检测精度. 其中阈值为0.3时取得77.2%的最优值. 相较于原模型提升4.4个百分点,且优于其他阈值选取的情况,FPS也在原模型基础上提升10帧. 综上所述,当阈值设为0.3时,SRU单元对网络的贡献能力最佳.
表 1 SRU不同权重阈值对比实验
Tab.1
| T | mAP/% | Params/106 | FLOPs/109 | FPS/帧 |
| 基线模型 | 72.8 | 11.1 | 28.8 | 109 |
| 0.1 | 74.4 | 10.3 | 26.9 | 112 |
| 0.2 | 74.9 | 10.3 | 26.9 | 117 |
| 0.3 | 77.2 | 10.3 | 26.9 | 119 |
| 0.4 | 74.4 | 10.3 | 26.9 | 119 |
| 0.5 | 75.2 | 10.3 | 26.9 | 129 |
| 0.6 | 74.2 | 10.3 | 26.9 | 119 |
| 0.7 | 73.3 | 10.3 | 26.9 | 121 |
| 0.8 | 75.0 | 10.3 | 26.9 | 123 |
| 0.9 | 75.2 | 10.3 | 26.9 | 120 |
此外,为了验证S-C2f模块替换YOLOv8s中C2f模块在不同位置对网络性能的贡献能力,在NEU-DET数据集上进行3种情况的实验验证,实验结果如表2所示. 其中,B、C和D分别表示替换主干、颈部和整个模型,加粗表示最优值.可以看出,综合考虑4个指标,情况D虽然具备更明显的轻量化优势,参数量和计算量仅为原模型的83.7%和85.4%. 但与情况C相比,在检测精度和速度方面均不具备优势. 情况C的FPS相较于原模型提升20帧,mAP达到77.2%,均为最优. 此外,参数量和计算量相对于原模型分别降低0.8×106和1.9×109,在具备检测精度和速度优势的同时兼顾了参数量和计算量. 之所以只替换颈部的效果最好,可能是因为颈部是特征融合的关键节点,融入SsConv模块后可以最大程度增强特征表达能力,使不同尺度的特征更好地融合,有效捕捉关键细节和上下文信息,从而提升检测效果.
表 2 S-C2f模块不同位置实验
Tab.2
| 位置 | mAP/% | Params/106 | FLOPs/109 | FPS/帧 |
| 基线模型 | 72.8 | 11.1 | 28.8 | 109 |
| B | 74.8 | 10.3 | 26.5 | 108 |
| C | 77.2 | 10.3 | 26.9 | 129 |
| D | 73.6 | 9.3 | 24.5 | 101 |
3.5.2. DilateFormer模块实验
针对DilateFormer模块中的空洞系数进行调节,在NEU-DET数据集上,通过调节3个空洞系数(r=1, 2, 3),验证对指标提升效果最佳的取值,实验结果如表3所示,其中加粗表示最优值.可以看出,3个空洞系数所带来的参数量和计算开销一致,且都带来检测精度的提升. 但当选择空洞系数为1时,以损失最少检测速度的代价换来检测精度最佳的提升,可能是因为当空洞系数为1时,DilateFormer不进行卷积操作,能较好地保持网络上下文信息的丰富性,同时避免过度扩张导致的信息冗余和过多的计算消耗,从而最大程度提高了检测精度和速度. 综上所述,当空洞系数设为1时,DilateForme对网络的贡献能力最佳.
表 3 DilateFormer系数调节实验
Tab.3
| r | mAP/% | Params/106 | FLOPs/109 | FPS/帧 |
| 基线模型 | 72.8 | 11.1 | 28.8 | 109 |
| 1 | 75.8 | 12.3 | 28.7 | 104 |
| 2 | 75.3 | 12.3 | 28.7 | 101 |
| 3 | 74.7 | 12.3 | 28.7 | 99 |
3.5.3. BS-ShuffleNetV2网络对比实验
为了验证改进BS-ShuffleNetV2主干网络的有效性,在NEU-DET数据集上与A:DarkNet-53(基线模型)、E:ShuffleNetV2、F:VanillaNet网络进行对比,实验结果如表4所示,其中加粗表示最优值.可以看出,将DarkNet-53替换成轻量化的ShuffleNetV2网络后参数量和计算量分别减少4.9×106和13.2×109,FPS提升108帧,且mAP相比于原模型降低0.3个百分点,表明ShuffleNetV2网络具有良好的轻量化特性,但无法有效平衡检测精度和轻量化问题;在将VanillaNet作为基线模型的主干网络时,虽然mAP、参数量、计算量和检测速度均得到一定改善,但相较于本研究设计的BS-ShuffleNetV2网络仍存在不足. 相比之下,本研究BS-ShuffleNetV2网络以损失微小参数量和计算量为代价,实现检测性能的提升,mAP达到74.0%. 在DarkNet-53、VanillaNet和ShuffleNetV2网络的基础上分别提升1.2、1.0和1.5个百分点,同时,其速度与ShuffleNetV2网络一致. 因此,本研究BS-ShuffleNetV2网络具备合理性和优越性.
表 4 改进BS-ShuffleNetV2对比实验
Tab.4
| 模型 | mAP/% | Params/106 | FLOPs/109 | FPS/帧 |
| A | 72.8 | 11.1 | 28.8 | 109 |
| E | 73.0 | 6.4 | 16.4 | 183 |
| F | 72.5 | 6.2 | 15.6 | 217 |
| 本研究 | 74.0 | 6.4 | 16.5 | 217 |
3.6. 消融实验
以YOLOv8s为基线模型,对其进行3个方面的改进,构建了SDB-YOLOv8s模型,通过在NEU-DET和Severstal数据集上进行5组消融实验,以验证各个模块的有效性. M1表示将颈部的C2f模块替换成S-C2f模块、M2表示在主干网络最后添加DilateFormer、M3表示将原主干网络替换成BS-ShuffleNetv2网络. 其实验结果如表5所示,加粗表示最优值. 可以看出,在NEU-DET和Severstal数据集上,首先将颈部的C2f模块替换为S-C2f模块,mAP分别提升4.4和4.3个百分点、参数量和计算复杂度仅为基线模型的92.7%和93.4%,FPS提升20帧和10帧,表明SsConv模块能够减少空间和通道维度上的冗余信息,优化模型参数量和计算复杂度,并提升检测速度. 同时,SUR单元通过重新构建空间和通道特征信息之间的相关性,进一步提高检测能力;其次在主干网络最后添加DilateFormer模块,损失微小参数量和检测速度,但检测精度得到提升. DilateFormer模块通过多尺度膨胀卷积核扩大感受野,增强对不同尺度的特征的感知能力,有效捕捉特征图的上下文信息,避免特征分辨率的损失,从而提高特征提取和检测能力;然后将主干网络替换为轻量化的BS-ShuffleNetv2网络后,在2个数据集上,mAP分别提升1.2和2.3个百分点,同时给检测速度带来显著提升,每秒检测帧数达到217、196帧,相比于原模型提升近一倍. 另外,参数量和计算量得到显著优化,仅为YOLOv8s的57.6%和71.0%,表明改进后的BS-ShuffleNetv2网络具备优越性. 最后,同时添加3个模块,即本研究所提SDB-YOLOv8s算法,mAP分别提升6.4和7.0个百分点,FPS分别提升11和18帧,精确度分别达到77.4%和77.6%,参数量和计算量则仅为基线模型的64.8%和56.2%. 消融实验结果表明本研究所提算法具有合理性,较好地平衡了检测精度、速度和轻量化.
表 5 NEU-DET和Severstal数据集消融实验结果
Tab.5
| 数据集 | 模型方法 | mAP/% | Params/106 | FLOPs/109 | FPS/帧 | P/% | R/% |
| NEU-DET | YOLOv8s | 72.8 | 11.1 | 28.8 | 109 | 72.8 | 70.9 |
| YOLOv8s+M1 | 77.2 | 10.3 | 26.9 | 129 | 77.1 | 70.4 | |
| YOLOv8s+M2 | 75.8 | 12.3 | 28.7 | 104 | 76.7 | 70.2 | |
| YOLOv8s+M3 | 74.0 | 6.4 | 16.5 | 217 | 71.5 | 76.0 | |
| YOLOv8s+M1+M2+M3 | 79.2 | 7.2 | 16.2 | 146 | 77.4 | 72.1 | |
| Severstal | YOLOv8s | 69.9 | 11.1 | 28.8 | 103 | 71.1 | 68.4 |
| YOLOv8s+M1 | 74.2 | 10.3 | 26.9 | 112 | 70.0 | 69.7 | |
| YOLOv8s+M2 | 71.1 | 12.3 | 28.7 | 88 | 68.8 | 70.9 | |
| YOLOv8s+M3 | 72.1 | 6.4 | 16.5 | 196 | 65.1 | 70.3 | |
| YOLOv8s+M1+M2+M3 | 76.9 | 7.2 | 16.2 | 121 | 77.6 | 70.4 |
如图9所示展示了本研究算法与基线模型在NEU-DET和Severstal数据集上对检测各类缺陷的平均精度. 可以看出,SDB-YOLOv8s算法对各类缺陷的AP均有所提升,在NEU-DET数据集上对裂缝、夹杂物、点蚀表面和氧化皮的提升效果较好,分别提高14.8、5.5、3.8和9.5个百分点;在Severstal数据集上则对裂缝、氧化皮和划痕三类缺陷的检测精度提升最显著,分别提高9.4、10.8和9.1个百分点,对于2个数据集的其余类别缺陷,原模型已达到较高的检测精度,因此提升效果略低. 实验结果表明本研究算法能有效提高钢材表面缺陷的检测精度.
图 9
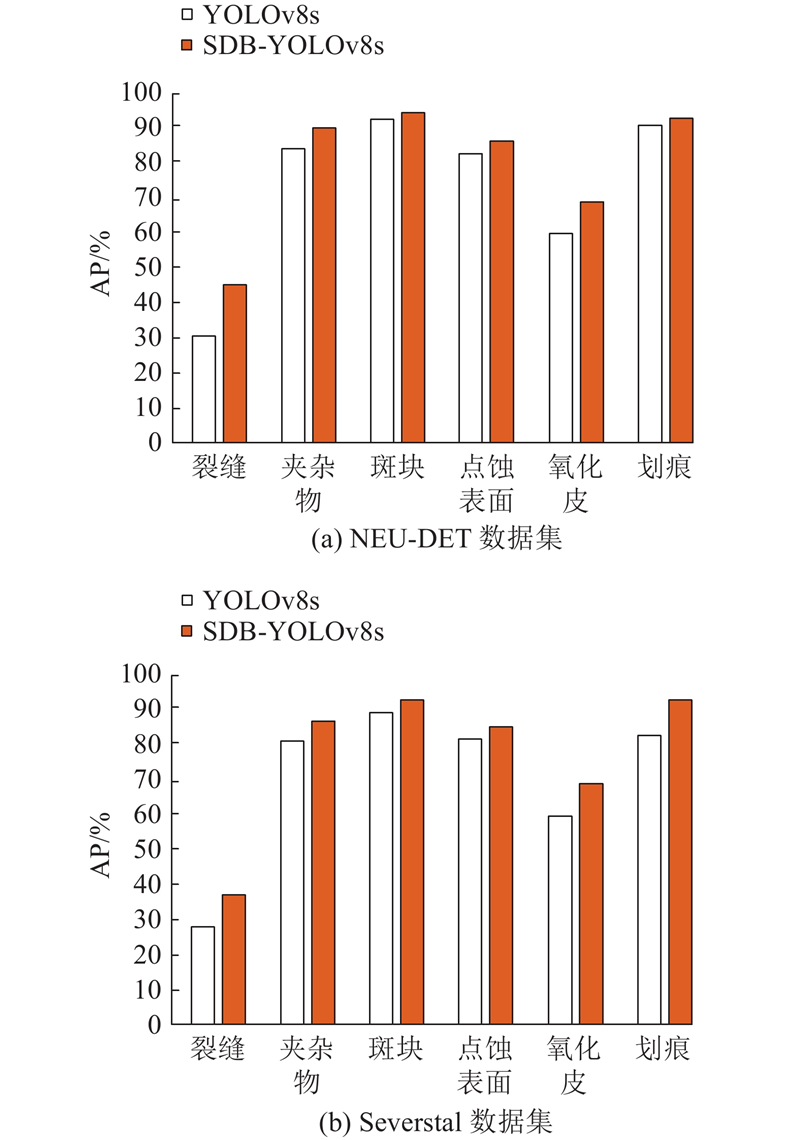
图 9 本研究算法与原模型对各类缺陷AP的对比
Fig.9 Comparison of AP values of proposed algorithm and original model for various types of defects
为了验证Severstal数据集中各项性能指标提升是因数据增强还是本研究算法效果,在相同实验条件下,对比本研究算法和YOLOv8s算法在扩充前后数据集上的实验结果,其中SeverstalA、SeverstalB分别表示扩充前后的数据集. 实验结果如表6所示,其中加粗表示最优值. 可以看出,扩充前Severstal数据集mAP达到74.3%,而扩充后数据集mAP反而降低4.4个百分点. 可能是由于数据增强前的样本过于简单,模型在训练过程中过拟合. 而本研究算法的mAP在数据增强前后均得到提升,表明Severstal数据集检测精度的提升是由本研究算法带来的效果,其余指标也得到一定优化. 实验结果表明,数据增强能在一定程度上避免过拟合,并且SDB-YOLOv8s算法具有良好的鲁棒性.
表 6 Severstal数据集扩充前后实验对比
Tab.6
| 数据集 | 模型方法 | mAP/% | Params/106 | FLOPs/109 | FPS/帧 |
| SeverstalA | YOLOv8s | 74.3 | 11.1 | 28.8 | 120 |
| YOLOv8s+M1+M2+M3 | 77.9 | 7.2 | 16.2 | 146 | |
| SeverstalB | YOLOv8s | 69.9 | 11.1 | 28.8 | 103 |
| YOLOv8s+M1+M2+M3 | 76.9 | 7.2 | 16.2 | 121 |
3.7. 对比实验分析
为了验证本研究算法的优越性,在相同实验条件下,分别在NEU-DET和Severstal数据集上,将改进后的算法与其他算法进行对比,包括Faster R-CNN、SSD、YOLOv3、YOLOv3-tiny、YOLOv4、YOLOv4-tiny、YOLOv5s、YOLOv5m、YOLOX-s、YOLOv7、YOLOv7-tiny、YOLOv8s和文献[11]、[18]的算法. 由于Severstal数据集扩充后样本数量庞大,本研究实验设备的计算能力和内存容量有限,无法对除SSD、YOLOv3-tiny、YOLOv4-tiny、YOLOv5s、YOLOv5m、YOLOv7-tiny和YOLOX-s算法之外的其他算法进行实验. 此外,文献[11]、[18]算法的检测对象是NEU-DET数据集,因此无法在Severstal数据集上进行对比分析. 如表7所示展示了实验结果,其中加粗表示最优值. 可以看出,SDB-YOLOv8s算法在NEU-DET和Severstal数据集上具有显著优势. 与Faster R-CNN、SSD、YOLOv3、YOLOv3-tiny、YOLOv4、YOLOv4-tiny、YOLOv5s、YOLOv5m、YOLOX-s、YOLOv7、YOLOv7-tiny和基线模型YOLOv8s相比,SDB-YOLOv8s算法具有较高的检测精度,其mAP分别达到79.2%和76.9%. 此外,SDB-YOLOv8s算法的FPS分别为146帧和121帧,优于其他对比算法. 相比之下,文献[11]算法在NEU-DET数据集上具有较高的检测精度,模型参数量和计算量也具备优势,但检测精度与实验设备、数据集划分以及实验参数设置也具有相关性. 同时其49帧的FPS较低,实时性较差,无法较好地平衡轻量化、检测精度和速度. 文献[18]的检测速度相比于文献[11]有所提升,但占用过多的计算资源,检测精度也有所降低. 反观本研究算法,参数量和计算量仅为7.2×106、16.2×109,检测速度达到最优,极大地满足实时性需求. 因此,SDB-YOLOv8s算法能更好地平衡检测精度、速度和轻量化,并具有较高的通用性的实用价值.
表 7 不同算法在NEU-DET和Severstal数据集上的对比实验结果
Tab.7
| 数据集 | 模型方法 | mAP/% | Params/106 | FLOPs/109 | FPS/帧 |
| NEU-DET | Faster R-CNN | 65.7 | 72.0 | 167.3 | 17 |
| SSD | 61.0 | 41.1 | 145.3 | 41 | |
| YOLOv3 | 67.0 | 61.5 | 155.0 | 31 | |
| YOLOv3-tiny | 46.5 | 8.6 | 12.9 | 142 | |
| YOLOv4 | 51.0 | 52.5 | 119.8 | 45 | |
| YOLOv4-tiny | 54.6 | 5.9 | 16.1 | 128 | |
| YOLOv5s | 70.1 | 7.07 | 16.4 | 102 | |
| YOLOX-s | 71.8 | 8.0 | 21.6 | 46 | |
| YOLOv7 | 70.0 | 37.2 | 104.8 | 36 | |
| YOLOv7-tiny | 68.7 | 6.02 | 13.1 | 108 | |
| YOLOv8s | 72.8 | 11.1 | 28.8 | 120 | |
| 文献[11] | 78.5 | 5.8 | 10.9 | 49 | |
| 文献[18] | 74.1 | 23.9 | — | 75 | |
| SDB-YOLOv8s(本研究) | 79.2 | 7.2 | 16.2 | 146 | |
| Severstal | SSD | 65.3 | 41.1 | 145.3 | 12 |
| YOLOv3-tiny | 56.4 | 8.6 | 12.9 | 117 | |
| YOLOv4-tiny | 59.6 | 5.9 | 16.1 | 103 | |
| YOLOv7-tiny | 68.7 | 6.02 | 13.1 | 108 | |
| YOLOv5s | 72.4 | 7.07 | 16.4 | 59 | |
| YOLOv5m | 73.2 | 21.0 | 50.3 | 52.6 | |
| YOLOX-s | 73.8 | 8.0 | 21.6 | 42 | |
| YOLOv8s | 69.8 | 11.1 | 28.8 | 103 | |
| SDB-YOLOv8s(本研究) | 76.9 | 7.2 | 16.2 | 121 |
3.8. 可视化对比
为了直观比较本研究算法和基线算法在钢材表面缺陷上的检测性能,分别使用SDB-YOLOv8s与YOLOv8s模型在NEU-DET和Severstal数据集上进行定性分析,并将检测效果进行可视化展示,如图10所示. 可以看出,本研究算法相比于基线模型能检测出更多有效缺陷区域,与前文图9中的对比结果图大致对应. 在NEU-DET数据集上本研究算法对裂缝、夹杂物、点蚀表面和氧化皮的检测效果较好;在Severstal数据集上对裂缝、氧化皮和划痕3类缺陷的检测效果较好,同时本研究算法所检测的缺陷置信度也较高. 虽然也存在部分漏检情况(例如,裂缝、点蚀表面和划痕缺陷),但总体而言能检测出大部分的缺陷区域,可视化结果表明本研究提出的SDB-YOLOv8s算法具有更强的浅层特征提取能力,可以较好地避免漏检和误检情况,并在检测性能上具备一定优势.
图 10

图 10 SDB-YOLOv8s算法和YOLOv8s算法可视化结果对比
Fig.10 Visualization results comparison of SDB-YOLOv8s algorithm and YOLOv8s algorithm
4. 结 语
针对钢材表面缺陷形态多样、结构复杂和小目标居多以及现有算法无法有效平衡检测精度、速度和轻量化等问题,提出轻量级的钢材表面缺陷检测算法(SDB-YOLOv8s). 该算法通过设计特征交互模块、引入空洞Transfomer模块和设计轻量化主干网络等方法,改善当前算法在钢材缺陷检测领域无法有效平衡检测精度、速度和轻量化的问题. 在NEU-DET和Severstal数据集上进行实验验证,该算法的mAP分别达到79.2%和76.8%,同时参数量和计算复杂度仅为基线模型的64.8%和56.2%、FPS分别达到146帧和121帧. SDB-YOLOv8s模型在保持较高检测精度的同时,所需的计算资源更少,检测速度更快,较好地平衡了检测精度、速度和轻量化. 目前,该模型的部署尚在实验阶段,未来的研究将考虑模型在不同光照和环境条件下对不同缺陷的表现能力,同时在实际部署时将考虑模型的寿命、维护和能源消耗等方面,最后将其应用在工业钢材缺陷检测领域.
参考文献
基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
[J].
Drum roller surface defect detection algorithm based on improved YOLOv8s
[J].
基于改进YOLOv5的推力球轴承表面缺陷检测算法
[J].
Surface defect detection algorithm of thrust ball bearing based on improved YOLOv5
[J].
Faster R-CNN: towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031 [本文引用: 1]
YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection
[J].DOI:10.3390/machines11070677 [本文引用: 1]
Surface defect detection of rolled steel based on lightweight model
[J].DOI:10.3390/app12178905 [本文引用: 1]
Steel plate surface defect detection based on dataset enhancement and lightweight convolution neural network
[J].DOI:10.3390/machines10070523 [本文引用: 1]
改进YOLOv5的轻量级带钢表面缺陷检测
[J].
Lightweight strip steel defect detection based on improved YOLOv5
[J].
基于改进Mask R-CNN 的金属板材表面缺陷检测
[J].
Research on surface defect recognition of metal sheet based on improved Mask R-CNN
[J].
基于改进SSD的钢材表面缺陷检测
[J].
Steel surface defect detection based on improved SSD
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}