

烟梗是烟草植物的主干部分,也是烟草制品制备的关键原料之一. 对于烟草工业来说,了解和有效处理烟梗是生产高质量烟草制品的必要步骤. 烟梗的长短梗率会影响烟草卷丝时的口感、烟草的燃烧性能以及烟草产品的整体质量[1]. 在卷烟厂制丝车间,工人投放烟梗物料,通过振槽进行输送和分流,须获得该批次物料的烟梗长短梗率及流量信息. 目前,烟梗长短梗率的检测主要通过人工筛选,而依靠人工筛选存在较大的主观因素干扰,并且任务繁琐乏味、工作量大. 同时,在生产过程中,获取烟梗物料的流量信息可以便于及时调整产线工作情况以提高生产效率. 因此,为了提高烟草制品的产品质量以及生产效率,须对烟梗进行实时识别检测,以获取烟梗物料的长短梗率以及流量信息.
近年来,随着深度学习的迅猛发展,目标检测网络在各个领域得到广泛应用,作为代表的YOLOv5更是在实践中展现出了卓越的性能. 苗新法等[6]通过引入GSconv模块,将骨干网络的特征信息融入PAN网络,以及引入坐标注意力机制(coordinate attention,CA)和自注意力机制Transformer,使YOLOv5网络对铁轨裂纹的检测性能得到大幅度提升. 崔丽群等[7]提出联合注意力的多尺度特征增强网络,并增加感受野模块和旋转角度,提高了复杂背景下遥感图像目标的检测精度. 金鑫等[8]提出基于轻量化 YOLOv5s网络的车底危险物识别算法,该算法通过引入ShuffleNetv2和Ghost卷积模块,优化数据增强算法和定位损失函数,从而提高了识别性能. Zhang等[9]采用挤压激励网络(squeeze-and-excitation networks ,SENet)、卷积块注意模块( convolutional block attention module,CBAM)和高效通道注意力机制(efficient channel attention,ECA)这3种注意机制的方法进行测试和比较,提出基于改进YOLOv5的小麦不健全粒实时分类检测算法. Hong等[10]提出BiFPN结构,使该结构替换掉原算法中的PANet(path aggregation network)结构,并将SE、ECA和CBAM这3种常用的注意力机制作为CA机制嵌入骨干中进行比较,用于检测复杂环境下的绿芦笋. Yuan等[11]引入注意力机制模块挤压和激励网络SENet和小目标检测层以减少输电线路典型缺陷识别的漏检率和误检率. Zhou等[12]提出改进的YOLOv5建筑固废检测算法,该算法设计融合Fusion-Concat模块取代Neck网络中原有的Concat模块,减小模型参数大小和计算复杂度,同时提升了检测性能.
针对制丝车间实际生产过程的需求,本研究基于YOLOv5s提出烟梗图像目标检测算法. 将RepViT结构引入骨干网络;应用结构重参数化技术改进RepViT结构;设计基于注意力机制的目标检测头Dynamic Head模块来取代原有的检测头模块,以增强模型的检测能力.
1. YOLOv5s模型概述
YOLOv5由美国公司Ultralytics提出,是YOLO系列的第5代. 与之前的版本相比,YOLOv5强调轻量化设计,在保持高检测精度的同时,实现模型的快速推理和部署,适用于嵌入式和移动设备. YOLOv5具有4个版本:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,其中s到x表示不同的模型大小和性能,YOLOv5s拥有最小的模型体积和最低的计算复杂度. 如图1所示,YOLOv5s的网络结构包括输入端(Input)、骨干(Backbone)、颈部(Neck)、头部(Head)等部分.
图 1
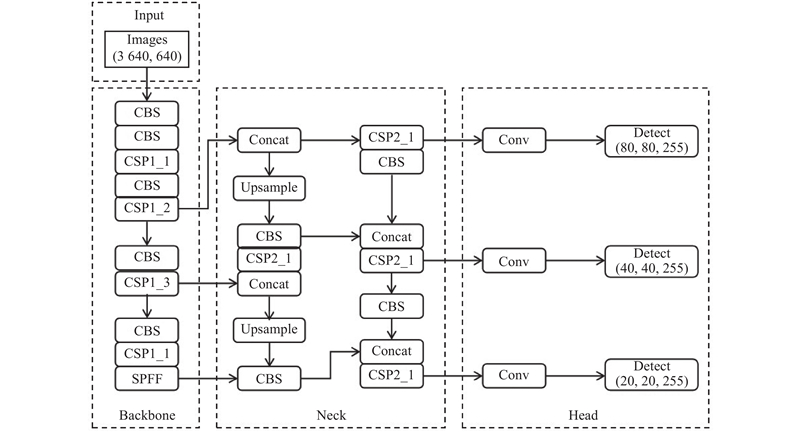
YOLOv5s的输入端接受彩色图像作为输入,常见输入尺寸为640×640像素. 输入图像首先经过归一化处理,以确保模型能够适应不同尺寸和亮度的图像,然后传递到骨干网络.
YOLOv5s的骨干网络采用CSPDarknet53结构,它包括多个卷积层、残差连接和空间金字塔池化模块(spatial pyramid pooling ,SPP). CSPDarknet53有效地保留了低层和高层特征,有助于提高检测性能.
颈部网络用于连接骨干网络和头部网络. 在YOLOv5s中,使用多个卷积层和PANet结构融合来自不同卷积层的特征,提高对目标上下文信息的理解. PANet通过路径聚合的方式,将低层和高层特征相互连接,有助于更好地理解目标的位置和形状.
YOLOv5s的头部网络负责预测目标的位置和类别. 多个检测头能够在不同的特征分辨率上执行检测,有助于模型在不同尺度下检测目标.
2. 算法改进
2.1. RepViT-m1引入
Transformer最初设计用于自然语言处理任务,如今已经在计算机视觉领域展现出卓越的潜力. 视觉转换器(vision transformer,ViT)[13]是一项基于Transformer架构的创新技术,它在大规模数据集(例如ImageNet)上取得了卓越的表现,成为了图像识别领域的一项重要突破. ViT的核心思想在于将图像切分成统一大小的图块,然后运用 Transformer中的自注意力机制来处理这些图块,实现对图像特征的提取和理解[14]. 在这一前沿思想的启发下,Wang等[15]提出了RepViT,旨在进一步提高图像处理任务的性能. RepViT将轻量级ViT结构与残差网络的特点相融合,这种融合为其引入了残差块(residual blocks). 这些残差块的存在有助于更好地捕捉图像中的低层特征,从而提高了对图像信息的多层次抽象表示. 相对于传统的ViT模型,RepViT允许采用更加紧凑的网络结构,有效减小了模型的复杂性,提升了模型在训练和推理中的效率. 本研究将YOLOv5s的骨干网络优化为RepViT的变体RepViT-m1结构,RepViT-m1引入的残差块有助于捕捉图像中的低层特征. 鉴于烟梗样本具有多种不同的形状和尺寸,多层次特征提取有助于更全面地捕捉这些细节信息. 相对于YOLOv5s的骨干网络,RepViT-m1具有更为紧凑的结构,这对于处理相对较小的数据集而言,通常更易于训练,并能提高训练和推理的效率. 与其他RepViT变体,如RepViT-m2和RepViT-m3相比,RepViT-m1在多个关键方面表现出独特的优势. 首先,它采用了更为精简的模型结构,这意味着模型的参数数量和计算复杂性都较低,这一优势不仅有助于降低硬件资源需求,还提高了模型在训练和推理过程中的效率. 这对于实际生产环境中需要实时性处理的检测任务来说至关重要,适用于需要快速响应和准确性的应用场景. 这一改进为目标检测任务引入了更强大的图像处理能力,提升了模型的性能和泛化能力.
2.2. 重参数化
结构重参数化是一项关键的神经网络优化技术,其核心目标是通过重新设计神经网络的层次结构、参数连接方式,以及参数的表示方法,以在保持或提高性能的前提下,显著提高网络的效率. 这一概念受到了经典VGG网络的启发,其中网络的深度和复杂性促使研究者思考如何简化这些深度神经网络. Ding等[16]提出的RepVGG,则是在这一思想的基础上构建的,它沿袭了“Rep”的架构命名,旨在简化网络结构,降低复杂度,同时保持卓越性能. 值得注意的是,本研究引入的RepViT-m1与RepVGG在一些设计理念上有相似之处,都采用了“Rep”架构,都着力于简化模型结构以提高训练和推理效率. 但与RepVGG的不同之处在于RepViT-m1采用了Transformer架构,不直接使用卷积核,而是通过自注意力机制处理输入数据. 借鉴RepVGG的思路,本研究在采用RepViT-m1骨干的同时应用了结构重参数化技术,融合子层以减少复杂度,并采用了消除批归一化的操作,以提高模型的速度和效率. 这一系列的改进旨在使模型更适合在实际部署和推理的阶段使用,使其具备更高的实用性.
2.3. 基于注意力机制的目标检测头Dynamic Head
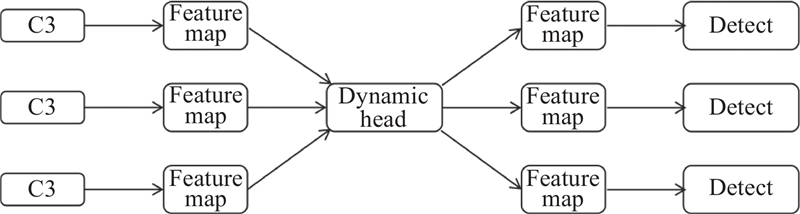
目标检测的头部网络负责定位和分类检测目标. 通常,它由多个卷积层和全连接层组成,用于提取目标位置(通常是边界框坐标)和类别信息. 检测头是头部网络中负责执行特定检测任务的组件,定义了如何将头部网络的输出整合以生成最终检测结果. 对于检测头的改进,关注的焦点通常包括性能提升、计算效率、尺度感知、空间感知和任务感知. Dai等[17]提出通用的检测头部框架,名为Dynamic Head,它整合了尺度感知、空间感知和任务感知的3种注意力机制,这些机制应用于不同特征维度,分别用于关卡智能、空间智能和渠道智能. 这一框架具有灵活性,可与现有的目标检测器集成以提高性能,并且可以通过学习进行有效改进,使目标检测头部能够更加适应多样化的检测任务,提高了检测头部的表示能力,而不会增加额外的计算开销. 本研究在头部网络中引入Dynamic Head模块,如图2所示. 首先,将Dynamic Head连接到骨干网络的输出,获取特征图,这些特征图包含了来自输入图像的高级语义信息,以及来自骨干网络的层次特征. 然后,根据输入特征图,多个输出头部连接到Dynamic Head,每个头部负责不同尺度的目标检测. 通过自注意力机制生成注意力权重,可以使网络更灵活地学习关于每个任务的特征,尤其是对于具有多样化和复杂性的数据集. 值得注意的是,Dynamic Head能够有效处理不同尺寸和形状的烟梗,提高了多尺度信息的利用效率.
图 2
3. 实验结果与分析
3.1. 数据集的建立
数据集通过在受控实验室环境中采集的烟梗样本图像构建而成. 该数据集涵盖了各种不同长度范围的烟梗样本,并经过细致处理,以确保数据的质量和可用性. 数据集通过在实验室环境下搭建的专用设备,包括CMOS工业相机、工业镜头和环形LED光源采集得到,工业相机型号为MV-CU013-A0UC,工业镜头型号为MVL-HV1050M-6MP. 烟梗样本根据其长度被分类为6个不同的范围,即0~20、20~30、30~40、40~50、50~60 mm和60 mm以上. 其中0~20、20~30、30~40、40~50、50~60 mm各含有350张图像,60 mm以上的样本数量较少则仅含有250张图像,总计
3.2. 基于连通域的自动标签算法
在深度学习目标检测算法中,样本标注是一个不可或缺的步骤,它为算法提供了学习和识别目标的关键信息. 然而,由于样本数量繁多,手动标注工作耗时且繁琐. 为了提高标注效率,为单样本图像设计了基于连通域的自动标签算法. 基于连通域的自动标签算法步骤如下:1)对烟梗图像进行加权平均值法灰度化处理,解决局部区域对比度弱、光照变化的问题;2)使用高斯滤波精确地清除图像背景中的噪声;3)使用自适应阈值算法对图像进行阈值分割,将图像分割成目标和背景2个部分,以便更好地定位烟梗;4)使用开运算,即先腐蚀后膨胀,在去除噪声的同时保留了完整的样本,确保只关注有效目标的区域;5)对处理后的图像进行连通域分析,通过面积筛选实现了只保留完整目标样本的连通域,并使用不同颜色的方框标记出来;6)提取当前处理图像的信息和已标记目标的位置信息并保存为VOC格式的XML标签文件. 过程图如图3所示.
图 3

图 3 基于连通域的自动标签算法过程图
Fig.3 Process diagram of automatic labeling algorithm based on connected domain
3.3. 设备搭建及实验参数设定
3.3.1. 设备搭建
针对车间现场环境搭建烟梗物料目标检测系统. 该系统硬件结构包括控制系统、光源、工业相机、相机支架、计算机、振槽等部分,如图4所示.
图 4
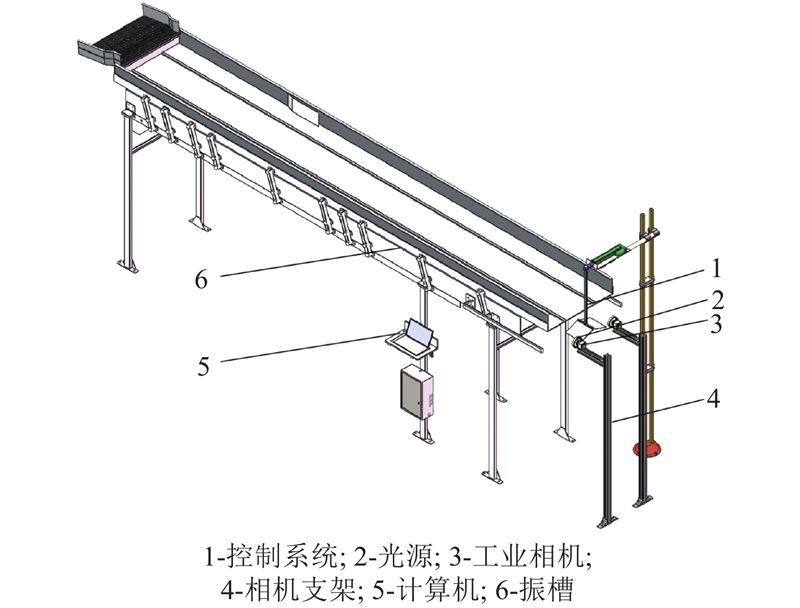
实际应用场景如图5所示,工业相机实时采集振槽下落口的烟梗图像,传递给计算机分析得到烟梗长短梗率以及流量信息,通过控制系统实现分流.
图 5

3.3.2. 实验参数设定
本实验使用的操作系统是 Windows11,CPU是12th Gen Intel(R) Core(TM) i7-12700H,GPU是NVIDIA GeForce RTX
3.4. 评价指标
使用的评价指标有混淆矩阵、准确率P、召回率R、mAP@0.50、mAP@0.50∶0.95、模型大小M、每秒浮点数运算次数GFLOPs、每秒传输帧数FPS.
1) 混淆矩阵:用于衡量分类模型性能的重要工具. 它显示了模型在不同类别上的预测结果与实际情况之间的关系,TP表示预测为正实际为正的样本个数,FP表示预测为正实际为负的样本个数,FN表示预测为负实际为正的样本个数,TN表示预测为负实际为负的样本个数.
2) 准确率P:表示模型预测为正例的样本中,有多少实际是真正的正例. 表达式如下:
3) 召回率R:表示实际正例中,有多少被模型正确地检测出来. 表达式如下:
4) mAP@0.50:一种用于多类别目标检测的性能度量,它计算了不同类别的平均精度. 在此,IoU 阈值被设为0.50,对于每个类别,计算 Precision-Recall曲线下的面积AP,然后对所有类别的AP取平均得到 mAP.
5) mAP@0.50∶0.95:一种更全面的mAP衡量方式,它考虑了多个IoU阈值范围. 通常,IoU范围为0.50~0.95,以0.05的间隔进行测量. 这样可以更全面地评估模型在不同IoU阈值下的性能.
6) 模型大小M:指训练好的深度学习模型所占用的存储空间.
7) GFLOPs:每秒浮点数运算次数,它表示模型的计算复杂度.
8) FPS:每秒传输帧数,它表示模型的推理速度和实时性能.
3.5. 消融实验
通过对YOLOv5s网络引入一系列的改进策略使网络性能得到了提升. 为了更清晰地量化这些策略对网络性能的实际影响,执行一系列的消融实验. 消融实验的主要目的在于逐一或同时去除这些改进策略中的一个或多个部分,以便深入评估这些部分对网络性能提升的贡献.
3.5.1. 模块消融实验
对所提到的改进模块进行消融实验,如表1所示为模块消融实验结果分析. 表中,①为原有YOLOv5s模型,②为引入RepViT-m1结构,③为引入重参数化的RepViT-m1结构,④为引入基于注意力机制的目标检测头Dynamic Head,⑤为同时引入RepViT-m1结构和基于注意力机制的目标检测头Dynamic Head,⑥为本研究所提算法,同时引入重参数化的RepViT-m1结构以及基于注意力机制的目标检测头Dynamic Head. 在烟梗图像数据集上,将实验①作为基准模型与后续消融实验进行对比,消融实验②表明引入RepViT-m1结构替换原有骨干结构能使模型准确率有所提高;消融实验②、③的对比表明对引入RepViT-m1结构采用重参数化技术,准确率略有下降,召回率提升明显,mAP@0.50及mAP@0.50∶0.95都有提升,模型大小大幅度降低,计算复杂度降低,检测速度提升;消融实验④表明引入基于注意力机制的目标检测头Dynamic Head对所有评价指标均有提升效果;消融实验⑤表明同时引入RepViT-m1结构和基于注意力机制的目标检测头Dynamic Head对模型效果提升明显,所有精度指标均有大幅度提升;消融实验⑥与⑤相比,准确率有所提升,召回率略微下降,但综合指标mAP@0.50、mAP@0.50∶0.95结果更优,检测速度更快,表明本研究算法效果更为出色. 综上所述,本研究算法相比于原始算法,在P、R、mAP@0.50以及mAP@0.50∶0.95上分别提高了8.4、0.8、5.8、5.7个百分点,有效提高了模型检测能力,模型大小减少了2.1 MB,且每个模块都起到了重要的作用.
表 1 模块消融实验结果分析
Tab.1
| 模型 | P/% | R/% | mAP@0.50/% | mAP@0.50∶0.95/% | M/MB | GFLOPs | FPS/帧 |
| ①YOLOv5s | 77.8 | 93.3 | 90.3 | 89.0 | 13.8 | 16.6 | 212.77 |
| ②YOLOv5s+RepViT-m1 | 81.9 | 85.3 | 89.8 | 86.2 | 26.2 | 24 | 144.93 |
| ③YOLOv5s+重参数化的RepViT-m1 | 80.3 | 90.4 | 91.5 | 86.5 | 11.4 | 19.9 | 192.31 |
| ④YOLOv5s+Dynamic Head | 79.7 | 93.6 | 92.1 | 90.6 | 13.7 | 17.8 | 185.19 |
| ⑤YOLOv5s+RepViT-m1+Dynamic Head | 84.1 | 96.4 | 95.8 | 94.3 | 14.2 | 21.8 | 133.33 |
| ⑥本研究算法 | 86.2 | 94.1 | 96.1 | 94.7 | 12.1 | 21.3 | 178.57 |
3.5.2. 头部深度消融实验
在本研究中,采用基于注意力机制的目标检测头,其中的头部深度,即Dynamic Head块的数量,被确认为一个直接影响检测性能的关键因素. 这些实验包括了4组不同头部深度的设置,具体是分别选取Dynamic Head块数量d分别为2、4、6、8进行实验. 实验结果如表2所示,当选取头部深度为6时,模型的检测效果最优.
表 2 头部深度消融实验结果分析
Tab.2
| d | P/% | R/% | mAP@0.50/% | mAP@0.50∶0.95/% |
| 2 | 88.3 | 91.9 | 93.7 | 90.7 |
| 4 | 84.5 | 85.6 | 92.3 | 89.5 |
| 6 | 86.2 | 94.1 | 96.1 | 94.7 |
| 8 | 87.4 | 92.9 | 95.9 | 91.6 |
3.6. 对比实验
为了进一步验证所提算法的有效性,进行详细的性能对比研究,将本研究的算法与一些常见的目标检测算法进行对比实验:Faster R-CNN、YOLOv3-tiny、YOLOv3、YOLOv7-tiny、YOLOv7、YOLOx-s、YOLOv8s、YOLOv5s,实验环境及参数设定保持一致. 不同目标检测算法对比试验的结果和分析如表3所示,Faster R-CNN、YOLOv3和YOLOv7由于其深层架构和大量参数,计算复杂度高、模型体积庞大、检测速度慢,在训练和部署到其他设备上时可能会面临挑战. YOLOv3-tiny和YOLOv7-tiny作为YOLOv3和YOLOv7的简化版,通过减小模型深度和参数数量降低了模型大小,但在检测精度、检测速度方面依然劣于YOLOv5s. YOLOx-s与YOLOv8s在多方面均劣于YOLOv5s. 综合考虑对比实验中检测精度、模型大小、计算复杂度、检测效率等指标,选用YOLOv5s作为改进的模型. 而本研究算法相较于YOLOv5s,在模型轻量化的同时全方位增强了检测精度.
表 3 不同目标检测算法对比实验结果分析
Tab.3
| 模型 | P/% | R/% | mAP@0.50/% | mAP@0.50∶0.95/% | M/MB | GFLOPs | FPS/帧 |
| Faster R-CNN | 78.6 | 83.3 | 87.5 | 82.0 | 108.0 | 150.8 | 13.14 |
| YOLOv3-tiny | 75.8 | 85.1 | 84.3 | 80.8 | 16.6 | 13.0 | 163.93 |
| YOLOv3 | 78.2 | 87.1 | 87.9 | 83.8 | 117.9 | 155.3 | 27.80 |
| YOLOv7-tiny | 85.2 | 88.7 | 89.8 | 86.4 | 11.7 | 13.2 | 123.46 |
| YOLOv7 | 75.3 | 87.7 | 86.3 | 84.8 | 71.3 | 105.2 | 25.58 |
| YOLOx-s | 76.5 | 92.9 | 89.1 | 84.0 | 34.3 | 26.8 | 101.73 |
| YOLOv8s | 80.3 | 93.5 | 89.5 | 86.7 | 21.4 | 28.8 | 112.36 |
| YOLOv5s | 77.8 | 93.3 | 90.3 | 89.0 | 13.8 | 16.6 | 212.77 |
| 本研究算法 | 86.2 | 94.1 | 96.1 | 94.7 | 12.1 | 21.3 | 178.57 |
3.7. 结果分析
3.7.1. 模型训练结果
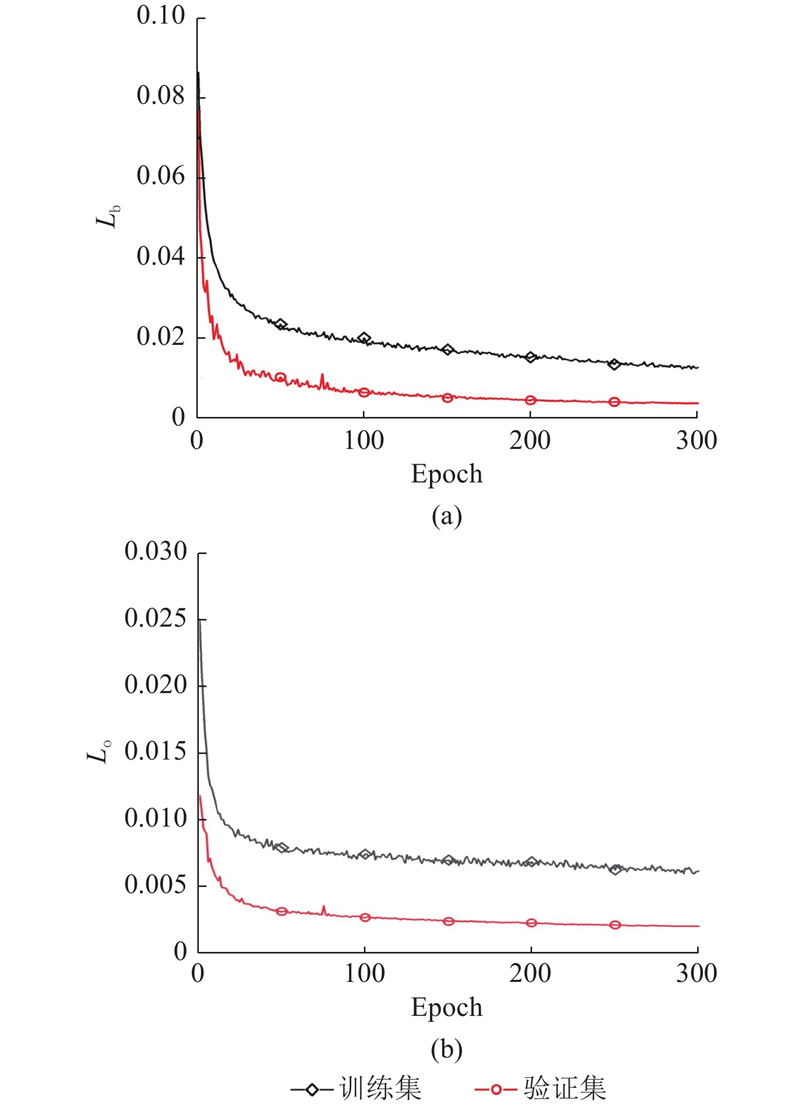
为了更直观看出模型训练的好坏,从本研究算法的训练日志中提取数据绘制出LOSS曲线以及混淆矩阵. LOSS曲线如图6所示. 图中,Lb表示框回归损失,Lo表示目标存在性损失. 图中曲线表示LOSS值逐渐减小并趋于平稳,表示模型已经收敛.
图 6
混淆矩阵如图7所示. 图中,A为准确率. 可以看出,对于6种长度类型的烟梗,0~20 mm的烟梗正确识别率接近100%,除了40~50 mm的烟梗的正确识别率略低,模型在其他长度范围的烟梗上都表现出了较高的正确识别率.
图 7
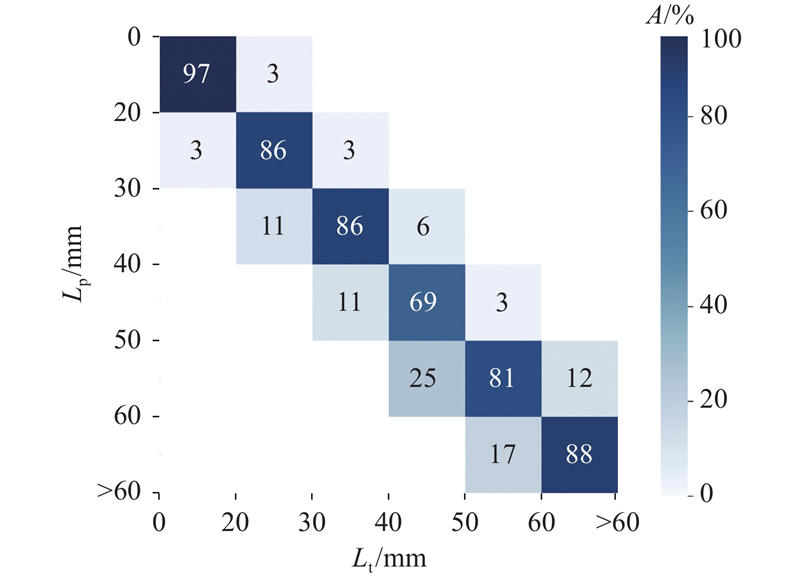
图 7 烟梗长度识别混淆矩阵图
Fig.7 Confusion matrix diagram of identification of tobacco steam length
3.7.2. 分类识别效果
如图8所示为分类识别效果图. 图中,lp、lt分别为烟梗预测长度和实际长度. 由实际标签与模型预测结果对比可知,模型会将少量40~50 mm长度范围的烟梗识别成50~60 mm长度范围的,对于大部分烟梗物料都能准确识别,且置信度高. 由实验可得,本研究算法模型预处理时间为0.2 ms,推理时间为3.5 ms,NMS操作时间为1.9 ms,模型检测一张图像的总时间为5.6 ms,即FPS为178.57帧,满足实际生产中的需求.
图 8

在下落口获取的烟梗图像中,烟梗的分布通常较为分散,但实际情况中也存在烟梗堆叠的现象. 针对这一复杂而常见的场景,如图9所示,YOLOv5s在此类图像中未能准确识别出所有烟梗,而本研究算法展现出更为卓越的识别性能.
图 9

图 9 模型改进前后识别效果对比
Fig.9 Comparison of recognition effects before and after model improvement
3.8. 长短梗率及流量信息获取
本研究方法为非接触式,在不干扰生产运行、不损坏物料的情况下获取到了生产所需的烟梗长短梗率及流量信息. 通过工业相机采集振槽下料口两侧下落的烟梗图像,再通过本研究算法检测出图像中烟梗物料的数量并识别出各物料的长度范围,得到该批次烟梗物料的长短梗率,结合已统计好的6类烟梗的单位质量,计算出前后下料口处下落的烟梗总质量,再换算得出两侧烟梗物料的实时流量信息,以便调整产线的工作情况. 换算公式如下:
式中:qm为烟梗物料质量流量,m为下落图像中获取的烟梗整体重量,V为烟梗物料运输速率,∆L为2张下落图像间烟梗物料运输距离.
4. 结 语
针对在卷烟厂制丝车间实际生产中获取烟梗长短梗率以及流量信息进行了一系列实验研究,发现烟梗物料在下落过程中存在目标数量多、大小形状不一、下落速度快等问题. 提出基于连通域的自动标签算法对数据集进行自动标注,再提出基于改进YOLOv5s的烟梗物料目标检测算法. 在所提算法中先将骨干网络替换为RepViT-m1结构,并对其使用重参数化技术,再在检测层引入基于注意力机制的目标检测头Dynamic Head. 实验结果表明,该模型的检测精度高于其他常见目标检测算法的,并且,模型大小仅12.1 MB,适用于移植部署到嵌入式设备中,另外算法检测速度快,FPS为178.57帧,可以解决烟梗物料下落速度快的问题.
相较于原模型,本研究算法在检测精度上有较大提升,但检测速度略有下降,后续将在保证检测精度的同时提升检测速度,从而更好地实现对烟梗的实时监控.
参考文献
梗丝结构对卷烟质量稳定性的影响
[J].DOI:10.3969/j.issn.1002-0861.2007.02.001 [本文引用: 1]
Influence of cut stem structure on quality stability of cigarette
[J].DOI:10.3969/j.issn.1002-0861.2007.02.001 [本文引用: 1]
BP神经网络在烟梗长短梗率检测中的应用
[J].DOI:10.11907/rjdk.202478 [本文引用: 1]
The application of BP neural network in the determination of the stalk length and stem rate
[J].DOI:10.11907/rjdk.202478 [本文引用: 1]
基于机器视觉和深度学习的烟梗识别方法
[J].
Tobacco stem recognition method based on machine vision and deep learning
[J].
基于深度学习技术的烟梗形态分类与识别
[J].
Classification and identification of tobacco stem morphology based on deep learning technology
[J].
基于改进YOLOv3网络的烟梗识别定位方法
[J].
Cigarette stem identification and location method based on improved YOLOv3 network
[J].
轻量化YOLOv5s网络车底危险物识别算法
[J].
Lightweight YOLOv5s network-based algorithm for identifying hazardous objects under vehicles
[J].
Real-time wheat unsound kernel classification detection based on improved YOLOv5
[J].DOI:10.20965/jaciii.2023.p0474 [本文引用: 1]
Detection of green asparagus in complex environments based on the improved YOLOv5 algorithm
[J].DOI:10.3390/s23031562 [本文引用: 1]
Identification method of typical defects in transmission lines based on YOLOv5 object detection algorithm
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}