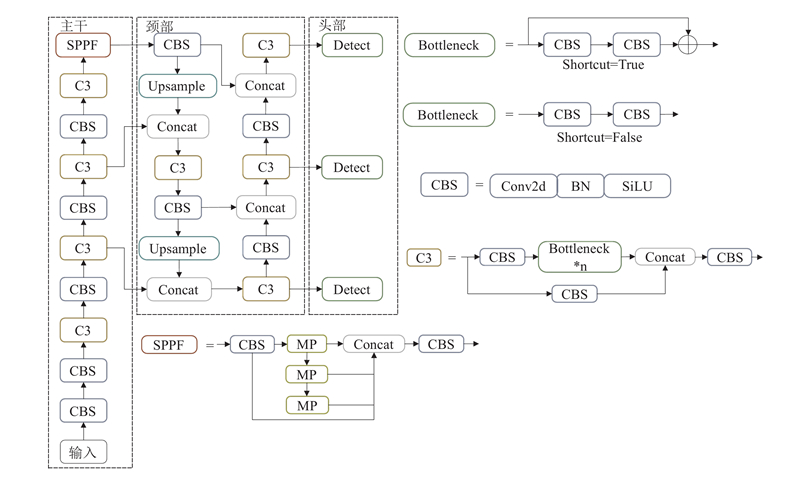
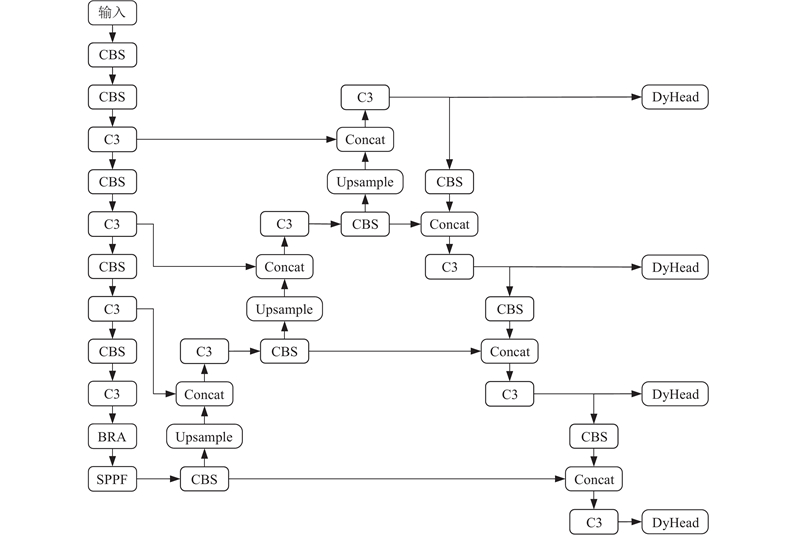
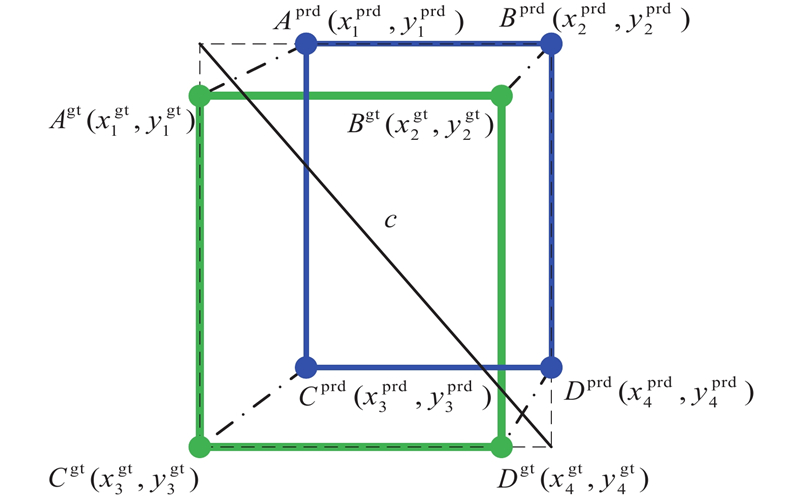
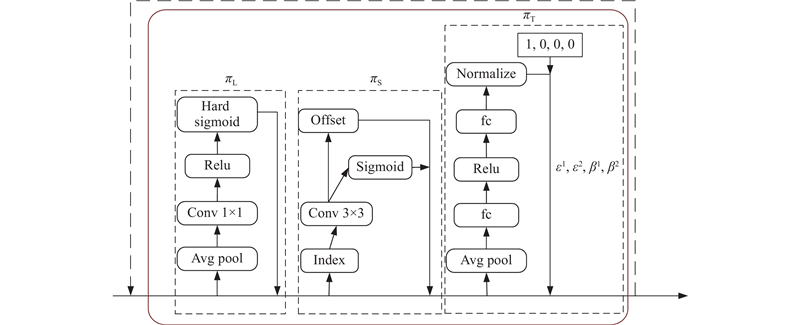
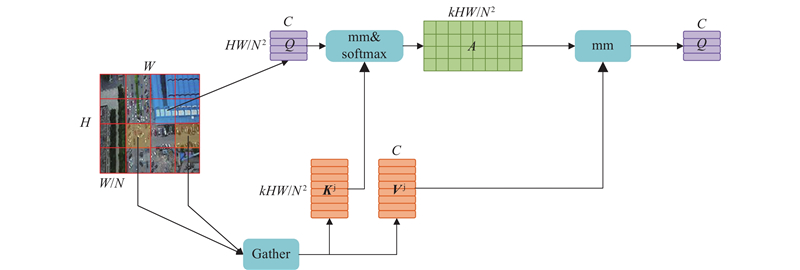
An unmanned aerial vehicle (UAV) small target detection algorithm based on YOLOv5, termed FDB-YOLO, was proposed to address the significant issue of misidentification and omissions in traditional target detection algorithms when applied to UAV aerial photography of small targets. Initially, a small target detection layer was added on the basis of YOLOv5, and the feature fusion network was optimized to fully leverage the fine-grained information of small targets in shallow layers, thereby enhancing the network’s perceptual capabilities. Subsequently, a novel loss function, FPIoU, was introduced, which capitalized on the geometric properties of anchor boxes and utilized a four-point positional bias constraint function to optimize the anchor box positioning and accelerate the convergence speed of the loss function. Furthermore, a dynamic target detection head (DyHead) incorporating attention mechanism was employed to enhance the algorithm’s detection capabilities through increased awareness of scale, space, and task. Finally, a bi-level routing attention mechanism (BRA) was integrated into the feature extraction phase, selectively computing relevant areas to filter out irrelevant regions, thereby improving the model’s detection accuracy. Experimental validation conducted on the VisDrone2019 dataset demonstrated that the proposed algorithm outperformed the YOLOv5s baseline in terms of Precision by an increase of 3.7 percentage points, Recall by an increase of 5.1 percentage points, mAP50 by an increase of 5.8 percentage points, and mAP50:95 by an increase of 3.4 percentage points, showcasing superior performance compared to current mainstream algorithms.
Keywords:unmanned aerial vehicle perspective
;
small object detection layer
;
loss function
;
attention mechanism
;
YOLOv5
SONG Yaolian, WANG Can, LI Dayan, LIU Xinyi. UAV small target detection algorithm based on improved YOLOv5s. Journal of Zhejiang University(Engineering Science)[J], 2024, 58(12): 2417-2426 doi:10.3785/j.issn.1008-973X.2024.12.001
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580–587.
REN S , HE K , GIRSHICK R , et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017, 39(6): 1137–1149.
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2999–3007.
ZHU X, LYU S, WANG X, et al. TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 2778–2788.
DAI X, CHEN Y, XIAO B, et al. Dynamic head: unifying object detection heads with attentions [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 7369–7378.
ZHU L, WANG X, KE Z, et al. BiFormer: vision transformer with bi-level routing attention [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 10323–10333.
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6517–6525.
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23)[2023-11-20]. https://arxiv.org/abs/2004.10934.
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 936–944.
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3–19.
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13708–13717.
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11531–11539.
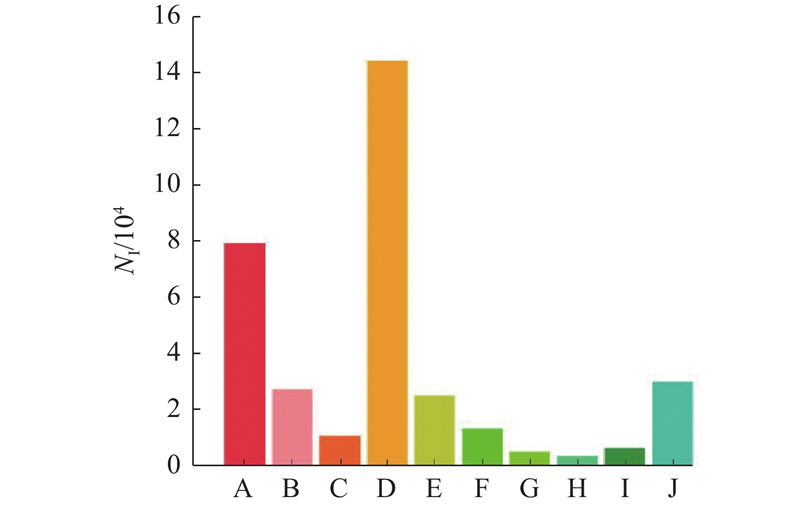
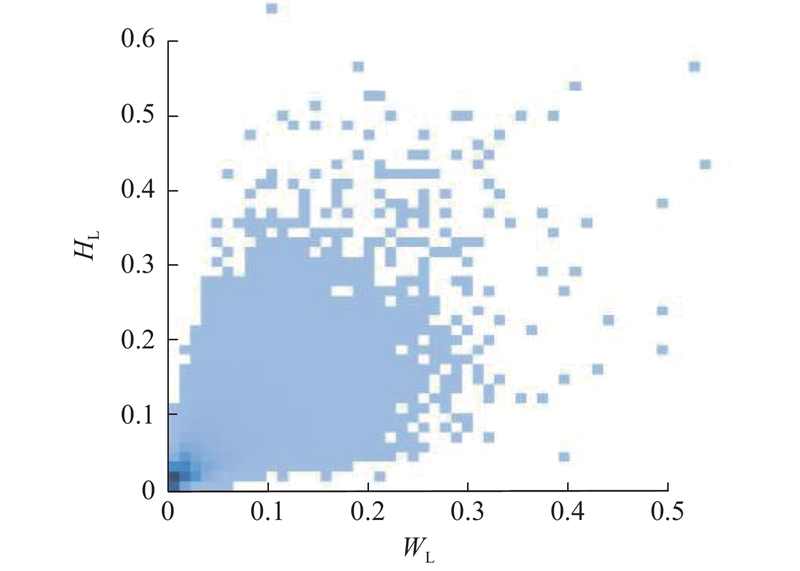
DU D, ZHU P, WEN L, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Seoul: IEEE, 2019: 213–226.
LI C, LI L, JIANG H, et al. YOLOv6: a single-stage object detection framework for industrial applications [EB/OL]. (2022-09-07)[2023-11-20]. https://arxiv.org/abs/2209.02976.
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464–7475.
REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: a metric and a loss for bounding box regression [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 658–666.
ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020, 34(7): 12993–13000.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}