[1]
BALESTRIERI E, DAPONTE P, DE VITO L, et al Sensors and measurements for UAV safety: an overview
[J]. Sensors , 2021 , 21 (24 ): 8253
DOI:10.3390/s21248253
[本文引用: 1]
[2]
LIU Y, SUN P, WERGELES N, et al A survey and performance evaluation of deep learning methods for small object detection
[J]. Expert Systems with Applications , 2021 , 172 : 114602
DOI:10.1016/j.eswa.2021.114602
[本文引用: 1]
[3]
KOUSHIK J. Understanding convolutional neural networks [EB/OL]. (2016-05-30). https://arxiv.org/abs/1605.09081.
[本文引用: 1]
[4]
韩俊, 袁小平, 王准, 等 基于YOLOv5s的无人机密集小目标检测算法
[J]. 浙江大学学报:工学版 , 2023 , 57 (6 ): 1224 - 1233
[本文引用: 1]
HAN Jun, YUAN Xiaoping, WANG Zhun, et al UAV dense small target detection algorithm based on YOLOv5s
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (6 ): 1224 - 1233
[本文引用: 1]
[5]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580−587.
[本文引用: 1]
[6]
GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440−1448.
[本文引用: 1]
[7]
REN S Q, HE K M, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. Advances in Neural Information Processing Systems , 2016 , 39 (6 ): 1137 - 1149
[本文引用: 1]
[8]
HE K, GKIOXARI G, DOLLAR P, et al. Mask R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2961–2969.
[本文引用: 1]
[9]
张艳, 孙晶雪, 孙叶美, 等 基于分割注意力与线性变换的轻量化目标检测
[J]. 浙江大学学报:工学版 , 2023 , 57 (6 ): 1195 - 1204
[本文引用: 1]
ZHANG Yan, SUN Jingxue, SUN Yemei, et al Lightweight object detection based on split attention and linear transformation
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (6 ): 1195 - 1204
[本文引用: 1]
[10]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[11]
LIU W, ANGUELOY D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 14th European Conference on Computer Vision . Berlin: ECCV, 2016: 21−37.
[本文引用: 1]
[12]
WANG Q, QIAN Y, HU Y, et al M2YOLOF: based on effective receptive fields and multiple-in-single-out encoder for object detection
[J]. Expert Systems with Applications , 2023 , 213 : 118928
DOI:10.1016/j.eswa.2022.118928
[本文引用: 1]
[13]
PENG C, ZHU M, REN H G, et al Small object detection method based on weighted feature fusion and CSMA attention module
[J]. Electronics , 2022 , 11 (16 ): 2546
DOI:10.3390/electronics11162546
[本文引用: 1]
[16]
DENG C F, WANG M M, LIU L, et al Extended feature pyramid network for small object detection
[J]. IEEE Transactions on Multimedia , 2021 , 24 : 1968 - 1979
[本文引用: 1]
[17]
HE X W, CHENG R, ZHENG Z L, et al Small object detection in traffic scenes based on YOLO-MXANet
[J]. Sensors , 2021 , 21 (21 ): 7422
DOI:10.3390/s21217422
[本文引用: 1]
[18]
JI S J, LING Q H, HAN F An improved algorithm for small object detection based on YOLOv4 and multi-scale contextual information
[J]. Computers and Electrical Engineering , 2023 , 105 : 108490
DOI:10.1016/j.compeleceng.2022.108490
[本文引用: 1]
[19]
张娜, 戚旭磊, 包晓安, 等 基于优化预测定位的单阶段目标检测算法
[J]. 浙江大学学报:工学版 , 2022 , 56 (4 ): 783 - 794
[本文引用: 1]
ZHANG Na, QI Xulei, BAO Xiaoan, et al Single-stage object detection algorithm based on optimizing position prediction
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (4 ): 783 - 794
[本文引用: 1]
[20]
谢誉, 包梓群, 张娜, 等 基于特征优化与深层次融合的目标检测算法
[J]. 浙江大学学报:工学版 , 2022 , 56 (12 ): 2403 - 2415
[本文引用: 1]
XIE Yu, BAO Ziqun, ZHANG Na, et al Object detection algorithm based on feature enhancement and deep fusion
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (12 ): 2403 - 2415
[本文引用: 1]
[21]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23). https://arxiv.org/abs/2004.10934v1.
[本文引用: 1]
[22]
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759-8768.
[本文引用: 1]
[23]
LIU H Y, SUN F Q, GU J, et al Sf-YOLOv5: a lightweight small object detection algorithm based on improved feature fusion mode
[J]. Sensors , 2022 , 22 (15 ): 5817
DOI:10.3390/s22155817
[本文引用: 1]
[24]
张云佐, 郭威, 蔡昭权, 等 联合多尺度与注意力机制的遥感图像目标检测
[J]. 浙江大学学报:工学版 , 2022 , 56 (11 ): 2215 - 2223
[本文引用: 1]
ZHANG Yunzuo, GUO Wei, CAI Zhaoquan, et al Remote sensing image target detection combining multi-scale and attention mechanism
[J]. Journal of Zhejiang University:Engineering Science , 2022 , 56 (11 ): 2215 - 2223
[本文引用: 1]
[25]
KIM M, KIM H, SUNG J, et al High-resolution processing and sigmoid fusion modules for efficient detection of small objects in an embedded system
[J]. Scientific Reports , 2023 , 13 (1 ): 244
DOI:10.1038/s41598-022-27189-5
[本文引用: 1]
[26]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFS [EB/OL]. (2014-12-22). https://arxiv.org/abs/1412.7062.
[本文引用: 1]
[27]
ZHAN W, SUN C F, WANG M C, et al An improved YOLOv5 real-time detection method for small objects captured by UAV
[J]. Soft Computing , 2022 , 26 : 361 - 373
DOI:10.1007/s00500-021-06407-8
[本文引用: 1]
[28]
WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: ECCV. 2018: 3−19.
[本文引用: 1]
[29]
DU D W, ZHU P F, WEN L Y, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Seoul: IEEE, 2019.
[本文引用: 1]
[30]
ZHANG S F, WEN L Y, BIAN X, et al. Single-shot refinement neural network for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4203−4212.
[本文引用: 1]
[31]
LIU S H, ZHA J L, SUN J, et al. EdgeYOLO: an edge-real-time object detector [EB/OL]. [2023-02-15]. https://arxiv.org/abs/2302.07483.
[本文引用: 2]
[32]
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. Scaled-YOLOv4: scaling cross stage partial network [C]// Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13029−13038.
[本文引用: 2]
[33]
CUI L S, MA R, LV P, et al MDSSD: multi-scale deconvolutional single shot detector for small objects
[J]. Science China Information Sciences , 2020 , 63 : 120113
DOI:10.1007/s11432-019-2723-1
[本文引用: 2]
[34]
ZHANG J Q, LEI J, XIE W Y, et al SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 1 - 15
[本文引用: 2]
Sensors and measurements for UAV safety: an overview
1
2021
... 随着无人机技术和功能的逐渐完善,各个领域都出现无人机的身影,这在丰富和便利人们日常生活的同时,也带来极大的安全隐患. 管控不当导致黑飞乱飞事件的日益增多,给公共安全和人民生活带来极大的威胁[1 ] . 因此,须采用反无人机系统来防范非法无人机的侵入. 在反无人机系统中,检测被视为至关重要的环节,因为只有在准确检测到无人机的存在之后,才能采取进一步的反制措施. 因此,对现实场景中低空飞行的无人机进行快速准确检测具有重要的现实意义. ...
A survey and performance evaluation of deep learning methods for small object detection
1
2021
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
1
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
基于YOLOv5s的无人机密集小目标检测算法
1
2023
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
基于YOLOv5s的无人机密集小目标检测算法
1
2023
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
1
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
1
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2016
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
1
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
基于分割注意力与线性变换的轻量化目标检测
1
2023
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
基于分割注意力与线性变换的轻量化目标检测
1
2023
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
1
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
1
... 目标检测作为近年来计算机视觉领域的热门研究方向之一,在视觉搜索、虚拟现实、增强现实、自动驾驶等场景应用广泛[2 ] . 随着卷积神经网络( convolutional neural network,CNN)[3 ] 的不断发展,基于深度学习的目标检测算法发展迅猛. 目前,基于深度学习的目标检测算法可以分为基于回归的单阶段目标检测算法和基于候选区域的两阶段目标检测算法[4 ] . 比较有代表性的两阶段算法有RCNN[5 ] 、Fast-RCNN[6 ] 、Faster-RCNN[7 ] 、Mask R-CNN[8 ] 等. 这类算法须先从生成的多个候选区域中提取特征,然后进行类标签和边界框的输出,检测精度较高,但是复杂的结构致使检测速度较慢,难以满足实时性的要求[9 ] . 以YOLO[10 ] 、SSD[11 ] 为代表的单阶段算法通过提取的特征直接回归目标的坐标和类别,具有检测速度快的优点,但检测精度往往不如两阶段算法. 这2类算法对大目标和中目标的检测效果较好,但是在小目标检测方面效果并不理想. 虽然两阶段算法具有较高的检测精度,但是无法突破检测速度的限制. 对于一些实时性检测任务,无法满足速度要求. 对于实际场景下的无人机目标检测须采用极高检测速度的算法,因此更适合使用单阶段算法来进行研究. ...
M2YOLOF: based on effective receptive fields and multiple-in-single-out encoder for object detection
1
2023
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
Small object detection method based on weighted feature fusion and CSMA attention module
1
2022
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
Attentional feature pyramid network for small object detection
1
2022
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
A simple and efficient network for small target detection
1
2019
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
Extended feature pyramid network for small object detection
1
2021
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
Small object detection in traffic scenes based on YOLO-MXANet
1
2021
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
An improved algorithm for small object detection based on YOLOv4 and multi-scale contextual information
1
2023
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
基于优化预测定位的单阶段目标检测算法
1
2022
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
基于优化预测定位的单阶段目标检测算法
1
2022
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
基于特征优化与深层次融合的目标检测算法
1
2022
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
基于特征优化与深层次融合的目标检测算法
1
2022
... 无人机作为小目标的一种,经过多层特征提取网络后,其分辨率降低,部分重要信息丢失. 因此,实现无人机小目标的快速精准检测绝非易事. 目前,诸多学者针对小目标检测提出有效的改进方法,检测性能不断提高. Wang等[12 ] 将金字塔最顶层2个特征图通过注意力编码器进行特征融合,以增强特征图的局部特征和全局表征. Peng等[13 ] 提出通道空间混合注意模块,抑制无用特征信息. Min等[14 ] 提出注意特征金字塔网络结构,过滤冗余信息突出小目标,并通过前景相关上下文增强特征,抑制背景噪声. 上述文献在特征融合时抑制冗余信息方面具有一定的效果,但是对于无人机此类微小目标的检测不能保证足够的精度. Ju等[15 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. Deng等[16 ] 设计扩张模块减少信息损失,并设计穿透模块来融合浅层细节信息和深层语义信息. He等[17 ] 提出多尺度特征增强融合网络,更好地融合提取的特征,同时提出SCSA模块提高交通场景中小目标的检测精度. Ji等[18 ] 提出扩展的感知块获取更多的上下文特征,并在CIoU的权重函数中引入纵横比权重因子增强网络对小目标的学习能力. 张娜等[19 ] 提出双向加权特征金字塔网络,对解码后的位置信息进行通道再分配,进一步融合特征信息. 谢誉等[20 ] 提出深层次特征金字塔网络,深层次融合多尺度特征层. 上述文献可以进一步增强小目标的特征信息,但是忽略了融合语义不一致特征时的冲突问题. ...
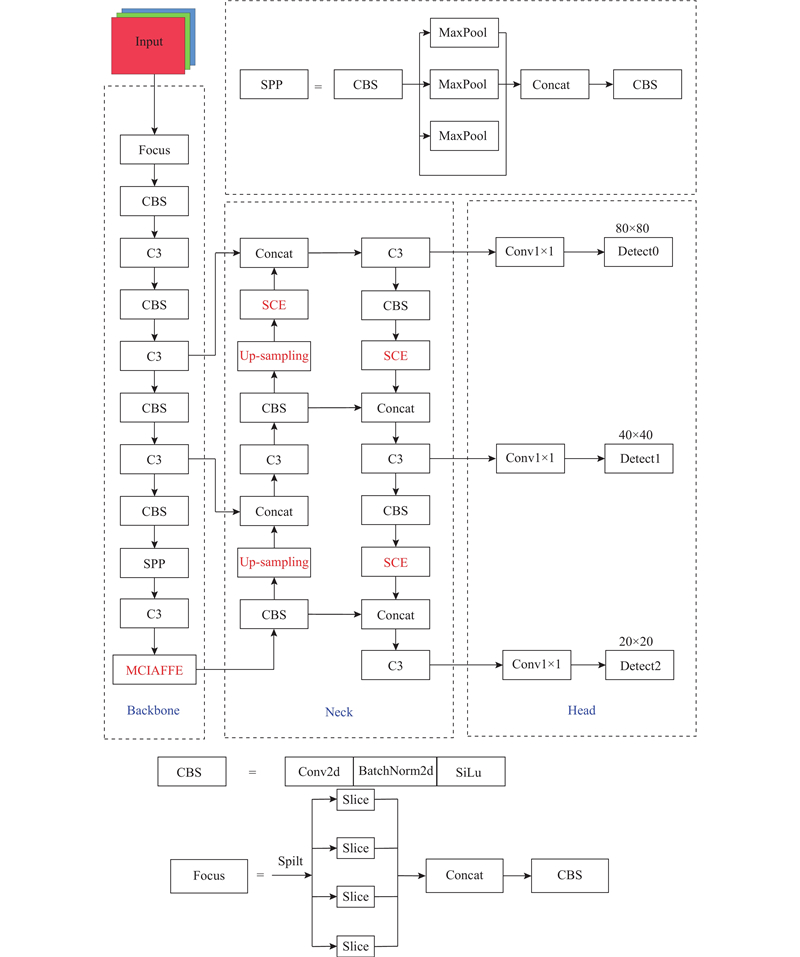
1
... YOLOv5作为端到端的单阶段检测网络,实现了检测速度和精度兼顾,能以极快的速度对目标完成分类和定位任务,被广泛应用于实时性要求高的目标检测任务中. YOLOv5整体结构分为3部分:骨干网络(Backbone)、特征融合网络(Neck)和检测头(Head). 输入图片在进行训练之前采用和YOLOv4[21 ] 一样的Mosaic数据增强方式,将4张图片经过随机剪裁、缩放变换后拼接在一起,不仅可以扩充数据集,而且可以提高训练速度,使模型具有更好的鲁棒性. ...
1
... Backbone网络的主要作用是提取图像特征,将输入的3维图像转化为多层特征图. 在网络训练过程中,输入图像经过Backbone结构实现32倍下采样提取特征. Neck网络的主要作用是跨层融合多尺度的特征图,整体采用PAN[22 ] 结构,该结构通过上采样和下采样可以得到与Backbone中相同尺度、包含丰富语义信息的深层特征图. 通过融合多尺度的深层特征与浅层特征,得到更丰富的特征表示,最终输出尺度为20×20、40×40、80×80的3个特征图,分别负责对大、中、小目标的检测[23 ] . Head网络生成目标的边界框和类别概率,从而实现目标定位和分类[24 ] . ...
Sf-YOLOv5: a lightweight small object detection algorithm based on improved feature fusion mode
1
2022
... Backbone网络的主要作用是提取图像特征,将输入的3维图像转化为多层特征图. 在网络训练过程中,输入图像经过Backbone结构实现32倍下采样提取特征. Neck网络的主要作用是跨层融合多尺度的特征图,整体采用PAN[22 ] 结构,该结构通过上采样和下采样可以得到与Backbone中相同尺度、包含丰富语义信息的深层特征图. 通过融合多尺度的深层特征与浅层特征,得到更丰富的特征表示,最终输出尺度为20×20、40×40、80×80的3个特征图,分别负责对大、中、小目标的检测[23 ] . Head网络生成目标的边界框和类别概率,从而实现目标定位和分类[24 ] . ...
联合多尺度与注意力机制的遥感图像目标检测
1
2022
... Backbone网络的主要作用是提取图像特征,将输入的3维图像转化为多层特征图. 在网络训练过程中,输入图像经过Backbone结构实现32倍下采样提取特征. Neck网络的主要作用是跨层融合多尺度的特征图,整体采用PAN[22 ] 结构,该结构通过上采样和下采样可以得到与Backbone中相同尺度、包含丰富语义信息的深层特征图. 通过融合多尺度的深层特征与浅层特征,得到更丰富的特征表示,最终输出尺度为20×20、40×40、80×80的3个特征图,分别负责对大、中、小目标的检测[23 ] . Head网络生成目标的边界框和类别概率,从而实现目标定位和分类[24 ] . ...
联合多尺度与注意力机制的遥感图像目标检测
1
2022
... Backbone网络的主要作用是提取图像特征,将输入的3维图像转化为多层特征图. 在网络训练过程中,输入图像经过Backbone结构实现32倍下采样提取特征. Neck网络的主要作用是跨层融合多尺度的特征图,整体采用PAN[22 ] 结构,该结构通过上采样和下采样可以得到与Backbone中相同尺度、包含丰富语义信息的深层特征图. 通过融合多尺度的深层特征与浅层特征,得到更丰富的特征表示,最终输出尺度为20×20、40×40、80×80的3个特征图,分别负责对大、中、小目标的检测[23 ] . Head网络生成目标的边界框和类别概率,从而实现目标定位和分类[24 ] . ...
High-resolution processing and sigmoid fusion modules for efficient detection of small objects in an embedded system
1
2023
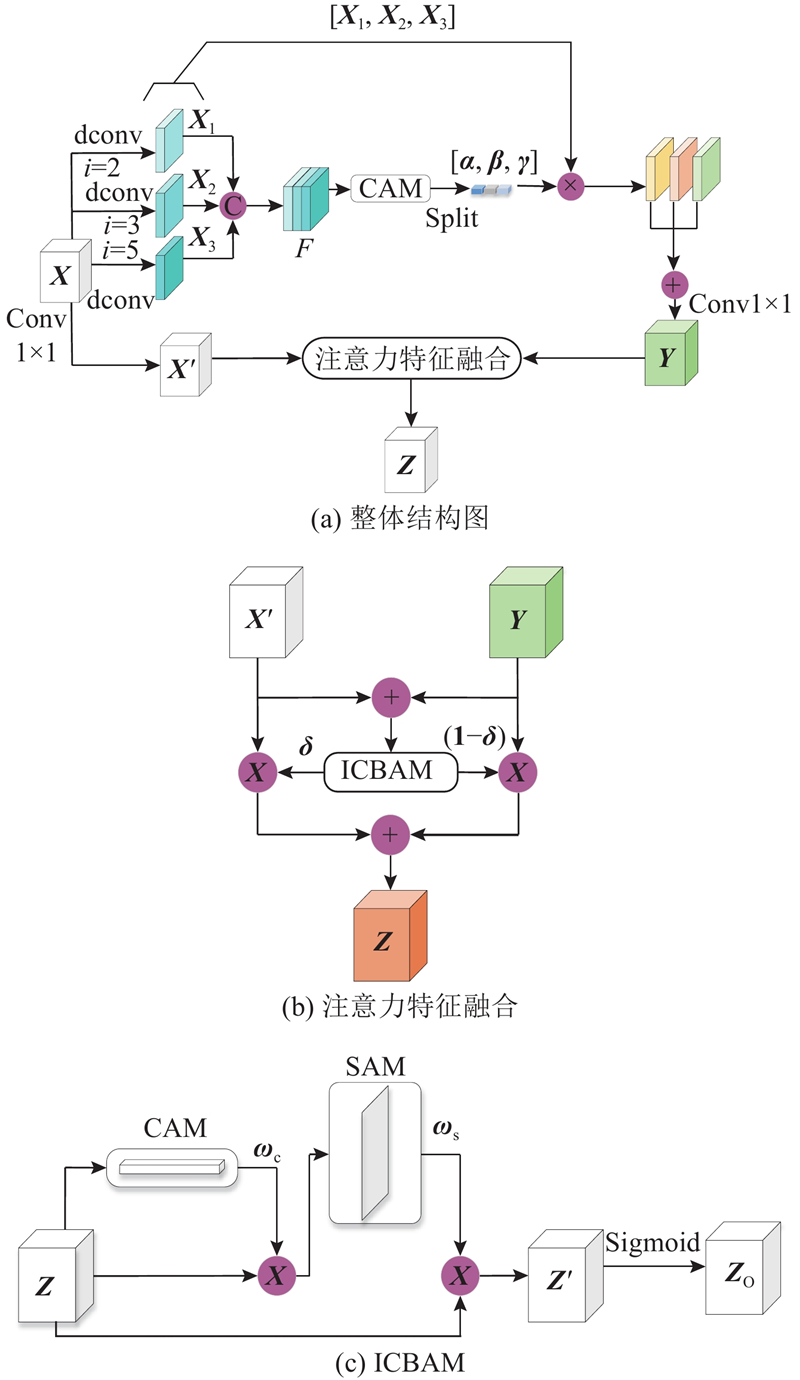
... 无人机小目标的特征信息主要集中在拥有丰富位置信息和细节信息的浅层特征中,但高层特征图中包含的丰富的语义信息也不可忽略. 为了解决在特征提取过程中,高层特征图中无人机小目标的低级特征丢失导致检测能力较弱的问题,须将浅层特征图的上下文信息融入到高层特征图中,即使得上下文信息能为小目标检测提供更有效的信息[25 ] ,故对金字塔最顶层进行特征融合增强. 设计多尺度上下文信息和注意力特征融合增强模块MCIAFFE,该模块结构如图2 所示. ...
1
... 如图2 (a)所示为多尺度上下文信息和注意力特征融合增强模块整体结构图. 首先,使用2、3、5这3个空洞率不同的空洞卷积对输入特征图${\boldsymbol{X}}$ [26 ] ,得到${{\boldsymbol{X}}_1}$ ${{\boldsymbol{X}}_2}$ ${{\boldsymbol{X}}_3}$
An improved YOLOv5 real-time detection method for small objects captured by UAV
1
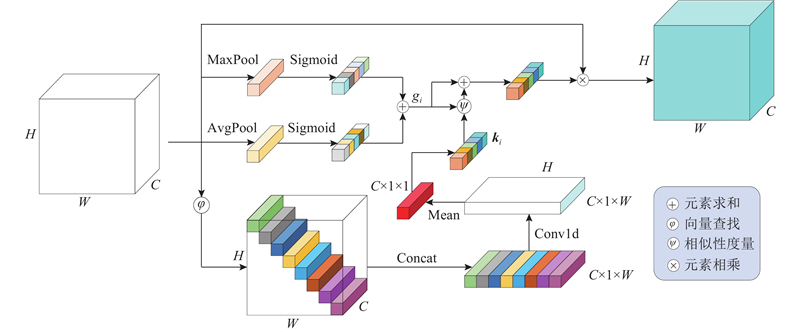
2022
... 式中:$ {\mathrm{split}}\;(\cdot ) $ $ S\;(\cdot ) $ [27 ] ;$ {\mathrm{MLP}}\;(\cdot ) $ $ {P}_{{\mathrm{a}}}\;(\cdot ) $ $ {P}_{{\mathrm{m}}}\;(\cdot ) $ $H \times W \times C$ C 大小的向量. ...
1
... ICBAM为改进的CBAM[28 ] ,ICBAM结构如图2 (c)所示. 首先经过CAM得到权重${{\boldsymbol{\omega}} _{\mathrm{c}}}$ ${{\boldsymbol{\omega}} _{\mathrm{s}}}$ . 无人机小目标的重要特征是浅层的低级信息,而非高层的语义信息,输入${\boldsymbol{Z}}$ ${{\boldsymbol{\omega}} _{\mathrm{s}}}$ ${\boldsymbol{Z}}$ ${{\boldsymbol{Z}}_{\mathrm{o}}}$
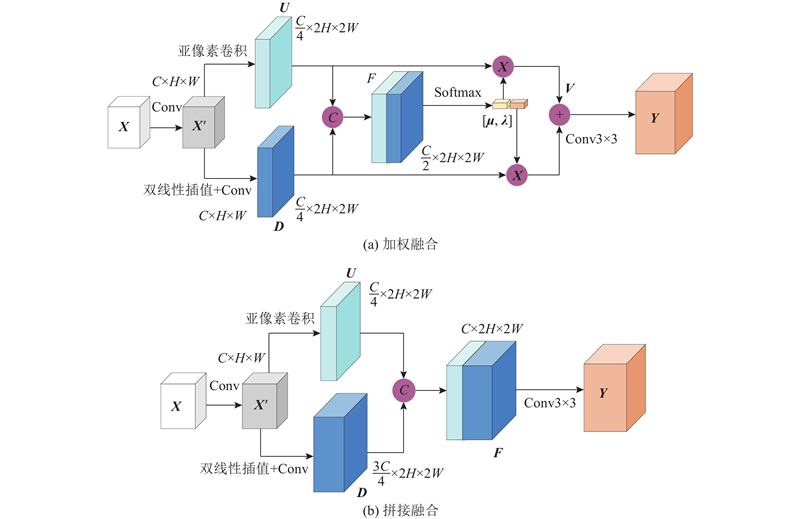
1
... 为了证明2种融合方式的优劣,在公共数据集VisDrone2019[29 ] 上进行对比实验,实验结果如表1 所示. 表中,P 为准确率,R 为召回率,mAP0.5表示IoU为0.5时所有类别的平均精度;mAP0.5∶0.95表示IoU在0.50~0.95以0.05的步长变化求得的10个检测精度的平均值;GFLOPs为10亿次浮点运算,用于表示模型的复杂度;基线模型为在YOLOv5算法模型的基础上引入了MCIAFFE和SCE模块. 相比于拼接融合方式,加权融合模型复杂度较小,且其他指标均有提升,因此本研究选择加权融合方式对${\boldsymbol{U}}$ ${\boldsymbol{D}}$
1
... Experimental results of different detection methods on self-made UAV dataset
Tab.4 方法 输入尺寸 P /%R /%mAP0.5/% mAP0.5∶0.95/% SSD 300×300 — — 48.6 — Refinedet[30 ] 512×512 — — 63.5 — YOLOv4 416×412 77.6 66.0 64.4 18.8 YOLOv5 640×640 92.9 70.5 73.7 29.8 Edgeyolo[31 ] 640×640 — — 63.1 24.5 ScaledYOLOv4[32 ] 640×640 93.0 73.2 72.5 30.7 MDSSD[33 ] 300×300 — — 59.3 — SuperYOLO[34 ] 640×640 88.7 71.9 75.5 31.6 本研究算法 640×640 94.5 74.8 76.1 32.5
为了进一步验证本研究算法的有效性,在公共数据集VisDrone2019上进行实验,并与原始YOLOv5目标检测模型进行对比,实验结果如表5 所示. 表中,模型A为3.2节中提到的基线模型,即在YOLOv5算法上引入了MCIAFFE和SCE. 可以看出,本研究提出的改进算法在VisDrone2019数据集上依然具有良好的性能,具体表现为:mAP0.5比原始YOLOv5模型提高了4.6%,mAP0.5∶0.95提高了1.3%,P 和R 分别具有4.6%和4.3%的提升,其中相对于模型A来说,替换本研究提出的上采样方式后,GFLOPs仅增加了1.6,且其他指标均略有上升. ...
2
... 为了验证所提算法在无人机小目标检测方面具有良好的性能,在自制数据集上将所提算法与目前主流检测算法进行对比,结果如表4 所示. 可以看出,所提算法在几种经典的通用目标检测算法当中具有良好的检测性能,其中相比于SSD算法,mAP0.5提高27.5%;相比于Refinedet算法,mAP0.5提高了12.6%;相比于YOLOv4算法,mAP0.5和mAP0.5∶0.95分别提高了11.7%和13.7%;与YOLOv5相比,mAP0.5和mAP0.5∶0.95也有2.4%和2.7%的提高;与先进的改进通用目标检测算法相比,也表现出良好的性能,相比于Edgeyolo[31 ] ,所提算法的mAP0.5和mAP0.5∶0.95分别提高了13%和8%;与ScaledYOLOv4[32 ] 相比,本研究算法依然具有更好的检测能力,其中P 、R 、mAP0.5和mAP0.5∶0.95分别提高了1.5%,1.6%,3.6%和1.8%. 与其他小目标检测算法相比,所提算法也表现更好,如与MDSSD[33 ] 相比,mAP0.5提高了16.8%,与SuperYOLO[34 ] 相比,所提算法的P 、R 、mAP0.5和mAP0.5∶0.95分别提高了5.8%、2.9%、0.6%和0.9%. ...
... Experimental results of different detection methods on self-made UAV dataset
Tab.4 方法 输入尺寸 P /%R /%mAP0.5/% mAP0.5∶0.95/% SSD 300×300 — — 48.6 — Refinedet[30 ] 512×512 — — 63.5 — YOLOv4 416×412 77.6 66.0 64.4 18.8 YOLOv5 640×640 92.9 70.5 73.7 29.8 Edgeyolo[31 ] 640×640 — — 63.1 24.5 ScaledYOLOv4[32 ] 640×640 93.0 73.2 72.5 30.7 MDSSD[33 ] 300×300 — — 59.3 — SuperYOLO[34 ] 640×640 88.7 71.9 75.5 31.6 本研究算法 640×640 94.5 74.8 76.1 32.5
为了进一步验证本研究算法的有效性,在公共数据集VisDrone2019上进行实验,并与原始YOLOv5目标检测模型进行对比,实验结果如表5 所示. 表中,模型A为3.2节中提到的基线模型,即在YOLOv5算法上引入了MCIAFFE和SCE. 可以看出,本研究提出的改进算法在VisDrone2019数据集上依然具有良好的性能,具体表现为:mAP0.5比原始YOLOv5模型提高了4.6%,mAP0.5∶0.95提高了1.3%,P 和R 分别具有4.6%和4.3%的提升,其中相对于模型A来说,替换本研究提出的上采样方式后,GFLOPs仅增加了1.6,且其他指标均略有上升. ...
2
... 为了验证所提算法在无人机小目标检测方面具有良好的性能,在自制数据集上将所提算法与目前主流检测算法进行对比,结果如表4 所示. 可以看出,所提算法在几种经典的通用目标检测算法当中具有良好的检测性能,其中相比于SSD算法,mAP0.5提高27.5%;相比于Refinedet算法,mAP0.5提高了12.6%;相比于YOLOv4算法,mAP0.5和mAP0.5∶0.95分别提高了11.7%和13.7%;与YOLOv5相比,mAP0.5和mAP0.5∶0.95也有2.4%和2.7%的提高;与先进的改进通用目标检测算法相比,也表现出良好的性能,相比于Edgeyolo[31 ] ,所提算法的mAP0.5和mAP0.5∶0.95分别提高了13%和8%;与ScaledYOLOv4[32 ] 相比,本研究算法依然具有更好的检测能力,其中P 、R 、mAP0.5和mAP0.5∶0.95分别提高了1.5%,1.6%,3.6%和1.8%. 与其他小目标检测算法相比,所提算法也表现更好,如与MDSSD[33 ] 相比,mAP0.5提高了16.8%,与SuperYOLO[34 ] 相比,所提算法的P 、R 、mAP0.5和mAP0.5∶0.95分别提高了5.8%、2.9%、0.6%和0.9%. ...
... Experimental results of different detection methods on self-made UAV dataset
Tab.4 方法 输入尺寸 P /%R /%mAP0.5/% mAP0.5∶0.95/% SSD 300×300 — — 48.6 — Refinedet[30 ] 512×512 — — 63.5 — YOLOv4 416×412 77.6 66.0 64.4 18.8 YOLOv5 640×640 92.9 70.5 73.7 29.8 Edgeyolo[31 ] 640×640 — — 63.1 24.5 ScaledYOLOv4[32 ] 640×640 93.0 73.2 72.5 30.7 MDSSD[33 ] 300×300 — — 59.3 — SuperYOLO[34 ] 640×640 88.7 71.9 75.5 31.6 本研究算法 640×640 94.5 74.8 76.1 32.5
为了进一步验证本研究算法的有效性,在公共数据集VisDrone2019上进行实验,并与原始YOLOv5目标检测模型进行对比,实验结果如表5 所示. 表中,模型A为3.2节中提到的基线模型,即在YOLOv5算法上引入了MCIAFFE和SCE. 可以看出,本研究提出的改进算法在VisDrone2019数据集上依然具有良好的性能,具体表现为:mAP0.5比原始YOLOv5模型提高了4.6%,mAP0.5∶0.95提高了1.3%,P 和R 分别具有4.6%和4.3%的提升,其中相对于模型A来说,替换本研究提出的上采样方式后,GFLOPs仅增加了1.6,且其他指标均略有上升. ...
MDSSD: multi-scale deconvolutional single shot detector for small objects
2
2020
... 为了验证所提算法在无人机小目标检测方面具有良好的性能,在自制数据集上将所提算法与目前主流检测算法进行对比,结果如表4 所示. 可以看出,所提算法在几种经典的通用目标检测算法当中具有良好的检测性能,其中相比于SSD算法,mAP0.5提高27.5%;相比于Refinedet算法,mAP0.5提高了12.6%;相比于YOLOv4算法,mAP0.5和mAP0.5∶0.95分别提高了11.7%和13.7%;与YOLOv5相比,mAP0.5和mAP0.5∶0.95也有2.4%和2.7%的提高;与先进的改进通用目标检测算法相比,也表现出良好的性能,相比于Edgeyolo[31 ] ,所提算法的mAP0.5和mAP0.5∶0.95分别提高了13%和8%;与ScaledYOLOv4[32 ] 相比,本研究算法依然具有更好的检测能力,其中P 、R 、mAP0.5和mAP0.5∶0.95分别提高了1.5%,1.6%,3.6%和1.8%. 与其他小目标检测算法相比,所提算法也表现更好,如与MDSSD[33 ] 相比,mAP0.5提高了16.8%,与SuperYOLO[34 ] 相比,所提算法的P 、R 、mAP0.5和mAP0.5∶0.95分别提高了5.8%、2.9%、0.6%和0.9%. ...
... Experimental results of different detection methods on self-made UAV dataset
Tab.4 方法 输入尺寸 P /%R /%mAP0.5/% mAP0.5∶0.95/% SSD 300×300 — — 48.6 — Refinedet[30 ] 512×512 — — 63.5 — YOLOv4 416×412 77.6 66.0 64.4 18.8 YOLOv5 640×640 92.9 70.5 73.7 29.8 Edgeyolo[31 ] 640×640 — — 63.1 24.5 ScaledYOLOv4[32 ] 640×640 93.0 73.2 72.5 30.7 MDSSD[33 ] 300×300 — — 59.3 — SuperYOLO[34 ] 640×640 88.7 71.9 75.5 31.6 本研究算法 640×640 94.5 74.8 76.1 32.5
为了进一步验证本研究算法的有效性,在公共数据集VisDrone2019上进行实验,并与原始YOLOv5目标检测模型进行对比,实验结果如表5 所示. 表中,模型A为3.2节中提到的基线模型,即在YOLOv5算法上引入了MCIAFFE和SCE. 可以看出,本研究提出的改进算法在VisDrone2019数据集上依然具有良好的性能,具体表现为:mAP0.5比原始YOLOv5模型提高了4.6%,mAP0.5∶0.95提高了1.3%,P 和R 分别具有4.6%和4.3%的提升,其中相对于模型A来说,替换本研究提出的上采样方式后,GFLOPs仅增加了1.6,且其他指标均略有上升. ...
SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery
2
2023
... 为了验证所提算法在无人机小目标检测方面具有良好的性能,在自制数据集上将所提算法与目前主流检测算法进行对比,结果如表4 所示. 可以看出,所提算法在几种经典的通用目标检测算法当中具有良好的检测性能,其中相比于SSD算法,mAP0.5提高27.5%;相比于Refinedet算法,mAP0.5提高了12.6%;相比于YOLOv4算法,mAP0.5和mAP0.5∶0.95分别提高了11.7%和13.7%;与YOLOv5相比,mAP0.5和mAP0.5∶0.95也有2.4%和2.7%的提高;与先进的改进通用目标检测算法相比,也表现出良好的性能,相比于Edgeyolo[31 ] ,所提算法的mAP0.5和mAP0.5∶0.95分别提高了13%和8%;与ScaledYOLOv4[32 ] 相比,本研究算法依然具有更好的检测能力,其中P 、R 、mAP0.5和mAP0.5∶0.95分别提高了1.5%,1.6%,3.6%和1.8%. 与其他小目标检测算法相比,所提算法也表现更好,如与MDSSD[33 ] 相比,mAP0.5提高了16.8%,与SuperYOLO[34 ] 相比,所提算法的P 、R 、mAP0.5和mAP0.5∶0.95分别提高了5.8%、2.9%、0.6%和0.9%. ...
... Experimental results of different detection methods on self-made UAV dataset
Tab.4 方法 输入尺寸 P /%R /%mAP0.5/% mAP0.5∶0.95/% SSD 300×300 — — 48.6 — Refinedet[30 ] 512×512 — — 63.5 — YOLOv4 416×412 77.6 66.0 64.4 18.8 YOLOv5 640×640 92.9 70.5 73.7 29.8 Edgeyolo[31 ] 640×640 — — 63.1 24.5 ScaledYOLOv4[32 ] 640×640 93.0 73.2 72.5 30.7 MDSSD[33 ] 300×300 — — 59.3 — SuperYOLO[34 ] 640×640 88.7 71.9 75.5 31.6 本研究算法 640×640 94.5 74.8 76.1 32.5
为了进一步验证本研究算法的有效性,在公共数据集VisDrone2019上进行实验,并与原始YOLOv5目标检测模型进行对比,实验结果如表5 所示. 表中,模型A为3.2节中提到的基线模型,即在YOLOv5算法上引入了MCIAFFE和SCE. 可以看出,本研究提出的改进算法在VisDrone2019数据集上依然具有良好的性能,具体表现为:mAP0.5比原始YOLOv5模型提高了4.6%,mAP0.5∶0.95提高了1.3%,P 和R 分别具有4.6%和4.3%的提升,其中相对于模型A来说,替换本研究提出的上采样方式后,GFLOPs仅增加了1.6,且其他指标均略有上升. ...



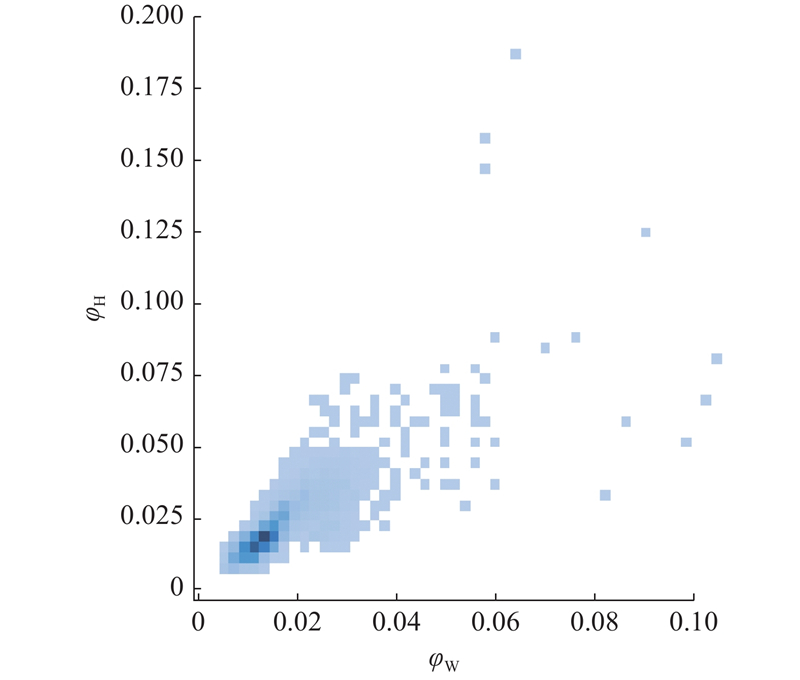
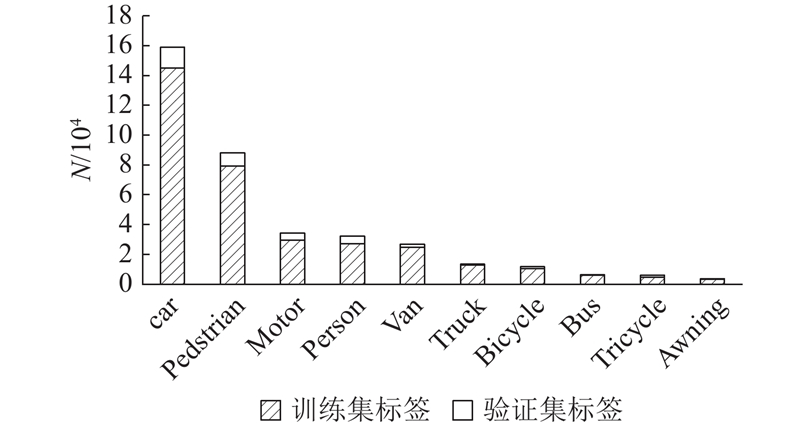
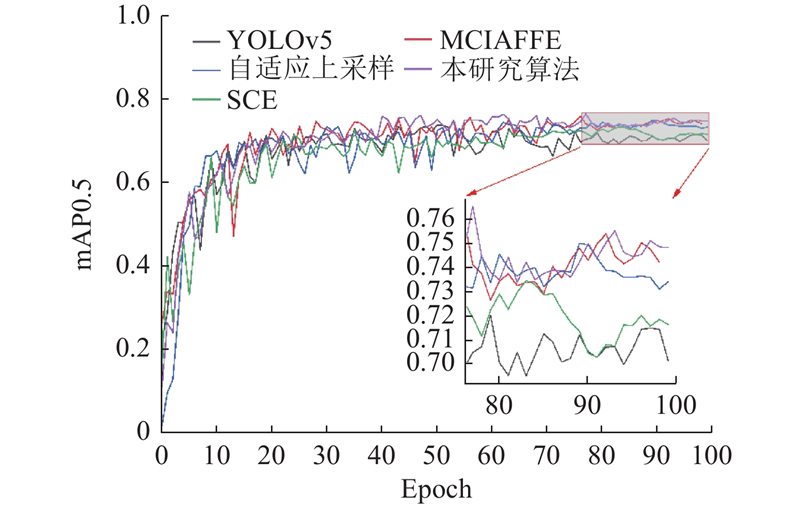



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}