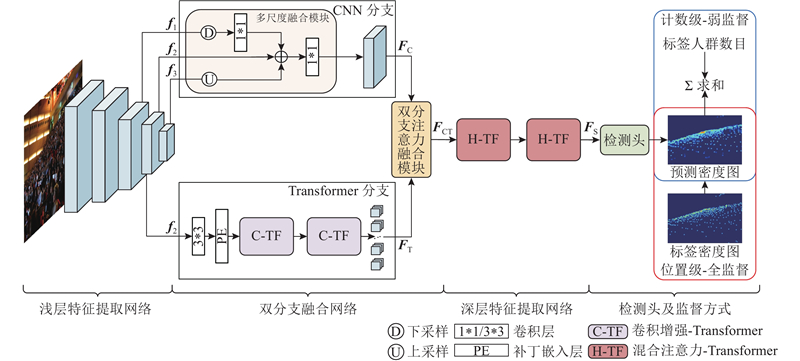
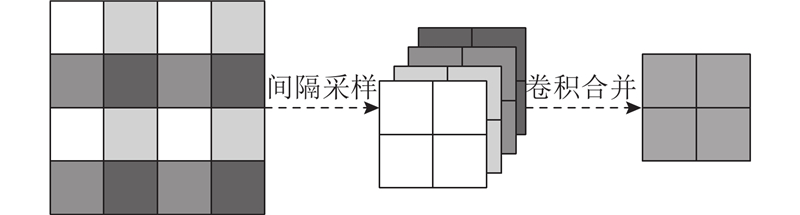
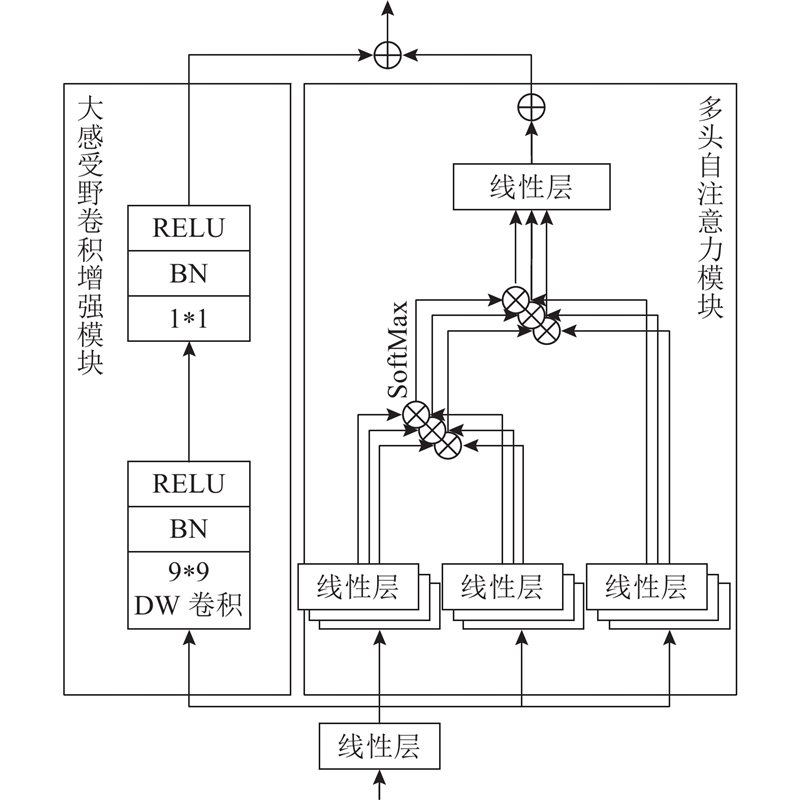
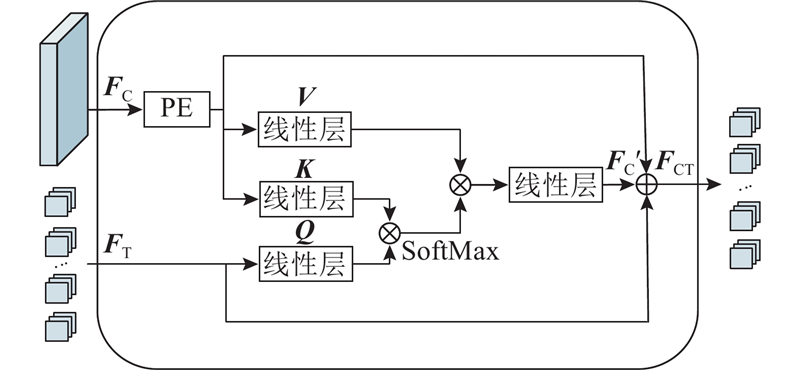
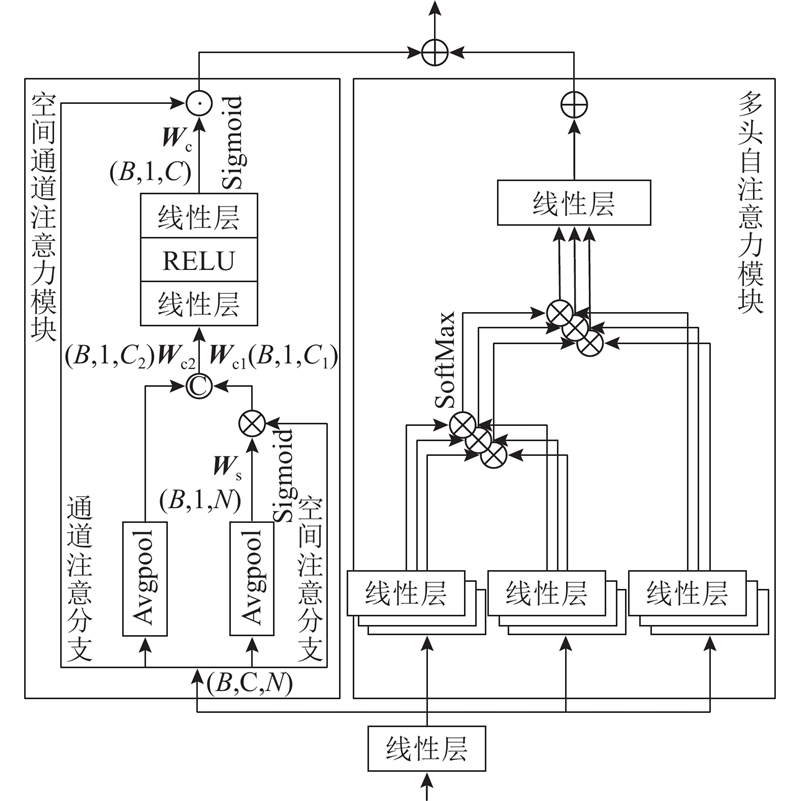
针对密集人群计数中人头尺度变化大、复杂背景干扰的问题,提出基于自注意力机制的双分支密集人群计数算法. 该算法结合卷积神经网络(CNN)和Transformer 2种网络框架,通过多尺度CNN分支和基于卷积增强自注意力模块的Transformer分支,分别获取人群局部信息和全局信息. 设计双分支注意力融合模块,以具备连续尺度的人群特征提取能力;通过基于混合注意力模块的Transformer网络提取深度特征,进一步区分复杂背景并聚焦人群区域. 采用位置级-全监督方式和计数级-弱监督方式,在ShanghaiTech Part A、ShanghaiTech Part B、UCF-QNRF、JHU-Crowd++等数据集上进行实验. 结果表明,算法在4个数据集上的性能均优于最近研究,全监督算法在上述数据集的平均绝对误差和均方根误差分别为55.3、6.7、82.9、55.7和93.1、9.8、145.1、248.0,可以实现高密集、高遮挡场景下的准确计数. 特别是在弱监督算法对比中,以低参数量实现了更佳的计数精度,并达到全监督87.9%的计数效果.
关键词:人群计数
;
深度学习
;
自注意力机制
;
双分支
;
弱监督学习
Abstract
A dual-branch crowd counting algorithm based on self-attention mechanism was proposed to solve the problems of large variation in head scale and complex background interference in crowd counting. The algorithm combined two network frameworks, including convolutional neural network (CNN) and Transformer. The multi-scale CNN branch and Transformer branch based on convolution enhanced self-attention module were used to obtain local and global crowd information respectively. The dual-branch attention fusion module was designed to enable continuous-scale crowd feature extraction. The Transformer network with the hybrid attention module was utilized to extract deep features, which facilitated the distinction of complex backgrounds and focused on the crowd regions. The experiments were conducted on ShanghaiTech Part A, ShanghaiTech Part B, UCF-QNRF, JHU-Crowd++ and other datasets using position-level full supervision and count-level weak supervision. Results showed that the performance of the proposed algorithms was better than that of recent studies. The MAE and MSE of the fully supervised algorithm in the above datasets were 55.3, 6.7, 82.9, 55.7, and 93.1, 9.8, 145.1, 248.0, respectively, which could achieve accurate counting in high density and high occlusion scenes. Good counting precision was achieved with low parameters, and a counting accuracy of 87.9% of the full supervision was attained especially in the comparison of weakly supervised algorithms.
YANG Tian-le, LI Ling-xia, ZHANG Wei. Dual-branch crowd counting algorithm based on self-attention mechanism. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(10): 1955-1965 doi:10.3785/j.issn.1008-973X.2023.10.005
ShanghaiTech: ShanghaiTech数据集[11]包含了1 195张标注图片和330 165个标注人数,数据集由Part A和Part B这2个部分组成. Part A由482张从互联网收集的高密集场景下的图片组成,训练集与测试集的数量比例为300∶182. Part A中单张图片人数在33~3 139,是一个高度密集的数据集. Part B由716张上海街道图片组成,训练集与测试集的数量比例为400∶316. Part B中单张图片人数为9~578,是相对稀疏的数据集. 在训练过程中,对于Part A数据集,Patch大小设置为256×256;对于Part B数据集,由于人群较稀疏且分辨率较差,裁剪大小设置为512×512.
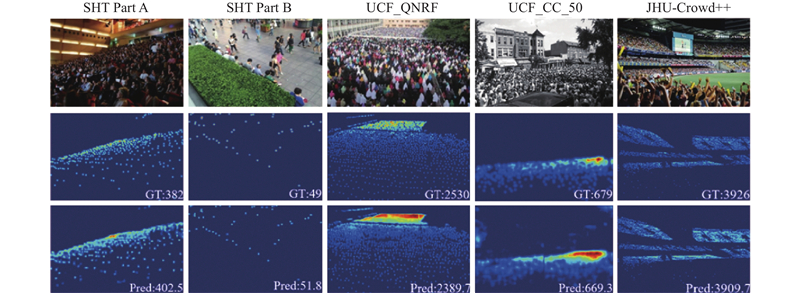
将模型输出进行可视化展示,图7展示全监督下的模型在4个数据集上的预测密度图. 其中,SHT Part B和UCF_CC_50图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A和QNRF图片为复杂场景、多尺度人头大小和遮挡下的检测效果. 由图7可以看出,预测密度图接近真实值,计数结果较为准确.
ZENG C, MA H. Robust Head-shoulder detection by PCA-based multilevel HOG-LBP detector for people counting [C]// 20th International Conference on Pattern Recognition. Istanbul: IEEE, 2010: 2069-2072.
LI M, ZHANG Z, HUANG K, et al. Estimating the number of people in crowded scenes by MID based foreground segmentation and head-shoulder detection [C]// 19th International Conference on Pattern Recognition. Tampa: IEEE, 2008: 1-4.
ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network [C]// Proceedings of the lEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 589-597.
LIU J, GAO C, MENG D, et al. DecideNet: counting varying density crowds through attention guided detection and density estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 5197-5206.
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 10012-10022.
CHEN X, WANG X, ZHOU J, et al. Activating more pixels in image super-resolution transformer [EB/OL]. [2022-05-09]. https://arxiv.org/abs/2205.04437.pdf.
WANG B, LIU H, SAMARAS D, et al. Distribution matching for crowd counting [C]// Proceedings of the Advances in Neural Information Processing Systems. Vancouver: CA, 2020: 1595-1607.
IDRESS H, TAYYAB M, ATHREY K, et al. Composition loss for counting, density map estimation and localization in dense crowds [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 532-546.
IDRESS H, SALEEMI I, SEIBERT C, et al. Multi-source multi-scale counting in extremely dense crowd images [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Portland: IEEE, 2013: 2547-2554.
LI Y, ZHANG X, CHEN D. Csrnet: dilated convolutional neural networks for understanding the highly congested scenes [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt lake city: IEEE, 2018: 1091-1100.
MA Z, WEI X, HONG X, et al. Bayesian loss for crowd count estimation with point supervision [C]// IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 6141-6150.
WAN J, LIU Z, CHAN A. A generalized loss function for crowd counting and localization [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1974-1983.
LIANG D, XU W, BAI X. An end-to-end transformer model for crowd localization [C]// Proceedings of the European Conference on Computer Vision. Cham: Springer, 2022: 38-54.
ZENG X, HU S, WANG H, et al. Joint contextual transformer and multi-scale information shared network for crowd counting [C]// 5th International Conference on Pattern Recognition and Artificial Intelligence. Chengdu: IEEE, 2022: 412-417.
YANG Y, WU Z, SU L, et al. Weakly-supervised crowd counting learns from sorting rather than locations [C]// Proceedings of European Conference on Computer Vision. Newcastle: Springer, 2020: 1-17.
PHUCT P. Attention in crowd counting using the transformer and density map to improve counting result [C]// 8th Nafosted Conference on Information and Computer Science. Hanoi: IEEE, 2021: 65-70.
RONG L, LI C. Coarse and fine-grained attention network with background-aware loss for crowd density map estimation [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2021: 3675-3684.
LIU W, SALZMANN M, FUA P. Context-aware crowd counting [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5094-5103.
TIAN Y, CHU X, WANG H. CCTrans: simplifying and improving crowd counting with transformer [EB/OL]. [2021-09-29]. https://arxiv.org/abs/2109.14483v1.pdf.
... ShanghaiTech: ShanghaiTech数据集[11]包含了1 195张标注图片和330 165个标注人数,数据集由Part A和Part B这2个部分组成. Part A由482张从互联网收集的高密集场景下的图片组成,训练集与测试集的数量比例为300∶182. Part A中单张图片人数在33~3 139,是一个高度密集的数据集. Part B由716张上海街道图片组成,训练集与测试集的数量比例为400∶316. Part B中单张图片人数为9~578,是相对稀疏的数据集. 在训练过程中,对于Part A数据集,Patch大小设置为256×256;对于Part B数据集,由于人群较稀疏且分辨率较差,裁剪大小设置为512×512. ...
... Results of position-level full supervision comparison experiment Tab.1
... Results of count-level weakly supervision comparison experiment Tab.2
算法
SHT Part A
SHT Part B
UCF_QNRF
UCF_CC_50
JHU-Crowd++
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
Yang[34]
104.6
145.2
12.3
21.2
—
—
—
—
—
—
MATT[15]
80.1
129.4
11.7
17.5
—
—
355.0
550.2
—
—
TDCrowd[35]
67.9
108.3
—
—
—
—
—
—
—
—
TransCrowd[16]
66.1
105.1
9.3
16.1
97.2
168.5
—
—
74.9
595.6
CCST[36]
62.8
94.1
8.3
13.4
93.7
166.9
190.7
289.0
61.4
239.3
DBCC-Net
60.1
94.0
7.5
12.5
90.9
156.3
177.1
237.9
61.3
241.8
2.3.2. 可视化结果
将模型输出进行可视化展示,图7展示全监督下的模型在4个数据集上的预测密度图. 其中,SHT Part B和UCF_CC_50图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A和QNRF图片为复杂场景、多尺度人头大小和遮挡下的检测效果. 由图7可以看出,预测密度图接近真实值,计数结果较为准确. ...
TransCrowd: weakly-supervised crowd counting with transformer
... Results of count-level weakly supervision comparison experiment Tab.2
算法
SHT Part A
SHT Part B
UCF_QNRF
UCF_CC_50
JHU-Crowd++
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
Yang[34]
104.6
145.2
12.3
21.2
—
—
—
—
—
—
MATT[15]
80.1
129.4
11.7
17.5
—
—
355.0
550.2
—
—
TDCrowd[35]
67.9
108.3
—
—
—
—
—
—
—
—
TransCrowd[16]
66.1
105.1
9.3
16.1
97.2
168.5
—
—
74.9
595.6
CCST[36]
62.8
94.1
8.3
13.4
93.7
166.9
190.7
289.0
61.4
239.3
DBCC-Net
60.1
94.0
7.5
12.5
90.9
156.3
177.1
237.9
61.3
241.8
2.3.2. 可视化结果
将模型输出进行可视化展示,图7展示全监督下的模型在4个数据集上的预测密度图. 其中,SHT Part B和UCF_CC_50图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A和QNRF图片为复杂场景、多尺度人头大小和遮挡下的检测效果. 由图7可以看出,预测密度图接近真实值,计数结果较为准确. ...
... Experimental results of time and space complexity comparison Tab.3
... Results of count-level weakly supervision comparison experiment Tab.2
算法
SHT Part A
SHT Part B
UCF_QNRF
UCF_CC_50
JHU-Crowd++
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
Yang[34]
104.6
145.2
12.3
21.2
—
—
—
—
—
—
MATT[15]
80.1
129.4
11.7
17.5
—
—
355.0
550.2
—
—
TDCrowd[35]
67.9
108.3
—
—
—
—
—
—
—
—
TransCrowd[16]
66.1
105.1
9.3
16.1
97.2
168.5
—
—
74.9
595.6
CCST[36]
62.8
94.1
8.3
13.4
93.7
166.9
190.7
289.0
61.4
239.3
DBCC-Net
60.1
94.0
7.5
12.5
90.9
156.3
177.1
237.9
61.3
241.8
2.3.2. 可视化结果
将模型输出进行可视化展示,图7展示全监督下的模型在4个数据集上的预测密度图. 其中,SHT Part B和UCF_CC_50图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A和QNRF图片为复杂场景、多尺度人头大小和遮挡下的检测效果. 由图7可以看出,预测密度图接近真实值,计数结果较为准确. ...
1
... Results of count-level weakly supervision comparison experiment Tab.2
算法
SHT Part A
SHT Part B
UCF_QNRF
UCF_CC_50
JHU-Crowd++
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
Yang[34]
104.6
145.2
12.3
21.2
—
—
—
—
—
—
MATT[15]
80.1
129.4
11.7
17.5
—
—
355.0
550.2
—
—
TDCrowd[35]
67.9
108.3
—
—
—
—
—
—
—
—
TransCrowd[16]
66.1
105.1
9.3
16.1
97.2
168.5
—
—
74.9
595.6
CCST[36]
62.8
94.1
8.3
13.4
93.7
166.9
190.7
289.0
61.4
239.3
DBCC-Net
60.1
94.0
7.5
12.5
90.9
156.3
177.1
237.9
61.3
241.8
2.3.2. 可视化结果
将模型输出进行可视化展示,图7展示全监督下的模型在4个数据集上的预测密度图. 其中,SHT Part B和UCF_CC_50图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A和QNRF图片为复杂场景、多尺度人头大小和遮挡下的检测效果. 由图7可以看出,预测密度图接近真实值,计数结果较为准确. ...
CCST: crowd counting with swin transformer
3
2023
... Results of count-level weakly supervision comparison experiment Tab.2
算法
SHT Part A
SHT Part B
UCF_QNRF
UCF_CC_50
JHU-Crowd++
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
MAE
MSE
Yang[34]
104.6
145.2
12.3
21.2
—
—
—
—
—
—
MATT[15]
80.1
129.4
11.7
17.5
—
—
355.0
550.2
—
—
TDCrowd[35]
67.9
108.3
—
—
—
—
—
—
—
—
TransCrowd[16]
66.1
105.1
9.3
16.1
97.2
168.5
—
—
74.9
595.6
CCST[36]
62.8
94.1
8.3
13.4
93.7
166.9
190.7
289.0
61.4
239.3
DBCC-Net
60.1
94.0
7.5
12.5
90.9
156.3
177.1
237.9
61.3
241.8
2.3.2. 可视化结果
将模型输出进行可视化展示,图7展示全监督下的模型在4个数据集上的预测密度图. 其中,SHT Part B和UCF_CC_50图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A和QNRF图片为复杂场景、多尺度人头大小和遮挡下的检测效果. 由图7可以看出,预测密度图接近真实值,计数结果较为准确. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}