

虚拟现实(virtual reality, VR)融合计算机图形学、多媒体、仿真等多种技术模拟出360°虚拟环境,能够为用户带来逼真、身临其境的观看和交互体验,广泛应用于工业、教育、艺术、医学、游戏娱乐等众多领域中. 在VR体验中极易产生头晕、恶心、呕吐等不适症状,严重者甚至会出现心率不齐、虚脱的情况,严重影响了VR技术与产业的发展. 对于VR体验中的这种不适,一些学者称其为运动病、模拟器病、网络病(cybersickness)、虚拟现实病(VR sickness)、视觉诱发运动病(visual induced motion sickness, VIMS)等. 这些名称存在相似之处,但不完全相同. 运动病通常是指人们暴露在真实环境(如乘车、船、飞机等)下因异常运动刺激产生的不适症状;模拟器病是使用飞行模拟器训练引起的一种运动病. 虚拟现实病[1]特指在VR环境下由视觉诱发的病症,也可称为网络病或视觉诱发运动病,属于运动病的一种. Mccauley等[2]将体验VR产生的不适称为VR病或网络病,近几年来,越来越多的学者认同了VR病这一名称[3-6].
准确地评估VR病是VR领域的一个重要研究内容. 有许多理论试图对VR病作出解释,其中感官冲突理论[7]是被广泛接受的理论. 该理论认为:当眼睛看到VR画面时,视觉系统产生运动感知,但实际上前庭系统感知到人体并没有运动,这种视觉与前庭系统的不匹配是引起VR病最重要的因素. 目前对于VR疾病的评估主要包括主观评价法和客观评价法. 主观评价法主要是通过人在VR体验后填写调查问卷,从而计算分值,评价VR的病症程度. VR病的主观评价主要采用Kennedy等[8]提出的模拟器病SSQ调查问卷. 主观评价方法的实施需要大量的人力物力资源,耗时长、成本高,容易受个人因素的影响. 大量学者以主观评估结果作为基准,研究VR病的客观评价方法.
本文提出双流网络VR病评估模型. 模型包括2个子网络,分别用于模拟人类视觉系统的腹侧流和背侧流. 分别以VR视频的彩色纹理信息及光流图运动信息作为输入,同时引入注意力机制,提升了病症评估的精度.
1. 算法简介
视觉与前庭系统感知运动不匹配是导致VR体验不适的主要原因. 人类视觉系统是复杂、神奇的系统,人眼摄取原始图像,大脑进行处理与抽象,所以VR病的形成机理复杂. Goodale等[12]的研究表明,人类的视觉系统包含2条通路:一条为负责识别物体的腹侧流,另一条为负责识别运动的背侧流. 本文创建3D-ResNet卷积神经网络,其中包含2个子网络:外观流网络和运动流网络. 这2个子网络分别模仿人类视觉系统的腹侧流、背侧流,将视频中包含的运动信息与能够识别物体的纹理信息分别作为输入,以主观评价值作为基准,利用双流卷积神经网络学习负责的人类视觉机制,实现VR病的评估. 考虑到视频连续帧的时序信息对视频理解的影响,将传统的ResNet50模型改进为3D-ResNet50模型,2个子网络均采用该模型. 网络的总体结构如图1所示. 其中外观流子网络的输入为连续RGB视频帧,用以提取视频中的物体、纹理、色彩等信息. 运动流子网络的输入为相应的连续光流图像,用以提取运动信息. 2个子网络独立地完成VR病评估任务,通过后端融合的方式,将2个子网络的预测结果进行融合.
图 1
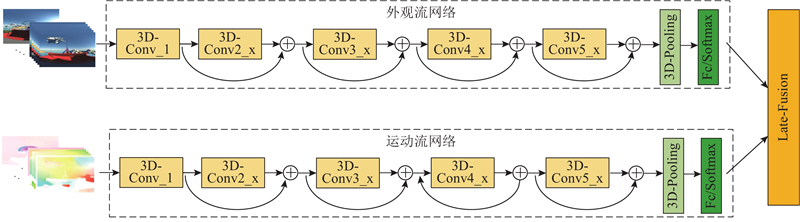
图 1 基于双流网络的3D-ResNet VR病评估模型
Fig.1 VR sickness estimation model based on 3D-ResNet two-stream network
1.1. 子网络结构
卷积神经网络(CNN)在计算机视觉和自然语言处理中表现出了优越的性能,传统的CNN模型只针对2D图像,无法提取视频特有的时间维度的信息. 使用3D CNN模型,增加一个深度通道来表示视频中的连续帧,以此提取视频中时间维度的信息.
表 1 子网络结构
Tab.1
| 网络层 | 输出大小 | 3D-ResNet50 |
| Conv1 | | |
| Conv2_x | | |
| Conv3_x | | |
| Conv4_x | | |
| Conv5_x | | |
| — | | 3D-Average Pool,Fc Layer with Softmax |
网络输入为
1.2. 基于后端融合方式的结果融合
目前,多模态数据融合主要包括前端融合、中间融合和后端融合. 后端融合(late-fusion),也称为决策级融合,可以避免不同子网络中错误的进一步累加,增强模型分类的鲁棒性. 采用后端融合的方式,将外观流网络和运动流网络的Softmax输出进行加权平均融合,平滑各子网络结果,如下所示.
式中:
1.3. 3D-CBAM注意力机制的引入
卷积神经网络能够提升视觉任务的性能. 从AlexNet到ResNet,网络越来越深,对特征提取的能力越来越强. 在提取特征的时候,这些模型都忽略了一个影响特征的因素,即注意力. Huang等[14]提出CBAM-Resnet神经网络,通过加入注意力机制,使得神经网络有选择性地接受和处理特征信息,抑制了无用信息,提高了网络性能.
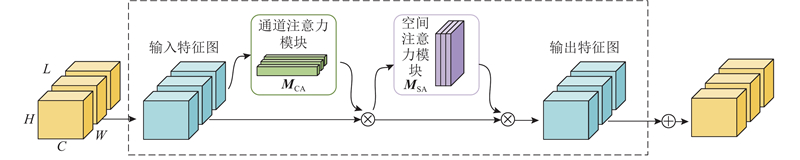
卷积注意力模块(convolutional block attention module, CBAM)[15]基于通道和空间2个维度,能够有效地提取图像的重点信息,增强网络性能. 作为轻量化模块,可以无缝地集成到ResNet架构中,用较小的参数代价,实现网络模型性能的优化. 由于卷积计算是通过混合跨通道信息和空间信息来提取特征信息,CBAM强调在通道和空间轴这2个维度中提取有意义的特征.
由于是将CBAM模块应用到3D-ResNet模型中,考虑到深度参数的变化,将输入特征图命名为
式中:
图 2
1) 通道注意力模块. 3D-CBAM基于特征通道间的相互关系解算通道注意力图,目的是为了寻找对于输入特征图有效的通道. 为了提高注意力计算的效率,3D-CBAM对特征图进行空间维度上的压缩,结合平均池化和最大池化增强特征信息,如图3所示.
图 3
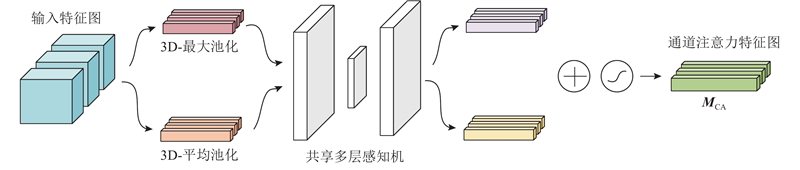
将输入特征图
式中:
2) 空间注意力模块. 该模块主要关注特征图空间上的相互关系,是针对通道注意力模块的补充,如图4所示.
图 4
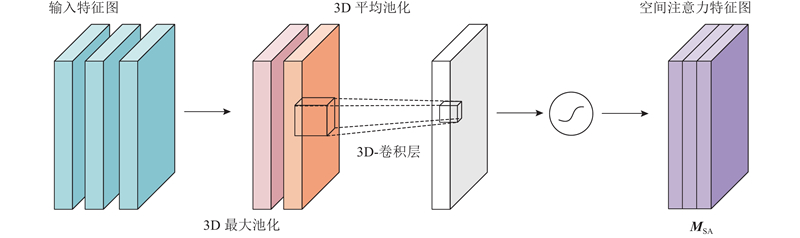
在3D-CBAM中对特征图进行通道维度上的压缩,结合平均池化和最大池化增强特征信息. 根据通道维度聚合特征,将运算结果拼接成深层次的空间特征描述子. 经过7×7×7的3D卷积层和Sigmoid激活函数生成空间注意力图,整个过程如下所示:
式中: 3DAvgPool和3DMaxPool为3D最大池化和3D平均池化,
在改进的3D-ResNet50网络中加入3D-CBAM注意力机制,如图5所示. 对于每一部分子网络,将3D-CBAM注意力机制接入第1层卷积3D-Conv1后,在网络的每个残差块后都加入注意力机制, 只增加很少的参数量和计算量,就可以使得网络更精确地学习空间表观特征和感知运动特征,有利于提升模型的精度.
图 5

2. 实验结果与分析
2.1. 数据预处理
现阶段能够用于VR体验舒适度研究的公开数据集非常有限[16]. Kim等[17]使用Unity3D建立包括36个VR场景的视频数据库,该数据库包含对象运动、相机运动、场景纹理等细节,但作者未公开该数据集. Padmanaban等[18]建立并公开包含主观评分的数据集,该数据集由19个播放时长为60 s的全景立体VR视频组成,大部分视频的分辨率为3 840×2 160像素,帧速率为30帧/s. 韩国先进科学院提供了VR视频库[10]. 该数据库被用于研究物体运动信息对视觉舒适的影响,但不是所有的视频都免费提供. Hell等[19]创建包含VR场景位置、速度及主观舒适度评分的RCVR数据库,但未公开数据集.
使用Padmanaban等[18]建立的公开数据集进行实验,该数据集主要来自于YouTube中的360°立体视频库,选取年龄为19~62岁的共96名受试者进行VR体验舒适度的主观评估实验. Padmanaban在实验中通过让受试者在观看视频后填写SSQ和MSSQ-Short问卷,计算视频的主观评分.
表 2 主观评分和舒适度等级分类
Tab.2
| 主观评分 | 舒适度等级 | 数字类别 |
| 0<Score≤10 | 舒适 | 0 |
| 10<Score≤30 | 轻度不适 | 1 |
| 31<Score≤40 | 明显不适 | 2 |
| Score>40 | 重度不适 | 3 |
考虑到原始视频数据的分辨率较大,直接应用于模型训练会产生较大的计算成本. 图像质量的优劣往往会对评估结果造成直接影响,因此在将数据送入网络前需要对视频的每帧图像进行预处理操作. 该操作能够消除视频帧中的多余信息,使得模型需要的真实信息得以呈现,增强舒适度评估的准确性. 在网络训练前对数据进行预处理操作: 采用标准化、图片缩放、多尺度中心裁剪和多尺度随机裁剪等方法,对数据进行预处理操作. 1)考虑到计算成本及实验设备参数,采用缩放的方法,使输入图片的分辨率归一化到112像素×112像素. 2)按照
2.2. 模型训练
实验环境的配置信息如表3所示. 在进行模型训练时,统一输入图像尺寸. 其中外观流网络的输入为3通道×112像素×112像素的连续视频帧,运动流网络的输入为2通道×112像素×112像素的连续视频帧.
表 3 测试平台的配置信息
Tab.3
| 配置 | 参数信息 |
| CPU | Intel(R) Xeon(R) CPU E5-2620@ 2.00 GHz |
| GPU | NVIDIA GeForce RTX 2080 SUPER 8 GB |
| 内存 | 16 GB |
| 操作系统 | Windows10 |
| 通用并行计算架构 | CUDA10.0、cuDNN7.6.1 |
| 深度学习框架 | Pytorch1.2 |
| 开发环境 | Anaconda3、Python3.6 |
整个训练模型采用随机梯度下降算法(stochastic gradient descent, SGD)进行优化,反向传播时的权重衰减为0.001,动量因子为0.9. 学习率从0.01开始,训练至第15轮时,学习率以10−1系数减小,每训练100次,开展一次模型验证调整. 考虑到计算机的内存和GPU利用率,采用的Batch-size大小为8,训练120个轮次,具体参数的设定如表4所示. 表中,L为采样帧数,α为初始学习率,w为权重衰减率,β为动量因子,Emax为最大迭代次数.
表 4 子网络训练参数的设置
Tab.4
| 参数 | 参数值 |
| L | 16 |
| 输入图像维度 | [3,112,112]、[2,112,112] |
| α | 10−2 |
| w | 10−3 |
| β | 0.9 |
| Batchsize | 8 |
| Emax | 120 |
| 优化器 | 动量SGD |
2.3. 实验对比分析
如图6所示分别为应用3D-ResNet50模型的外观流和运动流2个子网络在训练过程中的训练损失变化、模型验证变化以及添加3D-CBAM注意力机制后的模型变化. 图中,L为损失,E为迭代次数,P为精度. 从图6(a)可以看出,模型的整体训练损失在最初的迭代过程中较大,随着迭代次数的增加,在大约10次时开始出现迅速降低的情况,并持续到30次后开始缓慢降低并逐渐趋向于0,经过120次迭代后训练结束. 与之对应,精度曲线在10次迭代前迅速提高,最后趋于稳定,精度基本上收敛于90%以上,且添加3D-CBAM后网络精度的收敛速度更快,网络更加稳定. 从图6(b)可知,未添加注意力机制的运动流网络虽然训练误差不断减小,但始终处于较大的值域内,在网络中添加3D-CBAM后损失显著降低. 添加注意力机制的模型的精度和收敛速度高于未添加注意力机制的模型,这表明通过添加3D-CBAM注意力机制可以有效地提高网络性能与VR病的预测准确性.
图 6

总体来看,整个模型在训练过程中损失虽然会出现不同幅度的振荡,但会随着训练次数的增加而不断减小并趋向于0. 在精确度曲线中,随着训练次数的增加,模型验证精度逐渐增加. 可以发现,运动流网络的训练损失和精确度明显差于外观流网络. 原始的RGB图像中包含了更多的细节信息,使得网络提取的特征更准确,而稠密光流图虽然能够直观地表现视频序列中的运动信息,但对于自然场景下VR病的估计精度不高. 在基于卷积神经网络的VR病估计中不应仅考虑运动流网络,本文使用双流网络是恰当且非常必要的.
未添加注意力机制子网络的参数量为46237032,添加注意力机制后子网络的参数量为51250085. 结合表5可知,本网络没有增加太多的参数量,有效地提高了网络性能.
表 5 Padmanabar模型精度的对比
Tab.5
图 7

图7中,第1行为原始的输入图像,第2行为加入注意力机制后的网络特征可视化图像,展示了网络所认定的预测重要区域. 通过与实际人眼观看的主要区域相比,添加3D-CBAM注意力机制后模型预测的重要区域与人眼观看的目标对象区域基本一致,聚焦于图像中的物体. 这证明添加3D-CBAM模块后网络不仅感知到了图中的关键信息,而且抑制了其他冗余的无用信息,能够提取输入图像的关键特征,提高了模型预测的准确性.
对VR病评估模型的测试精度进行汇总,精度的定义如下:
式中:
结果如表5所示. 表中,
目前,本领域缺乏其他统一公开的数据集,本文与领域内近两年评估精度较高的文献进行对比,如表5所示. Garcia-Agundez等[24]测量受试者在进行VR体验时的线速度、角速度与加速度等信息,通过SSQ调查问卷得分将体验舒适度分别划分为二分类和三分类,利用SVM模型预测体验舒适度的精度分别为81.8%和58%. Shahid等[25]采用相同的四分类方式对SSQ主观评分进行分类,通过视频内容类型、摄像机运动特征进行人工神经网络(ANN)建模,对VR病进行预测,精确度最终达到90%. 利用外观流网络和运动流网络融合的方式,使得网络模型重点关注图像的显著特征,融合后的网络模型精度提高到93.7%.
3. 结 语
本文提出VR病评估模型,将传统的2D-ResNet50网络改进为3D-ResNet50,模仿人类视觉系统的2条通路,建立外观流和运动流2个子网络,同时融入了3D形式的通道注意力和空间注意力机制. 实验结果表明,利用该模型提升了评估网络的性能,提高了预测精度.
在未来的研究中,将开展立体深度信息对VR病影响的研究,计划将眼动、头部、生理信号等信息加入评估模型进行多模态训练,提升评估模型的准确性.
参考文献
Influence of video content type on users’ virtual reality sickness perception and physiological response
[J].DOI:10.1016/j.future.2018.08.049 [本文引用: 1]
Cybersickness: perception of self-motion in virtual environments
[J].DOI:10.1162/pres.1992.1.3.311 [本文引用: 1]
Virtual reality sickness and challenges behind different technology and content settings
[J].DOI:10.1007/s11036-019-01373-w [本文引用: 1]
The temporal pattern of VR sickness during 7.5-h virtual immersion
[J].DOI:10.1007/s10055-021-00592-5
A novel method for VR sickness reduction based on dynamic field of view processing
[J].DOI:10.1007/s10055-020-00457-3 [本文引用: 1]
Simulator sickness questionnaire: an enhanced method for quantifying simulator sickness
[J].DOI:10.1207/s15327108ijap0303_3 [本文引用: 1]
Vrsa net: VR sickness assessment considering exceptional motion for 360 VR video
[J].
Motion sickness prediction in stereoscopic videos using 3D convolutional neural networks
[J].DOI:10.1109/TVCG.2019.2899186 [本文引用: 1]
Separate visual pathways for perception and action
[J].DOI:10.1016/0166-2236(92)90344-8 [本文引用: 1]
基于运动感知的VR体验舒适度研究
[J].DOI:10.16182/j.issn1004731x.joss.21-0966 [本文引用: 1]
Research on VR experience comfort based on motion perception
[J].DOI:10.16182/j.issn1004731x.joss.21-0966 [本文引用: 1]
Towards a machine-learning approach for sickness prediction in 360 stereoscopic videos
[J].DOI:10.1109/TVCG.2018.2793560 [本文引用: 2]
Machine learning assessment of visually induced motion sickness levels based on multiple biosignals
[J].DOI:10.1016/j.bspc.2018.12.007 [本文引用: 1]
Grad-CAM: visual explanations from deep networks via gradient-based localization
[J].DOI:10.1007/s11263-019-01228-7 [本文引用: 1]
Development of a classifier to determine factors causing cybersickness in virtual reality environments
[J].DOI:10.1089/g4h.2019.0045 [本文引用: 3]
Evaluating the factors affecting QoE of 360-degree videos and cybersickness levels predictions in virtual reality
[J].DOI:10.3390/electronics9091530 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}