

点击率预测(click-through rate, CTR)任务是预测用户点击广告的概率,在工业应用中十分重要,比如推荐系统或在线广告. 模型的性能和预测结果与广告商利润有着最直接的关联,对后续下游任务比如推荐排序算法、重排算法和广告替换等决策有着重要的参考意义.
当前CTR模型中存在以下3个问题. 1)Embedding占用资源及计算耗费较高,Embedding可以将原始高度稀疏的输入数据映射到低维密集空间中,大型数据集中每个特征的非重复值数量为千万级别,Embedding维度设置过高会导致占用很大的内存或显存资源,导致计算耗费昂贵. 2)并行架构Embedding输入部分参数过度共享,导致输入到并行架构中的特征信息无任何可分辨性. 对于不同的特征建模方式,关注的特征信息不同,因此不是所有特征对该建模方式有意义[1]. 并行架构的Embedding输入部分应该有所区分,要训练出更匹配建模方式的特征输入. 3)并行架构子网络部分参数共享不足. 显式建模和隐式建模部分独立计算,这2个部分只有在最后计算结束的时候才会进行信息融合. Hu等[2]的研究表明,并行架构计算部分因缺乏共享参数而无法捕捉不同特征语义的相关性,在反向传播期间容易出现梯度较陡的情况.
本研究提出轻量级且高性能的多专家并行推荐算法框架(mixture of experts for parallel recommendation algorithm framework, ME-PRAF),其核心组件为Fusion模块和Broker模块. Fusion模块用于在显式建模层和隐式建模层之间建立连接,融合显式特征和隐式特征的关联信息,解决参数共享不足的问题. Broker模块用于学习表现力更强的低维度Embedding输入,分别为显式建模层和隐式建模层训练具有分辨性和个性化的特征信息,解决参数过度共享的问题. 由于Fusion模块与Broker模块的轻量级和高性能特性,在3个公共数据集上的大量实验结果表明,利用该算法框架,能够有效地提高SOTA并行架构算法模型的性能.
1. 相关工作
1.1. 并行架构与串行架构
在研究早期,学者们通常手工刻画所有特征,导致模型过拟合很难泛化[3]. 使用线性模型、支持向量机及因子分解机[4]等方法训练CTR模型,但是都只能建模低阶特征信息. 大规模数据集都隐含用户和用户、用户和物品以及物品与物品之间的高阶特征关联[5],因此有必要对数据集中的高阶特征关联建模[6]. 近年来,学者提出众多深度神经网络来建模高阶特征关联,以端到端的方式捕捉特征信息,无须繁琐地手动刻画特征. 大部分模型使用多层感知机(multilayer perception, MLP)建模隐式高阶特征关联. Beutel等[7]的研究表明,MLP在建模2阶或3阶特征时的交叉效果较差,且隐式建模的方式导致模型的可解释性较差,因此大部分CTR算法将显式建模和隐式建模2个模块搭配使用. 根据2个模块不同的组织方式,可以分为串行架构和并行架构. 如图1所示,串行架构是显式建模网络后连接隐式建模网络,PIN[8]、DIN[9]和DIEN[10]等算法属于这种架构;并行架构中,两者独立进行计算,最终将两者输出融合,比如算法模型DCN[11]、AutoInt+[12]和DCN-v2[6]等. 在实际的工业生产环境中,通常使用多GPU进行训练,并行架构能够充分利用多GPU资源,相比于串行架构可以节约训练时间,因此本文主要关注对并行架构的优化.
图 1

1.2. 特征关联
1.3. 并行架构的优化
学者们对并行架构提出很多优化方案. 在多模态训练任务中,针对模型只对浅层和输出层进行特征融合的问题,DMF[2]算法使用并行架构中的每一层都进行特征融合,用于捕捉不同模态任务之间的关联程度,充分挖掘不同任务之间的特征关联信息. 对于并行架构中只能手工选取输入特征的问题,AutoFeature[1]使用自动寻找重要特征关联的方法,为模型输入选取具有侧重点的特征信息,忽略次要冗余的特征信息. GateNet[14]使用Embedding Gate选取重要潜在特征信息,通过使用Hidden Gate,可以使MLP自适应选取隐式特征传给下一层,但对并行架构输入是无差别的. EDCN[15]使用bridge和regulation模块解决参数共享的问题,regulation模块使用门控网络为并行架构学习不同特征的输入,但是只提供一种解决方案,无法捕捉单一特征在不同情况下的多语义信息,因此实验效果不理想. 在多任务模型中,多门多专家系统(multi-gate mixture of experts, MMoE)[16]通过学习不同任务之间的联系和差异来提高模型质量,使用门控网络学习多个任务之间的关联,最大化各种策略对模型的提升价值. 本文使用MMoE对CTR任务进行更细粒度的划分,提出ME-PRAF框架来学习不同建模任务之间的关联,训练性能更高的推荐算法模型,ME-PRAF整体网络架构如图2所示.
图 2
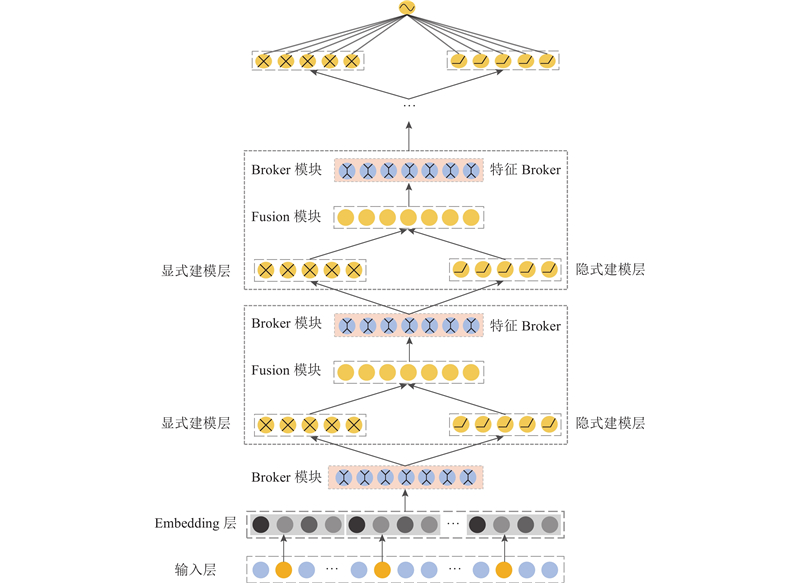
图 2 多专家并行推荐算法框架的整体示意图
Fig.2 Illustration overall architecture diagram of ME-PRAF
2. ME-PRAF框架
2.1. 输入层和Embedding层
输入层将用户属性和物品属性聚合,把所有特征拼接后组成高维稀疏向量:
式中:
由于类别型特征非常稀疏而且维度较高,常见的处理方式是使用Embedding,将高维稀疏的特征映射到低维密集的空间中. 对于输入数据中的每个类别型特征,使用低维向量进行表示:
对于数值型特征,直接取原数值,将所有的特征拼接起来得到:
式中:
对于基于注意力机制的模型,由于需要训练不同特征之间的注意力权重矩阵,须对数值型特征进行进一步的处理,将其从标量转为与类别型特征相同维度的向量:
式中:
2.2. Fusion模块
在当前现存的推荐算法并行架构中,主流深度CTR模型使用2个子网络,分别对显式特征关联和隐式特征关联进行建模. 2个网络之间独立进行训练,只在2个子网络输出层进行特征融合. 这种特征融合策略只能捕捉语义级别的关联,无法捕捉中间层显式特征和隐式特征之间的关联. 在2个独立子网络反向传播期间,会存在梯度较高、导致模型过拟合的问题,这是导致模型性能变差的原因之一. 在人体大脑结构中,生物认知科学家发现多器官感知不仅存在于大脑颞叶,而且存在于额叶和顶叶中[17]. 这意味着信息融合应该在信息处理中间阶段开展,用于捕捉不同特征类型之间更复杂的关联.
为了解决上述问题,使用密集融合(dense fusion)的策略构建Fusion模块. 对2个独立子网络中的每一层输出进行信息融合,充分捕捉显式特征和隐式特征之间的关联,缓和反向传播期间的梯度.
在ME-PRAF中,令
1)拼接. 使用最简单的融合方式,将显式建模层和隐式建模层每一层的输出直接进行拼接:
2)按位加. 将2个相同维度的向量进行加法计算:
3)Hardmard积. 将2个相同维度的向量对应元素进行乘法计算:
Fusion模块用于融合同一层显式特征和隐式特征之间的层级关联,当多个Fusion模块叠加时能够融合不同层之间更复杂的关联信息,极大改善了并行架构中参数共享不足的问题. 3种融合方式的对比在3.6节的实验中给出.
2.3. Broker模块
在现存的并行架构CTR模型中,使用完全一致的Embedding作为输入进行计算,然而不同建模方式对特征信息的关注点不同,应该采取因地制宜的策略. DCN-v2中交叉网络是通过显式建模的方式来高效捕捉有限阶特征关联,MLP网络是用来建模高阶隐式特征. 2种方式对特征建模的角度不同,为不同的子网络学习具有可分辨性的特征输入.
受到MMoE中多任务学习的启发,将CTR任务进行更细粒度、更精细化的划分,提出使用Broker模块对模型中的子网络训练专有的特征输入. 如图3所示为Broker模块的内部结构. 根据使用场景的不同,Broker模块分为Embedding Broker和Feature Broker. 前者用于解决模型输入参数过度共享的问题,为并行架构中不同子网络学习更具有分辨性的、个性化的特征输入. 后者用于配合Fusion模块,对融合后的数据进行训练并且拆分为2个数据流,为子网络下一层提供个性化的输入,捕捉显式特征和隐式特征之间的关联,多层叠加还可以学习高阶和低阶特征之间的关联.
图 3
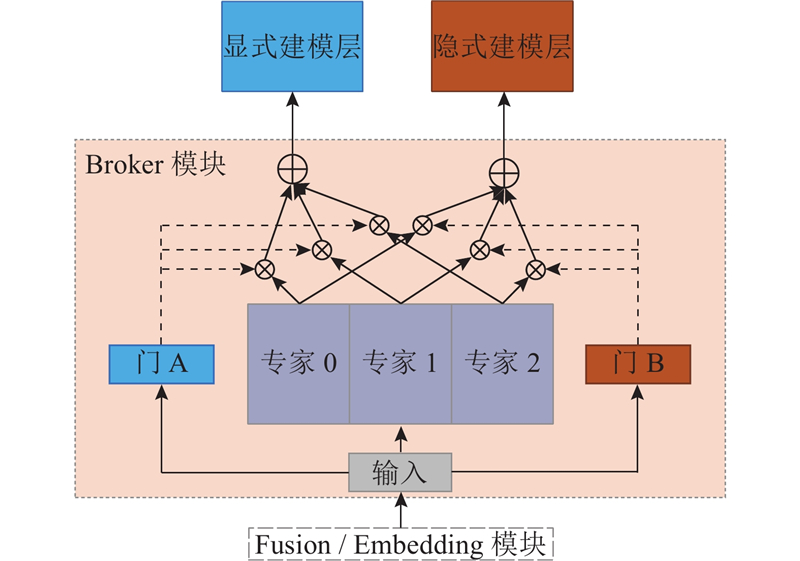
设置2个独立的门控网络,分别对应2个细粒度的任务:建模显式特征关联和建模隐式特征关联. 对于任务k,输出为
式中:
式中:
式中:
对于现实生活中人或者物品的属性来说,都可能由多个标签组成. 比如Movielens-1M中电影《Toy Story》,所属类别是动画片、儿童片及喜剧,人或物品的类别型属性可能有一个或多个标签. EDCN中的Regulation Module可以看作单个Experts,因此只能捕捉特征中的单个语义,忽略了其他大量关键的语义信息,这是EDCN效果更差的原因. Broker模块中有多个专家,因此可以将特征的不同语义映射到多个子空间中,每个专家对应一个子空间,从而达到增强Embedding中特征表现力的效果. 每个门可以选取所有专家的一个子集,根据各种建模方式为每个专家学习不同侧重点的权重. 当显式特征和隐式特征之间的关联较多时,Broker模块会为某个专家分配较高的权重;当关联较少时,Broker模块会惩罚对应的专家,尽量使用多个专家. 对于并行架构中存在的参数共享不足问题来说,这是非常灵活的解决方案. Broker模块参数数量是常数级别,在整个模型中是可以忽略不计的,因此在并行架构添加Broker模块后,可以在不增加计算复杂度的情况下,显著提高模型性能,这是Broker模块的好处之一.
2.4. 输出层
输出层将2个网络的输出拼接起来,最终输出点击率预测结果:
式中:在ME-PRAF中
损失函数使用LogLoss进行评估:
式中:
2.5. CowClip训练加速
通常情况下,在训练过程中,增大训练batch虽然会缩短训练时间,但是会带来模型性能的下降. 使用CowClip[18]模型来提高模型的训练速度,由于推荐系统的大部分数据集中存在特征频次数量级相差较大的问题,若增大训练batch但是不相应调整其他超参数,比如学习速率和正则化系数,则会导致模型训练造成偏差. 利用CowClip算法,可以在不损耗模型性能的基础上增大训练的批次大小,从而达到大幅度缩减训练时间的目的.
3. 实验与分析
由于该算法框架是与模型无关的框架,对比在各SOTA模型上使用ME-PRAF框架的效果.
3.1. 数据集
使用以下3个数据集进行实验:Criteo数据集、Avazu数据集、MovieLens-1M数据集. 具体数据如表1所示. 表中,
表 1 3个实验数据集的参数
Tab.1
| 数据集 | M/106 | F | C/106 |
| Criteo | 45 | 39 | 33 |
| Avazu | 40 | 23 | 9.4 |
| Movielens-1M | 0.74 | 7 | 0.013 |
Criteo数据集是当前最流行的CTR基准数据集,该数据集包含用户7天内点击广告的数据日志信息. 遵循先前SOTA工作中的处理操作,将前6天的用户数据作为训练集,将最后一天的用户数据平分作为验证集和测试集. 对于数值型数据,将所有数据放缩到[0, 1.0].
Avazu数据集是流行的CTR基准数据集,数据中包含了用户11 d内在移动端点击广告的信息,将80%的数据作为训练集,10%的数据作为验证集,最终剩余10%的数据作为测试集.
MovieLens-1M是十分知名流行的数据集,其中包含3个文件:评分数据、用户数据和电影数据. 将3个文件聚合成1个文件,其中每行数据对应的组织形式为:
3.2. 实现细节
将ME-PRAF框架应用到DCN-v2算法上,在3个数据集上的性能可以达到最优,以这个具有代表性的并行架构CTR模型作为演示,本文称为ME-DCN(mixture of experts for DCN-v2)算法. 若将ME-DCN中的Broker模块和Fusion模块删除,则会退化为DCN-v2算法.
3.3. 模型性能比较
表 2 ME-DCN与其他SOTA模型在3个数据集上的性能比较
Tab.2
| 模型 | Criteo | Avazu | MovieLens-1M | |||||
| AUC | LogLoss | AUC | LogLoss | AUC | LogLoss | |||
| DeepFM | 0.8007 | 0.4508 | 0.7852 | 0.3780 | 0.8932 | 0.3202 | ||
| DCN | 0.8099 | 0.4419 | 0.7905 | 0.3744 | 0.8935 | 0.3197 | ||
| xDeepFM | 0.8052 | 0.4418 | 0.7894 | 0.3794 | 0.8923 | 0.3251 | ||
| AutoInt+ | 0.8083 | 0.4434 | 0.7774 | 0.3811 | 0.8488 | 0.3753 | ||
| DCN-v2 | 0.8115 | 0.4406 | 0.7907 | 0.3742 | 0.8964 | 0.3160 | ||
| EDCN | 0.8001 | 0.5415 | 0.7793 | 0.3803 | 0.8722 | 0.3469 | ||
| CowClip | 0.8097 | 0.4420 | 0.7906 | 0.3740 | 0.8961 | 0.3174 | ||
| 本文方法 | 0.8122 | 0.4398 | 0.7928 | 0.3732 | 0.8970 | 0.3163 | ||
如表3所示为ME-DCN与主流SOTA并行架构模型参数量
表 3 ME-DCN与其他模型参数量的对比(Criteo)
Tab.3
| 模型 | |
| DeepFM | 1.4 |
| DCN | 3.1 |
| xDeepFM | 4.2 |
| AutoInt+ | 3.7 |
| DCN-v2 | 7.2 |
| EDCN | 11 |
| 本文方法 | 5.7 |
分析ME-DCN 的算法时间度可知,与DCN-v2模型相比,增加时间复杂度的部分是Broker模块,专家部分和门控网络使用的是线性模型,因此时间复杂度为
3.4. ME-PRAF框架的鲁棒性
为了证明ME-PRAF框架的鲁棒性,在其他CTR并行算法的基础上,融合ME-PRAF框架进行实验检验. 由于DeepFM显式建模部分只能有一层不能进行叠加,xDeepFM在压缩感知层计算耗费十分昂贵,因此工业界很少使用. EDCN模型中由于regulation模块的存在无法添加Broker模块,使用以下3种流行的CTR模型进行对比:DCN、AutoInt+、DCN-v2. 3个数据集上的实验结果如表4所示.
表 4 SOTA并行架构模型使用ME-PRAF后在3个数据集上的性能比较
Tab.4
| 模型 | Criteo | Avazu | MovieLens-1M | |||||
| AUC | LogLoss | AUC | LogLoss | AUC | LogLoss | |||
| DCN | 0.8099 | 0.4419 | 0.7905 | 0.3744 | 0.8935 | 0.3197 | ||
| DCNME | 0.8116 | 0.4403 | 0.7919 | 0.3731 | 0.8962 | 0.3174 | ||
| AutoInt+ | 0.8083 | 0.4434 | 0.7774 | 0.3811 | 0.8488 | 0.3753 | ||
| AutoInt+ME | 0.8104 | 0.4414 | 0.7899 | 0.3737 | 0.8928 | 0.3250 | ||
| DCN-v2 | 0.8115 | 0.4406 | 0.7907 | 0.3742 | 0.8964 | 0.3160 | ||
| DCN-v2ME | 0.8122 | 0.4398 | 0.7928 | 0.3732 | 0.8970 | 0.3163 | ||
由于Embedding在模型中的参数量占据模型参数的很大一部分,利用本文算法可以大幅度减少模型的参数量,节约计算机内存及显存资源,在参与到模型计算时可以更快速地进行运算.
3.5. 消融实验
为了进一步了解ME-PRAF算法框架中Broker模块的效果,对Broker模块进行消融实验. 由上文可知,Broker模块分为Embedding Broker及Feature Broker. 前者用于解决模型参数过度共享的问题,为并行架构训练学习具有可分辨性和个性化的输入;后者用于解决模型参数共享不足的问题,学习显式特征与隐式特征之间的关联. 对Broker模块进行消融实验的具体数据如表5所示.
表 5 ME-DCN模型上的Broker模块消融实验(Criteo)
Tab.5
| 模型 | AUC | LogLoss |
| ME-DCN -w/o FB | 0.811 7 | 0.440 3 |
| ME-DCN -w/o EB | 0.811 3 | 0.440 7 |
| ME-DCN | 0.812 2 | 0.439 8 |
表5中,w/o FB表示将ME-DCN模型删除Feature Broker及Fusion模块后的实验结果,w/o EB表示将ME-DCN模型删除Embedding Broker后的实验结果. 结果表明,删除其中一个都会导致模型性能下降,因此Embedding Broker和Feature Broker在算法模型中都十分重要而且缺一不可. 2种Broker起到相辅相成的作用,为并行模型中存在的参数共享问题提供了解决方案,提高了模型性能.
3.6. Fusion模块融合方式的对比
Fusion模块的3种融合方式为拼接、按位加及Hardmard积. 这3种方式都不需要额外的参数,因此计算效率都很高. 为了探索不同Fusion方式对模型的影响,分别在3种方式下进行实验,实验结果如表6所示.
表 6 ME-DCN模型上Fusion模块不同融合方式的性能对比(Criteo)
Tab.6
| 模型 | AUC | LogLoss |
| ME-DCN -w/ concat | 0.812 2 | 0.439 8 |
| ME-DCN -w/ add | 0.810 5 | 0.441 8 |
| ME-DCN -w/ Hardmard | 0.810 7 | 0.441 6 |
由表6可知,拼接方式的效果比其他方式更好. 按位加方式的效果最差,由于相差较大的2对特征进行按位加融合后,最终向量会有较大概率出现结果相似的情况,选择拼接的融合方式更佳. 按照先前学者的研究经验,使用Hardmard积应取得较好的实验结果,但是此处的实验效果不理想,因此未来会进一步优化Hardmard积的融合方式.
3.7. 模型参数调整
对于ME-PRAF算法框架来说,模型需要调参的地方如下.
1)在Fusion模块中需要调整对比的是特征的融合方式,这在3.6节中已进行讨论.
2)Broker模块中参数的调整是对专家数量的调整. 为了研究专家数量对模型性能的影响,对Broker模块中专家数量分别为2、3、4、5的情况进行对比实验. 当专家数量小于4时,模型的性能会随着专家数量的增加而提高;当专家数量大于4时,性能开始变差;当专家数量为4时,模型性能最好. 可知,大部分数据集中特征不同语义平均数量为4 ,当专家数量大于4时会捕捉无用冗余的语义特征,导致模型性能下降.
3.8. 模型分析
分析模型的关键在于模型是否能够学习到有意义的特征关联,在本框架中表现为以下2个方面.
1)Embedding Broker是否能为不同类型的子网络学习到具有可分辨性和个性化的特征输入.
2)Feature Broker是否能够学习到显式特征和隐式特征之间的关联信息.
现在大部分公司考虑用户隐私问题,将大部分数据集中的特征部分进行过脱敏处理,特征是加密后的数据. 采用Avazu数据集,分析Broker模块对特征的处理.
如图4(a)所示为Embedding Broker对输入特征的权重
图 4
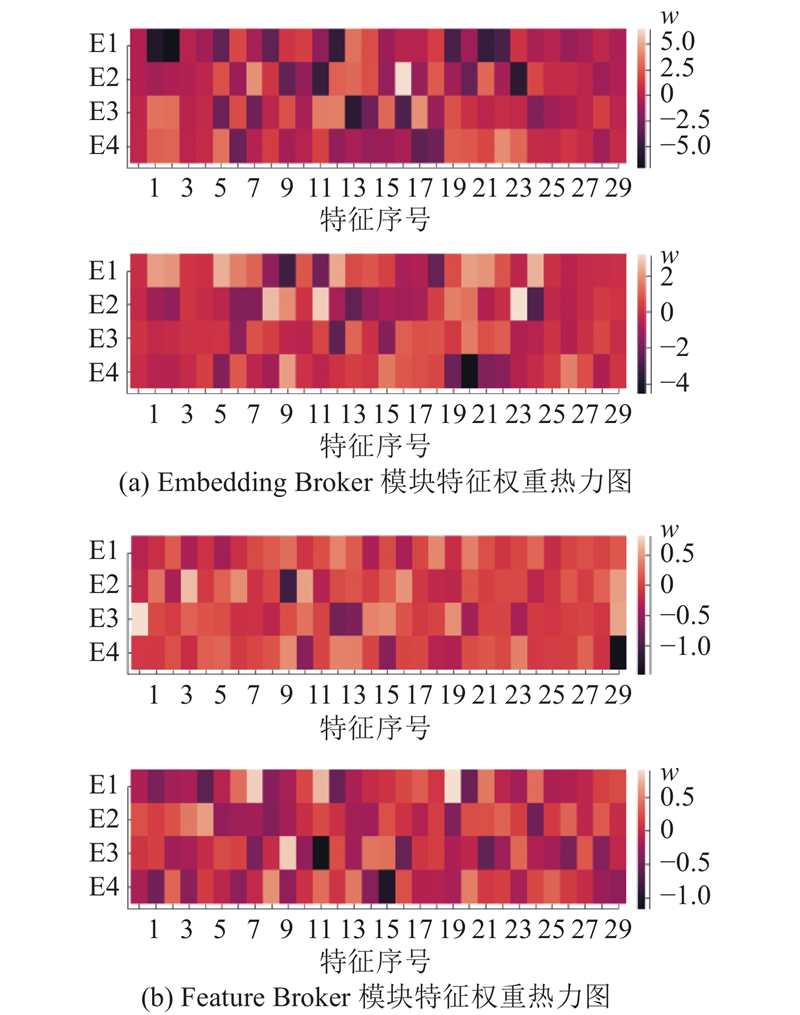
图 4 Broker模块特征权重的差异度分析
Fig.4 Analysis of diversity factor of feature weight of Broker module
如图4(a)所示,不同门控网络中热力图权重分布有着明显不同,在融合显式特征和隐式特征后,能够为下一层学习到具有可分辨性及个性化的特征信息,证明Broker模块的有效性.
将Fusion模块和Broker模型两者配合,对不同子网络中的特征进行融合. 将融合后的信息分裂成最适合2个子网络的输入,显式特征与隐式特征之间的信息得到有效交互,提升了模型性能.
4. 结 语
ME-PRAF是轻量级且高性能的并行算法框架,用于解决目前主流并行CTR推荐模型中普遍存在的参数共享问题. 对于并行架构中输入部分参数过度共享及子网络部分参数共享不足的问题,可以泛化到众多并行CTR算法上,有效提高模型的性能. 在数据集上的大量实验表明,ME-PRAF框架能够有效地提高SOTA并行CTR算法模型的性能. 下一步将研究解决推荐系统中常见的冷启动问题以及如何在串行架构中融合显式特征和隐式特征.
参考文献
Product-based neural networks for user response prediction over multi-field categorical data
[J].
GateNet: gating-enhanced deep network for click-through rate prediction
[J].
Multisensory integration: space, time and superadditivity
[J].DOI:10.1016/j.cub.2005.08.058 [本文引用: 1]
CowClip: reducing CTR prediction model training time from 12 hours to 10 minutes on 1 GPU
[J].
Adam: a method for stochastic optimization
[J].
Tensorflow: large-scale machine learning on heterogeneous distributed systems
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}