[1]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Santiago: IEEE, 2015: 3431-3440.
[本文引用: 1]
[2]
BADRINARAYANAN V, KENDALL A, CIPOLLA R Segnet: a deep convolutional encoder-decoder architecture for image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (12 ): 2481 - 2495
DOI:10.1109/TPAMI.2016.2644615
[本文引用: 4]
[3]
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241.
[本文引用: 4]
[4]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. [2014-12-22]. https://arxiv.org/abs/1412.7062.
[本文引用: 4]
[5]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 40 (4 ): 834 - 848
[6]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. [2017-06-17]. https://arxiv.org/abs/1706.05587.
[本文引用: 1]
[7]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881-2890.
[本文引用: 4]
[8]
周登文, 田金月, 马路遥, 等 基于多级特征并联的轻量级图像语义分割
[J]. 浙江大学学报: 工学版 , 2020 , 54 (8 ): 1516 - 1524
[本文引用: 1]
ZHOU Deng-wen, TIAN Jin-yue, MA Lu-yao, et al Lightweight image semantic segmentation based on multi-level feature cascaded network
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (8 ): 1516 - 1524
[本文引用: 1]
[9]
LIU F, FANG M Semantic segmentation of underwater images based on improved Deeplab
[J]. Journal of Marine Science and Engineering , 2020 , 8 (3 ): 188
DOI:10.3390/jmse8030188
[本文引用: 1]
[10]
ZHOU J, WEI X, SHI J, et al Underwater image enhancement via two-level wavelet decomposition maximum brightness color restoration and edge refinement histogram stretching
[J]. Optics Express , 2022 , 30 (10 ): 17290 - 17306
DOI:10.1364/OE.450858
[本文引用: 1]
[11]
ZHOU J, WANG Y, ZHANG W, et al Underwater image restoration via feature priors to estimate background light and optimized transmission map
[J]. Optics Express , 2021 , 29 (18 ): 28228 - 28245
DOI:10.1364/OE.432900
[12]
ZHOU J, YANG T, REN W, et al Underwater image restoration via depth map and illumination estimation based on a single image
[J]. Optics Express , 2021 , 29 (19 ): 29864 - 29886
DOI:10.1364/OE.427839
[本文引用: 1]
[13]
ISLAM M J, EDGE C, XIAO Y, et al. Semantic segmentation of underwater imagery: dataset and benchmark [C]// 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems . Las Vegas: IEEE, 2020: 1769-1776.
[本文引用: 5]
[14]
PASZKE A, CHAURASIA A, KIM S, et al. Enet: a deep neural network architecture for real-time semantic segmentation [EB/OL]. [2016-06-07]. https://arxiv.org/abs/1606.02147.
[本文引用: 5]
[15]
YUAN Y, HUANG L, GUO J, et al OCNet: object context for semantic segmentation
[J]. International Journal of Computer Vision , 2021 , 129 (8 ): 2375 - 2398
DOI:10.1007/s11263-021-01465-9
[本文引用: 4]
[16]
ROMERA E, ALVAREZ J M, BERGASA L M, et al ERFNet: efficient residual factorized convnet for real-time semantic segmentation
[J]. IEEE Transactions on Intelligent Transportation Systems , 2017 , 19 (1 ): 263 - 272
[本文引用: 5]
[17]
WU T, TANG S, ZHANG R, et al CGNet: a light-weight context guided network for semantic segmentation
[J]. IEEE Transactions on Image Processing , 2020 , 30 : 1169 - 1179
[本文引用: 4]
[18]
LI H, XIONG P, FAN H, et al. DFANet: deep feature aggregation for real-time semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 9522-9531.
[本文引用: 1]
[19]
WANG Y, ZHOU Q, LIU J, et al. LEDNet: a lightweight encoder-decoder network for real-time semantic segmentation [C]// 2019 IEEE International Conference on Image Processing . Taipei: IEEE, 2019: 1860-1864.
[本文引用: 4]
[20]
YU C, WANG J, PENG C, et al. Bisenet: bilateral segmentation network for real-time semantic segmentation [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 325-341.
[本文引用: 1]
[21]
YU C, GAO C, WANG J, et al Bisenet v2: bilateral network with guided aggregation for real-time semantic segmentation
[J]. International Journal of Computer Vision , 2021 , 129 (11 ): 3051 - 3068
DOI:10.1007/s11263-021-01515-2
[本文引用: 5]
[22]
REUS G, MÖLLER T, JÄGER J, et al. Looking for seagrass: deep learning for visual coverage estimation [C]// 2018 OCEANS-MTS/IEEE Kobe Techno-Oceans . Kobe: IEEE, 2018: 1-6.
[本文引用: 2]
[23]
SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: inverted residuals and linear bottlenecks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4510-4520.
[本文引用: 1]
[24]
PENG C, ZHANG X, YU G, et al. Large kernel matters-improve semantic segmentation by global convolutional network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 4353-4361.
[本文引用: 4]
[25]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
1
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
Segnet: a deep convolutional encoder-decoder architecture for image segmentation
4
2017
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
4
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
4
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
0
2017
1
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
4
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
基于多级特征并联的轻量级图像语义分割
1
2020
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
基于多级特征并联的轻量级图像语义分割
1
2020
... 语义分割是当今计算机视觉领域的核心问题之一,在自动驾驶、医学影像分析、地理信息系统等领域有着广泛的应用. 在过去几年里,基于深度学习的卷积神经网络的发展使得陆地场景下的语义分割方法进步显著. Long等[1 ] 提出全卷积网络(FCN),开启了卷积神经网络应用在语义分割领域的先河. 基于FCN,SegNet[2 ] 在降低计算成本的同时,得到了略好于FCN的分割精度. U-Net[3 ] 通过跨连接将各个层次的信息保留,取得了很好的分割效果. Deeplab[4 -6 ] 系列网络使用的空洞卷积层和PSPNet[7 ] 提出的金字塔池化模块可以有效地提升网络的性能. 周登文等[8 ] 提出基于多级特征并联网络的语义分割网络,能够较好地平衡网络的准确度与速度. ...
Semantic segmentation of underwater images based on improved Deeplab
1
2020
... 近年来,随着水下机器视觉任务需求的增加,水下图像语义分割成为值得研究的问题. Liu等[9 ] 提出水下图像语义分割网络,设计无监督色彩校正模块,以提高输入图像的质量. Zhou等[10 -12 ] 提出多种水下图像增强的方法,全面解决了各种退化问题. ...
Underwater image enhancement via two-level wavelet decomposition maximum brightness color restoration and edge refinement histogram stretching
1
2022
... 近年来,随着水下机器视觉任务需求的增加,水下图像语义分割成为值得研究的问题. Liu等[9 ] 提出水下图像语义分割网络,设计无监督色彩校正模块,以提高输入图像的质量. Zhou等[10 -12 ] 提出多种水下图像增强的方法,全面解决了各种退化问题. ...
Underwater image restoration via feature priors to estimate background light and optimized transmission map
0
2021
Underwater image restoration via depth map and illumination estimation based on a single image
1
2021
... 近年来,随着水下机器视觉任务需求的增加,水下图像语义分割成为值得研究的问题. Liu等[9 ] 提出水下图像语义分割网络,设计无监督色彩校正模块,以提高输入图像的质量. Zhou等[10 -12 ] 提出多种水下图像增强的方法,全面解决了各种退化问题. ...
5
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... 采用Islam等[13 ] 提出的用于水下图像语义分割的数据集SUIM和Reus等[22 ] 提出的海草数据集. SUIM包含1 525幅自然水下图像及其真实语义标签、110幅图片的测试集,这些图像是在海洋探索和人-机器人合作实验期间收集的. 该数据集对8个对象类别进行了像素级注释: 鱼类和其他脊椎动物、珊瑚礁和其他无脊椎动物、水生植物/植物群、沉船/废墟、人类潜水员、机器人和仪器、海底和岩石、水体背景. 海草数据集包含12682幅图片,该数据集包含海草和水体背景2个类别. 其中6037幅是人工标注过的,这些图片采集于0~6 m深的海底,实验中随机挑选其中的80%作为训练集,剩余20%作为测试集. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
5
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... [14 ,16 -17 ,19 ,21 ]. 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
OCNet: object context for semantic segmentation
4
2021
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
ERFNet: efficient residual factorized convnet for real-time semantic segmentation
5
2017
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... ,16 -17 ,19 ,21 ]. 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
CGNet: a light-weight context guided network for semantic segmentation
4
2020
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... -17 ,19 ,21 ]. 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
1
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
4
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... ,19 ,21 ]. 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
1
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
Bisenet v2: bilateral network with guided aggregation for real-time semantic segmentation
5
2021
... Islam等[13 ] 提出首个用于水下图像语义分割的大规模数据集SUIM. 笔者将FCN、SegNet、U-Net等经典分割网络应用在SUIM数据集上,取得了不错的分割结果. 这些语义分割模型都很少考虑分割速度和计算成本,因此实时语义分割算法越来越受到关注. ENet[14 ] 降低了模型的复杂度,但导致感受野不足. Ocnet[15 ] 结合交叉稀疏自注意力方法与空洞金字塔池化方法,提高了网络的精度. ERFNet[16 ] 提出基于残差连接和深度可分离卷积的语义分割网络,减少了模型的运算量. CGNet[17 ] 设计模块同时学习局部特征和全局特征,模型参数量小于0.5M,但精度较差. DFANet[18 ] 提出的深度特征聚合网络旨在利用网络级和阶段级相结合的特征. LEDNet[19 ] 设计轻量级的上采样模块APN,显著加快了处理速度. Bisenet[20 ] 和BiseNetv2[21 ] 采用2个分支,语义分支得到的深层信息对空间分支得到的浅层信息进行指导,提升了网络的性能. 尽管这些语义分割模型在陆地场景都取得了不错的分割效果,但在水下场景的表现较差[14 ,16 -17 ,19 ,21 ] . 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... ,21 ]. 由于水下图像存在对比度较低、噪声较大的问题,大部分水下图像都存在不同程度的模糊,使得这些语义分割模型得到的分割结果边缘粗糙,语义边界不明显. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
2
... 为了解决上述问题,本文提出面向水下场景的轻量级语义分割网络. 在水下语义分割数据集SUIM和Reus等[22 ] 提出的海草数据集上训练并评估提出的网络. 这2个数据集的测试结果表明,该网络能够在保持高准确度的同时,达到实时的处理速度. ...
... 采用Islam等[13 ] 提出的用于水下图像语义分割的数据集SUIM和Reus等[22 ] 提出的海草数据集. SUIM包含1 525幅自然水下图像及其真实语义标签、110幅图片的测试集,这些图像是在海洋探索和人-机器人合作实验期间收集的. 该数据集对8个对象类别进行了像素级注释: 鱼类和其他脊椎动物、珊瑚礁和其他无脊椎动物、水生植物/植物群、沉船/废墟、人类潜水员、机器人和仪器、海底和岩石、水体背景. 海草数据集包含12682幅图片,该数据集包含海草和水体背景2个类别. 其中6037幅是人工标注过的,这些图片采集于0~6 m深的海底,实验中随机挑选其中的80%作为训练集,剩余20%作为测试集. ...
1
... 编码器中的倒置瓶颈层和金字塔池化模块是进行轻量化设计需要重点考虑的模块. MobileNetv2[23 ] 利用升降维操作和深度可分离卷积,有效减少了模型的参数量. 借鉴MobileNetv2倒置残差的思想,设计倒置瓶颈层,将空洞卷积添加到Mobilenetv2的倒置残差模块(inverted residual block)中. 在PSPNet的金字塔池化模块的基础上改进了升降维操作的位置,减小了参数量. 设计的倒置瓶颈层和金字塔池化模块如图2 所示. ...
4
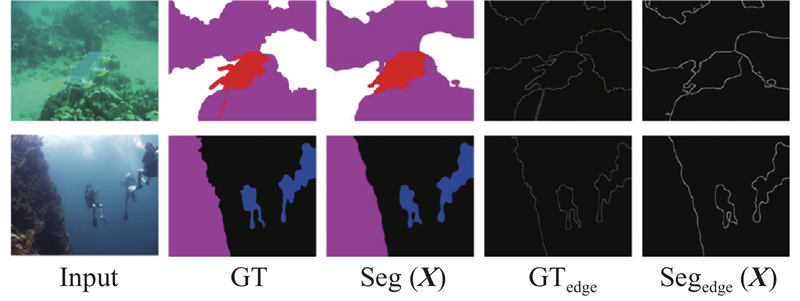
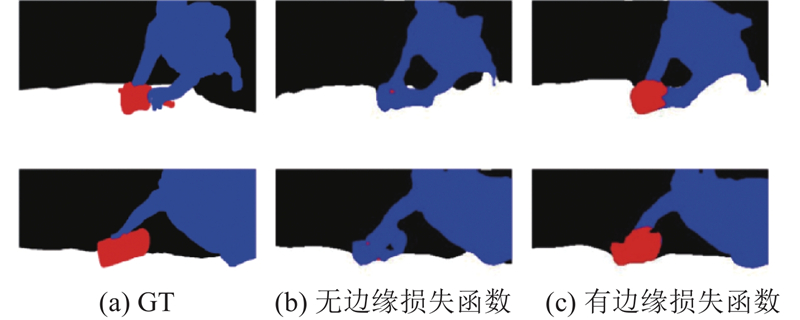
... 从图5 可得如下结论. 1)所提网络与经典的常规语义分割网络U-Net、SegNet、Deeplab、GCN[24 ] 相比,得到的语义分割结果的视觉效果明显优于这4种网络. 例如第1列,U-Net和SegNet得到的语义分割结果明显出现了大面积分类错误的情况,所提网络可以较准确地进行分类并划分出准确的语义边界. 2)所提网络与优秀的轻量级网络ENet、ERFNet、LEDNet、BiseNetv2得到的分割结果在视觉效果上相差不大,在某些情况下的分割准确度更优. 例如第4列,所提网络得到的分割结果图获得了最接近真实语义标签的分割边界,这是因为所提网络使用的辅助边缘损失函数可以使网络更关注边缘,起到细化边缘的作用. 3)与经典的常规语义分割网络PSPNet、OCNet相比,所提网络的分割效果略差,这是由于PSPNet、OCNet的网络层数和通道数更多,特征学习能力更强. 例如第6列,所提网络的部分区域出现分类错误的情况,而PSPNet、OCNet分割结果更准确. ...
... Comparison results of accuracy index on SUIM dataset in each network
Tab.3 语义分割模型 IoU/% mIoU/% PA/% BW HD PF WR RO RI FV SR 本文方法 84.62 63.99 18.46 41.84 61.93 53.44 46.00 58.42 53.55 85.32 U-Net[3 ] 79.46 32.25 21.85 33.94 23.65 50.28 38.16 42.16 39.85 79.44 SegNet[2 ] 80.63 45.67 17.45 32.24 55.72 47.62 43.92 51.51 46.85 82.19 Deeplab[4 ] 81.82 50.26 17.05 43.33 63.60 57.18 43.59 55.35 51.52 84.27 PSPNet[7 ] 82.51 65.04 28.54 46.56 62.88 55.80 46.78 55.98 55.51 86.41 GCN[24 ] 79.32 38.57 15.09 30.38 54.25 49.94 36.09 52.02 44.46 81.28 OCNet[15 ] 83.14 64.03 24.31 43.11 61.78 54.92 47.41 54.97 54.30 85.89 SUIMNet[13 ] 80.64 63.45 23.27 41.25 60.89 53.12 46.02 57.12 53.22 85.22 LEDNet[19 ] 82.96 58.47 18.02 42.86 50.96 58.13 46.13 54.99 51.36 84.25 BiseNetv2[21 ] 83.67 59.29 18.27 39.58 56.54 58.16 47.33 56.93 52.47 84.96 ENet[14 ] 80.94 50.60 16.97 36.71 51.73 49.24 41.99 50.46 47.33 82.31 ERFNet[16 ] 83.02 52.95 17.50 41.72 49.80 53.70 45.98 54.30 50.40 83.75 CGNet[17 ] 81.21 60.04 17.71 42.91 53.62 57.62 46.46 53.71 51.66 83.99
从表4 可知,所提网络在海草数据集上分别在0~2 m和2~6 m的范围内达到88.63%和89.01%的mIoU指标以及96.08%和96.10%的PA指标,在所有轻量级网络中精度指标可以排在前两位,仅次于轻量级网络BiseNetv2. 相比于经典的语义分割网络U-Net、SegNet、Deeplab等,所提网络的分割精度明显更优,但与PSPNet和OCNet相比,所提网络的分割精度略差. ...
... Comparison results of accuracy index in each network on seagrass dataset
Tab.4 语义分割模型 mIoU/% PA/% 0~2 m 2~6 m 0~2 m 2~6 m 本文方法 88.63 89.01 96.08 96.10 U-Net[3 ] 87.69 87.42 95.89 95.62 SegNet[2 ] 83.90 82.93 94.96 94.92 Deeplab[4 ] 87.36 87.93 95.84 95.88 PSPNet[7 ] 89.08 89.29 96.31 96.33 GCN[24 ] 87.37 86.97 95.82 95.73 OCNet[15 ] 88.96 89.41 96.26 96.35 SUIMNet[13 ] 88.24 88.45 95.91 95.93 LEDNet[29] 87.48 87.84 95.85 95.88 BiseNetv2[21 ] 88.43 88.85 96.03 96.09 ENet[14 ] 85.94 86.60 95.17 95.21 ERFNet[16 ] 86.72 87.05 95.36 95.48 CGNet[27] 87.15 87.24 95.43 95.46
因为本文的目标是设计轻量且高效的水下图像语义分割网络,通过对比实验评估其他语义分割网络与所提网络的效率和实时性. 评估指标包括模型参数量p (Param)、浮点运算数f (floating point operations,FLOPs)和推理速度v (inference speed). 其中浮点运算数表示网络模型的计算成本,浮点运算数越小表明需要的计算成本越小. 推理速度v 以每秒帧数来衡量,每秒帧数越大,表明网络每秒可以处理的图片数越多,实时性越强. ...
... Comparison results of efficiency index in each network
Tab.5 语义分割模型 v /(帧·s−1 ) p /106 f /109 本文方法 258.94 1.45 0.31 U-Net[3 ] 19.98 14.39 38.79 SegNet[2 ] 17.52 28.44 61.39 Deeplab[4 ] 16.00 5.81 8.28 PSPNet[7 ] 6.65 27.50 49.78 GCN[24 ] 11.26 23.95 7.09 OCNet[15 ] 31.71 60.48 81.36 SUIMNet[13 ] 27.69 3.86 4.59 LEDNet[19 ] 111.73 0.92 1.78 BiseNetv2[21 ] 244.63 3.35 3.83 ENet[14 ] 117.41 0.35 0.77 ERFNet[16 ] 198.36 2.06 4.64 CGNet[17 ] 116.49 0.48 1.08
综合对比平均交并比、像素准确率、推理速度、参数量和浮点运算数可知,所提网络在参数量、计算成本及处理速度等方面与常规的语义分割网络相比得到了很大的提升,与其他轻量级网络相比体现出一定的优势. 在分割精度上十分接近甚至优于常规的语义分割网络,在所有的轻量级语义分割网络中取得了较好的分割精度. ...
1
... 测试不同的基础网络编解码器结构对分割精度和速度的影响. 将编码器的5个模块分别替换为Mobilenetv2和ResNet-18[25 ] ,测试精度指标mIoU和速度指标FPS. 为了验证采用的非对称的编解码器结构的优势,将所提网络的解码器部分替换成与编码器对称的结构,把编码器中步长为2的卷积层替换成2倍上采样模块,实验结果如表7 所示. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}