

随着计算机技术的飞速发展,为了推动短期供水量预测方法的改良提升,集成学习算法与深度学习算法被引入供水预测领域. Brentan等[5]提出改进的支持向量回归方法,并进行短期水资源需求预测,消除了固定回归结构在响应新的输出时间序列时固有的偏差. 物联网集成的基于长短时记忆(long short term memory,LSTM)神经网络的配水网络相比于采用整合移动平均自回归方法(ARIMA)的配水网络,将运输过程中的损失和对消费者的水质量的损失降到更低[6]. 通过插值和外推2种情景,Shuang等[7]在传统统计模型和机器学习模型中寻找最合适的预测模型,结果表明相比于线性回归法、Lasso回归与岭回归法、AdaBoost法,梯度推进决策树方法的预测性能最佳. Guo等[8]建立门限递归单元网络(GRUN)需水预测模型,该模型性能明显优于人工神经网络和季节性差分自回归滑动平均模型. Xenochristou等[9]使用随机森林模型预测英国居民的日需水量,并运用可解释的机器学习技术量化预测因素对用水量的影响,此方法结合了机器学习模型的高精度和统计方法的可解释性. Huang等[10]将BP神经网络集合到AdaBoost算法中,有效提高了需水预测的准确性与稳定性.
日供水量预测方法主要有单一深度学习方法、单一集成学习方法、耦合数据前处理方法与深度学习方法的方法等,这些方法的预测精度、稳定性与泛化性能均较差. 此外,耦合集成学习算法与深度学习算法的方法的研究不多. 为了扩展短期供水预测的应用,本研究以义乌市为研究区域,运用自相关系数法与网格搜索法的结合方法进行数据特征选择,采用拉依达准则对日供水数据进行预处理,提出AdaBoost集成学习算法改进的LSTM神经网络的组合短期供水预测方法,并与随机森林(random forest, RF)、AdaBoost(adaptive boosting)与LSTM神经网络3种短期供水预测方法进行比较,验证改良短期供水预测方法的适用性与准确性.
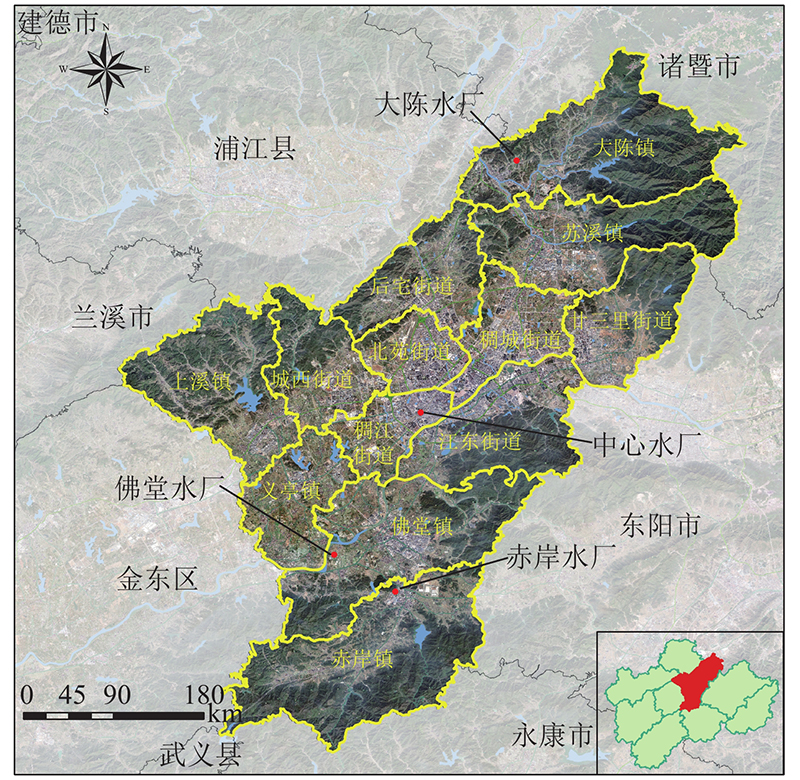
1. 研究区域概况
义乌市地处浙中盆地,属亚热带季风气候,温和湿润,四季分明. 尽管地处南方丰水地区,受独特的地理位置和空间条件限制,义乌市仍是重度缺水地区[11],水资源总量仅占浙江省总量的0.86%,人均水资源量仅为410
图 1
2. 研究方法
2.1. 供水预测方法介绍
2.1.1. RF方法
2.1.2. AdaBoost算法
AdaBoost是Freund[17]在Boosting算法上改进的、拥有自适应增强能力的集成学习算法. 依据加权方法,AdaBoost组合同一训练集上训练能力较差的多个弱学习器,构成训练能力极强的强学习器. AdaBoost可以有效避免过拟合,能够作为算法框架优化其他算法,应用极为灵活.
2.1.3. LSTM神经网络方法
遗忘门的公式为
输入门的公式为
输出门的公式为
式中:
2.1.4. 基于集成学习改进的LSTM方法
基于集成学习改进的LSTM方法(以下简称改进LSTM)以集成学习的方式增强LSTM神经网络方法的预测精度与鲁棒性,通过AdaBoost集成学习算法串行训练多个LSTM弱预测器,并在训练过程中不断调整样本与弱预测器权重,再将弱预测器进行加权组合生成强预测器,输出最终的预测结果. 改进LSTM融合了AdaBoost深度挖掘算法潜力与LSTM处理时间序列问题的优势,解决了多层LSTM参数选择复杂的难题,改善了AdaBoost对异常值敏感的缺陷.
改进LSTM的构造流程如下.
1)赋予每个样本数据相同的权重:
式中:Dn为第n个样本数据的权重,M为样本数据总数量.
2)设定网络超参数,并设定LSTM弱预测器总数为Nn,采用LSTM神经网络训练样本.
3)对第
式中:yi为弱预测器在训练集上的预测值,Gn(xi)为训练集的观测值.
4)计算每个样本的相对误差为
式中:en,i为第n个弱预测器的第i个样本数据的相对误差.
5)得到第
式中:en为第n个若预测器的误差率,wn,i为第n个弱预测器的第i个样本数据的权重.
6)获得第
7)对第
其中规范化因子为
8)采用取中位数的结合方法,将多个弱学习器融合为强学习器:
式中:
2.2. 评价指标
选择平均绝对误差MAE,均方根误差RMSE和纳什效率系数NSE为评估预测方法性能的代表性指标,计算式分别为
式中:M为总时间步长数,
3. 结果与分析
3.1. 供水预测方法建立
供水数据一般持续时间长,并会受检测设施、人为因素或极端天气影响而产生异常值,导致供水数据的准确性降低,因此在使用供水数据进行训练分析前,须筛选和剔除异常值. 本研究采用拉依达准则进行异常值筛选与替换. 拉依达准则假定数据为正态分布,利用数据的均值
本研究选取的是水厂4~6 a的日供水数据,数据量较大,若直接输入至神经网络进行训练,预测效果较差. 为此,将采用拉依达准则筛选后的供水量数据进行归一化处理,这样既加快了训练收敛速度,又提高了预测精度. 将供水量数据归一化至[0, 1.0],数据归一化
式中:
在日供水量预测领域中,数据输入变量往往使用2种主要特征:历史供水量与气象因素(如温度、湿度与降雨). 特征选取得越多不代表方法性能越好,与供水量相关系数较低的特征变量(如温度)往往会影响深度学习方法的训练与学习,从而影响方法性能. 因此,本研究选择历史供水量作为唯一输入. 在选择供水量作为唯一输入的前提下,须重构水需求数据以更好表示样本数据间的关系,而不同时期的用水需求间存在时间相关性[10]. 以义乌市中心水厂为例,采用自相关系数法与网格搜索法确认数据输入的格式. 自相关系数法的计算式为
图 2
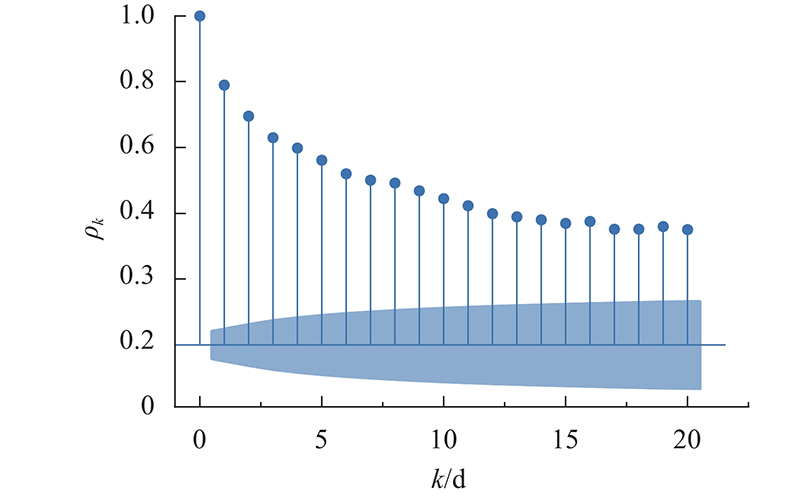
图 2 日供水序列不同延迟期数的自相关系数
Fig.2 Autocorrelation coefficients of daily water supply series with different delay periods
表 1 不同输入天数的LSTM神经网络方法性能对比
Tab.1
| Td/d | NSE | MAE/(m3·d−1) | RMSE/(m3·d−1) |
| 2 | 0.919 | 1 136 | 1 601 |
| 3 | 0.917 | 1 146 | 1 616 |
| 4 | 0.924 | 1 242 | 1 548 |
| 5 | 0.918 | 1 154 | 1 607 |
| 6 | 0.924 | 1 241 | 1 550 |
| 7 | 0.927 | 1 104 | 1 520 |
| 8 | 0.921 | 1 233 | 1 581 |
| 9 | 0.921 | 1 168 | 1 581 |
| 10 | 0.919 | 1 207 | 1 605 |
3.1.1. RF方法
表 2 不同决策树个数的随机森林方法性能对比
Tab.2
| NRF | NSE | MAE/( m3·d−1) | RMSE/( m3·d−1) |
| 10 | 0.937 | 864 | 1 408 |
| 20 | 0.938 | 879 | 1 405 |
| 30 | 0.938 | 830 | 1 395 |
| 40 | 0.937 | 848 | 1 416 |
| 50 | 0.938 | 861 | 1 402 |
| 60 | 0.941 | 841 | 1 367 |
| 70 | 0.944 | 819 | 1 335 |
| 80 | 0.938 | 873 | 1 402 |
| 90 | 0.939 | 853 | 1 389 |
| 100 | 0.939 | 837 | 1 390 |
表 3 不同决策树深度的随机森林方法性能对比
Tab.3
| DRF | NSE | MAE/( m3·d−1) | RMSE/( m3·d−1) |
| 2 | 0.872 | 1 382 | 2 009 |
| 3 | 0.933 | 874 | 1 455 |
| 4 | 0.939 | 853 | 1 390 |
| 5 | 0.932 | 915 | 1 469 |
| 6 | 0.923 | 928 | 1 559 |
| 7 | 0.921 | 971 | 1 577 |
| 8 | 0.896 | 1 134 | 1 816 |
| 9 | 0.881 | 1 193 | 1 937 |
| 10 | 0.860 | 1 317 | 2 107 |
| 11 | 0.824 | 1 471 | 2 363 |
3.1.2. AdaBoost方法
影响AdaBoost方法精度的参数主要有基学习器类型、基学习器的最大个数、基学习器的权重缩减系数,其中对方法精度起主要作用为基学习器的个数NAB. 当NAB=1时,AdaBoost方法无法使用;当NAB较小时,方法易欠拟合;当NAB较大时,易过拟合并导致严重的计算负担. 以中心水厂为例,本研究依据网格搜索法确定AdaBoost方法的最佳基学习器数量为30,如表4所示.
表 4 不同决策树个数的AdaBoost方法性能对比
Tab.4
| NAB | NSE | MAE/( m3·d−1) | RMSE/( m3·d−1) |
| 10 | 0.846 | 1 432 | 2 207 |
| 20 | 0.793 | 1 701 | 2 560 |
| 30 | 0.860 | 1 404 | 2 102 |
| 40 | 0.802 | 1 796 | 2 503 |
| 50 | 0.783 | 1 783 | 2 620 |
| 60 | 0.844 | 1 406 | 2 224 |
| 70 | 0.822 | 1 659 | 2 375 |
| 80 | 0.822 | 1 782 | 2 373 |
| 90 | 0.829 | 1 571 | 2 324 |
| 100 | 0.814 | 1 534 | 2 424 |
3.1.3. LSTM神经网络方法
为了方便方法性能比较,LSTM神经网络方法中的神经网络超参数设置与改进LSTM中弱预测器LSTM方法保持一致.
3.1.4. 改进LSTM
以前7 d的供水数据作为方法数据输入,以当天的供水数据作为方法输出结果,故输入节点为7个,输出节点为1个. 该方法以单层LSTM作为弱预测器,避免选取多层参数的烦琐,因此选取神经网络隐藏层层数为1层,神经网络隐藏层内神经元个数由网格搜索法确定为128个,神经网络训练期间将均方误差MSE作为损失误差,采用Adam优化算法训练LSTM方法. 学习率根据文献[21]、[22]及方法默认值设定为0.001. 迭代次数依据LSTM训练日志设定为100. 本研究由网格搜索法设定批量大小NBS=32,如表5所示. 为了避免方法过拟合,使用正则化方法,dropout=0.2,训练集与测试集的划分比例为8∶2.
表 5 不同批量大小的改进LSTM方法性能对比
Tab.5
| NBS | NSE | MAE/( m3·d−1) | RMSE/( m3·d−1) |
| 16 | 0.924 | 1 115 | 1 548 |
| 32 | 0.927 | 1 335 | 1 646 |
| 64 | 0.917 | 1 170 | 1 617 |
| 128 | 0.896 | 1 376 | 1 811 |
| 256 | 0.761 | 1 980 | 2 752 |
表 6 不同弱预测器个数的改进LSTM方法性能对比
Tab.6
| N | NSE | |||||
| 第1次 | 第2次 | 第3次 | 第4次 | 第5次 | 平均值 | |
| 2 | 0.897 | 0.898 | 0.894 | 0.883 | 0.896 | 0.894 |
| 3 | 0.852 | 0.853 | 0.849 | 0.839 | 0.851 | 0.849 |
| 4 | 0.839 | 0.842 | 0.835 | 0.829 | 0.840 | 0.837 |
| 5 | 0.831 | 0.836 | 0.831 | 0.824 | 0.836 | 0.832 |
| 6 | 0.830 | 0.833 | 0.830 | 0.822 | 0.833 | 0.830 |
| 7 | 0.830 | 0.832 | 0.828 | 0.822 | 0.830 | 0.828 |
| 8 | 0.796 | 0.824 | 0.815 | 0.826 | 0.793 | 0.811 |
| 9 | 0.772 | 0.827 | 0.786 | 0.810 | 0.793 | 0.798 |
| 10 | 0.775 | 0.810 | 0.790 | 0.811 | 0.779 | 0.793 |
3.2. 供水预测方法性能比较
选用4个水厂的日供水量数据建立4种基于集成学习、深度学习的日供水量预测方法,并对比方法的性能. 集成学习与深度学习每次运行会产生不同的预测结果,为了更合理地评估方法性能,对每个方法都运行5次取平均值. 如图3所示为各方法的预测结果曲线,其中Q为日供水量. 可以看出,RF方法、AdaBoost方法的预测值均与实际数值的变化趋势拟合度较其他2种方法的低,部分时间跨度以线性变化形式反映供水曲线的变化,局部时间范围的预测值甚至维持不变,对峰值的拟合也无法达到令人满意的效果,且均为负偏差. LSTM神经网络方法对变化趋势与峰值的拟合效果均较好,可以有效捕捉供水量极值点的信息,其曲线趋势基本与实测曲线相合,但仍有较大偏差. 改进LSTM对变化趋势与峰值的拟合效果比LSTM方法的更好,原因是引入AdaBoost算法使得改进LSTM对未被预测精确的样本的学习能力更强. 如表7所示为各方法的性能对比. 由表可知,改进LSTM的日供水量预测性能显著优于其他传统集成学习与深度学习方法的. 原因是改进LSTM将LSTM方法对复杂非线性时序数据的优秀处理能力与AdaBoost方法对大误差数据的强学习能力结合. 改进LSTM的优越性通过最高的NSE、最低的MAE与RMSE来验证. 在经由AdaBoost集成算法改进后,LSTM方法的精度有了较大的提升. 以赤岸水厂为例,NSE由0.900提升至0.929,性能提升了3.2%,MAE由158.3
图 3
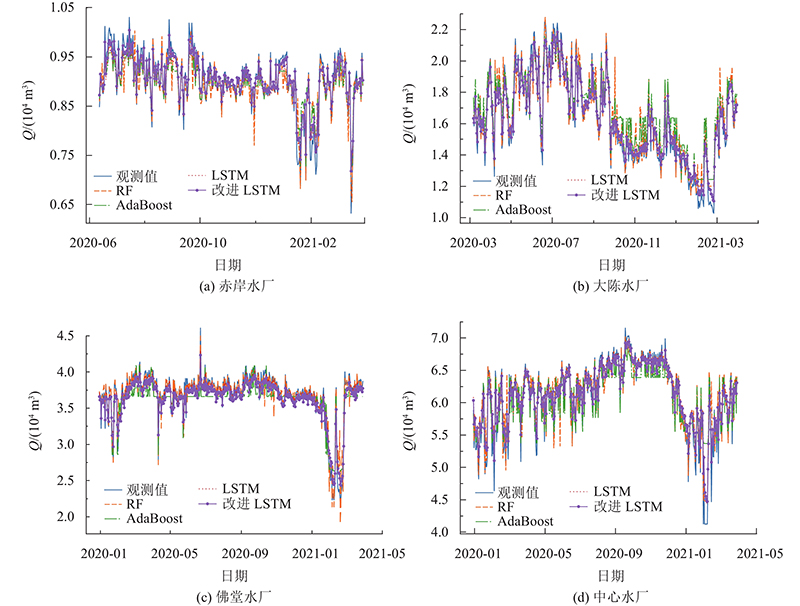
图 3 4座水厂不同供水预测方法的日供水量预测结果曲线图
Fig.3 Curves of daily water supply prediction results for different water supply forecasting models at four water plants
表 7 4座水厂不同供水预测方法的性能对比
Tab.7
| 方法 | 赤岸水厂 | 大陈水厂 | 佛堂水厂 | 中心水厂 | |||||||||||
| NSE | MAE/ (m3·d−1) | RMSE/ (m3·d−1) | NSE | MAE/ (m3·d−1) | RMSE/ (m3·d−1) | NSE | MAE/ (m3·d−1) | RMSE/ (m3·d−1) | NSE | MAE/ (m3·d−1) | RMSE/ (m3·d−1) | ||||
| RF | 0.852 | 171.5 | 239.1 | 0.943 | 499.5 | 674.0 | 0.897 | 1 205.1 | 1 812.2 | 0.894 | 1 122.7 | 1 827.5 | |||
| AdaBoost | 0.844 | 187.8 | 245.2 | 0.892 | 791.9 | 929.8 | 0.816 | 1 587.6 | 2 420.7 | 0.836 | 1 611.3 | 2 275.0 | |||
| LSTM | 0.900 | 158.3 | 196.1 | 0.961 | 475.9 | 557.7 | 0.913 | 1 190.0 | 1 662.0 | 0.905 | 1 258.9 | 1 733.6 | |||
| 改进LSTM | 0.929 | 118.4 | 165.2 | 0.971 | 402.2 | 484.8 | 0.925 | 1 131.8 | 1 545.2 | 0.924 | 1 113.9 | 1 547.2 | |||
4. 结 语
将基于AdaBoost集成学习算法改进的LSTM神经网络方法与3种基准方法(RF方法、AdaBoost方法、LSTM方法)进行对比. RF方法过分追求训练集上的预测性能,导致测试集上的精度下降,易出现过拟合现象. AdaBoost方法在训练过程中会偏向预测困难的样本,易受异常值干扰. LSTM方法虽然对时序数据有较好的处理能力,但仍有精度限制. 改进LSTM结合LSTM方法对复杂非线性时序数据的优秀处理能力与AdaBoost方法对大误差数据的强学习能力,方法的性能获得极大提升. 将改进LSTM应用于义乌市的4个水厂,方法预测性能、对供水曲线变化趋势与峰值的拟合效果在4个方法中皆为最优,证明改进LSTM具有较好的泛化能力和稳定的预测性能. 本研究仍存在诸多不足: 1)直接采用历史供水数据进行分析,未提取供水数据的趋势和残差特性,未考虑供水数据的非平稳性;2)对比基准方法选择较少,仅选用集成学习与深度学习的代表方法,未构建传统供水预测方法(如多元线性回归法或灰色预测法)进行性能比较. 下一步研究将考虑采用时间序列分解方法,并搭建更多基准模型用于性能比较.
参考文献
国际上水资源综合管理进展
[J].
International progress in integrated water resources management
[J].
气候变化对水文循环的影响
[J].
Impacts of climate change on water cycle
[J].
1956—2018 年中国江河径流演变及其变化特征
[J].
Evolution and variation characteristics of the recorded runoff for the major rivers in China during 1956-2018
[J].
A comparison of short-term water demand forecasting models
[J].DOI:10.1007/s11269-019-02213-y [本文引用: 1]
Hybrid regression model for near real-time urban water demand forecasting
[J].DOI:10.1016/j.cam.2016.02.009 [本文引用: 1]
Water demand forecasting using deep learning in IoT enabled water distribution network
[J].
Water demand prediction using machine learning methods: a case study of the Beijing–Tianjin–Hebei region in China
[J].DOI:10.3390/w13030310 [本文引用: 1]
Short-term water demand forecast based on deep learning method
[J].DOI:10.1061/(ASCE)WR.1943-5452.0000992 [本文引用: 1]
Short-term forecasting of household water demand in the UK using an interpretable machine learning approach
[J].DOI:10.1061/(ASCE)WR.1943-5452.0001325 [本文引用: 1]
An ensemble-learning-based method for short-term water demand forecasting
[J].DOI:10.1007/s11269-021-02808-4 [本文引用: 4]
义乌市水资源开发利用对策研究
[J].
Research on countermeasures for water resources development and utilization in Yiwu City
[J].
水资源紧缺约束下义乌市人口承载力研究
[J].
Study on the population carrying capacity of Yiwu City under water scarcity constraint
[J].
The random subspace method for constructing decision forests
[J].DOI:10.1109/34.709601 [本文引用: 1]
Boosting a weak learning algorithm by majority
[J].
基于双向长短时神经网络的水量预测方法研究
[J].
Study on water quantity prediction method based on bidirectional long and short time neural network
[J].
Exploring a long short-term memory based encoder-decoder framework for multi-step-ahead flood forecasting
[J].DOI:10.1016/j.jhydrol.2020.124631
Streamflow and rainfall forecasting by two long short-term memory-based models
[J].DOI:10.1016/j.jhydrol.2019.124296 [本文引用: 1]
Deep learning with long short-term memory neural networks combining wavelet transform and principal component analysis for daily urban water demand forecasting
[J].DOI:10.1016/j.eswa.2021.114571 [本文引用: 1]
Hourly and daily urban water demand predictions using a long short-term memory based model
[J].DOI:10.1061/(ASCE)WR.1943-5452.0001276 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}