

公路隧道由于空间封闭且路面摩阻系数小,车辆碰撞起火成为隧道交通事故的主要形式,不仅破坏隧道结构导致坍塌,还会造成巨大损失[1]. 隧道早期火灾亟须快速精准识别,保障隧道运营安全.
传统烟火检测使用火灾探测器,检测区域覆盖狭窄、检测速度慢且易误检,应用于复杂公路隧道效果一般[2]. 基于视频的火灾检测有实时、精准的特点,将是最有效、最直接的火灾检测手段[3]. 隧道烟火检测可以从静态和动态两方面开展[4]. 火焰检测主要通过颜色、形状、闪烁特性及面积变化等特征,实现火焰提取[5-7]. 烟雾检测通过融合多重特征信息检测烟雾,或基于变分特征检测烟雾运动[8-10]. 现有的烟火检测存在误报率高、泛化能力弱、响应时间长等缺点,不利于早期火灾预警. 近年来,深度学习已逐渐应用于视频火灾检测,检测效果有较大程度的提高[11]. Hou等[12]基于Faster RCNN检测火灾,精度良好但实时性较弱. 利用基于CNN的烟火检测法,实时识别烟火,但检测速度慢[13-15]. 采用改进算法可以提升烟火检测的效率,石磊等[16]改进SSD,在损失函数中引入Focal Loss函数,权衡了精度、速度和实时性. 赵媛媛等[17]基于融合多尺度特征的Yolov3算法提高检测率,但对不同分辨率图像的检测效果差. Yolo系列算法中,检测精度和实时性良好的只有YOLOv4、YOLOv5和YOLOX火灾检测网络[18-20]. YOLOv4权重文件过大;YOLOX为YOLOv5的优化,但网络模型较复杂且收益不一定理想;YOLOv5网络结构简单,易运用于公路隧道场景下对烟雾和火焰特征进行针对性改进.
为了增强算法在复杂公路隧道场景下对烟火深度的检测效果,解决算法中样本不均衡的问题,进一步提高视频烟火检测的精度. 基于YOLOv5s视频烟火检测算法,优化骨干网络特征提取部分,增强对烟火特征的深度学习,实现模型的轻量化和改进设计. 将大规模数据集用于模型训练,以满足网络对多样性训练数据的需求. 实验结果表明,在隧道早期火灾中,改进算法在满足实时性的要求下,对烟火目标的形态变化、干扰物及特征模糊有较好的鲁棒性.
1. YOLOv5s网络结构
图 1
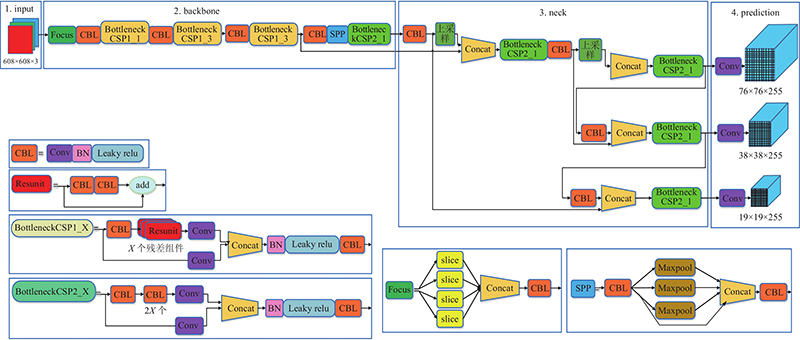
公路隧道烟火检测模型YOLOv5s分为烟火特征提取层和烟火特征检测层. 特征提取层的第1层是Focus模块,可以减少参数量和提高速度. 第2层是CBL模块,作为标准卷积层,可以获取火焰和烟雾图像特征. 第3层是Bottleneck CSP模块,能够提取火焰和烟雾图像的深度特征. 第9层是SPP模块,可以将输入的大小不限的烟火特征图进行量化,得到指定大小的烟火特征图像,以此来提高网络的接受域. 特征检测层Neck模块为FPN+PAN的结构,输出3组不同分辨率的融合特征. 预测端将特征检测层输出的3组融合特征图进行卷积,得到不同分辨率特征图所对应的预测边界框,实现火灾的烟火检测.
2. YOLOv5s模型优化与改进
2.1. 火焰或烟雾深层特征提取
图 2
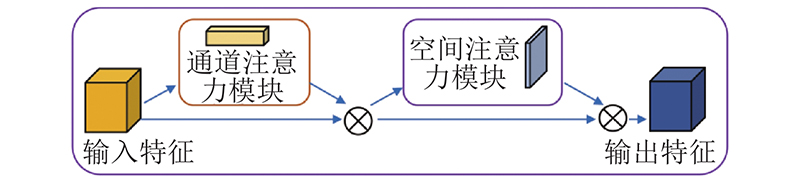
图2中,CBAM模块通过跨通道和空间信息,提取烟雾和火焰特征的语义信息. 通道注意力模块可以学习通道轴中的内容信息,关注火灾烟火特征信息,忽视非火灾特征信息,其中计算过程如下:
式中:F为原始特征图;Mc(F) 为输出的通道注意力值;
将通道注意力模块的输出值输入到空间注意力模块,可以分别学习空间轴中的位置信息,保证烟火特征信息在网络中得到真正学习. 空间注意力的计算过程如下:
式中:Ms(F) 为输出的空间注意力值;
当输入给定的一个中间烟火特征映射F∈RC×H×W(其中H和W为特征映射的长度和宽度)时,CBAM依次推断出一维通道注意图Mc∈RC×1×1和二维空间注意图Ms∈R1×H×W. 整体注意过程如下:
式中:
2.2. 火灾特征提取网络改进
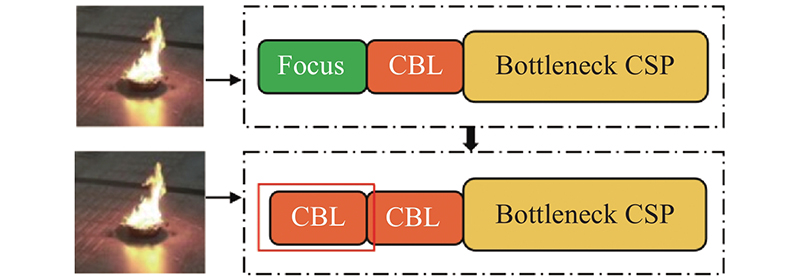
公路隧道烟火检测模型识别算法在满足准确识别烟火的同时,对模型的尺寸进行压缩,以便其在硬件设备上的部署. 采用卷积核为6、步长为2的Conv卷积替换骨干网络中的Focus结构,提高网络的检测速度和精度,如图3所示.
图 3
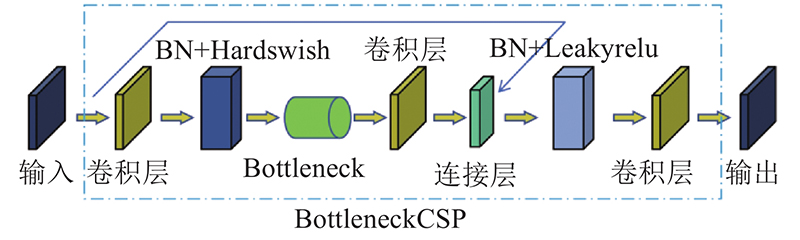
YOLOv5s架构的骨干网络共4个BottleneckCSP模块,其包含多个卷积运算,有利于提取烟火特征信息,但参数量较多,导致计算量增大,训练时间增加,权重变大. 改进设计BottleneckCSP模块,去掉原模块桥接分支上的卷积层,将BottleneckCSP模块的输入特征映射与另一个分支的输出特征映射进行深度直接连接,有效减少模块的参数数量. 改进的BottleneckCSP模块的体系结构如图4所示,名为BottleneckCSP-2.
图 4
使用SPPF代替SPP层,提升网络计算效率. 在SPPF中用卷积核5×5代替之前的大卷积核,置于骨干网络的末端,将骨干网络第2个BottleneckCSP-2中的卷积网络个数从9减少至6,将骨干网络最后1个BottleneckCSP-2中采用残差. 改进后的YOLOv5s网络结构如图5所示.
图 5

表 1 原YOLOv5s与YOLOv5s-PRO参数量及计算量的对比
Tab.1
| 序号 | M1 | P1/104 | Q1/ GLOPs | M1 | P2/104 | Q2/ GLOPs | (P1—P2)/ 104 | (Q1—Q2)/ GLOPs |
| 0 | Focus | 0.3520 | 0.3539 | Conv | 0.0640 | 0.0590 | 0.2880 | 0.2949 |
| 1 | CBL | 1.8560 | 0.4719 | CBL | 1.8560 | 0.4719 | 0.0000 | 0.0000 |
| 2 | BottleneckCSP | 1.9904 | 0.4981 | BottleneckCSP-2 | 1.7792 | 0.4456 | 0.2112 | 0.0524 |
| 3 | CBL | 7.3984 | 0.4719 | CBAM | 0.0610 | 0.0156 | −0.0610 | −0.0156 |
| 4 | BottleneckCSP | 16.1152 | 1.0224 | CBL | 7.3984 | 0.4719 | 0.0000 | 0.0000 |
| 5 | CBL | 29.5424 | 0.4719 | BottleneckCSP-2 | 10.7392 | 0.6816 | 5.3760 | 0.3408 |
| 6 | BottleneckCSP | 64.1792 | 1.0224 | CBAM | 0.2146 | 0.0137 | −0.2146 | −0.0137 |
| 7 | SPP | 65.6896 | 0.2621 | CBL | 29.5424 | 0.4719 | 0.0000 | 0.0000 |
| 8 | BottleneckCSP | 124.8768 | 0.4981 | BottleneckCSP-2 | 60.8768 | 0.9699 | 3.3024 | 0.0524 |
| 9 | CBL | 118.0672 | 0.4719 | CBAM | 0.8290 | 0.0133 | −0.8290 | −0.0133 |
| 10 | — | — | — | CBL | 118.0672 | 0.4719 | 0.0000 | 0.0000 |
| 11 | — | — | — | BottleneckCSP-2 | 111.7184 | 0.4456 | 13.1584 | 0.0524 |
| 12 | — | — | — | CBAM | 3.2866 | 0.0131 | −3.2866 | −0.0131 |
| 13 | — | — | — | SPPF | 65.6896 | 0.2621 | 0.0000 | 0.0000 |
| 总量 | — | 430.0672 | 5.5443 | — | 412.1224 | 4.8071 | 17.9448 | 0.7372 |
表1中,M1、M2分别为YOLOv5s与YOLOv5s-PRO骨干网络中的各个模块,P1、P2分别为YOLOv5s与YOLOv5s-PRO的模块参数量,Q1、Q2分别为YOLOv5s与YOLOv5s-PRO的模块计算量,P1−P2、Q1−Q2分别为模块的参数量变化和计算量变化. 从表1可知,在引入轻量型CBAM注意力模块后,网络的计算量有一定的增加,但总体上影响不大,改进后的YOLOv5s-PRO模型的参数量为412.1224 ×104,比YOLOv5s模型减少了17.9448 × 104,计算量达到4.8071 GLOPs,比YOLOv5s模型减少了0.7372 GLOPs,提升了YOLOv5s-PRO模型的检测速度.
2.3. 损失函数和学习率调优
YOLOv5s算法采用GIoU函数,作为火灾检测边界框的损失函数[23]. 损失计算根据预测边界框,损失函数如下:
基于IoU及变体,计算各层预测边界框与真实边界框之间的边框回归损失,如下所示:
式中:l为金字塔层数,l∈[1, L];M为金字塔第l层对应的边界框数,m∈[1, M];box为边界框位置信息;pre、gt为预测值和真实值;C为pre和gt的最小区域面积;
GIoU解决了梯度的问题,但存在不稳定、收敛慢的缺点. DIoU解决了GIoU中检测框和真实框出现包含时收敛慢的问题,未考虑box纵横比. CIoU在DIoU的基础上增加了检测框尺度,使得预测框更加符合真实框,因此将CIoU作为火灾烟火检测的损失函数. 它包括烟火检测框损失Lcu、烟火置信度损失Lcf和烟火分类损失Lcs,如下所示.
式中:S2为特征图尺度;B为先验框;
为了提高烟雾图像数据集和火焰图像数据集之间的平衡,置信度函数采用Focal Loss,引入权重因子
式中:
式中:
在对损失函数进行优化后,对YOLOv5s的整个置信度有一定的优化.
学习率调优采用warm-up对学习率进行预热,在YOLOv5s烟火检测模型数据训练前60次的每次结束后,用一维线性插值更新下一轮迭代训练的学习率. 60次以后,利用余弦退火算法更新下一轮迭代训练的学习率,计算原理为
式中:Ln为新得到的学习率,Lmin为最小的学习率,L1为初始学习率,Ec为当前训练到某个轮次对应的值,Tmax为训练的总轮次数量.
3. 实验及结果分析
3.1. 数据集
模型训练在Intel Core I5-10200H处理器、16 GB内存、NVIDIA GeForce RTX 2060、6 GB独立显存的硬件环境下,采用Python3.8编程语言,结合PyTorch深度学习框架,实现对原模型和改进后的YOLOv5s-PRO公路隧道烟火检测模型的训练.
火灾烟火检测的训练样本数据集的构建是通过养护公司收集的现场数据资料和在线搜索公开的火灾图像或视频. 使用辅助标注工具对数据集进行初步标注,利用开源工具LabelImg进行可视化. 构建5 000张模拟隧道火灾实验数据集(适应隧道场景)、1 000张重组数据集(降低类火物体干扰)和4 000张其他烟火数据集(烟火数据集均衡化),共10 000张火灾数据集及几十段火灾的视频库.
3.2. 模型训练
实验使用自建的烟火数据集图像,样本为火焰(fire)、烟雾(smoke)2类. 实际测试时,验证集图像为1 000张,测试集图像为1 500张(含烟火). 测试集分为3大类:模拟隧道火灾数据集 Ⅰ、真实隧道火灾数据集 Ⅱ 和其他类型火灾数据集 Ⅲ.
图 6

图 7

图6中,左、右2栏分别为训练集和验证集. 可以看出,3类损失函数在模型训练的0~50次时下降幅度很大,但相对平滑. 50~100次时,变化趋势减小. 100次以后基本平稳,保持稳定的状态,说明训练使得模型的检测效果更好.
表 2 YOLOv5s-PRO训练数据的统计表
Tab.2
| n | Pr | Re | mAP-U | mAP-H |
| 103 | 0.9612 | 0.8552 | 0.9376 | 0.5240 |
| 105 | 0.9466 | 0.8656 | 0.9193 | 0.5245 |
| 104 | 0.9576 | 0.8830 | 0.9287 | 0.5233 |
| 106 | 0.9634 | 0.8824 | 0.9314 | 0.5224 |
| 100 | 0.9619 | 0.8763 | 0.9258 | 0.5216 |
| 88 | 0.9754 | 0.9000 | 0.9279 | 0.5195 |
| 118 | 0.9685 | 0.8590 | 0.9144 | 0.5206 |
| 109 | 0.9362 | 0.8603 | 0.9226 | 0.5157 |
| 82 | 0.9258 | 0.8850 | 0.9307 | 0.5133 |
| 97 | 0.9270 | 0.8835 | 0.9301 | 0.5127 |
| 108 | 0.9541 | 0.8679 | 0.9184 | 0.5132 |
| 114 | 0.9320 | 0.8758 | 0.9257 | 0.5121 |
| 119 | 0.9458 | 0.8516 | 0.9047 | 0.5144 |
| 92 | 0.9594 | 0.8445 | 0.9145 | 0.5129 |
| 107 | 0.9613 | 0.8485 | 0.9205 | 0.5118 |
| 98 | 0.9140 | 0.8568 | 0.9173 | 0.5112 |
| 112 | 0.9613 | 0.8254 | 0.9074 | 0.5118 |
| 96 | 0.9299 | 0.8733 | 0.9225 | 0.5100 |
| 87 | 0.9509 | 0.8831 | 0.9176 | 0.5104 |
| 94 | 0.9605 | 0.8530 | 0.9167 | 0.5097 |
图 8
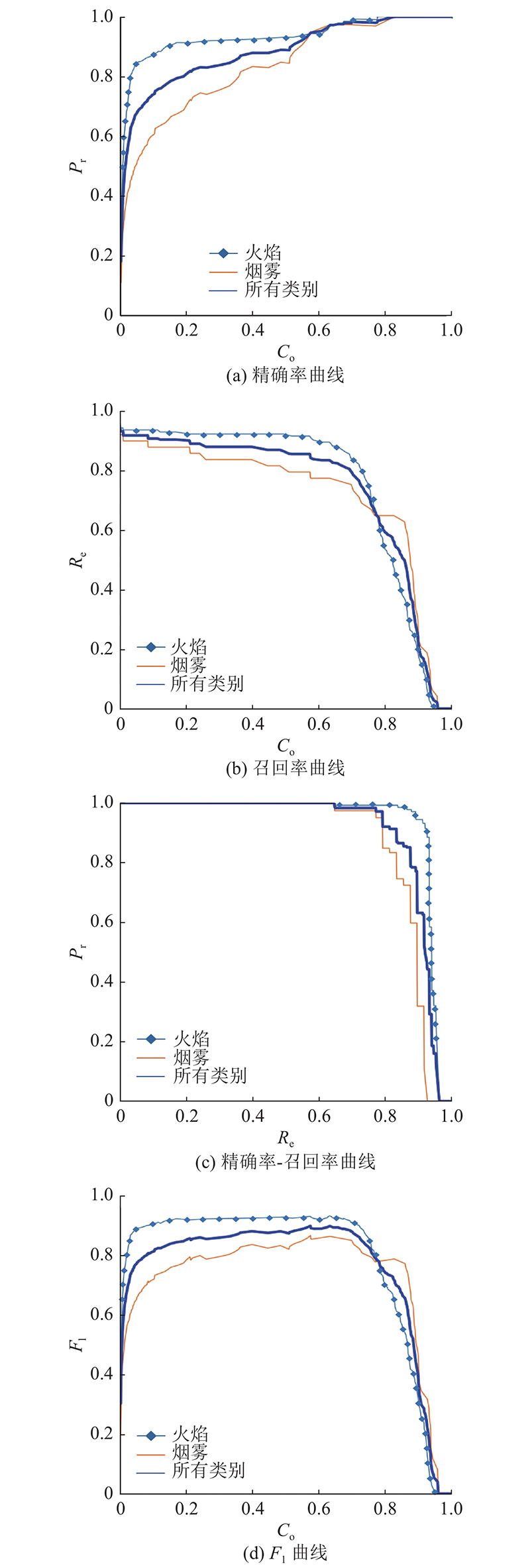
3.3. 对比分析
图 9
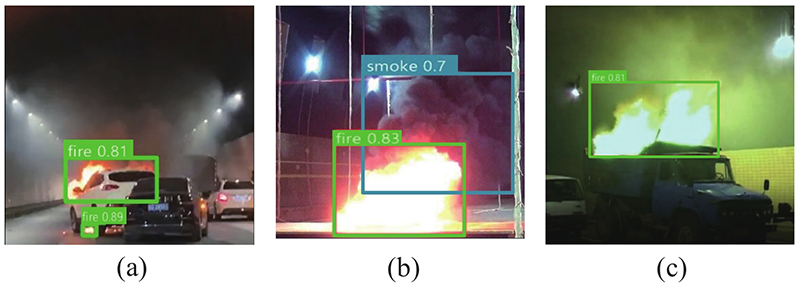
图 10

图 10 YOLOv5s-PRO深层火灾特征检测图样
Fig.10 YOLOv5s-PRO deep fire feature detection drawing
图 11

图 11 骨干网络中间特征层的分析
Fig.11 Analysis of middle characteristic layer of backbone network
如图11(a)、(b)所示分别为原始隧道火灾图像和标记后的火灾图像. 如图11(c)、(d)所示分别为改进前、后的P/2特征图,在卷积初始阶段,火焰轮廓在改进前、后都比较清晰,但图11(c)的烟雾轮廓基本看不清楚,图11(d)有一定的烟雾边界轮廓. 如图11(e)、(f)所示分别为改进前、后的P/4特征图,图11(f)的烟火特征明显强于图11(e),获取了更多的特征信息. 如图11(g)、(h)所示分别为改进前、后的P/8特征图,图11(h)的信息比图11(g)更丰富. 如图11(i)、(j)所示分别为改进前、后的P/16特征图,图11(j)较图11(i)具有更深层的特征信息. 如图11(k)、(l)所示分别为改进前、后P/32的特征图,图11(l)有明显的烟火信息. 综上所述,改进后的公路隧道烟火检测特征提取网络能够获取更深层的烟火信息.
为了更好地体现优化后的网络模型,将改进前、后的模型在相同的环境和参数配置下,采用相同的隧道烟火图像数据集进行对比测试,训练过程的验证集检测框损失、分类损失和置信度损失变化如图12所示.
图 12
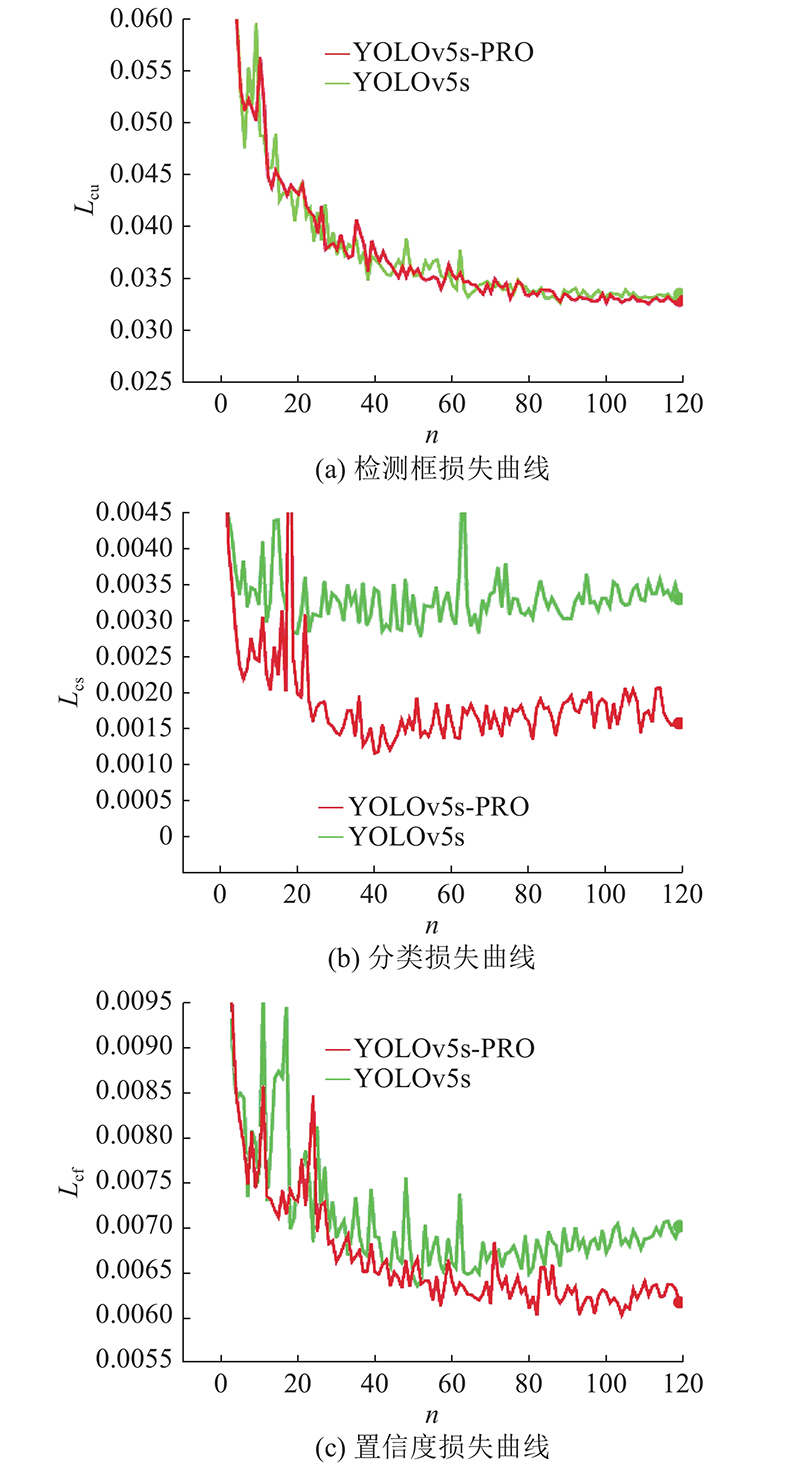
图 13

表 3 原YOLOv5s与YOLOv5s-PRO的测试性能
Tab.3
| 数据集 | F1 | F2 | F1− F2 | S1 | S2 | S1− S2 | mAP1 | mAP2 | mAP1− mAP2 | t1/ms | t2/ms | (t1− t2)/ms |
| Ⅰ | 95.28 | 96.74 | −1.46 | 90.81 | 92.63 | −1.82 | 93.12 | 94.69 | −1.57 | 6.53 | 6.09 | 0.44 |
| Ⅱ | 90.33 | 91.61 | −1.28 | 83.38 | 89.78 | −6.40 | 87.41 | 90.70 | −3.29 | 6.51 | 6.11 | 0.40 |
| Ⅲ | 88.78 | 90.89 | −2.11 | 81.61 | 87.52 | −5.91 | 84.42 | 89.21 | −4.79 | 6.57 | 6.17 | 0.40 |
| 均值 | 91.46 | 93.08 | −1.62 | 85.27 | 89.98 | −4.71 | 88.32 | 91.53 | −3.21 | 6.54 | 6.12 | 0.42 |
表3中,F1、F2分别为改进前、后模型的火焰检测率,S1、S2分别为改进前、后模型的烟雾检测率,mAP1、mAP2分别为改进前、后模型的平均检测精度,t1、t2分别为改进前、后模型的平均单张检测时间. 从表3可知,在3类数据集中,因数据集 Ⅰ 的背景干扰已在训练中排除,模型表现较好;数据集 Ⅱ 和数据集 Ⅲ 受干扰物和背景的影响,检测精度有所下降,YOLOv5s-PRO模型加强了烟火的深度特征提取,烟火检测精度明显高于YOLOv5s模型,平均检测精度为91.53%. YOLOv5s-PRO的检测速度高于YOLOv5s. 从表1可知,检测速度的提升主要在于替换Focus模块及改进BottleneckCSP模块,使得网络的参数量及计算量减少,网络检测时间减少了0.42 ms. 总的来说,YOLOv5s-PRO模型具有良好的检测精度和检测速度.
对比不同改进方法的mAP值,验证烟火检测效果,结果如图14所示. 其中,YOLOv5s-C是嵌入了CBAM卷积块注意模块的模型,YOLOv5s-NS是对特征提取网络进行优化的模型,YOLOv5s-PRO是融合特征层优化的模型.
图 14
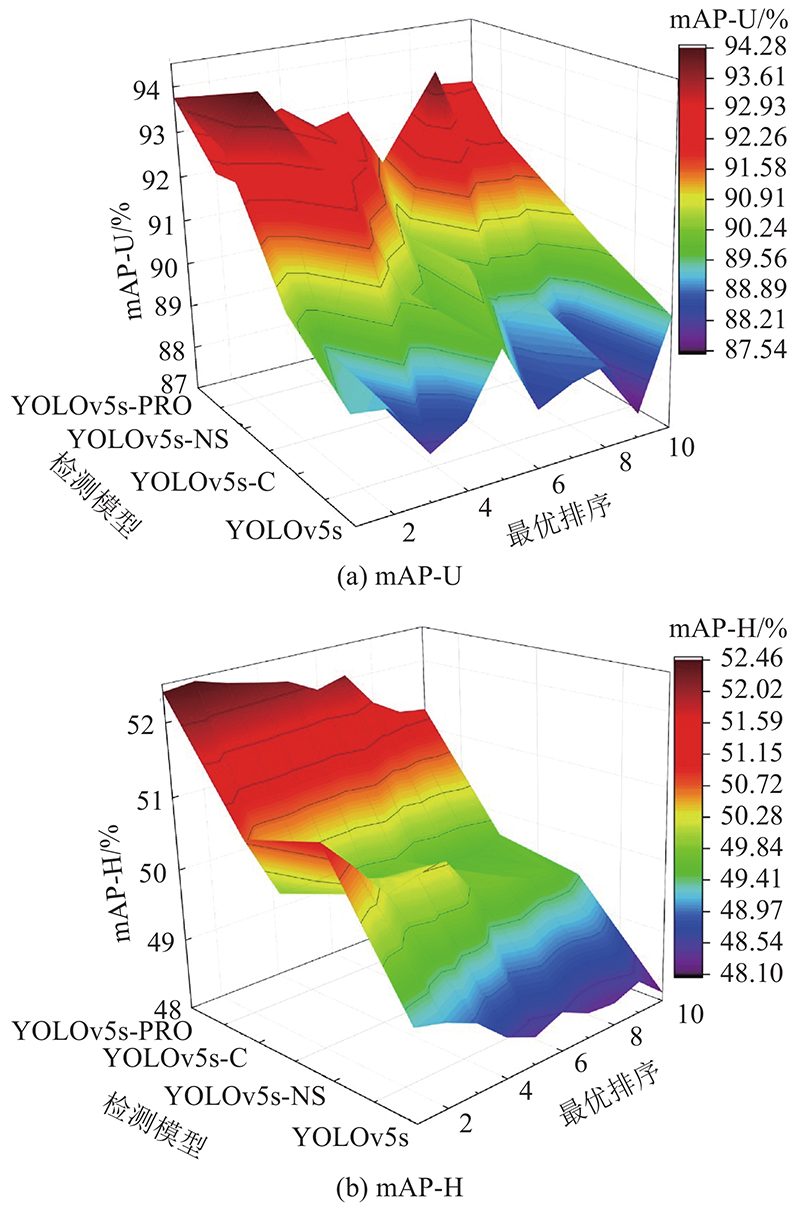
图 14 不同改进方案与YOLOv5s-PRO性能评价
Fig.14 Performance evaluation of improved schemes and YOLOv5s-PRO
裁剪一段发生在重庆真武山隧道的真实隧道火灾视频,对YOLOv5-PRO公路隧道烟火检测模型的检测效果进行测试,部分测试结果如图15所示.
图 15

图 16

图 16 重庆真武山隧道的火灾误检
Fig.16 Fire misdiagnosis of Zhenwu Mountain Tunnel in Chongqing
表 4 真武山隧道火灾视频测试结果的统计
Tab.4
| 类别 | nd | nn | nf | Pd/% | Pa/% |
| 火焰 | 381 | 11 | 7 | 97.11 | 98.16 |
| 烟雾 | 357 | 17 | 0 | 95.24 | 100.00 |
表4中,真武山隧道火灾视频数据中火灾视角在不停地变换,使得火焰检测出现了误检和漏检现象,火焰检测率为97.11%,准确率为98.16%. 视频中火灾的烟雾特征非常浅,轮廓不清晰,检测比较困难,出现漏检现象,烟雾检测率为95.24%,准确率为100.00%. 综上所述,YOLOv5s-PRO公路隧道烟火检测模型在真武山隧道的火灾检测中取得了不错的效果.
4. 结 语
针对目前对火灾烟火检测算法中存在烟火漏检、误检,造成检测率低的情况,改进YOLOv5s模型深层特征提取网络,引入CBAM模块提高烟火表征能力,提升模型对无具体形状烟火检测及多重干扰物下的烟火检测能力. 采用Conv卷积网络替换骨干网络中的Focus结构,在BottleneckCSP模块中减少卷积计算量,提升烟火检测模型的效率. 在损失函数引入Focal Loss函数,解决了样本不均衡的问题,增强了模型的收敛速度. YOLOv5s-PRO算法模型与原YOLOv5s算法相比,不仅提高了检测精度,而且兼顾了模型的检测速度,平均检测精度达到91.53%,单张图像检测仅需6.12 ms,实现公路隧道的烟火实时检测.
参考文献
隧道内横向偏置火源火灾烟气温度特性全尺寸试验研究
[J].DOI:10.3969/j.issn.1001-7372.2020.11.019 [本文引用: 1]
Full-scale experimental study on smoke temperature and fire characteristics occurred at deflected positions in tunnels
[J].DOI:10.3969/j.issn.1001-7372.2020.11.019 [本文引用: 1]
融合多分辨率表征的实时烟雾分割算法
[J].
Real-time smoke segmentation algorithm fused with multi-resolution representation
[J].
公路隧道火灾初期视频火焰检测
[J].DOI:10.3969/j.issn.1001-7372.2018.11.013 [本文引用: 1]
Video-based recognition of early fire flame in road tunnel
[J].DOI:10.3969/j.issn.1001-7372.2018.11.013 [本文引用: 1]
基于ViBe与机器学习的早期火灾检测算法
[J].
Early fire detection algorithm based on ViBe and machine learning
[J].
A new fire detection method using a multi-expert system based on color dispersion, similarity and centroid motion in indoor environment
[J].
基于动静态特征的监控视频火灾检测算法
[J].
Monitoring video fire detection algorithm based on dynamic characteristics and static characteristics
[J].
Autonomous flame detection in videos with a Dirichlet process Gaussian mixture color model
[J].DOI:10.1109/TII.2017.2768530 [本文引用: 1]
时空背景模型下结合多种纹理特征的烟雾检测
[J].DOI:10.7652/xjtuxb201808011 [本文引用: 1]
A smoke detection algorithm with multi-texture feature exploration under a spatio temporal background model
[J].DOI:10.7652/xjtuxb201808011 [本文引用: 1]
基于YUV颜色空间和多特征融合的视频烟雾检测
[J].DOI:10.3969/j.issn.1004-1699.2019.02.014
Video smoke detection based on YUV color space and multiple feature fusion
[J].DOI:10.3969/j.issn.1004-1699.2019.02.014
基于总有界变分的森林火灾烟雾图像检测方法
[J].DOI:10.13382/j.jemi.B2003042 [本文引用: 1]
Smoke image detection method of the forest fire based on total bounded variation
[J].DOI:10.13382/j.jemi.B2003042 [本文引用: 1]
基于深度学习的通用目标检测研究综述
[J].DOI:10.12263/DZXB.20200570 [本文引用: 1]
A survey of generic object detection methods based on deep learning
[J].DOI:10.12263/DZXB.20200570 [本文引用: 1]
Improved multi-scale flame detection method
[J].DOI:10.37188/CJLCD.2020-0221 [本文引用: 1]
Real-time video fire smoke detection by utilizing spatial-temporal ConvNet features
[J].DOI:10.1007/s11042-018-5978-5 [本文引用: 1]
Video fire recognition based on multi-channel convolutional neural network
[J].DOI:10.1088/1742-6596/1634/1/012020
UFS-Net: a unified flame and smoke detection method for early detection of fire in video surveillance applications using CNNs
[J].DOI:10.1016/j.jocs.2022.101638 [本文引用: 1]
基于改进型SSD的视频烟火检测算法
[J].DOI:10.3969/j.issn.1000-386x.2021.12.027 [本文引用: 1]
Video-based fire and smoke detection based on improved SSD
[J].DOI:10.3969/j.issn.1000-386x.2021.12.027 [本文引用: 1]
改进Yolo-v3的视频图像火焰实时检测算法
[J].
A real-time video flame detection algorithm based on improved Yolo-v3
[J].
基于视觉的火灾检测研究
[J].DOI:10.3969/j.issn.1006-8023.2022.01.011 [本文引用: 1]
Fire detection research based on vision
[J].DOI:10.3969/j.issn.1006-8023.2022.01.011 [本文引用: 1]
Detection of coal and gangue based on improved YOLOv5.1 which embedded scSE module
[J].DOI:10.1016/j.measurement.2021.110530
基于YOLOv5s网络的垃圾分类和检测
[J].DOI:10.19554/j.cnki.1001-3563.2021.08.007 [本文引用: 1]
Garbage classification and detection based on YOLOv5s network
[J].DOI:10.19554/j.cnki.1001-3563.2021.08.007 [本文引用: 1]
Improving YOLOv5 with attention mechanism for detecting boulders from planetary images
[J].DOI:10.3390/rs13183776 [本文引用: 1]
采用注意力机制与改进YOLOv5的水下珍品检测
[J].DOI:10.11975/j.issn.1002-6819.2021.18.035 [本文引用: 1]
Detection of underwater treasures using attention mechanism and improved YOLOv5
[J].DOI:10.11975/j.issn.1002-6819.2021.18.035 [本文引用: 1]
A robust fabric defect detection method based on improved RefineDet
[J].DOI:10.3390/s20154260 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}