

在盾构法隧道施工过程中,管片的安装过程分为管片的递送、抓取和拼装3个阶段. 由吊装设备将管片运输至工作区,再抓取放置于拼装区域,最后由管片拼装机完成拼装. 在管片抓取环节,需要人工调整拼装机的径向和轴向油缸,使抓头对准管片完成抓取,效率较低. 采用自动化方法是提升工程效率的首选之策. 确定目标管片的位姿是实现自动化的前提,也是自动化控制的对象. 对于管片的位姿测量,Wada等[1-4]利用激光传感器与机器视觉结合的方法,提升了测量效率. 刘飞香[5]使用多个激光测距仪测量管片的相关参数,推导拼装机的运动状态,完成抓取设备与管片间相对位姿的测量. 朱凯源等[6-7] 通过设置管片外的标志和管片上的靶标,完成管片位置的测量以及管片相对靶标位姿的求解. 高翔等[8-9]使用激光传感器检测管片的几何信息,实现无标记物的位姿测量. 李穗婷[10]使用双目视觉方法对管片螺栓进行测量,直接完成需要被抓取的管片螺栓的位置测量.
在对管片抓取的过程中,使用靶标进行位姿测量时,除了增加设置靶标的时间、人力成本外,增大了靶标与管片间的相对误差. 由于管片递送至工作区后在摆放时不规整,直接对管片进行视觉测量时,需要避免识别到其他工作区的管片,目前的研究仅限于对单一管片进行位姿测量,未考虑管片在工作区的实际情况. 针对上述问题,本文提出针对管片抓取的位置测量方法,利用特征匹配和深度学习算法,直接对需要抓取的管片螺栓进行识别,避免位于工作区其他管片螺栓被误识别的情况. 融合深度相机数据完成管片的三维坐标测量,确定管片螺栓的位置.
1. 实现方法
1.1. 基于SIFT的螺栓特征匹配
利用SIFT算法,可以进行具有尺度不变性、旋转不变性的稳定的特征匹配[16]. 利用不同角度的螺栓图片建立匹配库,使不同角度、距离的管片螺栓都能被匹配.
1)构建图像的多尺度空间. 像素图像的尺度空间
构建尺度空间可以获得不受尺度影响的特征点. 对原始图像采样得到不同尺度图像的特征金字塔,将金字塔相邻的图像相减得到高斯差分,如下:
将图像差值组合,获得高斯金字塔(difference of Gaussian,DoG).
2)DoG金字塔极值点检测. 为了找到极值点,每个像素点需要与金字塔中同一尺度和相邻尺度的相邻点进行对比,最大和最小处为极值点. 金字塔的上、下2层无法比较,通过高斯模糊在上层额外生成3张图像进行比较,可以得到连续的尺度变换.
3)特征点筛选. 对于筛选出的特征点,需要将对比度较低以及边缘响应点中较不稳定的点删除. 对于对比度,需要设置阈值进行筛选. 特征点
由于特征点为极值点,令式(3)的导数为0,可得
将
设置阈值
对于不稳定的边缘响应点,须将其去除. 特征点的海森阵为
式中:
令
式中:
为了消除边缘效应,DoG函数
4)求取特征点主方向. 根据式(1)可知,每个像素点
对于筛选出的特征点,对邻域内像素求取模和方向,在
5)特征点的匹配与目标点的确定. 待匹配图与匹配库中的管片螺栓参考图的匹配效果以欧氏距离衡量,如下所示:
图 1
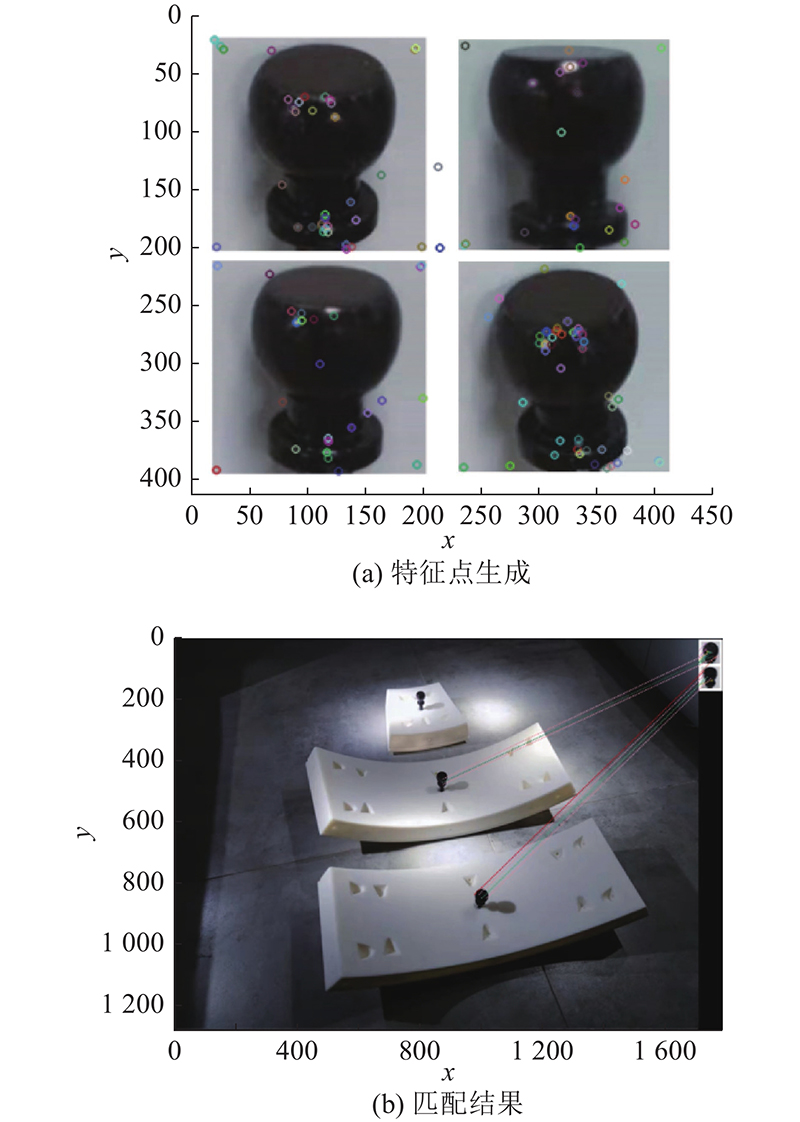
为了测量位置,需要在图像上确定1个位于管片螺栓上的点为目标点,从图像上可以获得该目标点的像素坐标. 在实际匹配时,有时会产生远离正确匹配点的离散点,根据高斯分布
式中:
1.2. 基于深度学习的目标螺栓筛选
在实际的盾构施工中,会有多个管片运送至工作区进行堆放,因此匹配时通常会生成2、3个管片螺栓上的目标点. 除了待抓取管片上的螺栓,也匹配到了其他在工作区的管片螺栓,需要对待抓取管片及其他工作区管片进行区分. 探究将待抓取管片与其他管片区分开的识别算法,研究如何筛选位于待抓取管片上的管片螺栓,获得最终测量的唯一目标点.
图 2
式中:
式中:
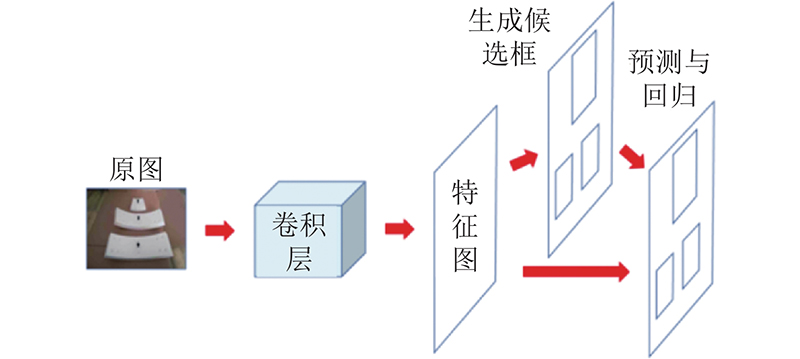
2)基于注意力机制的特征提取网络改进. 当对目标识别的准确率进行检验时,通常以真实框与预测框的交并比是否为0.5作为预测正确的检测标准. 分析采集图像可知,若真实框与预测框的交并比小于0.8,则有可能使得“目标管片”的预测框将其他位于工作区的管片螺栓包含在内,致使匹配到多个管片螺栓,如图3所示. 为了排除其他管片螺栓的影响,需要更加准确地识别框,因此对特征提取网络进行改进,以使模型适应更加严苛的0.8交并比.
图 3
图 3 0.5交并比下误匹配多个管片螺栓
Fig.3 Mismatching of more than 1 segment bolts under 0.5 IOU
图 4

本文使用的Faster-Rcnn算法的主干网络为Resnet50,主要构成为Identity Block. 由于注意力机制不会改变输入特征图的尺寸,仅通过全连接层为通道及图像像素分配权重,注意力机制可以放置在特征提取网络的任意位置. 本文的主干网络中共有4组Identity Block的堆叠,分别在第1组和第4组中的Identity Block中RELU层和输出之间添加混合注意力机制模块CBAM,Identity Block变为如图5所示的结构,识别效果在2.2节中详述.
图 5

图 5 添加注意力机制的Identity Block结构
Fig.5 Structure of Identity Block after adding attention module
1.3. 信息融合位置测量
通过引入注意力机制的Faster-Rcnn算法,结合特征匹配生成测量目标点,可以有效地找到目标管片上螺栓的像素位置. 仅有像素位置只能推断出管片螺栓相对于相机光心坐标系的
图 6
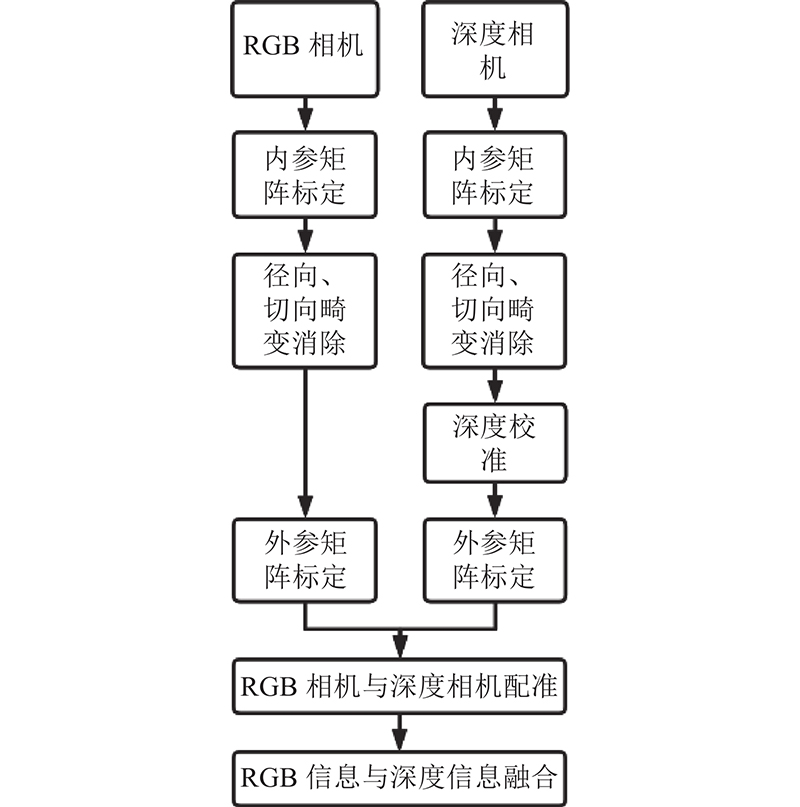
图 6 基于信息融合的管片螺栓位置测量流程
Fig.6 Process of position measurement of segment bolt based on information fusion
1)相机内参标定. 相机成像原理为小孔成像,三维世界的物体经过相机小孔在配置有感光元件的成像平面上映射出倒立的实像. 该实像通过感光元件将光信号转化为电信号,经过转化放大处理得到数字图像,转化关系如下:
式中:世界坐标系下物体点
2)相机外参数标定. 相机的外参数矩阵描述相机在世界坐标系中的位置,关系如下:
式中:
3)相机畸变消除. 在实际的相机拍摄中,镜头会产生径向畸变及切向畸变,致使成像失真,因此需要对畸变进行校正. 校正后的图像点坐标为
式中:
其中
4)深度相机校准. 在进行相机参数标定及畸变消除后,需要对深度相机的深度进行校准,使用线性校准
通过内参矩阵计算出的深度为真值dshift,与测量值dmea一起进行线性回归,可以完成深度信息的校准.
5)信息融合. 所使用的拍摄设备为Kinect相机,由于自带RGB相机的分辨率为
图 7
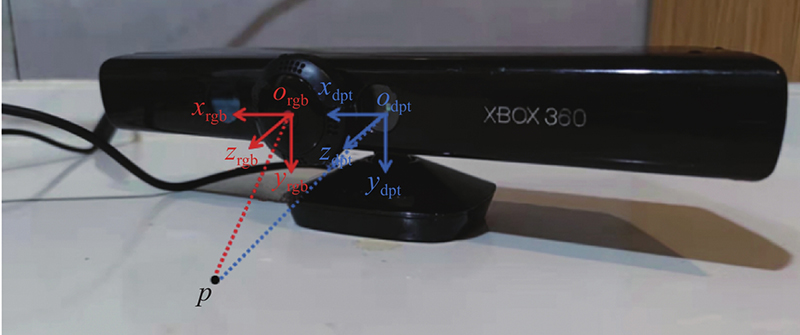
式中:
2. 实验分析
2.1. 图像采集策略
为了在实验室环境下更接近盾构施工的实际条件,采用与实际管片颜色相近的3D打印管片,形状与管片上的孔洞与真实管片完全相同,大小为实际管片的1/20. 对实验环境进行分析,提出图像采集策略.
1)在施工时的隧道中,待抓取的管片都来自于已经拼装完成的隧道中,因此周围环境较单一. 隧道内没有自然光源,须使用光源照明. 随着盾构机的推进,照射在管片上的光照不固定,因此在隔绝自然光的暗室中设置变化的光源,对管片进行照明并采集图像.
2)在隧道中可能由于光噪声的干扰,导致图像不清晰、产生噪声或者管片的某一部分较暗无法识别. 为了获得鲁棒性较强的识别模型,对一部分图像进行添加高斯噪声、椒盐噪声及随机遮挡处理.
3)管片拼装在完成一次砌环时遵循1.2节中所述的拼装顺序,管片吊运装置按照该顺序将管片运送至工作区等待抓取. 在该过程中,管片的放置具有随机性,因此在采集图像时用随机的位姿和不同的顺序放置管片.
综上所述,图像采集策略如图8所示.
图 8

根据以上实验条件,共采集约5 000张图像,使用华为云平台Modelarts的NVIDIA V100显卡进行训练.
2.2. 添加注意力机制识别效果实验分析
将训练集送入神经网络,每批16个样本,在迭代约17次时准确率趋于平稳. 当预测框与真实框的交并比设置为0.5时,随着损失值的下降,准确率达到约95%;当交并比为0.8时,准确率下降至约90.6%. 利用相同的数据集对添加混合注意力机制后的神经网络进行训练,当迭代约20次时准确率趋于稳定,交并比为0.5和0.8时的准确率约为96%和94%,测试集的准确率变化趋势如图9所示. 图中,Ep为迭代次数,Acc为测试集准确率.
图 9
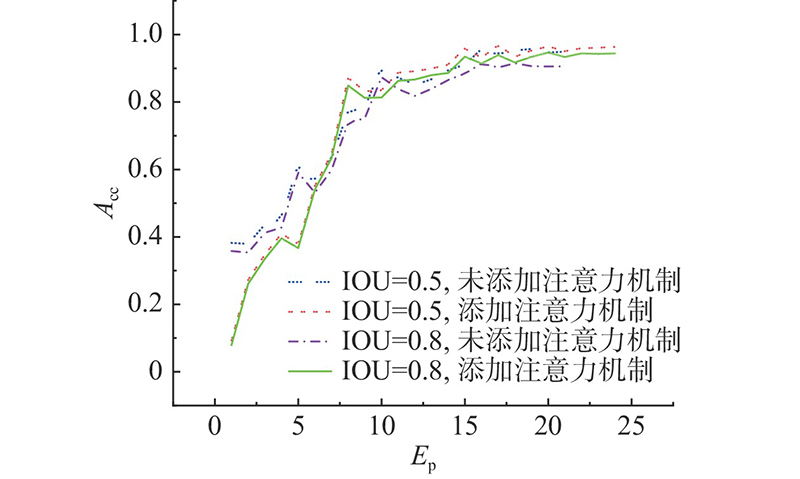
图 9 不同交并比条件下注意力机制对测试集准确率的影响变化
Fig.9 Influence of attention module on accuracy of test set under different IOU conditions
图 10

图 10 添加注意力机制前、后Grad-Cam可视化热图的对比
Fig.10 Comparison of Grad-Cam heat map between before and after adding attention module
当未添加注意力机制时,神经网络在识别“后备管片”时,不仅关注了部分“目标管片”中的区域,还额外关注了一些图像中的无关区域. 在加入注意力机制后,热图显示“后备管片”被给予了更加准确的“注意力”,减少了对无关区域的关注,这从侧面印证了在0.8的交并比下添加注意力机制维持更高准确率的原因.
2.3. 管片螺栓位置测量实验结果的分析
图 11
表 1 管片螺栓的位置测量结果
Tab.1
| 序号 | 坐标实际值/mm | 坐标测量值/mm | 各轴误差/mm |
| 1 | (−150,260,535) | (−151.315, 259.504, 533.467) | (1.315, 0.496, 1.533) |
| 2 | (300,180,710) | (299.407, 178.901, 707.661) | (0.593, 1.099, 2.339) |
| 3 | (−350,340,605) | (−348.159, 342.073, 606.517) | (−1.841, −2.073, −1.517) |
| 4 | (550,420,570) | (552.542, 419.404, 570.113) | (−2.542, 0.596, −0.113) |
| 5 | (−400,220,745) | (−399.669, 221.963, 747.673) | (−0.331, −1.963, −2.673) |
| 6 | (200,140,780) | (199.867, 139.417, 782.735) | (0.133, 0.583, −2.735) |
| 7 | (500,380,675) | (497.884, 381.682, 672.139) | (2.116, −1.682, 2.861) |
| 8 | (−250,100,500) | (−247.947, 98.754, 502.227) | (−2.053, 1.246, −2.227) |
| 9 | (450,300,640) | (448.682, 300.676, 642.410) | (1.318, −0.676, −2.410) |
观察以上测量结果可以发现,测量值在3个轴上的误差均不超过3 mm. 对于本文的抓取装置所适配的锁紧机构,管片螺栓轴线理论上可偏离锁紧机构中心轴的最大距离为5.5 mm,因此可以将管片螺栓纳入抓取范围,该测量方法可以满足管片抓取的需要.
3. 结 语
本文针对管片抓取阶段,提出利用深度学习与特征匹配获取RGB信息并与深度信息融合的管片螺栓位置测量方法,避免了设置靶标的位置误差和管片螺栓误识别. 在特征提取网络部分添加了混合注意力机制,使得识别准确率在高交并比要求下维持在94%左右. 利用Grad-Cam可视化技术,从侧面证明了注意力机制的有效性.
当进行目标物识别时,相对于管片,管片螺栓的体积过小,识别效果远低于管片的识别. 若采用深度学习的方法对管片螺栓进行有效识别,则可以省去特征匹配阶段,直接完成管片螺栓的定位,提高位置测量的效率.
参考文献
Automatic segment erection system for shield tunnels
[J].DOI:10.1163/156855391X00304 [本文引用: 1]
盾构管片拼装机国内外研究现状
[J].
Research status of segment erector in shield tunneling machine at home and abroad
[J].
Automatic segment assembly robot for shield tunneling machine
[J].DOI:10.1111/j.1467-8667.1995.tb00295.x [本文引用: 1]
管片拼装机抓取和拼装智能化研究
[J].
Study on intelligent grab and assemble of tunnel segment erecting robot
[J].
盾构机管片拼装自动控制传感检测系统的设计
[J].
Design of automatic control, sensing and detection system for segment assembly of shield machine
[J].
基于线激光传感器的盾构管片位姿检测方法
[J].
Position and posture detection method of shield segments using line laser sensors
[J].
Faster R-CNN: towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031 [本文引用: 2]
基于多传感器融合的轨道识别方法探究
[J].
Recognition method of railway tracks based on multi-sensor fusion
[J].
基于传感器融合的障碍物轮廓识别方法研究
[J].
Obstacle contour recognition method based on sensor fusion
[J].
Distinctive image features from scale-invariant keypoints
[J].DOI:10.1023/B:VISI.0000029664.99615.94 [本文引用: 1]
A flexible new technique for camera calibration
[J].DOI:10.1109/34.888718 [本文引用: 1]
Grad-CAM: visual explanations from deep networks via gradient-based localization
[J].DOI:10.1007/s11263-019-01228-7 [本文引用: 1]
盾构机管片吊运系统技术综合分析
[J].
Comprehensive analysis of segment lifting system technology of shield machine
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}