[1]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431-3440.
[本文引用: 1]
[2]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// International Conference on Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234-241.
[本文引用: 1]
[3]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2014 , 37 (9 ): 1904 - 1916
[本文引用: 1]
[4]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881-2890.
[5]
GU Z, CHENG J, FU H, et al CE-Net: context encoder network for 2D medical image segmentation
[J]. IEEE Transactions on Medical Imaging , 2019 , 38 (10 ): 2281 - 2292
DOI:10.1109/TMI.2019.2903562
[本文引用: 2]
[6]
WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]// Proceedings of the IEEE conference on computer vision and pattern recognition . Salt Lake City: IEEE, 2018: 7794-7803.
[本文引用: 1]
[7]
XING X, YUAN Y, MENG M Q Zoom in lesions for better diagnosis: attention guided deformation network for WCE image classification
[J]. IEEE Transactions on Medical Imaging , 2020 , 39 (12 ): 4047 - 4059
DOI:10.1109/TMI.2020.3010102
[本文引用: 1]
[8]
LIU R, LIU M, SHENG B, et al NHBS-Net: a feature fusion attention network for ultrasound neonatal hip bone segmentation
[J]. IEEE Transactions on Medical Imaging , 2021 , 40 (12 ): 3446 - 3458
DOI:10.1109/TMI.2021.3087857
[本文引用: 2]
[9]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 40 (4 ): 834 - 848
[本文引用: 1]
[10]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. [2021-08-01]. https://arxiv.org/abs/1706.05587.
[本文引用: 1]
[11]
SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-V4, inception-ResNet and the impact of residual connections on learning [C]// Thirty-first AAAI Conference on Artificial Intelligence . San Francisco: AAAI, 2017: 4278-4284.
[本文引用: 1]
[12]
ZHU X, HU H, LIN S, et al. Deformable convNets V2: more deformable, better results [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 9308-9316.
[本文引用: 1]
[13]
WANG X, JIANG X, DING H, et al Bi-directional dermoscopic feature learning and multi-scale consistent decision fusion for skin lesion segmentation
[J]. IEEE Transactions on Image Processing , 2019 , 29 : 3039 - 3051
[本文引用: 1]
[14]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE conference on computer vision and pattern recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
[15]
高颖琪, 郭松, 李宁, 等 语义融合眼底图像动静脉分类方法
[J]. 中国图象图形学报 , 2020 , 25 (10 ): 2259 - 2270
DOI:10.11834/jig.200187
[本文引用: 1]
GAO Ying-qi, GUO Song, LI Ning, et al Arteriovenous classification method in fundus images based on semantic fusion
[J]. Journal of Image and Graphics , 2020 , 25 (10 ): 2259 - 2270
DOI:10.11834/jig.200187
[本文引用: 1]
[16]
NI Z L, BIAN G B, ZHOU X H, et al. RAUNet: residual attention U-Net for semantic segmentation of cataract surgical instruments [C]// International Conference on Neural Information Processing . Shenzhen: Springer, 2019: 139-149.
[本文引用: 1]
[17]
OKTAY O, SCHLEMPER J, FOLGOC L L, et al. Attention U-Net: learning where to look for the pancreas [EB/OL]. [2021-08-01]. https://arxiv.org/abs/1804.03999.
[本文引用: 1]
[18]
PARK J, WOO S, LEE J Y, et al. BAM: bottleneck attention module [EB/OL]. [2021-08-01]. https://arxiv.org/abs/1807.06514.
[本文引用: 1]
[19]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3-19.
[本文引用: 2]
[20]
GU R, WANG G, SONG T, et al CA-Net: comprehensive attention convolutional neural networks for explainable medical image segmentation
[J]. IEEE Transactions on Medical Imaging , 2020 , 40 (2 ): 699 - 711
[本文引用: 2]
[21]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. [2021-08-01]. https://arxiv.org/abs/2010.11929.
[本文引用: 1]
[22]
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 10012-10022.
[本文引用: 2]
[23]
GUO J, HAN K, WU H, et al. CMT: convolutional neural networks meet vision transformers [EB/OL]. [2021-08-01].https://arxiv.org/abs/2107.06263.
[本文引用: 2]
[24]
CAO H, WANG Y, CHEN J, et al. Swin-Unet: Unet-like pure Transformer for medical image segmentation [EB/OL]. [2021-08-01]. https://arxiv.org/abs/2105.05537.
[本文引用: 1]
[25]
GAO Y, ZHOU M, METAXAS D. UTNet: a hybrid Transformer architecture for medical image segmentation [EB/OL]. [2021-08-01]. https://arxiv.org/abs/2107.00781.
[本文引用: 1]
[26]
CODELLA N C F, GUTMAN D, CELEBI M E, et al. Skin lesion analysis toward melanoma detection: a challenge at the 2017 international symposium on biomedical imaging (ISBI), hosted by the international skin imaging collaboration (ISIC) [C]// 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018) . Washington DC: IEEE, 2018: 168-172.
[本文引用: 1]
[27]
BERNAL J, SANCHEZ J, VILARINO F Towards automatic polyp detection with a polyp appearance model
[J]. Pattern Recognition , 2012 , 45 (9 ): 3166 - 3182
DOI:10.1016/j.patcog.2012.03.002
[本文引用: 1]
[28]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[29]
WU H, PAN J, LI Z, et al Automated skin lesion segmentation via an adaptive dual attention module
[J]. IEEE Transactions on Medical Imaging , 2020 , 40 (1 ): 357 - 370
[本文引用: 1]
[30]
SINHA A, DOLZ J Multi-scale self-guided attention for medical image segmentation
[J]. IEEE Journals on Biomedical and Health Informatics , 2021 , 25 (1 ): 121 - 130
DOI:10.1109/JBHI.2020.2986926
[本文引用: 1]
1
... 卷积神经网络(convolutional neural network, CNN)为医学图像的分割问题带来新的解决方法, 让分割和诊疗的自动化变得更加容易. 分割任务中, 全卷积网络[1 ] (fully convolutional network, FCN)将传统CNN中的全连接层替换为卷积层以实现语义分割. 为了在获得高级语义特征的基础上保留更多的结构信息, U-Net[2 ] 将“编码器-解码器”结构与跳跃连接结合, 使网络在解码过程中融入编码端低级特征, 具有优良的分割性能. ...
1
... 卷积神经网络(convolutional neural network, CNN)为医学图像的分割问题带来新的解决方法, 让分割和诊疗的自动化变得更加容易. 分割任务中, 全卷积网络[1 ] (fully convolutional network, FCN)将传统CNN中的全连接层替换为卷积层以实现语义分割. 为了在获得高级语义特征的基础上保留更多的结构信息, U-Net[2 ] 将“编码器-解码器”结构与跳跃连接结合, 使网络在解码过程中融入编码端低级特征, 具有优良的分割性能. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2014
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
CE-Net: context encoder network for 2D medical image segmentation
2
2019
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
... [5 ]利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
Zoom in lesions for better diagnosis: attention guided deformation network for WCE image classification
1
2020
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
NHBS-Net: a feature fusion attention network for ultrasound neonatal hip bone segmentation
2
2021
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
... [8 ]利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
1
2017
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
Bi-directional dermoscopic feature learning and multi-scale consistent decision fusion for skin lesion segmentation
1
2019
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
语义融合眼底图像动静脉分类方法
1
2020
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
语义融合眼底图像动静脉分类方法
1
2020
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
2
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
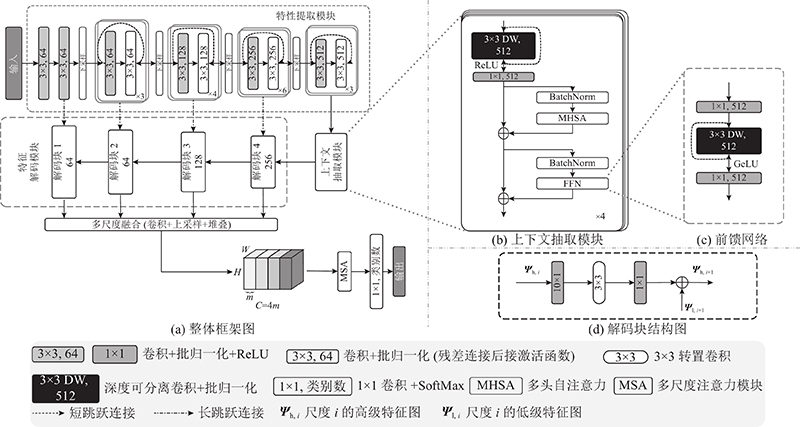
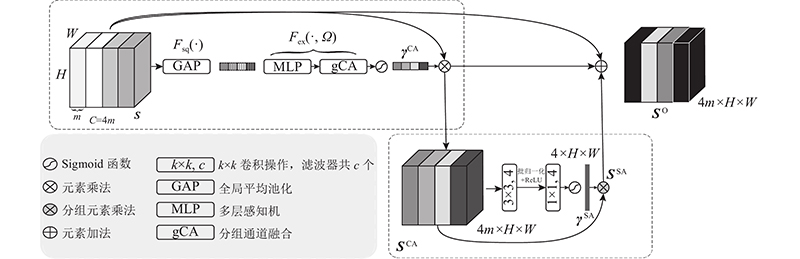
... “编码器−解码器”结构包含多个不同的尺度, 利用多个尺度的特征图学习不同尺度间关系, 突出各个尺度上与分割目标相关的特征将有利于提升分割性能. 基于Woo等[19 -20 ] 的方法, 本研究利用多尺度注意力自动学习每个尺度特征图的空间权重和通道权重, 使网络具备适应不同大小病灶的泛化能力, 其框架结构如图2 所示. 将特征解码模块(扩张路径)各尺度上的特征图分别进行卷积和上采样操作以统一大小. 以图1 中特征解码模块的4个尺度为例, 每个尺度经过卷积、上采样操作后都得到 $ m \times H \times W $ m 为每个尺度对应的处理后的特征图通道数. 每个尺度的特征图记为 $ {{\boldsymbol{S}}_i}(i = 1,2,3,4) $ $ {{\boldsymbol{S}}_i} $ $ {\boldsymbol{S}} \in {{{\bf{R}}}^{4m \times H \times W}} $ . ...
CA-Net: comprehensive attention convolutional neural networks for explainable medical image segmentation
2
2020
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
... “编码器−解码器”结构包含多个不同的尺度, 利用多个尺度的特征图学习不同尺度间关系, 突出各个尺度上与分割目标相关的特征将有利于提升分割性能. 基于Woo等[19 -20 ] 的方法, 本研究利用多尺度注意力自动学习每个尺度特征图的空间权重和通道权重, 使网络具备适应不同大小病灶的泛化能力, 其框架结构如图2 所示. 将特征解码模块(扩张路径)各尺度上的特征图分别进行卷积和上采样操作以统一大小. 以图1 中特征解码模块的4个尺度为例, 每个尺度经过卷积、上采样操作后都得到 $ m \times H \times W $ m 为每个尺度对应的处理后的特征图通道数. 每个尺度的特征图记为 $ {{\boldsymbol{S}}_i}(i = 1,2,3,4) $ $ {{\boldsymbol{S}}_i} $ $ {\boldsymbol{S}} \in {{{\bf{R}}}^{4m \times H \times W}} $ . ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
2
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
... 基于Liu等[22 ] 的方法, 为每个注意力头设置 $ (2h - 1) \times (2w - 1) $ $ {{\boldsymbol{P}}^n} $ $ (2h - 1) \times (2w - 1) $
2
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
... 在Transformer中, 前馈网络一般采用2个线性层. 第1个线性层将维度扩充为原来的4倍, 采用GeLU等函数作为激活函数, 第2个线性层用来恢复维度. 结合Guo等[23 ] 的设计, 本研究采用的前馈网络由1×1卷积、3×3深度可分离卷积、1×1卷积组成, 在每个卷积层后都进行批归一化操作, 并将GeLU作为激活函数; 在深度可分离卷积处引入跳连结构, 以促进梯度的跨层传播能力. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 由于卷积操作局部感知及权值共享的特性, 基于CNN的分割模型缺乏长距离依赖关系的建模能力和灵活的空间感知能力. 不少学者研究与改进CNN的模块、结构, 旨在提高医学图像分割性能. 例如采用自然图像处理中的空间金字塔[3 -5 ] 以及非局部块[6 -8 ] 的思想来获得更好的上下文特征表示. DeepLab系列[9 -10 ] 利用空洞金字塔池化和Multi-Grid策略、Gu等[5 ] 利用Inception结构[11 ] 和多核池化获取更丰富的多尺度和上下文信息. Xing等[7 ] 将可变形卷积[12 ] 与非局部块结合, 为后续模块提供了更为可靠的特征图. Wang等[13 ] 利用双向皮肤镜特征学习模块充分融合不同尺度的特征生成了丰富的特征表示. 学者们还从注意力的角度出发, 给特征图中的重要通道或位置自适应地赋以较大权重来突出重点并抑制噪声以提高分割性能. 通道注意力通过学习通道间的关联程度为各通道赋予对应权重, 其中“挤压−激励[14 ] (squeeze and excitation, SE)”架构被大量用于分割任务中. 例如SFUNet[15 ] 融合解码器各层级的输出特征图并应用SE修正特征图, 提高了眼底动静脉分割的准确度. RAUNet[16 ] 使用基于通道注意力机制的增强注意力模块来强调编码端低级特征图的有用通道, 使得该低级特征图能与解码端的高级特征图更可靠地融合. 类似地, 空间注意力通过为各像素赋予学习到的不同权重来调整特征图. 例如Attention UNet[17 ] 在跳跃连接处综合利用解码端和编码端的高低级特征图, 生成关于低级特征图每个像素的门控信息. 不少研究注重联合多种注意力来提高任务性能. 例如BAM[18 ] 和CBAM[19 ] 在通道和空间维度上独立地精炼卷积特征, CA-Net[20 ] 全面结合各种注意力机制以提高分割任务的准确性和解释性. 此外, 自注意力可以有效克服上下文信息提取能力有限的问题. 例如Liu等[8 ] 利用非局部块的思想融合全局信息. Transformer在自然语言处理(natural language processing, NLP)中取得巨大成功, 其中的多头自注意力机制通过上下文聚合算子实现成对的元素交互, 具有捕获远程关联特征的能力. 学者们先后提出ViT[21 ] 、Swin Transformer[22 ] 、CMT[23 ] 等来解决视觉任务问题, 在分割任务上Cao等[24 ] 提出基于纯Transformer结构的分割网络Swin-Unet, Gao等[25 ] 结合Transformer和卷积多方面的优势和不足, 提出UTNet, 为解决医学图像分割问题扩展了思路. ...
1
... 本研究综合考虑上下文和注意力的关键内容和技术, 提出融合多尺度和多头注意力的分割网络框架(MS2 Net). MS2 Net由特征提取模块、上下文抽取模块(context extractor, CE)、多尺度注意力(multi-scale attention, MSA)和特征解码模块组成, 旨在提升U-Net在医疗图像上的分割效果. 本研究将在ISBI 2017[26 ] 和CVC-ColonDB[27 ] 数据集上测试MS2 Net的分割性能. ...
Towards automatic polyp detection with a polyp appearance model
1
2012
... 本研究综合考虑上下文和注意力的关键内容和技术, 提出融合多尺度和多头注意力的分割网络框架(MS2 Net). MS2 Net由特征提取模块、上下文抽取模块(context extractor, CE)、多尺度注意力(multi-scale attention, MSA)和特征解码模块组成, 旨在提升U-Net在医疗图像上的分割效果. 本研究将在ISBI 2017[26 ] 和CVC-ColonDB[27 ] 数据集上测试MS2 Net的分割性能. ...
1
... 特征提取模块用于提取输入医学图像的高层语义信息, 通过CNN连续的卷积和池化操作逐步降低特征图的分辨率, 产生有关图像局部区域的抽象特征表示. U-Net每个编码块包含2个卷积层和1个最大池化层. MS2 Net采用ResNet34[28 ] 作为特征提取模块, 将ResNet起始步长为2的7×7卷积替换为2个连续步长为1的3×3卷积, 使得特征提取模块整体的下采样率为16. 结合迁移学习方法, 本研究使用在大规模数据集ImageNet上预训练的模型初始化特征提取模块中的部分参数. 与随机初始化相比, 迁移学习使网络能够更快地找到最优解, 提高模型的收敛速度. ...
Automated skin lesion segmentation via an adaptive dual attention module
1
2020
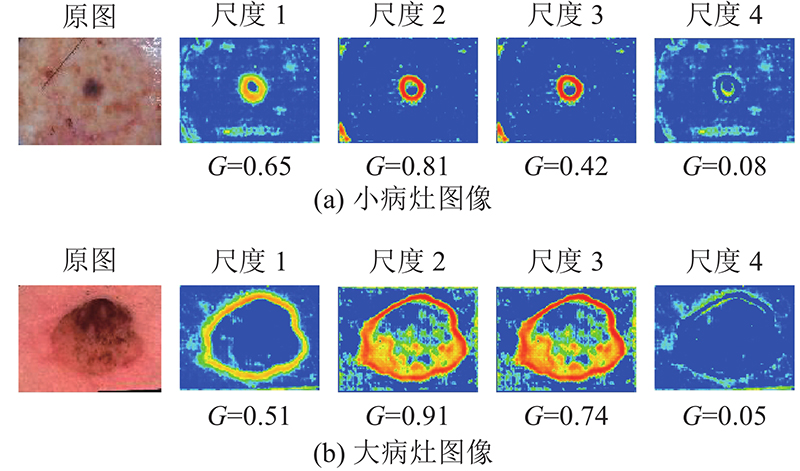
... 式中: P 为预测标签, G 为真实的标签, TP为预测正确且预测为正类的像素数量, TN为预测正确且预测为负类的像素数量, FP为预测错误且预测为正类的像素数量, FN为预测错误且预测为负类的像素数量. JA、DI指标侧重小目标的评价, 分割目标越小, 其越敏感; ACC、SEN和SPE用来度量分割的准确性, 评估的目的是判断相关像素是否被正确分类; TJI是JA的带阈值版本, 参考文献[29 ]将最小阈值设置为0.65. ...
Multi-scale self-guided attention for medical image segmentation
1
2021
... 分别利用直接融合、SE、CBAM和MS-Dual-Guided[30 ] 等方式对各层级解码端输出的特征图进行融合, 并与多尺度注意力进行比较分析, 结果如表8 所示. 结果表明, 多尺度注意力相较于其他融合策略有更优的表现. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}