[1]
LIU W, WEN Y, YU Z, et al. Sphere face: deep hypersphere embedding for face recognition [C]// Proceedings of the Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 6738-6746.
[本文引用: 1]
[2]
DENG J K, GUO J, XUE N N, et al. Arcface: additive angular margin loss for deep face recognition [C]// Proceedings of the Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4685-4694.
[本文引用: 2]
[3]
WANG F, CHENG L, LIU W Additive margin Soft-max for face verification
[J]. IEEE Signal Processing Letters , 2018 , 25 (7 ): 926 - 930
DOI:10.1109/LSP.2018.2822810
[本文引用: 2]
[4]
JIQUAN N, CHEN Z H, PANG W, et al. Learning deep energy models [C]// Proceedings of the 28th International Conference on Machine Learning, Washington: Omnipress, 2011: 1105-1112.
[本文引用: 2]
[5]
TAESUP K , YOSHUA B. Deep directed generative models with energy-based probability estimation [C]// Proceedings of the European Conference of Computer Vision . Amsterdam: Springer, 2016: 123-130.
[本文引用: 1]
[6]
YANN L, SUMIT C, RAIA H. A tutorial on energy-based learning [M]// Predicting structured data. Boston: MIT Press, 2006.
[本文引用: 2]
[7]
RITHESH K, ANIRUDH G, AARON C, et al. Maximum entropy generators for energy based models [C]// Proceedings of the International Conference on Computer Vision . Seoul: IEEE, 2019: 1701-1711.
[本文引用: 1]
[8]
LIU W T, WANG X Y, OWENS J. Energy-based out-of-distribution detection [C]// Proceedings of the Neural Information Processing System . Canada: IEEE, 2020: 112-123.
[本文引用: 2]
[9]
ZHOU K Y, YANG Y X, CAVALLARO A. Omni-scale feature learning for person re-identification [C]// Proceedings of the International Conference on Computer Vision . Seoul: IEEE, 2019: 3701-3711.
[本文引用: 1]
[10]
ZHENG L, SHEN L Y, TIAN L. Scalable person re-identification: a benchmark [C]// Proceedings of the Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 1116-1124.
[本文引用: 1]
[11]
RISTANI E, SOLERA F, ZOU R, et al. Performance measures and a data set for multi-target, multi-camera tracking [C]// Proceedings of the European Conference of Computer Vision . Amsterdam: Springer, 2016: 17-35.
[本文引用: 1]
[12]
WEI L H, ZHANG S L, GAO W, et al. Person transfer gan to bridge domain gap for person re-identification [C]// Proceedings of the Computer Vision and Pattern Recognition . Utah: IEEE, 2018: 79-88.
[本文引用: 1]
[13]
LIU X C, LIU W, MEI T. A deep learning-based approach to progressive vehicle re-identification for urban surveillance [C]// Proceedings of the European Conference of Computer Vision . Amsterdam: Springer, 2016: 123-130.
[本文引用: 1]
[14]
LIU H Y, TIAN Y H, WANG Y W. Deep relative distance learning: tell the difference between similar vehicles [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Nevada: IEEE, 2016: 2167-2175.
[本文引用: 1]
[15]
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Nevada: IEEE, 2016: 116-124.
[本文引用: 1]
[16]
WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]// Proceedings of the Computer Vision and Pattern Recognition . Utah: IEEE, 2018: 7794-7803.
[本文引用: 2]
[17]
WEN Y, ZHANG K, LI Z. A discriminative feature learning approach for deep face recognition [C]// Proceedings of the European Conference of Computer Vision . Amsterdam: Springer, 2016: 23-30.
[本文引用: 1]
[18]
ALEXANDER H, LUCAS B, BASTIAN L. In defense of the triplet loss for person re-identification [C]// Proceedings of the International Conference on Computer Vision . Seoul: Springer, 2018: 1132-1139.
[本文引用: 1]
[19]
ZHONG Z, ZHENG L, ZHENG Z D, et al Camstyle: a novel data augmentation method for person re-identification
[J]. IEEE Transactions on Image Processing , 2019 , 28 (3 ): 1176 - 1190
DOI:10.1109/TIP.2018.2874313
[本文引用: 3]
[20]
QIAN X L, FU Y W, XIANG T, et al. Pose-normalized image generation for person re-identification [C]// Proceedings of the European Conference of Computer Vision . Munich: Springer, 2018: 1123-1132.
[本文引用: 2]
[21]
WANG G S, YUAN Y F, CHEN X, et al. Learning discriminative features with multiple granularities for person re-identification [C]// Proceedings of the ACM Multimedia Conference on Multimedia Conference . Seoul: ACM, 2018: 1123-1132.
[本文引用: 2]
[22]
ZHENG F, DENG C, SUN X, et al. Pyramidal person re-identification via multi-loss dynamic training [C]// Proceedings of the Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 134-143.
[本文引用: 2]
[23]
CHEN T S, XU M X, HUI X L, et al. Learning semantic-specific graph representation for multi-label image recognition [C]// Proceedings of the International Conference on Computer Vision . Seoul: Springer, 2019: 2132-2139.
[本文引用: 1]
[24]
SUN Y F, ZHENG L, YANG Y. Beyond part models: person retrieval with refined part pooling and a strong convolutional baseline [C]// Proceedings of the European Conference of Computer Vision . Munich: Springer, 2018: 25-32.
[本文引用: 2]
[25]
KAKAYEH M M, BASRARN E. Human semantic parsing for person re-identification [C]// Proceedings of the Computer Vision and Pattern Recognition . Utah: IEEE, 2018: 99--107.
[本文引用: 1]
[26]
LEI Q, JING H, LEI W, et al. Maskreid: a mask based deep ranking neural network for person re-identification [C]// Proceedings of the International Conference of Multimedia Exposition . Shanghai: IEEE, 2019: 1138-1145.
[本文引用: 1]
[27]
FAN X, LUO H, ZHANG X, et al. SCPNet: spatial-channel parallelism network for joint holistic and partial person re-identification [C]// Proceedings of the Asian Conference of Computer Vision . Kyoto: IEEE, 2019: 2351-2359.
[本文引用: 1]
[28]
LI W, ZHU X T, GONG S G. Harmonious attention network for person re-identification [C]// Proceedings of the Computer Vision and Pattern Recognition . Utah: IEEE, 2018: 1324—1332.
[本文引用: 2]
[29]
SUN Y F, ZHENG L, DENG W J, et al. SVDNet for pedestrian retrieval[C]// Proceedings of the Computer Vision and Pattern Recognition . Utah: IEEE, 2018: 99-107.
[本文引用: 1]
[30]
HE S, LUO H, WANG P C, et al. TransReID: transformer-based object re-identification [C]// Proceedings of the Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 151-159.
[本文引用: 2]
[31]
ZHONG Z, ZHENG L, CAO D L, et al. Re-ranking person re-identification with k-reciprocal encoding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Hawaii: IEEE, 2017: 345-352.
[本文引用: 1]
[32]
LIU X C, LIU W, MEI T, et al. A deep learning-based approach to progressive vehicle re-identification for urban surveillance [C]// Proceedings of the European Conference of Computer Vision . Amsterdam: Springer, 2016: 123-130.
[本文引用: 1]
[33]
CHU R H, SUN Y F, LI Y D, et al. Vehicle re-identification with viewpoint aware metric learning [C]// Proceedings of the International Conference on Computer Vision . Seoul: Springer, 2019: 1132-1139.
[本文引用: 1]
[34]
LIU X B, ZHANG S L, HUANG Q M, et al. Ram: a region-aware deep model for vehicle re-identification [C]// Proceedings of the International Conference of Multimedia Exposition . San Diego: IEEE, 2018: 138-145.
[本文引用: 1]
[35]
ZHOU Y, SHAO L. Vehicle re-identification by adversarial bi-directional LSTM network [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision . Salt Lake City: IEEE, 2018: 1123-1132.
[本文引用: 1]
[36]
ZHOU Y, SHAO L. Viewpoint-aware attentive multi-view inference for vehicle re-identification [C]// Proceedings of the Computer Vision and Pattern Recognition . Utah: IEEE, 2018: 324-332.
[本文引用: 1]
[37]
LIU X C, LIU W, MEI T, et al PROVID: progressive and multimodal vehicle reidentification for large-scale urban surveillance
[J]. IEEE Transactions on Multimedia , 2018 , 20 (3 ): 645 - 658
DOI:10.1109/TMM.2017.2751966
[本文引用: 1]
[38]
KHORRAMSHAHI P, KUMAR A, PERI N, et al. A dual-path model with adaptive attention for vehicle re-identification [C]// Proceedings of the International Conference on Computer Vision . Seoul: Springer, 2019: 132-139.
[本文引用: 1]
[39]
ZHU J Q, ZENG H Q, HUANG J C, et al Vehicle re-identification using quadruple directional deep learning features
[J]. IEEE Transactions on Intelligent Transportation Systems , 2019 , 21 (1 ): 1 - 11
[本文引用: 1]
[40]
HE B, LI J, ZHAO Y, et al. Part-regularized near-duplicate vehicle re-identification [C]// Proceedings of the Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 154-163.
[本文引用: 1]
[41]
BAI Y, LOU Y H, GAO F, et al Group-sensitive triplet embedding for vehicle re-identification
[J]. IEEE Transaction on Multimedia , 2018 , 20 (9 ): 2385 - 2399
DOI:10.1109/TMM.2018.2796240
[本文引用: 1]
1
... 近些年来,随着深度学习的发展, 复杂的卷积神经网络及注意力模型极大地促进了该领域的发展. 对于网络训练的损失函数, Soft-max[1 ] 是该领域不可替代的方案. Soft-max形式简单, 可以较好地区分不同类别, 但是不能保证每个类别特征的高内聚性. 超球体嵌入方法[2 ] 具有良好的空间可解释性, 将样本特征投射到超球面上,较好地区分不同类别. 为了实现同类样本的内聚性, 角度边距[3 ] 方法使得同类样本之间的夹角更小, 异类之间的夹角大于一定的阈值. 上述方法均取得了较好的目标再识别效果, 但是特征区分度较低,限制了目标再识别的精度进一步提升. 为了实现区分度更好的目标再识别, 三元组损失函数往往和Soft-max集成到一起,以训练神经网络. 多种损失函数一起训练神经网络的方法是目前该领域较多采用的策略. 多种损失函数融合带来新的挑战, 一方面,样本采样过程较复杂,训练效率较低;另一方面,多种损失函数在训练过程中存在不一致的情况,即一种损失函数增大而另一种损失函数减小,如何给它们赋以恰当的权重是较难解决的问题. ...
2
... 近些年来,随着深度学习的发展, 复杂的卷积神经网络及注意力模型极大地促进了该领域的发展. 对于网络训练的损失函数, Soft-max[1 ] 是该领域不可替代的方案. Soft-max形式简单, 可以较好地区分不同类别, 但是不能保证每个类别特征的高内聚性. 超球体嵌入方法[2 ] 具有良好的空间可解释性, 将样本特征投射到超球面上,较好地区分不同类别. 为了实现同类样本的内聚性, 角度边距[3 ] 方法使得同类样本之间的夹角更小, 异类之间的夹角大于一定的阈值. 上述方法均取得了较好的目标再识别效果, 但是特征区分度较低,限制了目标再识别的精度进一步提升. 为了实现区分度更好的目标再识别, 三元组损失函数往往和Soft-max集成到一起,以训练神经网络. 多种损失函数一起训练神经网络的方法是目前该领域较多采用的策略. 多种损失函数融合带来新的挑战, 一方面,样本采样过程较复杂,训练效率较低;另一方面,多种损失函数在训练过程中存在不一致的情况,即一种损失函数增大而另一种损失函数减小,如何给它们赋以恰当的权重是较难解决的问题. ...
... 为了验证本文方法在不同网络结构上的通用性, 网络分别替换为ResNet50[15 ] 、ResNet50-NL(增加了Non-Local[16 ] 模块),测试目标再识别的性能差异. 对于每种基础网络, 将其他损失函数和本文方法进行比较, 验证本文方法相对于其他损失函数的优势. 将本文方法与Soft-max、AM-Soft-max[3 ] 、 Arc-Soft-max[2 ] 、Soft-max+Center[17 ] 及Soft-max+Triplet[18 ] 方法进行Rank1和mAP性能比较. 实验采用的数据集为Market1501. ...
Additive margin Soft-max for face verification
2
2018
... 近些年来,随着深度学习的发展, 复杂的卷积神经网络及注意力模型极大地促进了该领域的发展. 对于网络训练的损失函数, Soft-max[1 ] 是该领域不可替代的方案. Soft-max形式简单, 可以较好地区分不同类别, 但是不能保证每个类别特征的高内聚性. 超球体嵌入方法[2 ] 具有良好的空间可解释性, 将样本特征投射到超球面上,较好地区分不同类别. 为了实现同类样本的内聚性, 角度边距[3 ] 方法使得同类样本之间的夹角更小, 异类之间的夹角大于一定的阈值. 上述方法均取得了较好的目标再识别效果, 但是特征区分度较低,限制了目标再识别的精度进一步提升. 为了实现区分度更好的目标再识别, 三元组损失函数往往和Soft-max集成到一起,以训练神经网络. 多种损失函数一起训练神经网络的方法是目前该领域较多采用的策略. 多种损失函数融合带来新的挑战, 一方面,样本采样过程较复杂,训练效率较低;另一方面,多种损失函数在训练过程中存在不一致的情况,即一种损失函数增大而另一种损失函数减小,如何给它们赋以恰当的权重是较难解决的问题. ...
... 为了验证本文方法在不同网络结构上的通用性, 网络分别替换为ResNet50[15 ] 、ResNet50-NL(增加了Non-Local[16 ] 模块),测试目标再识别的性能差异. 对于每种基础网络, 将其他损失函数和本文方法进行比较, 验证本文方法相对于其他损失函数的优势. 将本文方法与Soft-max、AM-Soft-max[3 ] 、 Arc-Soft-max[2 ] 、Soft-max+Center[17 ] 及Soft-max+Triplet[18 ] 方法进行Rank1和mAP性能比较. 实验采用的数据集为Market1501. ...
2
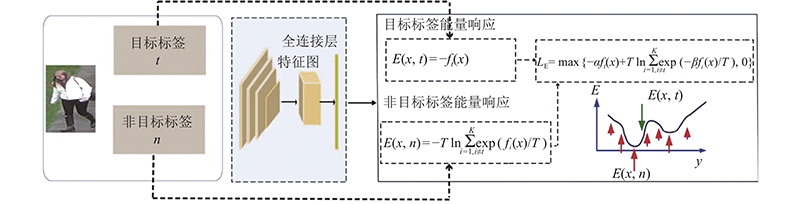
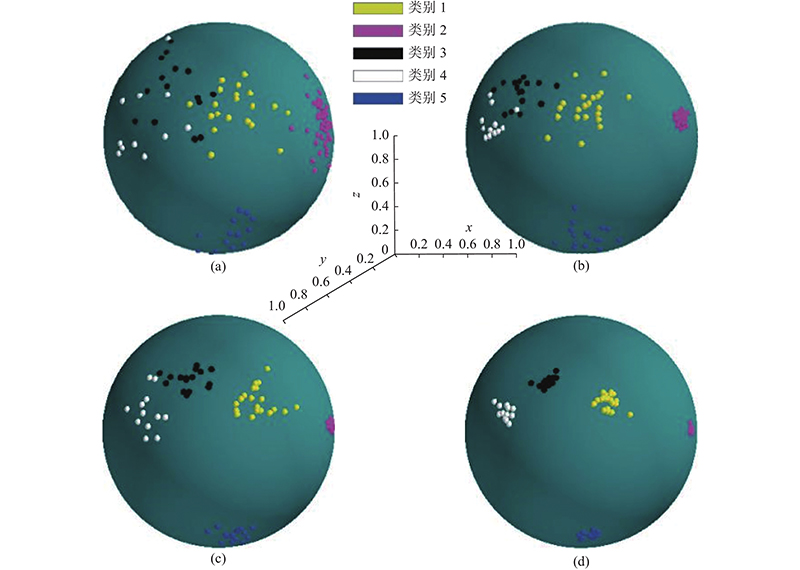
... 本文提出可以提高训练效率、识别精度优于Soft-max和Triplet混合损失的方法. 能量模型[4 -8 ] 是生成模型, 可以很好地对样本特征的概率空间密度进行表达. 在异常点检测、目标分类校准及神经网络模型样本对抗攻击等方面, 能量模型表现出了较优异的性能. 能量模型是对样本特征空间更本质的表述[6 ] , 是对样本特征空间概率密度的直接表示. 通过计算样本的目标响应和非目标响应之间的能量差异, 能量模型定义基于对比能量的损失函数. 该损失函数在训练过程中不需要通过固定采样类别N 和每类样本数K 生成训练集样本对, 只需要随机采样, 可以成倍地提高训练效率. 本文方法可以使得相同类别样本在特征空间中更加聚集而不同类别的样本在特征空间中距离更远, 以提高目标再识别的精度. ...
... 在深度学习模型流行之前, 能量模型作为一种生成模型被深入研究[4 ] . 能量模型将特征空间中概率分布较高的区域定义为低能量区域,低概率区域为高能量区域. 由于能量模型在计算过程中须确定特征空间中的能量,即概率密度, 而该数值的计算一般须借助蒙特卡洛采样完成, 所以复杂的计算限制了蒙特卡洛方法在机器学习领域的进一步发展和应用. Taesup等[5 -6 ] 提出辅助深度模型及摊派渐进采样策略,更好地计算能量模型中的概率密度. 由于能量模型直接对应特征空间中的概率分布密度及逐渐完善的样本采样策略, 能量模型近些年来得到越来越多的关注. Rithesh等[7 ] 将能量模型的定义进一步具体化, 把高维特征空间中的一个点表达为一个标量值, 称为能量. 能量模型和概率密度函数相对应, 一个点的能量和该点的概率密度函数值负相关, 能量越低,密度越高.该概率密度函数为吉布斯分布: ...
1
... 在深度学习模型流行之前, 能量模型作为一种生成模型被深入研究[4 ] . 能量模型将特征空间中概率分布较高的区域定义为低能量区域,低概率区域为高能量区域. 由于能量模型在计算过程中须确定特征空间中的能量,即概率密度, 而该数值的计算一般须借助蒙特卡洛采样完成, 所以复杂的计算限制了蒙特卡洛方法在机器学习领域的进一步发展和应用. Taesup等[5 -6 ] 提出辅助深度模型及摊派渐进采样策略,更好地计算能量模型中的概率密度. 由于能量模型直接对应特征空间中的概率分布密度及逐渐完善的样本采样策略, 能量模型近些年来得到越来越多的关注. Rithesh等[7 ] 将能量模型的定义进一步具体化, 把高维特征空间中的一个点表达为一个标量值, 称为能量. 能量模型和概率密度函数相对应, 一个点的能量和该点的概率密度函数值负相关, 能量越低,密度越高.该概率密度函数为吉布斯分布: ...
2
... 本文提出可以提高训练效率、识别精度优于Soft-max和Triplet混合损失的方法. 能量模型[4 -8 ] 是生成模型, 可以很好地对样本特征的概率空间密度进行表达. 在异常点检测、目标分类校准及神经网络模型样本对抗攻击等方面, 能量模型表现出了较优异的性能. 能量模型是对样本特征空间更本质的表述[6 ] , 是对样本特征空间概率密度的直接表示. 通过计算样本的目标响应和非目标响应之间的能量差异, 能量模型定义基于对比能量的损失函数. 该损失函数在训练过程中不需要通过固定采样类别N 和每类样本数K 生成训练集样本对, 只需要随机采样, 可以成倍地提高训练效率. 本文方法可以使得相同类别样本在特征空间中更加聚集而不同类别的样本在特征空间中距离更远, 以提高目标再识别的精度. ...
... 在深度学习模型流行之前, 能量模型作为一种生成模型被深入研究[4 ] . 能量模型将特征空间中概率分布较高的区域定义为低能量区域,低概率区域为高能量区域. 由于能量模型在计算过程中须确定特征空间中的能量,即概率密度, 而该数值的计算一般须借助蒙特卡洛采样完成, 所以复杂的计算限制了蒙特卡洛方法在机器学习领域的进一步发展和应用. Taesup等[5 -6 ] 提出辅助深度模型及摊派渐进采样策略,更好地计算能量模型中的概率密度. 由于能量模型直接对应特征空间中的概率分布密度及逐渐完善的样本采样策略, 能量模型近些年来得到越来越多的关注. Rithesh等[7 ] 将能量模型的定义进一步具体化, 把高维特征空间中的一个点表达为一个标量值, 称为能量. 能量模型和概率密度函数相对应, 一个点的能量和该点的概率密度函数值负相关, 能量越低,密度越高.该概率密度函数为吉布斯分布: ...
1
... 在深度学习模型流行之前, 能量模型作为一种生成模型被深入研究[4 ] . 能量模型将特征空间中概率分布较高的区域定义为低能量区域,低概率区域为高能量区域. 由于能量模型在计算过程中须确定特征空间中的能量,即概率密度, 而该数值的计算一般须借助蒙特卡洛采样完成, 所以复杂的计算限制了蒙特卡洛方法在机器学习领域的进一步发展和应用. Taesup等[5 -6 ] 提出辅助深度模型及摊派渐进采样策略,更好地计算能量模型中的概率密度. 由于能量模型直接对应特征空间中的概率分布密度及逐渐完善的样本采样策略, 能量模型近些年来得到越来越多的关注. Rithesh等[7 ] 将能量模型的定义进一步具体化, 把高维特征空间中的一个点表达为一个标量值, 称为能量. 能量模型和概率密度函数相对应, 一个点的能量和该点的概率密度函数值负相关, 能量越低,密度越高.该概率密度函数为吉布斯分布: ...
2
... 本文提出可以提高训练效率、识别精度优于Soft-max和Triplet混合损失的方法. 能量模型[4 -8 ] 是生成模型, 可以很好地对样本特征的概率空间密度进行表达. 在异常点检测、目标分类校准及神经网络模型样本对抗攻击等方面, 能量模型表现出了较优异的性能. 能量模型是对样本特征空间更本质的表述[6 ] , 是对样本特征空间概率密度的直接表示. 通过计算样本的目标响应和非目标响应之间的能量差异, 能量模型定义基于对比能量的损失函数. 该损失函数在训练过程中不需要通过固定采样类别N 和每类样本数K 生成训练集样本对, 只需要随机采样, 可以成倍地提高训练效率. 本文方法可以使得相同类别样本在特征空间中更加聚集而不同类别的样本在特征空间中距离更远, 以提高目标再识别的精度. ...
... 式中:y 为样本x 所对应的真实类别标签. 式(2)中省略了f . 上述能量函数称为亥姆霍兹能量函数[8 ] . x 对于目标类别响应的能量为 ...
1
... 能量模型的网络结构采用OSNet[9 ] . 该网络仅有2.7×106 个参数, 是行人再识别领域的轻量级网络. 整体的网络结构如图1 所示. ...
1
... 在3个行人再识别数据集(Market1501[10 ] 、 DukeMTMC-reID[11 ] 及MSMT[12 ] 数据集)上,开展一系列实验. Market1501数据集包括32 688 图片, 由6个不同摄像机拍摄, 包括1 501个不同的行人. 其中查询数据集包含3 368张图片, 检索数据集包含15 913张图片. DukeMTMC-reID数据集包含16522 个训练图片, 其中2 228张查询图像及17 661 张检索库图像. MSMT包含32 621 个图像, 其中有11 659 个查询样本及 82 161 个检索库样本. ...
1
... 在3个行人再识别数据集(Market1501[10 ] 、 DukeMTMC-reID[11 ] 及MSMT[12 ] 数据集)上,开展一系列实验. Market1501数据集包括32 688 图片, 由6个不同摄像机拍摄, 包括1 501个不同的行人. 其中查询数据集包含3 368张图片, 检索数据集包含15 913张图片. DukeMTMC-reID数据集包含16522 个训练图片, 其中2 228张查询图像及17 661 张检索库图像. MSMT包含32 621 个图像, 其中有11 659 个查询样本及 82 161 个检索库样本. ...
1
... 在3个行人再识别数据集(Market1501[10 ] 、 DukeMTMC-reID[11 ] 及MSMT[12 ] 数据集)上,开展一系列实验. Market1501数据集包括32 688 图片, 由6个不同摄像机拍摄, 包括1 501个不同的行人. 其中查询数据集包含3 368张图片, 检索数据集包含15 913张图片. DukeMTMC-reID数据集包含16522 个训练图片, 其中2 228张查询图像及17 661 张检索库图像. MSMT包含32 621 个图像, 其中有11 659 个查询样本及 82 161 个检索库样本. ...
1
... 车辆再识别数据集Veri-776[13 ] 中有50 000个样本图片, 来自于20个不同摄像机所拍摄的776个不同的车辆. 其中576个车辆的37 778张图片作为训练集, 另外200个车辆的11 579张图片作为被检索数据集, 测试集中有1 664张图片. 车辆再识别数据集VehicleID中有110 178张图片用以网络训练, 其中包含13 134个不同车辆;111 585张图片被用作测试集, 包含13 113个不同的车辆. VehicleID中的测试集按照规模大小分为3类, 分别是Small、Medium、Large测试子集. 累计匹配特性 (cumulative matching characteristic,CMC)[14 ] 用来评价不同算法在各个数据库上的检索性能. 累计匹配特性包括Rank1、Rank5和平均准确率 (mean average precision,mAP), 是本文实验对比的性能评价指标. 在训练阶段,所有的图片被统一缩放为256×128像素, 数据增强方法包括随机擦除和随机翻转. 神经网络输出均为512维向量. 优化方法采用Adam,使用默认参数. 初始学习率为0.001 5,在第80和150轮训练时学习率分别缩小10倍, 一共训练200轮. 在训练的第2阶段, 学习率设置为0.001 5,训练50轮. 本文算法的实现基于Pytorch平台. ...
1
... 车辆再识别数据集Veri-776[13 ] 中有50 000个样本图片, 来自于20个不同摄像机所拍摄的776个不同的车辆. 其中576个车辆的37 778张图片作为训练集, 另外200个车辆的11 579张图片作为被检索数据集, 测试集中有1 664张图片. 车辆再识别数据集VehicleID中有110 178张图片用以网络训练, 其中包含13 134个不同车辆;111 585张图片被用作测试集, 包含13 113个不同的车辆. VehicleID中的测试集按照规模大小分为3类, 分别是Small、Medium、Large测试子集. 累计匹配特性 (cumulative matching characteristic,CMC)[14 ] 用来评价不同算法在各个数据库上的检索性能. 累计匹配特性包括Rank1、Rank5和平均准确率 (mean average precision,mAP), 是本文实验对比的性能评价指标. 在训练阶段,所有的图片被统一缩放为256×128像素, 数据增强方法包括随机擦除和随机翻转. 神经网络输出均为512维向量. 优化方法采用Adam,使用默认参数. 初始学习率为0.001 5,在第80和150轮训练时学习率分别缩小10倍, 一共训练200轮. 在训练的第2阶段, 学习率设置为0.001 5,训练50轮. 本文算法的实现基于Pytorch平台. ...
1
... 为了验证本文方法在不同网络结构上的通用性, 网络分别替换为ResNet50[15 ] 、ResNet50-NL(增加了Non-Local[16 ] 模块),测试目标再识别的性能差异. 对于每种基础网络, 将其他损失函数和本文方法进行比较, 验证本文方法相对于其他损失函数的优势. 将本文方法与Soft-max、AM-Soft-max[3 ] 、 Arc-Soft-max[2 ] 、Soft-max+Center[17 ] 及Soft-max+Triplet[18 ] 方法进行Rank1和mAP性能比较. 实验采用的数据集为Market1501. ...
2
... 为了验证本文方法在不同网络结构上的通用性, 网络分别替换为ResNet50[15 ] 、ResNet50-NL(增加了Non-Local[16 ] 模块),测试目标再识别的性能差异. 对于每种基础网络, 将其他损失函数和本文方法进行比较, 验证本文方法相对于其他损失函数的优势. 将本文方法与Soft-max、AM-Soft-max[3 ] 、 Arc-Soft-max[2 ] 、Soft-max+Center[17 ] 及Soft-max+Triplet[18 ] 方法进行Rank1和mAP性能比较. 实验采用的数据集为Market1501. ...
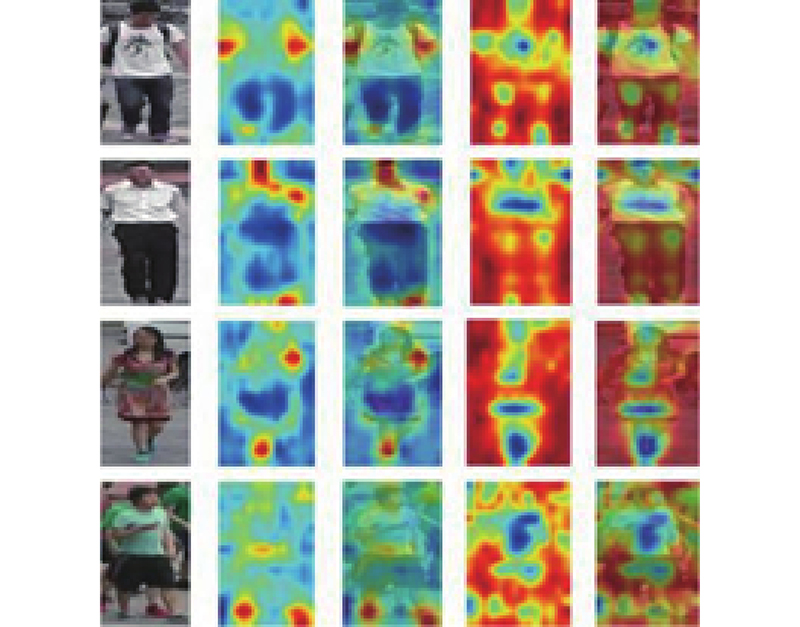
... 表2 中, 在Rank1和mAP指标上, 本文方法均超过了Soft-max系列方法. 与Soft-max和Triplet 的混合损失函数相比, 本文方法的准确率和训练效率更高. 在mAP指标上, 本文方法优于Soft-max和Triplet的混合损失. 混合损失函数在训练时的效率低于单个损失函数. Center Loss表现较差, 因为人脸识别任务中存在明显的特征脸,行人识别和车辆识别由于图片多角度的原因不存在明显的特征人和特征车,例如车辆的前身和后身图像甚至没有任何像素上的交集. 在网络结构的对比上, 随着网络参数的增多, 目标再识别的整体性能获得提升. 本文在ResNet50的基础上增加了Non-Local[16 ] 的自注意力机制模块, 进一步测试本文方法在该网络模型上的性能. 鉴于OSNet仅有2.7×106 个参数, 相对于2.4×107 个参数的ResNet50和2.5×107 个参数的ResNet50-NL, 综合表现更好. 实验说明, 能量模型的性能与采用的神经网络结构无关. 本文对OSNet卷积神经网络结构的最后一层进行可视化. 如图3 所示, 第1列为Market1501中的原始图像, 第2列和第3列为能量损失所产生的特征热力图和原始图像与热力图叠加后的图像, 第4列和第5列为三元组与Soft-max混合损失所产生的特征热力图及原始图像与热力图叠加后的图像. 能量模型实现了区分度较高的特征激活, 比如书包的背带、鞋子、头肩部特征等.三元组与Soft-max混合损失的激活区域缺乏目标识别的针对性, 当数据集中的行人身份增加时, 特征区分度会下降. ...
1
... 为了验证本文方法在不同网络结构上的通用性, 网络分别替换为ResNet50[15 ] 、ResNet50-NL(增加了Non-Local[16 ] 模块),测试目标再识别的性能差异. 对于每种基础网络, 将其他损失函数和本文方法进行比较, 验证本文方法相对于其他损失函数的优势. 将本文方法与Soft-max、AM-Soft-max[3 ] 、 Arc-Soft-max[2 ] 、Soft-max+Center[17 ] 及Soft-max+Triplet[18 ] 方法进行Rank1和mAP性能比较. 实验采用的数据集为Market1501. ...
1
... 为了验证本文方法在不同网络结构上的通用性, 网络分别替换为ResNet50[15 ] 、ResNet50-NL(增加了Non-Local[16 ] 模块),测试目标再识别的性能差异. 对于每种基础网络, 将其他损失函数和本文方法进行比较, 验证本文方法相对于其他损失函数的优势. 将本文方法与Soft-max、AM-Soft-max[3 ] 、 Arc-Soft-max[2 ] 、Soft-max+Center[17 ] 及Soft-max+Triplet[18 ] 方法进行Rank1和mAP性能比较. 实验采用的数据集为Market1501. ...
Camstyle: a novel data augmentation method for person re-identification
3
2019
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... [19 ]训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
2
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
2
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
2
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
1
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
2
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
1
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
1
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
1
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
2
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
... 在车辆再识别VehicleID上, 将能量模型与同类方法进行对比,说明能量模型的通用性. 车辆再识别和行人再识别属于同一类问题, 但是车辆再识别的难度更大. 这是因为车辆的款式和颜色有限, 相对于行人的各种衣着和各种姿态, 车辆的特征编码空间有限, 导致大规模的车辆再识别混淆程度较高. VehicleID数据集包含数十万张图片, 测试集划分为Small、Medium、Large 3部分. 能量模型采用ResNet50基础网络, 微调能量损失中的参数,得到最佳性能. 在这3个不同规模的测试集上,各种方法的性能指标如表4 所示. 与行人再识别存在较大区别的是车辆再识别的类内方差较大. ResNet50网络在训练结束后, 能量损失仍能维持较大的数值. 即使是ResNet50拥有2.4×107 个参数空间, 也不能完全拟合训练集. 鉴于测试集和训练集的偏差, 如何恰当地在训练集上拟合网络结构,以在测试集上获得最佳的性能, 比行人再识别任务更具有挑战性. 能量模型中的α 在第2阶段训练中保持为1, 因为第1阶段的剩余损失较大. β 取值不能过小, 否则影响分类性能,无法达到收缩类内距离的作用. 表4 中,最佳方法用黑体表示, 次优方法用下划线表示. VANet[28 ] 在Rank1指标上略优于本文方法, 这是因为VANet借助于复杂的网络结构, 采用了多分支网络. 表4 表明,在单分支网络中本文方法的各项指标均最好. GSTE方法利用特征聚类实现了目标再识别的目标, 与本文方法的原理类似, 但本文方法在训练效率上优于特征聚类方法, 在准确率上具有较大的优势, 在mAP上分别提高了10.42%、7.05%和5.28%. ...
1
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
2
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
... Rank1 and mAP performance comparison with state of art methods on three person re-ID datasets
Tab.3 % 方法 Market1501 DukeMTMC-ReID MSMT Rank1 mAP Rank1 mAP Rank1 mAP Camstyle[19 ] 88.1 68.7 75.3 53.5 — — PN-GAN[20 ] 89.4 72.6 73.6 53.2 — — MGN[21 ] 95.7 86.9 88.7 78.4 — — Pyramid[22 ] 95.7 88.2 89.0 79.0 — — ABD-Net[23 ] 95.6 88.3 88.3 78.6 — — PCB[24 ] 93.8 81.6 83.3 69.2 68.2 40.4 SPReID[25 ] 92.5 81.3 84.4 71.0 — — MaskReID[26 ] 90.0 75.3 78.8 61.9 — — SCPNet[27 ] 91.2 75.2 80.3 62.6 — — HA-CNN[28 ] 91.2 75.7 80.5 63.8 — — SVDNet[29 ] 82.3 62.1 76.7 56.8 — — TransReID[30 ] 95.2 89.5 91.1 82.1 86.20 69.4 Energy-Loss 95.9 89.9 92.3 83.5 85.52 70.9
表 4 在VehicleID 数据集上与最好方法的Rank1 和mAP指标对比 ...
1
... 如表3 所示,在3个行人再识别数据集Market1501、 DukeMTMC-ReID和MSMT上, 比较能量模型和目前其他主流方法的识别性能. 性能指标采用Rank1和mAP. Camstyle[19 ] 和PN-GAN[20 ] 属于数据增强类方法, 本文仅采用随机反转和随机擦除的基本数据增强方法;其他方法均对网络结构进行改进,如增加了多分支网络、注意力机制, 本文仅采用基础ResNet50. 重排序[31 ] 可以大幅度提高性能,同类方法中大多未使用该方法, 因此本文为了公平比较,不列出重排序后的结果. 更高的图像分辨率可以提高性能, 为了排除该影响, 限定所采用的图像分辨率为256×128像素. 在Market1501数据集上, MGN[21 ] 方法取得了Rank1的第一名, 达到95.7%, 但在mAP指标上,本文方法超过了MGN. 在DukeMTMC-ReID数据集上, Pyramid[22 ] 综合表现最好, 但和本文方法相比差别不大. 能量模型凭借简单的网络结构在性能表现上优势明显. 表4 中,最佳方法用黑体表示, 次优方法加下划线表示. 在大规模数据集MSMT上, 将能量模型与其他方法进行对比. 在Camstyle[19 ] 训练过程中,需要对每个相机生成新样本, 因而综合性能较低, 在Market1501上mAP低于本文方法8.3%. 本文方法与PCB[24 ] 方法相比, Rank1和mAP均表现出较大的优势, 在3个数据集上, Rank指标分别高出2.1%、 9.0%和17.3%. 与最新的无卷积网络模型TransReID[30 ] 相比,本文方法的模型参数远远少于TransReID, 在mAP指标上表现出优势,仅在MSMT数据集的Rank1指标上低于TransReID 0.68%. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
PROVID: progressive and multimodal vehicle reidentification for large-scale urban surveillance
1
2018
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
Vehicle re-identification using quadruple directional deep learning features
1
2019
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
1
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...
Group-sensitive triplet embedding for vehicle re-identification
1
2018
... Rank1 and mAP performance comparison with state of art methods on VehicleID
Tab.4 % 方法 VehicleID Small VehicleID Medium VehicleID Large Rank1 mAP Rank1 mAP Rank1 mAP CLVR[32 ] 62.00 — 56.10 — 50.60 — VANet[33 ] 88.12 — 83.17 — 80.45 — RAM[34 ] 75.20 — 72.30 — 67.70 — ABLN[35 ] 52.63 — — — — — VAMI[36 ] 63.12 — 52.87 — 47.34 — NuFACT[37 ] 48.90 — 43.64 — 38.63 — AAVER[38 ] 74.69 — 68.62 — 63.54 — QD-DLF[39 ] 72.32 76.54 70.66 74.63 64.14 68.41 Part-Reg[40 ] 78.40 61.50 75.00 — 74.20 — GSTE[41 ] 75.90 75.40 74.80 74.30 74.00 72.40 Energy-Loss 89.75 85.82 84.58 81.35 81.15 77.68
为了说明本文方法的识别效果, 在Market1501数据集上,列出行人再识别的检索匹配结果,如图4 所示. 第1列为待检索的行人图像, 后面10列为其他摄像头所拍摄的行人图像. 浅色框内表示检索出的行人与待检索图像属于同一身份, 深色框表示不同身份的图像. 从图4 可以看出,本文方法在大多数情况下均能够正确地识别行人身份. 当其他摄像头所拍摄的图像存在行人检测定位不准、检测不完整、检测图像模糊等情况时, 本文方法出现了识别错误的情形. 为了解决该类问题, 需要提高行人定位的准确率及拍摄清晰度. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}