(3) $ \left. {\begin{gathered} {\rm{loss}}\;(z,y) = {\rm{mean}}\left\{ {{l_0}, \cdots ,{l_{N - 1}}} \right\}, \hfill \\ {l_n} = {\rm{sum}}\left\{ {{l_{n,0}},{l_{n,1}}, \cdots, {l_{n,179}}} \right\}, \hfill \\ {l_{n,i}} = - [{y_{n,i}}{\rm{ln}}\;(\delta ({z_{n,i}})) + (1 - {y_{n,i}}){\rm{ln}}\;(1 - \delta ({z_{n,i}}))], \hfill \\ {y_{n,i}}{\text{ = }}{\rm{CSL}}(x). \hfill \\ \end{gathered}} \right\} $
[1]
康庄, 杨杰, 郭濠奇 基于机器视觉的垃圾自动分类系统设计
[J]. 浙江大学学报:工学版 , 2020 , 54 (7 ): 1272 - 1280
URL
[本文引用: 1]
KANG Zhuang, YANG Jie, GUO Hao-qi Automatic garbage classification system based on machine vision
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (7 ): 1272 - 1280
URL
[本文引用: 1]
[2]
谢先武, 熊禾根, 陶永, 等 一种面向机器人分拣的杂乱工件视觉检测识别方法
[J]. 高技术通讯 , 2018 , 28 (4 ): 344 - 353
DOI:10.3772/j.issn.1002-0470.2018.04.008
[本文引用: 1]
XIE Xian-wu, XIONG He-gen, TAO Yong, et al A method for visual detection and recognition of clutter workpieces for robot sorting
[J]. Chinese High Technology Letters , 2018 , 28 (4 ): 344 - 353
DOI:10.3772/j.issn.1002-0470.2018.04.008
[本文引用: 1]
[4]
陈智超, 焦海宁, 杨杰, 等 基于改进 MobileNet v2 的垃圾图像分类算法
[J]. 浙江大学学报:工学版 , 2021 , 55 (8 ): 1490 - 1499
URL
[本文引用: 1]
CHEN Zhi-chao, JIAO Hai-ning, YANG Jie, et al Garbage image classification algorithm based on improved MobileNet v2
[J]. Journal of Zhejiang University: Engineering Science , 2021 , 55 (8 ): 1490 - 1499
URL
[本文引用: 1]
[5]
袁建野, 南新元, 蔡鑫, 等 基于轻量级残差网路的垃圾图片分类方法
[J]. 环境工程 , 2021 , 39 (2 ): 6
URL
[本文引用: 1]
YUAN Jian-ye, NAN Xin-yuan, CAI Xin, et al Garbage image classification by lightweight residual network
[J]. Environmental Engineering , 2021 , 39 (2 ): 6
URL
[本文引用: 1]
[6]
NIE Z, DUAN W, LI X Domestic garbage recognition and detection based on Faster R-CNN
[J]. Journal of Physics: Conference Series , 2021 , 1738 (1 ): 012089
DOI:10.1088/1742-6596/1738/1/012089
[本文引用: 1]
[7]
LIANG B, WANG Y, WANG Y, et al Garbage sorting system based on composite layer cnn and multi-robots
[J]. Journal of Physics: Conference Series , 2020 , 1634 (1 ): 012083
DOI:10.1088/1742-6596/1634/1/012083
[本文引用: 1]
[8]
周滢慜. 基于机器视觉的生活垃圾智能分拣系统的设计与实现 [D]. 哈尔滨: 哈尔滨工业大学, 2018.
[本文引用: 1]
ZHOU Ying-min. Design and implementation of visionbased Sorting system for solid waste [D]. Harbin: Harbin Institute of Technology, 2018.
[本文引用: 1]
[9]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[10]
LIU K, TANG H, HE S, et al. Performance validation of Yolo variants for object detection [C]// Proceedings of the 2021 International Conference on Bioinformatics and Intelligent Computing . Vancouver: [s. n. ], 2021: 239-243.
[本文引用: 1]
[11]
朱煜, 方观寿, 郑兵兵, 等. 基于旋转框精细定位的遥感目标检测方法研究 [EB/OL]. [2021-10-01]. http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.C200261.
[本文引用: 1]
ZHU Yu, FANG Guan-shou, ZHENG Bing-bing, et al. Research on detection method of refined rotated boxes in remote sensing [EB/OL]. [2021-10-01]. http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.C200261.
[本文引用: 1]
[12]
DING J, XUE N, LONG Y, et al. Learning roi transformer for oriented object detection in aerial images [C]// 2019 IEEE Conference on Computer Vision and Pattern Recognition . Long Bench: IEEE, 2019: 2849-2858.
[本文引用: 1]
[13]
XU Y, FU M, WANG Q, et al Gliding vertex on the horizontal bounding box for multi-oriented object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 43 (4 ): 1452 - 1459
[本文引用: 1]
[14]
CHEN Y , DING W , LI H , et al. Arbitrary-oriented dense object detection in remote sensing imagery [C]// 2018 IEEE 9th International Conference on Software Engineering and Service Science . Beijing: IEEE, 2019: 436-440.
[本文引用: 1]
[15]
YANG X, YANG J, YAN J, et al. Scrdet: towards more robust detection for small, cluttered and rotated objects [C]// 2019 IEEE/CVF International Conference on Computer Vision . South Korea: IEEE, 2019: 8232-8241.
[本文引用: 2]
[16]
YANG X, LIU Q, YAN J, et al. R3 det: refined single-stage detector with feature refinement for rotating object [EB/OL]. [2021-10-01]. https://arxiv.org/abs/1908.05612.
[本文引用: 1]
[17]
YANG X, YAN J, HE T. On the arbitrary-oriented object detection: classification based approaches revisited [EB/OL]. [2021-10-01]. https://arxiv.org/abs/2003.05597v3.
[本文引用: 1]
[18]
ZHU X, LIU S, WANG X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 2778-2788.
[本文引用: 1]
[19]
FU L, GU W, LI W, et al Bidirectional parallel multi-branch convolution feature pyramid network for target detection in aerial images of swarm UAVs
[J]. Defence Technology , 2021 , 17 (4 ): 1531 - 1541
DOI:10.1016/j.dt.2020.09.018
[本文引用: 1]
[20]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: [s. n], 2017: 5998-6008.
[本文引用: 1]
[22]
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Hawaii: IEEE, 2017: 2117-2125.
[本文引用: 1]
[23]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759-8768.
[本文引用: 1]
[24]
GHIASI G, LIN T Y, LE Q V. Nas-fpn: Learning scalable feature pyramid architecture for object detection [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 7036-7045.
[本文引用: 1]
[25]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10781-10790.
[本文引用: 1]
基于机器视觉的垃圾自动分类系统设计
1
2020
... 利用机器视觉与自动化设备协同配合代替人工流水线再生物品分拣成为发展趋势[1 -2 ] . 瓶罐状物通常由塑料、玻璃、金属等材质制成,外形均是柱状体,分拣时易出现误检. 同种材质瓶罐状物具有多样化形态结构和多尺度的外形尺寸,易发生变形、遮挡的问题,透明度较高时易与分拣背景混淆,目标物外形特征提取难度加大. 统目标检测算法受特定参数约束条件,降低了分拣对象检测的准确性,易出现漏检、误检. 利用目标检测算法获取平面坐标、旋转角度等位姿信息,结合激光束、接触传感器等确定执行机构下降高度,在满足机械手精准抓取的前提下,降低传统识别旋转角度设备的成本. ...
基于机器视觉的垃圾自动分类系统设计
1
2020
... 利用机器视觉与自动化设备协同配合代替人工流水线再生物品分拣成为发展趋势[1 -2 ] . 瓶罐状物通常由塑料、玻璃、金属等材质制成,外形均是柱状体,分拣时易出现误检. 同种材质瓶罐状物具有多样化形态结构和多尺度的外形尺寸,易发生变形、遮挡的问题,透明度较高时易与分拣背景混淆,目标物外形特征提取难度加大. 统目标检测算法受特定参数约束条件,降低了分拣对象检测的准确性,易出现漏检、误检. 利用目标检测算法获取平面坐标、旋转角度等位姿信息,结合激光束、接触传感器等确定执行机构下降高度,在满足机械手精准抓取的前提下,降低传统识别旋转角度设备的成本. ...
一种面向机器人分拣的杂乱工件视觉检测识别方法
1
2018
... 利用机器视觉与自动化设备协同配合代替人工流水线再生物品分拣成为发展趋势[1 -2 ] . 瓶罐状物通常由塑料、玻璃、金属等材质制成,外形均是柱状体,分拣时易出现误检. 同种材质瓶罐状物具有多样化形态结构和多尺度的外形尺寸,易发生变形、遮挡的问题,透明度较高时易与分拣背景混淆,目标物外形特征提取难度加大. 统目标检测算法受特定参数约束条件,降低了分拣对象检测的准确性,易出现漏检、误检. 利用目标检测算法获取平面坐标、旋转角度等位姿信息,结合激光束、接触传感器等确定执行机构下降高度,在满足机械手精准抓取的前提下,降低传统识别旋转角度设备的成本. ...
一种面向机器人分拣的杂乱工件视觉检测识别方法
1
2018
... 利用机器视觉与自动化设备协同配合代替人工流水线再生物品分拣成为发展趋势[1 -2 ] . 瓶罐状物通常由塑料、玻璃、金属等材质制成,外形均是柱状体,分拣时易出现误检. 同种材质瓶罐状物具有多样化形态结构和多尺度的外形尺寸,易发生变形、遮挡的问题,透明度较高时易与分拣背景混淆,目标物外形特征提取难度加大. 统目标检测算法受特定参数约束条件,降低了分拣对象检测的准确性,易出现漏检、误检. 利用目标检测算法获取平面坐标、旋转角度等位姿信息,结合激光束、接触传感器等确定执行机构下降高度,在满足机械手精准抓取的前提下,降低传统识别旋转角度设备的成本. ...
Wasnet: a neural network-based garbage collection management system
1
2020
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
基于改进 MobileNet v2 的垃圾图像分类算法
1
2021
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
基于改进 MobileNet v2 的垃圾图像分类算法
1
2021
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
基于轻量级残差网路的垃圾图片分类方法
1
2021
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
基于轻量级残差网路的垃圾图片分类方法
1
2021
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
Domestic garbage recognition and detection based on Faster R-CNN
1
2021
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
Garbage sorting system based on composite layer cnn and multi-robots
1
2020
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
1
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
1
... 在再生物品图像识别的问题上,诸多学者展开研究. Yang等[3 ] 提出轻量级神经网络WasNet. 陈智超等[4 -5 ] 提出MobileNet垃圾图像分类改进算法. Nie等[6 ] 结合Faster R-CNN和ResNet50,完成垃圾图像识别、检测. Liang等[7 ] 提出整合高、低层次的特征图,设计复合层CNN网络. 上述模型无法获取目标物旋转角度信息,缺乏考虑同类物体多形态、多尺度问题,缺少单一图像中多类目标的检测. 周滢慜[8 ] 改进Faster-RCNN目标检测模型,调整原始VGG16分类网络,实现瓶子位置和旋转角度的识别. 数据集中瓶子的形态和尺度单一,缺乏考虑目标物之间遮挡、易发生变形等情况. 综上所述,现有再生物品目标检测算法无法同时满足实际分拣场景下位姿信息获取以及多形态、多尺度目标物的检测. ...
1
... YOLO(you only look once)算法由Redmon等[9 ] 提出, YOLOv5利用Mosaic数据增强、自适应锚框计算和图像缩放等方法,提高模型整体鲁棒性. Liu等[10 ] 比较YOLO系列模型后表明,YOLOv5在mAP和检测速度方面具有较大优势. YOLOv5多尺度自适应锚框计算实现多尺度检测,符合再生物品实际分拣场景的性能需求,但缺乏角度预测. ...
1
... YOLO(you only look once)算法由Redmon等[9 ] 提出, YOLOv5利用Mosaic数据增强、自适应锚框计算和图像缩放等方法,提高模型整体鲁棒性. Liu等[10 ] 比较YOLO系列模型后表明,YOLOv5在mAP和检测速度方面具有较大优势. YOLOv5多尺度自适应锚框计算实现多尺度检测,符合再生物品实际分拣场景的性能需求,但缺乏角度预测. ...
1
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
1
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
1
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
Gliding vertex on the horizontal bounding box for multi-oriented object detection
1
2020
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
1
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
2
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
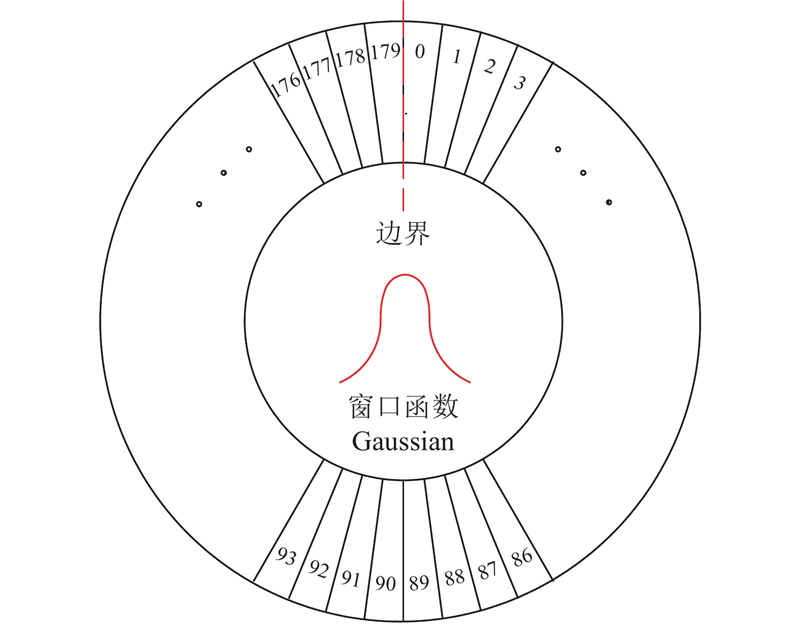
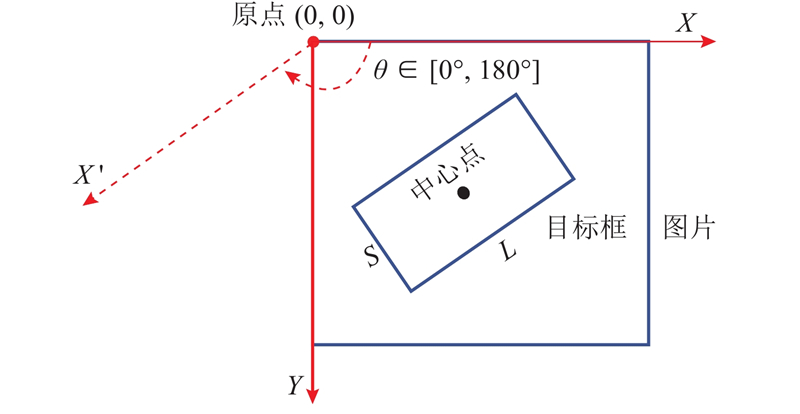
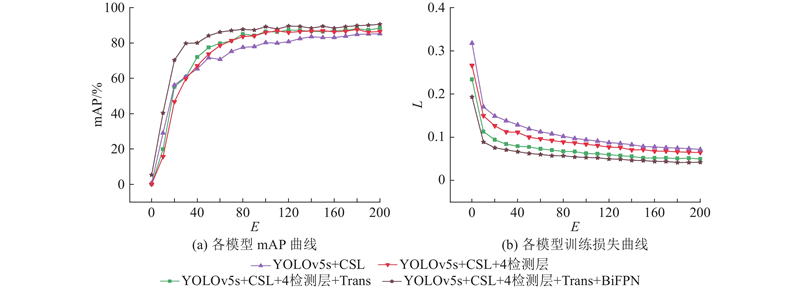
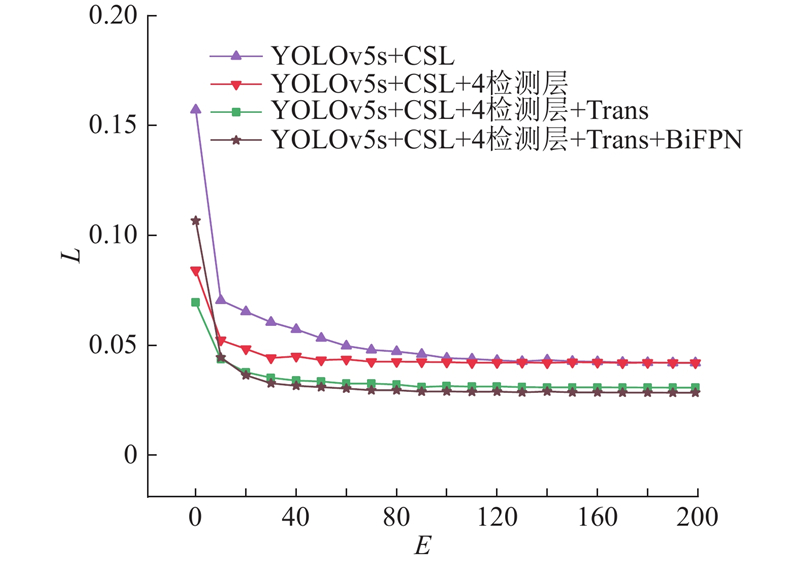
... 针对机器人分拣过程中对于位姿信息的需求,在原模型的基础上添加角度预测分支. 由于长宽比较大的目标对于角度变化十分敏感,目前主流的角度回归方法均存在不连续边界问题,使模型损失值在处于边界情况下出现突增,导致该类检测方法在边界条件下检测准确率低[15 ] . 将目标物角度预测视为分类问题,设计符合再生物品分拣物理场景的环形平滑标签(CSL),增加相邻角度之间的误差容忍度. 修改后的CSL可视化表达如图3 所示,CSL的具体表达式为 ...
1
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
1
... 诸多学者提出解决目标物角度预测问题的方法. 朱煜等[11 ] 提出粗调与细调两阶段旋转框检测网络R²-FRCNN. Ding等[12 ] 提出ROI-Transformer检测模型. Xu等[13 ] 提出学习水平框转换为旋转框后4个点的偏移. Chen等[14 ] 引入两阶段NMS算法,降低密集对象漏检率. Yang等提出旋转检测器SCRDet[15 ] 、R3 Det[16 ] . 上述基于回归方法实现旋转框检测,存在角度周期性(PoA)和边缘的交换性(EoE)问题. 针对该问题,Yang等[17 ] 提出将物体角度预测视为分类问题,且为限制预测结果,设计环形平滑标签(circular smooth label,CSL),但该方法多用于遥感图像检测,无法直接迁移至分拣场景下的再生物品目标物角度检测. ...
1
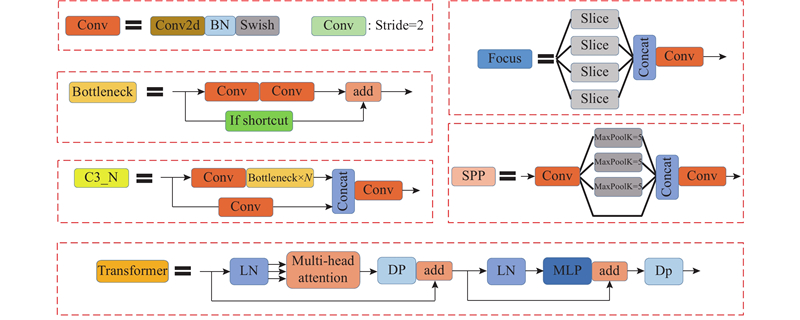
... 将Transformer模块融入YOLOv5模型,可以提升高密度遮挡目标物的检测性能[18 ] . Transformer特征提取结构由2部分组成,分别是编码器(encoder)和解码器(decoder),由于仅进行图像识别,只须利用编码器进行特征提取. 利用主干网络对于图像进行特征提取,结合位置编码将其转换为序列,作为Transformer编码器的输入. Transformer编码器主要包括2个主要模块:多头注意力机制模块(multi-head attention)和前馈神经网络(MLP). LN(LayerForm)层和DP(Dropout)层可以防止网络过拟合,提高特征融合[19 ] . ...
Bidirectional parallel multi-branch convolution feature pyramid network for target detection in aerial images of swarm UAVs
1
2021
... 将Transformer模块融入YOLOv5模型,可以提升高密度遮挡目标物的检测性能[18 ] . Transformer特征提取结构由2部分组成,分别是编码器(encoder)和解码器(decoder),由于仅进行图像识别,只须利用编码器进行特征提取. 利用主干网络对于图像进行特征提取,结合位置编码将其转换为序列,作为Transformer编码器的输入. Transformer编码器主要包括2个主要模块:多头注意力机制模块(multi-head attention)和前馈神经网络(MLP). LN(LayerForm)层和DP(Dropout)层可以防止网络过拟合,提高特征融合[19 ] . ...
1
... Transformer网络结合多个缩放点积注意力机制,形成多头注意力机制. 利用缩放点积注意力机制可以批量处理数据,表达式[20 ] 为 ...
融合BiFPN和改进Yolov3-tiny网络的航拍图像车辆检测方法
1
2021
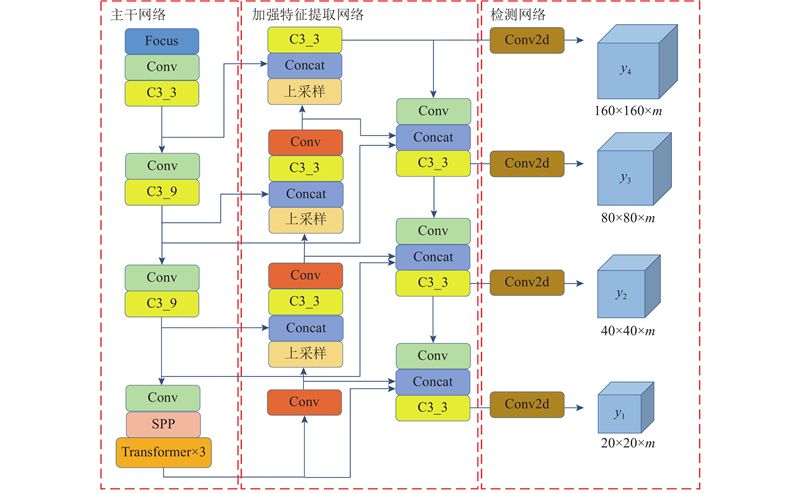
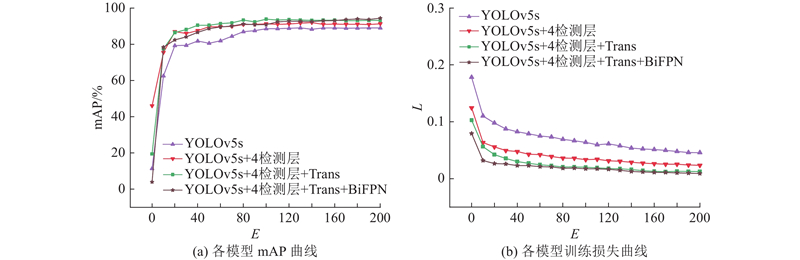
... 随着网络层数的加深,每一层网络都会在一定程度上造成特征丢失,增加检测分支和融合多尺度特征融合网络可以提升检测精度[21 ] . 目前已有的特征融合网络FPN[22 ] 、PANet[23 ] 、NAS-FPN[24 ] 、BiFPN[25 ] 等. 为了增强不同尺度的特征信息融合,将原始加强特征提取网络PANet结构改进为BiFPN结构,将主干网络中的多尺度特征图多次输入BiFPN结构中,开展自上而下和自下而上的多尺度特征融合;对于同尺度大小的特征层,利用跳跃连接的方式进行特征融合. MR2 -YOLOv5的BiFPN自下而上的部分对2个同尺度特征进行融合,自上而下的结构对3个同尺度特征进行融合,在经过C3模块以及Conv2d模块计算后,对于4个不同的尺度目标进行预测. 利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体的模型检测能力,降低了漏检率与误检率. ...
融合BiFPN和改进Yolov3-tiny网络的航拍图像车辆检测方法
1
2021
... 随着网络层数的加深,每一层网络都会在一定程度上造成特征丢失,增加检测分支和融合多尺度特征融合网络可以提升检测精度[21 ] . 目前已有的特征融合网络FPN[22 ] 、PANet[23 ] 、NAS-FPN[24 ] 、BiFPN[25 ] 等. 为了增强不同尺度的特征信息融合,将原始加强特征提取网络PANet结构改进为BiFPN结构,将主干网络中的多尺度特征图多次输入BiFPN结构中,开展自上而下和自下而上的多尺度特征融合;对于同尺度大小的特征层,利用跳跃连接的方式进行特征融合. MR2 -YOLOv5的BiFPN自下而上的部分对2个同尺度特征进行融合,自上而下的结构对3个同尺度特征进行融合,在经过C3模块以及Conv2d模块计算后,对于4个不同的尺度目标进行预测. 利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体的模型检测能力,降低了漏检率与误检率. ...
1
... 随着网络层数的加深,每一层网络都会在一定程度上造成特征丢失,增加检测分支和融合多尺度特征融合网络可以提升检测精度[21 ] . 目前已有的特征融合网络FPN[22 ] 、PANet[23 ] 、NAS-FPN[24 ] 、BiFPN[25 ] 等. 为了增强不同尺度的特征信息融合,将原始加强特征提取网络PANet结构改进为BiFPN结构,将主干网络中的多尺度特征图多次输入BiFPN结构中,开展自上而下和自下而上的多尺度特征融合;对于同尺度大小的特征层,利用跳跃连接的方式进行特征融合. MR2 -YOLOv5的BiFPN自下而上的部分对2个同尺度特征进行融合,自上而下的结构对3个同尺度特征进行融合,在经过C3模块以及Conv2d模块计算后,对于4个不同的尺度目标进行预测. 利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体的模型检测能力,降低了漏检率与误检率. ...
1
... 随着网络层数的加深,每一层网络都会在一定程度上造成特征丢失,增加检测分支和融合多尺度特征融合网络可以提升检测精度[21 ] . 目前已有的特征融合网络FPN[22 ] 、PANet[23 ] 、NAS-FPN[24 ] 、BiFPN[25 ] 等. 为了增强不同尺度的特征信息融合,将原始加强特征提取网络PANet结构改进为BiFPN结构,将主干网络中的多尺度特征图多次输入BiFPN结构中,开展自上而下和自下而上的多尺度特征融合;对于同尺度大小的特征层,利用跳跃连接的方式进行特征融合. MR2 -YOLOv5的BiFPN自下而上的部分对2个同尺度特征进行融合,自上而下的结构对3个同尺度特征进行融合,在经过C3模块以及Conv2d模块计算后,对于4个不同的尺度目标进行预测. 利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体的模型检测能力,降低了漏检率与误检率. ...
1
... 随着网络层数的加深,每一层网络都会在一定程度上造成特征丢失,增加检测分支和融合多尺度特征融合网络可以提升检测精度[21 ] . 目前已有的特征融合网络FPN[22 ] 、PANet[23 ] 、NAS-FPN[24 ] 、BiFPN[25 ] 等. 为了增强不同尺度的特征信息融合,将原始加强特征提取网络PANet结构改进为BiFPN结构,将主干网络中的多尺度特征图多次输入BiFPN结构中,开展自上而下和自下而上的多尺度特征融合;对于同尺度大小的特征层,利用跳跃连接的方式进行特征融合. MR2 -YOLOv5的BiFPN自下而上的部分对2个同尺度特征进行融合,自上而下的结构对3个同尺度特征进行融合,在经过C3模块以及Conv2d模块计算后,对于4个不同的尺度目标进行预测. 利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体的模型检测能力,降低了漏检率与误检率. ...
1
... 随着网络层数的加深,每一层网络都会在一定程度上造成特征丢失,增加检测分支和融合多尺度特征融合网络可以提升检测精度[21 ] . 目前已有的特征融合网络FPN[22 ] 、PANet[23 ] 、NAS-FPN[24 ] 、BiFPN[25 ] 等. 为了增强不同尺度的特征信息融合,将原始加强特征提取网络PANet结构改进为BiFPN结构,将主干网络中的多尺度特征图多次输入BiFPN结构中,开展自上而下和自下而上的多尺度特征融合;对于同尺度大小的特征层,利用跳跃连接的方式进行特征融合. MR2 -YOLOv5的BiFPN自下而上的部分对2个同尺度特征进行融合,自上而下的结构对3个同尺度特征进行融合,在经过C3模块以及Conv2d模块计算后,对于4个不同的尺度目标进行预测. 利用BiFPN网络,使得预测网络对不同大小的目标更敏感,提升了整体的模型检测能力,降低了漏检率与误检率. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}