|
|
|
| Contrastive learning-based sound source localization-guided audio-visual segmentation model |
Wenhu HUANG( ),Xing ZHAO*(),Liang XIE,Haoran LIANG,Ronghua LIANG ),Xing ZHAO*(),Liang XIE,Haoran LIANG,Ronghua LIANG |
| College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China |
|
|
|
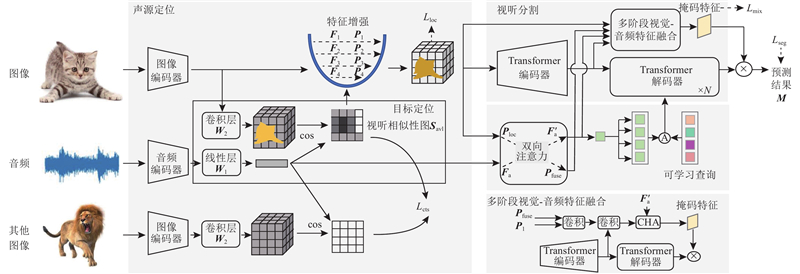
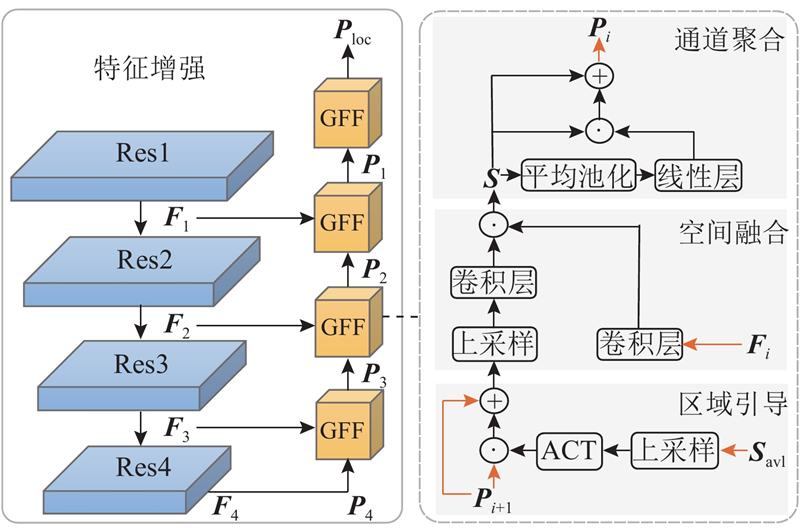
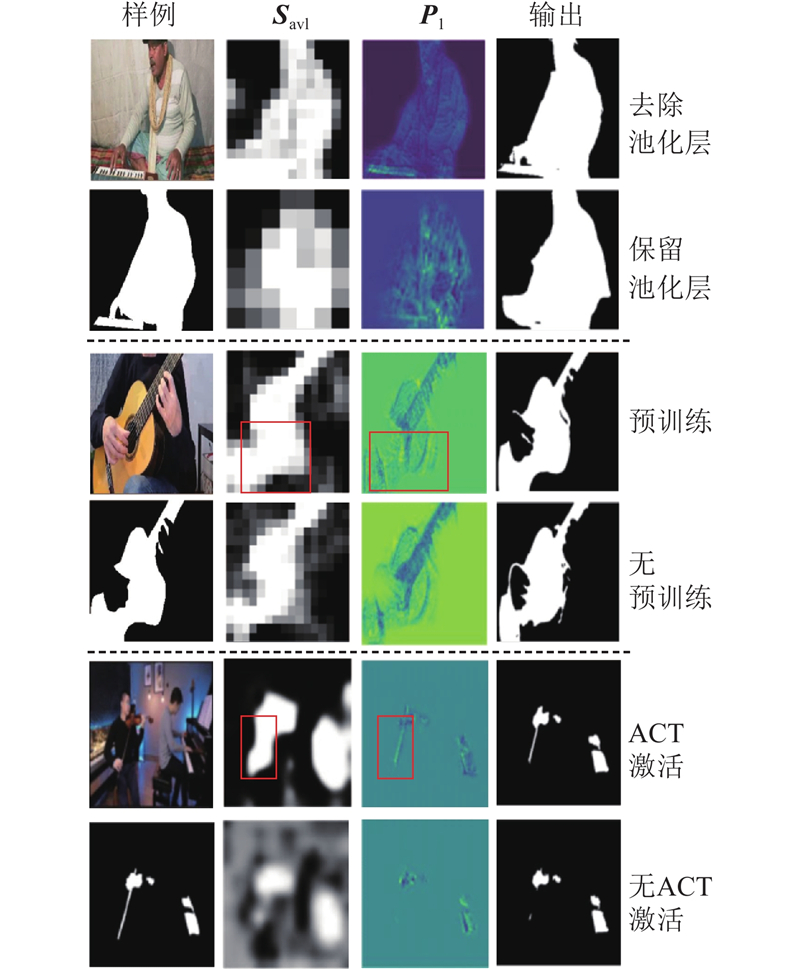
Abstract A sound source localization-guided audio-visual segmentation (SSL2AVS) model based on contrastive learning was proposed to address the problem that background noise hindered effective information exchange and object discrimination in audio-visual segmentation (AVS) tasks. A two-stage localization-to-segmentation progressive strategy was adopted, where visual features were refined through sound source localization to suppress background interference, making the model suitable for audio-visual segmentation in complex scenes. Prior to segmentation, a target localization module was introduced to align audio-visual modalities via the contrastive learning method, generating sound source heatmaps to achieve preliminary sound source localization. A multi-scale feature pyramid network incorporating a feature enhancement module was constructed to dynamically weight and fuse the shallow spatial detail features and the deep semantic features based on the localization results, effectively amplifying the visual features of target objects while suppressing background noise. The synergistic operation of the two modules improved visual representations of objects and enabled the model to focus on object identification. An auxiliary localization loss function was proposed to optimize localization results by encouraging the model to focus on the image regions that matched audio features. Experimental results on the MS3 dataset demonstrated that the model achieved a mean Intersection over Union (mIoU) of 62.15, surpassing the baseline AVSegFormer model.
|
|
Received: 04 December 2024
Published: 25 August 2025
|
|
|
| Fund: 国家自然科学基金资助项目(62402441, 62432014, 62176235); 浙江省自然科学基金资助项目(LDT23F0202, LDT23F02021F02). |
|
Corresponding Authors:
Xing ZHAO
E-mail: 211123120094@zjut.edu.cn;xing@zjut.edu.cn
|
基于对比学习的声源定位引导视听分割模型
针对视听分割任务中背景噪声阻碍有效信息交互和物体辨别的问题,提出基于对比学习的声源定位引导视听分割模型(SSL2AVS). 采用从定位到分割的两阶段策略,通过声源定位引导视觉特征优化,从而减少背景噪声干扰,使模型适用于复杂场景中的视听分割. 在分割前引入目标定位模块,利用对比学习方法对齐视听模态并生成声源热力图,实现发声物体粗定位;引入特征增强模块,构建多尺度特征金字塔网络,利用定位结果动态地加权融合浅层空间细节特征与深层语义特征,在引导增强目标物体视觉特征的同时抑制背景噪声. 2个模块协同作用,增强物体的视觉表示,使模型专注于物体辨识. 为了优化定位结果,提出辅助定位损失函数,促使模型关注与音频特征匹配的图像区域. 实验结果表明,模型在MS3数据集上的mIoU为62.15,高于基线AVSegFormer模型.
关键词:
视听分割,
跨模态交互,
声源定位,
对比学习,
特征增强
|
|
| [1] |
ARANDJELOVIĆ R, ZISSERMAN A. Look, listen and learn [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 609–617.
|
|
|
| [2] |
ARANDJELOVIĆ R, ZISSERMAN A. Objects that sound [C]// Proceedings of the European Conference on Computer Vision. Murich: ECVA, 2018: 451–466.
|
|
|
| [3] |
QIAN R, HU D, DINKEL H, et al. Multiple sound sources localization from coarse to fine [C]// Proceedings of the European Conference on Computer Vision. Glasgow: ECVA, 2020: 292–308.
|
|
|
| [4] |
MO S, MORGADO P. Localizing visual sounds the easy way [C]// Proceedings of the European Conference on Computer Vision. Tel Aviv: ECVA, 2022: 218–234.
|
|
|
| [5] |
HU X, CHEN Z, OWENS A. Mix and localize: localizing sound sources in mixtures [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10473–10482.
|
|
|
| [6] |
HU D, WEI Y, QIAN R, et al Class-aware sounding objects localization via audiovisual correspondence[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (12): 9844- 9859
|
|
|
| [7] |
MO S, TIAN Y. Audio-visual grouping network for sound localization from mixtures [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 10565–10574.
|
|
|
| [8] |
MINAEE S, BOYKOV Y, PORIKLI F, et al Image segmentation using deep learning: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (7): 3523- 3542
|
|
|
| [9] |
ZHOU J, WANG J, ZHANG J, et al. Audio–visual segmentation [C]// Proceedings of the European Conference on Computer Vision. Tel Aviv: ECVA, 2022: 386–403.
|
|
|
| [10] |
YANG Q, NIE X, LI T, et al. Cooperation does matter: exploring multi-order bilateral relations for audio-visual segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 27124–27133.
|
|
|
| [11] |
LIU J, WANG Y, JU C, et al. Annotation-free audio-visual segmentation [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2024: 5592–5602.
|
|
|
| [12] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2020-10-22) [2025-01-10]. https://arxiv.org/abs/2010.11929.
|
|
|
| [13] |
WANG R, TANG D, DUAN N, et al. K-adapter: infusing knowledge into pre-trained models with adapters [EB/OL]. (2020-02-05) [2025-01-10]. https://arxiv.org/abs/2002.01808.
|
|
|
| [14] |
KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything [C]// Proceedings of the IEEE International Conference on Computer Vision. Paris: IEEE, 2023: 3992–4003.
|
|
|
| [15] |
WANG Y, LIU W, LI G, et al. Prompting segmentation with sound is generalizable audio-visual source localizer [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2024: 5669–5677.
|
|
|
| [16] |
MA J, SUN P, WANG Y, et al. Stepping stones: a progressive training strategy for audio-visual semantic segmentation [C]// Proceedings of the European Conference on Computer Vision. Milan: ECVA, 2024: 311–327.
|
|
|
| [17] |
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask Transformer for universal image segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 1280–1289.
|
|
|
| [18] |
LIU J, JU C, MA C, et al. Audio-aware query-enhanced Transformer for audio-visual segmentation [EB/OL]. (2023-07-25) [2025-01-10]. https://arxiv.org/abs/2307.13236.
|
|
|
| [19] |
LI K, YANG Z, CHEN L, et al. CATR: combinatorial-dependence audio-queried Transformer for audio-visual video segmentation [C]// Proceedings of the 31st ACM International Conference on Multimedia. Ottawa: ACM, 2023: 1485–1494.
|
|
|
| [20] |
GAO S, CHEN Z, CHEN G, et al. AVSegFormer: audio-visual segmentation with Transformer [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2024: 12155–12163.
|
|
|
| [21] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach: NeurIPS Foundation, 2017: 6000–6010.
|
|
|
| [22] |
XU B, LIANG H, LIANG R, et al. Locate globally, segment locally: a progressive architecture with knowledge review network for salient object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.]: AAAI, 2021: 3004–3012.
|
|
|
| [23] |
MAO Y, ZHANG J, XIANG M, et al. Multimodal variational auto-encoder based audio-visual segmentation [C]// Proceedings of the IEEE International Conference on Computer Vision. Paris: IEEE, 2023: 954–965.
|
|
|
| [24] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
|
|
|
| [25] |
WANG W, XIE E, LI X, et al PVT v2: improved baselines with pyramid vision Transformer[J]. Computational Visual Media, 2022, 8 (3): 415- 424
doi: 10.1007/s41095-022-0274-8
|
|
|
| [26] |
HERSHEY S, CHAUDHURI S, ELLIS D P W, et al. CNN architectures for large-scale audio classification [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans: IEEE, 2017: 131–135.
|
|
|
| [27] |
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234–241.
|
|
|
| [28] |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision. Munich: ECVA, 2018: 3–19.
|
|
|
| [29] |
ZHAO X, LIANG H, LI P, et al Motion-aware memory network for fast video salient object detection[J]. IEEE Transactions on Image Processing, 2024, 33: 709- 721
|
|
|
| [30] |
WANG Q, WU B, ZHU P, et al. ECA-net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11531–11539.
|
|
|
| [31] |
MILLETARI F, NAVAB N, AHMADI S A. V-net: fully convolutional neural networks for volumetric medical image segmentation [C]// Fourth International Conference on 3D Vision. Stanford: IEEE, 2016: 565–571.
|
|
|
| [32] |
LIU J, LIU Y, ZHANG F, et al. Audio-visual segmentation via unlabeled frame exploitation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 26318–26329.
|
|
|
| [33] |
LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. (2017-11-14) [2025-01-10]. https://arxiv.org/abs/1711.05101.
|
|
|
| [34] |
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248–255.
|
|
|
| [35] |
GEMMEKE J F, ELLIS D P W, FREEDMAN D, et al. Audio set: an ontology and human-labeled dataset for audio events [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans: IEEE, 2017: 776–780.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|