|
|
|
| Cloud-edge collaborative natural language processing method based on lightweight transfer learning |
Yunlong ZHAO( ),Minzhe ZHAO(),Wenqiang ZHU,Xingyu CHA ),Minzhe ZHAO(),Wenqiang ZHU,Xingyu CHA |
| School of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China |
|
|
|
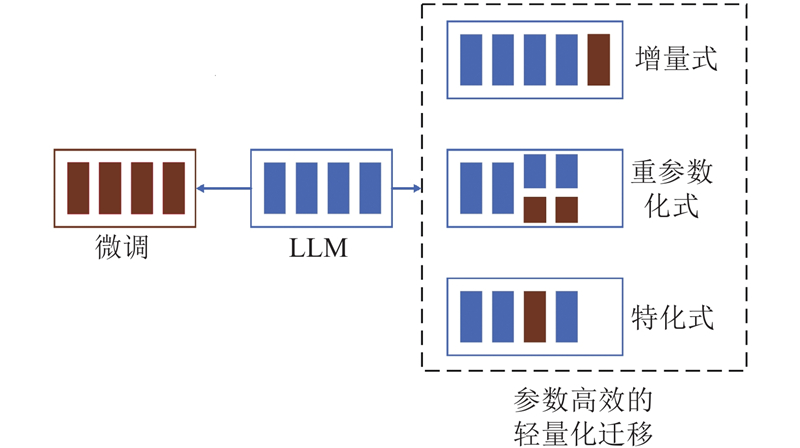
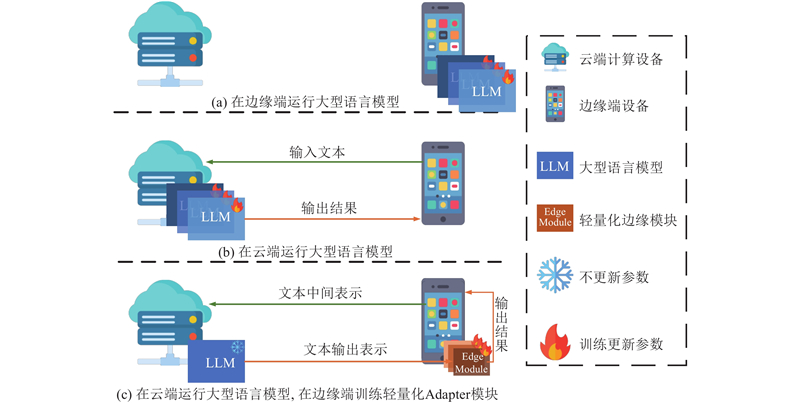
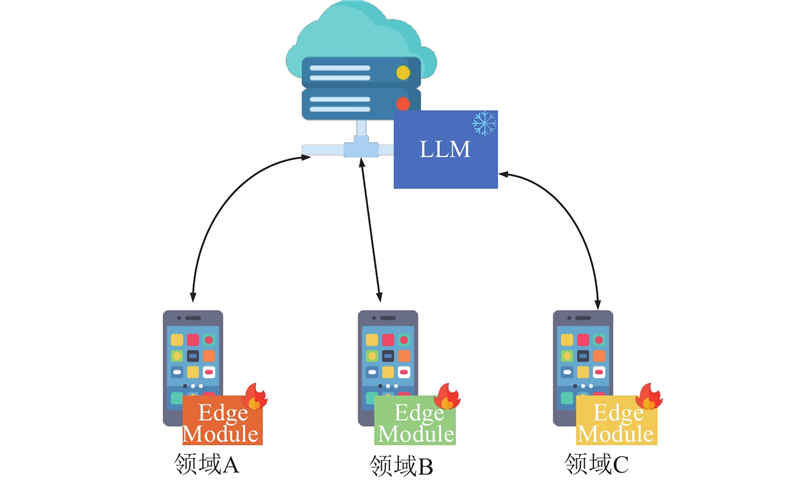
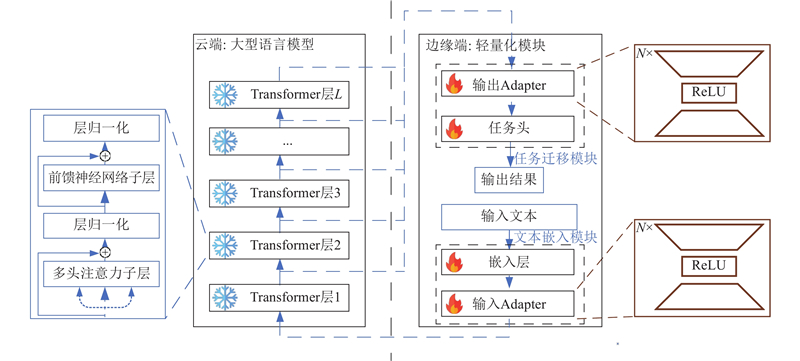
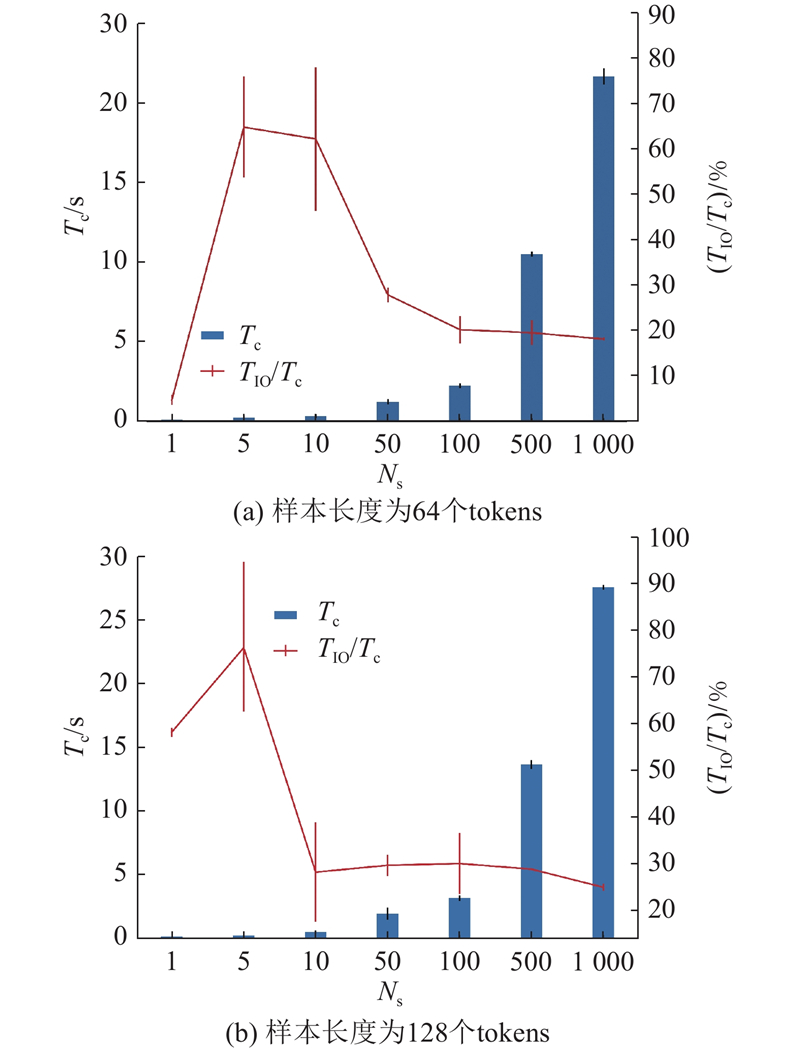
Abstract A lightweight transfer module was introduced to re solve the problem that current pre-trained language models (PLMs) cannot be operated and trained on edge devices due to the excessive number of parameters. The deployment of the transfer module was separated from the large PLM, and an efficient cloud-side collaborative transfer learning framework was implemented, which could transfer PLM to downstream tasks with only a small number of parameters fine-tuned. Cross-domain cloud-side collaborative deployment was also supported. Downstream tasks in multiple domain can collaboratively share the same PLM, which effectively saves computing overhead. Tasks can be efficiently separated and deployed on different devices to realize the separate deployment of multiple tasks and the sharing of PLM. Experiments on four public natural language processing task datasets were conducted, and the results showed that the performance of this framework was over 95% of that of fully fine-tuned BERT methods.
|
|
Received: 07 January 2024
Published: 25 November 2024
|
|
|
| Fund: 国家重点研发计划资助项目(2022ZD0115403);国家自然科学基金资助项目(62072236). |
基于轻量化迁移学习的云边协同自然语言处理方法
为了解决预训练语言模型(PLMs)由于参数量过大而无法在边缘设备上运行和训练的问题,引入轻量化的迁移模块,并将迁移模块和大型预训练语言模型分离部署,实现高效的云边协同迁移学习框架. 利用所提框架,可以在仅微调少量参数的条件下将大型预训练语言模型的表征迁移到下游任务,还可以进行跨领域的云边协同推理. 多个领域的下游任务可以协同共享同一个预训练语言模型,能有效节省计算开销. 任务可以高效地分离部署在不同的设备上,实现多个任务的分离部署和预训练模型共享. 在4项公开自然语言任务数据集上进行实验验证,结果表明,该框架的性能表现能达到完全微调BERT方法的95%以上.
关键词:
自然语言处理,
迁移学习,
云边协同,
计算效率,
模型部署
|
|
| [1] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Minneapolis: Association for Computational Linguistics, 2019: 4171–4186.
|
|
|
| [2] |
LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26). https://arxiv.org/pdf/1907.11692.pdf.
|
|
|
| [3] |
LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [s.l.]: Association for Computational Linguistics, 2020: 7871–7880.
|
|
|
| [4] |
YAN H, DAI J, JI T, et al. A unified generative framework for aspect-based sentiment analysis [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing . [s.l.]: Association for Computational Linguistics, 2021: 2416–2429.
|
|
|
| [5] |
ZHAO Q, MA S, REN S. KESA: a knowledge enhanced approach for sentiment analysis [EB/OL]. (2022-02-24). https://arxiv.org/pdf/2202.12093.pdf.
|
|
|
| [6] |
BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. (2016-05-19). https://arxiv.org/pdf/1409.0473.pdf.
|
|
|
| [7] |
BAPNA A, FIRAT O. Simple, scalable adaptation for neural machine translation [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: Association for Computational Linguistics, 2019: 1538–1548.
|
|
|
| [8] |
AKIYAMA K, TAMURA A, NINOMIYA T. Hie-BART: document summarization with hierarchical BART [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistic . [s.l.]: North American Chapter of the Association for Computational Linguistics, 2021: 159–165.
|
|
|
| [9] |
SHI T, KENESHLOO Y, RAMAKRISHNAN N, et al. Neural abstractive text summarization with sequence-to-sequence models[EB/OL]. (2020-09-18). https://arxiv.org/pdf/1812.02303.pdf.
|
|
|
| [10] |
GUI A, XIAO H. HiFi: high-information attention heads hold for parameter-efficient model adaptation [EB/OL]. (2023-05-08). https://arxiv.org/pdf/2305.04573.pdf.
|
|
|
| [11] |
KOLLURU K, AGGARWAL S, RATHORE V, et al. IMoJIE: iterative memory-based joint open information extraction [C]// Proceedings of the 58th Annual meeting of the Association for Computational Linguistics . [s.l.]: Association for Computational Linguistics, 2020: 5871–5886.
|
|
|
| [12] |
DODGE J, ILHARCO G, SCHWARTZ R, et al. Fine-tuning pretrained language models: weight initializations, data orders, and early stopping [EB/OL]. (2020-02-15). https://arxiv.org/pdf/2002.06305.pdf.
|
|
|
| [13] |
HOWARD J, RUDER S. Universal language model fine-tuning for text classification [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics . Melbourne: Association for Computational Linguistics, 2018: 328–339.
|
|
|
| [14] |
FRENCH R Catastrophic forgetting in connectionist networks[J]. Trends in Cognitive Sciences, 1999, 3 (4): 128- 135
doi: 10.1016/S1364-6613(99)01294-2
|
|
|
| [15] |
DYER E, LEWKOWYCZ A, RAMASESH V. Effect of scale on catastrophic forgetting in neural networks [EB/OL]. (2022-01-29). https://openreview.net/pdf?id=GhVS8_yPeEa.
DYER E, LEWKOWYCZ A, RAMASESH V. Effect of scale on catastrophic forgetting in neural networks [EB/OL]. (2022-01-29). https://openreview.net/pdf?id=GhVS8_yPeEa.
|
|
|
| [16] |
HOULSHY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP [EB/OL]. (2019-06-13). https://arxiv.org/pdf/1902.00751.pdf.
|
|
|
| [17] |
HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. (2021-10-16). https://arxiv.org/pdf/2106.09685.pdf.
|
|
|
| [18] |
LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing . [s.l.]: Association for Computational Linguistics, 2021: 4582–4597.
|
|
|
| [19] |
CHEN J, ZHANG A, SHI X, et al. Parameter-efficient fine-tuning design spaces [EB/OL]. (2023-06-04). https://arxiv.org/pdf/2301.01821.pdf.
|
|
|
| [20] |
HE J, ZHOU C, MA X, et al. Towards a unified view of parameter-efficient transfer learning [EB/OL]. (2022-02-02). https://arxiv.org/pdf/2110.04366.pdf.
|
|
|
| [21] |
DE BARCELOS SILVA A, GOMES M M, DA COSTA C A, et al Intelligent personal assistants: a systematic literature review[J]. Expert Systems with Applications, 2020, 147: 113193
doi: 10.1016/j.eswa.2020.113193
|
|
|
| [22] |
SUN Z, YU H, SONG X, et al. MobileBERT: a compact task-agnostic BERT for resource-limited devices [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [s.l.]: Association for Computational Linguistics, 2020: 2158–2170.
|
|
|
| [23] |
GUO L, CHOE W, LIN F X. STI: turbocharge NLP inference at the edge via elastic pipelining [C]// Proceedings of the 28th ACM International Conference on Architectural Support for Programming languages and Operating Systems . New York: Association for Computing Machinery, 2023: 791–803.
|
|
|
| [24] |
VASWANI A. Attention is all you need [J]. Advances in Neural Information Processing Systems. 2017, 30: 5998–6008.
|
|
|
| [25] |
RADFORD A, TIM S, ILYA S. Improving language understanding by generative pre-training [EB/OL]. [2024-01-01]. https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035.
|
|
|
| [26] |
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2024-01-01]. https://insightcivic.s3.us-east-1.amazonaws.com/language-models.pdf.
|
|
|
| [27] |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C]// LAROCHELLE H, RANZATU M, HADSELL R, et al. Advances in Neural Information Processing Systems: Vol. 33 . [s.l.]: Curran Associates, Inc. , 2020: 1877–1901.
|
|
|
| [28] |
RAFFEL C, SHAZEER N, ROBERTS A, et al Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of Machine Learning Research, 2020, 21 (140): 1- 67
|
|
|
| [29] |
MOOSAVI N S, DELFOSSE Q, KERSTING K, et al. Adaptable Adapters [EB/OL]. (2022-05-03). https://arxiv.org/pdf/2205.01549.pdf.
|
|
|
| [30] |
RUCKLE A, GEIGLE G, GLOCKNER M, et al. AdapterDrop: on the efficiency of adapters in transformers [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing . [s.l.]: Association for Computational Linguistics, 2021: 7930–7946.
|
|
|
| [31] |
KARIMI MAHABADI R, HENDERSON J, RUDER S. Compacter: efficient low-rank hypercomplex adapter layers [C]// Advances in Neural Information Processing Systems: Vol. 34 . [s.l.]: Curran Associates, Inc. , 2021: 1022–1035.
|
|
|
| [32] |
CARTAS A, KOCOUR M, RAMAN A, et al. A reality check on inference at mobile networks edge [C]// Proceedings of the 2nd International Workshop on Edge Systems, Analytics and Networking . New York: Association for Computing Machinery, 2019: 54–59.
|
|
|
| [33] |
TAMBE T, HOOPER C, PENTECOST L, et al. EdgeBERT: sentence-level energy optimizations for latency-aware multi-task NLP inference [C]// MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture . New York: Association for Computing Machinery, 2021: 830–844.
|
|
|
| [34] |
BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. (2016-07-21). https://arxiv.org/pdf/1607.06450.pdf.
|
|
|
| [35] |
BENTIVOGLI L, CLARK P, DAGAN I, et al. The fifth PASCAL recognizing textual entailment challenge [J]. TAC . 2009, 7(8): 1.
|
|
|
| [36] |
DAGAN I, GLICKMAN O, MAGNINI B. The PASCAL Recognising textual entailment challenge [M]// QUIÑONERO-CANDELA J, DAGAN I, MAGNINI B, et al. Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment . Berlin: Springer Berlin Heidelberg, 2006: 177–190.
|
|
|
| [37] |
BAR-HAIM R, DAGAN I, DOLAN B, et al. The second pascal recognising textual entailment challenge [C]// Proceedings of the 2nd PASCAL Challenges Workshop on Recognising Textual Entailment . [s.l.]: MSRA, 2006: 1.
|
|
|
| [38] |
GIAMPICCOLO D, MAGNINI B, DAGAN I, et al. The third PASCAL recognizing textual entailment challenge [C]// Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing . Prague: Association for Computational Linguistics, 2007: 1–9.
|
|
|
| [39] |
WARSTADT A, SINGH A, BOWMAN S R. Neural network acceptability judgments [EB/OL]. (2019-10-01). https://arxiv.org/pdf/1805.12471.pdf.
|
|
|
| [40] |
DOLAN W B, BROCKETT C. Automatically constructing a corpus of sentential paraphrases [C]// Proceedings of the third International Workshop on Paraphrasing . [s.l.]: IWP, 2005.
|
|
|
| [41] |
CER D, DIAB M, AGIRRE E, et al. SemEval-2017 task 1: semantic textual similarity multilingual and crosslingual focused evaluation [C]// Proceedings of the 11th International Workshop on Semantic Evaluation . Vancouver: Association for Computational Linguistics, 2017: 1–14.
|
|
|
| [42] |
LHONEST Q, VILLANOVA DEL MORAL A, JERNITE Y, et al. Datasets: a community library for natural language processing [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations . [s.l.]: Association for Computational Linguistics, 2021: 175–184.
|
|
|
| [43] |
WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations . [s.l.]: Association for Computational Linguistics, 2020: 38–45.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|