|
|
|
| Imitation learning for bipedal robots based on simplified probabilistic framework for options |
Wen XUE( ),Shuo ZHAO,Yongqiang LI*() ),Shuo ZHAO,Yongqiang LI*() |
| College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China |
|
|
|
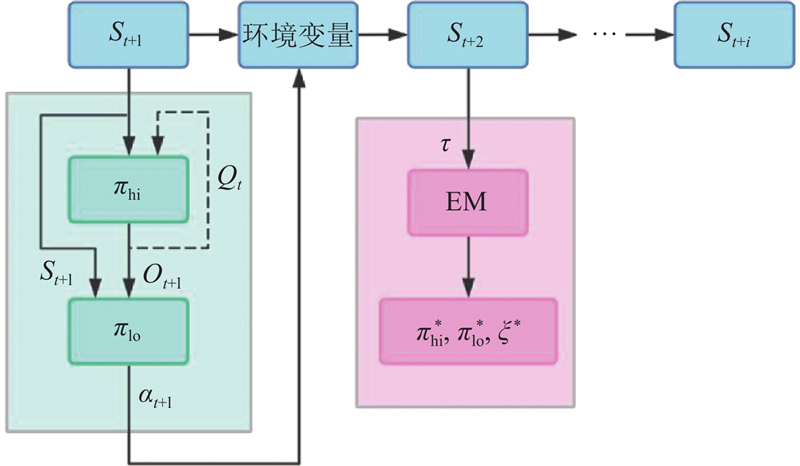
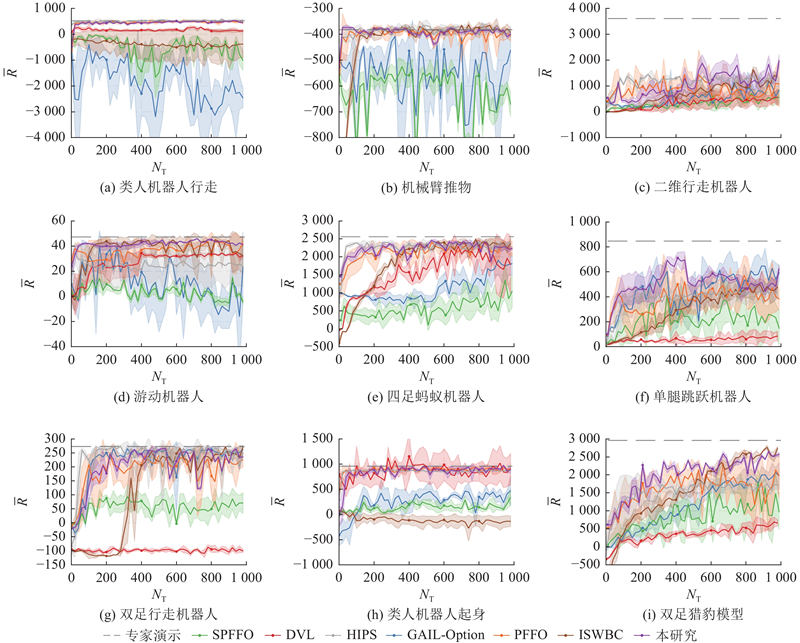
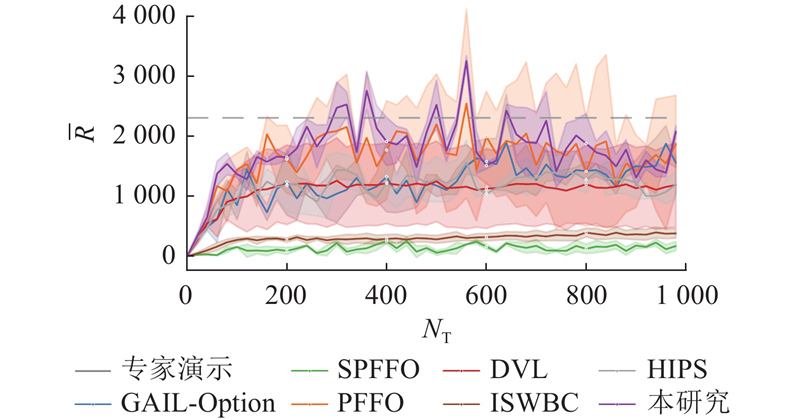
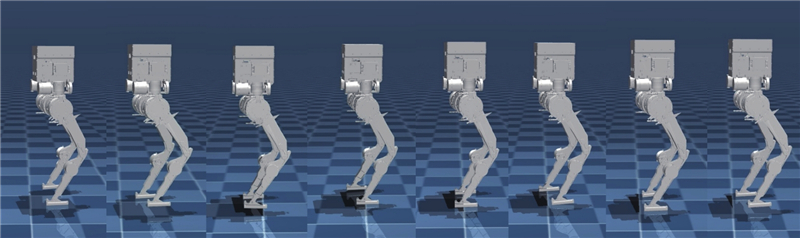
Abstract To address the limitation of imitation learning methods caused by expert data that does not explicitly satisfy Markov properties, a hierarchical imitation learning method based on a simplified probabilistic framework for options was proposed. By retaining option variables and removing termination variables, a compact strategy modeling framework was constructed. In the optimization process, the expectation maximization algorithm was combined to model latent variables, and the Lagrange multiplier method was introduced to handle constraints such as policy normalization. Simulation experiments on multiple typical continuous action control tasks were conducted, and the training performance was compared with various imitation learning methods. Results indicate that the proposed method has a more stable training process and better policy convergence under non-Markov conditions. Furthermore, the imitation learning model was applied to the simulation of bipedal robots, achieving stable forward walking and verifying the feasibility and effectiveness of the simplified probabilistic framework for options.
|
|
Received: 16 August 2025
Published: 06 May 2026
|
|
|
| Fund: 国家自然科学基金资助项目(U2341216). |
|
Corresponding Authors:
Yongqiang LI
E-mail: xuewen_xw@163.com;yqli@zjut.edu.cn
|
基于简化概率选择框架的双足机器人模仿学习
专家数据未显式满足马尔可夫性质会限制模仿学习方法的有效性,为此提出基于简化概率选择框架的分层模仿学习方法. 通过保留选项变量并去除终止变量, 构建紧凑的策略建模框架. 在优化过程中, 结合期望最大化算法进行隐变量建模, 引入拉格朗日乘子法进行约束条件处理(如策略归一性). 在多个典型连续动作控制任务中开展仿真实验, 对比不同模仿学习方法的训练性能. 结果表明, 所提方法在非马尔可夫条件下训练过程更稳定、策略收敛性更佳. 将该模仿学习模型应用于双足机器人仿真, 实现了机器人稳定的前向行走, 验证了简化概率选择框架的可行性与有效性.
关键词:
双足机器人,
模仿学习,
隐变量建模,
期望最大化算法,
拉格朗日优化
|
|
| [1] |
LI Z, PENG X B, ABBEEL P, et al Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control[J]. The International Journal of Robotics Research, 2025, 44 (5): 840- 888
doi: 10.1177/02783649241285161
|
|
|
| [2] |
RAIBERT M H, BROWN H B Jr, CHEPPONIS M Experiments in balance with a 3D one-legged hopping machine[J]. The International Journal of Robotics Research, 1984, 3 (2): 75- 92
doi: 10.1177/027836498400300207
|
|
|
| [3] |
CASTILLO G A, WENG B, ZHANG W, et al Reinforcement learning-based cascade motion policy design for robust 3D bipedal locomotion[J]. IEEE Access, 2022, 10: 20135- 20148
doi: 10.1109/ACCESS.2022.3151771
|
|
|
| [4] |
GULIYEV Z, PARSAYAN A. Reinforcement learning based robot control [C]// Proceedings of the IEEE 16th International Conference on Application of Information and Communication Technologies. Washington DC: IEEE, 2023: 1–6.
|
|
|
| [5] |
WANG S, BRAAKSMA J, BABUSKA R, et al. Reinforcement learning control for biped robot walking on uneven surfaces [C]// Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings. Vancouver: IEEE, 2006: 4173–4178.
|
|
|
| [6] |
SHAO Y, JIN Y, HUANG Z, et al A learning-based control pipeline for generic motor skills for quadruped robots[J]. Journal of Zhejiang University: Science A, 2024, 25 (6): 443- 454
doi: 10.1631/jzus.A2300128
|
|
|
| [7] |
JIN Y, LIU X, SHAO Y, et al High-speed quadrupedal locomotion by imitation-relaxation reinforcement learning[J]. Nature Machine Intelligence, 2022, 4 (12): 1198- 1208
doi: 10.1038/s42256-022-00576-3
|
|
|
| [8] |
KIM J W, ZHAO T Z, SCHMIDGALL S, et al. Surgical robot transformer (SRT): imitation learning for surgical tasks [EB/OL]. (2024−07−17)[2025−06−11]. https://arxiv.org/pdf/2407.12998.
|
|
|
| [9] |
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019, 575 (7782): 350- 354
doi: 10.1038/s41586-019-1724-z
|
|
|
| [10] |
丁加涛, 何杰, 李林芷, 等 基于模型预测控制的仿人机器人实时步态优化[J]. 浙江大学学报: 工学版, 2019, 53 (10): 1843- 1851
DING Jiatao, HE Jie, LI Linzhi, et al Real-time walking pattern optimization for humanoid robot based on model predictive control[J]. Journal of Zhejiang University: Engineering Science, 2019, 53 (10): 1843- 1851
|
|
|
| [11] |
秦海鹏, 秦瑞, 施晓芬, 等 基于模型预测的四足机器人运动控制[J]. 浙江大学学报: 工学版, 2024, 58 (8): 1565- 1576
QIN Haipeng, QIN Rui, SHI Xiaofen, et al Motion control of quadruped robot based on model prediction[J]. Journal of Zhejiang University: Engineering Science, 2024, 58 (8): 1565- 1576
|
|
|
| [12] |
AHN K, MHAMMEDI Z, MANIA H, et al. Model predictive control via on-policy imitation learning [EB/OL]. (2022−10−17)[2025−06−11]. https://arxiv.org/pdf/2210.09206.
|
|
|
| [13] |
TAGLIABUE A, HOW J P. Output feedback tube MPC-guided data augmentation for robust, efficient sensorimotor policy learning [C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 8644−8651.
|
|
|
| [14] |
DUAN H, DAO J, GREEN K, et al. Learning task space actions for bipedal locomotion [C]// Proceedings of the IEEE International Conference on Robotics and Automation. Xi’an: IEEE, 2021: 1276–1282.
|
|
|
| [15] |
SATO M A, NAKAMURA Y, ISHII S. Reinforcement learning for biped locomotion [C]// Artificial Neural Networks — ICANN 2002. Berlin: Springer, 2002: 777–782.
|
|
|
| [16] |
PETERS J, VIJAYAKUMAR S, SCHAAL S. Reinforcement learning for humanoid robotics [C]// Proceedings of the Third IEEE-RAS International Conference on Humanoid Robots. Karlsruhe: [s.n.], 2003: 1–20.
|
|
|
| [17] |
PENG X B, ABBEEL P, LEVINE S, et al DeepMimic: example-guided deep reinforcement learning of physics-based character skills[J]. ACM Transactions on Graphics, 2018, 37 (4): 1- 14
|
|
|
| [18] |
PENG X B, KANAZAWA A, MALIK J, et al SFV: reinforcement learning of physical skills from videos[J]. ACM Transactions on Graphics, 2018, 37 (6): 1- 14
|
|
|
| [19] |
GALLJAMOV R, ZHAO G, BELOUSOV B, et al. Improving sample efficiency of example-guided deep reinforcement learning for bipedal walking [C]// Proceedings of the IEEE-RAS 21st International Conference on Humanoid Robots. Ginowan: IEEE, 2023: 587–593.
|
|
|
| [20] |
JUDAH K, FERN A, TADEPALLI P, et al Imitation learning with demonstrations and shaping rewards[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2014, 28 (1): 1
doi: 10.1609/aaai.v28i1.9024
|
|
|
| [21] |
WEI T, LUO Q, MO Y, et al Design of the three-bus control system utilising periodic relay for a centipede-like robot[J]. Robotica, 2016, 34 (8): 1841- 1854
doi: 10.1017/S0263574714002628
|
|
|
| [22] |
WANG D, BELTRAME G. Deployable reinforcement learning with variable control rate [EB/OL]. (2024–04–02)[2025–06–11]. https://arxiv.org/pdf/2401.09286.
|
|
|
| [23] |
PAN Z, YIN S, WEN G, et al Reinforcement learning control for a three-link biped robot with energy-efficient periodic gaits[J]. Acta Mechanica Sinica, 2023, 39 (2): 522304
doi: 10.1007/s10409-022-22304-x
|
|
|
| [24] |
AGRAWAL R, DAHLIN N, JAIN R, et al Markov balance satisfaction improves performance in strictly batch offline imitation learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2025, 39 (15): 15311- 15319
|
|
|
| [25] |
DANIEL C, VAN HOOF H, PETERS J, et al Probabilistic inference for determining options in reinforcement learning[J]. Machine Learning, 2016, 104 (2): 337- 357
|
|
|
| [26] |
ZHANG Z, PASCHALIDIS I. Provable hierarchical imitation learning via EM [C]// Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS). San Diego: PMLR, 2021, 130: 883–891.
|
|
|
| [27] |
JING M, HUANG W, SUN F, et al. Adversarial option-aware hierarchical imitation learning [C]// Proceedings of the International Conference on Machine Learning (ICML). [S. l.]: PMLR, 2021: 5097–5106.
|
|
|
| [28] |
LI Z, XU T, QIN Z, et al. Imitation learning from imperfection: theoretical justifications and algorithms [C]// 37th Conference on Neural Information Processing Systems. 2023: 1−40.
|
|
|
| [29] |
SIKCHI H S, ZHENG Q, ZHANG A, et al. Dual RL: unification and new methods for reinforcement and imitation learning [C]// Proceedings of the International Conference on Learning Representations. Vienna: [s.n.], 2024: 1−48.
|
|
|
| [30] |
KUJANPÄÄ K, PAJARINEN J, ILIN A. Hierarchical imitation learning with vector quantized models [C]// Proceedings of the 40th International Conference on Machine Learning (ICML). [S.l.]: PMLR, 2023: 17896–17919.
|
|
|
| [31] |
GRANDIA R, JENELTEN F, YANG S, et al Perceptive locomotion through nonlinear model-predictive control[J]. IEEE Transactions on Robotics, 2023, 39 (5): 3402- 3421
doi: 10.1109/TRO.2023.3275384
|
|
|
| [32] |
DARIO BELLICOSO C, GEHRING C, HWANGBO J, et al. Perception-less terrain adaptation through whole body control and hierarchical optimization [C]// Proceedings of the IEEE-RAS 16th International Conference on Humanoid Robots. Cancun: IEEE, 2017: 558–564.
|
|
|
| [33] |
SLEIMAN J P, FARSHIDIAN F, MINNITI M V, et al A unified MPC framework for whole-body dynamic locomotion and manipulation[J]. IEEE Robotics and Automation Letters, 2021, 6 (3): 4688- 4695
doi: 10.1109/LRA.2021.3068908
|
|
|
| [34] |
YI X, CARAMANIS C. Regularized EM algorithms: a unified framework and statistical guarantees [C]// Proceedings of the 28th Advances in Neural Information Processing Systems (NeurIPS). [S.l.]: Curran Associates, Inc. , 2015: 1567−1575.
|
|
|
| [35] |
SUTTON R S, PRECUP D, SINGH S Between MDPs and semi-MDPs: a framework for temporal abstraction in reinforcement learning[J]. Artificial Intelligence, 1999, 112 (1/2): 181- 211
doi: 10.1016/s0004-3702(99)00052-1
|
|
|
| [36] |
BACON P L, HARB J, PRECUP D. The option-critic architecture [J]. Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.]: AAAI, 2017: 1726–1734.
|
|
|
| [37] |
KHREICH W, GRANGER E, MIRI A, et al On the memory complexity of the forward–backward algorithm[J]. Pattern Recognition Letters, 2010, 31 (2): 91- 99
doi: 10.1016/j.patrec.2009.09.023
|
|
|
| [38] |
PENG X B, MA Z, ABBEEL P, et al. AMP: adversarial motion priors for stylized physics-based character control [EB/OL]. (2022−05−12)[2025−06−11]. https://arxiv.org/pdf/2104.02180.
|
|
|
| [39] |
TAN J, ZHANG T, COUMANS E, et al. Sim-to-real: learning agile locomotion for quadruped robots [EB/OL]. (2018–05–16)[2025–06–11]. https://arxiv.org/pdf/1804.10332.
|
|
|
| [40] |
PENG X B, BERSETH G, VAN DE PANNE M Terrain-adaptive locomotion skills using deep reinforcement learning[J]. ACM Transactions on Graphics, 2016, 35 (4): 1- 12
doi: 10.1145/2897824.2925881
|
|
|
| [41] |
KIM D, DI CARLO J, KATZ B, et al. Highly dynamic quadruped locomotion via whole-body impulse control and model predictive control [EB/OL]. (2019−09−14)[2025−06−11]. https://arxiv.org/pdf/1909.06586.
|
|
|
| [42] |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on Machine Learning. [S.l.]: PMLR, 2015: 448−456.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|