| Automation Technology, Computer Technology |
|


|
|
|
| Convolutional neural network acceleration algorithm based on filters pruning |
Hao LI( ),Wen-jie ZHAO*(),Bo HAN ),Wen-jie ZHAO*(),Bo HAN |
| College of Aeronautics and Astronautics, Zhejiang University, Hangzhou 310027, China |
|
|
|
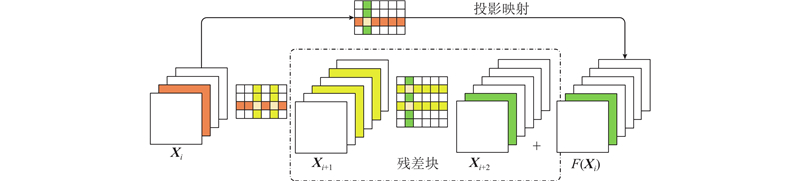
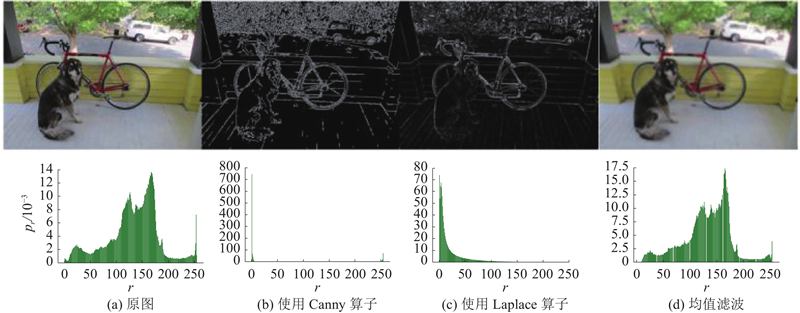
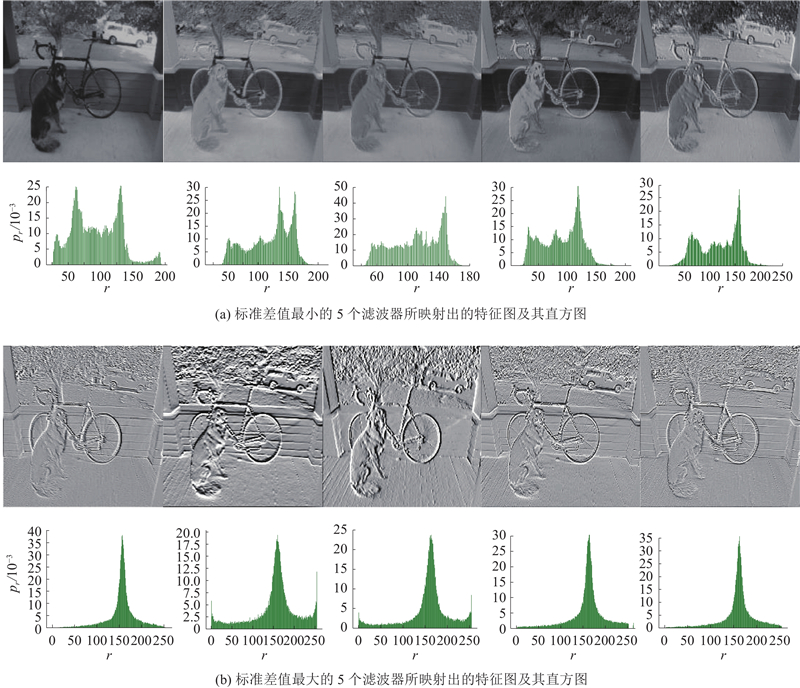
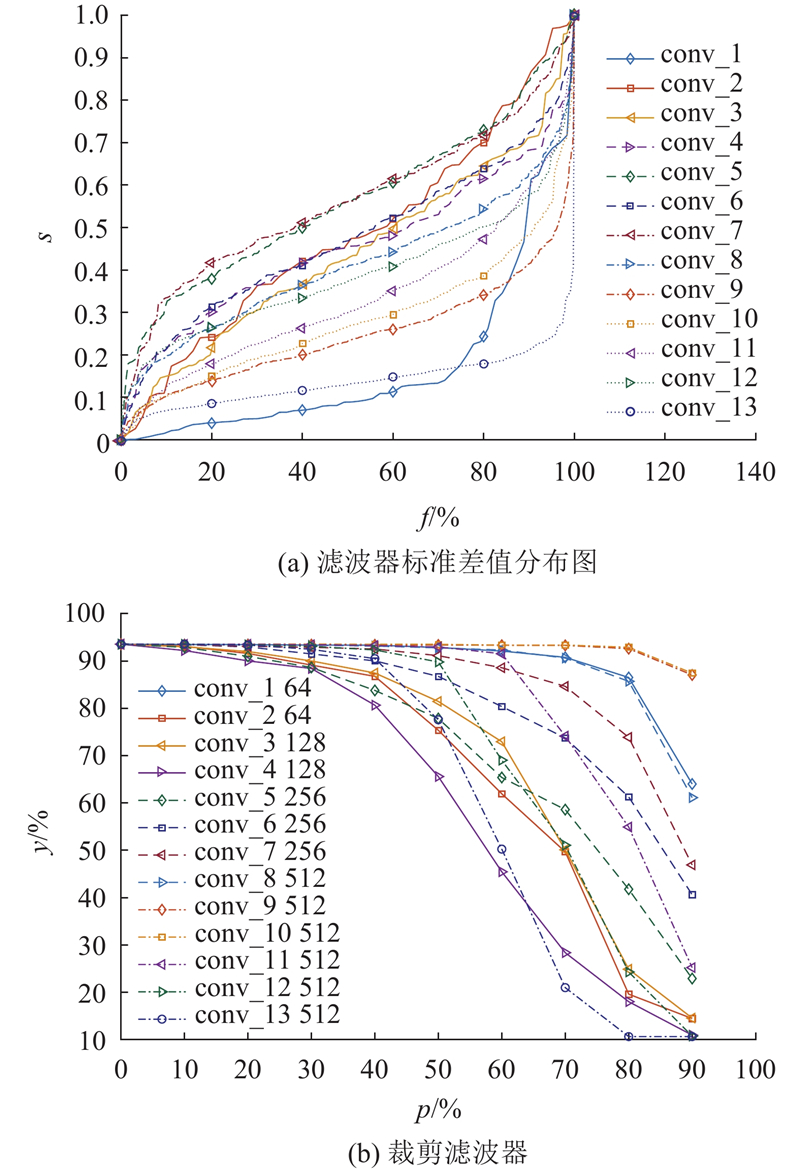
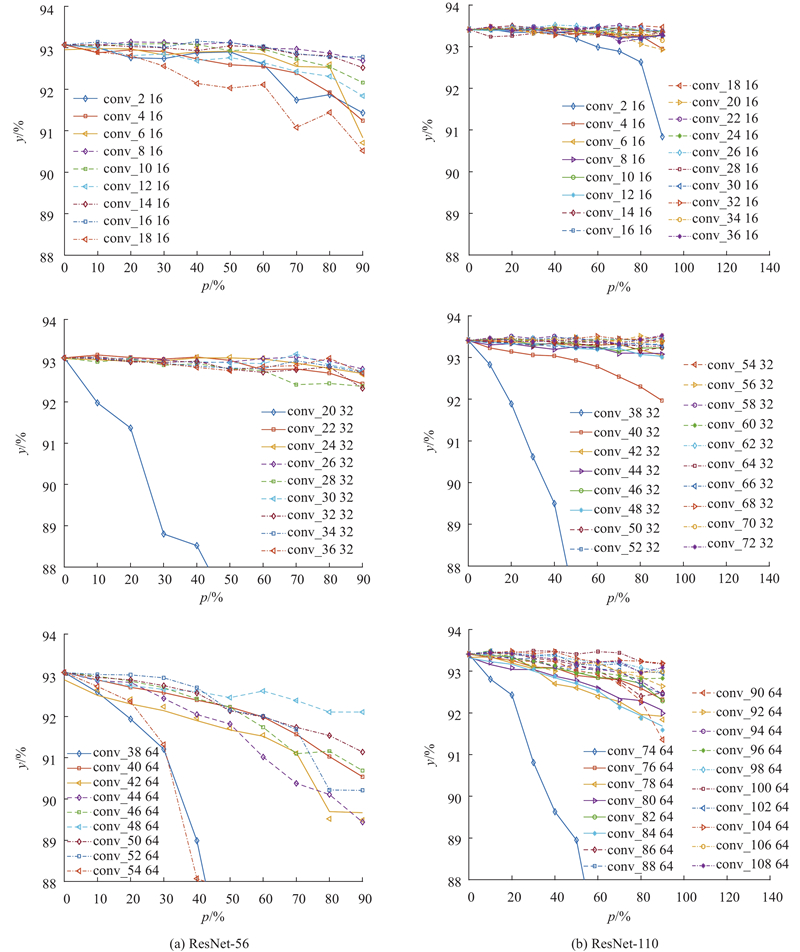
Abstract A new model acceleration algorithm of convolutional neural network (CNN) was proposed based on filters pruning in order to promote the compression and acceleration of the CNN model. The computational cost could be effectively reduced by calculating the standard deviation of filters in the convolutional layer to measure its importance and pruning filters with less influence on the accuracy of the neural network and its corresponding feature map. The algorithm did not cause the network to be sparsely connected unlike the method of pruning weight value, so there was no need of the support of special sparse convolution libraries. The experimental results based on the CIFAR-10 dataset show that the filters pruning algorithm can accelerate the VGG-16 and ResNet-110 models by more than 30%. Results can be close to or reach the accuracy of the original model by fine-tuning the inherited pre-training parameters.
|
|
Received: 05 December 2018
Published: 30 September 2019
|
|
|
|
Corresponding Authors:
Wen-jie ZHAO
E-mail: lhmzl2012@163.com;zhaowenjie8@zju.edu.cn
|
基于滤波器裁剪的卷积神经网络加速算法
针对卷积神经网络(CNN)模型的压缩和加速问题,提出基于滤波器裁剪的新型卷积神经网络模型加速算法. 通过计算卷积层中滤波器的标准差值衡量该滤波器的重要程度,裁剪对神经网络准确率影响较小的滤波器及对应的特征图,可以有效地降低计算成本. 与裁剪权重不同,该算法不会导致网络稀疏连接,不需要应用特殊的稀疏矩阵计算库. 基于CIFAR-10数据集的实验结果表明,该滤波器裁剪算法能够对VGG-16和ResNet-110模型加速30%以上,通过微调继承的预训练参数可以使结果接近或达到原始模型的精度.
关键词:
深度学习,
卷积神经网络(CNN),
模型压缩,
滤波器,
特征图
|
|
| [1] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C] // International Conference on Neural Information Processing Systems. Lake Tahoe: Curran Associates Inc., 2012.
|
|
|
| [2] |
GRAVES A, SCHMIDHUBER J Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Netw, 2005, 18 (5): 602- 610
|
|
|
| [3] |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C] // International Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2818-2826.
|
|
|
| [4] |
DENIL M, SHAKIBI B, DINH L, et al. Predicting parameters in deep learning [C] // Advances in Neural Information Processing Systems. Lake Tahoe: MIT, 2013: 2148-2156.
|
|
|
| [5] |
SRINIVAS S, BABU R V. Data-free parameter pruning for deep neural networks [EB/OL]. [2018-09-06]. http://arxiv.org/abs/1507.06149.
|
|
|
| [6] |
HAN S, POOL J, TRAN J, et al. Learning both weights and connections for efficient neural network [C] // Advances in Neural Information Processing Systems. Montreal: MIT, 2015: 1135-1143.
|
|
|
| [7] |
MARIET Z, SRA S. Diversity networks: neural network compression using determinantal point processes [EB/OL]. [2018-05-13]. http://arxiv.org/abs/1511.05077.
|
|
|
| [8] |
HAN S, MAO H, DALLY W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding [EB/OL]. [2018-08-09]. http://arxiv.org/abs/1510.00149.
|
|
|
| [9] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2018-07-22]. http://arxiv.org/abs/1409.1556.
|
|
|
| [10] |
IANDOLA F N, HAN S, MOSKEWICZ M W, et al. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and < 0.5 mb model size [EB/OL]. [2018-07-14]. http://arxiv.org/abs/1602.07360.
|
|
|
| [11] |
HAN S, LIU X, MAO H, et al EIE: efficient inference engine on compressed deep neural network[J]. ACM Sigarch Computer Architecture News, 2016, 44 (3): 243- 254
doi: 10.1145/3007787.3001163
|
|
|
| [12] |
MATHIEU M, HENAFF M, LECUN Y. Fast training of convolutional networks through FFTs [EB/OL]. [2018-09-03]. http://arxiv.org/abs/1312.5851.
|
|
|
| [13] |
RASTEGARI M, ORDONEZ V, REDMON J, et al. XNOR-Net: ImageNet classification using binary convolutional neural networks [C] // European Conference on Computer Vision. Cham: Springer, 2016: 525-542.
|
|
|
| [14] |
WEN W, WU C, WANG Y, et al. Learning structured sparsity in deep neural networks [C] // Advances in Neural Information Processing Systems. Barcelona: MIT, 2016: 2074-2082.
|
|
|
| [15] |
LI H, KADAV A, DURDANOVIC I, et al. Pruning filters for efficient convents [EB/OL]. [2018-09-11]. http://arxiv.org/abs/1608.08710.
|
|
|
| [16] |
MITTAL D, BHARDWAJ S, KHAPRA M M, et al. Recovering from random pruning: on the plasticity of deep convolutional neural networks [EB/OL]. [2018-09-12]. http://arxiv.org/abs/1801.10447.
|
|
|
| [17] |
ZHU M, GUPTA S. To prune, or not to prune: exploring the efficacy of pruning for model compression [EB/OL]. [2018-06-23]. http://arxiv.org/abs/1710.01878.
|
|
|
| [18] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [19] |
ZAGORUYKO S. 92.45% on CIFAR-10 in Torch[EB/OL].[2018-07-30]. http://torch.ch/blog/2015/07/30/cifar.html.
|
|
|
| [20] |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [EB/OL]. [2018-07-16]. http://arxiv.org/abs/1502.03167.
|
|
|
| [21] |
HU H, PENG R, TAI Y W, et al. Network trimming: a data-driven neuron pruning approach towards efficient deep architectures [EB/OL]. [2018-07-19]. http://arxiv.org/abs/1607.03250.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|