1. School of Control Science and Engineering, Shandong University, Jinan 250061, China 2. Jinan Haoyuan Automatic Control System Engineering Limited Company, Jinan 250061, China
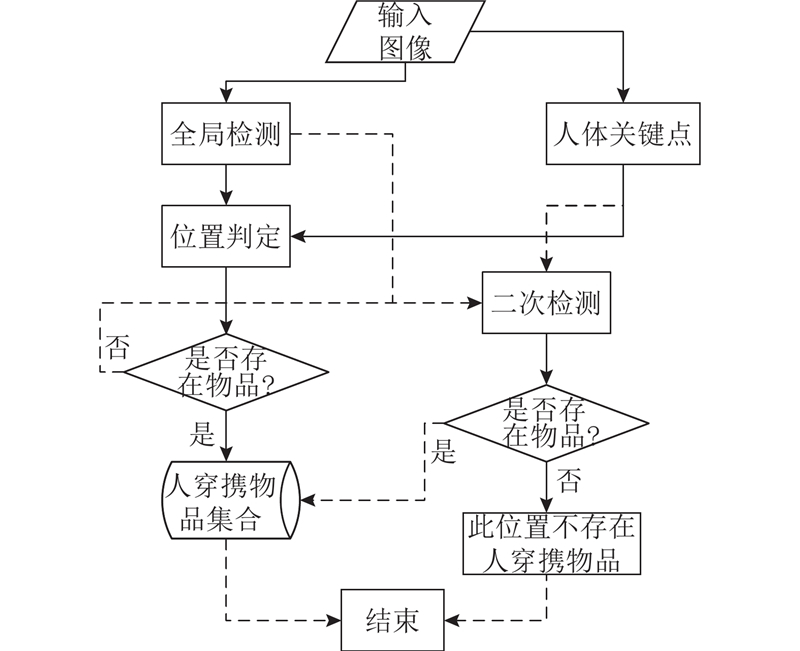
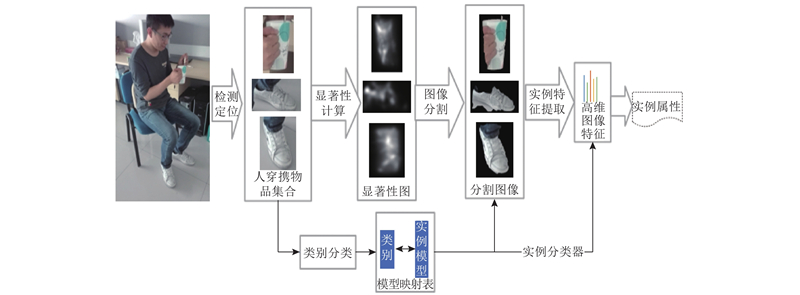
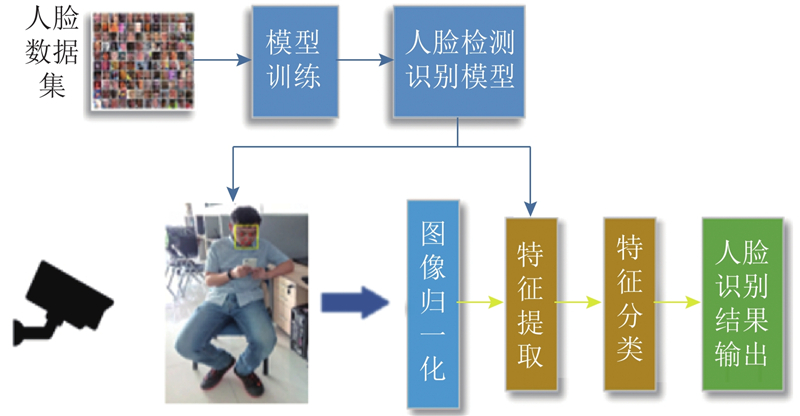
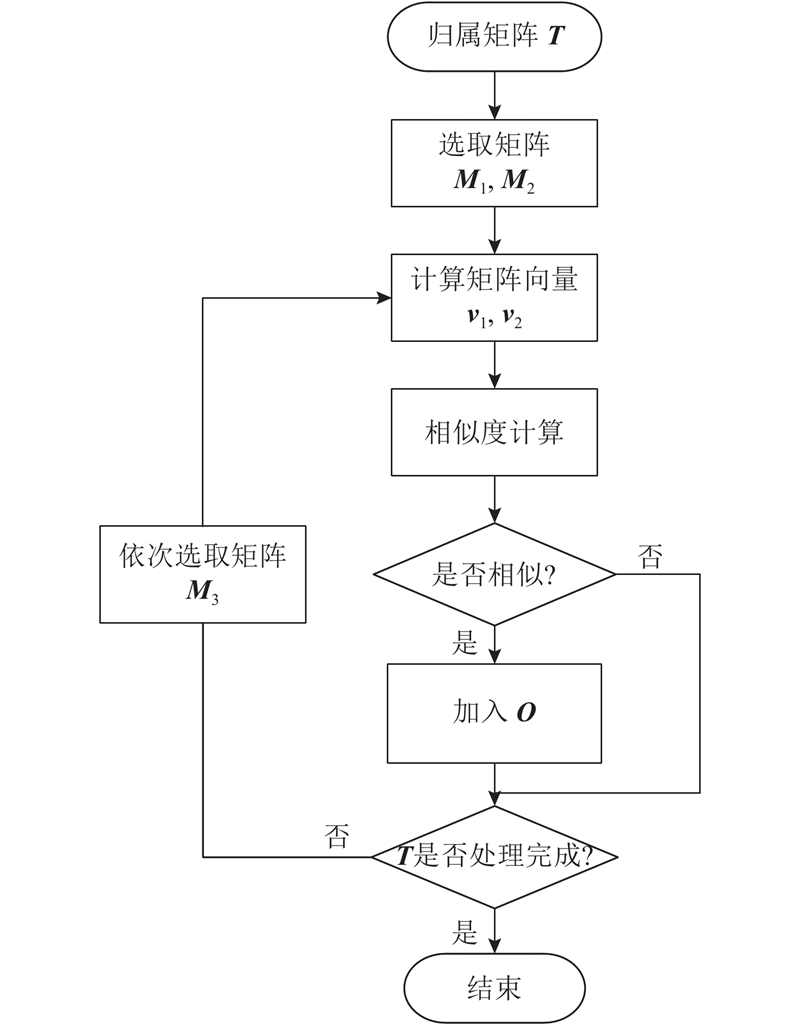
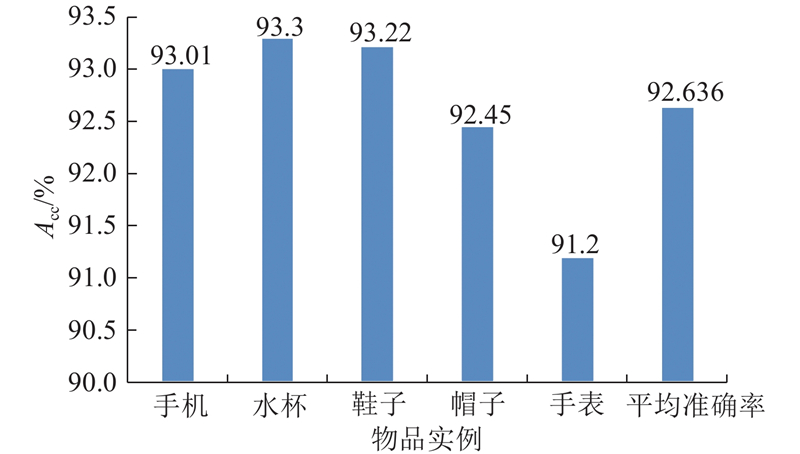
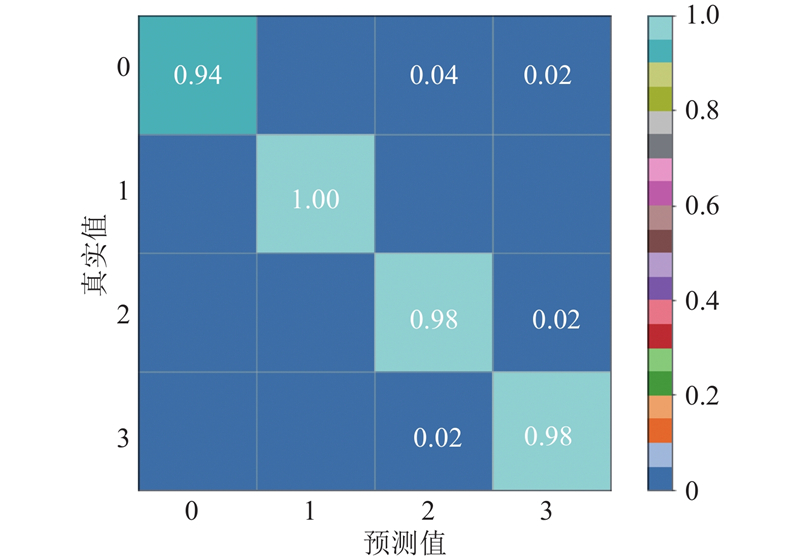
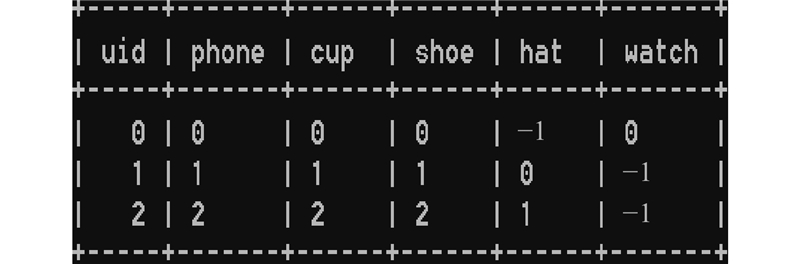
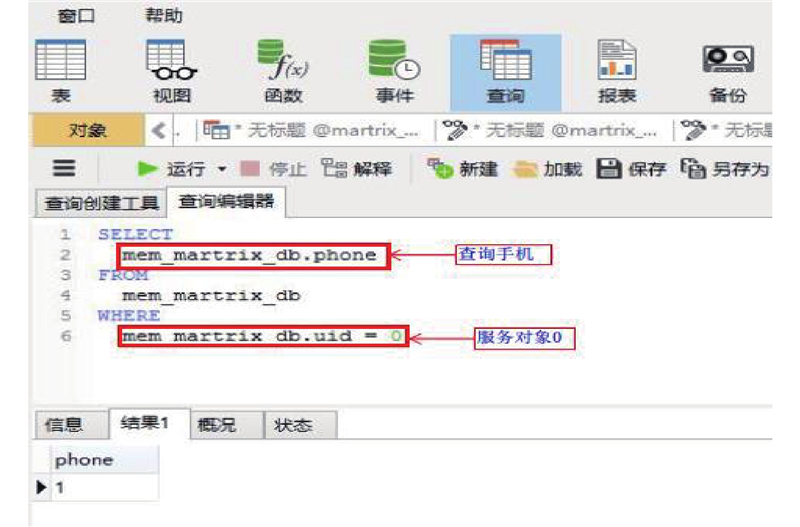
It is necessary for service robots to have the ability to independently obtain the attribution relationship between people and their carrying objects in order to satisfy the requirements of robot personalized service and enable robots to select exclusive objects to perform inference and planning according to different service individual. A self-learning framework for the attribution relationship between people and their carrying objects was proposed aiming at the problem of the attribution relationship between people carrying objects and people in the family environment. The method of detecting and locating people carrying objects was used based on the object detection model SSD and the human posture estimation model OpenPose in order to realize the detection of human carrying objects. The face detection and recognition model MTCNN were used to complete the service individual identification by extracting the objects features by convolutional neural network based on migration learning and using the backend classifier to complete the object instance attribute identification. The self-learning of the attribution relationship was completed through the self-learning strategy. The experimental results show that the proposed self-learning framework for attribution relationship of people carrying objects can accurately and efficiently complete the learning of attribution relationship, effectively eliminating the influence of environmental interference factors on attribution learning. The proposed framework has good accuracy and robustness.
Hao WU,Wen-jing LI,Guo-hui TIAN,Zhao-wei CHEN,Yong YANG. Self-learning framework for attribution relationship of people carrying objects under family environment. Journal of ZheJiang University (Engineering Science), 2019, 53(7): 1315-1322.
HSIEH J W, CHENG J C, CHEN L C, et al Handheld object detection and its related event analysis using ratio histogram and mixture of HMMs[J]. Journal of Visual Communication and Image Representation, 2014, 25 (6): 1399- 1415
doi: 10.1016/j.jvcir.2014.05.009
[2]
RIVERA-RUBIO J, IDREES S, ALEXIOU I, et al. A dataset for hand-held object recognition [C] // IEEE International Conference on Image Processing. Paris: IEEE, 2015: 5881-5885.
[3]
LV X, JIANG S Q, HERRANZ L, et al RGB-D hand-held object recognition based on heterogeneous feature fusion[J]. Computer Science and Technology, 2015, 30 (2): 340- 352
doi: 10.1007/s11390-015-1527-0
[4]
LI X, JIANG S Q, LV X, et al. Learning to recognize hand-held objects from scratch [C] // Advances in Multimedia Information Processing. Berlin: Springer, 2016: 527–539.
[5]
YAMAGUCHI K, KIAPOUR M H, ORTIZ L E, et al. Parsing clothing in fashion photographs [C] // Computer Vision and Pattern Recognition. Phode Island: IEEE, 2012: 3570-3577.
[6]
LIANG X D, XU C Y, SHEN X H, et al. Human parsing with contextualized convolutional neural network [C] // IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1386-1394.
[7]
GONG K, LIANG X D, ZHANG D Y, et al. Look into person: self-supervised structure-sensitive learning and a new benchmark for human parsing [C] // IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 932-940.
[8]
CHEN X J, MOTTAGHI R, LIU X B, et al. Detect what you can: detecting and representing objects using holistic models and body parts [C] // Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 1979-1986.
[9]
LI J S, ZHAO J, WEI Y C, et al. Towards real world human parsing: multiple-human parsing in the wild [C] // Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017.
[10]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C] // European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
[11]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C] // Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2999-3007.
[12]
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C] // Proceedings of the 32nd International Conference on Machine Learning. Coimbra: ACM, 2015: 448-456.
[13]
SARAFIANOS N, BOTEANU B, IONESCU B, et al 3D human pose estimation: a review of the literature and analysis of covariates[J]. Computer Vision and Image Understanding, 2016, 152: 1- 20
doi: 10.1016/j.cviu.2016.09.002
[14]
CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields [C] // Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1302-1310.
[15]
CHENG M M. Saliency and similarity detection for image scene analysis [D]. Tianjin: NanKai University, 2012: 33-56.
[16]
ZHAO Z Q, HUANG D S, SUN B Y Human face recognition based on multi-features using neural networks committee[J]. Pattern Recognition Letters, 2004, 25 (12): 1351- 1358
doi: 10.1016/j.patrec.2004.05.008
[17]
GEETHA K P, VADIVELU S S, SINGH N A. Human face recognition using neural networks [C] // Radio Science Conference. Cairo: IEEE, 2012: 260-263.
[18]
YANG S, LUO P, CHEN C L, et al. WIDER FACE: a face detection benchmark [C] // Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 5525-5533.
[19]
LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C] // Proceedings of the IEEE International Conference on Computer Vision. Boston: IEEE, 2015: 3730-3738.
[20]
WANG M, DENG W. Deep face recognition: a survey [C] // Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 471-478.
[21]
ZHANG K, ZHANG Z, LI Z, et al Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23 (10): 1499- 1503
doi: 10.1109/LSP.2016.2603342