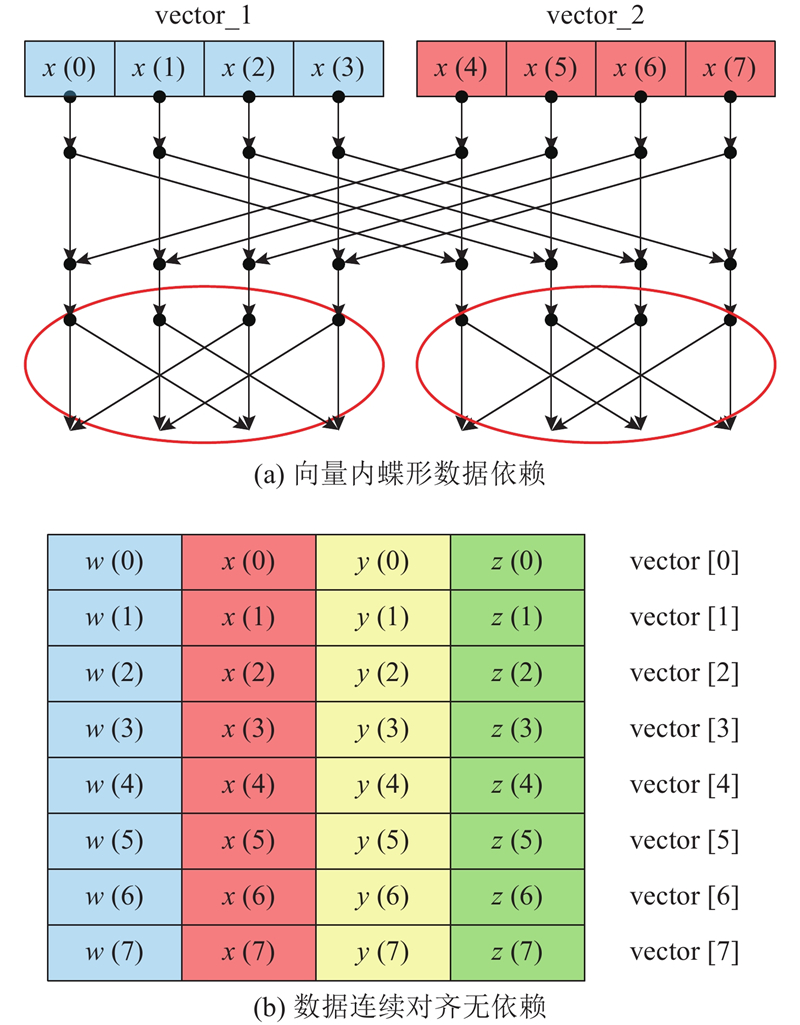
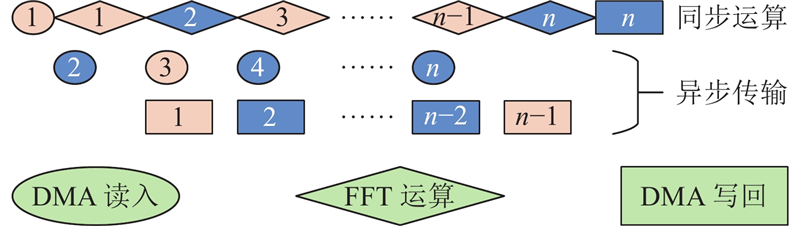
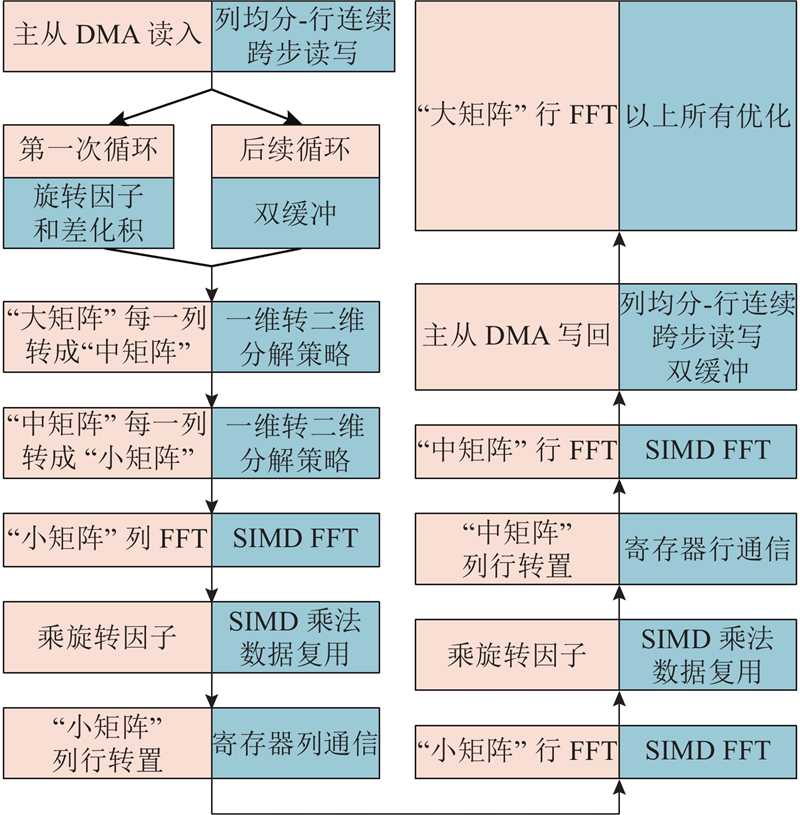
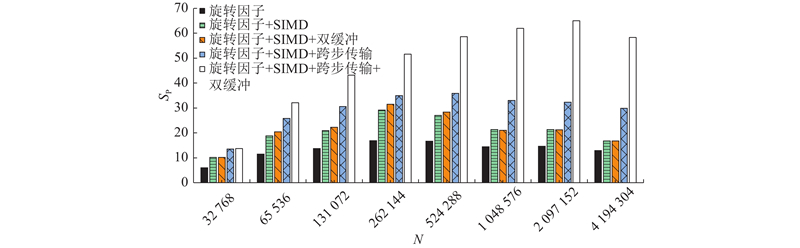
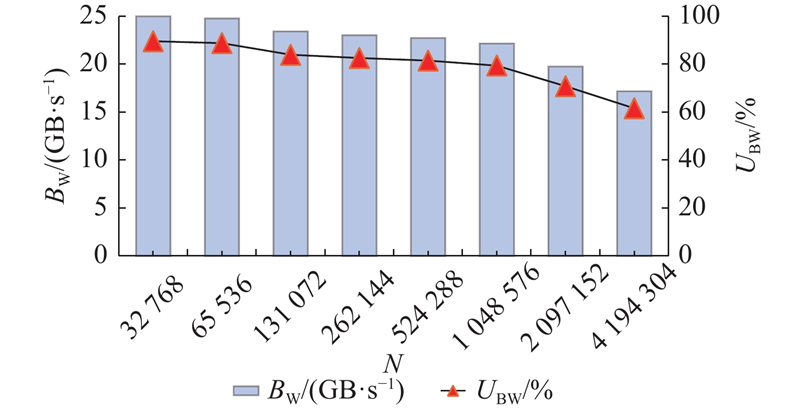
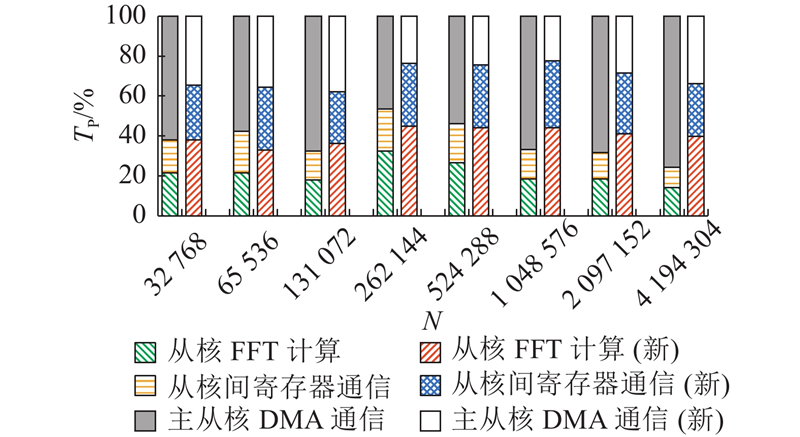
| 计算机技术 |
|

|
|
|
| 大点数FFT在“申威26010”上的并行优化 |
郭俊1,2( ),刘鹏3,杨昕遥4,张鲁飞5,吴东5 ),刘鹏3,杨昕遥4,张鲁飞5,吴东5 |
1. 湖州职业技术学院 信息工程与物联网学院,浙江 湖州 313000
2. 湖州职业技术学院 湖州市物联网智能系统集成技术重点实验室,浙江 湖州 313000
3. 浙江大学 信息与电子工程学院,浙江 杭州 310027
4. 蚂蚁科技集团股份有限公司,浙江 杭州 310013
5. 数学工程与先进计算国家重点实验室,江苏 无锡 214125 |
|
| Parallel optimization of large-point FFT on Sunway 26010 |
| Jun GUO1,2(),Peng LIU3,Xinyao YANG4,Lufei ZHANG5,Dong WU5 |
1. School of Information Engineering and Internet of Things, Huzhou Vocational and Technical College, Huzhou 313000, China
2. Huzhou Key Laboratory of IoT Intelligent System Integration Technology, Huzhou Vocational and Technical College, Huzhou 313000, China
3. College of Information Science and Electronic Engineering, Zhejiang University, Hangzhou 310027, China
4. Ant Group Limited Company, Hangzhou 310013, China
5. State Key Laboratory of Mathematical Engineering and Advanced Computing, Wuxi 214125, China |
引用本文:
郭俊,刘鹏,杨昕遥,张鲁飞,吴东. 大点数FFT在“申威26010”上的并行优化[J]. 浙江大学学报(工学版), 2024, 58(1): 78-86.
Jun GUO,Peng LIU,Xinyao YANG,Lufei ZHANG,Dong WU. Parallel optimization of large-point FFT on Sunway 26010. Journal of ZheJiang University (Engineering Science), 2024, 58(1): 78-86.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.01.009
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I1/78
|
| 21 |
SUN Jiadong, SUN Qiao, DENG Pan, et al Research on the optimization of blas level 1 and 2 functions on shenwei many-core processor[J]. Computer Systems and Application, 2017, 26 (11): 101- 108
doi: 10.15888/j.cnki.csa.006045
|
| 22 |
徐燚. 基于新一代申威众核处理器的BLAS并行优化的研究[D]. 上海: 华东师范大学, 2022: 15.
XU Yi. Research on parallel optimization of BLAS based on the new generation of sunway many-core processor [D]. Shanghai: East China Normal University, 2022: 15.
|
| 23 |
赵玉文, 敖玉龙, 杨超, 等 申威26010众核处理器上一维FFT实现与优化[J]. 软件学报, 2020, 31 (10): 3184- 3196
doi: 10.13328/j.cnki.jos.005848
|
| 1 |
TOP500. Top500 lists june 2016 [EB/OL]. [2016-06-30]. https://www.top500.org/lists/top500/2016/06/.
|
| 2 |
COOLEY J W, TUKEY J W An algorithm for the machine calculation of complex Fourier series[J]. Mathematics of Computation, 1965, 19 (90): 297- 301
doi: 10.1090/S0025-5718-1965-0178586-1
|
| 3 |
PRIYANKA C, LAKSHMI S, SAMHITHA A, et al High speed FFT computation using optimized radix 8 algorithm[J]. International Journal of Advanced Science and Technology, 2020, 29 (4): 6307- 6312
|
| 4 |
ELSHAFIY A, EL-MOTAZ M A, FARAG M E, et al. On optimization of mixed-radix FFT: a signal processing approach [C]// Proceedings of the IEEE Wireless Communications and Networking Conference. Marrakesh: IEEE, 2019: 1-6.
|
| 5 |
STASINSKI R. Split multiple radix FFT [C]// 30th European Signal Processing Conference. Belgrade: IEEE, 2022: 2251-2255.
|
| 6 |
KULKARNI V, OZA S Design and implementation of 3d FFT[J]. International Journal of Scientific and Engineering Research, 2017, 8 (4): 186- 189
|
| 7 |
GARRIDO M, SÁNCHEZ M A, LÓPEZ-VALLEJO M L, et al A 4096-point radix-4 memory-based FFT using DSP slices[J]. IEEE Transactions on Very Large Scale Integration Systems, 2017, 25 (1): 375- 379
doi: 10.1109/TVLSI.2016.2567784
|
| 8 |
XIA K F, WU B, XIONG T, et al A memory-based FFT processor design with generalized efficient conflict-free address schemes[J]. IEEE Transactions on Very Large Scale Integration Systems, 2017, 25 (6): 1919- 1929
doi: 10.1109/TVLSI.2017.2666820
|
| 9 |
INGEMARSSON C, KÄLLSTRÖM P, QURESHI F, et al Efficient FPGA mapping of pipeline SDF FFT cores[J]. IEEE Transactions on Very Large Scale Integration Systems, 2017, 25 (9): 2486- 2497
doi: 10.1109/TVLSI.2017.2710479
|
| 10 |
SHIH X Y, CHOU H R, LIU Y Q VLSI design and implementation of reconfigurable 46-mode combined-radix-based FFT hardware architecture for 3GPP LTE applications[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2018, 65 (1): 118- 129
doi: 10.1109/TCSI.2017.2725338
|
| 11 |
FRIGO M, JOHNSON S G The design and implementation of fftw3[J]. Proceedings of the IEEE, 2005, 93 (2): 216- 231
doi: 10.1109/JPROC.2004.840301
|
| 12 |
INTEL. Intel oneapi math kernel library [EB/OL]. [2020-09-20]. https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html.
|
| 13 |
NVIDIA. Fast Fourier transforms for nvidia GPUs [EB/OL]. [2021-03-30]. https://developer.nvidia.com/cufft.
|
| 14 |
AYALA A, TOMOV S, HAIDAR A, et al. Heffte: highly efficient FFT for exascale [C]// Proceedings of the International Conference on Computational Science. Amsterdam: Springer, 2020: 262-275.
|
| 15 |
张明. 龙芯平台上高性能计算的性能优化关键问题研究[D]. 合肥: 中国科学技术大学, 2017: 47.
ZHANG Ming. Research on key issues of performance optimization in high performance computing based on the Godson [D]. Hefei: University of Science and Technology of China, 2017: 47.
|
| 16 |
郭金鑫. 实数FFT算法在ARM V8处理器上的实现与性能优化研究[D]. 太原: 太原理工大学, 2021: 33.
GUO Jinxin. Real FFT implementation and performance optimization on ARM V8 processor [D]. Taiyuan: Taiyuan University of Technology, 2021: 33.
|
| 17 |
操庐宁. 基于X86-64计算平台的FFT实现与并行优化[D]. 长春: 吉林大学, 2019: 27.
CAO Luning. FFT implementation and parallel optimization based on X86-64 computing platform [D]. Changchun: Jilin University, 2019: 27.
|
| 18 |
YANG C, XUE W, FU H H, et al. 10m-core scalable fully-implicit solver for nonhydrostatic atmospheric dynamics [C]// Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Salt Lake City: IEEE, 2016: 57-68.
|
| 19 |
FU H H, YIN W W, YANG G W, et al. 18.9-pflops nonlinear earthquake simulation on sunway taihulight: enabling depiction of 18-Hz and 8-meter scenarios [C]// Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Denver: ACM, 2017: 13-24.
|
| 20 |
LIU Y, LIU X, LI F, et al. Closing the "quantum supremacy" gap: achieving real-time simulation of a random quantum circuit using a new sunway supercomputer [C]// Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. St. Louis Missouri: ACM, 2021: 25–36.
|
| 21 |
孙家栋, 孙乔, 邓攀, 等 基于申威众核处理器的1、2级BLAS函数优化研究[J]. 计算机系统应用, 2017, 26 (11): 101- 108
doi: 10.15888/j.cnki.csa.006045
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|