

随着数字计算机和超大规模集成电路的飞速发展,数字信号处理技术得到了越来越广泛的应用,快速傅里叶变换(fast Fourier transform,FFT)是其中最基本、使用最频繁的核心算法之一. 其他诸多信号处理算法,例如卷积、滤波、频谱分析等,都可以转化为FFT来实现.
超级计算机为解决当今海量级数据的科学与工程计算问题提供了良好的平台. “神威·太湖之光”是世界上首台峰值每秒浮点运算次数(FLOPs)超过100×1015的超级计算机,也是中国第一台全部采用自主技术构建的排名世界第一的超级计算机[1]. “神威·太湖之光”由国产“申威26010”处理器组成,单处理器峰值FLOPs可达3.1×1012. 相比之下,访存带宽仅有136.5 GB/s则略显逊色,计算访存比接近22.7. 在面对诸如FFT这样兼具计算密集型和访存密集型特点的程序时,需要设计特定的并行实现策略,以优化其性能.
本文的主要工作是根据“申威26010”处理器的架构特点和编程规范,提出针对大点数FFT的众核优化方案. 该方案源自经典的Cooley-Tukey FFT算法,将一维数据迭代分解为二维FFT进行加速. 为了解决“列FFT”的读写和计算问题,降低矩阵转置的影响,提出“列均分-行连续”结合DMA跨步传输的读写策略. 该方法还可以推广至其他需要进行大量列数据操作的应用. 计算部分采用旋转因子优化和向量化操作,传输部分采用双缓冲策略和寄存器通信,能够充分利用众核系统的计算资源和传输带宽,达到了良好的加速效果.
1. 相关工作及研究现状
1.1. 快速傅里叶变换
1.2. 申威26010与神威·太湖之光
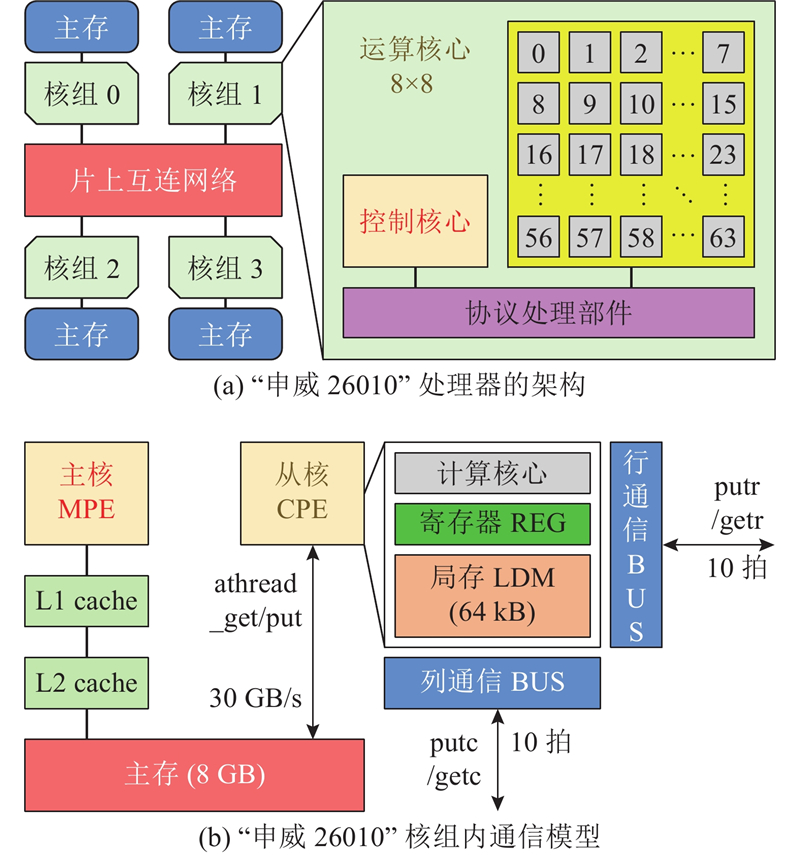
国产“申威26010”处理器由上海高性能集成电路设计中心通过自主技术研制,采用片上计算阵列集群和分布式共享存储相结合的异构众核体系架构,使用64位自主申威指令系统. 单芯片集成了4个核组共260个核心,每个核组包含1个控制核心(主核)和由64个运算核心(从核)组成的核心阵列. 如图1(a)所示为处理器的结构示意图,如图1(b)所示为从核与主存、局存、寄存器之间的简化通信模型. 在编程规范上,核组内部采用Athread多线程库或OpenACC并行编程,核组间使用MPI或OpenMP编程接口. 新一代“申威26010-Pro”处理器于2021年发布,单核组运算性能和访存带宽分别提升了3.1倍和1.8倍.
图 1
针对FFT优化的开发需求,根据“申威26010”处理器的架构特点与FFT算法的内在联系,提出“列均分-行连续”读写策略. 结合其他优化手段,对数据进行巧妙的划分、重排和交换,可以减少行列转置带来的影响,完成了经典Cooley-Tukey FFT的众核实现,达到了大点数下平均60x以上的加速比.
2. 大点数FFT算法
离散傅里叶变换DFT的计算公式为
式中:
FFT作为DFT的快速算法,核心思想是将长输入逐次分解成短序列DFT进行递归计算,通过分而治之的策略,将计算复杂度降至
将输入规模为
其中,
一维转二维FFT的计算流程(见图2)如下.
图 2
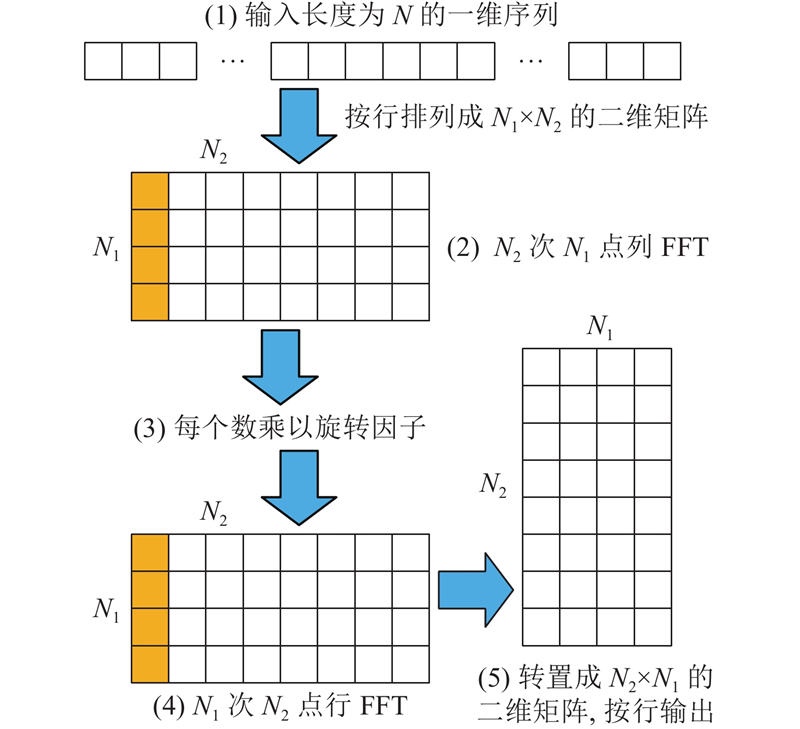
1)将一维数据按行优先顺序排列为
2)进行每一列
3)对于矩阵中的每一个数据,根据其坐标,乘以旋转因子
4)进行每一行
5)按列优先顺序将数据读出,得到
3. 大点数FFT在“申威26010”上的并行优化
将大点数FFT在“申威26010”上并行实现时,主要面临如下难题. 1)主核与从核之间列数据的读写问题. 2)从核间行列数据的分布与转置问题. 3)从核内小点数FFT的高效实现问题.
下面给出具体的并行优化解决方案.
3.1. 基本存储和分解策略
使用双精度浮点复数,包括8 B的实部和8 B的虚部. “申威26010”从核对局存LDM的访问延迟为4个CPU周期,仅为对主存访问延迟的1/40,应尽可能将主存中的数据放入LDM内再计算. 考虑到单从核LDM大小仅为64 kB,采用双缓冲策略需要2份输入/输出缓冲区(3.6节),将可单次写入LDM的最大数据量规定为512个复数. 输入和输出共占512×16×2×2=32 kB,余下一半空间存储中间结果和临时变量.
“申威26010”单个核组阵列包括8行8列共64个运算核心. 为了方便维度分解和FFT计算,总数据量采用2的正整数幂次,每一维上的最小尺寸设置为8. 下面给出基本的分解策略.
1)将总点数分解为
a)
b)
c)
2)同理,
3)每多分解一次,需要将当前FFT替换为图2所示的“列FFT-乘旋转因子-行FFT”流程,直至迭代计算完毕.
下面以输入数据量为262144=512×512的实例,阐述各创新实现技术.
3.2. “列均分-行连续”策略
在行优先的存储系统中,对列数据的读写是离散非连续的,传输效率很低. 一维转二维FFT并行方案的主要难点是对矩阵“列FFT”的处理. 大数据量加剧了FFT访存密集型特点带来的上述影响,若在主核上先进行显式转置再传输,则会增加不可忽略的额外开销.
为了提升“列FFT”的并行效率,结合FFT算法、处理器架构以及数据在从核间的分布特点,提出“列均分-行连续”读写策略,即并非用单个从核去读取主存中的列数据,而是把每一列的数据循环平分给64个从核. 如图3所示,对于“大矩阵”的每一列,0号核读第0行,1号核读第1行,······,63号核读第63行. 然后0号核读第64行,······,直至63号核读第511行. 从列的方向来看,每一列循环平分到64个从核内. 每个核一次可以读取多列,从行的方向来看,数据是连续读取的,即为“列均分-行连续”策略.
图 3
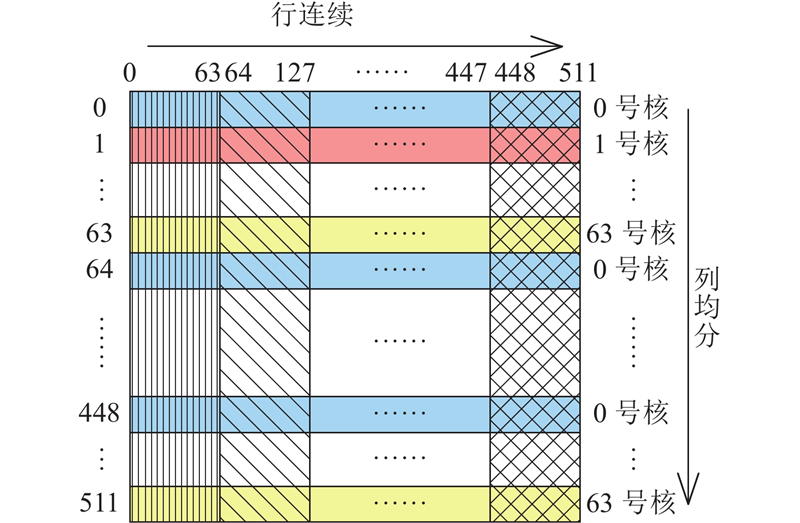
每个从核分到512/64=8行的数据. 由于LDM最大单次输入量为512,可以连续读入“大矩阵”每一行中512/8=64个数. 由于“申威26010”主存与局存之间的DMA带宽性能在传输粒度≥256 B(32个double数据)时达到峰值,采用“列均分-行连续”策略的第1个优点,即在保证一列数据能够完整读入从核阵列的同时,符合行优先的存储结构,且充分利用了传输带宽,从而有效解决了列读写的不连续性.
3.3. 从核间数据分布与寄存器通信转置
图 4
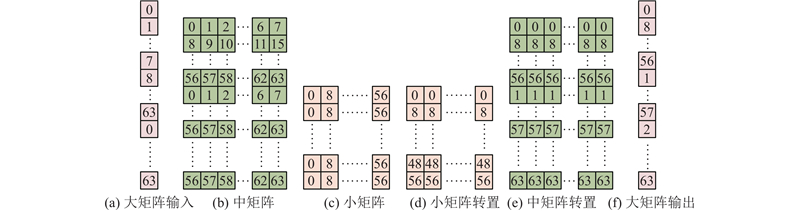
图4(c)中,“小矩阵”的每一行数据分散在同列8个从核中,可以利用“申威26010”的寄存器通信机制来实现从核间的数据交换. 使用putc和getc指令开启寄存器列通信模式,同列8个核之间彼此将各行数据传到对应的从核,并接收其他从核传给自己的数据,即可完成“小矩阵”的列与行转置(见图4(d)),继续执行“小矩阵”“行FFT”计算. 在“小矩阵”FFT计算完毕后,核间数据按图4(d)中的列优先顺序排列,实际上与图4(b)保持一致. “中矩阵”的转置过程与“小矩阵”类似,但须使用putr和getr指令开启寄存器行通信模式(见图4(e)). 在完成“中矩阵”FFT后,将数据按列优先顺序写回主存(见图4(f)). LDM内的64列数据均按图4(f)的顺序排列,因此写回过程符合“列均分-行连续”原则,DMA传输可达最大速度.
3.4. SIMD FFT
FFT计算采用单指令多数据流操作(single instruction multiple data,SIMD)进行加速. “申威26010”支持宽度为4个double数据的向量运算(doublev4),但须解决以下2个问题. 1)若将同组FFT数据放在一个向量内,则不同间距的蝶形会引起数据依赖问题(见图5(a)). 2)若分散在不同向量内,则离散数据装载/卸载向量的效率较低.
图 5

3.5. 旋转因子计算优化
根据欧拉公式可知,FFT的旋转因子
1)和差化积. 所有旋转因子系数均为
2)数据复用. 每个从核读入的“大矩阵”多列数据,实际上每一列在图4所示的“小矩阵”和“中矩阵”中所处的位置都是一样的,即坐标相同,因此只须计算第1列旋转因子并复用.
3)提前计算. 所有的旋转因子均由矩阵尺寸,即输入数据量决定,可以提前完成计算. 和差化积缩短了计算时间,数据复用减少了计算次数,将旋转因子计算与第一次DMA传输同步进行,不会给存储空间和计算时间带来额外负担.
此外,所有旋转因子的计算和相乘采用SIMD操作,可以与FFT结合.
3.6. 双缓冲策略和跨步读写
“申威26010”为异步DMA传输,当数据需要在主存与局存之间进行多次传输时,可以采用双缓冲策略. 如图6所示,数字表示循环轮次,奇数轮和偶数轮分别占用2份不同的输入/输出缓冲区. 可以看出,除了第1轮读入和最后1轮写回外,在进行中间轮次计算的同时,可以进行下一轮读入及上一轮写回,以计算时间隐藏通信开销.
图 6
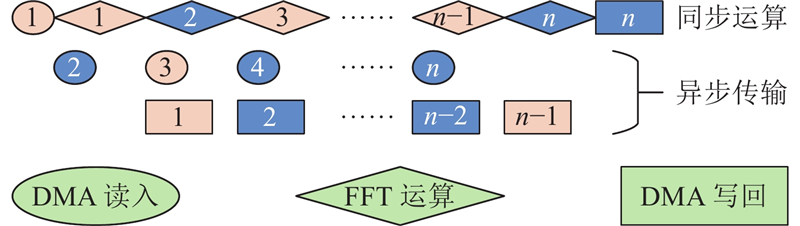
实际上,DMA还包括启动athread_get(读入)和athread_put(写回)的函数调用开销. 该步骤为串行过程,无法被计算隐藏,当一次完整读写需要多次调用这2个函数时,耗时不可忽略. 从核在每一轮“列均分”中共分到8行数据,须调用get和put函数各16次(实部和虚部各1次),因此无法被双缓冲隐藏的DMA时长
此时,每个从核在主存上的访问空间呈现等数据量(行连续)、等间隔(列均分)的特点(见图4(a)、(f)). 通过配置athread_get(dma_mode mode, void *src, void *dest, int len, void *reply, char mask, int stride, int bsize)的最后2个参数“间距”和“单次传输数据量”,可以实现跨步传输. 跨步读写仅须调用get和put各2次,无法隐藏的调用时间
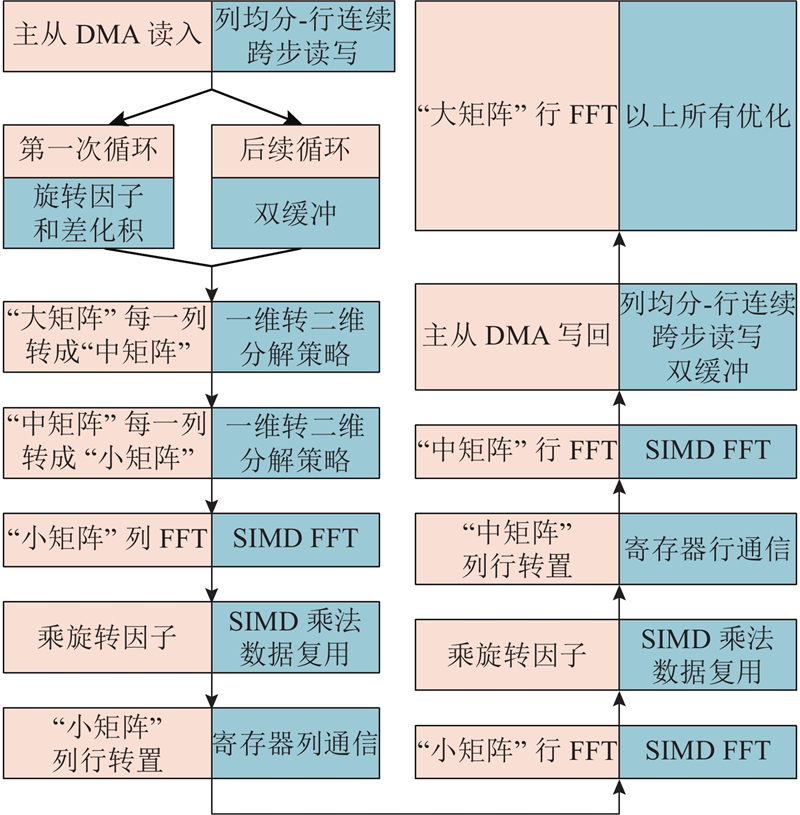
3.7. FFT完整流程
如图7所示为“大矩阵”“列FFT”的完整计算流程,包括各环节采用的优化方法. “大矩阵”“行FFT”的计算过程与“列FFT”类似,此处不再赘述.
图 7
4. 实验结果与分析
4.1. 实验运行环境
测试了数据量为32 768~4 194 304共8组随机生成的双精度浮点复数. 众核并行程序启用“申威26010”1个核组共64个从核,运行时间从athread_spawn开始至athread_join结束,包括传输和计算全过程. 对比基准为单主核上运行FFTW 3.3.4库以最优plan计算相同输入的用时,仅统计fftw_execute计算时间. 所有实验均重复多次,取稳定值求平均作为测试结果.
4.2. 各优化策略的加速效果
如图8所示为采用旋转因子优化、SIMD、双缓冲以及改用跨步传输后再结合双缓冲等各方案的加速比SP.
图 8
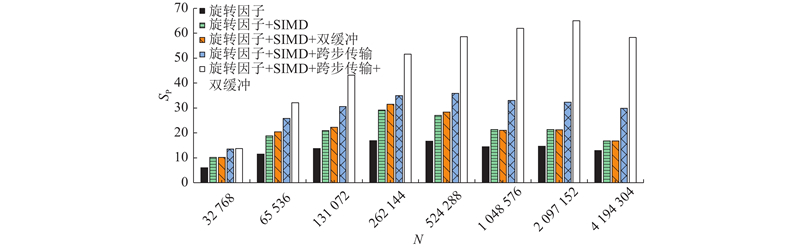
图 8 采用旋转因子优化、SIMD、跨步传输、双缓冲方案的加速比
Fig.8 Speedup using twiddle factor optimization, SIMD, stride transmission, double-buffering scheme
4.2.1. 计算环节
如表1所示为优化前、后单个从核内旋转因子的计算量. 其中,小点数FFT所需的旋转因子数量分别为4、8、16,可以一次完成计算,所以忽略不计,只统计一维转二维方案中“列FFT”转“行FFT”之间所须乘上的旋转因子. 3.5节优化策略的核心思想是以和差化积所需的复数乘法和加法(或4次实数乘法和2次实数加法)来代替耗时较长的三角函数调用. 以262 144=512×512为例,优化前需要40 960次三角函数,优化后仅为24次三角函数加上1 136次浮点运算. 且该加速效果随着计算规模的增大而提高.
表 1 旋转因子优化前、后的计算次数
Tab.1
| 类型 | 三角函数调用次数 | 复数乘法和加法的计算次数 |
| 优化前 | | 0 |
| 优化后 | | |
实验结果表明,若未对旋转因子计算进行优化,则多核并行总耗时比单主核FFTW长,而通过3.5节所述的和差化积、数据复用、提前计算等优化策略,可以达到15倍左右的加速比. 因此,旋转因子优化可以认为是计算环节中必须且最主要的加速部分.
在加入SIMD向量化运算后,可以在旋转因子优化的基础上提升近2倍的加速效果. SIMD覆盖了计算环节的几乎所有部分,包括FFT以及旋转因子相乘. 若单独测量运算部分,则可以达到约3.5倍的加速,接近4倍峰值,证明利用3.4节的方案,降低了装载/卸载向量引起的额外开销.
4.2.2. 通信环节
从核间寄存器单点通信的标称延迟为10拍,但是在应用中通常会叠加put/get指令执行开销、显式sync同步开销、网络堵塞延迟、连续读写延迟等,效率明显降低,需要采用汇编级流水线优化进行手动提升. 在本实验中,每次寄存器通信共须传输512×7/8 = 448个数,数量固定,因此耗时基本稳定,优于采用DMA传回主存,且改用DMA传输后会导致计算时间无法覆盖传输时间,使双缓冲失效. 寄存器通信是“小/中矩阵”“列/行”转置的首选方案.
在“列均分-行连续”策略中,直接采用双缓冲,加速比最大提升不到10%. 与get和put调用次数有关,数据量越大,调用次数越多,双缓冲效果越差. 在改用跨步传输再加上双缓冲后,达到了非常明显的加速效果,大数据量时可以再提升1倍以上,与3.6节的传输过程分析基本吻合.
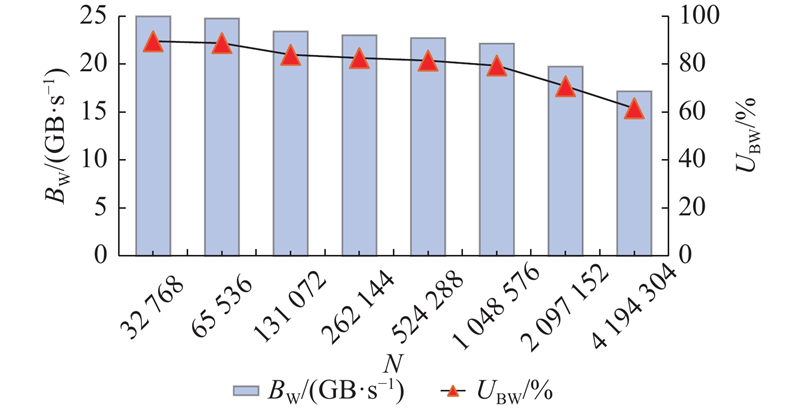
如图9所示为不同输入点数时的DMA平均传输带宽BW及利用率UBW统计. 可以看出,“行连续”策略能够保证连续传输字节数≥256 B,因此可以在大多数情况下保持对读写带宽的充分利用. 当仅在最大数据量分解方案为2 048列时,连续读写粒度减小为128 B,导致性能下降. 以实测读带宽峰值27.9 GB/s进行折算,带宽利用率最高可达89.6%,最低为61.6%,平均为79.8%.
图 9
如图10所示为“主-从核DMA通信”、“从核间寄存器通信”、“从核FFT计算”3个环节各自在总时长中的占比TP,左边为普通传输,右边为跨步读写(图例仅表示各部分功能的相对占比关系,不表示运行时长的绝对数值). 可以看出,跨步传输+双缓冲策略使得主/从核间DMA传输时长占比明显下降,不再是整体性能的瓶颈,各环节耗时更均衡.
图 10
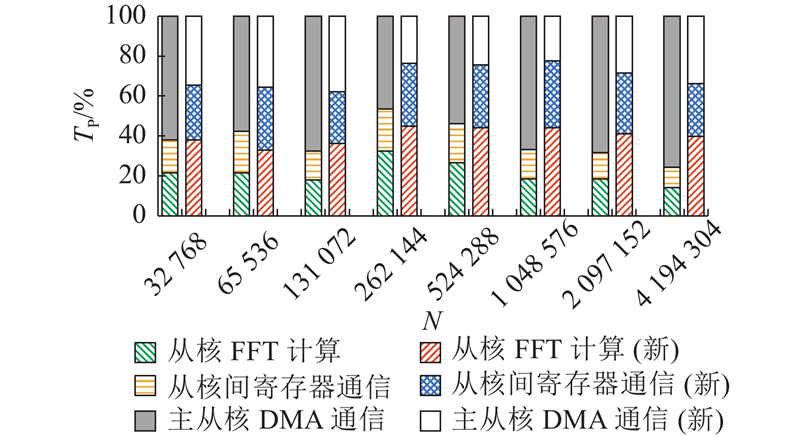
图 10 传输和计算各部分功能的耗时占比
Fig.10 Proportion of time consumed by transmission and calculation
4.2.3. 实验小结
表2给出FFTW串行程序和最终多核并行方案各自的运行拍数CS、CP及两者的加速比测试结果,可以得到以下结论.
表 2 并行FFT的加速测试结果
Tab.2
| 数据量 | CS | CP | SP |
| 32 768 | 8 063 390 | 589 862 | 13.67 |
| 65 536 | 32 225 901 | 1 004 552 | 32.08 |
| 131 072 | 83 236 162 | 1 930 484 | 43.12 |
| 262 144 | 190 366 763 | 3 690 079 | 51.59 |
| 524 288 | 418 159 392 | 7 138 959 | 58.57 |
| 1 048 576 | 855 418 759 | 13 790 789 | 62.03 |
| 2 097 152 | 1 801 385 481 | 27 709 105 | 65.01 |
| 4 194 304 | 3 717 210 028 | 63 708 120 | 58.35 |
1)该并行优化方案的核心是“列均分-行连续”策略,优点如下. a)列数据读写连续非离散,能够充分利用DMA带宽. b)数据在从核间的分布能够直接进行后续FFT. c)数据在从核内的排列可以实现高效的SIMD. d)有助于旋转因子的快速运算. 以上4点保证了除必需的主存和局存之间的数据读写以及算法中的矩阵“列/行转置”操作以外,计算过程中基本没有额外的数据搬移,最大程度上减少了数据移动的次数,有效消除了FFT访存密集型特点带来的影响.
2)“列均分-行连续”策略的不足,即需要多次调用读写函数而带来的开销,可以采用跨步传输+双缓冲进行弥补. 合理的跨步传输能够有效地减少传输次数,从而提高异步传输时间在DMA总耗时中的占比,再利用双缓冲加以隐藏,有利于“列均分”策略的实施.
3)随着输入数据量的成倍增长,多核并行总时长的增加倍数与计算数据量的增长倍数基本相当,DMA传输粒度保持在256 B及以上. 测试结果显示,浮点运算性能及主、从核间的传输带宽基本可以达到并维持在峰值.
4)单主核FFTW在数据量较小时的运算性能较好,在数据量大于262 144之后基本保持成倍增长,应该是FFTW在不同数据量下会选择不同的最优算法所致.
5)本实验最终的加速比可以达到平均48x、最高65x以上的出色效果,尤其是在大点数情况下,能够始终保持在50x以上,平均接近60x.
6)利用“列均分-行连续+跨步传输”的策略,能够有效解决主、从核间“列”数据的读写问题,在矩阵应用场景下可以消除显式转置带来的影响,起到良好的加速效果. 在新一代“申威26010-Pro”处理器架构中,LDM扩大至256 kB,单次可传输数据量增加,更有利于DMA带宽的充分利用. 从核间的寄存器传输改为RMA通信机制,性能得到进一步的提升. 本方法重点关注处理器架构与算法的内在适配性,无须对软件算法框架进行大幅调整,因此可以作为一种通用优化策略进行推广使用,为“申威26010”高性能数学库中针对FFT算法的并行优化做出一定的贡献.
5. 结 语
本文介绍了在国产“申威26010”众核处理器上对大点数FFT进行并行加速的方案. 为了有效地解决二维FFT对列数据的读写和计算问题,消除矩阵转置带来的影响,特别提出“列均分-行连续”的读写策略,结合SIMD向量操作、寄存器通信转置、旋转因子优化、双缓冲+跨步传输策略等优化方法,实现了经典Cooley-Tukey FFT算法在“申威26010”上的众核优化. 与单主核FFTW相比,可以达到平均48x以上、峰值65x以上的加速比.
参考文献
Research on the optimization of blas level 1 and 2 functions on shenwei many-core processor
[J].DOI:10.15888/j.cnki.csa.006045 [本文引用: 1]
申威26010众核处理器上一维FFT实现与优化
[J].DOI:10.13328/j.cnki.jos.005848 [本文引用: 1]
An algorithm for the machine calculation of complex Fourier series
[J].DOI:10.1090/S0025-5718-1965-0178586-1 [本文引用: 1]
High speed FFT computation using optimized radix 8 algorithm
[J].
Design and implementation of 3d FFT
[J].
General implementation of 1-d FFT on the sunway 26010 processor
[J].DOI:10.13328/j.cnki.jos.005848 [本文引用: 1]
A 4096-point radix-4 memory-based FFT using DSP slices
[J].DOI:10.1109/TVLSI.2016.2567784 [本文引用: 1]
A memory-based FFT processor design with generalized efficient conflict-free address schemes
[J].DOI:10.1109/TVLSI.2017.2666820 [本文引用: 1]
Efficient FPGA mapping of pipeline SDF FFT cores
[J].DOI:10.1109/TVLSI.2017.2710479 [本文引用: 1]
VLSI design and implementation of reconfigurable 46-mode combined-radix-based FFT hardware architecture for 3GPP LTE applications
[J].DOI:10.1109/TCSI.2017.2725338 [本文引用: 1]
The design and implementation of fftw3
[J].DOI:10.1109/JPROC.2004.840301 [本文引用: 1]
基于申威众核处理器的1、2级BLAS函数优化研究
[J].DOI:10.15888/j.cnki.csa.006045 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}