| Computer Science and Artificial Intelligence |
|


|
|
|
| Improved deep belief network and its application in voice conversion |
Wen-hao WANG( ),Xiao ZHANG,Yong-jing WAN*() ),Xiao ZHANG,Yong-jing WAN*() |
| School of Information Science and Engineering, East China University of Science and Technology, Shanghai 200237, China |
|
|
|
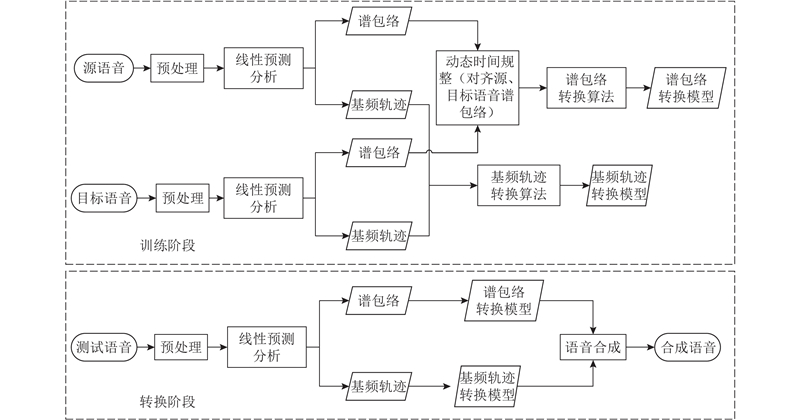
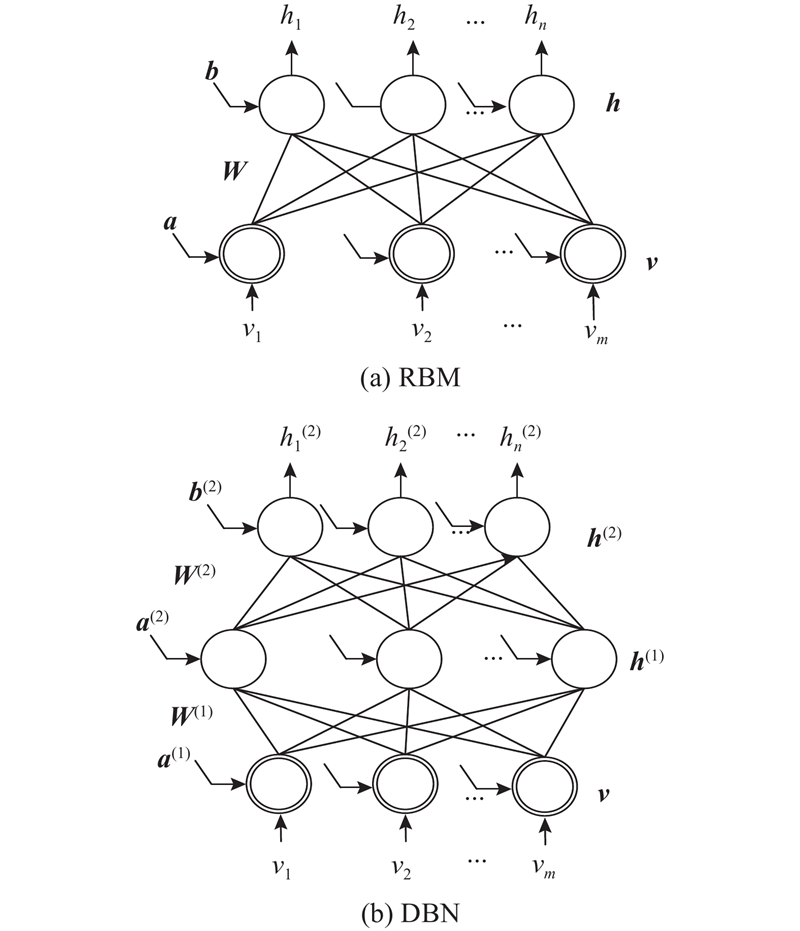
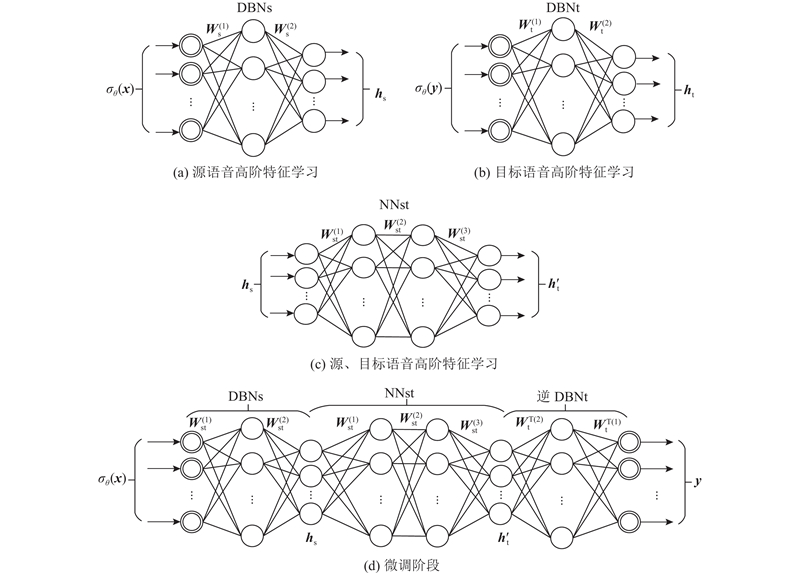
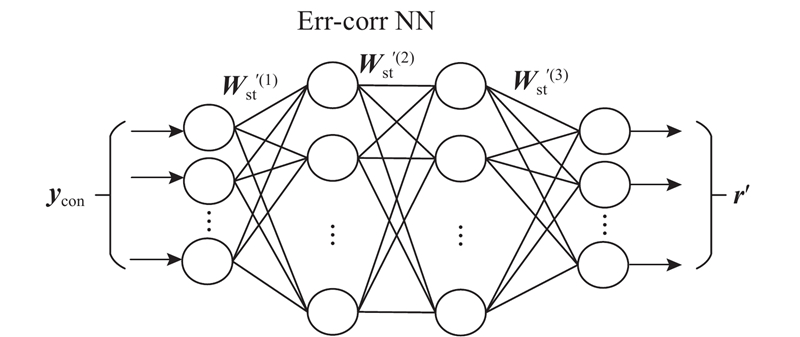
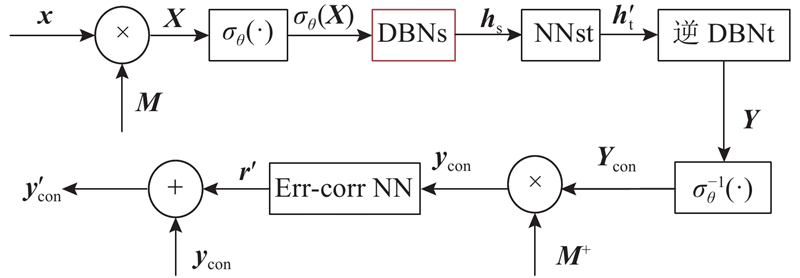
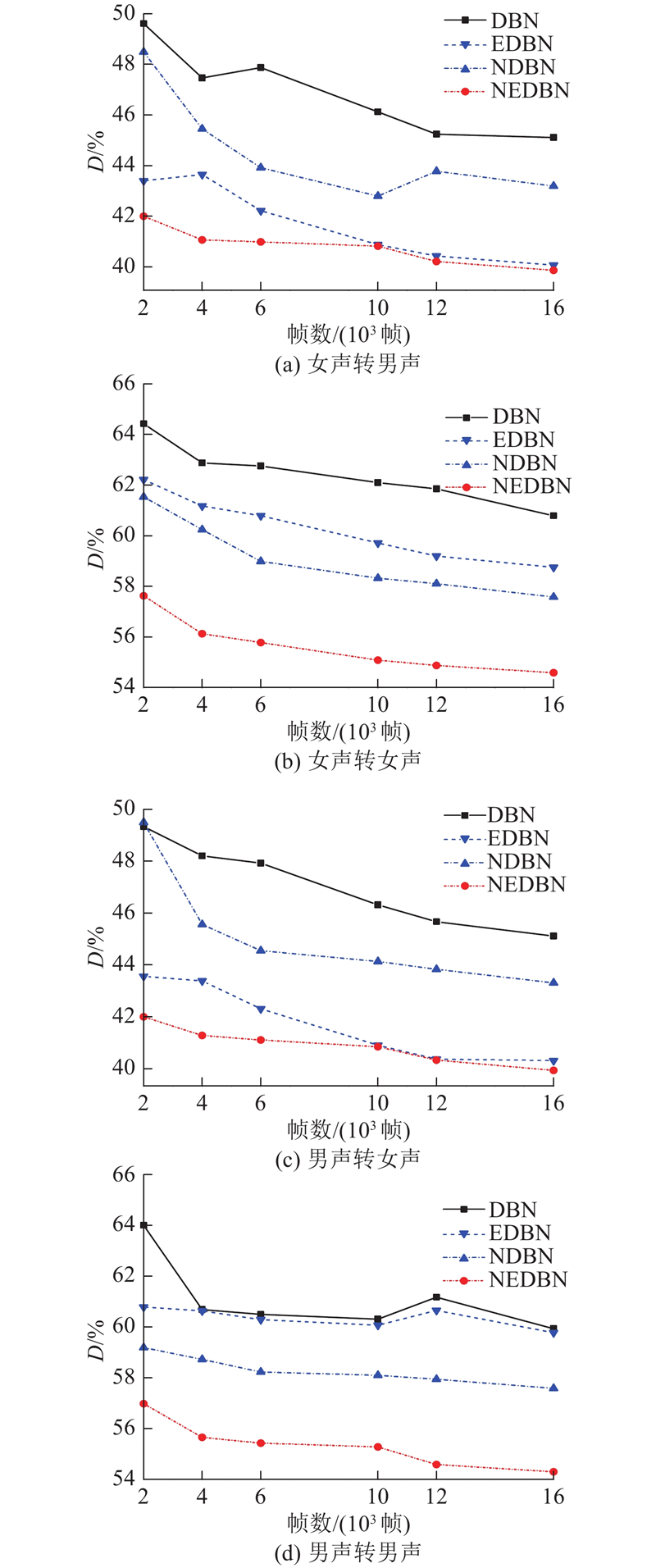
Abstract An improved voice conversion method based on deep belief network (DBN) was proposed, comprehensively considering the relationship between the speech frames and the effect of post-processing network. The method utilized a linear predictive analysis-synthesis model to extract the feature parameters of a speaker’s linear predictive spectrum, and the regional fusion spectral feature parameters for DBN were constructed so as to pretrain the model. Finally, an error correction network for the feature compensation of a detailed spectrum was introduced after fine-tuning. The comparison results show that, the spectral distortion of the converted speech shows the tendency of decreasing as the number of speech frames increases. Meanwhile, when the number of training speech frames was small, the spectral distortion of the proposed method was less than 50% between genders and less than 60% within genders. The experimental results showed that the spectral distortion of the proposed method was 6.5% lower than that of the traditional method. The proposed method significantly improves the naturalness and intelligibility of converted speech in view of two different subjective evaluations.
|
|
Received: 10 October 2018
Published: 17 December 2019
|
|
|
|
Corresponding Authors:
Yong-jing WAN
E-mail: 13122386132@163.com;wanyongjing@ecust.edu.cn
|
改进深度信念网络在语音转换中的应用
综合考虑语音帧间关系及后处理网络的效果,提出一种改进的基于深度信念网络(DBN)的语音转换方法. 该方法利用线性预测分析-合成模型提取说话人线性预测谱的特征参数,构建基于区域融合谱特征参数的深度信念网络用以预训练模型,经过微调阶段后引入误差修正网络以实现细节谱特征的补偿. 对比实验结果表明,随着训练语音帧数的增加,转换语音的谱失真呈下降趋势. 同时,在训练语音帧数较少的情况下,改进方法在异性间转换的谱失真小于50%,在同性间转换的谱失真小于60%. 实验结果表明,改进方法的谱失真度较传统方法降低约6.5%,且同性别间转换效果比异性间转换效果更为明显,转换后语音的自然度和可理解度明显提高.
关键词:
深度信念网络(DBN),
语音转换,
区域融合谱特征,
误差修正网络,
谱失真度
|
|
| [1] |
ERRO D, ALONSO A, SERRANO L Interpretable parametric voice conversion functions based on Gaussian Mixture Models and constrained transformations[J]. Computer Speech and Language, 2014, 30 (1): 3- 15
|
|
|
| [2] |
DOI H, TODA T, NAKAMURA K, et al Alaryngeal speech enhancement based on one-to-many eigenvoice conversion[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22 (1): 172- 183
doi: 10.1109/TASLP.2013.2286917
|
|
|
| [3] |
TODA T, NAKAGIRI M, SHIKANO K Statistical voice conversion techniques for body-conducted unvoiced speech enhancement[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20 (9): 2505- 2517
doi: 10.1109/TASL.2012.2205241
|
|
|
| [4] |
DENG L, ACERO A, JIANG L, et al. High-performance robust speech recognition using stereo training data [C] // IEEE International Conference on Acoustics, Speech, and Signal Processing. Las Vegas: IEEE, 2001: 301-304.
|
|
|
| [5] |
KUNIKOSHI A, QIAN L, MINEMATSU N, et al. Speech generation from hand gestures based on space mapping [C] // Tenth Annual Conference of the International Speech Communication Association. England: INTERSPEECH, 2009: 308-311.
|
|
|
| [6] |
MIZUNO H, ABE M Voice conversion algorithm based on piecewise linear conversion rules of formant frequency and spectral tilt[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 1 (6): 469- 472
|
|
|
| [7] |
ABE M, NAKAMURA S, et al. Voice conversion through vector quantization [C] // IEEE International Conference on Acoustics, Speech, and Signal Processing. Las Vegas: IEEE, 1988: 71-76.
|
|
|
| [8] |
YAMAGISHI J, KOBAYASHI T, NAKANO Y, et al Analysis of speaker adaptation algorithm[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17 (1): 66- 83
doi: 10.1109/TASL.2008.2006647
|
|
|
| [9] |
SARUWATARI T H, SHIKANO K. Voice conversion algorithm based on Gaussian Mixture Model with dynamic frequency warping of STRAIGHT spectrum [C] // Proceedings of IEEE International Conference on Acoust, Speech, Signal Processing. Las Vegas: IEEE, 2001: 841-844.
|
|
|
| [10] |
沈惠玲, 万永菁 一种基于预测谱偏移的自适应高斯混合模型在语音转换中的应用[J]. 华东理工大学学报:工学版, 2017, 43 (4): 546- 552
SHEN Hui-ling, WAN Yong-jing An adaptive Gaussian Mixed Model based on predictive spectral shift and its application in voice conversion[J]. Journal of East China University of Science and Technology: Engineering Science, 2017, 43 (4): 546- 552
|
|
|
| [11] |
左国玉, 刘文举, 阮晓钢 基于径向基神经网络的声音转换[J]. 中文信息学, 2004, 18 (1): 78- 84
ZUO Guo-yu, LIU Wen-ju, RUAN Xiao-gang Voice conversion by GA-based RBF neural network[J]. Journal of Chinese Information Processing, 2004, 18 (1): 78- 84
doi: 10.3969/j.issn.1003-0077.2004.01.012
|
|
|
| [12] |
NARENDRANATH M, MURTHY H A, RAJENDRAN S, et al Transformation of formants for voice conversion using artificial neural networks[J]. Speech Communication, 1995, 16 (2): 207- 216
|
|
|
| [13] |
王民, 黄斐, 刘利, 等 采用深度信念网络的语音转换方法[J]. 计算机工程与应用, 2016, 52 (15): 168- 171
WANG Ming, HUANG Fei, LIU Li, et al Voice conversion using deep belief networks[J]. Computer Engineering and Applications, 2016, 52 (15): 168- 171
doi: 10.3778/j.issn.1002-8331.1409-0383
|
|
|
| [14] |
叶伟, 俞一彪. 超帧特征空间下基于深度置信网络的语音转换[D]. 苏州: 苏州大学, 2016.
YE Wei, YU Yi-biao. Voice conversion using deep belief network in super frame feature space[D]. Soochow: Soochow University, 2016.
|
|
|
| [15] |
宋知用. Matlab在语音信号分析与合成中的应用: 第1版 [M]. 北京: 北京航空航天大学出版社, 2013: 2-16, 62-66, 161-162.
|
|
|
| [16] |
吕士楠, 初敏, 许洁萍, 等. 汉语语音合成: 原理和技术[M]. 北京: 科学出版社, 2012.
|
|
|
| [17] |
SMOLENSKY P. Information processing in dynamical systems: foundations of harmony theory [D]. Cambridge, MA, USA, 1986, 1(6): 194-281.
|
|
|
| [18] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2013: 111-115.
|
|
|
| [19] |
HINTON G Training products of experts by minimizing contrastive divergence[J]. Neural Computation, 2002, 12 (14): 1711- 1800
|
|
|
| [20] |
NAKASHIKA T, TAKASHIMA R, TAKIGUCH T, et al. Voice conversion in high-order eigen space using deep belief nets [C] // Interspeech. Lyon: INTERSPEECH, 2013: 369-372.
|
|
|
| [21] |
GHORBANDOOST M, SAYADIYAN A, AHANGAR M, et al. Voice conversion based on feature combination with limited training data[J]. Speech Communication, 2015, 67 (3): 115- 117
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|