

水下小型生物检测对水下生态平衡、生物多样性具有深远的影响[1]. 然而,水体的散射和吸收作用导致目标图像出现色偏、失真、对比度降低等问题,显著增加了水下目标检测的难度.
随着工业4.0的到来,计算机视觉和深度学习技术逐渐在水下目标检测中得到了广泛应用. Shi等[2]提出基于Faster R-CNN的水下生物检测算法,采用ResNet作为特征提取网络,并融合双向特征金字塔模块,在抵抗色偏干扰方面取得了良好的效果,但是在两阶段检测上的实时性有待提升. 张艳等[3]在YOLOv5中引入金字塔分割注意力机制和基于线性变换的GhostBottleNeck模块,捕获多尺度特征图的空间域信息以丰富特征表示,有效提升了检测性能,但是其忽略了对频率域信息的利用. 闵锋等[4]针对水下生物检测,在YOLOv8n的基础上加入浅层混合池下采样和深层最大池下采样模块,以优化特征融合,并设计轻量化门控正则单元部分卷积模块来为模型减负,在降低计算量的同时提高了检测精度,但是并未对水下色偏干扰提出有效的解决方案. Guo等[5]提出DCM-YOLO算法,利用UnitModule模块增强水下图像,并引入可变形卷积和分离增强注意力模块,以更好地捕获色偏目标特征,但是这类先图像增强、再目标检测的两阶段算法的计算资源消耗太大. Zhou等[6]提出水下目标检测网络UODN,通过跨阶段多分支模块优化特征提取,并采用大核空间金字塔模块来增强多尺度目标检测能力,但是未考虑模型轻量化设计. Zhang等[7]将双流特征金字塔网络与任务交互模块集成,通过并行路径融合策略有效地捕获多尺度特征,以增强网络在复杂水下环境中的检测性能,但是其收敛缓慢,训练较为困难.
目前,YOLO系列模型因其出色的检测精度和实时性,在水下目标检测中应用最为广泛,但是其对水下色偏环境的适应性仍须提升. 此外,无论是两阶段算法(如Faster R-CNN)还是单阶段算法(如YOLO系列),都受限于非极大值抑制(non-maximum suppression, NMS)后处理,影响了检测速度和精度. 为此,Carion等[8]提出的目标检测算法DETR创新性地采用Tranformer架构,将检测任务转化为集合预测问题,避免了NMS后处理对推理速度和鲁棒性的影响,但是其参数量大,训练效率低. 在此基础上,Zhu等[9]进一步提出端到端目标检测算法Deformable DETR,通过聚焦关键采样点,在提升检测性能的同时降低了计算成本. 针对DETR收敛缓慢的问题,Zhang等[10]提出DINO算法,使用混合查询选择方法,显著提高了训练效率和检测性能. Zhao等[11]对DINO的Transformer架构做出进一步优化,提出实时检测Transformer(real-time detection Transformer, RT-DETR). RT-DETR采用更加高效的混合编码器和不确定性最小查询选择策略,显著提升了推理速度和检测精度. 尽管RT-DETR性能优异,但是由于水下色偏现象使得目标与背景之间的颜色对比度降低,特征提取难度加大,RT-DETR容易出现漏检与误检的情况.
针对以上问题,提出基于改进RT-DETR的检测方法FES-DETR,创新点如下:1)设计高效多尺度注意力特征提取(Faster-Rep-EMA)模块,提高模型在色偏干扰下的图像特征提取能力和计算效率;2)提出纠缠Transformer-特征交互(ETB-AIFI)模块,实现跨域信息交互,提升模型的全局感知能力;3)构建轻量级小目标特征增强金字塔(SOEP)模块,增强对小目标的检测性能并降低计算冗余.
1. FES-DETR网络
RT-DETR是基于Transformer架构的实时端到端目标检测模型,避免了传统目标检测流程中的非极大值抑制(NMS)步骤,并克服了DETR系列模型计算成本高昂、实时性低的问题. 该模型由主干网络、混合编码器以及配备辅助预测头的Transformer解码器组成. 以主干网络在最后3个阶段提取的特征作为编码器的输入,通过基于注意力的尺度内特征交互(attention-based intra-scale feature interaction, AIFI)和跨尺度融合模块,将多尺度特征转化为一系列图像特征. IoU感知的查询选择模块从编码器输出中选取固定数量的特征,作为解码器的初始对象查询. 最终,解码器利用辅助预测头来迭代优化这些对象查询,生成检测框和置信度分数.
提出的面向水下色偏环境的小型生物检测框架FES-DETR是在RT-DETR基础上改进得到的,其整体结构如图1所示.
图 1
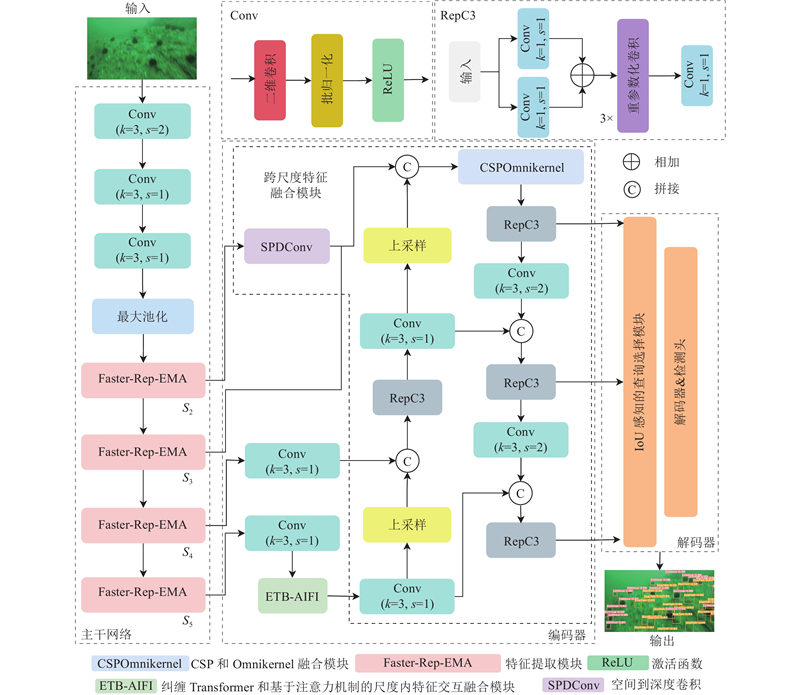
图 1 面向水下色偏环境的小型生物检测模型(FES-DETR)结构图
Fig.1 Structure diagram of small organism detection model (FES-DETR) targeting underwater color-cast environments
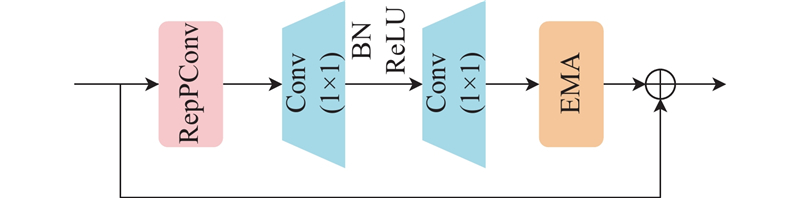
1.1. Faster-Rep-EMA模块
1.1.1. RepPConv结构及原理
波长较长的红光在水下传播时衰减较快,使得水下图像呈现绿色、蓝色等色偏现象,从而出现特征偏差[12]. 然而,RT-DETR采用的传统特征提取网络在经过自然场景训练后,其参数被固化,难以动态适应水下光谱吸收特性[13],且冗余计算过多,导致模型运算效率低下,无法充分利用色偏图像的特征信息,从而影响了检测性能. 针对以上问题,在高效、快速的FasterNet[14]基础上,将部分卷积(partial convolution, PConv)与结构重参数化卷积(re-parameterized convolution, RepConv)融合,构建RepPConv模块. 其中FasterNet的核心思想是采用PConv来代替标准卷积,使其仅对输入大小为
图 2
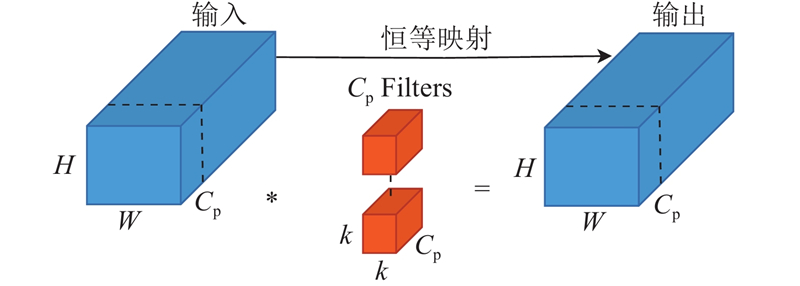
PConv模块的计算量
式中:k为卷积核的高和宽,Cp通常取总通道数C的1/4. PConv的计算量和内存访问量只有标准卷积的1/16和1/4.
RepConv的技术核心在于重参数化. 利用RepConv对PConv进行重参数化处理,即将部分卷积和批量归一化(batch normalization, BN)层融合成1个部分卷积. BN的表达式为
式中:
式中:
RepPConv模块在训练阶段并行使用3×3、1×1部分卷积和BN分支,通过融合各分支的输出,以实现对色偏图像的高效特征提取和色彩通道权重参数的优化. 在推理阶段,将1×1卷积和BN路径转化为3×3卷积,以单分支结构提高计算效率. RepPConv结合了RepConv和PConv的优势,在保持FasterNet的低计算量优点的同时,通过多分支结构捕捉更丰富的特征,从而提升了特征提取效率,避免了轻量级网络的精度丢失问题. 其结构如图3所示.
图 3
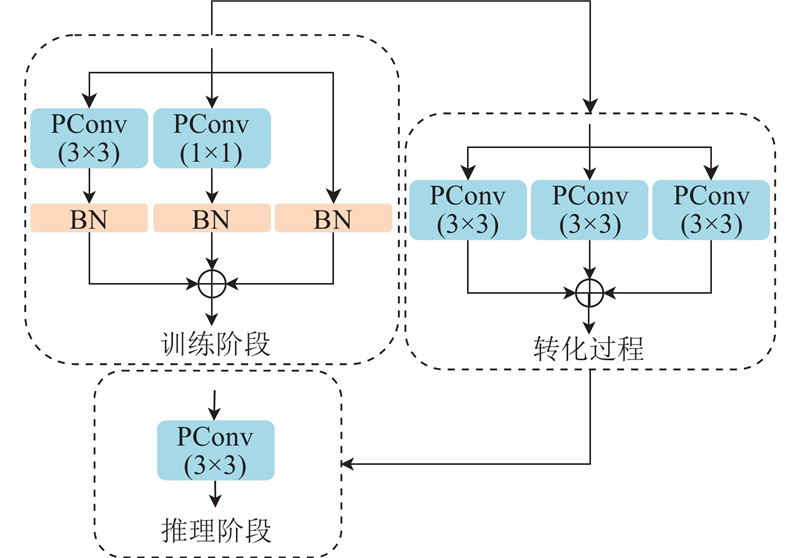
图 3 融合部分卷积与重参数化卷积的RepPConv模块结构图
Fig.3 Structure diagram of RepPConv module fusing partial convolution and re-parameterized convolution
1.1.2. 高效多尺度注意力模块
为了进一步增强模型在目标尺度变化和色偏干扰下的特征提取能力,引入高效多尺度注意力(efficient multi-scale attention, EMA)模块[15]. EMA模块结构如图4所示,其中,X AvgPool为水平全局池化操作,Y AvgPool为垂直全局池化操作,C//G为子特征图的通道数. 对于任意输入特征图
图 4
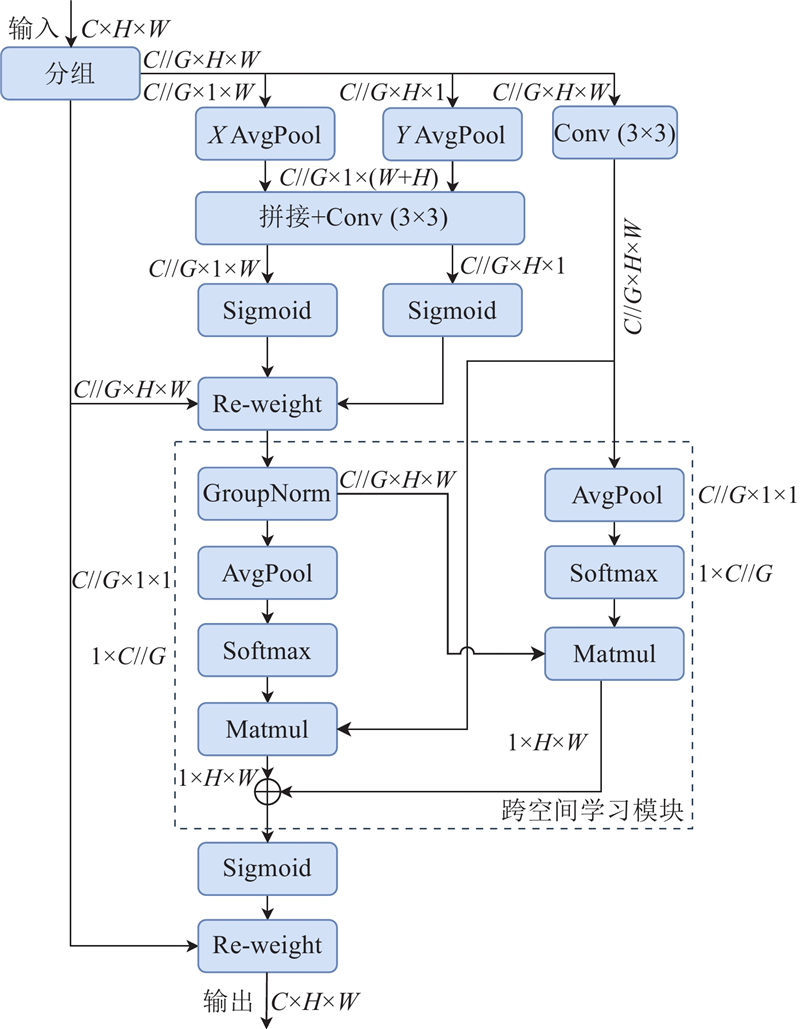
图 5
1.2. ETB-AIFI模块
图 6
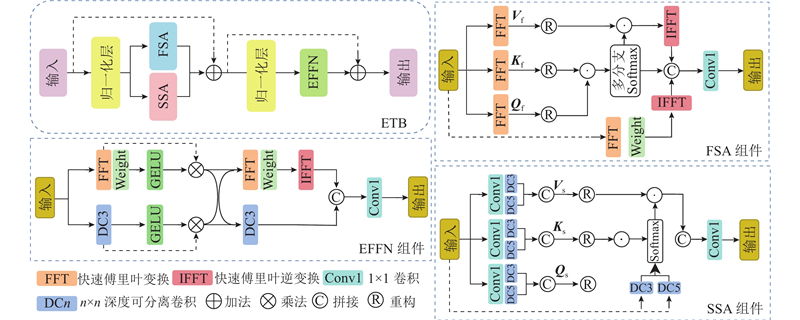
ETB通过频率自注意(frequency self-attention, FSA)、空间自注意力(spatial self-attention, SSA)和纠缠前馈网络(entanglement feed-forward network, EFFN)3个关键组件实现对频率域和空间域特征的联合优化,以提高对目标的检测能力. FSA组件通过快速傅里叶变换(fast Fourier transform, FFT)将特征转换至频率域,并对频段间关系进行建模. 输入特征
式中:Sof (·)为Softmax函数,Θ表示将虚部和实部组合成复数的组合函数,Φ为模运算,
SSA组件通过深度可分离卷积提取空间特征,并在空间域建模局部上下文信息. 与FSA类似,以特征
式中:
EFFN组件通过频率域和空间域特征之间的交互融合,生成更强大、完整的特征表示. 首先,将频率特征
其次,将归一化后的综合特征
式中:GE(·)为GELU函数,
最后,引入剩余连接以获得最终的特征X,对于具有n个通道的输入特征
通过多次聚合交互作用,全局频率特征和局部空间特征相互作用、纠缠在一起,形成丰富而全面的表征. 这种联合优化策略有效提高了模型对水下色偏目标的检测能力.
1.3. 小目标增强金字塔模块
RT-DETR中基于CNN的跨尺度特征融合(CNN-based cross-scale feature fusion, CCFF)模块在面对小目标检测时性能受限,其原因在于小目标在不同尺度下的特征变化较为复杂,且色偏环境导致小目标在高层特征图中像素少、特征弱. 因此,需要更精细的协同优化机制来增强其特征表示,而传统CCFF的特征融合方式相对简单,难以实现这种协同优化,导致小目标的特征表达不够丰富和准确,影响了检测性能. 针对这一问题,目前的主流策略是引入P2检测层[18],以提高模型对小目标的检测性能. 但是这种方法存在诸多弊端:一方面,加入P2检测层会使计算量显著增加,给模型的运行效率带来较大压力;另一方面,会导致后处理过程变得更加复杂和耗时,从而影响整个检测模型的实时性和实用性. 因此,基于RT-DETR中传统的CCFF进行改进,提出新型小目标增强金字塔(small object enhancement pyramid, SOEP)模块,提高对小目标的检测性能并降低计算冗余. SOEP的整体结构如图7所示.
图 7
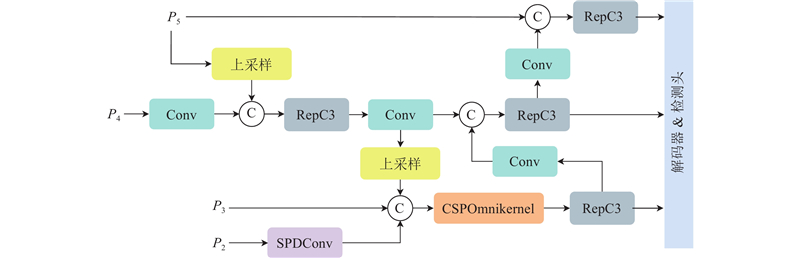
与传统的添加P2检测层的策略不同,创新地引入空间到深度卷积(space-to-depth convolution, SPDConv)[19]来处理P2特征层. 在提取小目标特征信息后,SPDConv能够在不丢失可学习信息的前提下降低特征图空间维度,从而提高了模型的计算效率.
具体来说,为了将输入特征图从空间维度转换到深度维度,对于输入尺寸为
图 8
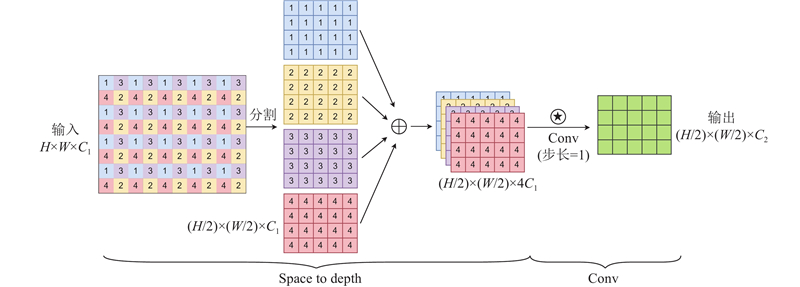
图 9
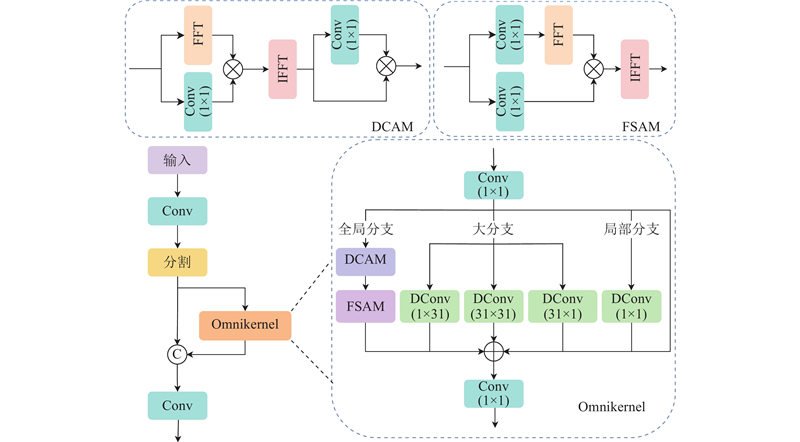
CSP结构通过跨阶段连接来提升特征融合效率,避免冗余计算. Omnikernel模块由3个分支组成,其中全局分支融合了双域通道注意力模块(dual-domain channel attention module, DCAM)与基于频率的空间注意力模块(frequency-based spatial attention module, FSAM),以增强全局特征捕获能力;大分支采用异构深度可分离卷积,以获得多粒度感受野,强化大尺度特征建模;局部分支使用1×1深度可分离卷积来补充局部细节,缓解小尺度特征的退化问题. 对于输入特征
式中:
最后,将经过CSPOmnikernel整合后的特征图与主干网络的浅层特征融合,补充小目标细节信息,再通过解耦头输出检测结果. 相较于直接引入P2检测层,SOEP模块通过高效、精细的多尺度特征融合,在保持高精度的同时提升了计算效率.
2. 实验结果与分析
2.1. 数据集
为了全面评估FES-DETR的性能,使用水下生物数据集DUO[21]进行训练与验证. DUO整合了多年水下机器人抓取大赛 (underwater robot picking contest,URPC)的数据,共有7 782张精确标注的水下图像,涵盖多种水下真实场景. 其包含4类生物:海参(Holothurian, 10.6%)、海胆(Echinus, 67.3%)、扇贝(Scallop, 2.6%)和海星(Starfish, 19.5%). 数据集中的图像呈现颜色失真、对比度低、光照不均等典型水下色偏特征,真实反映了水下目标检测所面临的困难. 按照8꞉1꞉1的比例将数据集随机划分为训练集、验证集和测试集,其中4类生物的样图如图10所示.
图 10

2.2. 实验环境配置
实验平台使用Ubuntu 20.04操作系统,GPU为NVIDIA RTX 4090D (24G),CPU为15vCPU Intel(R) Xeon(R) Platinum 8474C. 模型训练环境配置为PyTorch 1.11.0+Python 3.8+CUDA 11.3,优化器采用Adam W,具体参数设置如表1所示.
表 1 实验参数设置
Tab.1
| 参数 | 数值 | 参数 | 数值 | |
| 训练轮数 | 250 | 初始学习率 | 10−4 | |
| 批量大小 | 32 | 动量 | 0.9 | |
| 输入图像像素 | 640×640 | 权重衰减系数 | 10−4 |
2.3. 评估指标
使用目标检测领域中通用的精确率(P)、召回率(R)、平均精度均值(mean average precision, mAP)、每秒浮点运算次数(FLOPs)、参数量(Np)和帧率(FPS)来评估FES-DETR模型的性能. 精确率P指模型预测为正样本的样本中预测正确的比例:
式中:TP、FP分别为真正例和假正例的数目.
召回率R为预测正确的正例占总实际正例样本的比例:
式中:FN为假负例样本数目.
平均精度均值mAP用于评估模型在所有类别上的综合检测性能,表示为
式中:N为类别数,AP为单类别预测精度.
参数量Np和每秒浮点运算次数FLOPs分别用于评估模型复杂度和计算效率. 帧率FPS用于衡量模型每秒分析图像的能力,表示为
式中:tp为图像预处理时间,tn为图像推理时间,to为图像后处理时间,均以ms为单位.
2.4. 消融实验
2.4.1. EMA特征分组消融实验
在所提模型中,EMA模块的特征分组数G设置为32. 为了验证G对模型性能的影响,在基线模型上应用Faster-Rep-EMA模块,并设置EMA_no(不分组)、EMA_16(G=16)、EMA_32(G=32)、EMA_64(G=64)等不同的超参数配置进行消融实验,结果见表2.
表 2 采取不同特征分组数的实验结果
Tab.2
| 分组配置 | mAP@0.5/% | Np/M | FLOPs/G | FPS/(帧·s−1) |
| EMA_no | 83.1 | 16.1 | 47.1 | 99.7 |
| EMA_16 | 83.9 | 17.0 | 47.4 | 98.6 |
| EMA_32 | 84.3 | 16.4 | 47.2 | 99.4 |
| EMA_64 | 83.6 | 16.7 | 47.4 | 98.9 |
当G=16或64时,计算量和参数量较大,且性能提升不如EMA_32,这是因为当G过小时,子特征组的通道数C/G较大,而当G过大时,子特征组数过多,2种情况均会增加卷积操作和跨空间学习的计算复杂度. EMA_no因未进行跨空间学习,无法获取更多语义信息,检测精度显著低于EMA_32. 因此,采取EMA_32时能够在检测性能和计算复杂度之间取得较好的平衡.
2.4.2. 模块消融实验
为了验证所提模型中各改进措施的有效性,在相同的实验条件下,以RT-DETR为基线模型,依次应用Faster-Rep-EMA、ETB-AIFI、SOEP模块,在DUO数据集上进行消融实验. 最后,将3个模块同时加入基线模型,再次评估其各项数据指标. 实验结果如表3所示,其中,Faster-Rep-EMA模块被简写为FRE.
表 3 各模块的消融实验结果
Tab.3
| FRE | ETB-AIFI | SOEP | P/% | R/% | mAP@0.5/% | mAP@0.5꞉0.95/% | Np/M | FLOPs/G | FPS/(帧·s −1) |
| × | × | × | 84.8 | 74.9 | 82.4 | 63.2 | 20.8 | 56.9 | 85.5 |
| √ | × | × | 86.5 | 76.1 | 84.3 | 64.6 | 16.4 | 47.2 | 99.4 |
| × | √ | × | 87.1 | 76.6 | 84.9 | 64.8 | 22.1 | 60.3 | 73.5 |
| × | × | √ | 86.9 | 76.4 | 84.2 | 64.6 | 17.7 | 50.7 | 92.6 |
| √ | √ | × | 86.4 | 76.1 | 83.9 | 64.1 | 18.3 | 54.6 | 85.3 |
| √ | × | √ | 86.2 | 75.8 | 84.1 | 64.4 | 16.9 | 51.5 | 100.0 |
| × | √ | √ | 87.2 | 76.9 | 84.4 | 64.9 | 20.4 | 56.7 | 80.2 |
| √ | √ | √ | 87.4 | 77.2 | 85.6 | 65.3 | 17.8 | 48.4 | 95.7 |
由表3可知,各改进模块均有效提升了模型性能. 其中,高效多尺度注意力特征提取(Faster-Rep-EMA)模块使基线模型的精确率和召回率分别提升了1.7和1.2个百分点,mAP@0.5、mAP@0.5꞉0.95分别提升了1.9和1.4个百分点,参数量和计算量分别减少了4.4 M和9.7 G,FPS提高到99.4帧/s. 这主要得益于Faster-Rep-EMA模块在色偏环境下卓越的特征提取能力. 当单独采用ETB-AIFI模块时,尽管参数量和计算量有所增加,FPS降至73.5帧/s,但是精确率、召回率、mAP@0.5、mAP@0.5꞉0.95较基线模型分别提升了2.3、1.7、2.5、1.6个百分点,表明ETB-AIFI通过频率域和空间域特征的交互融合策略有效提升了模型的检测性能. 当单独采用小目标增强金字塔(SOEP)时,精确率、召回率、mAP@0.5、mAP@0.5꞉0.95较基线模型分别提升了2.1、1.5、1.8、1.4个百分点,参数量和计算量分别下降了3.1 M、6.2 G,FPS达到92.6帧/s,验证了SOEP模块能够在保持高精度的同时提升计算效率. 最后,在基线模型上同时应用Faster-Rep-EMA、ETB-AIFI、SOEP模块,精确率、召回率、mAP@0.5、mAP@0.5꞉0.95较基线模型分别提升了2.6、2.3、3.2、2.1个百分点,参数量和计算量分别下降了3.0 M和8.5 G,FPS提高至95.7帧/s. 这些结果表明改进模型与基线模型相比有了明显的性能提升,并在检测精度和计算资源消耗之间实现了良好的平衡,验证了其对水下色偏环境中小型生物检测的有效性.
2.5. 对比实验
2.5.1. PConv通道数对比实验
为了验证Faster-Rep-EMA模块中部分卷积的实际通道数Cp与输入特征图的总通道数C的比值r对FES-DETR检测速度和精度的影响,在相同的实验条件下,分别令Cp=C/2、C/4、C/8,在DUO数据集上进行3组对比试验. 实验结果如表4所示.
表 4 通道数对比实验结果
Tab.4
| r | mAP@0.5/% | Np/M | FLOPs/G | FPS/(帧·s−1) |
| 1/2 | 85.4 | 18.1 | 48.6 | 95.4 |
| 1/4 | 85.6 | 17.8 | 48.4 | 95.7 |
| 1/8 | 85.0 | 17.6 | 48.3 | 96.3 |
由表4可知,当r=1/2,即Cp取总通道数的1/2时,mAP@0.5比r=1/4(本研究模型)时下降了0.2个百分点,参数量和计算量分别增加了0.3 M和0.2 G,FPS下降到95.4 帧/s. 当r=1/8时,mAP@0.5比r=1/4时下降了0.6个百分点,参数量和计算量分别减少了0.2 M和0.1 G,FPS提高至96.3帧/s. 这是因为r过大会使PConv退化为常规卷积,影响了计算速度;当r过小时,PConv利用的特征图通道信息太少,使模型的特征提取能力不足,从而影响了检测精度. 当r=1/4时,模型在特征提取效率和检测精度之间取得了良好的平衡.
2.5.2. 模型对比实验
表 5 FES-DETR与主流目标检测算法的对比实验结果
Tab.5
| 模型 | P/% | R/% | mAP@0.5/% | mAP@0.5꞉0.95/% | Np/M | FLOPs/G | FPS/(帧·s−1) |
| Faster R-CNN | 75.8 | 70.4 | 73.1 | 57.2 | 41.1 | 126.7 | 46.5 |
| YOLOv5s | 81.0 | 71.2 | 77.6 | 61.5 | 10.1 | 23.2 | 123.7 |
| YOLOv8n | 83.7 | 72.6 | 79.3 | 61.7 | 7.9 | 17.6 | 128.4 |
| YOLOv9t | 84.5 | 73.1 | 80.4 | 62.1 | 9.8 | 20.3 | 97.2 |
| YOLOv10n | 84.7 | 73.5 | 82.3 | 62.8 | 7.7 | 18.4 | 133.4 |
| YOLOv11n | 85.2 | 75.2 | 82.7 | 63.4 | 9.4 | 19.1 | 148.2 |
| Deformable-DETR | 84.2 | 73.8 | 81.7 | 62.3 | 40.6 | 88.2 | 68.6 |
| RT-DETR-r50 | 85.3 | 75.3 | 82.9 | 63.6 | 41.9 | 130.8 | 63.7 |
| RT-DETR-r34 | 84.4 | 74.1 | 82.2 | 62.7 | 31.1 | 74.5 | 82.3 |
| RT-DETR-r18 | 84.8 | 74.9 | 82.4 | 63.2 | 20.8 | 56.9 | 85.5 |
| FES-DETR | 87.4 | 77.2 | 85.6 | 65.3 | 17.8 | 48.4 | 95.7 |
在检测精度方面,FES-DETR凭借高效、精细的特征融合能力和对色偏图像的针对性优化,展现出优越的性能. 在轻量化和实时性方面,先进的轻量级YOLO系列模型表现更佳,FES-DETR虽然稍逊一筹,但是凭借出色的检测精度弥补了这一不足,最终实现了轻量化、实时性和检测精度的良好平衡,展现出更优的综合性能. 训练结果如图11所示,其中(a)~(d)分别展示了不同模型在训练过程中的精确率、召回率、mAP@0.5和mAP@0.5∶0.95曲线. 结果表明,FES-DETR在各项指标上均优于其他模型,进一步验证了其以较低的计算资源消耗实现了最高的检测精度,综合性能优于主流目标检测模型.
图 11
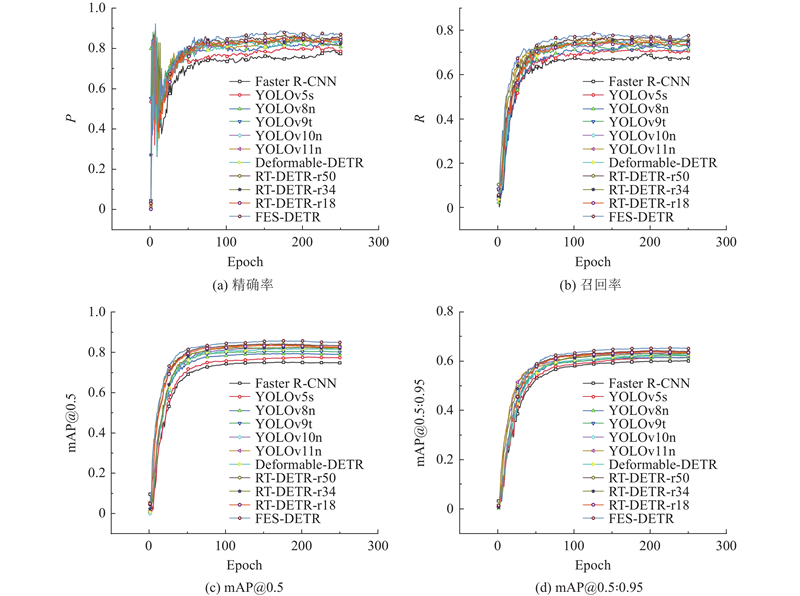
图 11 多算法实验指标对比
Fig.11 Comparison of experimental metrics for multiple algorithms
2.6. 可视化展示
为了更加直观地展示所提模型相较于其他主流模型在水下色偏环境中的优势,采用先进的可视化技术Grad-CAM++[25]深入了解模型在预测时如何关注输入图像中的重要特征,并以热力图的形式突出显示对模型输出影响最大的像素区域,从而增强改进模型的可解释性. 这种可视化策略不仅增强了对模型决策过程的理解,而且为模型的进一步优化提供了强大的视觉支持.
图 12

图 12 多算法检测结果可视化对比
Fig.12 Visual comparison of detection results of multiple algorithms
图 13

3. 结 语
针对水下小型生物检测任务中因图像失真、色偏、对比度降低引起的检测精度低、漏检率高的问题,提出基于改进RT-DETR的水下小型生物检测方法FES-DETR. 首先,在主干网络中设计高效多尺度注意力特征提取(Faster-Rep-EMA)模块,以提高模型对色偏图像的特征提取能力和计算效率. 其次,在颈部网络中构建ETB-AIFI模块,实现频率域和空间域特征的交互融合,进一步增强模型的抗色偏干扰能力. 最后,设计轻量化小目标特征增强金字塔(SOEP)来增强模型对小目标的检测性能并降低计算冗余. 在公开数据集DUO上的实验结果表明,FES-DETR对色偏环境下水下小型生物的检测性能显著提高. 精确率、召回率较基线模型RT-DETR-r18分别提升了2.6和2.3个百分点,平均精度均值mAP@0.5提升了3.2个百分点,mAP@0.5꞉0.95提升了2.1个百分点,参数量和计算量分别下降了3.0 M和8.5 G,FPS提高至95.7帧/s. 与其他主流目标检测模型相比,该模型的综合性能更为出色. 尽管FES-DETR在检测精度上表现不错,但是仍有很多方面需要进一步优化,如模型参数量、计算量、实时性等. 未来将开展更加深入的研究,考虑结合图像增强技术和水下机器人,进一步增强其在实际色偏环境中的检测性能.
参考文献
Advancing underwater vision: a survey of deep learning models for underwater object recognition and tracking
[J].DOI:10.1109/ACCESS.2025.3534098 [本文引用: 1]
Underwater biological detection algorithm based on improved faster-RCNN
[J].DOI:10.3390/w13172420 [本文引用: 1]
基于分割注意力与线性变换的轻量化目标检测
[J].DOI:10.3785/j.issn.1008-973X.2023.06.015 [本文引用: 1]
Lightweight object detection based on split attention and linear transformation
[J].DOI:10.3785/j.issn.1008-973X.2023.06.015 [本文引用: 1]
改进YOLOv8的轻量化水下生物检测模型
[J].DOI:10.3778/j.issn.1002-8331.2408-0411 [本文引用: 1]
Improving lightweight underwater biological detection model of YOLOv8
[J].DOI:10.3778/j.issn.1002-8331.2408-0411 [本文引用: 1]
Underwater object detection algorithm integrating image enhancement and deformable convolution
[J].DOI:10.1016/j.ecoinf.2025.103185 [本文引用: 1]
Real-time underwater object detection technology for complex underwater environments based on deep learning
[J].DOI:10.1016/j.ecoinf.2024.102680 [本文引用: 1]
Dual-stream feature pyramid network with task interaction for underwater object detection
[J].DOI:10.1016/j.dsp.2025.105199 [本文引用: 1]
基于改进CycleGAN的多失真类型水下图像增强
[J].
Multi-distortion type underwater image enhancement based on improved CycleGAN
[J].
Underwater single image color restoration using haze-lines and a new quantitative dataset
[J].DOI:10.1109/tpami.2020.2977624 [本文引用: 1]
SOD-YOLOv8: enhancing YOLOv8 for small object detection in aerial imagery and traffic scenes
[J].
Omni-kernel modulation for universal image restoration
[J].DOI:10.1109/TCSVT.2024.3429557 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}