

复杂城市交通环境中的目标遮挡与雾天干扰是降低自动驾驶感知可靠性的关键因素. 有雾导致图像对比度下降与细节丢失,而密集场景中的目标遮挡则引发边界重叠与语义混淆,共同导致检测精度下降. 为了解决上述问题,研究者们主要从图像去雾与遮挡目标检测2个方向展开探索. 去雾算法主要包括3类:1)基于图像增强的方法,如Retinex理论[5]与直方图均衡化;2)基于物理模型的方法,如He等[6]提出基于暗通道先验的单图像去雾方法;3)基于深度学习的方法,如Cai等[7]提出端到端的卷积神经网络,能够从数据中学习雾特征;Liu等[8]提出基于物理的对抗生成网络,通过反演-对抗与周期一致性损失增强对比度,并利用双CNN分别学习大气光与透射图以恢复纹理.
在遮挡目标检测方面,传统方法多采用基于部件的模型或专用分类器,Cai等[9]通过融合HOG与颜色特征,改进CNN分类器,提升了遮挡情况下目标检测的准确性与鲁棒性. 近年来,基于深度学习的检测框架成为主流,如Tang等[10]采用级联提升分类器替换Softmax,从而改进Faster R-CNN,提升检测精度,然而其检测速度仍须优化;Su等[11]提出改进的YOLOv7 Tiny算法,用于自动驾驶中的遮挡目标检测,相对于YOLOv7,其mAP提高了2.8个百分点,但在小目标检测场景下性能欠佳;Aghaee等[12]基于SSD-MobileNetV2构建新方案,在精度与速度间取得了良好均衡,相对于MobileNetV2,其在遮挡下的检测性能提升了6.08个百分点,但其计算开销仍有优化空间;Zhang等[13]提出的TransFusion框架通过激光雷达与雷达融合,有效提升了雾天检测的鲁棒性,但其对高分辨率激光雷达依赖性较高,从而成本较高. 综上,现有遮挡检测方法存在实时性不足与检测精度不足的问题,使得实现高效精准的检测成为车辆与行人检测领域的关键发展方向.
针对雾天交通场景中图像模糊和目标遮挡导致的检测性能下降问题,本研究提出融合改进AOD-Net[14]与SSD[15]的联合网络优化检测算法,用于提升有雾环境下车辆及行人检测的准确性与速度. 为了进行去雾增强,提出新去雾框架ABMD-Net(all-in-one bilateral enhancement module multilevel dehazing network),以降低模型复杂度和提升图像细节恢复能力;在目标检测架构设计中,提出新型网络框架MsF-SSD-Net(MobileNetV3_small[16] feature fusion single shot multibox detector network),以提升模型对局部可见目标的检测能力;检测优化层采用改进的自适应Soft-NMS[17],并结合经AdaXod[18]优化算法改进的自适应Focal Loss,动态平衡正负样本权重,以提升整体模型对噪声标签的鲁棒性.
1. 改进网络模型
1.1. 改进去雾算法网络
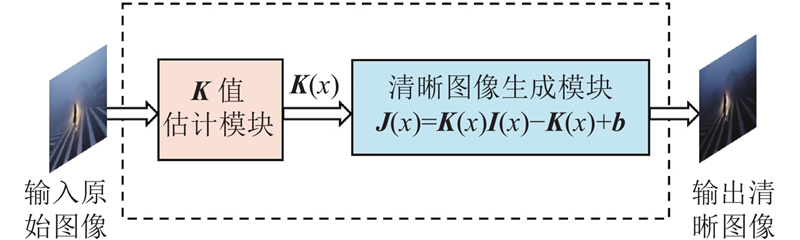
如图1所示,AOD-Net去雾网络算法是一种端到端的图像去雾网络,其核心创新在于重构了大气散射模型,通过一个轻量级CNN直接实现从有雾图像到清晰图像的映射,无需估计中间参数. 该网络包含2个核心模块:1)K-估计模块,用于估计蕴含深度与雾浓度信息的参数K(x);2)清晰图像恢复模块,利用K(x)作为自适应参数输出无雾图像J(x). AOD-Net受限于浅层架构,存在参数估计敏感且易引发误差传导、高频细节损失的问题,会导致去雾结果出现边缘模糊与纹理退化.
图 1
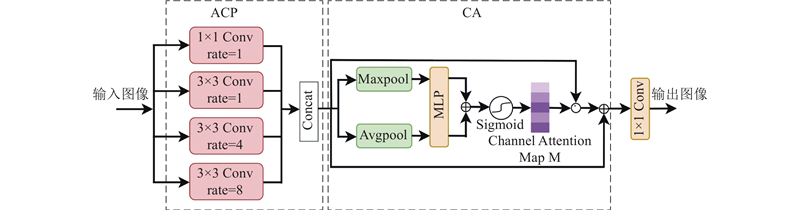
为了解决AOD-Net的局限性,提出基于三重优化策略的网络去雾算法ABMD-Net,结构如图2所示. 首先重构网络连接,建立跨层特征复用机制,利用参数共享实现轻量化设计. 其次构建包含多级下采样与上采样的特征金字塔结构,以扩展网络感受野并有效捕获非均匀雾分布特征. 最后引入边界增强模块(boundary enhancement module,BEM),采用自适应特征融合策略以平衡全局亮度校正与局部纹理增强. BEM结构如图3所示,采用双分支架构:1)自适应上下文金字塔模块(adaptive context pyramid module,ACP)利用多膨胀率空洞卷积提取多尺度边界特征;2)通道注意力模块(channel attention module,CA)通过双路池化与共享MLP生成注意力图,对特征进行重校准. 该模块最终通过残差连接输出优化后的边界特征,有效提升雾天复杂场景下的边界辨识能力. 此外,模型还采用深度可分离卷积替代标准卷积,进一步降低计算复杂度.改进后的模型通过层次化特征增强设计,兼顾实时性和去雾图像的细节还原度及整体质量,主客观评价均达到预期.
图 2
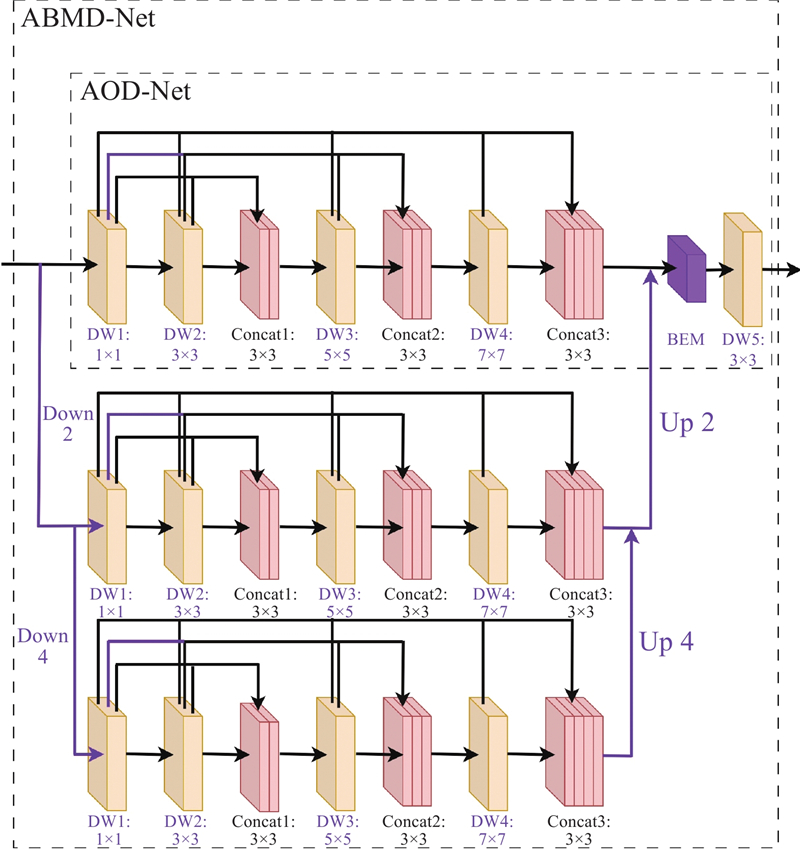
图 3
1.2. 改进遮挡目标检测算法
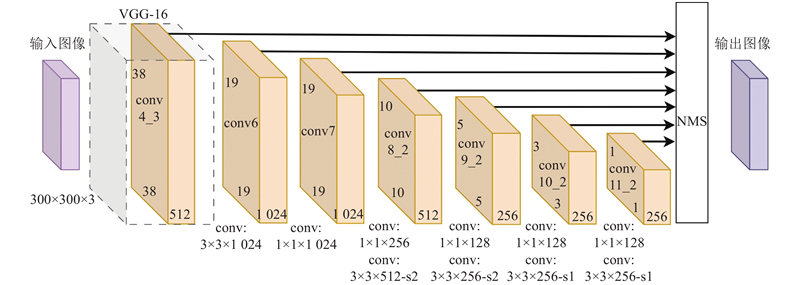
如图4所示,传统SSD目标检测网络作为单阶段多尺度检测的经典代表,其架构基于VGG-16骨干网络,采用300×300输入分辨率并辅以数据增强策略. 然而,VGG-16网络层级深、参数量大,在处理224×224的标准输入分辨率时须进行图像裁剪或缩放,导致边缘信息损失.
图 4
为了解决SSD网络参数量大、图像处理能力不足的问题,提出如图5所示的MsF-SSD-Net检测框架,采用多维度协同优化策略. 首先,输入图像经ABMD-Net进行去雾预处理,以提升图像质量. 在特征提取阶段采用集成注意力机制的轻量化MobileNetV3_small主干网络,结合深度可分离卷积与h-swish激活函数,降低计算复杂度和保持特征提取性能. 网络主体构建多层级特征融合模块(Fused feature 1~3),融合空间金字塔、可变形卷积与自适应池化,构建多尺度感知特征图,并通过门控单元动态调节融合权重,实现浅层细节与深层语义的有效互补. 在检测后处理阶段引入自适应超参数Soft-NMS算法,精准抑制冗余边界框以提升召回率与检测精度,同时采用改进的自适应Focal Loss重构置信度损失函数,缓解正负样本不平衡及噪声标签敏感性问题.
图 5
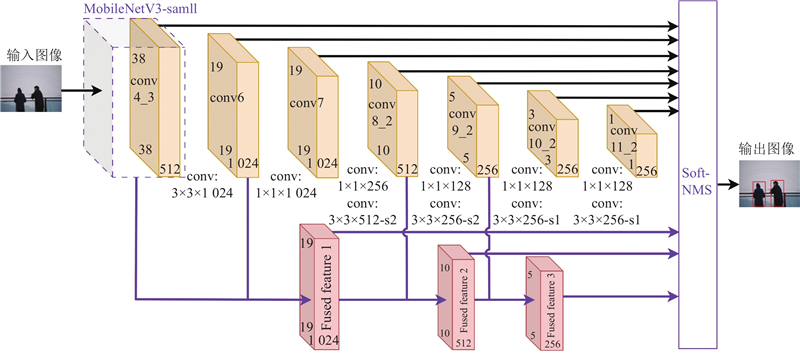
最终,通过图像增强、特征提取、多尺度融合与自适应检测优化,构建出适应复杂环境且兼顾准确性与效率的视觉检测算法.
1.2.1. 特征提取及改进注意力机制
如图6(a)所示, MobileNetV3_small的核心Block采用深度可分离卷积与SE(Squeeze-and-Excitation)注意力机制,减少了参数并实现了通道自适应加权,但是高压缩比策略过度削减通道维度,削弱了通道间依赖关系的建模,导致自适应校准能力下降与重要信息丢失,且在遮挡场景中难以捕捉关键空间结构.
图 6
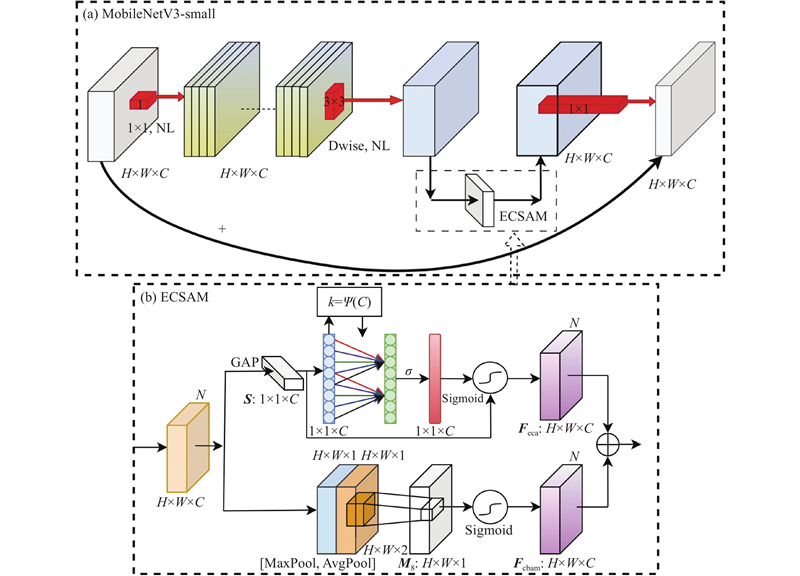
针对上述问题,提出如图6(b)所示的融合全局通道注意力与空间注意力(efficient channel-spatial attention module,ECSAM)模块. 该模块通过跨维度互补增强网络对局部特征的捕捉能力,提升模型在遮挡目标场景下的响应性能. 其中,空间感知模块结合通道统计与极值响应,经卷积生成空间权重图. 该设计在增强深层特征表达能力的同时,保持计算轻量化的特性.
1)通道注意力模块保留全局平均池化层,将输入特征图在空间维度上压缩成形状为(1,1,C)的特征向量,表达式如下:
式中:
2)空间注意力模块沿通道轴对输入特征图进行最大池化和平均池化,生成2个形状为(N,1,H,W)的2D特征图
式中:
式中:
图 7

图 7 特征提取网络检测对比图
Fig.7 Comparison of detection results by feature extraction networks
1.2.2. 特征融合机制
SSD采用多尺度独立预测机制,其浅层特征分辨率高但语义信息不足,深层特征语义丰富但分辨率低、细节丢失严重,导致不同层级特征之间存在语义鸿沟.
针对检测中的遮挡问题,提出双路径异构卷积特征融合机制(fused feature). 该结构采用并行分支:一路通过3×3深度可分离卷积提取空间细节(160通道),另一路借助3×3标准卷积捕获全局语义(
图 8
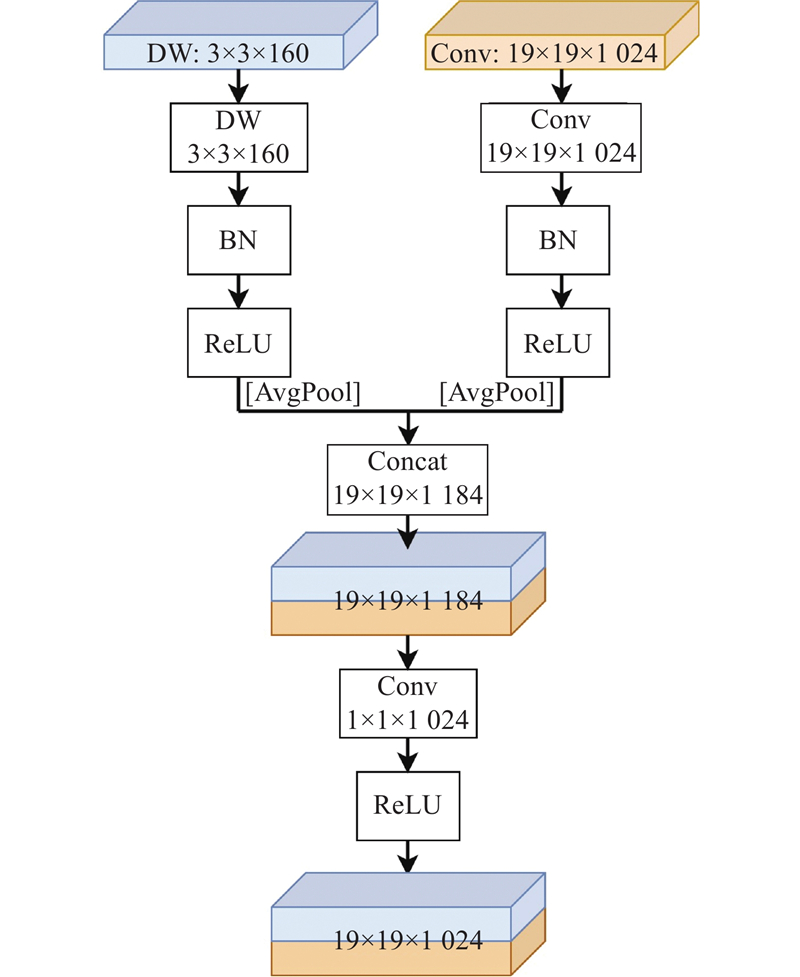
图 8 普通-深度可分离卷积双分支池化拼接融合模块
Fig.8 Ordinary-deep separable convolutional double branch pooling splicing fusion module
1.2.3. 改进损失函数
为了兼顾去雾与检测任务的端到端协同优化,将ABMD-Net与MsF-SSD-Net的损失函数相结合. 针对检测中小目标提取困难、背景噪声干扰和正负样本不平衡等问题,须构建多尺度敏感的损失函数. 原SSD损失由定位损失(Lloc,smooth L1 loss)与分类置信损失(Lconf,softmax loss)构成,但背景类锚框数量过多导致训练中正负样本严重失衡,易引发训练震荡与收敛缓慢. 为此,采用经AdaXod算法改进的Focal Loss重构置信度损失,能有效抑制负样本主导作用,缓解样本失衡与噪声敏感问题.
将ABMD-Net与MsF-SSD-Net的损失函数相结合是端到端训练的关键,可同时引导去雾与检测任务协同优化.
改进分类Focal Loss的表达式如下:
改进的SSD总损失函数表达式如下:
式中:
1.2.4. 改进的Soft-NMS算法
Soft-NMS算法是对经典NMS算法的有效改进,其核心是避免直接删除与高分检测框重叠的候选框,转而采用柔性抑制策略,通过降低高度重叠框的置信度实现目标保留,但其高斯衰减函数中的超参数
为此,提出超参数
Soft-NMS算法使用的高斯衰减函数与改进超参数调整策略表达式如下:
式中:
2. 实验配置
2.1. 数据集和训练配置
SOTS作为RESIDE的标准子集,提供有雾图像与对应无雾真实图像,支持PSNR、SSIM之类的客观量化评估;CityPersons基于Cityscapes构建,包含
参照世界气象组织(WMO)与中国气象局(CMA)标准,将能见度低于1 km的气象条件划分为薄雾、中雾与重雾3个等级,作为后续雾浓度分级的依据. 通过设置不同的
表 1 去雾评价指标
Tab.1
| 不同场景 | V/km | |
| 薄雾 | 0.005 | 0.6≤V<1.0 |
| 中雾 | 0.010 | 0.3≤V<0.6 |
| 重雾 | 0.020 | V<0.3 |
对于遮挡情况,在CityPersons和Foggy Cityscapes数据集中将目标的遮挡程度分为3个等级,定义遮挡指标为t,标准如下:轻微遮挡(slight occlusion,So, 0%<t≤35%)、部分遮挡(partial occlusion,Po,35%<t≤75%)、严重遮挡(severe occlusion,Se,75%<t≤100%).
在训练过程中,学习率为
2.2. 评估指标
为了对图像去雾处理的效果进行精确的定量评估,选用的图像质量评价指标为峰值信噪比(peak signal-to-noise ratio, PSNR)和结构性相似指数(structural similarity index measure, SSIM),计算公式如下:
式中:MAX表示单通道像素可能的最大值,对于8位深度的RGB图像,各颜色通道的最大值均为255;MSE为均方误差,须分别计算R/G/B通道后取平均值; x为参考图像,即无雾的原始图像;y为待评估图像,即去雾算法输出的结果图像;f为亮度分量的权重系数,用于调节亮度在整体SSIM中的贡献度,默认取1;
在遮挡目标检测阶段,采用多元化的评估指标体系,包括精度Pr、召回率Re、F1分数、平均像素准确率mPA和检测速度FPS. 各指标计算公式如下:
式中:TP、TN、FP和FN分别代表真阳性、真阴性、假阳性和假阴性样本数量,Time表示模型单帧图像前向推理与后处理的总耗时.
3. 结果分析
3.1. 去雾实验结果分析
在SOTS数据集上的实验表明,ABMD-Net在图像去雾方面具有优势. 如表2所示,在薄雾、中雾和重雾场景下的PSNR与SSIM指标均优于对比模型,能更准确地还原图像亮度与结构细节,有助于后续检测任务的特征提取. 在不同雾浓度下,ABMD-Net性能下降幅度最小,表现出良好的鲁棒性. 同时,其FPS达86.96 帧/s,保证了高质量去雾效果和实时处理,优于侧重推理速度的Improve AOD-Net模型,能够为雾天车辆与行人检测提供清晰、及时的图像输入.
表 2 有雾图像上的PSNR和SSIM
Tab.2
| 模型 | 薄雾 | 中雾 | 重雾 | FPS/(帧·s−1) | |||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||||
| AOD-Net | 19.49 | 18.15 | 17.79 | 38.46 | |||||
| MSCNN[25] | 19.80 | 18.15 | 16.92 | 27.78 | |||||
| GCANet[25] | 22.43 | 18.11 | 16.94 | 7.46 | |||||
| GFN[25] | 21.15 | 17.33 | 16.93 | 14.70 | |||||
| DehazeNet[25] | 20.46 | 19.18 | 18.89 | 23.81 | |||||
| ABMD-Net | 24.02 | 20.32 | 20.03 | 86.96 | |||||
| Improve AOD-Net[25] | 21.80 | 17.79 | 14.14 | 113.64 | |||||
图 9

3.2. 目标检测结果分析
如表3所示,为了评估目标检测系统在遮挡场景下的性能,基于CityPersons数据集进行不同遮挡环境下的检测实验. 结果表明,在实时性方面,其FPS达74.07 帧/s,优于SSD(FPS为15.38 帧/s)和Faster R-CNN(FPS为8.13 帧/s);与FPS更高但精度较低的improved YOLOv7相比,MsF-SSD-Net在保持高帧率的同时具备更均衡的准确率,满足雾天场景下对实时性与准确率的综合需求;在检测精度方面,MsF-SSD-Net的F1值为
表 3 基于CityPersons数据集的各目标检测模型在遮挡场景下的性能对比
Tab.3
| 模型 | FPS/ (帧·s−1) | F1 | Pr | Re | mAP | ||
| So | Po | Se | |||||
| SSD | 15.38 | ||||||
| Faster R-CNN | 8.13 | ||||||
| YOLOv10 | 55.56 | ||||||
| MsF-SSD-Net | 74.07 | ||||||
| DCT- YOLO[26] | — | — | — | ||||
| improved YOLOv7[27] | 252.00 | — | — | ||||
训练过程如图10所示,F1分数、Pr、Re和Loss函数这4项指标均随训练轮次的增加而稳步收敛. F1值最终达到并保持在较高水平,精确率与召回率曲线亦快速上升后维持高位,模型拥有对正样本的高识别精度与强检出能力. 损失函数迅速下降至较低水平并趋于稳定,表明模型收敛速度快、训练稳定性好. 整体性能优于Faster R-CNN、SSD和YOLOv10等对比网络.
图 10
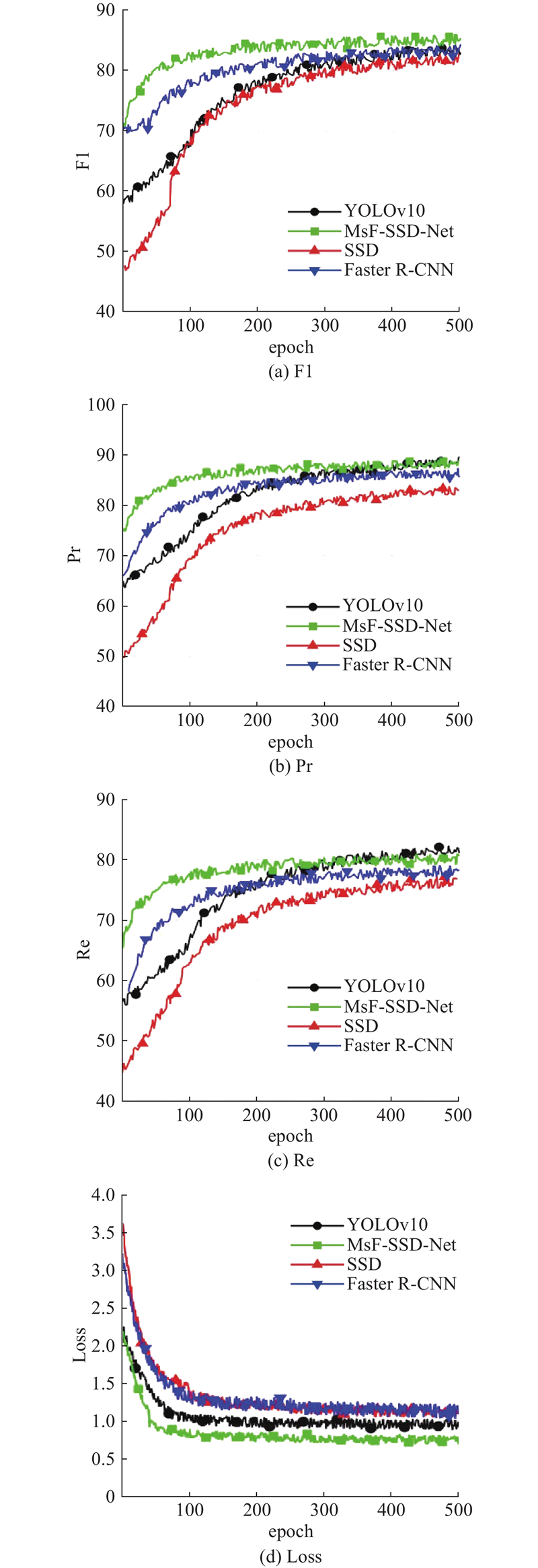
图 10 不同模型基于CityPersons 数据集的训练评价指标对比
Fig.10 Comparison of training evaluation metrics for different models based on CityPersons dataset
综上,MsF-SSD-Net在实时性、检测精度与遮挡鲁棒性三者间取得了良好平衡,能够为雾天与遮挡共存的复杂场景下的车辆与行人检测任务提供可靠技术支持.
如表4所示,针对Foggy Cityscapes数据集的复杂多变场景,MsF-SSD-Net在各类雾浓度与遮挡条件下均保持了稳定的性能优势,场景适应性与鲁棒性优于其他对比模型. 在检测精度方面,该模型在清晰、薄雾、中雾及重雾环境下的mAP分别为88.76%、84.01%、79.34%和66.78%,优于SSD、Faster R-CNN和YOLOv10等对比模型,在全雾浓度范围内展现出良好的适应性与特征保持能力. 在实时性方面,MsF-SSD-Net的FPS达71.43 帧/s,高于多数对比模型,且与FPS更高但精度较低的lightweight YOLOv8相比,在检测精度与推理速度上更为平衡,能够有效满足智能交通监控与辅助驾驶系统对实时可靠检测的需求.
表 4 各目标检测模型在Foggy Cityscapes有雾数据集上的量化性能对比
Tab.4
| 模型 | mAP | FPS/(帧·s−1) | ||||||
| 清晰图像 | 薄雾 | 中雾 | 重雾 | So | Po | Se | ||
| SSD | 14.92 | |||||||
| Faster R-CNN | 8.04 | |||||||
| YOLOv10 | 52.62 | |||||||
| MsF-SSD-Net | 71.43 | |||||||
| lightweight YOLOv8[28] | — | — | — | — | — | — | 166.00 | |
如图11和表5所示为经ABMD-Net去雾处理后的各模型在Foggy Cityscapes数据集上的检测性能对比结果,其中ABMD-Net+MsF-SSD-Net表示将去雾和检测模型进行简单级联形式,ABMD-Net-MsF-SSD-Net表示将去雾检测的特征结果直接输入到改进的目标检测中形成的联合优化网络. ABMD-Net与MsF-SSD-Net的组合在Foggy Cityscapes数据集上展现出优越的综合性能. 在检测精度方面,联合优化网络在薄雾、中雾和重雾环境下的mAP分别达到93.85%、86.83%和78.24%,优于其他对比模型且略高于简单级联结构. 在实时性方面,联合网络的FPS为47.61帧/s,高于ABMD-Net与其他模型的结合方案,也优于Defog YOLO、YOLOv5-Transformer和AO YOLO等网络.
图 11

图 11 经ABMD-Net去雾后的图像检测结果可视化对比图
Fig.11 Visual comparison chart of image detection results after defogging by ABMD-Net
表 5 经ABMD-Net去雾处理后的各模型检测性能量化对比表
Tab.5
| 模型 | mAP | FPS/(帧·s−1) | |||||
| 薄雾 | 中雾 | 重雾 | So | Po | Se | ||
| ABMD-Net+SSD | 9.74 | ||||||
| ABMD-Net+Faster R-CNN | 5.38 | ||||||
| ABMD-Net+YOLOv10 | 32.79 | ||||||
| AOD-Net+MsF-SSD-Net | 25.03 | ||||||
| ABMD-Net+MsF-SSD-Net | 45.21 | ||||||
| Defog YOLO[29] | — | — | — | — | — | — | |
| YOLOv5-Transformer[30] | — | — | — | — | — | — | |
| AO YOLO[31] | — | — | — | — | — | — | |
| ABMD-Net-MsF-SSD-Net | 47.61 | ||||||
此外,ABMD-Net-MsF-SSD-Net组合在全雾浓度范围内表现出良好的适应性与鲁棒性,检测精度随雾浓度的增加下降较为平缓,能有效应对晨雾、浓雾之类的复杂场景. 研究表明,ABMD-Net与MsF-SSD-Net的联合优化实现了去雾质量与检测性能的高效统一,为雾天环境下的车辆与行人检测提供了可靠解决方案.
如图12所示展示了不同网络组合的训练损失变化. 所有模型均表现出持续优化趋势,其中MsF-SSD-Net相比原始SSD收敛更快、损失更低,训练过程更稳定;SSD收敛较慢,性能相对较弱. 将MsF-SSD-Net分别与AOD-Net和ABMD-Net级联,由于采用相同损失函数,两者损失曲线未见明显差异. 将ABMD-Net与MsF-SSD-Net检测网络联合优化后,损失迅速下降后趋于平稳.
图 12
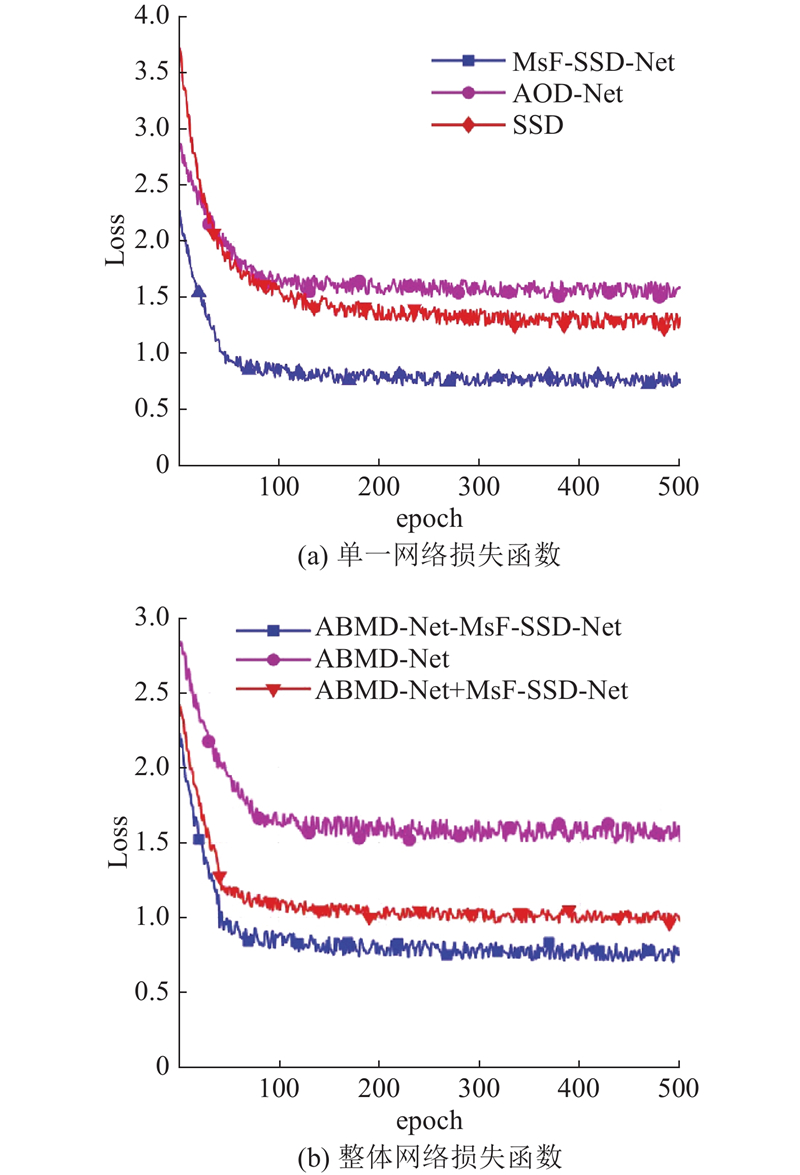
图 12 Foggy Cityscapes 数据集下不同网络模型的训练损失对比
Fig.12 Comparison of training losses of different network models on Foggy Cityscapes dataset
3.3. 消融实验
3.3.1. 改进去雾网络算法消融实验
为了验证ABMD-Net去雾网络算法的有效性及其性能提升效果,在公开的SOTS数据集上开展消融实验,结果如表6所示. 基于AOD-Net依次进行以下改进:首先重构原始网络连接拓扑形成AOD-Net1,该模型的PSNR和SSIM均实现小幅提升,细节保留略有改善,但FPS下降0.29 帧/s;随后引入深度可分离卷积得到AOD-Net1(DW),FPS提升至117.65 帧/s,在保障图像质量的同时提高了处理效率;进一步构建多级下采样与上采样的特征金字塔结构形成AOD-Net1(DW)(Pyramid),该模型在不同浓度雾图上的PSNR与SSIM均有提高,图像质量得到改善且处理速度较快.
表 6 AOD-Net算法消融实验结果
Tab.6
| 算法改动 | 薄雾 | 中雾 | 重雾 | FPS/(帧·s−1) | |||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||||
| AOD-Net | 20.31 | 18.15 | 17.79 | 38.17 | |||||
| AOD-Net1 | 20.82 | 18.87 | 17.92 | 37.88 | |||||
| AOD-Net1(DW) | 20.73 | 18.78 | 17.86 | 117.65 | |||||
| AOD-Net1(DW)(Pyramid) | 22.43 | 19.44 | 18.84 | 107.53 | |||||
| ABMD-Net | 24.02 | 20.32 | 20.03 | 86.96 | |||||
在AOD-Net1(DW)(Pyramid)架构中集成边界增强模块构建出ABMD-Net,模型性能达到最优. 在薄雾场景下,PSNR提升3.71,SSIM提高0.0870,图像清晰度接近无雾水平,FPS稳定维持在86.96 帧/s. 实验结果显示,ABMD-Net在所有测试环境中均取得最高的PSNR与SSIM,输出图像细节丰富、结构完整、视觉效果清晰,并保持较快处理速度,算法逐步改进的效果如图13所示.
图 13

图 13 AOD-Net消融实验效果对比图
Fig.13 Comparison of AOD-Net ablation experimental results
3.3.2. 改进遮挡目标检测消融实验
为了验证改进SSD算法在有雾场景下对遮挡目标的检测效果,基于CityPersons数据集进行消融实验. 如表7所示,通过逐步改进策略提升目标检测性能:首先将SSD的主干特征提取网络替换为MobileNetV3_small,检测速度FPS提升至117.65 帧/s,同时精度产生0.4%的损失;MobileNetV3-EC+SSD表示通过引入ECSAM注意力机制, mAP提升至85.45%,FPS为75.76 帧/s;其次,叠加多层级特征融合(MobileNetV3-EC+SSD1),mAP增长至87.32%;随后,应用Soft-NMS(MobileNetV3-EC+SSD1+Soft-NMS)将召回率提升至
表 7 SSD算法消融实验结果表
Tab.7
| 算法改动 | mAP | F1 | Time/ms | FPS/(帧·s−1) | Pr | Re | Params/106 |
| SSD | 65.1 | 15.36 | 138.36 | ||||
| MobileNetV3+SSD | 8.5 | 117.65 | 25.54 | ||||
| MobileNetV3-EC+SSD | 13.2 | 75.76 | 26.73 | ||||
| MobileNetV3-EC+SSD1 | 14.8 | 67.57 | 28.47 | ||||
| MobileNetV3-EC+SSD1+Soft-NMS | 15.3 | 65.36 | 28.47 | ||||
| MsF-SSD-Net | 13.5 | 74.07 | 28.47 | ||||
| L-SSD[32] | — | — | 106.00 | — | — | — |
综上所述,MsF-SSD-Net网络融合了主干轻量化、特征增强与训练优化等优点,最终模型的mAP值提升至88.75%,参数量减少至原模型的1/3.85,在检测速度与精度间取得了良好平衡.
4. 结 语
为了解决雾天与目标遮挡导致的检测准确率下降问题,提出融合ABMD-Net去雾模块与MsF-SSD-Net检测算法的联合模型. ABMD-Net在SOTS数据集上对不同浓度雾况均表现优异,能有效提升图像细节与结构完整性,在薄雾场景中,其PSNR与SSIM分别提高3.71与
本方案能有效提高雾天遮挡下的车辆与行人的检测精度,为智能驾驶系统提供支持. 不过,联合模型的检测速度由71.43帧/s降至47.61帧/s,可见去雾模块影响了实时性. 未来可从2方面优化:一是采用更高效和处理速度更快的去雾方法;二是增强模型在复杂真实环境中的准确率与泛化能力.
参考文献
Object detection in autonomous vehicles under adverse weather: a review of traditional and deep learning approaches
[J].DOI:10.3390/a17030103 [本文引用: 1]
Evaluation of automated emergency braking system’s avoidance of pedestrian crashes at intersections under occluded conditions within a virtual simulator
[J].DOI:10.1016/j.aap.2022.106797 [本文引用: 1]
Safety challenges for autonomous vehicles in the absence of connectivity
[J].DOI:10.1016/j.trc.2021.103133 [本文引用: 1]
Enhanced perception for autonomous vehicles at obstructed intersections: an implementation of vehicle to infrastructure (V2I) collaboration
[J].DOI:10.3390/s24030936 [本文引用: 1]
Retinex-based Laplacian pyramid method for image defogging
[J].DOI:10.1109/ACCESS.2019.2934981 [本文引用: 1]
Single image haze removal using dark channel prior
[J].DOI:10.18535/ijecs/v5i1.12 [本文引用: 1]
DehazeNet: an end-to-end system for single image haze removal
[J].DOI:10.1109/TIP.2016.2598681 [本文引用: 1]
A physics based generative adversarial network for single image defogging
[J].DOI:10.1016/j.imavis.2019.10.001 [本文引用: 1]
Anti-occlusion multi-object surveillance based on improved deep learning approach and multi-feature enhancement for unmanned smart grid safety
[J].DOI:10.1016/j.egyr.2023.01.074 [本文引用: 1]
Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining
[J].DOI:10.3390/s17020336 [本文引用: 1]
An improved YOLOv7 tiny algorithm for vehicle and pedestrian detection with occlusion in autonomous driving
[J].DOI:10.23919/cje.2023.00.256 [本文引用: 1]
MDSSD-MobV2: an embedded deconvolutional multispectral pedestrian detection based on SSD-MobileNetV2
[J].DOI:10.1007/s11042-023-17188-7 [本文引用: 1]
TransFusion: multi-modal robust fusion for 3D object detection in foggy weather based on spatial vision transformer
[J].DOI:10.1109/TITS.2024.3420432 [本文引用: 1]
Research on efficient classification algorithm for coal and gangue based on improved MobilenetV3-small
[J].DOI:10.1080/19392699.2024.2353128 [本文引用: 1]
Towards accurate dense pedestrian detection via occlusion-prediction aware label assignment and hierarchical-NMS
[J].DOI:10.1016/j.patrec.2023.08.019 [本文引用: 1]
AdaXod: a new adaptive and momental bound algorithm for training deep neural networks
[J].DOI:10.1007/s11227-023-05338-5 [本文引用: 1]
基于DCT-YOLO的密集遮挡行人检测算法
[J].DOI:10.3969/j.issn.1674-1331.2025.07.007 [本文引用: 1]
Dense occlusion pedestrian detection algorithm based on DCT-YOLO
[J].DOI:10.3969/j.issn.1674-1331.2025.07.007 [本文引用: 1]
An improved YOLOv7 tiny algorithm for vehicle and pedestrian detection with occlusion in autonomous driving
[J].DOI:10.23919/cje.2023.00.256 [本文引用: 1]
Road object detection in foggy complex scenes based on improved YOLOv8
[J].DOI:10.1109/ACCESS.2024.3438612 [本文引用: 1]
Defog YOLO for road object detection in foggy weather
[J].DOI:10.1093/comjnl/bxae074 [本文引用: 1]
Research on a recognition algorithm for traffic signs in foggy environments based on image defogging and transformer
[J].DOI:10.3390/s24134370 [本文引用: 1]
AOYOLO algorithm oriented vehicle and pedestrian detection in foggy weather
[J].DOI:10.23919/cje.2023.00.280 [本文引用: 1]
L-SSD: lightweight SSD target detection based on depth-separable convolution
[J].DOI:10.1007/s11554-024-01413-z [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}