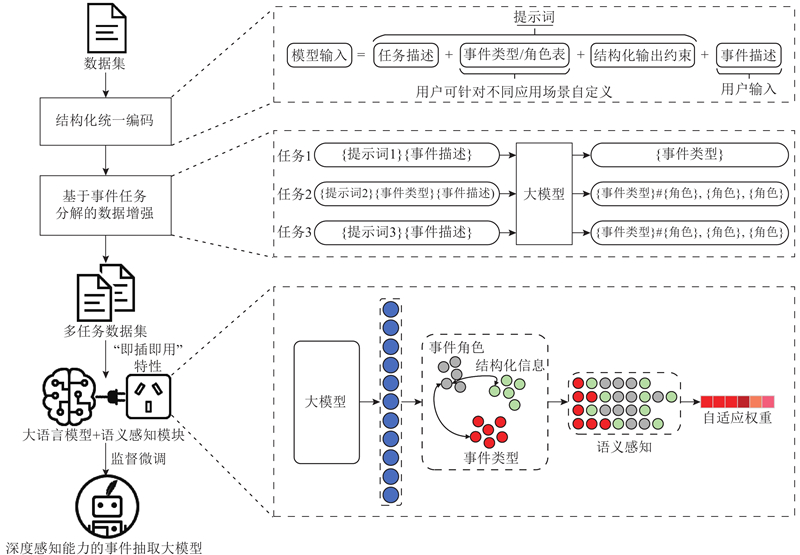
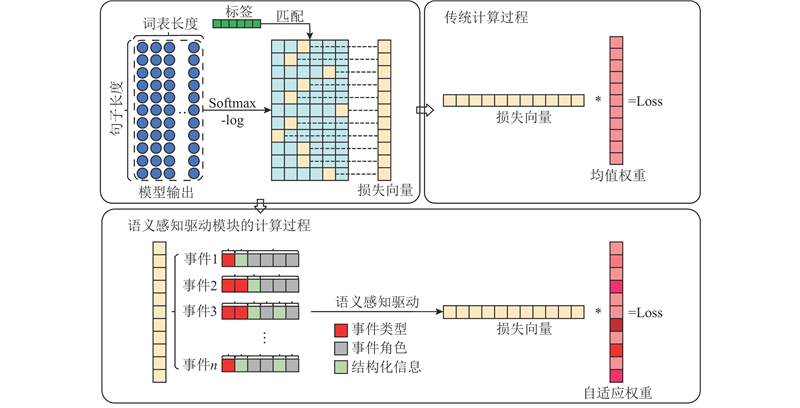
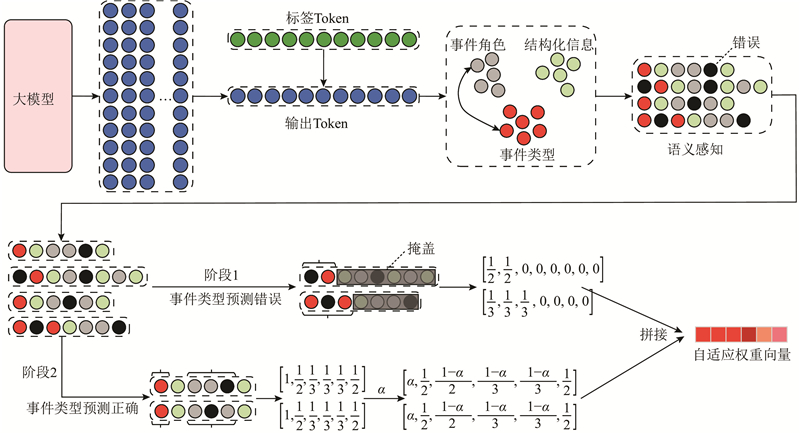
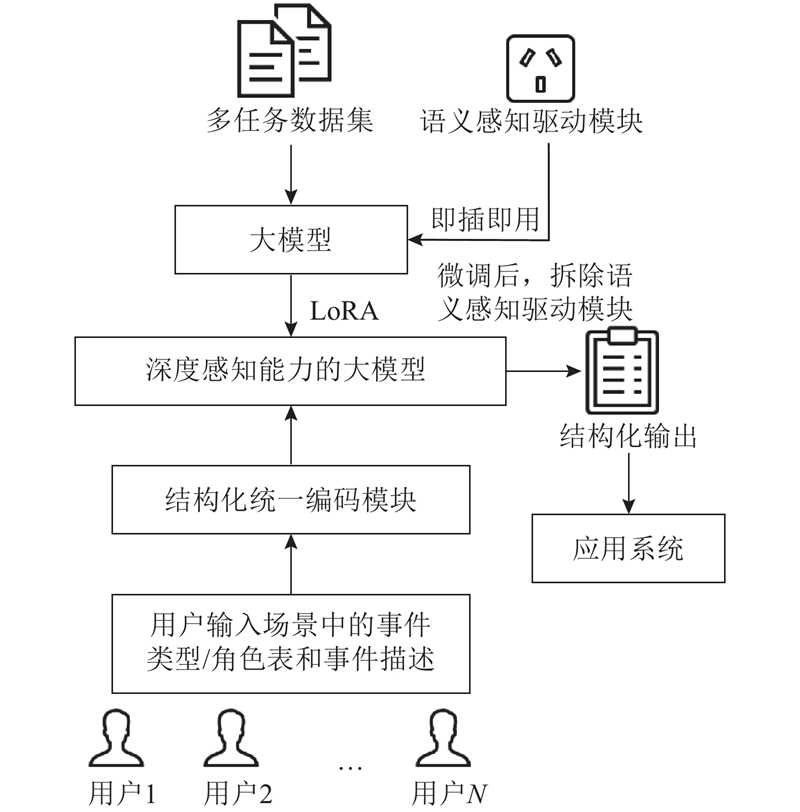
A large language model framework for event extraction based on staged semantic perception was proposed aiming at the difficulty in modeling the hierarchical semantics of events, which simulated the human cognitive mechanism of ‘recognizing the whole first and then learning the details’. The structured unified coding ensured consistency of prompts across different domains. The plug-and-play semantic perception driver unit supported staged learning for event-type prediction and argument extraction. The model focused on fine-grained semantic information by leveraging an adaptive weight mechanism. Data augmentation based on event decomposition was proposed to enrich the training data in order to enhance the generalization ability of the model. The experimental results on the CASIE and ACE2005 datasets demonstrated that our method significantly improved the performance of models in the event extraction.
Keywords:natural language processing
;
event extraction
;
large language model
;
supervised fine-tuning
;
data augmentation
LI Yansong, CHEN Ning, LIU Fengguang, CHEN Pan, HUANG Xiaofeng, GE Huili. Large language model framework for event extraction based on staged semantic perception. Journal of Zhejiang University(Engineering Science)[J], 2026, 60(3): 527-535 doi:10.3785/j.issn.1008-973X.2026.03.008
事件抽取(event extraction)是自然语言处理(natural language processing)领域中重要的研究,核心是从非结构化文本中识别并提取出用户感兴趣的信息并以结构化形式表达[1]. 自动内容抽取(automatic content extraction, ACE)国际评测会议组织将事件定义为:发生在某时、某地,由一个或多个角色参与的一个或多个动作组成的事件或者改变的状态[2]. 在实际应用中,事件抽取在信息检索[3]、知识图谱[4]、智能问答[5]和仪器设备管理[6-7]等多个领域发挥着关键作用,极大地提升了用户体验感.
NGUYEN T H, GRISHMAN R. Event detection and domain adaptation with convolutional neural networks [C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing: ACL, 2015: 365–371.
YAO L, MAO C, LUO Y. Graph convolutional networks for text classification [C]//Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019: 7370-7377.
ZHU M, ZENG K, JIBINGWU J, et al. LC4EE: LLMs as good corrector for event extraction [C]//Proceedings of the Findings of the Association for Computational Linguistics. St. Julian's, Malta: ACL, 2024: 12028–12038.
DODDINGTON G R, MITCHELL A, PRZYBOCKI M A, et al. The automatic content extraction (ACE) program: tasks, data, and evaluation [C]//Proceedings of the International Conference on Language Resources and Evaluation. Lisbon: ELRA, 2004: 837–840.
LU Y, LIU Q, DAI D, et al. Unified structure generation for universal information extraction [C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin: ACL, 2022: 5755–5772.
WANG X, ZHOU W, ZU C, et al. Instructuie: multi-task instruction tuning for unified information extraction [EB/OL]. (2023-04-17) [2024-12-20]. https://arxiv.org/abs/2304.08085.
ZHANG W, ZHAO X, ZHAO L, et al. DRL4IR: 2nd workshop on deep reinforcement learning for information retrieval [C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. [S. l. ]: ACM, 2021: 2681–2684.
BOSSELUT A, LE BRAS R, CHOI Y. Dynamic neuro-symbolic knowledge graph construction for zero-shot commonsense question answering [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S. l. ]: AAAI, 2021: 4923–4931.
GAO J, ZHAO H, YU C, et al. Exploring the feasibility of chatgpt for event extraction [EB/OL]. (2023-03-09) [2024-12-20]. https://arxiv.org/abs/2303.03836.
CAO Q, TRIVEDI H, BALASUBRAMANIAN A, et al. DeFormer: decomposing pre-trained Transformers for faster question answering [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle: ACL, 2020: 4487–4497.
LI Z, ZENG Y, ZUO Y, et al. KnowCoder: coding structured knowledge into LLMs for universal information extraction [C]//Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL, 2024: 8758–8779.
LOU J, LU Y, DAI D, et al. Universal information extraction as unified semantic matching [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S. l. ]: AAAI, 2023: 13318–13326.
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Minneapolis: ACL, 2019: 4171–4186.
DU X, CARDIE C. Event extraction by answering (almost) natural questions [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Punta Cana: ACL, 2020: 671–683.
SHIRI F, MOGHIMIFAR F, HAFFARI R, et al. Decompose, enrich, and extract! schema-aware event extraction using LLMs [C]//27th International Conference on Information Fusion. Florence: IEEE, 2024: 1–8.
WANG S, HUANG L. Targeted augmentation for low-resource event extraction [C]// Findings of the Association for Computational Linguistics: NAACL 2024. Mexico City: ACL, 2024: 4414–4428.
CHEN Y, XU L, LIU K, et al. Event extraction via dynamic multi-pooling convolutional neural networks [C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing: ACL, 2015: 167–176.
SUBBURATHINAM A, LU D, JI H, et al. Cross-lingual structure transfer for relation and event extraction [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: ACL, 2019: 313–325.
ZHANG J, QIN Y, ZHANG Y, et al. Extracting entities and events as a single task using a transition-based neural model [C]// 28th International Joint Conference on Artificial Intelligence. Macau: MKP, 2019: 5422–5428.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}