[1]
JIANG P, SINHA S, ALDAPE K, et al Big data in basic and translational cancer research
[J]. Nature Reviews Cancer , 2022 , 22 (11 ): 625 - 639
DOI:10.1038/s41568-022-00502-0
[本文引用: 1]
[2]
ACCIARINI C, CAPPA F, BOCCARDELLI P, et al How can organizations leverage big data to innovate their business models? A systematic literature review
[J]. Technovation , 2023 , 123 : 102713
DOI:10.1016/j.technovation.2023.102713
[本文引用: 1]
[3]
International Data Corporation. Worldwide IDC global datasphere forecast, 2024–2028: AI everywhere, but upsurge in data will take time [EB/OL]. (2024−05−31)[2025−11−12]. https://my.idc.com/getdoc.jsp?containerId=US52712424&pageType=PRINTFRIENDLY.
[本文引用: 1]
[4]
杜云箫, 陈珂, 寿黎但, 等 LazyStore: 基于混合存储架构的写优化键值存储系统
[J]. 软件学报 , 2025 , 36 (2 ): 805 - 829
[本文引用: 1]
DU Yunxiao, CHEN Ke, SHOU Lidan, et al LazyStore: write-optimized key-value storage system based on hybrid storage architecture
[J]. Journal of Software , 2025 , 36 (2 ): 805 - 829
[本文引用: 1]
[5]
LIU M, PAN L, LIU S Cost optimization for cloud storage from user perspectives: recent advances, taxonomy, and survey
[J]. ACM Computing Surveys , 2023 , 55 (13s ): 1 - 37
[本文引用: 1]
[6]
ZHANG T, SHEN J, LAI C F, et al Multi-server assisted data sharing supporting secure deduplication for metaverse healthcare systems
[J]. Future Generation Computer Systems , 2023 , 140 : 299 - 310
DOI:10.1016/j.future.2022.10.031
[本文引用: 1]
[7]
OH M, LEE S, JUST S, et al. TiDedup: a new distributed deduplication architecture for ceph [C]// 2023 USENIX Annual Technical Conference . Boston: [s.n.], 2023: 117–131.
[8]
LIN L, DENG Y, ZHOU Y, et al InDe: an inline data deduplication approach via adaptive detection of valid container utilization
[J]. ACM Transactions on Storage , 2023 , 19 (1 ): 1 - 27
[本文引用: 1]
[9]
SHAH M, YU X, DI S, et al. Lightweight Huffman coding for efficient GPU compression [C]// Proceedings of the 37th ACM International Conference on Supercomputing . Orlando: ACM, 2023: 99–110.
[本文引用: 1]
[10]
MING Y, WANG C, LIU H, et al Blockchain-enabled efficient dynamic cross-domain deduplication in edge computing
[J]. IEEE Internet of Things Journal , 2022 , 9 (17 ): 15639 - 15656
DOI:10.1109/JIOT.2022.3150042
[11]
XIA W, WEI C, LI Z, et al NetSync: a network adaptive and deduplication-inspired delta synchronization approach for cloud storage services
[J]. IEEE Transactions on Parallel and Distributed Systems , 2022 , 33 (10 ): 2554 - 2570
[本文引用: 1]
[12]
LIU X, AN P, CHEN Y, et al An improved lossless image compression algorithm based on Huffman coding
[J]. Multimedia Tools and Applications , 2022 , 81 (4 ): 4781 - 4795
DOI:10.1007/s11042-021-11017-5
[本文引用: 1]
[13]
ZHANG Y, ZHANG F, LI H, et al. CompressStreamDB: fine-grained adaptive stream processing without decompression [C]// Proceedings of the IEEE 39th International Conference on Data Engineering . Anaheim. IEEE, 2023: 408–422.
[本文引用: 1]
[14]
BACS A, MUSAEV S, RAZAVI K, et al. DUPEFS: leaking data over the network with filesystem deduplication side channels [C]// 20th USENIX Conference on File and Storage Technologies . Santa Clara: [s.n.], 2022: 281–296.
[本文引用: 1]
[15]
NI F, LIN X, JIANG S. SS-CDC: a two-stage parallel content-defined chunking for deduplicating backup storage [C]// Proceedings of the 12th ACM International Conference on Systems and Storage . Haifa: ACM, 2019: 86–96.
[本文引用: 1]
[16]
ZHANG Y, FU M, WU X, et al Improving restore performance of packed datasets in deduplication systems via reducing persistent fragmented chunks
[J]. IEEE Transactions on Parallel and Distributed Systems , 2020 , 31 (7 ): 1651 - 1664
DOI:10.1109/TPDS.2020.2972898
[17]
WU S, DU C, ZHANG W, et al DedupHR: exploiting content locality to alleviate read/write interference in deduplication-based flash storage
[J]. IEEE Transactions on Computers , 2022 , 71 (6 ): 1332 - 1343
[18]
CAO Z, LIU S, WU F, et al. Sliding look-back window assisted data chunk rewriting for improving deduplication restore performance [C]// Proceedings of the 17th USENIX Conference on File and Storage Technologies . Boston: ACM, 2019: 129–142.
[19]
ZHANG D, DENG Y, ZHOU Y, et al Improving the performance of deduplication-based backup systems via container utilization based hot fingerprint entry distilling
[J]. ACM Transactions on Storage , 2021 , 17 (4 ): 1 - 23
[本文引用: 1]
[20]
XU L J, HAO R, YU J, et al Secure deduplication for big data with efficient dynamic ownership updates
[J]. Computers and Electrical Engineering , 2021 , 96 : 107531
DOI:10.1016/j.compeleceng.2021.107531
[本文引用: 1]
[21]
COGO V, PAULO J, BESSANI A GenoDedup: similarity-based deduplication and delta-encoding for genome sequencing data
[J]. IEEE Transactions on Computers , 2021 , 70 (5 ): 669 - 681
DOI:10.1109/TC.2020.2994774
[22]
VESTERGAARD R, LUCANI D E, ZHANG Q. A randomly accessible lossless compression scheme for time-series data [C]// Proceedings of the IEEE INFOCOM 2020 - IEEE Conference on Computer Communications . Toronto: IEEE, 2020: 2145–2154.
[本文引用: 1]
[23]
XIA W, PU L, ZOU X, et al The design of fast and lightweight resemblance detection for efficient post-deduplication delta compression
[J]. ACM Transactions on Storage , 2023 , 19 (3 ): 1 - 30
[本文引用: 1]
[24]
SHARMA G Analysis of Huffman coding and Lempel–Ziv–Welch (LZW) coding as data compression techniques
[J]. International Journal of Scientific Research in Computer Science and Engineering , 2020 , 8 (1 ): 37 - 44
[本文引用: 1]
[25]
PERIASAMY J K, LATHA B Efficient hash function–based duplication detection algorithm for data deduplication deduction and reduction
[J]. Concurrency and Computation: Practice and Experience , 2021 , 33 (3 ): e5213
DOI:10.1002/cpe.5213
[本文引用: 1]
[26]
AHMED S T, GEORGE L E Lightweight hash-based de-duplication system using the self detection of most repeated patterns as chunks divisors
[J]. Journal of King Saud University - Computer and Information Sciences , 2022 , 34 (7 ): 4669 - 4678
DOI:10.1016/j.jksuci.2021.04.005
[本文引用: 1]
[27]
JIANG T, YUAN X, CHEN Y, et al FuzzyDedup: secure fuzzy deduplication for cloud storage
[J]. IEEE Transactions on Dependable and Secure Computing , 2023 , 20 (3 ): 2466 - 2483
DOI:10.1109/TDSC.2022.3185313
[本文引用: 1]
[28]
LI Y, TIAN C, GUO F, et al. ElasticBF: elastic Bloom filter with hotness awareness for boosting read performance in large key-value stores [C]// 2019 USENIX Annual Technical Conference . Renton: [s.n.], 2019: 739–752.
[本文引用: 1]
[29]
LIU T, HE X, ALIBHAI S, et al. Reference-counter aware deduplication in erasure-coded distributed storage system [C]// Proceedings of the IEEE International Conference on Networking, Architecture and Storage . Chongqing: IEEE, 2018: 1–10.
[本文引用: 3]
[30]
NI F, JIANG S. RapidCDC: leveraging duplicate locality to accelerate chunking in CDC-based deduplication systems [C]// Proceedings of the ACM Symposium on Cloud Computing . Santa Cruz: ACM, 2019: 220–232.
[本文引用: 1]
[31]
ZHANG G, XIE H, YANG Z, et al BDKM: a blockchain-based secure deduplication scheme with reliable key management
[J]. Neural Processing Letters , 2022 , 54 (4 ): 2657 - 2674
DOI:10.1007/s11063-021-10450-9
[本文引用: 1]
[32]
XIA W, ZHOU Y, JIANG H, et al. FastCDC: a fast and efficient content-defined chunking approach for data deduplication [C]// 2016 USENIX Annual Technical Conference . Denver: [s.n.], 2016: 101–114.
[本文引用: 1]
[33]
JIN X, LIU H, YE C, et al Accelerating content-defined chunking for data deduplication based on speculative jump
[J]. IEEE Transactions on Parallel and Distributed Systems , 2023 , 34 (9 ): 2568 - 2579
DOI:10.1109/TPDS.2023.3290770
[本文引用: 1]
[34]
XIA W, ZOU X, JIANG H, et al The design of fast content-defined chunking for data deduplication based storage systems
[J]. IEEE Transactions on Parallel and Distributed Systems , 2020 , 31 (9 ): 2017 - 2031
DOI:10.1109/TPDS.2020.2984632
[本文引用: 1]
[35]
BJØRNER N, BLASS A, GUREVICH Y Content-dependent chunking for differential compression, the local maximum approach
[J]. Journal of Computer and System Sciences , 2010 , 76 (3/4 ): 154 - 203
[本文引用: 1]
[36]
ZHANG Y, YUAN Y, FENG D, et al Improving restore performance for in-line backup system combining deduplication and delta compression
[J]. IEEE Transactions on Parallel and Distributed Systems , 2020 , 31 (10 ): 2302 - 2314
DOI:10.1109/TPDS.2020.2991030
[本文引用: 1]
[37]
GARG S, SINGH R, OBAIDAT M S, et al Statistical vertical reduction-based data abridging technique for big network traffic dataset
[J]. International Journal of Communication Systems , 2020 , 33 (4 ): e4249
DOI:10.1002/dac.4249
[本文引用: 1]
[38]
RANJAN R Canonical Huffman coding based image compression using wavelet
[J]. Wireless Personal Communications , 2021 , 117 (3 ): 2193 - 2206
DOI:10.1007/s11277-020-07967-y
[本文引用: 1]
[39]
HUSSEIN A M, IDREES A K, COUTURIER R A distributed prediction–compression-based mechanism for energy saving in IoT networks
[J]. The Journal of Supercomputing , 2023 , 79 (15 ): 16963 - 16999
DOI:10.1007/s11227-023-05317-w
[本文引用: 1]
[40]
NIU B, CAO X, WEI Z, et al Entropy optimized deep feature compression
[J]. IEEE Signal Processing Letters , 2021 , 28 : 324 - 328
DOI:10.1109/LSP.2021.3052097
[本文引用: 1]
[41]
COLLET Y. Finite state entropy [EB/OL]. [2025–11–13]. https://fastcompression.blogspot.com/2013/
[本文引用: 1]
[42]
WELCH A technique for high-performance data compression
[J]. Computer , 1984 , 17 (6 ): 8 - 19
[本文引用: 1]
[43]
MAJID A, ROBERTS S G, CILISSEN L, et al Differential coding of perception in the world’s languages
[J]. Proceedings of the National Academy of Sciences of the United States of America , 2018 , 115 (45 ): 11369 - 11376
[本文引用: 1]
[44]
RAJKUMAR K, HARIHARAN U, DHANAKOTI V, et al A secure framework for managing data in cloud storage using rapid asymmetric maximum based dynamic size chunking and fuzzy logic for deduplication
[J]. Wireless Networks , 2024 , 30 (1 ): 321 - 334
DOI:10.1007/s11276-023-03448-9
[本文引用: 1]
[45]
LI M, WANG H, YANG L, et al Fast hybrid dimensionality reduction method for classification based on feature selection and grouped feature extraction
[J]. Expert Systems with Applications , 2020 , 150 : 113277
DOI:10.1016/j.eswa.2020.113277
[本文引用: 1]
[46]
ZHANG B, WANG C, ZHOU B B, et al DCDedupe: selective deduplication and delta compression with effective routing for distributed storage
[J]. Journal of Grid Computing , 2018 , 16 (2 ): 195 - 209
DOI:10.1007/s10723-018-9429-3
[本文引用: 2]
[47]
ZHANG Y, JIANG H, FENG D, et al. LoopDelta: embedding locality-aware opportunistic delta compression in inline deduplication for highly efficient data reduction [C]// 2023 USENIX Annual Technical Conference . Boston: [s.n.], 2023: 133–148.
[本文引用: 1]
[48]
TAN H, ZHANG Z, ZOU X, et al. Exploring the potential of fast delta encoding: marching to a higher compression ratio [C]// Proceedings of the IEEE International Conference on Cluster Computing . Kobe: IEEE, 2020: 198–208.
[本文引用: 1]
[49]
XIA J, CHENG G, LUO L, et al The doctrine of MEAN: realizing deduplication storage at unreliable edge
[J]. IEEE Transactions on Parallel and Distributed Systems , 2023 , 34 (10 ): 2811 - 2826
DOI:10.1109/TPDS.2023.3305460
[本文引用: 1]
[50]
CHENG G, GUO D, LUO L, et al. Jingwei: an efficient and adaptable data migration strategy for deduplicated storage systems [C]// Proceedings of the IEEE INFOCOM 2022 - IEEE Conference on Computer Communications . London: IEEE, 2022: 1659–1668.
[本文引用: 2]
[51]
王青松, 葛慧 指纹极值的双层重复数据删除算法
[J]. 辽宁大学学报: 自然科学版 , 2018 , 45 (3 ): 201 - 207
[本文引用: 2]
WANG Qingsong, GE Hui Double layer deduplication algorithm based on fingerprint extremum
[J]. Journal of Liaoning University: Natural Sciences Edition , 2018 , 45 (3 ): 201 - 207
[本文引用: 2]
[52]
QIU J, PAN Y, XIA W, et al. Light-Dedup: a light-weight inline deduplication framework for non-volatile memory file systems [C]// 2023 USENIX Annual Technical Conference . Boston: [s.n.], 2023: 101−116.
[本文引用: 2]
[53]
DU C, LIN Z, WU S, et al FSDedup: feature-aware and selective deduplication for improving performance of encrypted non-volatile main memory
[J]. ACM Transactions on Storage , 2024 , 20 (4 ): 1 - 33
[本文引用: 2]
[54]
DENG C, CHEN Q, ZOU X, et al. imDedup: a lossless deduplication scheme to eliminate fine-grained redundancy among images [C]// Proceedings of the IEEE 38th International Conference on Data Engineering . Kuala Lumpur: IEEE, 2022: 1071–1084.
[本文引用: 2]
[55]
王龙翔, 董凯, 王鹏博, 等 R-dedup: 一种重复数据删除指纹计算的优化方法
[J]. 西安交通大学学报 , 2021 , 55 (1 ): 43 - 51
[本文引用: 2]
WANG Longxiang, DONG Kai, WANG Pengbo, et al R-dedup: a performance improvement strategy for fingerprint calculation of data de-duplication
[J]. Journal of Xi’an Jiaotong University , 2021 , 55 (1 ): 43 - 51
[本文引用: 2]
[56]
XIANG L, ZHAO X, RAO J, et al. Characterizing the performance of intel optane persistent memory: a close look at its on-DIMM buffering [C]// Proceedings of the Seventeenth European Conference on Computer Systems . Rennes: ACM, 2022: 488–505.
[本文引用: 1]
[57]
SAHARAN S, SOMANI G, GUPTA G, et al QuickDedup: efficient VM deduplication in cloud computing environments
[J]. Journal of Parallel and Distributed Computing , 2020 , 139 : 18 - 31
DOI:10.1016/j.jpdc.2020.01.002
[本文引用: 2]
[58]
DAGNAW G, ZHOU K, WANG H dCACH: content aware clustered and hierarchical distributed deduplication
[J]. Journal of Software Engineering and Applications , 2019 , 12 (11 ): 460 - 490
DOI:10.4236/jsea.2019.1211029
[本文引用: 2]
[59]
DAGNAW G, ZHOU K, WANG H SACRO: solid state drive-assisted chunk caching for restore optimization
[J]. Concurrency and Computation: Practice and Experience , 2023 , 35 (18 ): e6162
DOI:10.1002/cpe.6162
[本文引用: 2]
[60]
XIA W, FENG D, JIANG H, et al Accelerating content-defined-chunking based data deduplication by exploiting parallelism
[J]. Future Generation Computer Systems , 2019 , 98 : 406 - 418
DOI:10.1016/j.future.2019.02.008
[本文引用: 2]
[61]
LIN L, DENG Y, ZHOU Y. Improving restore performance of deduplication systems via a greedy rewriting scheme [C]// Proceedings of the IEEE 27th International Conference on Parallel and Distributed Systems . Beijing: IEEE, 2022: 291–298.
[本文引用: 2]
[62]
TAN Y, WANG B, WEN J, et al Improving restore performance in deduplication-based backup systems via a fine-grained defragmentation approach
[J]. IEEE Transactions on Parallel and Distributed Systems , 2018 , 29 (10 ): 2254 - 2267
DOI:10.1109/TPDS.2018.2828842
[本文引用: 2]
[63]
ZOU X, YUAN J, SHILANE P, et al From hyper-dimensional structures to linear structures: maintaining deduplicated data’s locality
[J]. ACM Transactions on Storage , 2022 , 18 (3 ): 1 - 28
[本文引用: 2]
[64]
ZOU X, YUAN J, SHILANE P, et al. The dilemma between deduplication and locality: can both be achieved [C]// 19th USENIX Conference on File and Storage Technologies (FAST 21) . [S.l.]: USENIX Association, 2021: 171−185.
[本文引用: 1]
[65]
XIAO L, ZOU B, ZHU C, et al ESDedup: an efficient and secure deduplication scheme based on data similarity and blockchain for cloud-assisted medical storage systems
[J]. The Journal of Supercomputing , 2023 , 79 (3 ): 2932 - 2960
DOI:10.1007/s11227-022-04746-3
[本文引用: 1]
[66]
LIU J, CHAI Y P, QIN X, et al Endurable SSD-based read cache for improving the performance of selective restore from deduplication systems
[J]. Journal of Computer Science and Technology , 2018 , 33 (1 ): 58 - 78
DOI:10.1007/s11390-018-1808-5
[本文引用: 1]
[67]
GODAVARI A, SUDHAKAR C, RAMESH T Hybrid deduplication system: a block-level similarity-based approach
[J]. IEEE Systems Journal , 2021 , 15 (3 ): 3860 - 3870
DOI:10.1109/JSYST.2020.3012702
[本文引用: 2]
[68]
GODAVARI A, SUDHAKAR C, RAMESH T File semantic aware primary storage deduplication system
[J]. IETE Journal of Research , 2023 , 69 (11 ): 7945 - 7957
DOI:10.1080/03772063.2022.2050306
[本文引用: 2]
[69]
LUO R, JIN H, HE Q, et al Enabling balanced data deduplication in mobile edge computing
[J]. IEEE Transactions on Parallel and Distributed Systems , 2023 , 34 (5 ): 1420 - 1431
DOI:10.1109/TPDS.2023.3247061
[本文引用: 2]
[70]
GHOLAMI TAGHIZADEH R, GHOLAMI TAGHIZADEH R, KHAKPASH F, et al CA-Dedupe: content-aware deduplication in SSDs
[J]. The Journal of Supercomputing , 2020 , 76 (11 ): 8901 - 8921
DOI:10.1007/s11227-020-03188-z
[本文引用: 2]
[71]
BRODER A Z. Identifying and filtering near-duplicate documents [C]// Annual Symposium on Combinatorial Pattern Matching . Berlin: Springer, 2000: 1–10.
[本文引用: 1]
[72]
WU S, TU Z, ZHOU Y, et al FASTSync: a FAST delta sync scheme for encrypted cloud storage in high-bandwidth network environments
[J]. ACM Transactions on Storage , 2023 , 19 (4 ): 1 - 22
[本文引用: 1]
[73]
BEZALELI D, GUTMAN J, NOSSENSON R. Using the ZDelta compression algorithm for data reduction in cellular networks [C]// Proceedings of the Future Network and Mobile Summit . Lisboa: IEEE, 2013: 1–7.
[本文引用: 1]
[74]
BETTINI L, DI SALLE A, IOVINO L, et al Supporting reusable model migration with Edelta
[J]. Journal of Systems and Software , 2024 , 212 : 112012
DOI:10.1016/j.jss.2024.112012
[本文引用: 1]
[75]
TAN H, ZOU X, WAN B, et al. SuperDelta: multiple referenced base chunks scheme for fine-grained deduplication backup storage system [C]// Proceedings of the Data Compression Conference . Snowbird: IEEE, 2024: 362–371.
[本文引用: 1]
[76]
ZHANG Y, XIA W, FENG D, et al. Finesse: fine-grained feature locality based fast resemblance detection for post-deduplication delta compression [C]// 17th USENIX Conference on File and Storage Technologies (FAST 19) . Boston: [s.n.], 2019: 121–128.
[本文引用: 1]
[77]
ZOU X, DENG C, XIA W, et al. Odess: speeding up resemblance detection for redundancy elimination by fast content-defined sampling [C]// Proceedings of the IEEE 37th International Conference on Data Engineering . Chania: IEEE, 2021: 480–491.
[本文引用: 1]
[78]
HUANG H, WANG P, SU Q, et al. Palantir: hierarchical similarity detection for post-deduplication delta compression [C]// Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 . La Jolla: ACM, 2024: 830–845.
[本文引用: 1]
[79]
PARK J, KIM J, KIM Y, et al. DeepSketch: a new machine learning-based reference search technique for post-deduplication delta compression [EB/OL]. (2022−02−17)[2025−11−13]. https://arxiv.org/pdf/2202.10584.
[本文引用: 2]
[80]
ZOU X, XIA W, SHILANE P, et al. Building a high-performance fine-grained deduplication framework for backup storage with high deduplication ratio [C]// Proceedings of the USENIX Annual Technical Conference . Carlsbad: [s.n.], 2022: 19−36.
[本文引用: 1]
[81]
CHENG W, ZHENG T, ZENG L, et al. DPLFS: a dual-mode PCM-based log-structured file system [C]// Proceedings of the IEEE 40th International Conference on Computer Design . Olympic Valley: IEEE, 2022: 324–331.
[本文引用: 1]
[82]
AJDARI M, RAAF P, KISHANI M, et al An enterprise-grade open-source data reduction architecture for all-flash storage systems
[J]. Proceedings of the ACM on Measurement and Analysis of Computing Systems , 2022 , 6 (2 ): 1 - 27
[本文引用: 1]
[83]
ELLAPPAN M, ABIRAMI S Dynamic prime chunking algorithm for data deduplication in cloud storage
[J]. KSII Transactions on Internet and Information Systems (TIIS) , 2021 , 15 (4 ): 1342 - 1359
[本文引用: 1]
[84]
FU Y, XIAO N, CHEN T, et al Fog-to-MultiCloud cooperative eHealth data management with application-aware secure deduplication
[J]. IEEE Transactions on Dependable and Secure Computing , 2022 , 19 (5 ): 3136 - 3148
DOI:10.1109/TDSC.2021.3086089
[本文引用: 1]
[85]
WU S, MAO B, JIANG H, et al PFP: improving the reliability of deduplication-based storage systems with per-file parity
[J]. IEEE Transactions on Parallel and Distributed Systems , 2019 , 30 (9 ): 2117 - 2129
DOI:10.1109/TPDS.2019.2898942
[本文引用: 1]
[86]
ZHOU Y, FENG D, XIA W, et al. DARM: a deduplication-aware redundancy management approach for reliable-enhanced storage systems [C]// Algorithms and Architectures for Parallel Processing . [S.l.]: Springer, 2018: 445–461.
[本文引用: 2]
[87]
KAN G, JIN C, ZHU H, et al An identity-based proxy re-encryption for data deduplication in cloud
[J]. Journal of Systems Architecture , 2021 , 121 : 102332
DOI:10.1016/j.sysarc.2021.102332
[本文引用: 1]
[88]
SONG M, HUA Z, ZHENG Y, et al Blockchain-based deduplication and integrity auditing over encrypted cloud storage
[J]. IEEE Transactions on Dependable and Secure Computing , 2023 , 20 (6 ): 4928 - 4945
DOI:10.1109/TDSC.2023.3237221
[本文引用: 2]
[89]
AN B, LI Y, MA J, et al. DCStore: a deduplication-based cloud-of-clouds storage service [C]// Proceedings of the IEEE International Conference on Web Services . Milan: IEEE, 2019: 291–295.
[本文引用: 2]
[90]
ZUO C, WANG F, HUANG P, et al. RepEC-Duet: ensure high reliability and performance for deduplicated and delta-compressed storage systems [C]// Proceedings of the IEEE 37th International Conference on Computer Design . Abu Dhabi: IEEE, 2020: 190–198.
[本文引用: 2]
[91]
ZUO C, WANG F, ZHENG M, et al Ensuring high reliability and performance with low space overhead for deduplicated and delta-compressed storage systems
[J]. Concurrency and Computation: Practice and Experience , 2022 , 34 (5 ): e6706
DOI:10.1002/cpe.6706
[本文引用: 2]
[92]
MENG L, GONG X, CHEN Y BAD-FM: backdoor attacks against factorization-machine based neural network for tabular data prediction
[J]. Chinese Journal of Electronics , 2024 , 33 (4 ): 1077 - 1092
DOI:10.23919/cje.2023.00.041
[本文引用: 1]
[93]
HUANG P, WU Y Teacher-student training approach using an adaptive gain mask for LSTM-based speech enhancement in the airborne noise environment
[J]. Chinese Journal of Electronics , 2023 , 32 (4 ): 882 - 895
DOI:10.23919/cje.2022.00.307
[本文引用: 1]
[94]
ZHANG R, E H, YUAN L, et al FGM-SPCL: open-set recognition network for medical images based on fine-grained data mixture and spatial position constraint loss
[J]. Chinese Journal of Electronics , 2024 , 33 (4 ): 1023 - 1033
DOI:10.23919/cje.2023.00.081
[本文引用: 1]
[95]
ZOU B, YANG K, KUI X, et al Anomaly detection for streaming data based on grid-clustering and Gaussian distribution
[J]. Information Sciences , 2023 , 638 : 118989
DOI:10.1016/j.ins.2023.118989
[本文引用: 1]
[96]
SUN T, JIANG B, LI B, et al. SimEnc: a high-performance similarity-preserving encryption approach for deduplication of encrypted Docker images [C]// 2024 USENIX Annual Technical Conference (USENIX ATC 24) . Santa Clara: [s.n.], 2024: 615–630.
[本文引用: 1]
[97]
LIN Y, MAO Y, ZHANG Y, et al Secure deduplication schemes for content delivery in mobile edge computing
[J]. Computers and Security , 2022 , 114 : 102602
[本文引用: 1]
[98]
XIAO W, HAO Y, LIANG J, et al Adaptive compression offloading and resource allocation for edge vision computing
[J]. IEEE Transactions on Cognitive Communications and Networking , 2024 , 10 (6 ): 2357 - 2369
DOI:10.1109/TCCN.2024.3400820
[本文引用: 1]
[99]
CHEN L, GUO C, GONG B, et al A secure cross-domain authentication scheme based on threshold signature for MEC
[J]. Journal of Cloud Computing , 2024 , 13 (1 ): 70
DOI:10.1186/s13677-024-00631-x
[本文引用: 1]
[100]
CHEN X, LU T, WANG J, et al. HA-CSD: host and SSD coordinated compression for capacity and performance [C]// Proceedings of the IEEE International Parallel and Distributed Processing Symposium . San Francisco: IEEE, 2024: 825–838.
[本文引用: 1]
Big data in basic and translational cancer research
1
2022
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
How can organizations leverage big data to innovate their business models? A systematic literature review
1
2023
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
1
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
LazyStore: 基于混合存储架构的写优化键值存储系统
1
2025
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
LazyStore: 基于混合存储架构的写优化键值存储系统
1
2025
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
Cost optimization for cloud storage from user perspectives: recent advances, taxonomy, and survey
1
2023
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
Multi-server assisted data sharing supporting secure deduplication for metaverse healthcare systems
1
2023
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
InDe: an inline data deduplication approach via adaptive detection of valid container utilization
1
2023
... 数据已经成为推动科学研究和社会发展的重要驱动力. 随着数字化时代的到来,数据的增长速度呈现出爆炸性增长的趋势,这不可避免地给数据存储、传输和处理带来了巨大的挑战[1 -2 ] . 同时,海量数据的存储和传输会造成能源和环境资源浪费. 根据国际数据公司(international data corporation, IDC)的预测,全球数据规模 2024 年为 159.2 ZB,到 2028 年将达 384.6 ZB(复合年均增长率为24.4%),总体超过1倍增长[3 ] . 中国的数据量每年以26.3%的速度增长,位居全球第一,这意味着存储系统面临的存储和处理任务在不断增加[4 ] . 研究表明,备份数据与高性能存储系统分别存在90%与70%的冗余数据[5 ] . 数据缩减技术可以有效地减少数据的体积和冗余,节约存储空间并提高数据传输效率[6 -8 ] . ...
1
... 数据缩减技术是指通过不同的方法和策略来减少数据占用的存储空间,旨在优化数据存储和管理过程、节约存储成本. 数据缩减方法通常包括传统压缩方法、差量压缩方法与数据去重技术[9 -11 ] . 传统压缩方法(如霍夫曼编码、算术编码和字典编码[12 ] )是数据压缩领域的基石,广泛应用于图像、音频、视频和文本等各种数据类型. 传统方法基于数据的统计特性和概率分布,通过较短的编码表示高频率的符号,较长的编码表示低频率的符号,以实现数据缩减. 差量压缩是高效的数据压缩技术,原理是在现有压缩数据的基础上,对新的或修改后的数据执行进一步的压缩. 相较于传统方法,它专注于处理数据的变化,避免了对整个数据重新压缩的开销,节省了时间和资源. 该方法在处理日志文件、备份和版本控制等场景下具有显著的优势[13 ] . 数据去重技术的基本原理是先通过比较数据的内容或哈希值来判断数据是否重复,再识别和消除数据中的重复部分. 数据去重在许多领域都有着广泛的应用,在云存储和大规模数据处理中,该技术可以减少存储开销、优化数据传输、加快数据处理速度、减少网络带宽的消耗[14 ] . ...
Blockchain-enabled efficient dynamic cross-domain deduplication in edge computing
0
2022
NetSync: a network adaptive and deduplication-inspired delta synchronization approach for cloud storage services
1
2022
... 数据缩减技术是指通过不同的方法和策略来减少数据占用的存储空间,旨在优化数据存储和管理过程、节约存储成本. 数据缩减方法通常包括传统压缩方法、差量压缩方法与数据去重技术[9 -11 ] . 传统压缩方法(如霍夫曼编码、算术编码和字典编码[12 ] )是数据压缩领域的基石,广泛应用于图像、音频、视频和文本等各种数据类型. 传统方法基于数据的统计特性和概率分布,通过较短的编码表示高频率的符号,较长的编码表示低频率的符号,以实现数据缩减. 差量压缩是高效的数据压缩技术,原理是在现有压缩数据的基础上,对新的或修改后的数据执行进一步的压缩. 相较于传统方法,它专注于处理数据的变化,避免了对整个数据重新压缩的开销,节省了时间和资源. 该方法在处理日志文件、备份和版本控制等场景下具有显著的优势[13 ] . 数据去重技术的基本原理是先通过比较数据的内容或哈希值来判断数据是否重复,再识别和消除数据中的重复部分. 数据去重在许多领域都有着广泛的应用,在云存储和大规模数据处理中,该技术可以减少存储开销、优化数据传输、加快数据处理速度、减少网络带宽的消耗[14 ] . ...
An improved lossless image compression algorithm based on Huffman coding
1
2022
... 数据缩减技术是指通过不同的方法和策略来减少数据占用的存储空间,旨在优化数据存储和管理过程、节约存储成本. 数据缩减方法通常包括传统压缩方法、差量压缩方法与数据去重技术[9 -11 ] . 传统压缩方法(如霍夫曼编码、算术编码和字典编码[12 ] )是数据压缩领域的基石,广泛应用于图像、音频、视频和文本等各种数据类型. 传统方法基于数据的统计特性和概率分布,通过较短的编码表示高频率的符号,较长的编码表示低频率的符号,以实现数据缩减. 差量压缩是高效的数据压缩技术,原理是在现有压缩数据的基础上,对新的或修改后的数据执行进一步的压缩. 相较于传统方法,它专注于处理数据的变化,避免了对整个数据重新压缩的开销,节省了时间和资源. 该方法在处理日志文件、备份和版本控制等场景下具有显著的优势[13 ] . 数据去重技术的基本原理是先通过比较数据的内容或哈希值来判断数据是否重复,再识别和消除数据中的重复部分. 数据去重在许多领域都有着广泛的应用,在云存储和大规模数据处理中,该技术可以减少存储开销、优化数据传输、加快数据处理速度、减少网络带宽的消耗[14 ] . ...
1
... 数据缩减技术是指通过不同的方法和策略来减少数据占用的存储空间,旨在优化数据存储和管理过程、节约存储成本. 数据缩减方法通常包括传统压缩方法、差量压缩方法与数据去重技术[9 -11 ] . 传统压缩方法(如霍夫曼编码、算术编码和字典编码[12 ] )是数据压缩领域的基石,广泛应用于图像、音频、视频和文本等各种数据类型. 传统方法基于数据的统计特性和概率分布,通过较短的编码表示高频率的符号,较长的编码表示低频率的符号,以实现数据缩减. 差量压缩是高效的数据压缩技术,原理是在现有压缩数据的基础上,对新的或修改后的数据执行进一步的压缩. 相较于传统方法,它专注于处理数据的变化,避免了对整个数据重新压缩的开销,节省了时间和资源. 该方法在处理日志文件、备份和版本控制等场景下具有显著的优势[13 ] . 数据去重技术的基本原理是先通过比较数据的内容或哈希值来判断数据是否重复,再识别和消除数据中的重复部分. 数据去重在许多领域都有着广泛的应用,在云存储和大规模数据处理中,该技术可以减少存储开销、优化数据传输、加快数据处理速度、减少网络带宽的消耗[14 ] . ...
1
... 数据缩减技术是指通过不同的方法和策略来减少数据占用的存储空间,旨在优化数据存储和管理过程、节约存储成本. 数据缩减方法通常包括传统压缩方法、差量压缩方法与数据去重技术[9 -11 ] . 传统压缩方法(如霍夫曼编码、算术编码和字典编码[12 ] )是数据压缩领域的基石,广泛应用于图像、音频、视频和文本等各种数据类型. 传统方法基于数据的统计特性和概率分布,通过较短的编码表示高频率的符号,较长的编码表示低频率的符号,以实现数据缩减. 差量压缩是高效的数据压缩技术,原理是在现有压缩数据的基础上,对新的或修改后的数据执行进一步的压缩. 相较于传统方法,它专注于处理数据的变化,避免了对整个数据重新压缩的开销,节省了时间和资源. 该方法在处理日志文件、备份和版本控制等场景下具有显著的优势[13 ] . 数据去重技术的基本原理是先通过比较数据的内容或哈希值来判断数据是否重复,再识别和消除数据中的重复部分. 数据去重在许多领域都有着广泛的应用,在云存储和大规模数据处理中,该技术可以减少存储开销、优化数据传输、加快数据处理速度、减少网络带宽的消耗[14 ] . ...
1
... 数据缩减技术在节约存储开销的同时也降低了系统性能及可靠性,例如影响存储系统的备份性能、恢复性能、删除性能、可靠性以及增加系统开销等[15 -19 ] . 因此,数据缩减须权衡利弊,综合考虑系统的特点、需求和性能指标,以在最小化存储开销的同时尽可能地降低性能损失. 本文将全面分析与总结针对这些性能优化提出的各类方法,探讨各类方法在不同领域的应用前景与挑战,结合冗余数据的分布特性提出新的数据缩减分类方法. ...
Improving restore performance of packed datasets in deduplication systems via reducing persistent fragmented chunks
0
2020
DedupHR: exploiting content locality to alleviate read/write interference in deduplication-based flash storage
0
2022
Improving the performance of deduplication-based backup systems via container utilization based hot fingerprint entry distilling
1
2021
... 数据缩减技术在节约存储开销的同时也降低了系统性能及可靠性,例如影响存储系统的备份性能、恢复性能、删除性能、可靠性以及增加系统开销等[15 -19 ] . 因此,数据缩减须权衡利弊,综合考虑系统的特点、需求和性能指标,以在最小化存储开销的同时尽可能地降低性能损失. 本文将全面分析与总结针对这些性能优化提出的各类方法,探讨各类方法在不同领域的应用前景与挑战,结合冗余数据的分布特性提出新的数据缩减分类方法. ...
Secure deduplication for big data with efficient dynamic ownership updates
1
2021
... 数据缩减技术在现代数据处理中具有重要的意义和明显的优势. 在物联网、社交媒体和传感器网络等领域,数据缩减技术可以有效应对数据爆炸问题,减少处理和存储的数据量,从而节省计算资源和存储空间. 在机器学习和数据挖掘中,处理高维数据容易导致“维度灾难”,通过缩减数据维度,减少特征的数量,能够大幅降低计算复杂度,提升模型训练和推理的效率. 数据集含有噪声、冗余和无关特征,会对模型的学习产生负面影响. 数据缩减技术可以帮助消除无关或冗余特征,使模型专注于最相关的信息,提高模型的准确性和泛化能力. 对于大规模数据集,数据缩减技术可以显著减少存储需求,在数据传输场景(如分布式计算或云计算)中,缩减的数据量也能减少带宽占用,提高数据传输的速度和效率. 特定的数据特性和应用需求需要不同的数据缩减方法来满足. 数据缩减技术可以显著提升存储系统的效率,不同方法适用于不同特征的数据和场景[20 -22 ] ,具体如表1 所示. ...
GenoDedup: similarity-based deduplication and delta-encoding for genome sequencing data
0
2021
1
... 数据缩减技术在现代数据处理中具有重要的意义和明显的优势. 在物联网、社交媒体和传感器网络等领域,数据缩减技术可以有效应对数据爆炸问题,减少处理和存储的数据量,从而节省计算资源和存储空间. 在机器学习和数据挖掘中,处理高维数据容易导致“维度灾难”,通过缩减数据维度,减少特征的数量,能够大幅降低计算复杂度,提升模型训练和推理的效率. 数据集含有噪声、冗余和无关特征,会对模型的学习产生负面影响. 数据缩减技术可以帮助消除无关或冗余特征,使模型专注于最相关的信息,提高模型的准确性和泛化能力. 对于大规模数据集,数据缩减技术可以显著减少存储需求,在数据传输场景(如分布式计算或云计算)中,缩减的数据量也能减少带宽占用,提高数据传输的速度和效率. 特定的数据特性和应用需求需要不同的数据缩减方法来满足. 数据缩减技术可以显著提升存储系统的效率,不同方法适用于不同特征的数据和场景[20 -22 ] ,具体如表1 所示. ...
The design of fast and lightweight resemblance detection for efficient post-deduplication delta compression
1
2023
... 数据去重适用于包含重复文件或重复块的数据,但无法识别相似文件或相似块. 差量压缩能识别相似性较高的数据,可以弥补数据去重的缺陷[23 ] . 有必要根据不同的应用场景,选择合适的缩减技术或组合来优化数据处理流程. 文本数据通常包含大量的重复字符和词汇,适合使用基于字典的压缩方法,如LZW (Lempel-Ziv-Welch)算法[24 ] ;在时间序列数据中,数据可能会频繁变化,适合使用差分压缩来处理数据的连续变化;对于包含大量重复数据和频繁更新的数据,须结合传统压缩、差量压缩和数据去重等技术进行高效压缩. 从数据块粒度进行冗余数据的特性分析,冗余数据主要存在于文件内部相似块、文件间相似块与重复块中. 如图1 所示,在文件 $ {F}_{n} $ $ {B}_{n}^{2} $ $ {B}_{n}^{3} $ $ {F}_{m} $ $ {F}_{n} $ $ {F}_{k} $ $ {B}_{m}^{4} $ $ {B}_{n}^{4} $ $ {B}_{k}^{4} $ $ {B}_{m}^{1},{B}_{m}^{2}{B}_{m}^{3},{B}_{n}^{1},{B}_{k}^{1} $ ) 则是重复块. 这3类冗余共同构成块粒度的数据冗余特性. ...
Analysis of Huffman coding and Lempel–Ziv–Welch (LZW) coding as data compression techniques
1
2020
... 数据去重适用于包含重复文件或重复块的数据,但无法识别相似文件或相似块. 差量压缩能识别相似性较高的数据,可以弥补数据去重的缺陷[23 ] . 有必要根据不同的应用场景,选择合适的缩减技术或组合来优化数据处理流程. 文本数据通常包含大量的重复字符和词汇,适合使用基于字典的压缩方法,如LZW (Lempel-Ziv-Welch)算法[24 ] ;在时间序列数据中,数据可能会频繁变化,适合使用差分压缩来处理数据的连续变化;对于包含大量重复数据和频繁更新的数据,须结合传统压缩、差量压缩和数据去重等技术进行高效压缩. 从数据块粒度进行冗余数据的特性分析,冗余数据主要存在于文件内部相似块、文件间相似块与重复块中. 如图1 所示,在文件 $ {F}_{n} $ $ {B}_{n}^{2} $ $ {B}_{n}^{3} $ $ {F}_{m} $ $ {F}_{n} $ $ {F}_{k} $ $ {B}_{m}^{4} $ $ {B}_{n}^{4} $ $ {B}_{k}^{4} $ $ {B}_{m}^{1},{B}_{m}^{2}{B}_{m}^{3},{B}_{n}^{1},{B}_{k}^{1} $ ) 则是重复块. 这3类冗余共同构成块粒度的数据冗余特性. ...
Efficient hash function–based duplication detection algorithm for data deduplication deduction and reduction
1
2021
... 重复数据缩减技术通过识别和消除数据中重复的部分来实现数据压缩,适用于具备高重复块的备份数据、定期更新数据场景,这些数据包含大量文件间及文件内部的重复内容. 数据去重的核心和关键特征是通过计算数据块的哈希指纹来识别重复块. 常用的数据去重方法主要依赖基于哈希函数的指纹计算;无哈希的分块算法常作为辅助技术,用以提高数据处理效率[25 ] . ...
Lightweight hash-based de-duplication system using the self detection of most repeated patterns as chunks divisors
1
2022
... 基于哈希函数的数据去重将数据块映射为哈希值,通过比较哈希值来识别重复数据[26 ] . 如果2个数据块具有相同的哈希值,则认为它们重复,常用的哈希函数有MD5、SHA-1、SHA-256. 由于哈希函数的固定性,可能会出现哈希冲突,即不同数据块生成相同的哈希值[27 ] . 可以采用如布隆过滤器(Bloom filter)的数据结构来进一步过滤冲突,提高数据去重的准确性[28 ] . 基于哈希函数的数据去重粒度包括文件和块,其中基于块级别的数据去重方法主要包括分块、哈希计算、数据去重与存储4个阶段,如图2 所示. ...
FuzzyDedup: secure fuzzy deduplication for cloud storage
1
2023
... 基于哈希函数的数据去重将数据块映射为哈希值,通过比较哈希值来识别重复数据[26 ] . 如果2个数据块具有相同的哈希值,则认为它们重复,常用的哈希函数有MD5、SHA-1、SHA-256. 由于哈希函数的固定性,可能会出现哈希冲突,即不同数据块生成相同的哈希值[27 ] . 可以采用如布隆过滤器(Bloom filter)的数据结构来进一步过滤冲突,提高数据去重的准确性[28 ] . 基于哈希函数的数据去重粒度包括文件和块,其中基于块级别的数据去重方法主要包括分块、哈希计算、数据去重与存储4个阶段,如图2 所示. ...
1
... 基于哈希函数的数据去重将数据块映射为哈希值,通过比较哈希值来识别重复数据[26 ] . 如果2个数据块具有相同的哈希值,则认为它们重复,常用的哈希函数有MD5、SHA-1、SHA-256. 由于哈希函数的固定性,可能会出现哈希冲突,即不同数据块生成相同的哈希值[27 ] . 可以采用如布隆过滤器(Bloom filter)的数据结构来进一步过滤冲突,提高数据去重的准确性[28 ] . 基于哈希函数的数据去重粒度包括文件和块,其中基于块级别的数据去重方法主要包括分块、哈希计算、数据去重与存储4个阶段,如图2 所示. ...
3
... (2)固定大小块级别数据去重. 固定大小块级别数据去重是将原始文件按固定大小(如4 kB或8 kB)划分为数据块[29 ] ,对每块计算哈希值以识别重复. 如图3 所示,该级别的数据去重流程包括1)数据分块,即将文件切割为固定大小块;2)哈希计算,即对每块生成唯一哈希值;3)数据去重,即比较哈希值,仅保留唯一块;4)数据存储,即保存去重后的数据块并建立映射表;5)重建文件,即根据映射表还原原始文件. 该方法可有效节省存储空间,适用于大规模数据去重和备份,尤其适合数据块结构均匀的场景. ...
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
... Comparison of data reduction technology schemes
Tab.7 方案 关键点 优点 缺点 RAD[29 ] 优化GC性能,根据数据块的可靠性需求采用不同的纠删编码方案 GC性能、可靠性、存储效率均提升 复杂度高,权衡存储与可靠,性能开销大,一致性难保 DARM[86 ] 去重感知冗余管理,利用语义信息提升存储可靠性 提升可靠性,降低存储开销 实现复杂性, 性能依赖参数的正确配置 ASDDS[88 ] 考虑隐私泄漏与审计伪造,提升数据安全与可信度 降低用户的密钥存储成本, 保证密钥的可恢复性和审计结果的可靠性 实现复杂性,性能依赖参数的正确配置 DCStore[89 ] 提供数据外包到云端的解决方案,以实现成本效益和高可用性 提高可用性,降低存储成本,提高访问性能,增强数据容错能力 实现复杂性,依赖云服务提供商,网络带宽限制 RepEC-Duet[90 ] 通过结合数据去重和差量压缩技术,提高存储系统的可靠性和性能 存储空间高效利用,数据恢复性能提升,缓存局部性维护 复杂性增加,缓存管理挑战,平衡性能与可靠性 RepEC+[91 ] 结合副本与纠删码,历史驱动差量压缩,提升可靠性与恢复效能 存储空间高效利用,数据恢复性能提升,减少循环碎片化 复杂性增加,缓存管理挑战,平衡恢复性能与存储开销
6. 数据缩减技术的应用场景以及未来的研究方向 6.1. 数据缩减技术的应用场景 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
1
... (3)可变大小块级别数据去重. 固定大小分块方法在数据插入或修改时容易导致块边界偏移[30 ] ,影响哈希值,削弱去重效果. 为此,Zhang等[31 ] 提出基于内容定义的可变大小分块方法(content-defined chunking, CDC),根据数据内容变化划分块,提升鲁棒性和去重效果. Xia等[32 ] 提出的数据去重内容定义分块方法(fast and efficient content-defined chunking,FastCD)是主流的高效CDC,相较传统Rabin-CDC,通过引入预处理机制和滚动掩码,避免逐字节滑动窗口计算,显著提升分块效率,适用于性能敏感场景(如数据去重与增量备份). FastCD主要流程如下:1)预处理窗口跳跃,减少不必要计算;2)滑动窗口与指纹计算,结合掩码提升效率;3)块边界判断,结合最小块大小和低位特征值进行双重判断;4)哈希计算,为每块生成唯一哈希值. FastCD可高效处理大型数据流,鲁棒性良好且能够保持块大小稳定. JC(jump-based chunking)[33 ] 方法通过设定跳跃条件,实现跳跃式分块,在保证重复数据识别率的同时,分块吞吐率比原算法提高超过2倍,进一步优化了可变大小分块的性能. ...
BDKM: a blockchain-based secure deduplication scheme with reliable key management
1
2022
... (3)可变大小块级别数据去重. 固定大小分块方法在数据插入或修改时容易导致块边界偏移[30 ] ,影响哈希值,削弱去重效果. 为此,Zhang等[31 ] 提出基于内容定义的可变大小分块方法(content-defined chunking, CDC),根据数据内容变化划分块,提升鲁棒性和去重效果. Xia等[32 ] 提出的数据去重内容定义分块方法(fast and efficient content-defined chunking,FastCD)是主流的高效CDC,相较传统Rabin-CDC,通过引入预处理机制和滚动掩码,避免逐字节滑动窗口计算,显著提升分块效率,适用于性能敏感场景(如数据去重与增量备份). FastCD主要流程如下:1)预处理窗口跳跃,减少不必要计算;2)滑动窗口与指纹计算,结合掩码提升效率;3)块边界判断,结合最小块大小和低位特征值进行双重判断;4)哈希计算,为每块生成唯一哈希值. FastCD可高效处理大型数据流,鲁棒性良好且能够保持块大小稳定. JC(jump-based chunking)[33 ] 方法通过设定跳跃条件,实现跳跃式分块,在保证重复数据识别率的同时,分块吞吐率比原算法提高超过2倍,进一步优化了可变大小分块的性能. ...
1
... (3)可变大小块级别数据去重. 固定大小分块方法在数据插入或修改时容易导致块边界偏移[30 ] ,影响哈希值,削弱去重效果. 为此,Zhang等[31 ] 提出基于内容定义的可变大小分块方法(content-defined chunking, CDC),根据数据内容变化划分块,提升鲁棒性和去重效果. Xia等[32 ] 提出的数据去重内容定义分块方法(fast and efficient content-defined chunking,FastCD)是主流的高效CDC,相较传统Rabin-CDC,通过引入预处理机制和滚动掩码,避免逐字节滑动窗口计算,显著提升分块效率,适用于性能敏感场景(如数据去重与增量备份). FastCD主要流程如下:1)预处理窗口跳跃,减少不必要计算;2)滑动窗口与指纹计算,结合掩码提升效率;3)块边界判断,结合最小块大小和低位特征值进行双重判断;4)哈希计算,为每块生成唯一哈希值. FastCD可高效处理大型数据流,鲁棒性良好且能够保持块大小稳定. JC(jump-based chunking)[33 ] 方法通过设定跳跃条件,实现跳跃式分块,在保证重复数据识别率的同时,分块吞吐率比原算法提高超过2倍,进一步优化了可变大小分块的性能. ...
Accelerating content-defined chunking for data deduplication based on speculative jump
1
2023
... (3)可变大小块级别数据去重. 固定大小分块方法在数据插入或修改时容易导致块边界偏移[30 ] ,影响哈希值,削弱去重效果. 为此,Zhang等[31 ] 提出基于内容定义的可变大小分块方法(content-defined chunking, CDC),根据数据内容变化划分块,提升鲁棒性和去重效果. Xia等[32 ] 提出的数据去重内容定义分块方法(fast and efficient content-defined chunking,FastCD)是主流的高效CDC,相较传统Rabin-CDC,通过引入预处理机制和滚动掩码,避免逐字节滑动窗口计算,显著提升分块效率,适用于性能敏感场景(如数据去重与增量备份). FastCD主要流程如下:1)预处理窗口跳跃,减少不必要计算;2)滑动窗口与指纹计算,结合掩码提升效率;3)块边界判断,结合最小块大小和低位特征值进行双重判断;4)哈希计算,为每块生成唯一哈希值. FastCD可高效处理大型数据流,鲁棒性良好且能够保持块大小稳定. JC(jump-based chunking)[33 ] 方法通过设定跳跃条件,实现跳跃式分块,在保证重复数据识别率的同时,分块吞吐率比原算法提高超过2倍,进一步优化了可变大小分块的性能. ...
The design of fast content-defined chunking for data deduplication based storage systems
1
2020
... LMC算法是无哈希分块算法,旨在解决Rabin-CDC在高分块差异情况下块大小不均、效率低的问题[34 ] . 如图4 所示,LMC算法通过检测局部最大值来确定切点,实现高效、精确的内容分块. 该算法的主要流程如下:1)设置固定大小的滑动窗口;2)逐字节滑动窗口;3)检测窗口内的局部最大值;4)若最大值位于2个窗口之间,则作为切点划分数据块;5)重复上述步骤直至完成分块. LMC算法无需哈希计算,降低了计算复杂度和内存开销;该算法对数据局部变化较敏感,能够在高分块差异场景下保持良好的分块准确性与去重效果,适用于大规模数据去重和同步任务. ...
Content-dependent chunking for differential compression, the local maximum approach
1
2010
... AE算法是基于极值的无哈希分块方法,如图5 所示,它通过固定窗口+可变窗口的组合检测极值确定切点[35 ] ,避免了LMC算法在滑动窗口中多次比较带来的效率下降问题. 该算法核心流程如下:1)初始化固定与可变窗口组合;2)扫描字节值,与固定窗口中所有字节进行比较;3)若当前字节大于右侧固定窗口中的所有值,则判定为切点. AE算法无需滑动窗口,比较次数比LMC算法更少;由于极值检测对数据变化敏感,该算法可在高分块差异场景中实现更精准的内容感知分块,提高数据去重效果. ...
Improving restore performance for in-line backup system combining deduplication and delta compression
1
2020
... RAM算法是在AE算法基础上优化而来的高效无哈希分块方法,旨在降低计算复杂度并提升去重效率. 如图6 所示,该算法同样采用固定窗口+可变窗口的结构,但将固定窗口置于数据块起始位置,并优先搜索最大值字节[36 ] . RAM算法的关键优化在于仅比较可变窗口中大于或等于最大值的字节,避免了AE算法中对所有字节的冗余比较,降低了计算开销. 该算法主要流程如下:1)始化窗口;2)在固定窗口中查找最大值字节;3)扫描可变窗口,与最大值比较;4)若发现大于最大值的字节,则作为切点划分数据块. RAM算法能够在保持分块准确性的同时,实现比AE算法更高的处理效率,适用于高性能数据去重场景. ...
Statistical vertical reduction-based data abridging technique for big network traffic dataset
1
2020
... 全局字典压缩是面向多文件的数据压缩方法,通过构建包含多个文件中重复片段的共享字典,利用文件间的相似性提升压缩效率[37 ] . 该方法的流程如下:1)构建全局字典,即扫描所有文件,提取重复数据片段;2)文件压缩,即将文件中的重复片段替换为全局字典的索引;3)存储结果,即保存压缩文件及全局字典,用于后续解压. 与传统单文件字典压缩不同,全局字典压缩跨文件识别冗余内容,适用于存在较强内容相似性的文件集合,如版本演化数据、日志或配置文件等场景,能够显著减少整体存储空间占用. ...
Canonical Huffman coding based image compression using wavelet
1
2021
... Broder 理论认为若集合${A_1}$ ${A_2}$ [38 ] . 这个理论为文本块的相似性判断提供了有效方法,尤其在处理大规模数据集时,通过随机生成的代表特征可以更高效地估计相似性. 使用Rabin指纹值计算数据块的特征. 将Rabin指纹值经过多次线性变换,并选择最大值作为块特征,通过对特征按大小分组,形成超特征, ...
A distributed prediction–compression-based mechanism for energy saving in IoT networks
1
2023
... 文件内部相似数据缩减技术适用于文件内部存在相似性的数据(低熵数据),主要包括基于统计模型的数据缩减方法[39 ] 、基于字典编码的数据缩减方法、基于预测模型的数据缩减方法. 文件内部相似性的概率与信息熵之间存在密切关系. 信息熵用于衡量随机变量的不确定性或信息量[40 ] ,可由数据的平均编码长度表示,即每个符号所需的平均位数, ...
Entropy optimized deep feature compression
1
2021
... 文件内部相似数据缩减技术适用于文件内部存在相似性的数据(低熵数据),主要包括基于统计模型的数据缩减方法[39 ] 、基于字典编码的数据缩减方法、基于预测模型的数据缩减方法. 文件内部相似性的概率与信息熵之间存在密切关系. 信息熵用于衡量随机变量的不确定性或信息量[40 ] ,可由数据的平均编码长度表示,即每个符号所需的平均位数, ...
1
... 基于统计模型的数据缩减方法利用数据的概率分布特性进行高效压缩. 有限状态熵编码(finite state entropy, FSE)[41 ] 是主流的应用方法,它融合了霍夫曼编码的速度优势和算术编码的压缩比优势,是许多现代压缩库(如Zstandard)中的核心算法. 传统方法仍具有代表性:霍夫曼编码通过构建最短前缀树为频率高的符号分配短码;算术编码通过将整个数据序列映射为概率区间内的实数,实现更高的压缩比,但计算复杂度更高. 相比之下,FSE 在保持高压缩率的同时,具有更好的解码效率和并行化优势,已成为当前主流压缩方案. ...
A technique for high-performance data compression
1
1984
... 字典编码是通过用字典中索引替代重复数据片段实现压缩的方法,它将数据划分为固定长度的符号,通过匹配并更新字典表实现高效编码. 代表算法包括LZ77(Lempel-Ziv-77)方法基于滑动窗口,利用指针和长度引用历史数据,压缩重复模式;LZW方法自适应构建字典,动态添加新片段,无需预知数据特性,适应性强[42 ] , 字典编码结构简单、压缩效率高,广泛应用于具有重复模式(如文本、图像)的数据压缩场景. ...
Differential coding of perception in the world’s languages
1
2018
... 基于预测模型的数据缩减方法通过对数据进行预测,利用预测值和预测误差来表示数据. 这种方法尝试找到数据中的规律和重复模式,使用更简洁的表示方法来存储数据. 差分编码利用数据与前一个数据之间的差异来表示数据,是预测编码的常见方法[43 ] . 压缩过程中,它将数据与前一个数据进行差分运算,得到差分值作为压缩数据,再将差分值进行编码表示;在解压缩过程中,通过累加差分值和前一个数据,恢复出原始数据. 差分编码适用于一些连续变化的数据,比如音频数据或时间序列数据,其中连续的数据点之间可能存在较小的差异[44 ] . ...
A secure framework for managing data in cloud storage using rapid asymmetric maximum based dynamic size chunking and fuzzy logic for deduplication
1
2024
... 基于预测模型的数据缩减方法通过对数据进行预测,利用预测值和预测误差来表示数据. 这种方法尝试找到数据中的规律和重复模式,使用更简洁的表示方法来存储数据. 差分编码利用数据与前一个数据之间的差异来表示数据,是预测编码的常见方法[43 ] . 压缩过程中,它将数据与前一个数据进行差分运算,得到差分值作为压缩数据,再将差分值进行编码表示;在解压缩过程中,通过累加差分值和前一个数据,恢复出原始数据. 差分编码适用于一些连续变化的数据,比如音频数据或时间序列数据,其中连续的数据点之间可能存在较小的差异[44 ] . ...
Fast hybrid dimensionality reduction method for classification based on feature selection and grouped feature extraction
1
2020
... 混合选择数据缩减是根据数据特征与工作负载类型动态选择最优压缩方法的策略,旨在在多样化场景中提升压缩效率与系统性能. 可以从以下角度为不同数据选择合适的数据缩减方法: 1)数据特征分析:根据文件类型、数据分布与变化率评估数据特征. 2)数据缩减方法选择:如文本类适合字典压缩,改动频繁的数据适合差量压缩. 3)动态切换:系统依据数据实时变化自动调整压缩策略. 4)应用感知:根据延迟或存储需求灵活选择压缩算法. Li等[45 ] 结合多策略特征选择和分组特征提取,融合2种方法在去除无关和冗余信息方面的优势,提出新的快速混合维度缩减方法,采用4种经典分类器和表示熵来评估缩减集的分类性能和信息损失,使原始数据的维度快速减少,提升了计算效率和分类性能. 如图8 所示,Zhang等[46 ] 分析固定大小块级别数据去重、可变大小块级别数据去重与差量压缩在不同文件类型的存储收益,其中 G 为存储增益(压缩前容量/压缩后容量). 对于Excel和PDF文档类型,数据去重无法识别任何重复内容. 对于Linux源文件,可变大小块级别数据去重比固定大小块级别数据去重的存储收益高约10%. 对于VMDK文件,可变大小分块技术略优于固定大小分块技术. 差量压缩在这几类文件上的存储收益最高,原因是基于可变大小分块的数据去重方法无法消除因小改动而引起的内容变化,差量压缩可以有效地压缩由小改动产生的相似文件,从而比数据去重节约更多的存储开销. 综上,混合选择数据缩减策略能够结合数据特性与任务需求灵活选用最优方法,在保持压缩性能的同时兼顾效率与应用适配性,适用于多种复杂工作负载环境. ...
DCDedupe: selective deduplication and delta compression with effective routing for distributed storage
2
2018
... 混合选择数据缩减是根据数据特征与工作负载类型动态选择最优压缩方法的策略,旨在在多样化场景中提升压缩效率与系统性能. 可以从以下角度为不同数据选择合适的数据缩减方法: 1)数据特征分析:根据文件类型、数据分布与变化率评估数据特征. 2)数据缩减方法选择:如文本类适合字典压缩,改动频繁的数据适合差量压缩. 3)动态切换:系统依据数据实时变化自动调整压缩策略. 4)应用感知:根据延迟或存储需求灵活选择压缩算法. Li等[45 ] 结合多策略特征选择和分组特征提取,融合2种方法在去除无关和冗余信息方面的优势,提出新的快速混合维度缩减方法,采用4种经典分类器和表示熵来评估缩减集的分类性能和信息损失,使原始数据的维度快速减少,提升了计算效率和分类性能. 如图8 所示,Zhang等[46 ] 分析固定大小块级别数据去重、可变大小块级别数据去重与差量压缩在不同文件类型的存储收益,其中 G 为存储增益(压缩前容量/压缩后容量). 对于Excel和PDF文档类型,数据去重无法识别任何重复内容. 对于Linux源文件,可变大小块级别数据去重比固定大小块级别数据去重的存储收益高约10%. 对于VMDK文件,可变大小分块技术略优于固定大小分块技术. 差量压缩在这几类文件上的存储收益最高,原因是基于可变大小分块的数据去重方法无法消除因小改动而引起的内容变化,差量压缩可以有效地压缩由小改动产生的相似文件,从而比数据去重节约更多的存储开销. 综上,混合选择数据缩减策略能够结合数据特性与任务需求灵活选用最优方法,在保持压缩性能的同时兼顾效率与应用适配性,适用于多种复杂工作负载环境. ...
... 混合数据缩减技术是将多种数据缩减技术结合使用的方法,能够为不同类型和特征的数据实现更好的压缩率与压缩效率. 针对传统哈希数据去重方法无法应对微小更改的情况,Zhang等[46 ] 提出DCDedupe,可根据数据特性智能选择差量压缩或数据去重,并结合路由算法优化分布式存储效率. 该“先去重、后差量”的组合在空间、带宽与版本管理方面更具优势. 在备份和存储系统中,数据去重可以减少存储需求,但随着时间推移,备份之间的差异性减小,因此采用差量压缩来进一步节省空间尤为重要. 相似度检测是数据去重后差量压缩的关键步骤,用于找出在不同备份中相似但不完全相同的数据块. N-transform是基于Broder定理的相似块检测方法,通过滚动哈希与多次线性变换提取超级特征,提升相似块识别精度,适用于高相似数据检测,但计算开销较大. 为了减少N-transform线性变换的计算开销,Zhang等[76 ] 提出面向去重后差分压缩的基于细粒度特征局部性的快速相似性检测方法(fine-grained feature locality based fast resemblance detection,Finesse),通过将文件块分成多个子区域,并从每个子区域提取1个特征来加速特征计算过程. Finesse利用细粒度局部性特征来解决N-transform的计算密集性问题,与N-transform SF 方法相比,Finesse的相似度检测效率提升了3.2~3.5倍,系统吞吐量提高了41%~85%. Finesse虽然提升了系统吞吐量,但是检测准确度和压缩率较低. Zou等[77 ] 提出基于代理采样的相似度检测方法(Odess),引入代理采样与Gear哈希,在压缩率接近N-transform的基础上,效率比Finesse和N-transform分别提升5.4倍和26.9倍. 重复数据消除通过识别和删除重复块来压缩备份数据,通过将差量压缩与数据去重技术结合,获得比使用单独数据去重方法更高的压缩率. 针对数据去重无法检测到2个重复块何时非常相似的问题,Huang等[78 ] 提出面向去重后差分压缩的分层相似性检测方法(hierarchical similarity detection for post-deduplication delta compression,Palantir),采用分层相似性检测策略,通过分级超特征匹配提高重复数据识别率,整体压缩性能比N-transform和Odess提升7.3%,比Finesse提升26.5%. Park等[79 ] 提出面向后去重 Delta 压缩的机器学习参考搜索新方法(DeepSketch),利用深度学习提取数据草图,压缩率比Finesse提升33%. DeepSketch需要GPU支持,资源开销大,适用于无语义二进制数据,通用性较差. 其他针对数据去重后差量压缩的相关研究旨在解决细粒度数据去重在高数据去重率的同时备份与恢复性能下降的问题. Zou等[80 ] 通过引入增量选择器与“始终向前引用”机制,解决了高去重率下的I/O放大与性能下降问题,与传统的贪心方法相比,备份与恢复性能最高分别提升34.45倍与105倍. ...
1
... 嵌套数据缩减将多个缩减步骤按顺序级联执行,使已处理的数据再次被后续算法压缩,从而在特定场景获得更高压缩比并减少存储占用[47 ] . 嵌套数据缩减方法的要点如下. 1)数据缩减级别:在嵌套数据缩减中,数据先被一个缩减算法处理,其输出作为输入传递给另一个缩减算法. 这种方法可以多级嵌套,即连续应用多个数据缩减步骤. 2)数据缩减算法选择:通常,选择不同类型的数据缩减算法进行嵌套可以产生更好的效果. 可以先使用数据去重进行初步压缩,再应用霍夫曼编码进行进一步压缩. 3)数据缩减顺序:嵌套数据缩减的效果可能会受到缩减算法的顺序影响. 一些缩减算法可能更适合在先前的缩减步骤之后使用,原因是它们可以更好地处理已处理的数据. 4)性能考虑:尽管嵌套数据缩减可以实现更高的压缩比,但会增加解压缩的开销. 因为解压缩涉及多个压缩步骤,所以解压缩时间会比单一压缩算法更长. 5)数据特征:嵌套数据缩减的效果可能因数据的特征而异. 一些数据受益于连续的缩减步骤,而其他数据可能不会有显著的效果. 数据去重后差量压缩是常见的嵌套数据缩减方法,它嵌套了数据去重和差量压缩的思想,以在特定情况下实现更高的压缩率. 该方法通常用于小粒度修改的备份数据、存档数据、定期更新数据,这些数据同时包含大量的重复块和相似块. 嵌套数据缩减方法可以在某些情况下提供更好的压缩效果,但须权衡存储空间和解压缩性能. 在应用嵌套数据缩减时,应根据数据类型、压缩算法选择和性能需求进行综合考虑,以确定最适合的策略. ...
1
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
The doctrine of MEAN: realizing deduplication storage at unreliable edge
1
2023
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
2
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
... Comparison of schemes based on deduplication rate
Tab.3 方案 关键点 优点 缺点 Jingwei[50 ] 实现高效自适应的数据去重系统迁移 提高存储空间利用率,促进服务适应性 较高的计算成本和复杂性,依赖数据块分析和参数调整 DLDAFE[51 ] 双层去重提升率,兼顾性能与块效应 动态分块组合降低开销,平衡性能与时间,减弱硬分块影响 复杂度增加,须调参数,第二层精确删除在大数据量下成瓶颈 Light-Dedup[52 ] 哈希比对结合,优化I/O实现快速块去重 提升I/O性能并节省存储开销,提高数据去重效率 内存使用依赖服务器环境,伴随额外索引开销 FSDedup[53 ] 纠错码辅助去重,指纹识别相似数据,消除高引用冗余 减少相似比较读取开销,消除更多冗余数据 依赖工作负载局部性,伴随额外计算开销 imDedup[54 ] I/O路径去重提升云主存储系统性能 降低延迟影响,灵活阈值设置,优化内存缓存使用 动态缓存调整复杂,依赖工作负载特性
数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
指纹极值的双层重复数据删除算法
2
2018
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
... Comparison of schemes based on deduplication rate
Tab.3 方案 关键点 优点 缺点 Jingwei[50 ] 实现高效自适应的数据去重系统迁移 提高存储空间利用率,促进服务适应性 较高的计算成本和复杂性,依赖数据块分析和参数调整 DLDAFE[51 ] 双层去重提升率,兼顾性能与块效应 动态分块组合降低开销,平衡性能与时间,减弱硬分块影响 复杂度增加,须调参数,第二层精确删除在大数据量下成瓶颈 Light-Dedup[52 ] 哈希比对结合,优化I/O实现快速块去重 提升I/O性能并节省存储开销,提高数据去重效率 内存使用依赖服务器环境,伴随额外索引开销 FSDedup[53 ] 纠错码辅助去重,指纹识别相似数据,消除高引用冗余 减少相似比较读取开销,消除更多冗余数据 依赖工作负载局部性,伴随额外计算开销 imDedup[54 ] I/O路径去重提升云主存储系统性能 降低延迟影响,灵活阈值设置,优化内存缓存使用 动态缓存调整复杂,依赖工作负载特性
数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
指纹极值的双层重复数据删除算法
2
2018
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
... Comparison of schemes based on deduplication rate
Tab.3 方案 关键点 优点 缺点 Jingwei[50 ] 实现高效自适应的数据去重系统迁移 提高存储空间利用率,促进服务适应性 较高的计算成本和复杂性,依赖数据块分析和参数调整 DLDAFE[51 ] 双层去重提升率,兼顾性能与块效应 动态分块组合降低开销,平衡性能与时间,减弱硬分块影响 复杂度增加,须调参数,第二层精确删除在大数据量下成瓶颈 Light-Dedup[52 ] 哈希比对结合,优化I/O实现快速块去重 提升I/O性能并节省存储开销,提高数据去重效率 内存使用依赖服务器环境,伴随额外索引开销 FSDedup[53 ] 纠错码辅助去重,指纹识别相似数据,消除高引用冗余 减少相似比较读取开销,消除更多冗余数据 依赖工作负载局部性,伴随额外计算开销 imDedup[54 ] I/O路径去重提升云主存储系统性能 降低延迟影响,灵活阈值设置,优化内存缓存使用 动态缓存调整复杂,依赖工作负载特性
数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
2
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
... Comparison of schemes based on deduplication rate
Tab.3 方案 关键点 优点 缺点 Jingwei[50 ] 实现高效自适应的数据去重系统迁移 提高存储空间利用率,促进服务适应性 较高的计算成本和复杂性,依赖数据块分析和参数调整 DLDAFE[51 ] 双层去重提升率,兼顾性能与块效应 动态分块组合降低开销,平衡性能与时间,减弱硬分块影响 复杂度增加,须调参数,第二层精确删除在大数据量下成瓶颈 Light-Dedup[52 ] 哈希比对结合,优化I/O实现快速块去重 提升I/O性能并节省存储开销,提高数据去重效率 内存使用依赖服务器环境,伴随额外索引开销 FSDedup[53 ] 纠错码辅助去重,指纹识别相似数据,消除高引用冗余 减少相似比较读取开销,消除更多冗余数据 依赖工作负载局部性,伴随额外计算开销 imDedup[54 ] I/O路径去重提升云主存储系统性能 降低延迟影响,灵活阈值设置,优化内存缓存使用 动态缓存调整复杂,依赖工作负载特性
数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
FSDedup: feature-aware and selective deduplication for improving performance of encrypted non-volatile main memory
2
2024
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
... Comparison of schemes based on deduplication rate
Tab.3 方案 关键点 优点 缺点 Jingwei[50 ] 实现高效自适应的数据去重系统迁移 提高存储空间利用率,促进服务适应性 较高的计算成本和复杂性,依赖数据块分析和参数调整 DLDAFE[51 ] 双层去重提升率,兼顾性能与块效应 动态分块组合降低开销,平衡性能与时间,减弱硬分块影响 复杂度增加,须调参数,第二层精确删除在大数据量下成瓶颈 Light-Dedup[52 ] 哈希比对结合,优化I/O实现快速块去重 提升I/O性能并节省存储开销,提高数据去重效率 内存使用依赖服务器环境,伴随额外索引开销 FSDedup[53 ] 纠错码辅助去重,指纹识别相似数据,消除高引用冗余 减少相似比较读取开销,消除更多冗余数据 依赖工作负载局部性,伴随额外计算开销 imDedup[54 ] I/O路径去重提升云主存储系统性能 降低延迟影响,灵活阈值设置,优化内存缓存使用 动态缓存调整复杂,依赖工作负载特性
数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
2
... 数据去重率是衡量重复数据缩减效果的重要指标,它表示实际去除的重复数据块与总数据块数量的比例[48 -49 ] . Cheng等[50 ] 提出针对数据去重存储系统的高效且适应性强的数据迁移策略(Jingwei),面向去重存储系统,优化数据迁移过程,通过扩展热点数据副本提升服务适应性,相比生成面向数据去重存储的最优种子方案(generating an optimal seeding plan for deduplicated storage,Goseed),Jingwei可额外提升约25%的文件副本数量,同时仅带来约5.7%的额外存储开销. 为了平衡数据去重率和数据去重效率,王青松等[51 ] 采用“两层分块”机制,先用大分块保证效率,再用小分块提升去重率,结果显著优于单层去重模型. Qiu等[52 ] 针对非易失性主存提出轻量级内联去重框架(light-weight inline deduplication framework,Light-Dedup),利用异步预取与缓冲区机制,提升 I/O 性能并减少冗余存储. Du等[53 ] 提出面向特征的选择性去重方法(feature-aware and selective deduplication,FSDedup),结合预取缓存与刷新机制,在减少读取开销的同时提升冗余识别能力,最高提升写读速度 1.8 倍、降低能耗达 2 倍. 为了应对数据中心图像存储需求的增长,Deng等[54 ] 研究图像压缩和数据去重技术,提出无损图像数据去重框架(lossless similarity-based deduplication scheme for decoded image data,imDedup),聚焦图像存储,结合图像解码与差量压缩,实现细粒度冗余剔除,在多个图像数据集上实现高压缩率与高吞吐性能. 基于数据去重率的方案优缺点比较如表3 所示. ...
... Comparison of schemes based on deduplication rate
Tab.3 方案 关键点 优点 缺点 Jingwei[50 ] 实现高效自适应的数据去重系统迁移 提高存储空间利用率,促进服务适应性 较高的计算成本和复杂性,依赖数据块分析和参数调整 DLDAFE[51 ] 双层去重提升率,兼顾性能与块效应 动态分块组合降低开销,平衡性能与时间,减弱硬分块影响 复杂度增加,须调参数,第二层精确删除在大数据量下成瓶颈 Light-Dedup[52 ] 哈希比对结合,优化I/O实现快速块去重 提升I/O性能并节省存储开销,提高数据去重效率 内存使用依赖服务器环境,伴随额外索引开销 FSDedup[53 ] 纠错码辅助去重,指纹识别相似数据,消除高引用冗余 减少相似比较读取开销,消除更多冗余数据 依赖工作负载局部性,伴随额外计算开销 imDedup[54 ] I/O路径去重提升云主存储系统性能 降低延迟影响,灵活阈值设置,优化内存缓存使用 动态缓存调整复杂,依赖工作负载特性
数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
R-dedup: 一种重复数据删除指纹计算的优化方法
2
2021
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
... Comparison of schemes based on backup performance
Tab.4 方案 关键点 优点 缺点 R-dedup[55 ] 缓解固态存储指纹瓶颈,提升数据去重整体效率 显著提高安全哈希算法1(SHA-1)吞吐率, 减少计算量, 兼具兼容性与扩展性, 误差小 内存开销大,I/O限制性能提升空间 QuickDedup[57 ] 针对云环境中虚拟机磁盘映像的高效数据去重方法 时间效率高, 最小化元数据开销, 数据去重速度快, 适用性强 固定块大小限制数据类型适配,影响去重率 dCACH[58 ] 优化备份磁盘索引,缓解分布式去重节点孤岛 高可扩展性, 高吞吐量, 高存储效率 复杂性增加, 资源消耗大, 依赖组件 SACRO[59 ] 布隆过滤器加速所有权验证,实现冗余数据快速检测 降低误报率, 提高数据块的局部性 依赖文件相似性, 缓存管理复杂 P-Dedupe[60 ] 选择性重写与缓存优化提升局部性,增强恢复性能 提升数据去重吞吐量, 并行化内容定义分块和指纹生成 对硬件资源需求较高, 不适合所有数据集类型
数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
R-dedup: 一种重复数据删除指纹计算的优化方法
2
2021
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
... Comparison of schemes based on backup performance
Tab.4 方案 关键点 优点 缺点 R-dedup[55 ] 缓解固态存储指纹瓶颈,提升数据去重整体效率 显著提高安全哈希算法1(SHA-1)吞吐率, 减少计算量, 兼具兼容性与扩展性, 误差小 内存开销大,I/O限制性能提升空间 QuickDedup[57 ] 针对云环境中虚拟机磁盘映像的高效数据去重方法 时间效率高, 最小化元数据开销, 数据去重速度快, 适用性强 固定块大小限制数据类型适配,影响去重率 dCACH[58 ] 优化备份磁盘索引,缓解分布式去重节点孤岛 高可扩展性, 高吞吐量, 高存储效率 复杂性增加, 资源消耗大, 依赖组件 SACRO[59 ] 布隆过滤器加速所有权验证,实现冗余数据快速检测 降低误报率, 提高数据块的局部性 依赖文件相似性, 缓存管理复杂 P-Dedupe[60 ] 选择性重写与缓存优化提升局部性,增强恢复性能 提升数据去重吞吐量, 并行化内容定义分块和指纹生成 对硬件资源需求较高, 不适合所有数据集类型
数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
1
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
QuickDedup: efficient VM deduplication in cloud computing environments
2
2020
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
... Comparison of schemes based on backup performance
Tab.4 方案 关键点 优点 缺点 R-dedup[55 ] 缓解固态存储指纹瓶颈,提升数据去重整体效率 显著提高安全哈希算法1(SHA-1)吞吐率, 减少计算量, 兼具兼容性与扩展性, 误差小 内存开销大,I/O限制性能提升空间 QuickDedup[57 ] 针对云环境中虚拟机磁盘映像的高效数据去重方法 时间效率高, 最小化元数据开销, 数据去重速度快, 适用性强 固定块大小限制数据类型适配,影响去重率 dCACH[58 ] 优化备份磁盘索引,缓解分布式去重节点孤岛 高可扩展性, 高吞吐量, 高存储效率 复杂性增加, 资源消耗大, 依赖组件 SACRO[59 ] 布隆过滤器加速所有权验证,实现冗余数据快速检测 降低误报率, 提高数据块的局部性 依赖文件相似性, 缓存管理复杂 P-Dedupe[60 ] 选择性重写与缓存优化提升局部性,增强恢复性能 提升数据去重吞吐量, 并行化内容定义分块和指纹生成 对硬件资源需求较高, 不适合所有数据集类型
数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
dCACH: content aware clustered and hierarchical distributed deduplication
2
2019
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
... Comparison of schemes based on backup performance
Tab.4 方案 关键点 优点 缺点 R-dedup[55 ] 缓解固态存储指纹瓶颈,提升数据去重整体效率 显著提高安全哈希算法1(SHA-1)吞吐率, 减少计算量, 兼具兼容性与扩展性, 误差小 内存开销大,I/O限制性能提升空间 QuickDedup[57 ] 针对云环境中虚拟机磁盘映像的高效数据去重方法 时间效率高, 最小化元数据开销, 数据去重速度快, 适用性强 固定块大小限制数据类型适配,影响去重率 dCACH[58 ] 优化备份磁盘索引,缓解分布式去重节点孤岛 高可扩展性, 高吞吐量, 高存储效率 复杂性增加, 资源消耗大, 依赖组件 SACRO[59 ] 布隆过滤器加速所有权验证,实现冗余数据快速检测 降低误报率, 提高数据块的局部性 依赖文件相似性, 缓存管理复杂 P-Dedupe[60 ] 选择性重写与缓存优化提升局部性,增强恢复性能 提升数据去重吞吐量, 并行化内容定义分块和指纹生成 对硬件资源需求较高, 不适合所有数据集类型
数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
SACRO: solid state drive-assisted chunk caching for restore optimization
2
2023
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
... Comparison of schemes based on backup performance
Tab.4 方案 关键点 优点 缺点 R-dedup[55 ] 缓解固态存储指纹瓶颈,提升数据去重整体效率 显著提高安全哈希算法1(SHA-1)吞吐率, 减少计算量, 兼具兼容性与扩展性, 误差小 内存开销大,I/O限制性能提升空间 QuickDedup[57 ] 针对云环境中虚拟机磁盘映像的高效数据去重方法 时间效率高, 最小化元数据开销, 数据去重速度快, 适用性强 固定块大小限制数据类型适配,影响去重率 dCACH[58 ] 优化备份磁盘索引,缓解分布式去重节点孤岛 高可扩展性, 高吞吐量, 高存储效率 复杂性增加, 资源消耗大, 依赖组件 SACRO[59 ] 布隆过滤器加速所有权验证,实现冗余数据快速检测 降低误报率, 提高数据块的局部性 依赖文件相似性, 缓存管理复杂 P-Dedupe[60 ] 选择性重写与缓存优化提升局部性,增强恢复性能 提升数据去重吞吐量, 并行化内容定义分块和指纹生成 对硬件资源需求较高, 不适合所有数据集类型
数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
Accelerating content-defined-chunking based data deduplication by exploiting parallelism
2
2019
... 数据去重会消耗额外的计算资源,导致系统的整体吞吐量下降[55 -56 ] . Saharan等[57 ] 提出云计算场景下的高效虚拟机去重方案(efficient VM deduplication in cloud computing environments,QuickDedup),面向虚拟机磁盘镜像,采用字节比较与块分类策略,避免冗余计算,减少元数据开销,提升备份性能达96%. 为了提升Extreme Binning的磁盘索引效率,Dagnaw等[58 ] 提出结合内容感知聚类和分层数据去重的方法(content aware clustered and hierarchical distributed deduplication,dCACH);融合内容感知聚类与分层数据去重机制,结合布隆过滤器提升索引效率,在保持准确性的同时,实现比作为基线的面向备份场景的可扩展数据去重技术(extreme binning) 高约 10 倍的去重效率. 此外,Dagnaw等[59 ] 还提出固态硬盘辅助的分块缓存恢复优化方法(solid state drive-assisted chunk caching for restore optimization,SACRO),通过在云中上传文件时进行双重加密来最大限度地减少网络攻击,使所有权证明的效率提高,实现冗余数据块和块的快速检测,降低了误报率. 为了进一步提升数据去重的速度,Xia等[60 ] 提出流水线和并行化的数据去重方法P-Dedupe;采用流水线并行架构,将分块与指纹生成过程并行处理,在略微牺牲去重率的前提下显著提高系统吞吐量. 基于备份性能的方案优缺点比较如表4 所示. ...
... Comparison of schemes based on backup performance
Tab.4 方案 关键点 优点 缺点 R-dedup[55 ] 缓解固态存储指纹瓶颈,提升数据去重整体效率 显著提高安全哈希算法1(SHA-1)吞吐率, 减少计算量, 兼具兼容性与扩展性, 误差小 内存开销大,I/O限制性能提升空间 QuickDedup[57 ] 针对云环境中虚拟机磁盘映像的高效数据去重方法 时间效率高, 最小化元数据开销, 数据去重速度快, 适用性强 固定块大小限制数据类型适配,影响去重率 dCACH[58 ] 优化备份磁盘索引,缓解分布式去重节点孤岛 高可扩展性, 高吞吐量, 高存储效率 复杂性增加, 资源消耗大, 依赖组件 SACRO[59 ] 布隆过滤器加速所有权验证,实现冗余数据快速检测 降低误报率, 提高数据块的局部性 依赖文件相似性, 缓存管理复杂 P-Dedupe[60 ] 选择性重写与缓存优化提升局部性,增强恢复性能 提升数据去重吞吐量, 并行化内容定义分块和指纹生成 对硬件资源需求较高, 不适合所有数据集类型
数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
2
... 数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
... Comparison of schemes based on recovery performance
Tab.5 方案 关键点 优点 缺点 TRS[61 ] 解决数据去重碎片化,避免恢复时检索冗余容器块 显著提升恢复性能, 减少回收元数据开销, 高效利用存储空间 依赖历史信息, 利用阈值敏感 FGDEFRAG[62 ] 采用可变大小与自适应定位数据组,精准识别并消除碎片化数据 提升恢复性能,减少重写数据,精准识别碎片,适应性高 参数敏感,增量性能有限,存储开销增加 MFDedup[63 ] 通过数据分类优化布局,保持备份局部性,缓解去重碎片化问题 提升恢复性能, 减少碎片化, 低开销GC过程, 简化管理与空间利用 依赖生命周期连续,恢复顺序执行,存在额外开销
引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
Improving restore performance in deduplication-based backup systems via a fine-grained defragmentation approach
2
2018
... 数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
... Comparison of schemes based on recovery performance
Tab.5 方案 关键点 优点 缺点 TRS[61 ] 解决数据去重碎片化,避免恢复时检索冗余容器块 显著提升恢复性能, 减少回收元数据开销, 高效利用存储空间 依赖历史信息, 利用阈值敏感 FGDEFRAG[62 ] 采用可变大小与自适应定位数据组,精准识别并消除碎片化数据 提升恢复性能,减少重写数据,精准识别碎片,适应性高 参数敏感,增量性能有限,存储开销增加 MFDedup[63 ] 通过数据分类优化布局,保持备份局部性,缓解去重碎片化问题 提升恢复性能, 减少碎片化, 低开销GC过程, 简化管理与空间利用 依赖生命周期连续,恢复顺序执行,存在额外开销
引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
From hyper-dimensional structures to linear structures: maintaining deduplicated data’s locality
2
2022
... 数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
... Comparison of schemes based on recovery performance
Tab.5 方案 关键点 优点 缺点 TRS[61 ] 解决数据去重碎片化,避免恢复时检索冗余容器块 显著提升恢复性能, 减少回收元数据开销, 高效利用存储空间 依赖历史信息, 利用阈值敏感 FGDEFRAG[62 ] 采用可变大小与自适应定位数据组,精准识别并消除碎片化数据 提升恢复性能,减少重写数据,精准识别碎片,适应性高 参数敏感,增量性能有限,存储开销增加 MFDedup[63 ] 通过数据分类优化布局,保持备份局部性,缓解去重碎片化问题 提升恢复性能, 减少碎片化, 低开销GC过程, 简化管理与空间利用 依赖生命周期连续,恢复顺序执行,存在额外开销
引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
1
... 数据去重导致数据块在物理存储上被分散, 引发恢复性能低下的问题,可以通过写入重复数据(如重写)或将数据缓存到内存或固态硬盘中来保持局部性, 但碎片化仍然会降低恢复和垃圾回收(garbage collection,GC)性能. Lin等[61 ] 提出基于“有效容器引用计数”的阈值重写策略,结合贪婪算法( F-greedy),在维持备份性能的同时,将恢复速度提升 1.3~2.4 倍. Tan等[62 ] 提出细粒度碎片消除方法(fine-grained defragmentation approach,FGDEFRAG), 采用可变大小、自适应定位的读写方式,精确识别并去除碎片,有效减少了25%~87% 的重写数据量,恢复性能提升 14%~329%. 为了利用备份数据的局部性, Zou等[63 ] 提出从高维结构到线性结构的维护去重数据的局部方法(maintaining deduplicated data’s locality,MFDedup), 基于数据分类与邻居版本索引优化数据布局[64 ] ,利用版本感知重组与离线迭代重排块顺序,显著减少恢复过程中的随机 I/O,恢复吞吐量最高提升 11.64 倍,提高数据去重率 1.12~2.19 倍. 基于恢复性能的方案优缺点比较如表5 所示. ...
ESDedup: an efficient and secure deduplication scheme based on data similarity and blockchain for cloud-assisted medical storage systems
1
2023
... 引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
Endurable SSD-based read cache for improving the performance of selective restore from deduplication systems
1
2018
... 引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
Hybrid deduplication system: a block-level similarity-based approach
2
2021
... 引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
... Comparison of schemes based on system overhead
Tab.6 方案 关键点 优点 缺点 HDS[67 ] 减少随机访问与并发元数据开销,降低碎片化,提升主存储性能 减少元数据开销,提升存储效率,优化I/O性能 去重覆盖有限,复杂性高,缓存管理难,扩展受限 FADD[68 ] 利用文件的语义信息(如文件类型和大小)指导数据去重过程 针对性强, 减少系统开销, 提升存储性能, 灵活性高 初始投入成本及实现复杂度高, 存在安全性问题和隐私问题 BEDD[69 ] 提出小规模平衡化边缘数据去重问题优化解法及大规模次优方案 延迟约束下综合优化去重率、存储效益与资源平衡 计算开销主要由云服务商承担 CA-Dedupe[70 ] 按写请求内容分类,仅在特定类别中执行去重搜索 减少写延迟及内存消耗, 节省存储空间 软件复杂性增加, 性能依赖于文件类型
3. 文件内部、文件间相似数据缩减技术的性能研究 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
File semantic aware primary storage deduplication system
2
2023
... 引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
... Comparison of schemes based on system overhead
Tab.6 方案 关键点 优点 缺点 HDS[67 ] 减少随机访问与并发元数据开销,降低碎片化,提升主存储性能 减少元数据开销,提升存储效率,优化I/O性能 去重覆盖有限,复杂性高,缓存管理难,扩展受限 FADD[68 ] 利用文件的语义信息(如文件类型和大小)指导数据去重过程 针对性强, 减少系统开销, 提升存储性能, 灵活性高 初始投入成本及实现复杂度高, 存在安全性问题和隐私问题 BEDD[69 ] 提出小规模平衡化边缘数据去重问题优化解法及大规模次优方案 延迟约束下综合优化去重率、存储效益与资源平衡 计算开销主要由云服务商承担 CA-Dedupe[70 ] 按写请求内容分类,仅在特定类别中执行去重搜索 减少写延迟及内存消耗, 节省存储空间 软件复杂性增加, 性能依赖于文件类型
3. 文件内部、文件间相似数据缩减技术的性能研究 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
Enabling balanced data deduplication in mobile edge computing
2
2023
... 引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
... Comparison of schemes based on system overhead
Tab.6 方案 关键点 优点 缺点 HDS[67 ] 减少随机访问与并发元数据开销,降低碎片化,提升主存储性能 减少元数据开销,提升存储效率,优化I/O性能 去重覆盖有限,复杂性高,缓存管理难,扩展受限 FADD[68 ] 利用文件的语义信息(如文件类型和大小)指导数据去重过程 针对性强, 减少系统开销, 提升存储性能, 灵活性高 初始投入成本及实现复杂度高, 存在安全性问题和隐私问题 BEDD[69 ] 提出小规模平衡化边缘数据去重问题优化解法及大规模次优方案 延迟约束下综合优化去重率、存储效益与资源平衡 计算开销主要由云服务商承担 CA-Dedupe[70 ] 按写请求内容分类,仅在特定类别中执行去重搜索 减少写延迟及内存消耗, 节省存储空间 软件复杂性增加, 性能依赖于文件类型
3. 文件内部、文件间相似数据缩减技术的性能研究 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
CA-Dedupe: content-aware deduplication in SSDs
2
2020
... 引入重复数据缩减技术会增加系统的开销(如计算开销、内存开销),这些额外的开销会占用系统资源,导致系统整体性能下降[65 -66 ] . Godavari等[67 ] 提出混合去重系统(hybrid deduplication system, HDS), 结合块级内联与离线去重,通过基于相似性的段分组与局部顺序索引,减少搜索空间与元数据开销,提升了顺序访问效率. 为了进一步减少磁盘访问的IO开销, Godavari等[68 ] 又提出文件感知去重系统(file semantic aware primary storage deduplication system, FADD), 引入文件感知机制,根据文件类型和大小采用差异化去重策略,显著降低元数据访问开销与响应延迟. Luo等[69 ] 针对边缘存储系统资源受限问题,综合考虑去重率、空间利用与延迟约束,提出平衡化边缘数据去重方法(balanced edge data deduplication, BEDD),实现数据在节点间高效平衡. Gholami Taghizadeh等[70 ] 提出智能数据重复删除方法(content-aware deduplication, CA-Dedupe),面向闪存设备,对写入请求按内容和类型分类,仅在同类中去重,有效减少查找范围,使写入延迟降低32%,去重率达69.8%. 基于系统开销的方案优缺点比较如表6 所示. ...
... Comparison of schemes based on system overhead
Tab.6 方案 关键点 优点 缺点 HDS[67 ] 减少随机访问与并发元数据开销,降低碎片化,提升主存储性能 减少元数据开销,提升存储效率,优化I/O性能 去重覆盖有限,复杂性高,缓存管理难,扩展受限 FADD[68 ] 利用文件的语义信息(如文件类型和大小)指导数据去重过程 针对性强, 减少系统开销, 提升存储性能, 灵活性高 初始投入成本及实现复杂度高, 存在安全性问题和隐私问题 BEDD[69 ] 提出小规模平衡化边缘数据去重问题优化解法及大规模次优方案 延迟约束下综合优化去重率、存储效益与资源平衡 计算开销主要由云服务商承担 CA-Dedupe[70 ] 按写请求内容分类,仅在特定类别中执行去重搜索 减少写延迟及内存消耗, 节省存储空间 软件复杂性增加, 性能依赖于文件类型
3. 文件内部、文件间相似数据缩减技术的性能研究 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
1
... 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
FASTSync: a FAST delta sync scheme for encrypted cloud storage in high-bandwidth network environments
1
2023
... 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
1
... 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
Supporting reusable model migration with Edelta
1
2024
... 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
1
... 文件内部相似数据缩减技术指针对单个文件内部存在的重复或相似数据,采用特定的方法进行识别和消除,减少数据量,提高存储和传输效率的技术. 性能研究旨在深入探讨针对单个文件内部冗余数据的缩减技术,系统评估其在不同场景和条件下的性能表现;通过对技术的有效性、效率和资源消耗的分析,找出最优的解决方案,为实际应用提供有价值的参考. 文件间相似数据缩减技术是指针对不同文件之间存在的相似或重复数据,采用特定的方法进行识别和消除,从而降低数据存储需求,提高系统效率的技术. 性能研究主要集中在数据压缩率、编码速度、资源利用率和开销等方面[71 ] . Xdelta是最经典的差量压缩方法,它通过比较原始文件和目标文件之间的差异,以滑动窗口、Adler-32校验技术,生成精简的差异文件. 该方法有效降低了传输所需带宽和存储空间,提高了文件更新和变更的传递效率[72 ] . Zdelta在Xdelta的基础上优化了压缩算法,实现了更高的压缩率和性能[73 ] . 它使用“预测指令序列”的方法,通过预测源文件和目标文件之间的差异,生成更紧凑的增量补丁以实现更好的压缩效果. 相较 Xdelta与 Zdelta,Ddelta 通过融合数据去重与差分编码,并结合 Gear 分块和 SpookyHash 指纹以加速重复识别,实现了编码速度 2.5~8.0 倍、解码吞吐量 2~20 倍的提升. Edelta旨在加速差量压缩过程,利用单词内容的局部性来减少耗时的单词匹配操作,从而优化相似文件和块的差异计算. 它先寻找匹配的单词,再通过贪婪地扩展匹配单词的边界来寻找更长的重复单词. 实验结果表明,相比Ddelta、Xdelta和Zdelta等方法,Edelta在不明显牺牲压缩率的情况下,实现了3~10倍的编码加速[74 ] . 为了进一步提升压缩率与加速差量压缩过程,Tan等[75 ] 提出面向细粒度去重备份存储系统的多基准引用分块方案(SuperDelta),基于多引用基块与重基方案,进一步消除相似块冗余,与传统“一对一”的细粒度去重相比,SuperDelta压缩比提升1.05~2.40倍,备份恢复性能无显著下降. ...
1
... 混合数据缩减技术是将多种数据缩减技术结合使用的方法,能够为不同类型和特征的数据实现更好的压缩率与压缩效率. 针对传统哈希数据去重方法无法应对微小更改的情况,Zhang等[46 ] 提出DCDedupe,可根据数据特性智能选择差量压缩或数据去重,并结合路由算法优化分布式存储效率. 该“先去重、后差量”的组合在空间、带宽与版本管理方面更具优势. 在备份和存储系统中,数据去重可以减少存储需求,但随着时间推移,备份之间的差异性减小,因此采用差量压缩来进一步节省空间尤为重要. 相似度检测是数据去重后差量压缩的关键步骤,用于找出在不同备份中相似但不完全相同的数据块. N-transform是基于Broder定理的相似块检测方法,通过滚动哈希与多次线性变换提取超级特征,提升相似块识别精度,适用于高相似数据检测,但计算开销较大. 为了减少N-transform线性变换的计算开销,Zhang等[76 ] 提出面向去重后差分压缩的基于细粒度特征局部性的快速相似性检测方法(fine-grained feature locality based fast resemblance detection,Finesse),通过将文件块分成多个子区域,并从每个子区域提取1个特征来加速特征计算过程. Finesse利用细粒度局部性特征来解决N-transform的计算密集性问题,与N-transform SF 方法相比,Finesse的相似度检测效率提升了3.2~3.5倍,系统吞吐量提高了41%~85%. Finesse虽然提升了系统吞吐量,但是检测准确度和压缩率较低. Zou等[77 ] 提出基于代理采样的相似度检测方法(Odess),引入代理采样与Gear哈希,在压缩率接近N-transform的基础上,效率比Finesse和N-transform分别提升5.4倍和26.9倍. 重复数据消除通过识别和删除重复块来压缩备份数据,通过将差量压缩与数据去重技术结合,获得比使用单独数据去重方法更高的压缩率. 针对数据去重无法检测到2个重复块何时非常相似的问题,Huang等[78 ] 提出面向去重后差分压缩的分层相似性检测方法(hierarchical similarity detection for post-deduplication delta compression,Palantir),采用分层相似性检测策略,通过分级超特征匹配提高重复数据识别率,整体压缩性能比N-transform和Odess提升7.3%,比Finesse提升26.5%. Park等[79 ] 提出面向后去重 Delta 压缩的机器学习参考搜索新方法(DeepSketch),利用深度学习提取数据草图,压缩率比Finesse提升33%. DeepSketch需要GPU支持,资源开销大,适用于无语义二进制数据,通用性较差. 其他针对数据去重后差量压缩的相关研究旨在解决细粒度数据去重在高数据去重率的同时备份与恢复性能下降的问题. Zou等[80 ] 通过引入增量选择器与“始终向前引用”机制,解决了高去重率下的I/O放大与性能下降问题,与传统的贪心方法相比,备份与恢复性能最高分别提升34.45倍与105倍. ...
1
... 混合数据缩减技术是将多种数据缩减技术结合使用的方法,能够为不同类型和特征的数据实现更好的压缩率与压缩效率. 针对传统哈希数据去重方法无法应对微小更改的情况,Zhang等[46 ] 提出DCDedupe,可根据数据特性智能选择差量压缩或数据去重,并结合路由算法优化分布式存储效率. 该“先去重、后差量”的组合在空间、带宽与版本管理方面更具优势. 在备份和存储系统中,数据去重可以减少存储需求,但随着时间推移,备份之间的差异性减小,因此采用差量压缩来进一步节省空间尤为重要. 相似度检测是数据去重后差量压缩的关键步骤,用于找出在不同备份中相似但不完全相同的数据块. N-transform是基于Broder定理的相似块检测方法,通过滚动哈希与多次线性变换提取超级特征,提升相似块识别精度,适用于高相似数据检测,但计算开销较大. 为了减少N-transform线性变换的计算开销,Zhang等[76 ] 提出面向去重后差分压缩的基于细粒度特征局部性的快速相似性检测方法(fine-grained feature locality based fast resemblance detection,Finesse),通过将文件块分成多个子区域,并从每个子区域提取1个特征来加速特征计算过程. Finesse利用细粒度局部性特征来解决N-transform的计算密集性问题,与N-transform SF 方法相比,Finesse的相似度检测效率提升了3.2~3.5倍,系统吞吐量提高了41%~85%. Finesse虽然提升了系统吞吐量,但是检测准确度和压缩率较低. Zou等[77 ] 提出基于代理采样的相似度检测方法(Odess),引入代理采样与Gear哈希,在压缩率接近N-transform的基础上,效率比Finesse和N-transform分别提升5.4倍和26.9倍. 重复数据消除通过识别和删除重复块来压缩备份数据,通过将差量压缩与数据去重技术结合,获得比使用单独数据去重方法更高的压缩率. 针对数据去重无法检测到2个重复块何时非常相似的问题,Huang等[78 ] 提出面向去重后差分压缩的分层相似性检测方法(hierarchical similarity detection for post-deduplication delta compression,Palantir),采用分层相似性检测策略,通过分级超特征匹配提高重复数据识别率,整体压缩性能比N-transform和Odess提升7.3%,比Finesse提升26.5%. Park等[79 ] 提出面向后去重 Delta 压缩的机器学习参考搜索新方法(DeepSketch),利用深度学习提取数据草图,压缩率比Finesse提升33%. DeepSketch需要GPU支持,资源开销大,适用于无语义二进制数据,通用性较差. 其他针对数据去重后差量压缩的相关研究旨在解决细粒度数据去重在高数据去重率的同时备份与恢复性能下降的问题. Zou等[80 ] 通过引入增量选择器与“始终向前引用”机制,解决了高去重率下的I/O放大与性能下降问题,与传统的贪心方法相比,备份与恢复性能最高分别提升34.45倍与105倍. ...
1
... 混合数据缩减技术是将多种数据缩减技术结合使用的方法,能够为不同类型和特征的数据实现更好的压缩率与压缩效率. 针对传统哈希数据去重方法无法应对微小更改的情况,Zhang等[46 ] 提出DCDedupe,可根据数据特性智能选择差量压缩或数据去重,并结合路由算法优化分布式存储效率. 该“先去重、后差量”的组合在空间、带宽与版本管理方面更具优势. 在备份和存储系统中,数据去重可以减少存储需求,但随着时间推移,备份之间的差异性减小,因此采用差量压缩来进一步节省空间尤为重要. 相似度检测是数据去重后差量压缩的关键步骤,用于找出在不同备份中相似但不完全相同的数据块. N-transform是基于Broder定理的相似块检测方法,通过滚动哈希与多次线性变换提取超级特征,提升相似块识别精度,适用于高相似数据检测,但计算开销较大. 为了减少N-transform线性变换的计算开销,Zhang等[76 ] 提出面向去重后差分压缩的基于细粒度特征局部性的快速相似性检测方法(fine-grained feature locality based fast resemblance detection,Finesse),通过将文件块分成多个子区域,并从每个子区域提取1个特征来加速特征计算过程. Finesse利用细粒度局部性特征来解决N-transform的计算密集性问题,与N-transform SF 方法相比,Finesse的相似度检测效率提升了3.2~3.5倍,系统吞吐量提高了41%~85%. Finesse虽然提升了系统吞吐量,但是检测准确度和压缩率较低. Zou等[77 ] 提出基于代理采样的相似度检测方法(Odess),引入代理采样与Gear哈希,在压缩率接近N-transform的基础上,效率比Finesse和N-transform分别提升5.4倍和26.9倍. 重复数据消除通过识别和删除重复块来压缩备份数据,通过将差量压缩与数据去重技术结合,获得比使用单独数据去重方法更高的压缩率. 针对数据去重无法检测到2个重复块何时非常相似的问题,Huang等[78 ] 提出面向去重后差分压缩的分层相似性检测方法(hierarchical similarity detection for post-deduplication delta compression,Palantir),采用分层相似性检测策略,通过分级超特征匹配提高重复数据识别率,整体压缩性能比N-transform和Odess提升7.3%,比Finesse提升26.5%. Park等[79 ] 提出面向后去重 Delta 压缩的机器学习参考搜索新方法(DeepSketch),利用深度学习提取数据草图,压缩率比Finesse提升33%. DeepSketch需要GPU支持,资源开销大,适用于无语义二进制数据,通用性较差. 其他针对数据去重后差量压缩的相关研究旨在解决细粒度数据去重在高数据去重率的同时备份与恢复性能下降的问题. Zou等[80 ] 通过引入增量选择器与“始终向前引用”机制,解决了高去重率下的I/O放大与性能下降问题,与传统的贪心方法相比,备份与恢复性能最高分别提升34.45倍与105倍. ...
2
... 混合数据缩减技术是将多种数据缩减技术结合使用的方法,能够为不同类型和特征的数据实现更好的压缩率与压缩效率. 针对传统哈希数据去重方法无法应对微小更改的情况,Zhang等[46 ] 提出DCDedupe,可根据数据特性智能选择差量压缩或数据去重,并结合路由算法优化分布式存储效率. 该“先去重、后差量”的组合在空间、带宽与版本管理方面更具优势. 在备份和存储系统中,数据去重可以减少存储需求,但随着时间推移,备份之间的差异性减小,因此采用差量压缩来进一步节省空间尤为重要. 相似度检测是数据去重后差量压缩的关键步骤,用于找出在不同备份中相似但不完全相同的数据块. N-transform是基于Broder定理的相似块检测方法,通过滚动哈希与多次线性变换提取超级特征,提升相似块识别精度,适用于高相似数据检测,但计算开销较大. 为了减少N-transform线性变换的计算开销,Zhang等[76 ] 提出面向去重后差分压缩的基于细粒度特征局部性的快速相似性检测方法(fine-grained feature locality based fast resemblance detection,Finesse),通过将文件块分成多个子区域,并从每个子区域提取1个特征来加速特征计算过程. Finesse利用细粒度局部性特征来解决N-transform的计算密集性问题,与N-transform SF 方法相比,Finesse的相似度检测效率提升了3.2~3.5倍,系统吞吐量提高了41%~85%. Finesse虽然提升了系统吞吐量,但是检测准确度和压缩率较低. Zou等[77 ] 提出基于代理采样的相似度检测方法(Odess),引入代理采样与Gear哈希,在压缩率接近N-transform的基础上,效率比Finesse和N-transform分别提升5.4倍和26.9倍. 重复数据消除通过识别和删除重复块来压缩备份数据,通过将差量压缩与数据去重技术结合,获得比使用单独数据去重方法更高的压缩率. 针对数据去重无法检测到2个重复块何时非常相似的问题,Huang等[78 ] 提出面向去重后差分压缩的分层相似性检测方法(hierarchical similarity detection for post-deduplication delta compression,Palantir),采用分层相似性检测策略,通过分级超特征匹配提高重复数据识别率,整体压缩性能比N-transform和Odess提升7.3%,比Finesse提升26.5%. Park等[79 ] 提出面向后去重 Delta 压缩的机器学习参考搜索新方法(DeepSketch),利用深度学习提取数据草图,压缩率比Finesse提升33%. DeepSketch需要GPU支持,资源开销大,适用于无语义二进制数据,通用性较差. 其他针对数据去重后差量压缩的相关研究旨在解决细粒度数据去重在高数据去重率的同时备份与恢复性能下降的问题. Zou等[80 ] 通过引入增量选择器与“始终向前引用”机制,解决了高去重率下的I/O放大与性能下降问题,与传统的贪心方法相比,备份与恢复性能最高分别提升34.45倍与105倍. ...
... 随着如深度学习和神经网络的人工智能技术在数据处理中的广泛应用,研究者开始探索将AI技术与数据缩减结合,以提升压缩效率与系统智能化水平. AI不仅可用于自动化存储管理与智能压缩策略选择,还可通过如模型预测压缩率、解压延迟的关键指标实现面向性能优化的数据缩减系统设计[79 ] . 如SimEnc[96 ] 将语义哈希与消息锁加密(message-locked encryption,MLE)结合,针对加密 Docker 镜像实现无需解压的高性能语义保持去重. 这些工作展示了AI在数据特征建模、压缩控制与去重匹配中的巨大潜力,为构建智能化、自适应的数据缩减系统奠定了基础. ...
1
... 混合数据缩减技术是将多种数据缩减技术结合使用的方法,能够为不同类型和特征的数据实现更好的压缩率与压缩效率. 针对传统哈希数据去重方法无法应对微小更改的情况,Zhang等[46 ] 提出DCDedupe,可根据数据特性智能选择差量压缩或数据去重,并结合路由算法优化分布式存储效率. 该“先去重、后差量”的组合在空间、带宽与版本管理方面更具优势. 在备份和存储系统中,数据去重可以减少存储需求,但随着时间推移,备份之间的差异性减小,因此采用差量压缩来进一步节省空间尤为重要. 相似度检测是数据去重后差量压缩的关键步骤,用于找出在不同备份中相似但不完全相同的数据块. N-transform是基于Broder定理的相似块检测方法,通过滚动哈希与多次线性变换提取超级特征,提升相似块识别精度,适用于高相似数据检测,但计算开销较大. 为了减少N-transform线性变换的计算开销,Zhang等[76 ] 提出面向去重后差分压缩的基于细粒度特征局部性的快速相似性检测方法(fine-grained feature locality based fast resemblance detection,Finesse),通过将文件块分成多个子区域,并从每个子区域提取1个特征来加速特征计算过程. Finesse利用细粒度局部性特征来解决N-transform的计算密集性问题,与N-transform SF 方法相比,Finesse的相似度检测效率提升了3.2~3.5倍,系统吞吐量提高了41%~85%. Finesse虽然提升了系统吞吐量,但是检测准确度和压缩率较低. Zou等[77 ] 提出基于代理采样的相似度检测方法(Odess),引入代理采样与Gear哈希,在压缩率接近N-transform的基础上,效率比Finesse和N-transform分别提升5.4倍和26.9倍. 重复数据消除通过识别和删除重复块来压缩备份数据,通过将差量压缩与数据去重技术结合,获得比使用单独数据去重方法更高的压缩率. 针对数据去重无法检测到2个重复块何时非常相似的问题,Huang等[78 ] 提出面向去重后差分压缩的分层相似性检测方法(hierarchical similarity detection for post-deduplication delta compression,Palantir),采用分层相似性检测策略,通过分级超特征匹配提高重复数据识别率,整体压缩性能比N-transform和Odess提升7.3%,比Finesse提升26.5%. Park等[79 ] 提出面向后去重 Delta 压缩的机器学习参考搜索新方法(DeepSketch),利用深度学习提取数据草图,压缩率比Finesse提升33%. DeepSketch需要GPU支持,资源开销大,适用于无语义二进制数据,通用性较差. 其他针对数据去重后差量压缩的相关研究旨在解决细粒度数据去重在高数据去重率的同时备份与恢复性能下降的问题. Zou等[80 ] 通过引入增量选择器与“始终向前引用”机制,解决了高去重率下的I/O放大与性能下降问题,与传统的贪心方法相比,备份与恢复性能最高分别提升34.45倍与105倍. ...
1
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
An enterprise-grade open-source data reduction architecture for all-flash storage systems
1
2022
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
Dynamic prime chunking algorithm for data deduplication in cloud storage
1
2021
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
Fog-to-MultiCloud cooperative eHealth data management with application-aware secure deduplication
1
2022
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
PFP: improving the reliability of deduplication-based storage systems with per-file parity
1
2019
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
2
... 数据缩减技术在一定情况下会降低系统的可靠性,数据去重通过识别和删除重复的数据块来节省存储空间. 多个文件或数据可能会共享同个数据块,如果共享的数据块损坏或丢失,会影响多个文件的完整性,降低系统的可靠性[81 ] . 某些压缩算法可能对数据的容错性较低,在出现存储介质错误或传输错误时,数据的可靠性也可能会受到影响[82 ] . 因此,在使用数据缩减技术时,须仔细考虑数据的重要性和可靠性需求,确保有适当的备份和恢复机制以应对潜在的数据丢失或损坏风险 [83 -84 ] . Wu等[85 ] 分析数据去重系统中数据块的引用次数与其重要性的关系,发现少部分数据块被频繁访问且具备高引用次数;利用该数据引用特性,将低引用次数与高引用次数的数据块分别采用副本与纠删码方案相结合的方式存储. Liu等[29 ] 提出引用感知去重方法(reference-counter aware deduplication, RAD),基于引用计数智能编码,区分可靠性水平采用不同纠删码,有效降低存储与编码开销,GC性能提升24.8%. Zhou等[86 ] 提出去重感知的冗余管理方法(deduplication-aware redundancy management approach,Darm),结合去重语义信息,动态选择冗余策略,低引用块用纠删码,高引用块用副本存储,与基线方案DeepStore相比,在提升可靠性的同时降低了43.4%存储开销. ...
... Comparison of data reduction technology schemes
Tab.7 方案 关键点 优点 缺点 RAD[29 ] 优化GC性能,根据数据块的可靠性需求采用不同的纠删编码方案 GC性能、可靠性、存储效率均提升 复杂度高,权衡存储与可靠,性能开销大,一致性难保 DARM[86 ] 去重感知冗余管理,利用语义信息提升存储可靠性 提升可靠性,降低存储开销 实现复杂性, 性能依赖参数的正确配置 ASDDS[88 ] 考虑隐私泄漏与审计伪造,提升数据安全与可信度 降低用户的密钥存储成本, 保证密钥的可恢复性和审计结果的可靠性 实现复杂性,性能依赖参数的正确配置 DCStore[89 ] 提供数据外包到云端的解决方案,以实现成本效益和高可用性 提高可用性,降低存储成本,提高访问性能,增强数据容错能力 实现复杂性,依赖云服务提供商,网络带宽限制 RepEC-Duet[90 ] 通过结合数据去重和差量压缩技术,提高存储系统的可靠性和性能 存储空间高效利用,数据恢复性能提升,缓存局部性维护 复杂性增加,缓存管理挑战,平衡性能与可靠性 RepEC+[91 ] 结合副本与纠删码,历史驱动差量压缩,提升可靠性与恢复效能 存储空间高效利用,数据恢复性能提升,减少循环碎片化 复杂性增加,缓存管理挑战,平衡恢复性能与存储开销
6. 数据缩减技术的应用场景以及未来的研究方向 6.1. 数据缩减技术的应用场景 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
An identity-based proxy re-encryption for data deduplication in cloud
1
2021
... 数据去重技术可以让云服务器通过删除冗余数据来节省存储空间,Kan等[87 ] 发现传统的数据去重技术无法对加密数据进行数据去重,便提出基于身份的数据去重方案,采用代理重加密和所有权证明来管理云中的加密数据,在数据所有者离线状态下实现灵活支持密文分发,提升了访问安全性和用户存储成本. 该数据去重方案在审核同一文件时,不同用户生成的身份验证标签会对云服务商造成相当大的存储消耗. Song等[88 ] 从考虑所有权隐私的泄漏和低熵数据审计结果的可伪造性角度出发,提出面向加密云存储的区块链式去重与完整性验证方法(auditable and secure deduplication with distributed storage, ASDDS),引入区块链来管理加密密钥,降低了用户的密钥存储成本,保证了密钥的可恢复性和审计结果的可靠性. 为了实现云存储数据去重环境中高可用性和低成本的目标,An等[89 ] 提出DCStore,基于应用感知进行分块,对静态与动态文件采用不同策略,实现高去重率与吞吐量平衡;结合纠删码提升多云环境下的可用性,并通过共享容器管理减少I/O与网络开销. 针对混合数据缩减存储系统的可靠性, Zuo等[90 ] 提出同时利用复制与纠删码来确保去重与 delta 压缩存储系统高可靠性与高性能的方法(RepEC-Duet),结合副本与纠删码技术提升了混合缩减系统中增量块与唯一块的容错性;引入利用率感知过滤与协同缓存,缓解了随机放置与频繁访问问题,与Random 基线方案相比,在降低最高98%存储开销的同时恢复性能提升59%. 后续的RepEC+[91 ] 通过选择性差量压缩避免碎片化,将恢复性能提升约76.7%. 不同数据缩减技术方案的优缺点如表7 所示. ...
Blockchain-based deduplication and integrity auditing over encrypted cloud storage
2
2023
... 数据去重技术可以让云服务器通过删除冗余数据来节省存储空间,Kan等[87 ] 发现传统的数据去重技术无法对加密数据进行数据去重,便提出基于身份的数据去重方案,采用代理重加密和所有权证明来管理云中的加密数据,在数据所有者离线状态下实现灵活支持密文分发,提升了访问安全性和用户存储成本. 该数据去重方案在审核同一文件时,不同用户生成的身份验证标签会对云服务商造成相当大的存储消耗. Song等[88 ] 从考虑所有权隐私的泄漏和低熵数据审计结果的可伪造性角度出发,提出面向加密云存储的区块链式去重与完整性验证方法(auditable and secure deduplication with distributed storage, ASDDS),引入区块链来管理加密密钥,降低了用户的密钥存储成本,保证了密钥的可恢复性和审计结果的可靠性. 为了实现云存储数据去重环境中高可用性和低成本的目标,An等[89 ] 提出DCStore,基于应用感知进行分块,对静态与动态文件采用不同策略,实现高去重率与吞吐量平衡;结合纠删码提升多云环境下的可用性,并通过共享容器管理减少I/O与网络开销. 针对混合数据缩减存储系统的可靠性, Zuo等[90 ] 提出同时利用复制与纠删码来确保去重与 delta 压缩存储系统高可靠性与高性能的方法(RepEC-Duet),结合副本与纠删码技术提升了混合缩减系统中增量块与唯一块的容错性;引入利用率感知过滤与协同缓存,缓解了随机放置与频繁访问问题,与Random 基线方案相比,在降低最高98%存储开销的同时恢复性能提升59%. 后续的RepEC+[91 ] 通过选择性差量压缩避免碎片化,将恢复性能提升约76.7%. 不同数据缩减技术方案的优缺点如表7 所示. ...
... Comparison of data reduction technology schemes
Tab.7 方案 关键点 优点 缺点 RAD[29 ] 优化GC性能,根据数据块的可靠性需求采用不同的纠删编码方案 GC性能、可靠性、存储效率均提升 复杂度高,权衡存储与可靠,性能开销大,一致性难保 DARM[86 ] 去重感知冗余管理,利用语义信息提升存储可靠性 提升可靠性,降低存储开销 实现复杂性, 性能依赖参数的正确配置 ASDDS[88 ] 考虑隐私泄漏与审计伪造,提升数据安全与可信度 降低用户的密钥存储成本, 保证密钥的可恢复性和审计结果的可靠性 实现复杂性,性能依赖参数的正确配置 DCStore[89 ] 提供数据外包到云端的解决方案,以实现成本效益和高可用性 提高可用性,降低存储成本,提高访问性能,增强数据容错能力 实现复杂性,依赖云服务提供商,网络带宽限制 RepEC-Duet[90 ] 通过结合数据去重和差量压缩技术,提高存储系统的可靠性和性能 存储空间高效利用,数据恢复性能提升,缓存局部性维护 复杂性增加,缓存管理挑战,平衡性能与可靠性 RepEC+[91 ] 结合副本与纠删码,历史驱动差量压缩,提升可靠性与恢复效能 存储空间高效利用,数据恢复性能提升,减少循环碎片化 复杂性增加,缓存管理挑战,平衡恢复性能与存储开销
6. 数据缩减技术的应用场景以及未来的研究方向 6.1. 数据缩减技术的应用场景 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
2
... 数据去重技术可以让云服务器通过删除冗余数据来节省存储空间,Kan等[87 ] 发现传统的数据去重技术无法对加密数据进行数据去重,便提出基于身份的数据去重方案,采用代理重加密和所有权证明来管理云中的加密数据,在数据所有者离线状态下实现灵活支持密文分发,提升了访问安全性和用户存储成本. 该数据去重方案在审核同一文件时,不同用户生成的身份验证标签会对云服务商造成相当大的存储消耗. Song等[88 ] 从考虑所有权隐私的泄漏和低熵数据审计结果的可伪造性角度出发,提出面向加密云存储的区块链式去重与完整性验证方法(auditable and secure deduplication with distributed storage, ASDDS),引入区块链来管理加密密钥,降低了用户的密钥存储成本,保证了密钥的可恢复性和审计结果的可靠性. 为了实现云存储数据去重环境中高可用性和低成本的目标,An等[89 ] 提出DCStore,基于应用感知进行分块,对静态与动态文件采用不同策略,实现高去重率与吞吐量平衡;结合纠删码提升多云环境下的可用性,并通过共享容器管理减少I/O与网络开销. 针对混合数据缩减存储系统的可靠性, Zuo等[90 ] 提出同时利用复制与纠删码来确保去重与 delta 压缩存储系统高可靠性与高性能的方法(RepEC-Duet),结合副本与纠删码技术提升了混合缩减系统中增量块与唯一块的容错性;引入利用率感知过滤与协同缓存,缓解了随机放置与频繁访问问题,与Random 基线方案相比,在降低最高98%存储开销的同时恢复性能提升59%. 后续的RepEC+[91 ] 通过选择性差量压缩避免碎片化,将恢复性能提升约76.7%. 不同数据缩减技术方案的优缺点如表7 所示. ...
... Comparison of data reduction technology schemes
Tab.7 方案 关键点 优点 缺点 RAD[29 ] 优化GC性能,根据数据块的可靠性需求采用不同的纠删编码方案 GC性能、可靠性、存储效率均提升 复杂度高,权衡存储与可靠,性能开销大,一致性难保 DARM[86 ] 去重感知冗余管理,利用语义信息提升存储可靠性 提升可靠性,降低存储开销 实现复杂性, 性能依赖参数的正确配置 ASDDS[88 ] 考虑隐私泄漏与审计伪造,提升数据安全与可信度 降低用户的密钥存储成本, 保证密钥的可恢复性和审计结果的可靠性 实现复杂性,性能依赖参数的正确配置 DCStore[89 ] 提供数据外包到云端的解决方案,以实现成本效益和高可用性 提高可用性,降低存储成本,提高访问性能,增强数据容错能力 实现复杂性,依赖云服务提供商,网络带宽限制 RepEC-Duet[90 ] 通过结合数据去重和差量压缩技术,提高存储系统的可靠性和性能 存储空间高效利用,数据恢复性能提升,缓存局部性维护 复杂性增加,缓存管理挑战,平衡性能与可靠性 RepEC+[91 ] 结合副本与纠删码,历史驱动差量压缩,提升可靠性与恢复效能 存储空间高效利用,数据恢复性能提升,减少循环碎片化 复杂性增加,缓存管理挑战,平衡恢复性能与存储开销
6. 数据缩减技术的应用场景以及未来的研究方向 6.1. 数据缩减技术的应用场景 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
2
... 数据去重技术可以让云服务器通过删除冗余数据来节省存储空间,Kan等[87 ] 发现传统的数据去重技术无法对加密数据进行数据去重,便提出基于身份的数据去重方案,采用代理重加密和所有权证明来管理云中的加密数据,在数据所有者离线状态下实现灵活支持密文分发,提升了访问安全性和用户存储成本. 该数据去重方案在审核同一文件时,不同用户生成的身份验证标签会对云服务商造成相当大的存储消耗. Song等[88 ] 从考虑所有权隐私的泄漏和低熵数据审计结果的可伪造性角度出发,提出面向加密云存储的区块链式去重与完整性验证方法(auditable and secure deduplication with distributed storage, ASDDS),引入区块链来管理加密密钥,降低了用户的密钥存储成本,保证了密钥的可恢复性和审计结果的可靠性. 为了实现云存储数据去重环境中高可用性和低成本的目标,An等[89 ] 提出DCStore,基于应用感知进行分块,对静态与动态文件采用不同策略,实现高去重率与吞吐量平衡;结合纠删码提升多云环境下的可用性,并通过共享容器管理减少I/O与网络开销. 针对混合数据缩减存储系统的可靠性, Zuo等[90 ] 提出同时利用复制与纠删码来确保去重与 delta 压缩存储系统高可靠性与高性能的方法(RepEC-Duet),结合副本与纠删码技术提升了混合缩减系统中增量块与唯一块的容错性;引入利用率感知过滤与协同缓存,缓解了随机放置与频繁访问问题,与Random 基线方案相比,在降低最高98%存储开销的同时恢复性能提升59%. 后续的RepEC+[91 ] 通过选择性差量压缩避免碎片化,将恢复性能提升约76.7%. 不同数据缩减技术方案的优缺点如表7 所示. ...
... Comparison of data reduction technology schemes
Tab.7 方案 关键点 优点 缺点 RAD[29 ] 优化GC性能,根据数据块的可靠性需求采用不同的纠删编码方案 GC性能、可靠性、存储效率均提升 复杂度高,权衡存储与可靠,性能开销大,一致性难保 DARM[86 ] 去重感知冗余管理,利用语义信息提升存储可靠性 提升可靠性,降低存储开销 实现复杂性, 性能依赖参数的正确配置 ASDDS[88 ] 考虑隐私泄漏与审计伪造,提升数据安全与可信度 降低用户的密钥存储成本, 保证密钥的可恢复性和审计结果的可靠性 实现复杂性,性能依赖参数的正确配置 DCStore[89 ] 提供数据外包到云端的解决方案,以实现成本效益和高可用性 提高可用性,降低存储成本,提高访问性能,增强数据容错能力 实现复杂性,依赖云服务提供商,网络带宽限制 RepEC-Duet[90 ] 通过结合数据去重和差量压缩技术,提高存储系统的可靠性和性能 存储空间高效利用,数据恢复性能提升,缓存局部性维护 复杂性增加,缓存管理挑战,平衡性能与可靠性 RepEC+[91 ] 结合副本与纠删码,历史驱动差量压缩,提升可靠性与恢复效能 存储空间高效利用,数据恢复性能提升,减少循环碎片化 复杂性增加,缓存管理挑战,平衡恢复性能与存储开销
6. 数据缩减技术的应用场景以及未来的研究方向 6.1. 数据缩减技术的应用场景 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
Ensuring high reliability and performance with low space overhead for deduplicated and delta-compressed storage systems
2
2022
... 数据去重技术可以让云服务器通过删除冗余数据来节省存储空间,Kan等[87 ] 发现传统的数据去重技术无法对加密数据进行数据去重,便提出基于身份的数据去重方案,采用代理重加密和所有权证明来管理云中的加密数据,在数据所有者离线状态下实现灵活支持密文分发,提升了访问安全性和用户存储成本. 该数据去重方案在审核同一文件时,不同用户生成的身份验证标签会对云服务商造成相当大的存储消耗. Song等[88 ] 从考虑所有权隐私的泄漏和低熵数据审计结果的可伪造性角度出发,提出面向加密云存储的区块链式去重与完整性验证方法(auditable and secure deduplication with distributed storage, ASDDS),引入区块链来管理加密密钥,降低了用户的密钥存储成本,保证了密钥的可恢复性和审计结果的可靠性. 为了实现云存储数据去重环境中高可用性和低成本的目标,An等[89 ] 提出DCStore,基于应用感知进行分块,对静态与动态文件采用不同策略,实现高去重率与吞吐量平衡;结合纠删码提升多云环境下的可用性,并通过共享容器管理减少I/O与网络开销. 针对混合数据缩减存储系统的可靠性, Zuo等[90 ] 提出同时利用复制与纠删码来确保去重与 delta 压缩存储系统高可靠性与高性能的方法(RepEC-Duet),结合副本与纠删码技术提升了混合缩减系统中增量块与唯一块的容错性;引入利用率感知过滤与协同缓存,缓解了随机放置与频繁访问问题,与Random 基线方案相比,在降低最高98%存储开销的同时恢复性能提升59%. 后续的RepEC+[91 ] 通过选择性差量压缩避免碎片化,将恢复性能提升约76.7%. 不同数据缩减技术方案的优缺点如表7 所示. ...
... Comparison of data reduction technology schemes
Tab.7 方案 关键点 优点 缺点 RAD[29 ] 优化GC性能,根据数据块的可靠性需求采用不同的纠删编码方案 GC性能、可靠性、存储效率均提升 复杂度高,权衡存储与可靠,性能开销大,一致性难保 DARM[86 ] 去重感知冗余管理,利用语义信息提升存储可靠性 提升可靠性,降低存储开销 实现复杂性, 性能依赖参数的正确配置 ASDDS[88 ] 考虑隐私泄漏与审计伪造,提升数据安全与可信度 降低用户的密钥存储成本, 保证密钥的可恢复性和审计结果的可靠性 实现复杂性,性能依赖参数的正确配置 DCStore[89 ] 提供数据外包到云端的解决方案,以实现成本效益和高可用性 提高可用性,降低存储成本,提高访问性能,增强数据容错能力 实现复杂性,依赖云服务提供商,网络带宽限制 RepEC-Duet[90 ] 通过结合数据去重和差量压缩技术,提高存储系统的可靠性和性能 存储空间高效利用,数据恢复性能提升,缓存局部性维护 复杂性增加,缓存管理挑战,平衡性能与可靠性 RepEC+[91 ] 结合副本与纠删码,历史驱动差量压缩,提升可靠性与恢复效能 存储空间高效利用,数据恢复性能提升,减少循环碎片化 复杂性增加,缓存管理挑战,平衡恢复性能与存储开销
6. 数据缩减技术的应用场景以及未来的研究方向 6.1. 数据缩减技术的应用场景 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
BAD-FM: backdoor attacks against factorization-machine based neural network for tabular data prediction
1
2024
... 在金融行业,数据缩减技术广泛应用于交易数据处理、历史数据存储和风险管理等方面. 该技术通过对高频交易和银行结算系统中的数据进行去重与压缩,能够减少日志冗余,提高交易处理效率. 金融机构可以利用数据缩减技术优化历史数据归档,降低存储成本并提升查询性能. 在风险控制方面,数据缩减能够减少欺诈检测系统中的冗余日志数据[92 ] ,加快模型训练和实时检测的响应速度,提升金融安全性和运营效率. ...
Teacher-student training approach using an adaptive gain mask for LSTM-based speech enhancement in the airborne noise environment
1
2023
... 在教育行业,数据缩减技术主要应用于在线教学、考试管理和学术资源存储等方面. 该技术通过对慕课及在线课堂视频进行压缩,可以降低带宽占用,提升播放流畅性和用户体验. Huang等[93 ] 提出基于自适应增益掩码的教师-学生训练方法,有效提升了LSTM语音增强模型在复杂噪声下的表现,为在线语音教学提供了高效的语音压缩与传输方案,体现了数据缩减技术在教育场景中的智能化应用潜力. 教育管理系统利用数据去重优化学生成绩和试题库的存储,提高数据库查询效率. 此外,高校图书馆和学术数据库可以借助文本压缩技术减少存储需求,提升学术资源的检索和管理效率,支持高效的教育信息化发展. ...
FGM-SPCL: open-set recognition network for medical images based on fine-grained data mixture and spatial position constraint loss
1
2024
... 在医疗行业,数据缩减技术在医学影像处理、电子病历管理和远程医疗等方面发挥重要作用. 对于如MRI、CT的高分辨率医学影像,采用无损或有损压缩技术能够优化存储和传输效率,减少存储空间占用. 电子病历系统通过数据去重能够减少重复患者信息,提高数据检索速度和管理效率. 此外,在远程医疗诊断中,数据压缩能够降低影像和视频流的带宽需求,提升实时诊断的流畅性和精准度,优化医疗资源的利用和患者体验. 如Zhang等[94 ] 提出的结合细粒度数据混合与空间位置约束损失的医学图像开放集识别方法模型(fine-grained data mixture and spatial position constraint loss,FGM-SPCL),使医学图像在开放环境下的识别性能得到提升,且具备良好的判别能力与计算效率,为医学图像压缩与智能处理提供了新的研究方向. ...
Anomaly detection for streaming data based on grid-clustering and Gaussian distribution
1
2023
... 在工业制造领域,数据缩减技术在物联网(IoT)、设备日志管理和智能制造大数据优化等方面发挥重要作用. 工业传感器持续生成海量数据,通过压缩和去重可有效降低存储成本,提升数据传输效率. 在设备维护和运维管理中,日志数据的压缩减少了存储占用,提高了日志分析和故障诊断的速度. Zou等[95 ] 提出基于网格聚类与高斯分布的无监督异常检测算法,在不依赖先验知识的前提下实现对工业流数据的压缩处理与异常识别,同时借助滑动窗口与过滤机制降低内存消耗,提升了系统运行效率. 此外,在智能制造环境下,数据缩减技术能够优化生产数据处理,实现高效的实时监控和分析,为工业自动化和智能化提供有力支持. ...
1
... 随着如深度学习和神经网络的人工智能技术在数据处理中的广泛应用,研究者开始探索将AI技术与数据缩减结合,以提升压缩效率与系统智能化水平. AI不仅可用于自动化存储管理与智能压缩策略选择,还可通过如模型预测压缩率、解压延迟的关键指标实现面向性能优化的数据缩减系统设计[79 ] . 如SimEnc[96 ] 将语义哈希与消息锁加密(message-locked encryption,MLE)结合,针对加密 Docker 镜像实现无需解压的高性能语义保持去重. 这些工作展示了AI在数据特征建模、压缩控制与去重匹配中的巨大潜力,为构建智能化、自适应的数据缩减系统奠定了基础. ...
Secure deduplication schemes for content delivery in mobile edge computing
1
2022
... 随着数据隐私和安全问题的日益突出,未来研究还将探索在保证数据去冗余效率的同时,保护数据隐私的技术. 例如在去冗余过程中对敏感信息进行加密或模糊化,以保障数据的隐私安全[97 -98 ] . ...
Adaptive compression offloading and resource allocation for edge vision computing
1
2024
... 随着数据隐私和安全问题的日益突出,未来研究还将探索在保证数据去冗余效率的同时,保护数据隐私的技术. 例如在去冗余过程中对敏感信息进行加密或模糊化,以保障数据的隐私安全[97 -98 ] . ...
A secure cross-domain authentication scheme based on threshold signature for MEC
1
2024
... 数据缩减技术必须保证数据完整性和正确性,即不应删除或改变源数据中的任何内容. 在如备份和归档的关键应用中,数据缩减技术必须具备高度的可靠性,确保数据在恢复时能够准确无误. 未来的研究将着重于提高数据缩减算法的可靠性和鲁棒性[99 ] . ...
1
... 随着数据的多样性和应用场景的复杂性增加,传统的静态压缩方法可能无法满足所有情况的需求. 自适应数据缩减算法能够根据数据访问模式、使用情况、存储需求等因素动态调整压缩策略. 如对于频繁访问的数据,压缩算法可以优化以减少解压时间;对于不常访问的数据,则可以采用更高压缩比的算法以节省存储空间. 此外,自适应算法还可以根据硬件的性能特征进行调整,以达到最优的存储效率和系统性[100 ] . ...


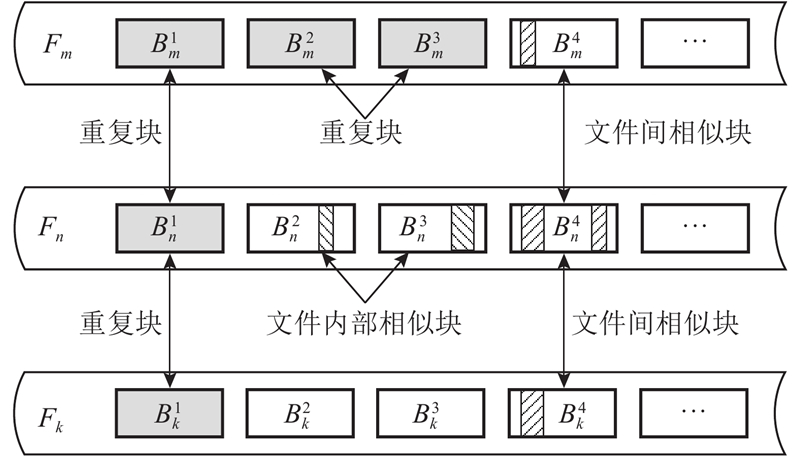
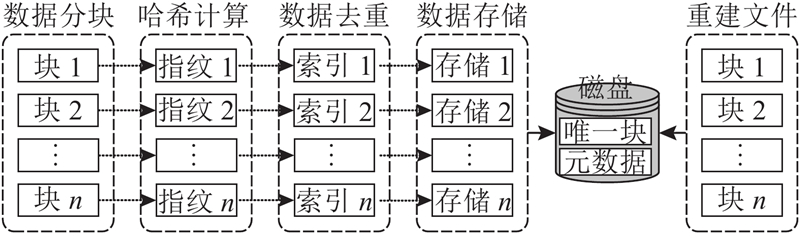
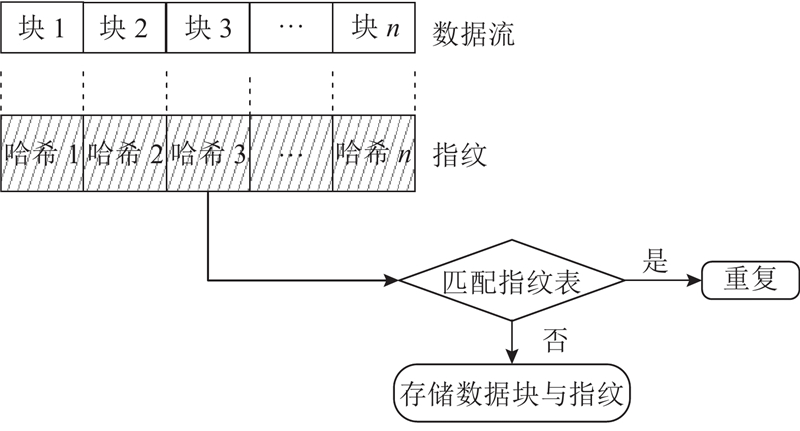
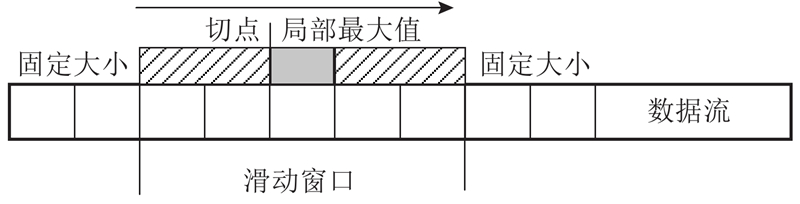


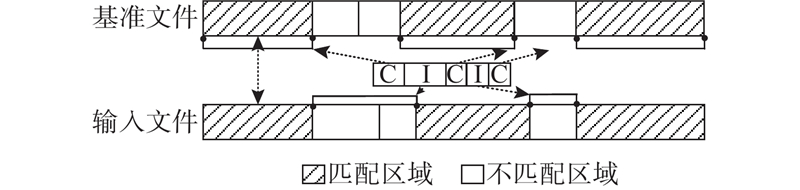
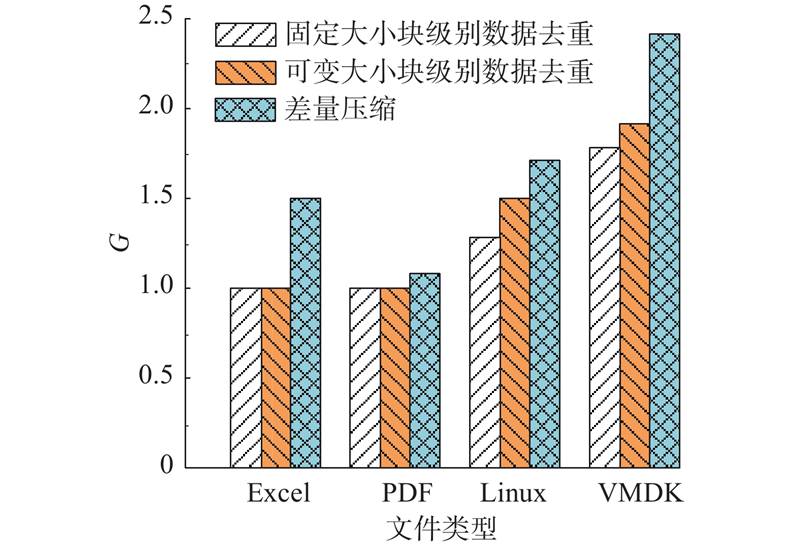

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}