[1]
MAHMOUD M, KASEM M S, KANG H S A comprehensive survey of masked faces: recognition, detection, and unmasking
[J]. Applied Sciences , 2024 , 14 (19 ): 8781
DOI:10.3390/app14198781
[本文引用: 1]
[2]
JIA Z, HUANG C, WANG Z, et al Finger recovery transformer: toward better incomplete fingerprint identification
[J]. IEEE Transactions on Information Forensics and Security , 2024 , 19 : 8860 - 8874
DOI:10.1109/TIFS.2024.3419690
[3]
KUEHLKAMP A, BOYD A, CZAJKA A, et al. Interpretable deep learning-based forensic iris segmentation and recognition [C]// IEEE/CVF Winter Conference on Applications of Computer Vision Workshops . Waikoloa: IEEE, 2022: 359–368.
[本文引用: 1]
[4]
赵晓东, 刘作军, 陈玲玲, 等 下肢假肢穿戴者跑动步态识别方法
[J]. 浙江大学学报: 工学版 , 2018 , 52 (10 ): 1980 - 1988
[本文引用: 1]
ZHAO Xiaodong, LIU Zuojun, CHEN Lingling, et al Approach of running gait recognition for lower limb amputees
[J]. Journal of Zhejiang University: Engineering Science , 2018 , 52 (10 ): 1980 - 1988
[本文引用: 1]
[5]
CHAO H, WANG K, HE Y, et al GaitSet: cross-view gait recognition through utilizing gait as a deep set
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (7 ): 3467 - 3478
[本文引用: 3]
[6]
FAN C, PENG Y, CAO C, et al. GaitPart: temporal part-based model for gait recognition [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 14213–14221.
[本文引用: 2]
[7]
HUANG Z, XUE D, SHEN X, et al. 3D local convolutional neural networks for gait recognition [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 14900–14909.
[本文引用: 1]
[8]
LIN B, ZHANG S, YU X. Gait recognition via effective global-local feature representation and local temporal aggregation [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 14628–14636.
[本文引用: 1]
[9]
DOU H, ZHANG P, SU W, et al. GaitGCI: generative counterfactual intervention for gait recognition [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 5578–5588.
[本文引用: 1]
[10]
FAN C, LIANG J, SHEN C, et al. OpenGait: revisiting gait recognition toward better practicality [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 9707–9716.
[本文引用: 2]
[11]
WANG M, GUO X, LIN B, et al. DyGait: exploiting dynamic representations for high-performance gait recognition [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 13378–13387.
[本文引用: 3]
[12]
LIAO R, YU S, AN W, et al A model-based gait recognition method with body pose and human prior knowledge
[J]. Pattern Recognition , 2020 , 98 : 107069
DOI:10.1016/j.patcog.2019.107069
[本文引用: 2]
[13]
TEEPE T, KHAN A, GILG J, et al. Gaitgraph: graph convolutional network for skeleton-based gait recognition [C]// IEEE International Conference on Image Processing . Anchorage: IEEE, 2021: 2314–2318.
[本文引用: 2]
[14]
FU Y, MENG S, HOU S, et al. GPGait: generalized pose-based gait recognition [C]// 2023 IEEE/CVF International Conference on Computer Vision . Los Alamitos: IEEE Computer Soc, 2023: 19538–19547.
[本文引用: 2]
[15]
ZHANG C, CHEN X P, HAN G Q, et al Spatial transformer network on skeleton-based gait recognition
[J]. Expert Systems , 2023 , 40 (6 ): e13244
DOI:10.1111/exsy.13244
[本文引用: 2]
[16]
SUN Y, FENG X, MA L, et al. TriGait: aligning and fusing skeleton and silhouette gait data via a tri-branch network [C]// IEEE International Joint Conference on Biometrics . Ljubljana: IEEE, 2023: 1–9.
[本文引用: 2]
[17]
ZOU S, XIONG J, FAN C, et al. A multi-stage adaptive feature fusion neural network for multimodal gait recognition [C]// IEEE International Joint Conference on Biometrics . Ljubljana: IEEE, 2023: 1–10.
[本文引用: 3]
[18]
ZHU H, ZHENG W, ZHENG Z, et al. GaitRef: gait recognition with refined sequential skeletons [C]// 2023 IEEE International Joint Conference on Biometrics . Ljubljana: IEEE, 2023: 1–10.
[本文引用: 1]
[19]
ZHENG W, ZHU H, ZHENG Z, et al GaitSTR: gait recognition with sequential two-stream refinement
[J]. IEEE Transactions on Biometrics, Behavior, and Identity Science , 2024 , 6 (4 ): 528 - 538
DOI:10.1109/TBIOM.2024.3390626
[本文引用: 3]
[20]
ZHENG J, LIU X, LIU W, et al. Gait recognition in the wild with dense 3D representations and a benchmark [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 20196–20205.
[本文引用: 6]
[21]
DONG Y, YU C, HA R, et al. HybridGait: a benchmark for spatial-temporal cloth-changing gait recognition with hybrid explorations [C]// AAAI Conference on Artificial Intelligence . Palo Alto: Assoc Advancement Artificial Intelligence, 2024: 1600–1608.
[本文引用: 5]
[22]
LOPER M, MAHMOOD N, ROMERO J, et al SMPL: a skinned multi-person linear model
[J]. ACM Transactions on Graphics , 2015 , 34 (6 ): 248
[本文引用: 1]
[23]
YU S, TAN D, TAN T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition [C]// International Conference on Pattern Recognition . Hong Kong: IEEE, 2006: 441–444.
[本文引用: 1]
[24]
TAKEMURA N, MAKIHARA Y, MURAMATSU D, et al Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition
[J]. IPSJ Transactions on Computer Vision and Applications , 2018 , 10 (1 ): 4
DOI:10.1186/s41074-018-0039-6
[本文引用: 1]
[25]
ZHU Z, GUO X, YANG T, et al. Gait recognition in the wild: a benchmark [C]// 2021 IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 14789–14799.
[本文引用: 1]
[26]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// International Conference on Learning Representations . Toulon: [s. n. ], 2017.
[本文引用: 1]
[27]
LI J, ZHANG Y, SHAN H, et al. Gaitcotr: improved spatial-temporal representation for gait recognition with a hybrid convolution-transformer framework [C]// 2023 IEEE International Conference on Acoustics, Speech and Signal Processing . Rhodes Island: IEEE, 2023: 1–5.
[本文引用: 1]
[28]
SONG Y F, ZHANG Z, SHAN C, et al. Stronger, faster and more explainable: a graph convolutional baseline for skeleton-based action recognition [C]// ACM International Conference on Multimedia . Seattle: ACM, 2020: 1625–1633.
[本文引用: 1]
[29]
LIU Z, WANG L, WU W, et al. TAM: temporal adaptive module for video recognition [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 13688–13698.
[本文引用: 1]
A comprehensive survey of masked faces: recognition, detection, and unmasking
1
2024
... 生物识别技术通过提取人体独特的生物特征实现个体身份的自动化识别,为安全、便捷的身份认证提供了可靠的手段. 其中,步态识别具备远距离识别的能力,无须识别对象主动配合且不易受环境因素影响,相较于其他生物识别技术[1 -3 ] 具有显著优势,在安防监控、智能交通、智慧医疗等实际场景[4 ] 中具有广阔的应用前景. ...
Finger recovery transformer: toward better incomplete fingerprint identification
0
2024
1
... 生物识别技术通过提取人体独特的生物特征实现个体身份的自动化识别,为安全、便捷的身份认证提供了可靠的手段. 其中,步态识别具备远距离识别的能力,无须识别对象主动配合且不易受环境因素影响,相较于其他生物识别技术[1 -3 ] 具有显著优势,在安防监控、智能交通、智慧医疗等实际场景[4 ] 中具有广阔的应用前景. ...
下肢假肢穿戴者跑动步态识别方法
1
2018
... 生物识别技术通过提取人体独特的生物特征实现个体身份的自动化识别,为安全、便捷的身份认证提供了可靠的手段. 其中,步态识别具备远距离识别的能力,无须识别对象主动配合且不易受环境因素影响,相较于其他生物识别技术[1 -3 ] 具有显著优势,在安防监控、智能交通、智慧医疗等实际场景[4 ] 中具有广阔的应用前景. ...
下肢假肢穿戴者跑动步态识别方法
1
2018
... 生物识别技术通过提取人体独特的生物特征实现个体身份的自动化识别,为安全、便捷的身份认证提供了可靠的手段. 其中,步态识别具备远距离识别的能力,无须识别对象主动配合且不易受环境因素影响,相较于其他生物识别技术[1 -3 ] 具有显著优势,在安防监控、智能交通、智慧医疗等实际场景[4 ] 中具有广阔的应用前景. ...
GaitSet: cross-view gait recognition through utilizing gait as a deep set
3
2022
... 当前的步态识别研究大致分为2类:单模态的步态识别方法和多模态的步态识别方法. 单模态方法中,基于轮廓的方法[5 -11 ] 以步态轮廓作为输入,能够提供丰富的外观信息,但是对服装、携带物品、视角等外观变化较为敏感,且无法捕捉人体的内部结构信息;基于模型的方法[12 -15 ] 一般以骨骼模型作为输入,能够提供精确的人体结构和运动信息,但在外观特征的区分性表达方面存在不足. ...
... 基于轮廓的方法直接从背景减除后的二进制轮廓图中学习步态特征. 比如Chao等[5 ] 将步态的轮廓帧视为无序集合作为输入,避免受帧排列的影响. Fan等[6 ] 提出焦点卷积层来增强部分级空间特征的细粒度学习,并加入微动作捕捉模块以提取短期时间特征. Huang等[7 ] 提出三维局部卷积,自适应地对每个身体部位进行三维局部体积的时空特征提取. Wang等[11 ] 提出动态增强模块,从二值轮廓中分离出动态特征,建立人体动态部位的时空表示. Li等[27 ] 提出基于卷积-Transformer的混合框架来改进步态的时空表示. 与基于模型的方法相比,基于轮廓的步态识别方法更简单高效,对图像的分辨率要求不高,计算成本较低,因此在步态识别领域占主导地位. 但这种方法对外观变化高度敏感,且因依赖外部形状,在行走过程中身体重叠时会丢失人体内部结构信息,从而限制了其在复杂场景中的应用. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
2
... 基于轮廓的方法直接从背景减除后的二进制轮廓图中学习步态特征. 比如Chao等[5 ] 将步态的轮廓帧视为无序集合作为输入,避免受帧排列的影响. Fan等[6 ] 提出焦点卷积层来增强部分级空间特征的细粒度学习,并加入微动作捕捉模块以提取短期时间特征. Huang等[7 ] 提出三维局部卷积,自适应地对每个身体部位进行三维局部体积的时空特征提取. Wang等[11 ] 提出动态增强模块,从二值轮廓中分离出动态特征,建立人体动态部位的时空表示. Li等[27 ] 提出基于卷积-Transformer的混合框架来改进步态的时空表示. 与基于模型的方法相比,基于轮廓的步态识别方法更简单高效,对图像的分辨率要求不高,计算成本较低,因此在步态识别领域占主导地位. 但这种方法对外观变化高度敏感,且因依赖外部形状,在行走过程中身体重叠时会丢失人体内部结构信息,从而限制了其在复杂场景中的应用. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
1
... 基于轮廓的方法直接从背景减除后的二进制轮廓图中学习步态特征. 比如Chao等[5 ] 将步态的轮廓帧视为无序集合作为输入,避免受帧排列的影响. Fan等[6 ] 提出焦点卷积层来增强部分级空间特征的细粒度学习,并加入微动作捕捉模块以提取短期时间特征. Huang等[7 ] 提出三维局部卷积,自适应地对每个身体部位进行三维局部体积的时空特征提取. Wang等[11 ] 提出动态增强模块,从二值轮廓中分离出动态特征,建立人体动态部位的时空表示. Li等[27 ] 提出基于卷积-Transformer的混合框架来改进步态的时空表示. 与基于模型的方法相比,基于轮廓的步态识别方法更简单高效,对图像的分辨率要求不高,计算成本较低,因此在步态识别领域占主导地位. 但这种方法对外观变化高度敏感,且因依赖外部形状,在行走过程中身体重叠时会丢失人体内部结构信息,从而限制了其在复杂场景中的应用. ...
1
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
1
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
2
... 在轮廓分支中,以Fan等[10 ] 提出的GaitBase为基线网络进行优化改进. 针对原始GaitBase仅关注空间特征提取而忽略步态时序建模的局限性,构建时间特征提取模块. 如图2 所示,通过时间卷积对步态轮廓的时间动态特征进行建模,从而弥补GaitBase在时间维度特征提取上的不足. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
3
... 当前的步态识别研究大致分为2类:单模态的步态识别方法和多模态的步态识别方法. 单模态方法中,基于轮廓的方法[5 -11 ] 以步态轮廓作为输入,能够提供丰富的外观信息,但是对服装、携带物品、视角等外观变化较为敏感,且无法捕捉人体的内部结构信息;基于模型的方法[12 -15 ] 一般以骨骼模型作为输入,能够提供精确的人体结构和运动信息,但在外观特征的区分性表达方面存在不足. ...
... 基于轮廓的方法直接从背景减除后的二进制轮廓图中学习步态特征. 比如Chao等[5 ] 将步态的轮廓帧视为无序集合作为输入,避免受帧排列的影响. Fan等[6 ] 提出焦点卷积层来增强部分级空间特征的细粒度学习,并加入微动作捕捉模块以提取短期时间特征. Huang等[7 ] 提出三维局部卷积,自适应地对每个身体部位进行三维局部体积的时空特征提取. Wang等[11 ] 提出动态增强模块,从二值轮廓中分离出动态特征,建立人体动态部位的时空表示. Li等[27 ] 提出基于卷积-Transformer的混合框架来改进步态的时空表示. 与基于模型的方法相比,基于轮廓的步态识别方法更简单高效,对图像的分辨率要求不高,计算成本较低,因此在步态识别领域占主导地位. 但这种方法对外观变化高度敏感,且因依赖外部形状,在行走过程中身体重叠时会丢失人体内部结构信息,从而限制了其在复杂场景中的应用. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
A model-based gait recognition method with body pose and human prior knowledge
2
2020
... 当前的步态识别研究大致分为2类:单模态的步态识别方法和多模态的步态识别方法. 单模态方法中,基于轮廓的方法[5 -11 ] 以步态轮廓作为输入,能够提供丰富的外观信息,但是对服装、携带物品、视角等外观变化较为敏感,且无法捕捉人体的内部结构信息;基于模型的方法[12 -15 ] 一般以骨骼模型作为输入,能够提供精确的人体结构和运动信息,但在外观特征的区分性表达方面存在不足. ...
... 基于模型的方法通过预定义的二维或三维人体模型提取步态特征,比如,二维骨骼、三维骨骼、SMPL模型,建模肢体长度、关节角度和部位相对位置等运动学参数. 通过提取人体运动中的关键点和姿态变化,实现对步态的分析和识别. 如Liao等[12 ] 通过结合三维骨骼与先验知识提高识别精度. Zhang等[15 ] 提出组合空间转换器和时间卷积网络的模型来进行基于骨骼的步态识别. 随着图卷积神经网络(graph convolutional networks, GCN)[26 ] 在动作识别领域的广泛使用,GCN逐渐被引入步态识别领域,Teepe等[13 ] 首次将骨骼姿势与GCN相结合,通过构建骨骼关节点之间的图结构以及关节点在时间上的变化进行有效的时空建模. Fu等[14 ] 提出部分感知图卷积网络,通过分区掩码进行图分割以提取局部和全局的空间特征关系. 基于模型的步态识别方法关注关节位置这类结构特征,因此能够有效克服外观变化带来的干扰,提供更稳定的特征. 然而其结构化的表征方式难以捕捉个体在体型轮廓上的外观差异,当不同个体具有相似运动模式时,仅依赖关节位置信息难以准确区分. ...
2
... 基于模型的方法通过预定义的二维或三维人体模型提取步态特征,比如,二维骨骼、三维骨骼、SMPL模型,建模肢体长度、关节角度和部位相对位置等运动学参数. 通过提取人体运动中的关键点和姿态变化,实现对步态的分析和识别. 如Liao等[12 ] 通过结合三维骨骼与先验知识提高识别精度. Zhang等[15 ] 提出组合空间转换器和时间卷积网络的模型来进行基于骨骼的步态识别. 随着图卷积神经网络(graph convolutional networks, GCN)[26 ] 在动作识别领域的广泛使用,GCN逐渐被引入步态识别领域,Teepe等[13 ] 首次将骨骼姿势与GCN相结合,通过构建骨骼关节点之间的图结构以及关节点在时间上的变化进行有效的时空建模. Fu等[14 ] 提出部分感知图卷积网络,通过分区掩码进行图分割以提取局部和全局的空间特征关系. 基于模型的步态识别方法关注关节位置这类结构特征,因此能够有效克服外观变化带来的干扰,提供更稳定的特征. 然而其结构化的表征方式难以捕捉个体在体型轮廓上的外观差异,当不同个体具有相似运动模式时,仅依赖关节位置信息难以准确区分. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
2
... 基于模型的方法通过预定义的二维或三维人体模型提取步态特征,比如,二维骨骼、三维骨骼、SMPL模型,建模肢体长度、关节角度和部位相对位置等运动学参数. 通过提取人体运动中的关键点和姿态变化,实现对步态的分析和识别. 如Liao等[12 ] 通过结合三维骨骼与先验知识提高识别精度. Zhang等[15 ] 提出组合空间转换器和时间卷积网络的模型来进行基于骨骼的步态识别. 随着图卷积神经网络(graph convolutional networks, GCN)[26 ] 在动作识别领域的广泛使用,GCN逐渐被引入步态识别领域,Teepe等[13 ] 首次将骨骼姿势与GCN相结合,通过构建骨骼关节点之间的图结构以及关节点在时间上的变化进行有效的时空建模. Fu等[14 ] 提出部分感知图卷积网络,通过分区掩码进行图分割以提取局部和全局的空间特征关系. 基于模型的步态识别方法关注关节位置这类结构特征,因此能够有效克服外观变化带来的干扰,提供更稳定的特征. 然而其结构化的表征方式难以捕捉个体在体型轮廓上的外观差异,当不同个体具有相似运动模式时,仅依赖关节位置信息难以准确区分. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
Spatial transformer network on skeleton-based gait recognition
2
2023
... 当前的步态识别研究大致分为2类:单模态的步态识别方法和多模态的步态识别方法. 单模态方法中,基于轮廓的方法[5 -11 ] 以步态轮廓作为输入,能够提供丰富的外观信息,但是对服装、携带物品、视角等外观变化较为敏感,且无法捕捉人体的内部结构信息;基于模型的方法[12 -15 ] 一般以骨骼模型作为输入,能够提供精确的人体结构和运动信息,但在外观特征的区分性表达方面存在不足. ...
... 基于模型的方法通过预定义的二维或三维人体模型提取步态特征,比如,二维骨骼、三维骨骼、SMPL模型,建模肢体长度、关节角度和部位相对位置等运动学参数. 通过提取人体运动中的关键点和姿态变化,实现对步态的分析和识别. 如Liao等[12 ] 通过结合三维骨骼与先验知识提高识别精度. Zhang等[15 ] 提出组合空间转换器和时间卷积网络的模型来进行基于骨骼的步态识别. 随着图卷积神经网络(graph convolutional networks, GCN)[26 ] 在动作识别领域的广泛使用,GCN逐渐被引入步态识别领域,Teepe等[13 ] 首次将骨骼姿势与GCN相结合,通过构建骨骼关节点之间的图结构以及关节点在时间上的变化进行有效的时空建模. Fu等[14 ] 提出部分感知图卷积网络,通过分区掩码进行图分割以提取局部和全局的空间特征关系. 基于模型的步态识别方法关注关节位置这类结构特征,因此能够有效克服外观变化带来的干扰,提供更稳定的特征. 然而其结构化的表征方式难以捕捉个体在体型轮廓上的外观差异,当不同个体具有相似运动模式时,仅依赖关节位置信息难以准确区分. ...
2
... 为了突破单模态的局限,基于多模态的步态识别方法融合了模型和轮廓的互补优势,在实际场景中有更强的适应性. 例如,基于骨骼与轮廓的多模态方法[16 -19 ] ,通过结合骨骼的结构信息和轮廓的外观信息提升识别效果. 最近的研究中,Zheng等[20 -21 ] 在工作中引入蒙皮多人线性(skinned multi-person linear, SMPL)模型[22 ] ,来代替传统的骨骼模型. SMPL模型能提供精确的关节姿态和形状参数,弥补了骨骼在外观表达上的不足,使得基于SMPL模型和轮廓的多模态方法不仅保留了模型在结构信息表达上的优势,还显著增强了对人体姿态与形状变化的适应性. 然而,尽管模型与轮廓2个模态的相互补充提供了更丰富的表征能力,但目前的多模态步态识别方法仍然存在一定的不足. ...
... 近年来,步态识别领域对集成多个模态的方法进行了研究. 如Sun等[16 ] 提出的三分支网络、Zou等[17 ] 提出的多阶段自适应融合网络以及Zheng等[19 ] 提出的顺序双流细化网络,通过融合骨骼和轮廓模态,有效提升步态识别的准确性和鲁棒性. 此外,SMPL模型的引入为多模态步态识别提供了更全面的步态表征. Zheng等[20 ] 首次提出包含SMPL模型的真实场景数据集,同时提出多模态步态识别方法SMPLGait,利用SMPL模型在三维人体表征方面的优势,通过构建三维空间变换模块将SMPL模型与轮廓模态进行信息融合. Dong等[21 ] 引入投影分支,将SMPL模型的投影轮廓作为辅助输入,帮助表示身体特征,以实现更加精确的信息融合. 尽管如此,现有方法仍面临分支信息挖掘不足、跨模态特征对齐不充分的挑战,制约了多模态步态识别的性能上限. ...
3
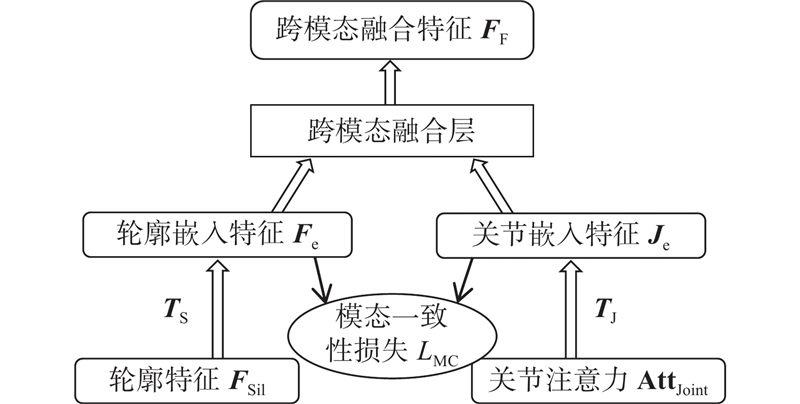
... 首先,现有方法更关注模态之间的融合,缺乏对各模态分支特征提取的针对性优化. 如Zheng等[20 ] 采用全连接网络学习SMPL模型的步态信息,结构较简单,难以充分捕捉姿态变化的时序特征;Dong等[21 ] 通过提取22个关节点并转换为特征图来进行融合,虽考虑了姿势信息,但其方法在Gait3D上准确率仍不足54%,表明关键姿势信息在转换中存在一定丢失,同时也未能有效利用SMPL模型所包含的静态形状特征. 这些方法未能充分挖掘SMPL模型包含的形状信息和运动姿势信息,影响了特征的有效表达. 其次,由于不同模态在数据形式上的差异,模态融合过程中的特征对齐成为关键问题. 现有方法尝试从不同角度进行对齐. 例如,Dong等[21 ] 使用K最近邻法对齐轮廓特征与SMPL模型的姿势特征,虽能实现局部特征匹配,但难以建模全局语义关联;Zou等[17 ] 通过交叉注意力机制,动态搜索骨骼和轮廓各部分之间的关联权值进行对齐融合,虽提升了特征对齐的灵活性,但无法量化模态间对齐的程度,且缺乏对模态间表征一致性的显式约束. 这些方法在一定程度上实现了模态间的特征对齐,但普遍存在缺乏特征一致性约束和语义对齐机制不完善的问题,进而限制了跨模态特征融合的有效性. ...
... 近年来,步态识别领域对集成多个模态的方法进行了研究. 如Sun等[16 ] 提出的三分支网络、Zou等[17 ] 提出的多阶段自适应融合网络以及Zheng等[19 ] 提出的顺序双流细化网络,通过融合骨骼和轮廓模态,有效提升步态识别的准确性和鲁棒性. 此外,SMPL模型的引入为多模态步态识别提供了更全面的步态表征. Zheng等[20 ] 首次提出包含SMPL模型的真实场景数据集,同时提出多模态步态识别方法SMPLGait,利用SMPL模型在三维人体表征方面的优势,通过构建三维空间变换模块将SMPL模型与轮廓模态进行信息融合. Dong等[21 ] 引入投影分支,将SMPL模型的投影轮廓作为辅助输入,帮助表示身体特征,以实现更加精确的信息融合. 尽管如此,现有方法仍面临分支信息挖掘不足、跨模态特征对齐不充分的挑战,制约了多模态步态识别的性能上限. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
1
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
GaitSTR: gait recognition with sequential two-stream refinement
3
2024
... 为了突破单模态的局限,基于多模态的步态识别方法融合了模型和轮廓的互补优势,在实际场景中有更强的适应性. 例如,基于骨骼与轮廓的多模态方法[16 -19 ] ,通过结合骨骼的结构信息和轮廓的外观信息提升识别效果. 最近的研究中,Zheng等[20 -21 ] 在工作中引入蒙皮多人线性(skinned multi-person linear, SMPL)模型[22 ] ,来代替传统的骨骼模型. SMPL模型能提供精确的关节姿态和形状参数,弥补了骨骼在外观表达上的不足,使得基于SMPL模型和轮廓的多模态方法不仅保留了模型在结构信息表达上的优势,还显著增强了对人体姿态与形状变化的适应性. 然而,尽管模型与轮廓2个模态的相互补充提供了更丰富的表征能力,但目前的多模态步态识别方法仍然存在一定的不足. ...
... 近年来,步态识别领域对集成多个模态的方法进行了研究. 如Sun等[16 ] 提出的三分支网络、Zou等[17 ] 提出的多阶段自适应融合网络以及Zheng等[19 ] 提出的顺序双流细化网络,通过融合骨骼和轮廓模态,有效提升步态识别的准确性和鲁棒性. 此外,SMPL模型的引入为多模态步态识别提供了更全面的步态表征. Zheng等[20 ] 首次提出包含SMPL模型的真实场景数据集,同时提出多模态步态识别方法SMPLGait,利用SMPL模型在三维人体表征方面的优势,通过构建三维空间变换模块将SMPL模型与轮廓模态进行信息融合. Dong等[21 ] 引入投影分支,将SMPL模型的投影轮廓作为辅助输入,帮助表示身体特征,以实现更加精确的信息融合. 尽管如此,现有方法仍面临分支信息挖掘不足、跨模态特征对齐不充分的挑战,制约了多模态步态识别的性能上限. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
6
... 为了突破单模态的局限,基于多模态的步态识别方法融合了模型和轮廓的互补优势,在实际场景中有更强的适应性. 例如,基于骨骼与轮廓的多模态方法[16 -19 ] ,通过结合骨骼的结构信息和轮廓的外观信息提升识别效果. 最近的研究中,Zheng等[20 -21 ] 在工作中引入蒙皮多人线性(skinned multi-person linear, SMPL)模型[22 ] ,来代替传统的骨骼模型. SMPL模型能提供精确的关节姿态和形状参数,弥补了骨骼在外观表达上的不足,使得基于SMPL模型和轮廓的多模态方法不仅保留了模型在结构信息表达上的优势,还显著增强了对人体姿态与形状变化的适应性. 然而,尽管模型与轮廓2个模态的相互补充提供了更丰富的表征能力,但目前的多模态步态识别方法仍然存在一定的不足. ...
... 首先,现有方法更关注模态之间的融合,缺乏对各模态分支特征提取的针对性优化. 如Zheng等[20 ] 采用全连接网络学习SMPL模型的步态信息,结构较简单,难以充分捕捉姿态变化的时序特征;Dong等[21 ] 通过提取22个关节点并转换为特征图来进行融合,虽考虑了姿势信息,但其方法在Gait3D上准确率仍不足54%,表明关键姿势信息在转换中存在一定丢失,同时也未能有效利用SMPL模型所包含的静态形状特征. 这些方法未能充分挖掘SMPL模型包含的形状信息和运动姿势信息,影响了特征的有效表达. 其次,由于不同模态在数据形式上的差异,模态融合过程中的特征对齐成为关键问题. 现有方法尝试从不同角度进行对齐. 例如,Dong等[21 ] 使用K最近邻法对齐轮廓特征与SMPL模型的姿势特征,虽能实现局部特征匹配,但难以建模全局语义关联;Zou等[17 ] 通过交叉注意力机制,动态搜索骨骼和轮廓各部分之间的关联权值进行对齐融合,虽提升了特征对齐的灵活性,但无法量化模态间对齐的程度,且缺乏对模态间表征一致性的显式约束. 这些方法在一定程度上实现了模态间的特征对齐,但普遍存在缺乏特征一致性约束和语义对齐机制不完善的问题,进而限制了跨模态特征融合的有效性. ...
... 步态识别是通过分析个体行走姿态特征实现身份识别的技术. 随着深度学习技术的快速发展,步态识别技术取得了显著进步,其研究方法已从早期的传统特征提取方法逐步演变为基于深度学习的从输入数据中直接学习步态特征进行识别. 与此同时,研究场景也逐渐从受限的室内环境如CASIA-B数据集[23 ] 和OU-MVLP数据集[24 ] 扩展至更有挑战性的开放式真实场景如Gait3D数据集[20 ] 和GREW数据集[25 ] ,进一步推动了步态识别技术的实用化进程. 当前的步态识别方法大致可归纳为2类:基于单模态的方法和基于多模态的方法. ...
... 近年来,步态识别领域对集成多个模态的方法进行了研究. 如Sun等[16 ] 提出的三分支网络、Zou等[17 ] 提出的多阶段自适应融合网络以及Zheng等[19 ] 提出的顺序双流细化网络,通过融合骨骼和轮廓模态,有效提升步态识别的准确性和鲁棒性. 此外,SMPL模型的引入为多模态步态识别提供了更全面的步态表征. Zheng等[20 ] 首次提出包含SMPL模型的真实场景数据集,同时提出多模态步态识别方法SMPLGait,利用SMPL模型在三维人体表征方面的优势,通过构建三维空间变换模块将SMPL模型与轮廓模态进行信息融合. Dong等[21 ] 引入投影分支,将SMPL模型的投影轮廓作为辅助输入,帮助表示身体特征,以实现更加精确的信息融合. 尽管如此,现有方法仍面临分支信息挖掘不足、跨模态特征对齐不充分的挑战,制约了多模态步态识别的性能上限. ...
... Gait3D[20 ] 是第1个基于三维表示的大规模步态识别数据集,广泛应用于真实场景下的步态识别研究. 其数据采集工作是在大型超市中进行的,具有高度的真实性. 该数据集包含了来自4000 名受试者的25309 个视频序列. 其中训练集包含3000 名受试者,18940 个序列;测试集包含1000 名受试者,6369 个序列. 为了进行评估,从每个受试者的序列中随机选择一个作为注册集,其余序列作为验证集,用于匹配与验证. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
5
... 为了突破单模态的局限,基于多模态的步态识别方法融合了模型和轮廓的互补优势,在实际场景中有更强的适应性. 例如,基于骨骼与轮廓的多模态方法[16 -19 ] ,通过结合骨骼的结构信息和轮廓的外观信息提升识别效果. 最近的研究中,Zheng等[20 -21 ] 在工作中引入蒙皮多人线性(skinned multi-person linear, SMPL)模型[22 ] ,来代替传统的骨骼模型. SMPL模型能提供精确的关节姿态和形状参数,弥补了骨骼在外观表达上的不足,使得基于SMPL模型和轮廓的多模态方法不仅保留了模型在结构信息表达上的优势,还显著增强了对人体姿态与形状变化的适应性. 然而,尽管模型与轮廓2个模态的相互补充提供了更丰富的表征能力,但目前的多模态步态识别方法仍然存在一定的不足. ...
... 首先,现有方法更关注模态之间的融合,缺乏对各模态分支特征提取的针对性优化. 如Zheng等[20 ] 采用全连接网络学习SMPL模型的步态信息,结构较简单,难以充分捕捉姿态变化的时序特征;Dong等[21 ] 通过提取22个关节点并转换为特征图来进行融合,虽考虑了姿势信息,但其方法在Gait3D上准确率仍不足54%,表明关键姿势信息在转换中存在一定丢失,同时也未能有效利用SMPL模型所包含的静态形状特征. 这些方法未能充分挖掘SMPL模型包含的形状信息和运动姿势信息,影响了特征的有效表达. 其次,由于不同模态在数据形式上的差异,模态融合过程中的特征对齐成为关键问题. 现有方法尝试从不同角度进行对齐. 例如,Dong等[21 ] 使用K最近邻法对齐轮廓特征与SMPL模型的姿势特征,虽能实现局部特征匹配,但难以建模全局语义关联;Zou等[17 ] 通过交叉注意力机制,动态搜索骨骼和轮廓各部分之间的关联权值进行对齐融合,虽提升了特征对齐的灵活性,但无法量化模态间对齐的程度,且缺乏对模态间表征一致性的显式约束. 这些方法在一定程度上实现了模态间的特征对齐,但普遍存在缺乏特征一致性约束和语义对齐机制不完善的问题,进而限制了跨模态特征融合的有效性. ...
... [21 ]使用K最近邻法对齐轮廓特征与SMPL模型的姿势特征,虽能实现局部特征匹配,但难以建模全局语义关联;Zou等[17 ] 通过交叉注意力机制,动态搜索骨骼和轮廓各部分之间的关联权值进行对齐融合,虽提升了特征对齐的灵活性,但无法量化模态间对齐的程度,且缺乏对模态间表征一致性的显式约束. 这些方法在一定程度上实现了模态间的特征对齐,但普遍存在缺乏特征一致性约束和语义对齐机制不完善的问题,进而限制了跨模态特征融合的有效性. ...
... 近年来,步态识别领域对集成多个模态的方法进行了研究. 如Sun等[16 ] 提出的三分支网络、Zou等[17 ] 提出的多阶段自适应融合网络以及Zheng等[19 ] 提出的顺序双流细化网络,通过融合骨骼和轮廓模态,有效提升步态识别的准确性和鲁棒性. 此外,SMPL模型的引入为多模态步态识别提供了更全面的步态表征. Zheng等[20 ] 首次提出包含SMPL模型的真实场景数据集,同时提出多模态步态识别方法SMPLGait,利用SMPL模型在三维人体表征方面的优势,通过构建三维空间变换模块将SMPL模型与轮廓模态进行信息融合. Dong等[21 ] 引入投影分支,将SMPL模型的投影轮廓作为辅助输入,帮助表示身体特征,以实现更加精确的信息融合. 尽管如此,现有方法仍面临分支信息挖掘不足、跨模态特征对齐不充分的挑战,制约了多模态步态识别的性能上限. ...
... Comparison results of different methods on Gait3D dataset
Tab.3 模态 方法 来源 Rank-1 Rank-5 mAP/% mINP/% 轮廓 GaitSet[5 ] AAAI2019 36.70 58.30 30.01 17.30 GaitPart[6 ] CVPR2020 28.20 47.60 21.58 12.36 GaitGL[8 ] ICCV2021 29.70 48.50 22.29 13.26 GaitGCI[9 ] CVPR2023 50.30 68.50 39.50 24.30 GaitBase[10 ] CVPR2023 64.20 79.50 54.51 36.36 DyGait[11 ] ICCV2023 66.30 80.80 56.40 37.30 骨骼 GaitGraph[13 ] ICIP2021 8.30 16.60 7.14 4.80 GPGait[14 ] ICCV2023 22.50 — — — 轮廓+ MSAFF[17 ] IJCB2023 48.10 66.60 38.45 23.49 GaitRef[18 ] IJCB2023 49.00 69.30 40.69 25.26 GaitSTR[19 ] T-BIOM2024 65.10 81.30 55.59 36.84 SMPLGait[20 ] CVPR2022 46.30 64.50 37.16 22.23 HybirdGait[21 ] AAAI2024 53.30 72.00 43.29 26.65 DFGait 本研究 70.40 85.00 61.04 41.27
实验结果表明,本研究提出的方法在各项评价指标上均显著优于其他先进的步态识别方法,验证了其在步态特征全面提取与跨模态信息融合方面的有效性. 所提出的自适应帧关节注意力模块(AFJAtt)通过在关节的空间维度与帧的时间维度进行自适应注意力分配,精准聚焦于步态序列中的重要运动关节与关键帧. 模态嵌入融合模块(MEFusion)显著增强了不同模态的语义对齐,实现了高效的跨模态信息融合. 这些模块的协同设计使DFGait在真实场景下的步态识别任务中展现出更强的鲁棒性和识别准确性. ...
SMPL: a skinned multi-person linear model
1
2015
... 为了突破单模态的局限,基于多模态的步态识别方法融合了模型和轮廓的互补优势,在实际场景中有更强的适应性. 例如,基于骨骼与轮廓的多模态方法[16 -19 ] ,通过结合骨骼的结构信息和轮廓的外观信息提升识别效果. 最近的研究中,Zheng等[20 -21 ] 在工作中引入蒙皮多人线性(skinned multi-person linear, SMPL)模型[22 ] ,来代替传统的骨骼模型. SMPL模型能提供精确的关节姿态和形状参数,弥补了骨骼在外观表达上的不足,使得基于SMPL模型和轮廓的多模态方法不仅保留了模型在结构信息表达上的优势,还显著增强了对人体姿态与形状变化的适应性. 然而,尽管模型与轮廓2个模态的相互补充提供了更丰富的表征能力,但目前的多模态步态识别方法仍然存在一定的不足. ...
1
... 步态识别是通过分析个体行走姿态特征实现身份识别的技术. 随着深度学习技术的快速发展,步态识别技术取得了显著进步,其研究方法已从早期的传统特征提取方法逐步演变为基于深度学习的从输入数据中直接学习步态特征进行识别. 与此同时,研究场景也逐渐从受限的室内环境如CASIA-B数据集[23 ] 和OU-MVLP数据集[24 ] 扩展至更有挑战性的开放式真实场景如Gait3D数据集[20 ] 和GREW数据集[25 ] ,进一步推动了步态识别技术的实用化进程. 当前的步态识别方法大致可归纳为2类:基于单模态的方法和基于多模态的方法. ...
Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition
1
2018
... 步态识别是通过分析个体行走姿态特征实现身份识别的技术. 随着深度学习技术的快速发展,步态识别技术取得了显著进步,其研究方法已从早期的传统特征提取方法逐步演变为基于深度学习的从输入数据中直接学习步态特征进行识别. 与此同时,研究场景也逐渐从受限的室内环境如CASIA-B数据集[23 ] 和OU-MVLP数据集[24 ] 扩展至更有挑战性的开放式真实场景如Gait3D数据集[20 ] 和GREW数据集[25 ] ,进一步推动了步态识别技术的实用化进程. 当前的步态识别方法大致可归纳为2类:基于单模态的方法和基于多模态的方法. ...
1
... 步态识别是通过分析个体行走姿态特征实现身份识别的技术. 随着深度学习技术的快速发展,步态识别技术取得了显著进步,其研究方法已从早期的传统特征提取方法逐步演变为基于深度学习的从输入数据中直接学习步态特征进行识别. 与此同时,研究场景也逐渐从受限的室内环境如CASIA-B数据集[23 ] 和OU-MVLP数据集[24 ] 扩展至更有挑战性的开放式真实场景如Gait3D数据集[20 ] 和GREW数据集[25 ] ,进一步推动了步态识别技术的实用化进程. 当前的步态识别方法大致可归纳为2类:基于单模态的方法和基于多模态的方法. ...
1
... 基于模型的方法通过预定义的二维或三维人体模型提取步态特征,比如,二维骨骼、三维骨骼、SMPL模型,建模肢体长度、关节角度和部位相对位置等运动学参数. 通过提取人体运动中的关键点和姿态变化,实现对步态的分析和识别. 如Liao等[12 ] 通过结合三维骨骼与先验知识提高识别精度. Zhang等[15 ] 提出组合空间转换器和时间卷积网络的模型来进行基于骨骼的步态识别. 随着图卷积神经网络(graph convolutional networks, GCN)[26 ] 在动作识别领域的广泛使用,GCN逐渐被引入步态识别领域,Teepe等[13 ] 首次将骨骼姿势与GCN相结合,通过构建骨骼关节点之间的图结构以及关节点在时间上的变化进行有效的时空建模. Fu等[14 ] 提出部分感知图卷积网络,通过分区掩码进行图分割以提取局部和全局的空间特征关系. 基于模型的步态识别方法关注关节位置这类结构特征,因此能够有效克服外观变化带来的干扰,提供更稳定的特征. 然而其结构化的表征方式难以捕捉个体在体型轮廓上的外观差异,当不同个体具有相似运动模式时,仅依赖关节位置信息难以准确区分. ...
1
... 基于轮廓的方法直接从背景减除后的二进制轮廓图中学习步态特征. 比如Chao等[5 ] 将步态的轮廓帧视为无序集合作为输入,避免受帧排列的影响. Fan等[6 ] 提出焦点卷积层来增强部分级空间特征的细粒度学习,并加入微动作捕捉模块以提取短期时间特征. Huang等[7 ] 提出三维局部卷积,自适应地对每个身体部位进行三维局部体积的时空特征提取. Wang等[11 ] 提出动态增强模块,从二值轮廓中分离出动态特征,建立人体动态部位的时空表示. Li等[27 ] 提出基于卷积-Transformer的混合框架来改进步态的时空表示. 与基于模型的方法相比,基于轮廓的步态识别方法更简单高效,对图像的分辨率要求不高,计算成本较低,因此在步态识别领域占主导地位. 但这种方法对外观变化高度敏感,且因依赖外部形状,在行走过程中身体重叠时会丢失人体内部结构信息,从而限制了其在复杂场景中的应用. ...
1
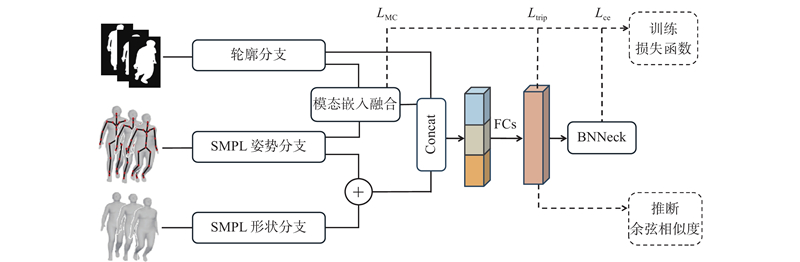
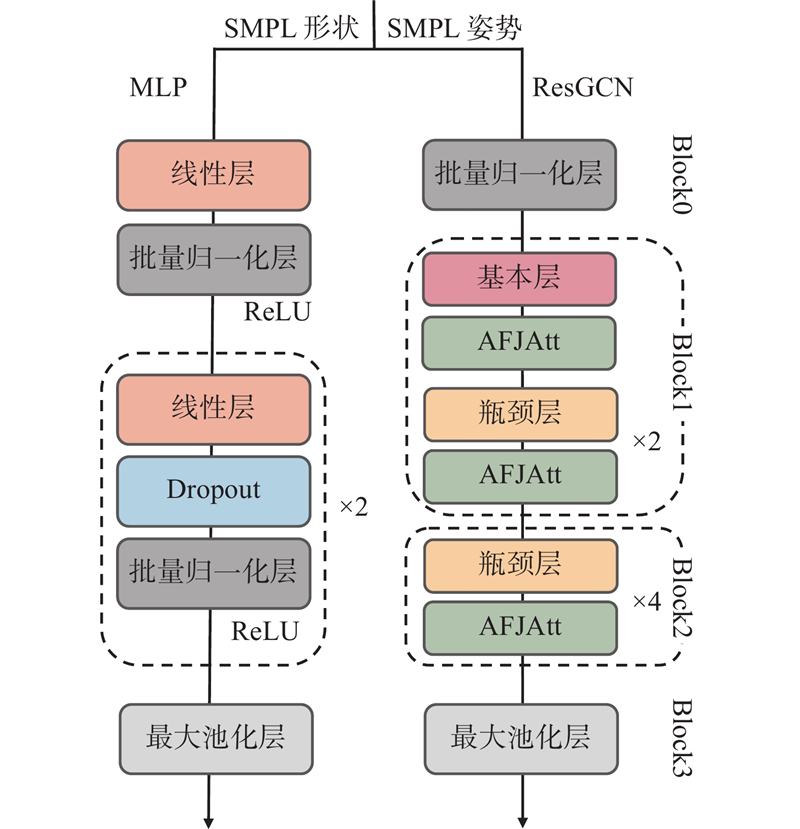
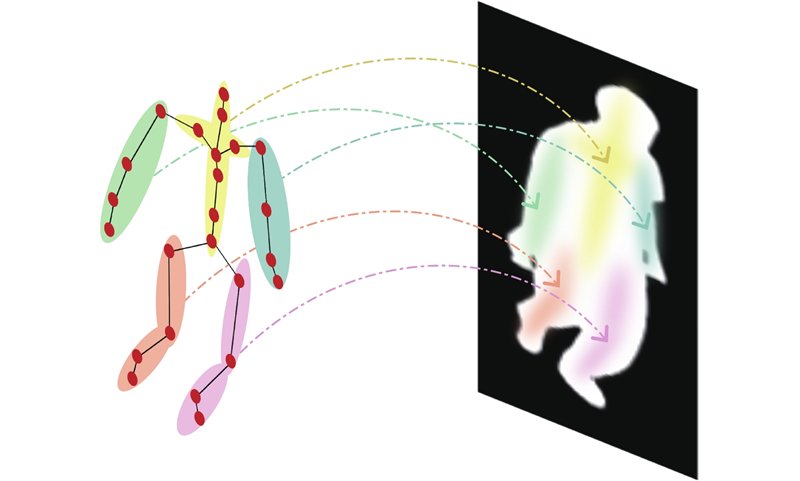
... 为了充分挖掘SMPL人体模型包含的形状和姿势信息,设计了双分支处理结构,如图3 所示. 其中,SMPL姿势分支采用ResGCN网络[28 ] 提取人体的动态运动姿势特征,通过图卷积操作建模关节间的时空依赖关系;SMPL形状分支则基于多层感知机(multilayer perceptron, MLP)网络,专注于提取表征人体体型、肢体比例的静态形状特征. 这种基于SMPL模态分解的双分支设计实现了运动特征和形状特征的独立提取与优化,既保留了SMPL模型在人体结构表征方面的优势,又增强了对个体形态差异的辨识能力. ...
1
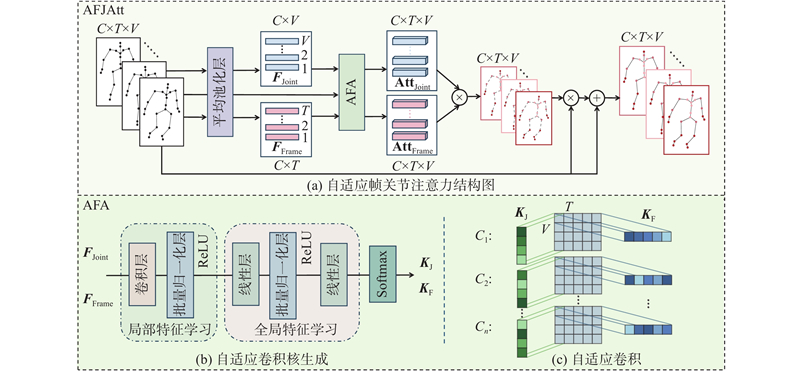
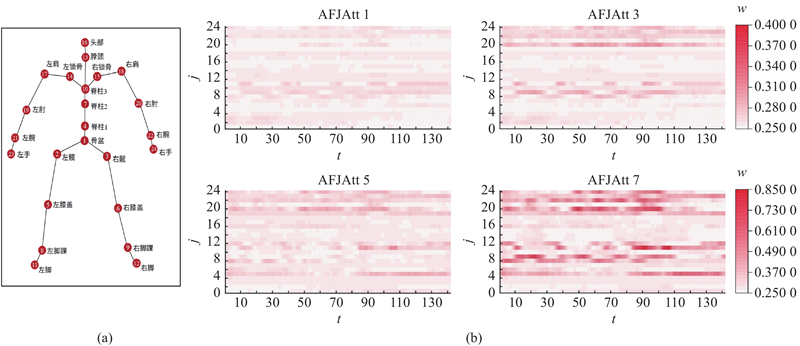
... 经过自适应特征聚合(adaptive feature aggregation, AFA)模块,包含自适应卷积核的生成(见图4 (b)),以及自适应卷积过程(见图4 (c)). 受视频识别中Liu等[29 ] 提出的时间自适应思想的启发,本研究将其自适应机制扩展到帧和关节的时空维度. 该模块通过帧自适应分支捕获时序中的关键特征,关节自适应分支捕获重要关节特征,从而自适应地提取时空信息. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}