[1]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[2]
LI W, ZHAO D, YUAN B, et al PETDet: proposal enhancement for two-stage fine-grained object detection
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 62 : 5602214
[3]
LI H, SHI F A DETR-like detector-based semi-supervised object detection method for Brassica Chinensis growth monitoring
[J]. Computers and Electronics in Agriculture , 2024 , 219 : 108788
DOI:10.1016/j.compag.2024.108788
[本文引用: 1]
[4]
HOU X, LIU M, ZHANG S, et al. Relation DETR: exploring explicit position relation prior for object detection [C]// Proceedings of the European Conference on Computer Vision . Milan: Springer, 2024: 89–105.
[本文引用: 1]
[5]
ZHAO Y, LV W, XU S, et al. DETRs beat YOLOs on real-time object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 16965–16974.
[6]
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with Transformers [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 213–229.
[本文引用: 2]
[7]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2999–3007.
[本文引用: 6]
[8]
TIAN Z, SHEN C, CHEN H, et al. FCOS: fully convolutional one-stage object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9626–9635.
[本文引用: 2]
[9]
DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6568–6577.
[本文引用: 2]
[10]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3–19.
[本文引用: 2]
[11]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 936–944.
[本文引用: 1]
[12]
CHEN F, ZHANG H, HU K, et al. Enhanced training of query-based object detection via selective query recollection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 23756–23765.
[本文引用: 2]
[13]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018−04−08) [2024−10−07]. https://arxiv.org/abs/1804.02767.
[本文引用: 1]
[14]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020−04-23) [2024−10−07]. https://arxiv.org/abs/2004.10934.
[本文引用: 1]
[15]
TIAN Z, CHU X, WANG X, et al. Fully convolutional one-stage 3D object detection on LiDAR range images [EB/OL]. (2022−09−20) [2024−10−07]. https://arxiv.org/abs/2205.13764.
[本文引用: 1]
[16]
GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021 [EB/OL]. (2021−08−06) [2024−10−07]. https://arxiv.org/abs/2107.08430.
[本文引用: 2]
[17]
WU Y, CHEN Y, YUAN L, et al. Rethinking classification and localization for object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10183–10192.
[本文引用: 1]
[18]
DAI X, CHEN Y, XIAO B, et al. Dynamic head: unifying object detection heads with attentions [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 7369–7378.
[本文引用: 1]
[19]
LIANG J, SONG G, LENG B, et al. Unifying visual perception by dispersible points learning [C]// Proceedings of the European Conference on Computer Vision . Tel Aviv: Springer, 2022: 439–456.
[本文引用: 1]
[20]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
[本文引用: 1]
[21]
DING X, ZHANG X, HAN J, et al. Scaling up your kernels to 31×31: revisiting large kernel design in CNNs [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11953–11965.
[本文引用: 2]
[22]
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 9992–10002.
[本文引用: 2]
[23]
ZHOU H, YANG R, ZHANG Y, et al UniHead: unifying multi-perception for detection heads
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2025 , 36 (5 ): 9565 - 9576
[本文引用: 2]
[24]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: Curran Associates Inc, 2017: 6000–6010.
[本文引用: 2]
[25]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the European Conference on Computer Vision . Zurich: Springer, 2014: 740–755.
[本文引用: 1]
[26]
EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al The pascal visual object classes (VOC) challenge
[J]. International Journal of Computer Vision , 2010 , 88 (2 ): 303 - 338
DOI:10.1007/s11263-009-0275-4
[本文引用: 1]
[27]
CHEN K, WANG J, PANG J, et al. MMDetection: open MMLab detection toolbox and benchmark. [EB/OL]. (2019−06−17) [2024−10−07]. https://arxiv.org/abs/1906.07155.
[本文引用: 1]
[28]
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 248–255.
[本文引用: 1]
[29]
ZHANG S, CHI C, YAO Y, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9756–9765.
[本文引用: 2]
[30]
KIM K, LEE H S. Probabilistic anchor assignment with IoU prediction for object detection [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 355–371.
[本文引用: 1]
[31]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 2]
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
PETDet: proposal enhancement for two-stage fine-grained object detection
0
2023
A DETR-like detector-based semi-supervised object detection method for Brassica Chinensis growth monitoring
1
2024
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
1
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
2
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... [6 -7 ],改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
6
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... -7 ],改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... [7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... 为了证明MdfHead的有效性,将其插入经典的目标检测器中,包括RetinaNet[7 ] 、FCOS[8 ] 、CenterNet[9 ] 、ATSS[29 ] 和PAA[30 ] . 这些被选择评估的检测器代表了多种主流目标检测框架,包括基于锚框、无锚框、基于锚点与强基线的方法. 实验结果如表1 所示,其中baseline表示使用原始检测头(平行检测头)的方法. MdfHead在略微增加模型参数量与计算量的情况下,提升了所有检测器的性能. 例如,在RetinaNet[7 ] 上AP值实现了2.9个百分点的提升,在ATSS[29 ] 上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
... [7 ]上AP值实现了2.9个百分点的提升,在ATSS[29 ] 上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
... 采用以ResNet-101[31 ] 为主干网络的RetinaNet[7 ] 作为整个消融实验的基准网络,共训练12个轮次,以证明MdfHead中每个模块的有效性. ...
2
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... 为了证明MdfHead的有效性,将其插入经典的目标检测器中,包括RetinaNet[7 ] 、FCOS[8 ] 、CenterNet[9 ] 、ATSS[29 ] 和PAA[30 ] . 这些被选择评估的检测器代表了多种主流目标检测框架,包括基于锚框、无锚框、基于锚点与强基线的方法. 实验结果如表1 所示,其中baseline表示使用原始检测头(平行检测头)的方法. MdfHead在略微增加模型参数量与计算量的情况下,提升了所有检测器的性能. 例如,在RetinaNet[7 ] 上AP值实现了2.9个百分点的提升,在ATSS[29 ] 上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
2
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... 为了证明MdfHead的有效性,将其插入经典的目标检测器中,包括RetinaNet[7 ] 、FCOS[8 ] 、CenterNet[9 ] 、ATSS[29 ] 和PAA[30 ] . 这些被选择评估的检测器代表了多种主流目标检测框架,包括基于锚框、无锚框、基于锚点与强基线的方法. 实验结果如表1 所示,其中baseline表示使用原始检测头(平行检测头)的方法. MdfHead在略微增加模型参数量与计算量的情况下,提升了所有检测器的性能. 例如,在RetinaNet[7 ] 上AP值实现了2.9个百分点的提升,在ATSS[29 ] 上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
2
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... 注意力机制对于提升模型性能至关重要. 在基于卷积注意力的机制中,挤压激励注意力网络[20 ] 通过缩放每个通道来增强显著特征并抑制不相关的特征. 卷积块注意力模块[10 ] 结合通道注意力和空间注意力,在保持通道维度的同时压缩空间维度以实现通道注意力机制,并且利用卷积操作为特征图的空间维度生成注意力权重,从而引导模型在通道和空间上都关注关键区域. RepLKNet[21 ] 使用超大卷积核来捕获特征图的宽区域信息,常用于增强显著特征或捕获局部/全局信息. 基于Transformer的注意力机制的核心是多头自注意力及其变体,目前对于多头自注意力的研究更多地聚焦于2个方向:降低复杂度,或者提出新型多头注意力模块以优化信息捕获模式(如基于窗口的多头自注意力[22 ] 和交叉注意力[23 ] ). 然而,单一注意力的重复使用容易导致特征信息单调化. ...
1
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
2
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
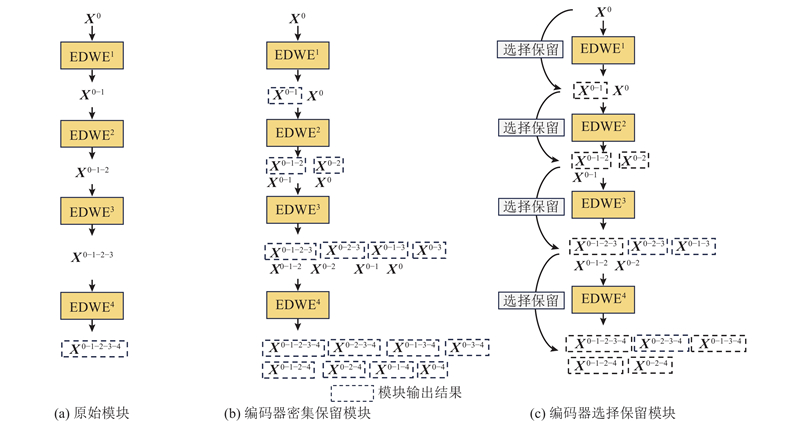
... 值得注意的是,若将Transformer架构[24 ] 及其注意力机制直接应用于检测头,虽然能够捕获全局信息,但是会带来新的挑战. 1)过度强调全局信息:在网络学习的后期,普通注意力机制对于全局信息过度重视,容易丢失图片的局部纹理信息;普通注意力机制的计算量过大,会带来整体网络参数的大量增加. 2)特征空间不匹配:检测头的输入特征图通常来自深层主干网络,更倾向于强调局部纹理信息,而Transformer架构强调全局信息. 当直接使用编码器结构替代检测头中的卷积方法时,特征空间的显著差异会导致网络性能下降. 3)在较小数据集上难以拟合:Transformer的核心是注意力机制,需要计算每个查询向量与所有键-值向量之间的相似性,导致二次计算复杂性. 在较小数据集上训练时,由于样本数量有限,网络可能无法充分学习到有效的注意力模式,从而难以收敛,最终影响检测性能. 4)堆叠编码器的错误传播问题:堆叠多个编码器可能会导致在前中期编码阶段预测正确,而在最终编码阶段出现错误预测[12 ] . ...
1
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
1
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
1
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
2
... 在计算机视觉领域,目标检测是重要的研究方向,其目标是在图像中精确定位和识别感兴趣的对象. 目标检测器主要分为3种类型:两阶段检测器[1 -3 ] 、单阶段检测器和Transformer检测器(如DETR)[4 -6 ] . 单阶段检测器可以被进一步细分为基于锚点的检测器[7 ] 和无锚点的检测器[8 -9 ] ,区别在于是否预定义大量锚点框. 对于目标检测的优化,主要包括设计创新性主干网络[6 -7 ] ,改进特征提取方法[10 -11 ] ,以及优化训练策略[12 ] 等技术. 这些发展极大地丰富了目标检测领域. 此外,高性能目标检测器的实现通常依赖于优秀的检测头,后者负责在检测器的最后阶段处理由主干网络提取的特征图,进行对象定位与分类. 检测头主要分为耦合检测头[13 -14 ] 和平行检测头[7 ,15 -16 ] 2种形式. 耦合检测头通过一系列堆叠的卷积层处理输入的特征图,随后通过全连接层同时产生分类和目标框回归结果. 平行检测头为分类和回归任务建立2条不同的检测分支,2条分支通常共享相同的特征图输入,每个分支通过各自的堆叠卷积层处理这些输入,再通过各自的全连接层分别产生分类和目标框回归结果. 由于分类和回归任务之间存在特征空间差异,平行检测头在检测器中应用更为普遍[16 ] . ...
... [16 ]. ...
1
... 当前研究对检测头潜力的挖掘仍显不足. 标准的平行头设计依赖于卷积层的堆叠,存在全局信息捕获能力欠缺的问题. Wu等[17 ] 提出Double Head,强调全连接层表现出更强的空间敏感性,更适合分类任务,而卷积层具有更强的空间相关性,更适合定位任务. 然而,该检测头仍未解决全局信息捕获能力不足的问题. Dynamic Head[18 ] 通过集成尺度感知、空间感知和任务感知3个感知维度,构建插件模块以提升现有框架的性能,但是其泛化能力仍然受限,尤其在适应不同规模的数据集时局限性更为明显. UniHead[19 ] 将Transformer编码器架构整合到多个视觉下游任务的检测头中,采用点分散学习来统一视觉感知,但是面临着特征信息过于单一、在最终编码阶段预测错误的问题,且较大的计算成本限制了其实用性. ...
1
... 当前研究对检测头潜力的挖掘仍显不足. 标准的平行头设计依赖于卷积层的堆叠,存在全局信息捕获能力欠缺的问题. Wu等[17 ] 提出Double Head,强调全连接层表现出更强的空间敏感性,更适合分类任务,而卷积层具有更强的空间相关性,更适合定位任务. 然而,该检测头仍未解决全局信息捕获能力不足的问题. Dynamic Head[18 ] 通过集成尺度感知、空间感知和任务感知3个感知维度,构建插件模块以提升现有框架的性能,但是其泛化能力仍然受限,尤其在适应不同规模的数据集时局限性更为明显. UniHead[19 ] 将Transformer编码器架构整合到多个视觉下游任务的检测头中,采用点分散学习来统一视觉感知,但是面临着特征信息过于单一、在最终编码阶段预测错误的问题,且较大的计算成本限制了其实用性. ...
1
... 当前研究对检测头潜力的挖掘仍显不足. 标准的平行头设计依赖于卷积层的堆叠,存在全局信息捕获能力欠缺的问题. Wu等[17 ] 提出Double Head,强调全连接层表现出更强的空间敏感性,更适合分类任务,而卷积层具有更强的空间相关性,更适合定位任务. 然而,该检测头仍未解决全局信息捕获能力不足的问题. Dynamic Head[18 ] 通过集成尺度感知、空间感知和任务感知3个感知维度,构建插件模块以提升现有框架的性能,但是其泛化能力仍然受限,尤其在适应不同规模的数据集时局限性更为明显. UniHead[19 ] 将Transformer编码器架构整合到多个视觉下游任务的检测头中,采用点分散学习来统一视觉感知,但是面临着特征信息过于单一、在最终编码阶段预测错误的问题,且较大的计算成本限制了其实用性. ...
1
... 注意力机制对于提升模型性能至关重要. 在基于卷积注意力的机制中,挤压激励注意力网络[20 ] 通过缩放每个通道来增强显著特征并抑制不相关的特征. 卷积块注意力模块[10 ] 结合通道注意力和空间注意力,在保持通道维度的同时压缩空间维度以实现通道注意力机制,并且利用卷积操作为特征图的空间维度生成注意力权重,从而引导模型在通道和空间上都关注关键区域. RepLKNet[21 ] 使用超大卷积核来捕获特征图的宽区域信息,常用于增强显著特征或捕获局部/全局信息. 基于Transformer的注意力机制的核心是多头自注意力及其变体,目前对于多头自注意力的研究更多地聚焦于2个方向:降低复杂度,或者提出新型多头注意力模块以优化信息捕获模式(如基于窗口的多头自注意力[22 ] 和交叉注意力[23 ] ). 然而,单一注意力的重复使用容易导致特征信息单调化. ...
2
... 注意力机制对于提升模型性能至关重要. 在基于卷积注意力的机制中,挤压激励注意力网络[20 ] 通过缩放每个通道来增强显著特征并抑制不相关的特征. 卷积块注意力模块[10 ] 结合通道注意力和空间注意力,在保持通道维度的同时压缩空间维度以实现通道注意力机制,并且利用卷积操作为特征图的空间维度生成注意力权重,从而引导模型在通道和空间上都关注关键区域. RepLKNet[21 ] 使用超大卷积核来捕获特征图的宽区域信息,常用于增强显著特征或捕获局部/全局信息. 基于Transformer的注意力机制的核心是多头自注意力及其变体,目前对于多头自注意力的研究更多地聚焦于2个方向:降低复杂度,或者提出新型多头注意力模块以优化信息捕获模式(如基于窗口的多头自注意力[22 ] 和交叉注意力[23 ] ). 然而,单一注意力的重复使用容易导致特征信息单调化. ...
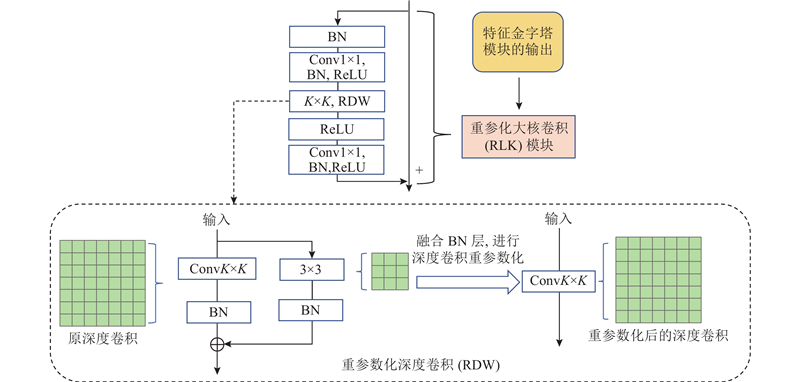
... RLK模块使用了残差连接和大核深度卷积,并使用1×1卷积调整深度卷积前后的通道数. 在大核深度卷积之前,通过1×1卷积增加维度,以防止因特征图数量有限而导致信息丢失. 经过大核深度卷积后,使用另一个1×1卷积将维度恢复到原始大小[24 ] . 此外,在每个大核深度卷积中,引入重参数化深度(reparameterized depthwise,RDW)卷积[21 ] ,通过构建并行的$ 3\times 3 $ $ 3\times 3 $ $ 3\times 3 $ $ 3\times 3 $
2
... 注意力机制对于提升模型性能至关重要. 在基于卷积注意力的机制中,挤压激励注意力网络[20 ] 通过缩放每个通道来增强显著特征并抑制不相关的特征. 卷积块注意力模块[10 ] 结合通道注意力和空间注意力,在保持通道维度的同时压缩空间维度以实现通道注意力机制,并且利用卷积操作为特征图的空间维度生成注意力权重,从而引导模型在通道和空间上都关注关键区域. RepLKNet[21 ] 使用超大卷积核来捕获特征图的宽区域信息,常用于增强显著特征或捕获局部/全局信息. 基于Transformer的注意力机制的核心是多头自注意力及其变体,目前对于多头自注意力的研究更多地聚焦于2个方向:降低复杂度,或者提出新型多头注意力模块以优化信息捕获模式(如基于窗口的多头自注意力[22 ] 和交叉注意力[23 ] ). 然而,单一注意力的重复使用容易导致特征信息单调化. ...
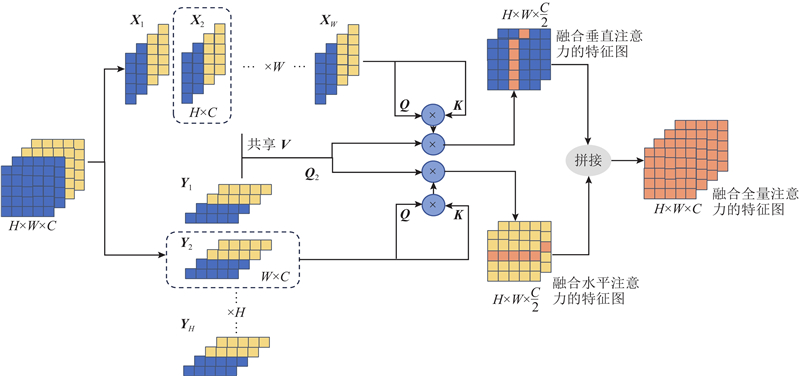
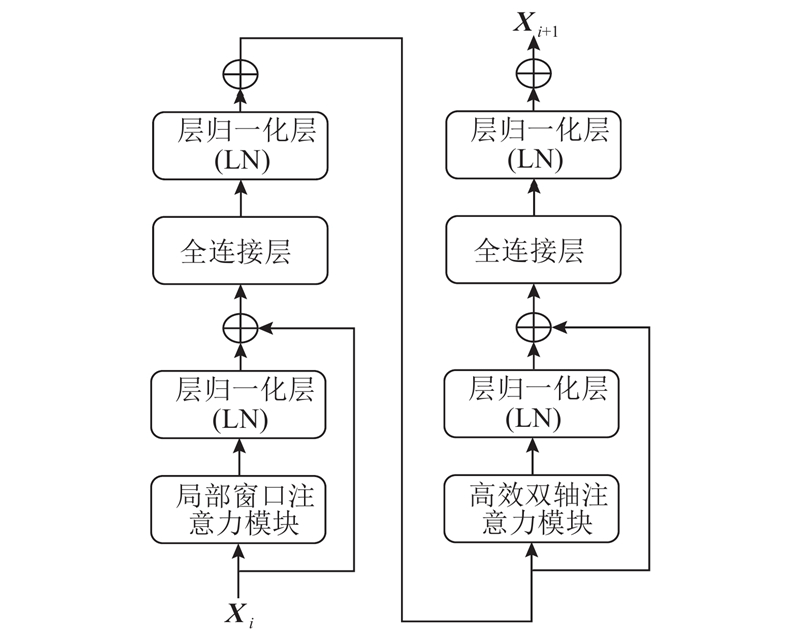
... EDWE模块可以分为2部分:高效双轴注意力(efficient dual-axial attention, EDA)模块[23 ] 和基于窗口的多头自注意力(window-based multi-head self attention, W-MSA)模块[22 ] . 如图2 所示,EDA模块同时使用水平轴向和垂直轴向注意力来模拟长期依赖关系. 对于水平轴向注意力,输入特征图$ {{\boldsymbol{X}}}\in {\mathbf{R}}^{H\times W\times C} $ $ H $ $ W $ . 假设$ {{{\boldsymbol{X}}}}_{i}\in {\mathbf{R}}^{W\times C} $ $ i $
UniHead: unifying multi-perception for detection heads
2
2025
... 注意力机制对于提升模型性能至关重要. 在基于卷积注意力的机制中,挤压激励注意力网络[20 ] 通过缩放每个通道来增强显著特征并抑制不相关的特征. 卷积块注意力模块[10 ] 结合通道注意力和空间注意力,在保持通道维度的同时压缩空间维度以实现通道注意力机制,并且利用卷积操作为特征图的空间维度生成注意力权重,从而引导模型在通道和空间上都关注关键区域. RepLKNet[21 ] 使用超大卷积核来捕获特征图的宽区域信息,常用于增强显著特征或捕获局部/全局信息. 基于Transformer的注意力机制的核心是多头自注意力及其变体,目前对于多头自注意力的研究更多地聚焦于2个方向:降低复杂度,或者提出新型多头注意力模块以优化信息捕获模式(如基于窗口的多头自注意力[22 ] 和交叉注意力[23 ] ). 然而,单一注意力的重复使用容易导致特征信息单调化. ...
... EDWE模块可以分为2部分:高效双轴注意力(efficient dual-axial attention, EDA)模块[23 ] 和基于窗口的多头自注意力(window-based multi-head self attention, W-MSA)模块[22 ] . 如图2 所示,EDA模块同时使用水平轴向和垂直轴向注意力来模拟长期依赖关系. 对于水平轴向注意力,输入特征图$ {{\boldsymbol{X}}}\in {\mathbf{R}}^{H\times W\times C} $ $ H $ $ W $ . 假设$ {{{\boldsymbol{X}}}}_{i}\in {\mathbf{R}}^{W\times C} $ $ i $
2
... 值得注意的是,若将Transformer架构[24 ] 及其注意力机制直接应用于检测头,虽然能够捕获全局信息,但是会带来新的挑战. 1)过度强调全局信息:在网络学习的后期,普通注意力机制对于全局信息过度重视,容易丢失图片的局部纹理信息;普通注意力机制的计算量过大,会带来整体网络参数的大量增加. 2)特征空间不匹配:检测头的输入特征图通常来自深层主干网络,更倾向于强调局部纹理信息,而Transformer架构强调全局信息. 当直接使用编码器结构替代检测头中的卷积方法时,特征空间的显著差异会导致网络性能下降. 3)在较小数据集上难以拟合:Transformer的核心是注意力机制,需要计算每个查询向量与所有键-值向量之间的相似性,导致二次计算复杂性. 在较小数据集上训练时,由于样本数量有限,网络可能无法充分学习到有效的注意力模式,从而难以收敛,最终影响检测性能. 4)堆叠编码器的错误传播问题:堆叠多个编码器可能会导致在前中期编码阶段预测正确,而在最终编码阶段出现错误预测[12 ] . ...
... RLK模块使用了残差连接和大核深度卷积,并使用1×1卷积调整深度卷积前后的通道数. 在大核深度卷积之前,通过1×1卷积增加维度,以防止因特征图数量有限而导致信息丢失. 经过大核深度卷积后,使用另一个1×1卷积将维度恢复到原始大小[24 ] . 此外,在每个大核深度卷积中,引入重参数化深度(reparameterized depthwise,RDW)卷积[21 ] ,通过构建并行的$ 3\times 3 $ $ 3\times 3 $ $ 3\times 3 $ $ 3\times 3 $
1
... 采用MS-COCO2017数据集[25 ] 与多种主干网络进行实验,以证明MdfHead的整体有效性. 此外,在较小的公共数据集Pascal VOC2007[26 ] 上进行实验,以强调RLK模块在整个方法中的重要性. MS-COCO2017数据集包含80个目标类别,大约有164 000张图像,其中约有118 000张用于训练,5 000张用于验证,41 000张用于测试. Pascal VOC2007数据集包括20个目标类别,总共有9 963张图片,其中5 011张用于训练和验证,4 952张用于测试. 对于MS-COCO2017数据集,在train2017子集上训练模型,在val2017子集上评估网络性能并进行消融实验. 使用平均精度(AP)来衡量检测性能,并使用模型参数量(N p )和每秒浮点运算次数(FLOPs)来评估模型效率. 对于Pascal VOC2007数据集,在trainval子集上训练模型,在测试子集上评估网络性能,并使用平均精度均值(mAP)作为性能指标. ...
The pascal visual object classes (VOC) challenge
1
2010
... 采用MS-COCO2017数据集[25 ] 与多种主干网络进行实验,以证明MdfHead的整体有效性. 此外,在较小的公共数据集Pascal VOC2007[26 ] 上进行实验,以强调RLK模块在整个方法中的重要性. MS-COCO2017数据集包含80个目标类别,大约有164 000张图像,其中约有118 000张用于训练,5 000张用于验证,41 000张用于测试. Pascal VOC2007数据集包括20个目标类别,总共有9 963张图片,其中5 011张用于训练和验证,4 952张用于测试. 对于MS-COCO2017数据集,在train2017子集上训练模型,在val2017子集上评估网络性能并进行消融实验. 使用平均精度(AP)来衡量检测性能,并使用模型参数量(N p )和每秒浮点运算次数(FLOPs)来评估模型效率. 对于Pascal VOC2007数据集,在trainval子集上训练模型,在测试子集上评估网络性能,并使用平均精度均值(mAP)作为性能指标. ...
1
... 采用MMDetection[27 ] 作为检测平台,以此为基础部署MdfHead,替代经典检测器中默认的平行头,并对MdfHead与默认的平行头进行比较. 在所有实验中,采用在ImageNet数据集[28 ] 上预训练的模型作为主干网络. 在训练过程中,分辨率设置为MMDetection中的默认大小;采用AdamW作为优化器,初始学习率为0.0001 ,权重衰减率为0.2. 遵循MMDetection中的默认训练策略,在第9、12个epoch中将学习率降低10倍. 在数据增强方面,仅使用水平翻转方式. 除非另有说明,所有实验均使用4个EDWE模块,从第1个EDWE阶段开始使用ESM. 默认数据集为MS-COCO2017. 所有实验均在2个内存为24 GB的3090 GPU上进行. ...
1
... 采用MMDetection[27 ] 作为检测平台,以此为基础部署MdfHead,替代经典检测器中默认的平行头,并对MdfHead与默认的平行头进行比较. 在所有实验中,采用在ImageNet数据集[28 ] 上预训练的模型作为主干网络. 在训练过程中,分辨率设置为MMDetection中的默认大小;采用AdamW作为优化器,初始学习率为0.0001 ,权重衰减率为0.2. 遵循MMDetection中的默认训练策略,在第9、12个epoch中将学习率降低10倍. 在数据增强方面,仅使用水平翻转方式. 除非另有说明,所有实验均使用4个EDWE模块,从第1个EDWE阶段开始使用ESM. 默认数据集为MS-COCO2017. 所有实验均在2个内存为24 GB的3090 GPU上进行. ...
2
... 为了证明MdfHead的有效性,将其插入经典的目标检测器中,包括RetinaNet[7 ] 、FCOS[8 ] 、CenterNet[9 ] 、ATSS[29 ] 和PAA[30 ] . 这些被选择评估的检测器代表了多种主流目标检测框架,包括基于锚框、无锚框、基于锚点与强基线的方法. 实验结果如表1 所示,其中baseline表示使用原始检测头(平行检测头)的方法. MdfHead在略微增加模型参数量与计算量的情况下,提升了所有检测器的性能. 例如,在RetinaNet[7 ] 上AP值实现了2.9个百分点的提升,在ATSS[29 ] 上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
... [29 ]上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
1
... 为了证明MdfHead的有效性,将其插入经典的目标检测器中,包括RetinaNet[7 ] 、FCOS[8 ] 、CenterNet[9 ] 、ATSS[29 ] 和PAA[30 ] . 这些被选择评估的检测器代表了多种主流目标检测框架,包括基于锚框、无锚框、基于锚点与强基线的方法. 实验结果如表1 所示,其中baseline表示使用原始检测头(平行检测头)的方法. MdfHead在略微增加模型参数量与计算量的情况下,提升了所有检测器的性能. 例如,在RetinaNet[7 ] 上AP值实现了2.9个百分点的提升,在ATSS[29 ] 上实现了3.4个百分点的提升. 此外,在选择更深的主干网络的情况下,MdfHead对AP的提升效果更为明显. ...
2
... 采用以ResNet-101[31 ] 为主干网络的RetinaNet[7 ] 作为整个消融实验的基准网络,共训练12个轮次,以证明MdfHead中每个模块的有效性. ...
... 大部分与编、解码相关的方法都体现出一个特征:在数据集规模较小的情况下,网络容易出现欠拟合以及难以收敛的问题,导致精度较低. 为了验证RLK模块在此类场景下的作用,在Pascal VOC2007数据集上使用较小的主干网络ResNet-50[31 ] ,在RetinaNet、FCOS与ATSS检测器上进行实验,结果如表6 所示. 如果未使用RLK模块,MdfHead的性能显著下降,其mAP值甚至低于基线模型,这凸显了当数据有限时特征空间差异带来的负面影响;而引入RLK模块后,所有检测器的性能均得到显著提升,RetinaNet、FCOS、ATSS的mAP值分别提升了1.3、1.0、1.1个百分点. RLK模块通过减小特征空间差异,有效增强了网络对较小数据集的适应性,为EDWE模块与ESM在数据有限条件下的稳定工作提供了关键支持. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}