[1]
李修文, 曾承志, 杨荣华, 等 轨道故障引发的轮轨冲击特征研究
[J]. 城市轨道交通研究 , 2022 , 25 (1 ): 122 - 126
[本文引用: 1]
LI Xiuwen, ZENG Chengzhi, YANG Ronghua, et al Research on the characteristics of wheel rail impact caused by rail fault
[J]. Urban Mass Transit , 2022 , 25 (1 ): 122 - 126
[本文引用: 1]
[2]
侯学良, 单腾飞, 薛靖国 深度学习的目标检测典型算法及其应用现状分析
[J]. 国外电子测量技术 , 2022 , 41 (6 ): 165 - 174
[本文引用: 1]
HOU Xueliang, SHAN Tengfei, XUE Jingguo Analysis of typical target detection algorithm based on deep learning and its application status
[J]. Foreign Electronic Measurement Technology , 2022 , 41 (6 ): 165 - 174
[本文引用: 1]
[4]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580–587.
[本文引用: 1]
[5]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[6]
LIU W, DRAGOMIR A, DUMITRU E, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . Cham: Springer, 2016: 21–37.
[本文引用: 1]
[7]
薛雅丽, 贺怡铭, 崔闪, 等 基于改进YOLOv5的SAR图像有向舰船目标检测算法
[J]. 浙江大学学报: 工学版 , 2025 , 59 (2 ): 261 - 268
[本文引用: 1]
XUE Yali, HE Yiming, CUI Shan, et al Oriented ship detection algorithm in SAR image based on improved YOLOv5
[J]. Journal of Zhejiang University: Engineering Science , 2025 , 59 (2 ): 261 - 268
[本文引用: 1]
[8]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[9]
李鑫, 李香蓉, 汪诚, 等 基于改进YOLOv5的航空发动机表面缺陷检测模型
[J]. 激光与光电子学进展 , 2023 , 60 (16 ): 304 - 313
[本文引用: 1]
LI Xin, LI Xiangrong, WANG Cheng, et al Aero-engine surface defect detection model based on improved YOLOv5
[J]. Laser & Optoelectronics Progress , 2023 , 60 (16 ): 304 - 313
[本文引用: 1]
[10]
汪沛洁, 谌雨章, 王诗琦, 等 基于改进YOLOv5的鱼群小目标检测优化算法
[J]. 湖北大学学报: 自然科学版 , 2024 , 46 (1 ): 14 - 24
[本文引用: 1]
WANG Peijie, CHEN Yuzhang, WANG Shiqi, et al Optimization algorithm of fish shoal small target detection based on improved YOLOv5
[J]. Journal of Hubei University: Natural Science , 2024 , 46 (1 ): 14 - 24
[本文引用: 1]
[11]
王宏志, 宋明轩, 程超, 等 基于改进 YOLOv5 算法的道路目标检测方法
[J]. 吉林大学学报: 工学版 , 2024 , (9 ): 2658 - 2667
[本文引用: 1]
WANG Hongzhi, SONG Mingxuan, CHENG Chao, et al Road object detection method based on improved YOLOv5 algorithm
[J]. Journal of Jilin University: Engineering and Technology Edition , 2024 , (9 ): 2658 - 2667
[本文引用: 1]
[12]
令雅莉, 杨桂芹, 张又元, 等 基于改进算法YOLOv5+的混凝土轨枕裂纹检测
[J]. 铁道标准设计 , 2024 , 68 (4 ): 70 - 77
[本文引用: 1]
LING Yali, YANG Guiqin, ZHANG Youyuan, et al Crack detection of concrete sleeper based on improved algorithm YOLOv5+
[J]. Railway Standard Design , 2024 , 68 (4 ): 70 - 77
[本文引用: 1]
[13]
王琳毅, 白静, 李文静, 等 YOLO系列目标检测算法研究进展
[J]. 计算机工程与应用 , 2023 , 59 (14 ): 15 - 29
DOI:10.3778/j.issn.1002-8331.2301-0081
[本文引用: 1]
WANG Linyi, BAI Jing, LI Wenjing, et al Research progress of YOLO series target detection algorithms
[J]. Computer Engineering and Applications , 2023 , 59 (14 ): 15 - 29
DOI:10.3778/j.issn.1002-8331.2301-0081
[本文引用: 1]
[14]
GUO S, LI L, GUO T, et al Research on mask-wearing detection algorithm based on improved YOLOv5
[J]. Sensors , 2022 , 22 (13 ): 4933
DOI:10.3390/s22134933
[本文引用: 1]
[15]
LI C, ZHOU A, YAO A. Omni-dimensional dynamic convolution [C]// International Conference on Learning Representations . Appleton: [s.n.], 2022(1181): 1–20.
[本文引用: 1]
[16]
YANG B, BENDER G, LE Q V, et al. Condconv: conditionally parameterized convolutions for efficient inference [J]. Advances in Neural Information Processing Systems , 2019, 32.
[本文引用: 1]
[17]
CHEN Y, DAI X, LIU M, et al. Dynamic convolution: attention over convolution kernels [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11030–11039.
[本文引用: 1]
[18]
LIU Z, MAO H, WU C Y, et al. A ConvNet for the 2020s [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11966–11976.
[本文引用: 1]
[19]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 9992–10002.
[本文引用: 1]
[20]
刘欢, 李云红, 张蕾涛, 等 基于MA-ConvNext网络和分步关系知识蒸馏的苹果叶片病害识别
[J]. 浙江大学学报: 工学版 , 2024 , 58 (9 ): 1757 - 1767,1780
[本文引用: 1]
LIU Huan, LI Yunhong, ZHANG Leitao, et al Identification of apple leaf diseases based on MA-ConvNext network and stepwise relational knowledge distillation
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (9 ): 1757 - 1767,1780
[本文引用: 1]
[21]
朱宏禹, 韩建宁, 徐勇 基于改进型YOLOv5s的印刷线路板瑕疵检测
[J]. 国外电子测量技术 , 2023 , 42 (3 ): 152 - 159
[本文引用: 1]
ZHU Hongyu, HAN Jianning, XU Yong Printed circuit board blemishes detection based on the improved YOLOv5s
[J]. Foreign Electronic Measurement Technology , 2023 , 42 (3 ): 152 - 159
[本文引用: 1]
[22]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10778–10787.
[本文引用: 1]
[24]
曹建斌. 基于深度学习的高速铁路混凝土轨枕裂纹检测[D]. 上海: 上海大学, 2020.
[本文引用: 1]
CAO Jianbin. Crack detection of railway concrete sleeper based on deep learning [D]. Shanghai: Shanghai University, 2020.
[本文引用: 1]
[25]
李飞, 胡坤, 张勇, 等 基于混合域注意力YOLOv4的输送带纵向撕裂多维度检测
[J]. 浙江大学学报: 工学版 , 2022 , 56 (11 ): 2156 - 2167
[本文引用: 1]
LI Fei, HU Kun, ZHANG Yong, et al Multi-dimensional detection of longitudinal tearing of conveyor belt based on YOLOv4 of hybrid domain attention
[J]. Journal of Zhejiang Universit: Engineering Science , 2022 , 56 (11 ): 2156 - 2167
[本文引用: 1]
[26]
王安静, 袁巨龙, 朱勇建, 等 基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
[J]. 浙江大学学报: 工学版 , 2024 , 58 (2 ): 370 - 380
[本文引用: 1]
WANG Anjing, YUAN Julong, ZHU Yongjian, et al Drum roller surface defect detection algorithm based on improved YOLOv8s
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (2 ): 370 - 380
[本文引用: 1]
[27]
HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1577–1586.
[本文引用: 1]
[28]
MA N, ZHANG X, ZHENG H T, et al. Shufflenet v2: practical guidelines for efficient cnn architecture design [C]// European Conference on Computer Vision . Berlin: Springer, 2018: 116–131.
[本文引用: 1]
轨道故障引发的轮轨冲击特征研究
1
2022
... 随着高铁铁轨铺设年限的增加,铁轨轨枕表面不可避免会产生裂纹,如果不及时对轨枕表面产生的裂纹进行监管处理,可能会付出高昂的维修成本,甚至造成严重的交通事故[1 ] . 为了提高铁路轨道巡检的效率以及轨枕裂纹检测的精度,有必要对现有铁路轨枕缺陷检测的先进技术进行研究. ...
轨道故障引发的轮轨冲击特征研究
1
2022
... 随着高铁铁轨铺设年限的增加,铁轨轨枕表面不可避免会产生裂纹,如果不及时对轨枕表面产生的裂纹进行监管处理,可能会付出高昂的维修成本,甚至造成严重的交通事故[1 ] . 为了提高铁路轨道巡检的效率以及轨枕裂纹检测的精度,有必要对现有铁路轨枕缺陷检测的先进技术进行研究. ...
深度学习的目标检测典型算法及其应用现状分析
1
2022
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
深度学习的目标检测典型算法及其应用现状分析
1
2022
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
An improved YOLOv8 algorithm for rail surface defect detection
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
1
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
1
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进YOLOv5的SAR图像有向舰船目标检测算法
1
2025
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进YOLOv5的SAR图像有向舰船目标检测算法
1
2025
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
1
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进YOLOv5的航空发动机表面缺陷检测模型
1
2023
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进YOLOv5的航空发动机表面缺陷检测模型
1
2023
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进YOLOv5的鱼群小目标检测优化算法
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进YOLOv5的鱼群小目标检测优化算法
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进 YOLOv5 算法的道路目标检测方法
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进 YOLOv5 算法的道路目标检测方法
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进算法YOLOv5+的混凝土轨枕裂纹检测
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
基于改进算法YOLOv5+的混凝土轨枕裂纹检测
1
2024
... 传统轨枕裂纹检测方法包括人工检测、磁粉检测、超声波检测、电涡流检测等,这些检测方式对人工技能要求过高,且成本高、检测效率低. 近年来,深度学习目标检测技术不断进步完善,这种低成本高效益的技术方法在众多工业检测领域都取得了成功的应用[2 ] . 目前,针对铁路轨枕裂纹缺陷区域的定位检测已经开展了深入研究,通常采用基于深度学习的目标检测和图像分割方法,这种自动化检测方案可减少人力与设备成本投入[3 ] . 深度学习的目标检测算法有RCNN[4 ] 、Faster-RCNN[5 ] 和FPN等双阶段检测算法和SDD[6 ] 、YOLO[7 ] 和RetinaNet等单阶段检测算法. 双阶段检测算法的识别效率难以满足实时性检测的需求,因此单阶段目标检测算法的应用更加广泛. 如今已有多项研究利用YOLO系列模型实现轨道裂纹和交通、工业、农业等行业的缺陷检测. Redmon 等[8 ] 通过在YOLO模型结构中融合残差模块、双特征金字塔、解耦头等方式,提出RDD-YOLO模型用于解决钢铁表面缺陷检测. 李鑫等[9 ] 在YOLOv5中引入坐标注意力机制、优化损失函数,实现了航空发动机表面缺陷的高效智能检测. 汪沛洁等[10 ] 通过在主干网络中添加多头自注意力机制、优化特征融合及优化计算效率等方式改进YOLOv5,弥补水环境中鱼群小目标误检、漏检的问题. 王宏志等[11 ] 在YOLOv5中增加小目标检测层、解耦检测头、注意力机制与特征增强等方式增强对复杂道路目标检测的能力. 令雅莉等[12 ] 在YOLOv5主干网络中引入SE注意力模块,同时改进SPP池化模块和特征融合结构,有效降低了轨枕裂纹的漏检情况,但对细小裂纹的识别效果还有较大的提升空间. ...
YOLO系列目标检测算法研究进展
1
2023
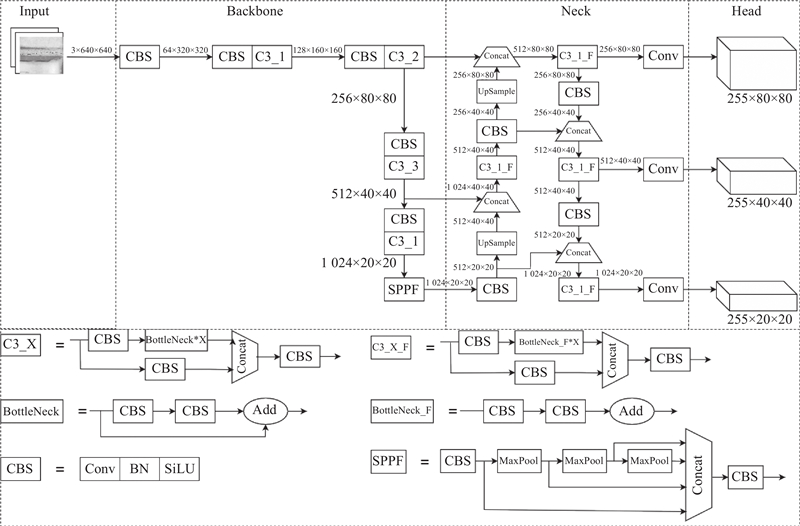
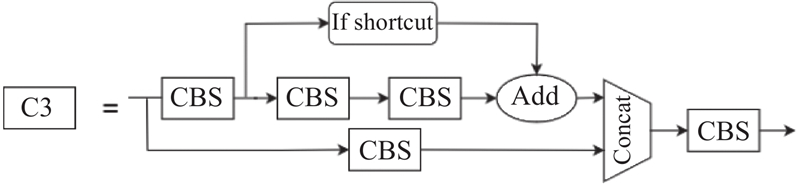
... 随着近些年YOLO系列算法的更新换代,其检测准确性和检测速度逐渐提升[13 ] ,2020年已演变为YOLOv5,成为目前最流行的目标检测算法之一[14 ] . YOLOv5模型不断更新, 根据不同的工业需求发展出YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x等版本,其中YOLOv5s模型参数量最少、检测速度最快,更适合于轨枕裂纹检测的研究,因此本研究以YOLOv5的6.0版本中的YOLOv5s模型为基础,其网络结构如图1 所示. YOLOv5s模型由输入端、主干网络、特征融合网络和输出端4部分构成,6.0版本在原始模型上进行了一些改进:1)在网络初始层中使用6×6大小的卷积层代替了Focus模块,更便于部署应用. 2)使用C3模块代替CSP模块,强化网络特征融合能力,同时减少了计算量. 3)使用SPPF模块代替SPP模块,提高了运行速度. ...
YOLO系列目标检测算法研究进展
1
2023
... 随着近些年YOLO系列算法的更新换代,其检测准确性和检测速度逐渐提升[13 ] ,2020年已演变为YOLOv5,成为目前最流行的目标检测算法之一[14 ] . YOLOv5模型不断更新, 根据不同的工业需求发展出YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x等版本,其中YOLOv5s模型参数量最少、检测速度最快,更适合于轨枕裂纹检测的研究,因此本研究以YOLOv5的6.0版本中的YOLOv5s模型为基础,其网络结构如图1 所示. YOLOv5s模型由输入端、主干网络、特征融合网络和输出端4部分构成,6.0版本在原始模型上进行了一些改进:1)在网络初始层中使用6×6大小的卷积层代替了Focus模块,更便于部署应用. 2)使用C3模块代替CSP模块,强化网络特征融合能力,同时减少了计算量. 3)使用SPPF模块代替SPP模块,提高了运行速度. ...
Research on mask-wearing detection algorithm based on improved YOLOv5
1
2022
... 随着近些年YOLO系列算法的更新换代,其检测准确性和检测速度逐渐提升[13 ] ,2020年已演变为YOLOv5,成为目前最流行的目标检测算法之一[14 ] . YOLOv5模型不断更新, 根据不同的工业需求发展出YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x等版本,其中YOLOv5s模型参数量最少、检测速度最快,更适合于轨枕裂纹检测的研究,因此本研究以YOLOv5的6.0版本中的YOLOv5s模型为基础,其网络结构如图1 所示. YOLOv5s模型由输入端、主干网络、特征融合网络和输出端4部分构成,6.0版本在原始模型上进行了一些改进:1)在网络初始层中使用6×6大小的卷积层代替了Focus模块,更便于部署应用. 2)使用C3模块代替CSP模块,强化网络特征融合能力,同时减少了计算量. 3)使用SPPF模块代替SPP模块,提高了运行速度. ...
1
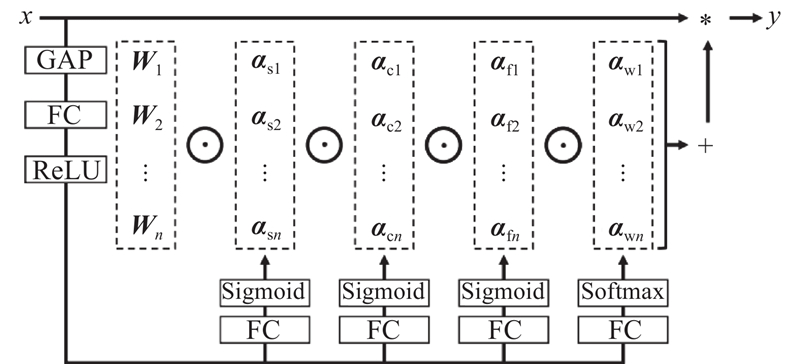
... 常规卷积(Conv)的静态卷积核,其结构参数在不同输入样本和不同网络深度中都不会发生改变,当网络深度和通道受到限制时,网络性能会变差,对复杂背景下的轨道裂纹特征提取有限. 动态卷积使用n 个卷积核的线性组合,通过注意力机制动态加权,使卷积运算自适应输入数据的不同部分或上下文,这种动态特性提升了模型对各种输入数据的提取性能. 全维动态卷积[15 ] (ODConv)弥补了条件参数卷积[16 ] (CondConv)和动态卷积[17 ] (DyConv)参数量大,及只关注卷积内核数量一个维度的不足,采用多维注意力机制,以平行的方式沿卷积内核的数量、空间大小、输入通道数、输出通道数4个维度互补学习卷积内核的4种注意力,从而强化卷积操作特征提取能力. 为了提高网络整体性能,在主干网络中使用全维动态卷积代替常规卷积模块,丰富轨道裂纹在卷积核数量、空间大小、通道数上不同纬度的语义信息,强化网络对裂纹特征的识别能力. ...
1
... 常规卷积(Conv)的静态卷积核,其结构参数在不同输入样本和不同网络深度中都不会发生改变,当网络深度和通道受到限制时,网络性能会变差,对复杂背景下的轨道裂纹特征提取有限. 动态卷积使用n 个卷积核的线性组合,通过注意力机制动态加权,使卷积运算自适应输入数据的不同部分或上下文,这种动态特性提升了模型对各种输入数据的提取性能. 全维动态卷积[15 ] (ODConv)弥补了条件参数卷积[16 ] (CondConv)和动态卷积[17 ] (DyConv)参数量大,及只关注卷积内核数量一个维度的不足,采用多维注意力机制,以平行的方式沿卷积内核的数量、空间大小、输入通道数、输出通道数4个维度互补学习卷积内核的4种注意力,从而强化卷积操作特征提取能力. 为了提高网络整体性能,在主干网络中使用全维动态卷积代替常规卷积模块,丰富轨道裂纹在卷积核数量、空间大小、通道数上不同纬度的语义信息,强化网络对裂纹特征的识别能力. ...
1
... 常规卷积(Conv)的静态卷积核,其结构参数在不同输入样本和不同网络深度中都不会发生改变,当网络深度和通道受到限制时,网络性能会变差,对复杂背景下的轨道裂纹特征提取有限. 动态卷积使用n 个卷积核的线性组合,通过注意力机制动态加权,使卷积运算自适应输入数据的不同部分或上下文,这种动态特性提升了模型对各种输入数据的提取性能. 全维动态卷积[15 ] (ODConv)弥补了条件参数卷积[16 ] (CondConv)和动态卷积[17 ] (DyConv)参数量大,及只关注卷积内核数量一个维度的不足,采用多维注意力机制,以平行的方式沿卷积内核的数量、空间大小、输入通道数、输出通道数4个维度互补学习卷积内核的4种注意力,从而强化卷积操作特征提取能力. 为了提高网络整体性能,在主干网络中使用全维动态卷积代替常规卷积模块,丰富轨道裂纹在卷积核数量、空间大小、通道数上不同纬度的语义信息,强化网络对裂纹特征的识别能力. ...
1
... 轨枕裂纹排查检测任务更适合使用移动端的边缘设备检测完成,为了控制设备成本、节约计算资源,使用高性能ConvNeXt[18 ] 结构和深度可分离卷积[19 ] (DWConv)改进C3特征融合模块,在减少网络参数量的同时,依然保持了对裂纹特征的提取能力. ConvNeXt网络是2022年Facebook团队借鉴SwinTransformer[20 ] 思想利用现有的方法和技术构建出来的网络,结构如图4 所示,以更简单的结构和规模在图像分类、识别和训练等效果上反超Transformer. ...
1
... 轨枕裂纹排查检测任务更适合使用移动端的边缘设备检测完成,为了控制设备成本、节约计算资源,使用高性能ConvNeXt[18 ] 结构和深度可分离卷积[19 ] (DWConv)改进C3特征融合模块,在减少网络参数量的同时,依然保持了对裂纹特征的提取能力. ConvNeXt网络是2022年Facebook团队借鉴SwinTransformer[20 ] 思想利用现有的方法和技术构建出来的网络,结构如图4 所示,以更简单的结构和规模在图像分类、识别和训练等效果上反超Transformer. ...
基于MA-ConvNext网络和分步关系知识蒸馏的苹果叶片病害识别
1
2024
... 轨枕裂纹排查检测任务更适合使用移动端的边缘设备检测完成,为了控制设备成本、节约计算资源,使用高性能ConvNeXt[18 ] 结构和深度可分离卷积[19 ] (DWConv)改进C3特征融合模块,在减少网络参数量的同时,依然保持了对裂纹特征的提取能力. ConvNeXt网络是2022年Facebook团队借鉴SwinTransformer[20 ] 思想利用现有的方法和技术构建出来的网络,结构如图4 所示,以更简单的结构和规模在图像分类、识别和训练等效果上反超Transformer. ...
基于MA-ConvNext网络和分步关系知识蒸馏的苹果叶片病害识别
1
2024
... 轨枕裂纹排查检测任务更适合使用移动端的边缘设备检测完成,为了控制设备成本、节约计算资源,使用高性能ConvNeXt[18 ] 结构和深度可分离卷积[19 ] (DWConv)改进C3特征融合模块,在减少网络参数量的同时,依然保持了对裂纹特征的提取能力. ConvNeXt网络是2022年Facebook团队借鉴SwinTransformer[20 ] 思想利用现有的方法和技术构建出来的网络,结构如图4 所示,以更简单的结构和规模在图像分类、识别和训练等效果上反超Transformer. ...
基于改进型YOLOv5s的印刷线路板瑕疵检测
1
2023
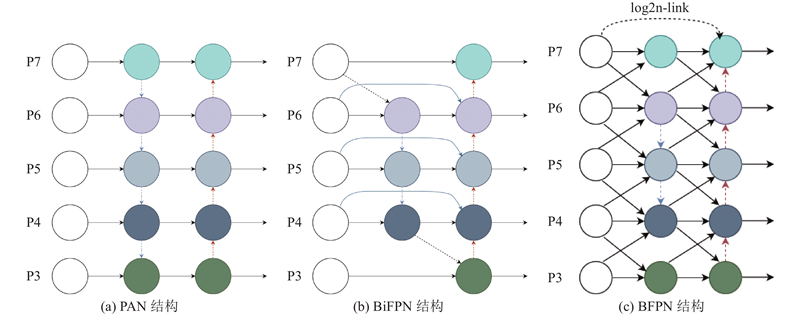
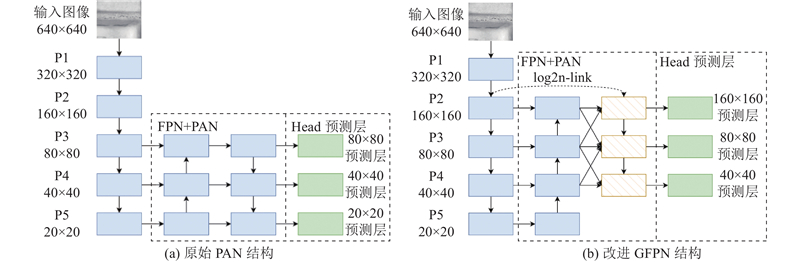
... 轨枕表面裂纹在图像中占有较小的像素比例,其携带的信息多存在于卷积操作的初始层之中. 经过多次下采样操作后,细节特征容易丢失,造成对细小裂纹的漏检. 在YOLOv5s中采用PAN进行多尺度特征融合,通过简单上下采样将各尺度特征变为相同尺寸进行特征融合,从而获得不同尺寸的目标特征信息,但输入特征有不同分辨率,不同分辨率输入特征融合后对输出特征图有不同的贡献[21 ] ,因此无法把握输入特征图中的主要特征信息. 在BiFPN[22 ] 结构中引入可学习的权重分量来区分不同输入特征贡献度,经多次双向路径堆叠实现深层特征融合,但BiFPN内部各模块相互独立,堆叠过深可能造成梯度消失的问题. 从GFPN[23 ] 中借鉴DenseNet思想设计log2n-link,强化各尺度特征之间的联系,保留更多有效的特征复用. 如图6 所示为不同尺度的特征融合结构图,其中下箭头表示下采样,上箭头表示上采样. ...
基于改进型YOLOv5s的印刷线路板瑕疵检测
1
2023
... 轨枕表面裂纹在图像中占有较小的像素比例,其携带的信息多存在于卷积操作的初始层之中. 经过多次下采样操作后,细节特征容易丢失,造成对细小裂纹的漏检. 在YOLOv5s中采用PAN进行多尺度特征融合,通过简单上下采样将各尺度特征变为相同尺寸进行特征融合,从而获得不同尺寸的目标特征信息,但输入特征有不同分辨率,不同分辨率输入特征融合后对输出特征图有不同的贡献[21 ] ,因此无法把握输入特征图中的主要特征信息. 在BiFPN[22 ] 结构中引入可学习的权重分量来区分不同输入特征贡献度,经多次双向路径堆叠实现深层特征融合,但BiFPN内部各模块相互独立,堆叠过深可能造成梯度消失的问题. 从GFPN[23 ] 中借鉴DenseNet思想设计log2n-link,强化各尺度特征之间的联系,保留更多有效的特征复用. 如图6 所示为不同尺度的特征融合结构图,其中下箭头表示下采样,上箭头表示上采样. ...
1
... 轨枕表面裂纹在图像中占有较小的像素比例,其携带的信息多存在于卷积操作的初始层之中. 经过多次下采样操作后,细节特征容易丢失,造成对细小裂纹的漏检. 在YOLOv5s中采用PAN进行多尺度特征融合,通过简单上下采样将各尺度特征变为相同尺寸进行特征融合,从而获得不同尺寸的目标特征信息,但输入特征有不同分辨率,不同分辨率输入特征融合后对输出特征图有不同的贡献[21 ] ,因此无法把握输入特征图中的主要特征信息. 在BiFPN[22 ] 结构中引入可学习的权重分量来区分不同输入特征贡献度,经多次双向路径堆叠实现深层特征融合,但BiFPN内部各模块相互独立,堆叠过深可能造成梯度消失的问题. 从GFPN[23 ] 中借鉴DenseNet思想设计log2n-link,强化各尺度特征之间的联系,保留更多有效的特征复用. 如图6 所示为不同尺度的特征融合结构图,其中下箭头表示下采样,上箭头表示上采样. ...
RDD-YOLO: a modified YOLO for detection of steel surface defects
1
2023
... 轨枕表面裂纹在图像中占有较小的像素比例,其携带的信息多存在于卷积操作的初始层之中. 经过多次下采样操作后,细节特征容易丢失,造成对细小裂纹的漏检. 在YOLOv5s中采用PAN进行多尺度特征融合,通过简单上下采样将各尺度特征变为相同尺寸进行特征融合,从而获得不同尺寸的目标特征信息,但输入特征有不同分辨率,不同分辨率输入特征融合后对输出特征图有不同的贡献[21 ] ,因此无法把握输入特征图中的主要特征信息. 在BiFPN[22 ] 结构中引入可学习的权重分量来区分不同输入特征贡献度,经多次双向路径堆叠实现深层特征融合,但BiFPN内部各模块相互独立,堆叠过深可能造成梯度消失的问题. 从GFPN[23 ] 中借鉴DenseNet思想设计log2n-link,强化各尺度特征之间的联系,保留更多有效的特征复用. 如图6 所示为不同尺度的特征融合结构图,其中下箭头表示下采样,上箭头表示上采样. ...
1
... 曹建斌[24 ] 收集了大量轨枕缺陷检测现场数据,从中挑选出2000 张高质量轨枕裂纹图组成实验数据集,用Labelimg软件对图像中裂纹进行单类别标注. 由于裂纹在图像中像素占比较小,大量背景像素的干扰会使裂纹误检增加,为了使标注框中含有裂纹目标的像素比例增加,使用多个较小的标注框沿裂纹的形状对一个裂纹进行标注. 按照8∶2的比例将数据集划分为训练集和验证集,其中训练集有1600 张,验证集有400张,数据标注和部分数据集样例如图8 所示. ...
1
... 曹建斌[24 ] 收集了大量轨枕缺陷检测现场数据,从中挑选出2000 张高质量轨枕裂纹图组成实验数据集,用Labelimg软件对图像中裂纹进行单类别标注. 由于裂纹在图像中像素占比较小,大量背景像素的干扰会使裂纹误检增加,为了使标注框中含有裂纹目标的像素比例增加,使用多个较小的标注框沿裂纹的形状对一个裂纹进行标注. 按照8∶2的比例将数据集划分为训练集和验证集,其中训练集有1600 张,验证集有400张,数据标注和部分数据集样例如图8 所示. ...
基于混合域注意力YOLOv4的输送带纵向撕裂多维度检测
1
2022
... 为了客观评价算法的综合性能,在轨枕裂纹数据集下使用经典目标检测算法模型Faster-RCNN、SSD、CenterNet、RetinaNet、YOLO等[25 -26 ] 和用于缺陷检测的轻量化模型YOLOv5s-GhostNet[27 ] 、YOLOv5s-shufflenetv2[28 ] 进行实验对比分析,不同算法模型的各性能指标实验结果如表3 所示.可以看出,与经典目标检测算法相比,YOLOv5s-OCG的平均精度均值相比Faster-RCNN、SSD、CenterNet、RetinaNet、YOLOv3、YOLOv5s、YOLOv7-tiny分别提升了14.5、9.0、5.3、7.1、5.2、4.2、5.1个百分点,在检测速度和模型体积方面,YOLOv5s-OCG有最快的检测速度,同时所需的内存空间最少. 另外,与用于缺陷检测的轻量化模型相比,本研究算法的平均精度均值较YOLOv5s-GhostNet、YOLOv5s-shufflenetv2模型分别提升了8.6个百分点和10.9个百分点,虽然检测速度和模型大小不如轻量化模型,但96帧/s的检测速度和5.64×106 的计算量已经满足实时检测的要求. 经综合比较,YOLOv5s-OCG较其他主流目标检测算法,拥有更稳定的性能,更适合于实际场景的轨枕裂纹检测任务. ...
基于混合域注意力YOLOv4的输送带纵向撕裂多维度检测
1
2022
... 为了客观评价算法的综合性能,在轨枕裂纹数据集下使用经典目标检测算法模型Faster-RCNN、SSD、CenterNet、RetinaNet、YOLO等[25 -26 ] 和用于缺陷检测的轻量化模型YOLOv5s-GhostNet[27 ] 、YOLOv5s-shufflenetv2[28 ] 进行实验对比分析,不同算法模型的各性能指标实验结果如表3 所示.可以看出,与经典目标检测算法相比,YOLOv5s-OCG的平均精度均值相比Faster-RCNN、SSD、CenterNet、RetinaNet、YOLOv3、YOLOv5s、YOLOv7-tiny分别提升了14.5、9.0、5.3、7.1、5.2、4.2、5.1个百分点,在检测速度和模型体积方面,YOLOv5s-OCG有最快的检测速度,同时所需的内存空间最少. 另外,与用于缺陷检测的轻量化模型相比,本研究算法的平均精度均值较YOLOv5s-GhostNet、YOLOv5s-shufflenetv2模型分别提升了8.6个百分点和10.9个百分点,虽然检测速度和模型大小不如轻量化模型,但96帧/s的检测速度和5.64×106 的计算量已经满足实时检测的要求. 经综合比较,YOLOv5s-OCG较其他主流目标检测算法,拥有更稳定的性能,更适合于实际场景的轨枕裂纹检测任务. ...
基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
1
2024
... 为了客观评价算法的综合性能,在轨枕裂纹数据集下使用经典目标检测算法模型Faster-RCNN、SSD、CenterNet、RetinaNet、YOLO等[25 -26 ] 和用于缺陷检测的轻量化模型YOLOv5s-GhostNet[27 ] 、YOLOv5s-shufflenetv2[28 ] 进行实验对比分析,不同算法模型的各性能指标实验结果如表3 所示.可以看出,与经典目标检测算法相比,YOLOv5s-OCG的平均精度均值相比Faster-RCNN、SSD、CenterNet、RetinaNet、YOLOv3、YOLOv5s、YOLOv7-tiny分别提升了14.5、9.0、5.3、7.1、5.2、4.2、5.1个百分点,在检测速度和模型体积方面,YOLOv5s-OCG有最快的检测速度,同时所需的内存空间最少. 另外,与用于缺陷检测的轻量化模型相比,本研究算法的平均精度均值较YOLOv5s-GhostNet、YOLOv5s-shufflenetv2模型分别提升了8.6个百分点和10.9个百分点,虽然检测速度和模型大小不如轻量化模型,但96帧/s的检测速度和5.64×106 的计算量已经满足实时检测的要求. 经综合比较,YOLOv5s-OCG较其他主流目标检测算法,拥有更稳定的性能,更适合于实际场景的轨枕裂纹检测任务. ...
基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
1
2024
... 为了客观评价算法的综合性能,在轨枕裂纹数据集下使用经典目标检测算法模型Faster-RCNN、SSD、CenterNet、RetinaNet、YOLO等[25 -26 ] 和用于缺陷检测的轻量化模型YOLOv5s-GhostNet[27 ] 、YOLOv5s-shufflenetv2[28 ] 进行实验对比分析,不同算法模型的各性能指标实验结果如表3 所示.可以看出,与经典目标检测算法相比,YOLOv5s-OCG的平均精度均值相比Faster-RCNN、SSD、CenterNet、RetinaNet、YOLOv3、YOLOv5s、YOLOv7-tiny分别提升了14.5、9.0、5.3、7.1、5.2、4.2、5.1个百分点,在检测速度和模型体积方面,YOLOv5s-OCG有最快的检测速度,同时所需的内存空间最少. 另外,与用于缺陷检测的轻量化模型相比,本研究算法的平均精度均值较YOLOv5s-GhostNet、YOLOv5s-shufflenetv2模型分别提升了8.6个百分点和10.9个百分点,虽然检测速度和模型大小不如轻量化模型,但96帧/s的检测速度和5.64×106 的计算量已经满足实时检测的要求. 经综合比较,YOLOv5s-OCG较其他主流目标检测算法,拥有更稳定的性能,更适合于实际场景的轨枕裂纹检测任务. ...
1
... 为了客观评价算法的综合性能,在轨枕裂纹数据集下使用经典目标检测算法模型Faster-RCNN、SSD、CenterNet、RetinaNet、YOLO等[25 -26 ] 和用于缺陷检测的轻量化模型YOLOv5s-GhostNet[27 ] 、YOLOv5s-shufflenetv2[28 ] 进行实验对比分析,不同算法模型的各性能指标实验结果如表3 所示.可以看出,与经典目标检测算法相比,YOLOv5s-OCG的平均精度均值相比Faster-RCNN、SSD、CenterNet、RetinaNet、YOLOv3、YOLOv5s、YOLOv7-tiny分别提升了14.5、9.0、5.3、7.1、5.2、4.2、5.1个百分点,在检测速度和模型体积方面,YOLOv5s-OCG有最快的检测速度,同时所需的内存空间最少. 另外,与用于缺陷检测的轻量化模型相比,本研究算法的平均精度均值较YOLOv5s-GhostNet、YOLOv5s-shufflenetv2模型分别提升了8.6个百分点和10.9个百分点,虽然检测速度和模型大小不如轻量化模型,但96帧/s的检测速度和5.64×106 的计算量已经满足实时检测的要求. 经综合比较,YOLOv5s-OCG较其他主流目标检测算法,拥有更稳定的性能,更适合于实际场景的轨枕裂纹检测任务. ...
1
... 为了客观评价算法的综合性能,在轨枕裂纹数据集下使用经典目标检测算法模型Faster-RCNN、SSD、CenterNet、RetinaNet、YOLO等[25 -26 ] 和用于缺陷检测的轻量化模型YOLOv5s-GhostNet[27 ] 、YOLOv5s-shufflenetv2[28 ] 进行实验对比分析,不同算法模型的各性能指标实验结果如表3 所示.可以看出,与经典目标检测算法相比,YOLOv5s-OCG的平均精度均值相比Faster-RCNN、SSD、CenterNet、RetinaNet、YOLOv3、YOLOv5s、YOLOv7-tiny分别提升了14.5、9.0、5.3、7.1、5.2、4.2、5.1个百分点,在检测速度和模型体积方面,YOLOv5s-OCG有最快的检测速度,同时所需的内存空间最少. 另外,与用于缺陷检测的轻量化模型相比,本研究算法的平均精度均值较YOLOv5s-GhostNet、YOLOv5s-shufflenetv2模型分别提升了8.6个百分点和10.9个百分点,虽然检测速度和模型大小不如轻量化模型,但96帧/s的检测速度和5.64×106 的计算量已经满足实时检测的要求. 经综合比较,YOLOv5s-OCG较其他主流目标检测算法,拥有更稳定的性能,更适合于实际场景的轨枕裂纹检测任务. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}