[1]
ZRELLI I, REJEB A, ABUSULAIMAN R, et al Drone applications in logistics and supply chain management: a systematic review using latent Dirichlet allocation
[J]. Arabian Journal for Science and Engineering , 2024 , 49 (9 ): 12411 - 12430
DOI:10.1007/s13369-023-08681-0
[本文引用: 1]
[2]
奉志强, 谢志军, 包正伟, 等 基于改进YOLOv5的无人机实时密集小目标检测算法
[J]. 航空学报 , 2023 , 44 (7 ): 251 - 265
[本文引用: 1]
FENG Zhiqiang, XIE Zhijun, BAO Zhengwei, et al Real-time dense small object detection algorithm for UAV based on improved YOLOv5
[J]. Acta Aeronautica et Astronautica Sinica , 2023 , 44 (7 ): 251 - 265
[本文引用: 1]
[3]
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464-7475.
[本文引用: 1]
[4]
ZHU X K, LYU S C, WANG X, et al. TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Montreal: IEEE, 2021: 2778-2788.
[本文引用: 2]
[5]
WANG G, CHEN Y F, AN P, et al UAV-YOLOv8: a small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios
[J]. Sensors , 2023 , 23 (16 ): 7190
DOI:10.3390/s23167190
[本文引用: 1]
[6]
LI Y T, FAN Q S, HUANG H S, et al A modified YOLOv8 detection network for UAV aerial image recognition
[J]. Drones , 2023 , 7 (5 ): 304
DOI:10.3390/drones7050304
[本文引用: 1]
[7]
SHAO Y F, YANG Z X, LI Z H, et al Aero-YOLO: an efficient vehicle and pedestrian detection algorithm based on unmanned aerial imagery
[J]. Electronics , 2024 , 13 (7 ): 1190
DOI:10.3390/electronics13071190
[本文引用: 1]
[8]
XU L Y, ZHAO Y F, ZHAI Y H, et al Small object detection in UAV images based on YOLOv8n
[J]. International Journal of Computational Intelligence Systems , 2024 , 17 (1 ): 1 - 9
DOI:10.1007/s44196-023-00380-w
[本文引用: 1]
[9]
SUI J C, CHEN D K, ZHENG X, et al A new algorithm for small target detection from the perspective of unmanned aerial vehicles
[J]. IEEE Access , 2024 , 12 (99 ): 29690 - 29697
[本文引用: 1]
[10]
刘树东, 刘业辉, 孙叶美, 等 基于倒置残差注意力的无人机航拍图像小目标检测
[J]. 北京航空航天大学学报 , 2023 , 49 (3 ): 514 - 524
[本文引用: 1]
LIU Shudong, LIU Yehui, SUN Yemei, et al Small object detection in UAV aerial images based on inverted residual attention
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2023 , 49 (3 ): 514 - 524
[本文引用: 1]
[11]
潘玮, 韦超, 钱春雨, 等 面向无人机视角下小目标检测的YOLOv8s改进模型
[J]. 计算机工程与应用 , 2024 , 60 (9 ): 142 - 150
DOI:10.3778/j.issn.1002-8331.2312-0043
[本文引用: 1]
PAN Wei, WEI Chao, QIAN Chunyu, et al Improved YOLOv8s model for small object detection from perspective of drones
[J]. Computer Engineering and Applications , 2024 , 60 (9 ): 142 - 150
DOI:10.3778/j.issn.1002-8331.2312-0043
[本文引用: 1]
[12]
邓天民, 程鑫鑫, 刘金凤, 等 基于特征复用机制的航拍图像小目标检测算法
[J]. 浙江大学学报: 工学版 , 2024 , 58 (3 ): 437 - 448
[本文引用: 1]
DENG Tianming, CHENG Xinxin, LIU Jinfeng, et al Small target detection algorithm for aerial images based on feature reuse mechanism
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (3 ): 437 - 448
[本文引用: 1]
[13]
LIU S, QI L, QIN H F. et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759-8768.
[本文引用: 1]
[14]
LIN T Y, DOLLAR P, CIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 936-944.
[本文引用: 1]
[15]
DING X H, ZHANG X Y, MA N N, et al. Repvgg: making VGG-style convnets great again [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13733-13742.
[本文引用: 1]
[16]
MISRA D, NALAMADA T, ARASANIPALAI A U, et al. Rotate to attend: convolutional triplet attention module [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2021: 3138-3147.
[本文引用: 1]
[17]
TONG Z J, CHEN Y H, XU Z W, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism [EB/OL]. (2023-04-08) [2024-07-13]. https://arxiv.org/pdf/2301.10051.
[本文引用: 1]
[18]
DU D, ZHU P F, WEN L Y, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops . Seoul: IEEE, 2019: 213-226.
[本文引用: 1]
[19]
YU W P, YANG T, CHEN C. Towards resolving the challenge of long-tail distribution in UAV images for object detection [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2021: 3258-3267.
[本文引用: 1]
[20]
ZHAO H P, ZHOU Y, ZHANG L, et al Mixed YOLOv3-LITE: a lightweight real-time object detection method
[J]. Sensors , 2020 , 20 (7 ): 1861
DOI:10.3390/s20071861
[本文引用: 1]
[22]
冯迎宾, 郭枭尊, 晏佳华. 基于多尺度注意力机制的无人机小目标检测算法[EB/OL]. (2024-08-02)[2024-08-11]. http://www.co-journal.com/CN/10.12382/bgxb.2023.1124.
[本文引用: 1]
FENG Yingbin, GUO Xiaozun, YAN Jiahua. UVA small target detection algorithm based on multi-scale attention mechanism [EB/OL]. (2024-08-02)[2024-08-11]. http://www.co-journal.com/ CN/10.12382/bgxb.2023.1124.
[本文引用: 1]
[23]
TAHIR N U A, LONG Z, ZHANG Z, et al PVswin-YOLOv8s: UAV-based pedestrian and vehicle detection for traffic management in smart cities using improved YOLOv8
[J]. Drones , 2024 , 8 (3 ): 84
DOI:10.3390/drones8030084
[本文引用: 1]
[24]
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 618-626.
[本文引用: 1]
Drone applications in logistics and supply chain management: a systematic review using latent Dirichlet allocation
1
2024
... 随着无人机(unmanned aerial vehicle,UAV)技术的快速发展,其在军事侦察、灾难救援、农业监测和城市规划等领域的应用日益扩大[1 -2 ] . 尤其在目标检测方面,无人机独特的高空视角能够快速、大范围地获取高分辨率图像. 由于无人机拍摄角度多变、目标遮挡、光照和天气变化等因素,小目标的特征常常不完整,易造成漏检和误检. 如何有效利用小目标的特征信息来提升检测性能,是无人机航拍图像目标检测的一大难点,具有重要的研究价值与广阔的应用前景. ...
基于改进YOLOv5的无人机实时密集小目标检测算法
1
2023
... 随着无人机(unmanned aerial vehicle,UAV)技术的快速发展,其在军事侦察、灾难救援、农业监测和城市规划等领域的应用日益扩大[1 -2 ] . 尤其在目标检测方面,无人机独特的高空视角能够快速、大范围地获取高分辨率图像. 由于无人机拍摄角度多变、目标遮挡、光照和天气变化等因素,小目标的特征常常不完整,易造成漏检和误检. 如何有效利用小目标的特征信息来提升检测性能,是无人机航拍图像目标检测的一大难点,具有重要的研究价值与广阔的应用前景. ...
基于改进YOLOv5的无人机实时密集小目标检测算法
1
2023
... 随着无人机(unmanned aerial vehicle,UAV)技术的快速发展,其在军事侦察、灾难救援、农业监测和城市规划等领域的应用日益扩大[1 -2 ] . 尤其在目标检测方面,无人机独特的高空视角能够快速、大范围地获取高分辨率图像. 由于无人机拍摄角度多变、目标遮挡、光照和天气变化等因素,小目标的特征常常不完整,易造成漏检和误检. 如何有效利用小目标的特征信息来提升检测性能,是无人机航拍图像目标检测的一大难点,具有重要的研究价值与广阔的应用前景. ...
1
... 目前,主流的目标检测算法主要基于深度学习模型,依据检测方式可以分为以下两大类. 1)两阶段算法,如R-CNN等算法. 这类算法的准确率较高,但因计算量大,导致检测速度慢,不适用于无人机快速运动和高速检测的环境. 2)单阶段算法,如RetinaNet、SSD、YOLO[3 ] 系列等算法. 单阶段算法的检测精度略低于两阶段算法,但检测速度更快,便于部署到各项任务中,因此更适合使用单阶段算法进行研究. ...
2
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
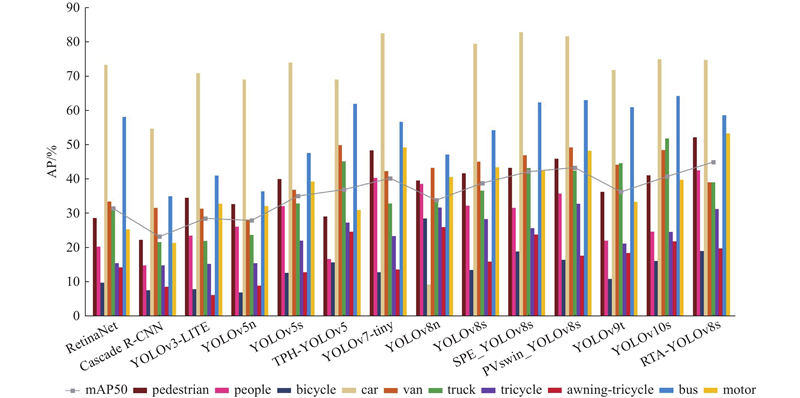
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
UAV-YOLOv8: a small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios
1
2023
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
A modified YOLOv8 detection network for UAV aerial image recognition
1
2023
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
Aero-YOLO: an efficient vehicle and pedestrian detection algorithm based on unmanned aerial imagery
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
Small object detection in UAV images based on YOLOv8n
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
A new algorithm for small target detection from the perspective of unmanned aerial vehicles
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
基于倒置残差注意力的无人机航拍图像小目标检测
1
2023
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
基于倒置残差注意力的无人机航拍图像小目标检测
1
2023
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
面向无人机视角下小目标检测的YOLOv8s改进模型
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
面向无人机视角下小目标检测的YOLOv8s改进模型
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
基于特征复用机制的航拍图像小目标检测算法
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
基于特征复用机制的航拍图像小目标检测算法
1
2024
... 针对无人机航拍图像中的小目标检测问题,国内外学者展开了大量研究. Zhu等[4 ] 提出TPH-YOLOv5,通过集成Transformer编码器和CBAM模块,显著提升了目标检测性能. Wang等[5 ] 提出UAV-YOLOv8检测模型,通过引入WIoU v3损失函数、BiFormer注意力机制和FFNB,提升了检测精度,但增加了计算资源消耗. Li等[6 ] 改进了Bi-PAN-FPN特征融合,使用GhostblockV2减少参数,采用WiseIoU损失函数,在边缘设备上实现了高效检测,但在某些小类别上无法取得比其他模型更好的结果. Shao等[7 ] 在骨干和头部引入CoordAtt和shuffle注意力机制,提高了检测的准确性,但尚未有效解决遮挡或模糊车辆的识别问题. Xu等[8 ] 通过集成改进的卷积模块、多尺度检测头和优化的IoU机制,模型实现了显著的性能提升. Sui等[9 ] 提出改进的小目标检测模型BDH-YOLO,通过引入BiFPN,采用动态检测头DyHead,显著提升了检测的精度. 刘树东等[10 ] 在主干网络嵌入倒置残差注意力模块,改善了小目标漏检的问题. 潘玮等[11 ] 引入感受野注意力卷积和CBAM注意力机制,增加具有小目标语义信息的特征层,利用较小的模型得到较高的精度. 邓天民等[12 ] 通过降低通道维数,实现对冗余特征信息的高效复用. ...
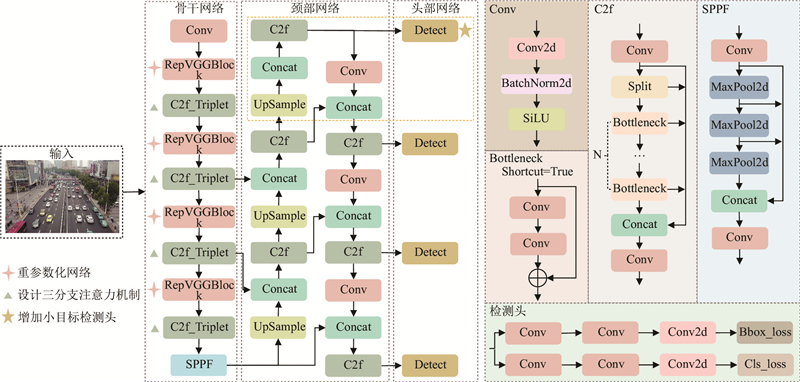
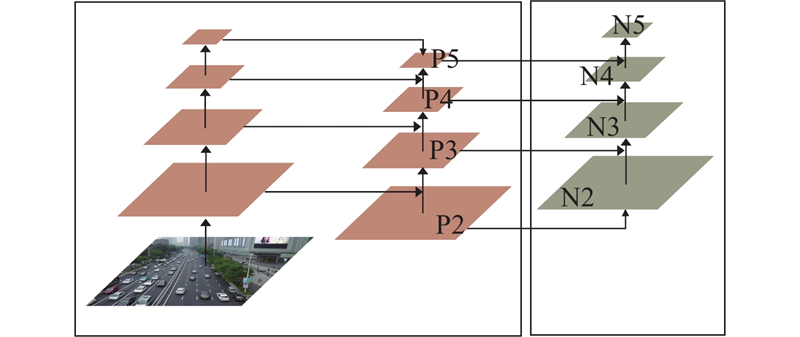
1
... YOLOv8的整体结构分为4部分,分别为输入端(input)、主干网络(backbone)、颈部网络(neck)和检测头(head). 输入端采用Mosaic数据增强方法. 主干网络由Conv、C2f和SPPF模块组成. C2f模块借鉴了C3和ELAN的设计思想,通过并行级联获取丰富的梯度流信息,以轻量方式提升检测精度. 颈部网络采用PAN-FPN[13 -14 ] 结构,通过上采样和下采样路径,实现不同尺度特征图的融合. 检测头采用解耦头结构(decoupled-head),实现分类与检测任务的分离. 采用无锚框Anchor-free机制,精确地获取大、中、小尺寸目标物体的分类和位置信息. ...
1
... YOLOv8的整体结构分为4部分,分别为输入端(input)、主干网络(backbone)、颈部网络(neck)和检测头(head). 输入端采用Mosaic数据增强方法. 主干网络由Conv、C2f和SPPF模块组成. C2f模块借鉴了C3和ELAN的设计思想,通过并行级联获取丰富的梯度流信息,以轻量方式提升检测精度. 颈部网络采用PAN-FPN[13 -14 ] 结构,通过上采样和下采样路径,实现不同尺度特征图的融合. 检测头采用解耦头结构(decoupled-head),实现分类与检测任务的分离. 采用无锚框Anchor-free机制,精确地获取大、中、小尺寸目标物体的分类和位置信息. ...
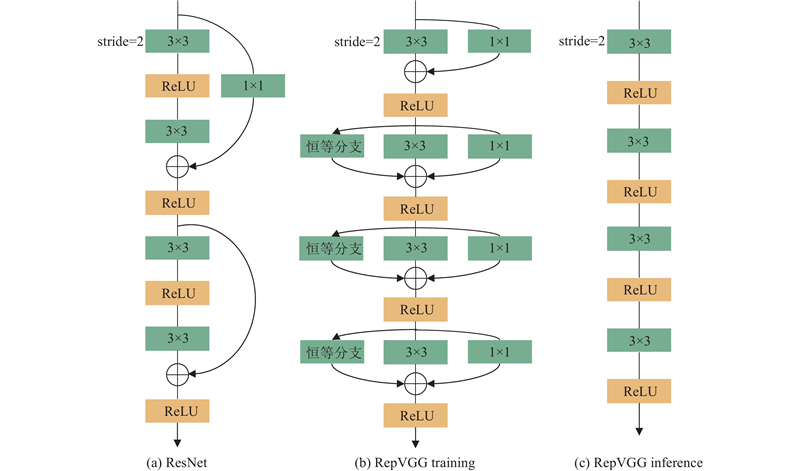
1
... 将YOLOv8主干网络中的卷积模块替换为RepVGG[15 ] ,能够更好地适应复杂的高空场景,满足无人机高精度、快速度的检测需求. ...
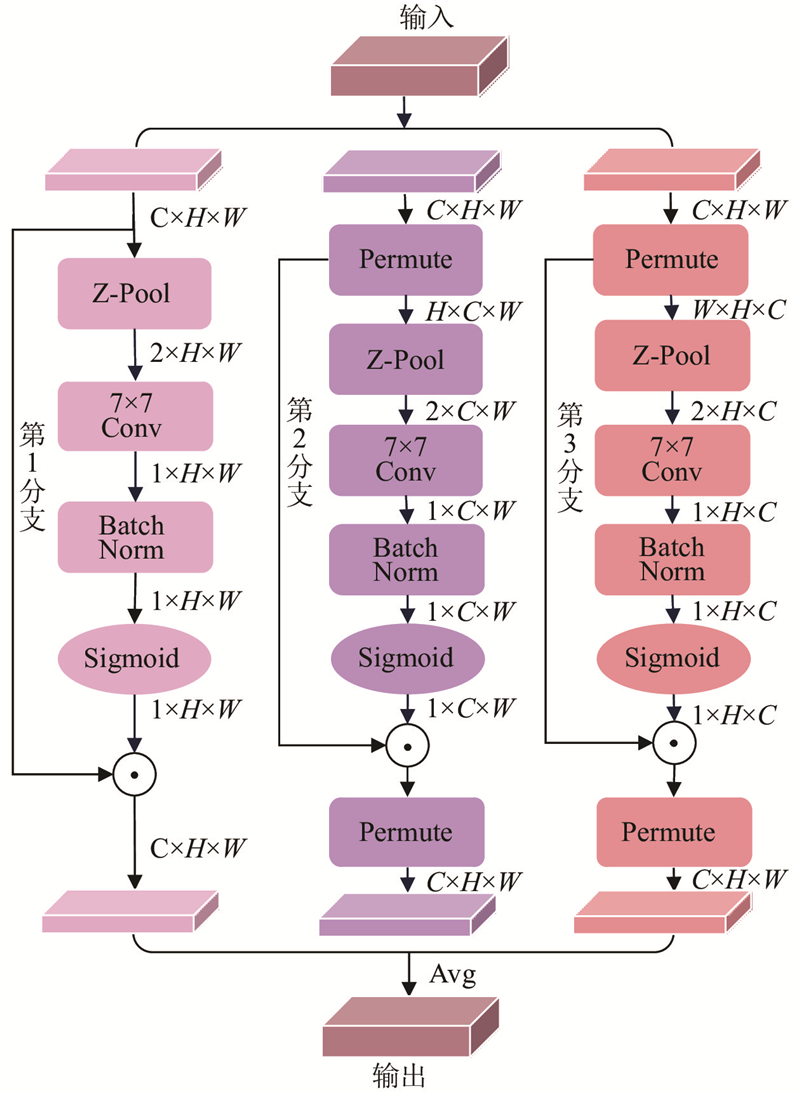
1
... 传统注意力机制的缺点在于通道注意力和空间注意力相互独立,忽略二者之间的关系. 在骨干网络中嵌入Triplet Attention[16 ] 模块,通过减少冗余信息,并抑制背景干扰,更关注小目标的关键区域. 该模块引入跨维度交互,通过旋转操作和残差变换建立维度间的依存关系,并以极低的计算开销,实现通道间和空间信息的有效编码,提高网络对重要特征的学习能力. 三分支注意力机制的结构如图3 所示. ...
1
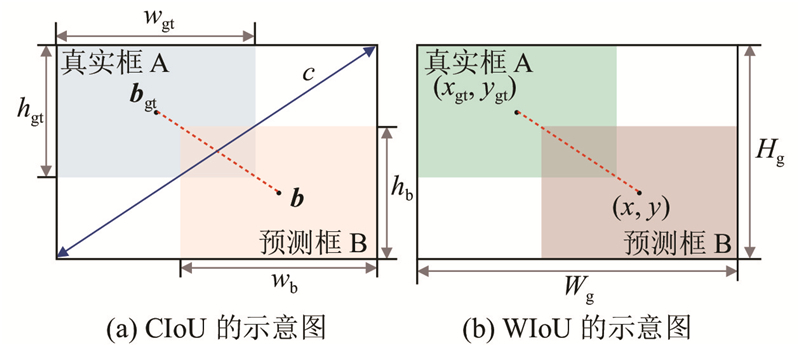
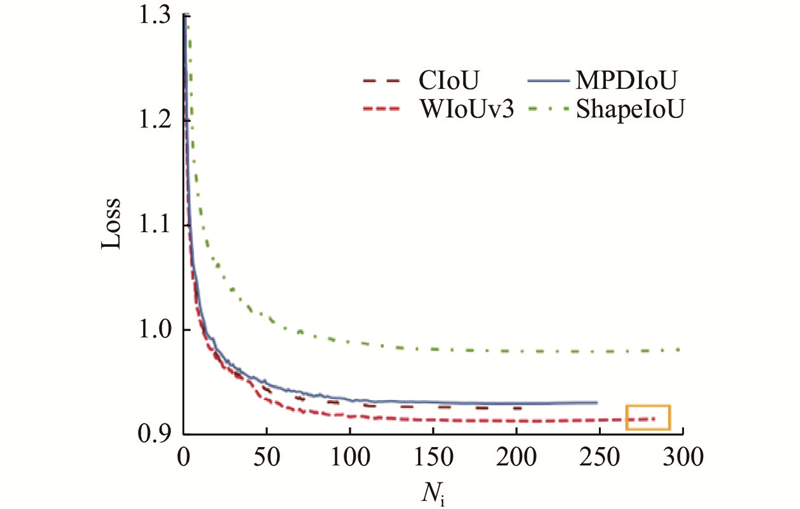
... 为了削弱预测框和真实框重合时几何度量的惩罚,提高模型的泛化能力,引入具有动态非单调聚焦机制[17 ] 的损失函数. 根据距离度量构建距离注意力,得到具有2层注意力机制的WIoUv1损失函数,计算公式如下. ...
1
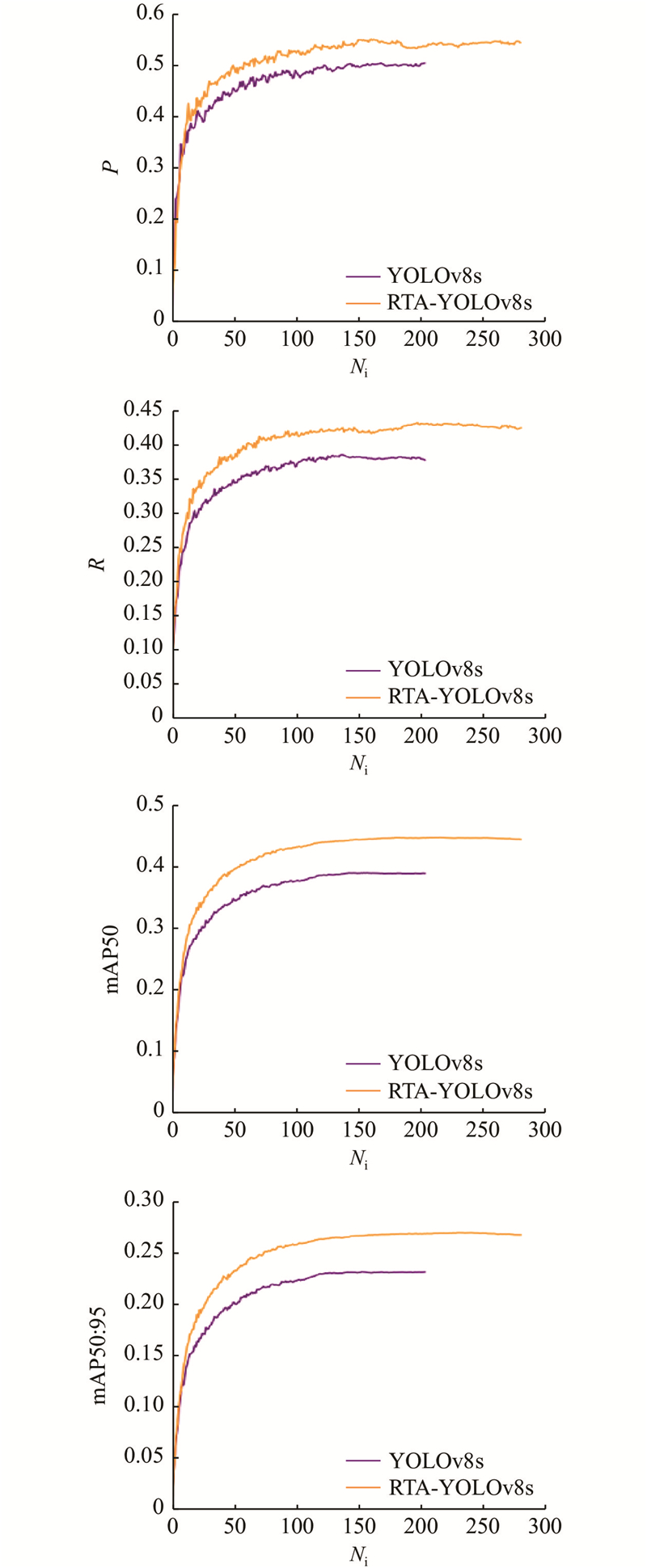
... 使用公开的无人机视觉目标检测数据集VisDrone2019[18 ] . 该数据集由天津大学AISKYEYE团队收集,涵盖城乡道路交通场景中的pedestrian、people、bicycle、car、van、truck、tricycle、awning-tricycle、bus、motor共10个类别. 将数据集中的8 629张标记图像按照7︰2︰1的比例随机划分,使用6 471张图像用于训练,548张图像用于验证,1 610张图像用于测试. ...
1
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
Mixed YOLOv3-LITE: a lightweight real-time object detection method
1
2020
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
改进YOLOv7-tiny的无人机目标检测算法
1
2024
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
改进YOLOv7-tiny的无人机目标检测算法
1
2024
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
1
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
1
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
PVswin-YOLOv8s: UAV-based pedestrian and vehicle detection for traffic management in smart cities using improved YOLOv8
1
2024
... Comparison of result of different algorithms on VisDrone 2019 dataset
Tab.2 模型 AP/% mAP50/% pedestrian people bicycle car van truck tricycle awning-tricycle bus motor RetinaNet 28.6 20.3 9.8 73.2 33.4 31.8 15.5 14.3 58.0 25.3 31.4 Faster R-CNN[19 ] 22.2 14.8 7.6 54.6 31.5 21.6 14.8 8.6 34.9 21.4 23.2 YOLOv3-LITE[20 ] 34.5 23.4 7.9 70.8 31.3 21.9 15.2 6.2 40.9 32.7 28.5 YOLOv5n 32.6 26.1 6.9 69.0 28.1 23.7 15.5 8.9 36.4 32.1 27.9 YOLOv5s 40.0 32.1 12.6 73.9 36.8 32.9 22.0 12.8 47.5 39.2 35.0 TPH-YOLOv5[4 ] 29.0 16.7 15.7 68.9 49.8 45.1 27.3 24.7 61.8 30.9 36.9 YOLOv7-tiny[21 ] 48.3 40.3 12.8 82.4 42.3 32.9 23.3 13.6 56.6 49.2 40.2 YOLOv8n 39.5 38.5 28.5 9.2 43.3 34.1 31.7 26.0 47.1 40.5 33.8 YOLOv8s 41.6 32.2 13.5 79.3 45.0 36.6 28.3 15.9 54.2 43.4 38.8 SPE_ YOLOv8s[22 ] 43.3 31.5 18.9 82.7 46.9 43.1 25.6 23.8 62.3 42.5 42.1 PVswin-YOLOv8s[23 ] 45.9 35.7 16.4 81.5 49.1 42.4 32.8 17.7 62.9 48.2 43.3 YOLOv9t 36.2 22.0 10.9 71.7 44.1 44.6 21.2 18.4 60.8 33.3 36.2 YOLOv10s 41.1 24.6 16.1 74.9 48.4 51.8 24.5 21.8 64.1 39.8 40.7 RTA-YOLOv8s 52.1 42.5 19.0 84.5 48.9 39.0 31.2 19.7 58.6 53.2 44.9
图 8 不同模型的AP对比 ...
1
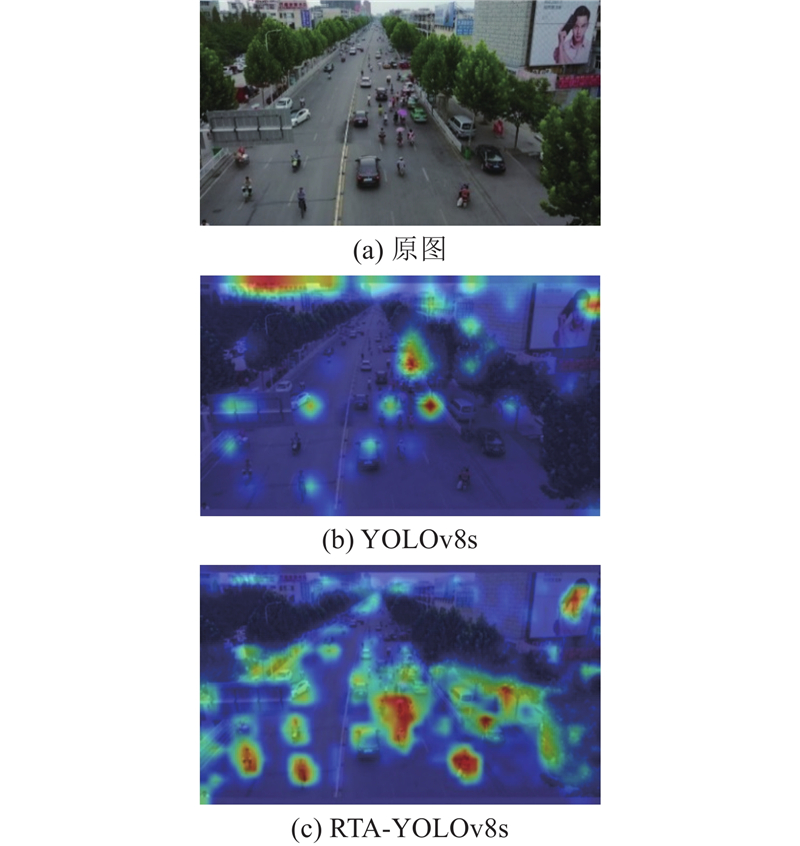
... 为了更直观地展示所提改进措施的有效性,采用Grad-CAM[24 ] 技术进行可视化分析,确定网络各部分对特定类别预测的重要性. Grad-CAM通过反向传播得到梯度矩阵,进行全局平均池化后,生成特征层通道的加权激活热力图. 热力图颜色越深表示模型对区域的关注度越高,目标存在的概率越大. 如图9 所示为YOLOv8s和RTA-YOLOv8s的热力图可视化结果对比. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}