

高级驾驶辅助系统核心模块为汽车感知,包括决策制定、运动规划和控制3部分[1]. 高级驾驶辅助系统视觉感知部分利用摄像头采集数据[2],利用目标检测和轨迹跟踪算法,识别检测道路上的车辆、行人及道路标志,跟踪移动轨迹,实现保持车距、盲点监测、调整行驶路径等关键任务. 基于深度学习的目标检测算法YOLOv8 是Ultralytics 公司推出的YOLO 系列单阶段目标检测算法,适用于图像分类、物体检测、实例分割等任务. 学者针对小目标、多尺度变换、模型参数等问题优化YOLOv8 模型. Wang等[3] 将小目标检测结构嵌入网络,融合浅特征和深特征,并在YOLOv8m骨干底层引入全局关注,提高小目标语义信息收集. Zhang 等[4]提出CR-YOLOv8多尺度交通检测模型,在特征提取模块引入注意力机制增强通道和空间特征,在特征融合模块引入Receptive Field Block 模块,提升网络多尺度目标检测能力. Ma 等[5]提出小目标轻量级目标检测算法,引入GhostNet 作为YOLOv8 骨干网络,融合Soft-NMS 算法多尺度注意模块.
目标跟踪技术在车辆协同行驶中发挥关键作用,实时监测目标车辆的位置变化,结合传感器数据和几何关系计算前车速度,从而保持安全距离. 以AlexNet 为代表的深度学习方法应用在图像处理领域,孪生网络、强化学习框架融入目标跟踪算法[6]. 基于AlexNet 网络进行图像处理的方法,Bertinetto 等[7]提出端到端的全卷积网络,将深度学习与相关滤波结合实现目标跟踪. 聂源等[8]融合MFF-YOLOv7 和Bytetrack 算法,在MOT17 和Visdrone-MOT 多目标跟踪数据集上进行实验,在动态视频跟踪中性能表现良好. Zheng等[9]提出YOLO-BYTE 多目标跟踪方法,改进卡尔曼滤波器的状态参数和ByteTrack 算法,提高跟踪框匹配目标精度.
传统车辆图像测距主要方法包括逆投影变换、数据回归建模和相机几何模型. 随着图像处理算法的发展,学者利用神经网络强大的端到端学习能力,将图像检测算法与传统测距方法相结合提出测距方法,建立输入与输出之间的非线性复杂关系. 通过图像检测算法预测目标在图中的位置和尺寸信息,并结合相机成像几何关系,实现像素坐标系与世界坐标系的映射转换,实现车辆测距. 例如,Dirgantara 等[12] 提出基于SSD目标检测框架的测距方法,通过神经网络输出的检测框参数作为特征输入,结合线性回归模型实现前方车辆距离估计. Song 等[13]融合多视觉线索,包括2个连续时间单目图像提供的深度特征、场景几何和时间光流线索,进而提出基于深度神经网络训练的车辆间距离和相对速度估计方法. Liu 等[14]提出YOLO 目标检测模型和长短焦距相机相融合的测距方法,通过长、短焦距融合匹配,利用车牌宽度计算实际车辆宽度并估计距离. Liu 等[15]提出基于深度学习的车辆距离估计方法,构建卷积神经网络,并将车辆图像放入网络中训练;从原始图像中检测车牌的位置和距离,结合几何视觉测距原理,实现对前方车辆的定位和距离测量. 但由于车牌的尺寸较小,远距离检测、测距具有局限性. Gao 等[16]提出使用YOLOv4 算法检测车辆前方障碍物,获取障碍物的类别和位置信息,利用改进的边缘检测算法调整检测框的位置,根据相机成像原理和几何关系,通过三维坐标到像平面二维坐标的转换模型实现测距.
基于精确测定的前车距离数据,结合目标跟踪技术提取的连续帧间目标车辆的位置变化,可实时计算前车行驶速度. Czajewski 等[17]将车牌作为特征块,根据连续图像车辆位置之间的垂直差测量车辆速度,但未以特征点所在平面建立坐标系,导致结果误差较大. Arenado 等[18]通过目标检测算法定位前方车辆车牌,建立车牌像素尺寸与实际距离的映射关系模型,再通过分析连续帧图像,计算车辆相对速度. Yang 等[19]从立体视频提取车辆车牌特征,根据立体视觉系统参数和立体视频车辆的视差,计算车辆实际空间位置和连续视频帧间的车速. Yang 等[20]提出基于ECA-yolov4 的车辆多特征检测反打,设计基于后视镜、车灯、车标、车牌的双目立体视觉的车辆多特征测速系统.
诸多学者将深度学习网络与传统测距方法结合实现距离测定,但对特征点被遮挡情况下的研究较少. 针对上述不足,本研究提出基于车辆图像特征的前车距离感知模型与车辆跟踪测速模型.创新研究工作包括:1) 设计车辆特征提取网络,通过卷积、池化、激活函数操作,提取图像中车辆特征,生成车辆特征向量;2) 串联拼接融合多维车辆图像特征向量,建立车辆测距神经网络,端对端学习车辆图像特征与前车距离的非线性复杂关系,构建基于车辆图像特征的前车测距模型,实现前车距离测定; 3) 在YOLOv8n 模型基础上引入小目标检测头,采用Wise-IoU[21] 损失函数,提出SW-YOLOv8n车辆目标检测模型,并结合Bytetrack[22]跟踪网络提取视频帧间信息,提出车辆跟踪测速模型,实现前车速度感知;4) 设计前车无遮挡与遮挡场景下的前车距离感知实验,验证距离感知模型的可行性,设计前车速度感知实验,验证车辆跟踪测速模型稳定性.
1. 车辆目标检测跟踪模型
1.1. SW-YOLOv8n车辆目标检测模型
为了提高车辆目标检测模型的准确率,在YOLOv8n 网络引入小目标检测头,采用Wise-IoU 损失函数,提出SW-YOLOv8n 车辆目标检测模型.
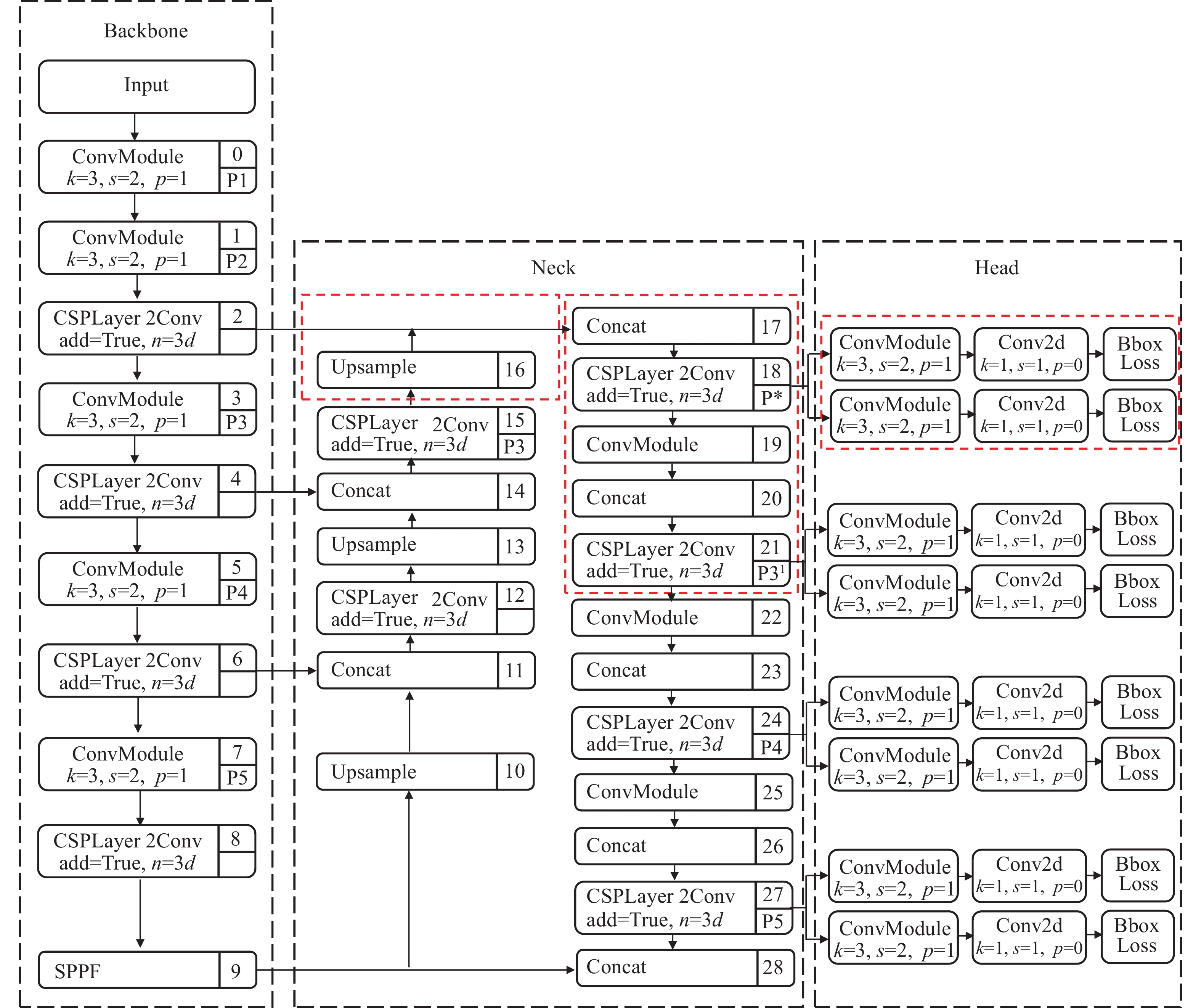
SW-YOLOv8n 结构包括主干特征提取网络 (Backbone) 、特征融合网络 (Neck) 以及检测头 (Head) 3个部分. Backbone 部分负责提取输入图像特征,并传递给后续检测层. Neck 部分引入自顶向下和自底向上的双向融合骨干网络,通过添加 shortcut 连接来缩短层之间的路径,使用自适应特征池化融合不同层次的特征,保证特征的完整性和多样性. 如图1所示为SW-YOLOv8n车辆目标检测模型. 图中,k表示卷积核大小,s表示卷积步长,p表示边缘填充像素数,n表示模块重复次数或深度系数. 在Neck原有结构P3、 P4、 P5 层3个检测头基础上,引入尺寸为160×160的特征图,增加小目标检测层. SW-YOLOv8n 检测头变为P*、P31、P4、P5. 通过增加下采样和拼接操作获得更大的感受野,实现多层级特征图融合;同时,提供小目标语义信息和特征图表示,减少远距离小目标车辆的漏检问题. Head部分采用解耦头结构,将回归分支和预测分支分离,生成目标检测的结果 (预测目标框的坐标和类别),并利用无锚分裂 (Anchor Free) 策略直接预测目标框的位置. SW-YOLOv8n损失函数包括目标分类损失函数和边界框坐标回归损失函数. 目标分类损失采用二元交叉熵损失函数 (BCELoss) ,衡量模型预测目标类别与实际目标类别的差异. 边界框坐标回归损失采用基于动态非单调聚焦机制的Wise-IoU (WIoU) 损失函数,衡量模型目标边界框坐标回归预测和实际边界框间的差异,通过调整预测的边界框位置,减小模型目标检测中的定位误差. WIoU损失函数通过实时梯度增益分配测量,降低低质量锚框产生的有害梯度,同时抑制高质量锚框的竞争力,从而增强模型对普通锚框的专注度. 基于注意力的边界框损失WIoUv1 表达式如下:
图 1
式中:IoU 表示真实目标边界框Bgt和预测框Bpred的重叠程度;RWIoU表示预测框和真实框中心点之间的归一化距离;Wi、Hi表示第i个预测框与真实框相交区域的宽、高;Wg、Hg表示预测框与真实框最小外接框的宽、高;Su表示预测框和真实框的联合区域;(x, y) 表示预测框的中心点坐标,(xgt, ygt) 表示真实框的中心点坐标; * 表示将Wg、Hg 从计算图中分离,消除阻碍收敛的因素.
在城市道路车辆检测中,同向行驶车辆与垂直方向行驶车辆的长宽比例差异较大,且载体车辆与前车的相对距离动态变化,导致目标检测框的尺寸具有不平衡性. WIoU 损失函数能够预测更加精确的目标检测框,为前车距离与速度感知模型提供精确数据.
1.2. 车辆目标跟踪模型
基于深度学习的Bytetrack 多目标跟踪算法,结合SW-YOLOv8n 车辆目标检测模型,形成SW-YOLOv8n-Bytetrack车辆目标检测跟踪网络,原理如图2所示. 视频帧通过SW-YOLOv8n 车辆检测模型获取检测结果 (车辆检测框及置信度). 根据置信度,将检测框分为高得分集合Dhigh (置信度≥ 0.6) 和低得分集合Dlow. Dhigh 中的检测框与轨迹通过匈牙利算法进行首次匹配,匹配成功则更新卡尔曼滤波状态,并将检测框加入对应轨迹集合;若未匹配成功检测框的置信度高于跟踪得分阈值,则初始化新轨迹,否则直接忽略;未匹配的轨迹与Dlow 中的检测框进行第2次匹配,匹配成功则更新卡尔曼滤波并存入轨迹集合;对于未匹配的低分检测框 (置信度< 0.1),直接剔除;未匹配轨迹若持续超过 30 帧未更新则删除,否则继续更新卡尔曼滤波状态并保留.
图 2

图 2 SW-YOLOv8n-Bytetrack 跟踪原理
Fig.2 Tracking principle of SW-YOLOv8n-Bytetrack
2. 前方车辆测距与测速模型
2.1. 单目相机成像原理
相机成像是将三维世界中的物体通过数学模型映射到二维成像平面的过程,原理如图3所示.
图 3
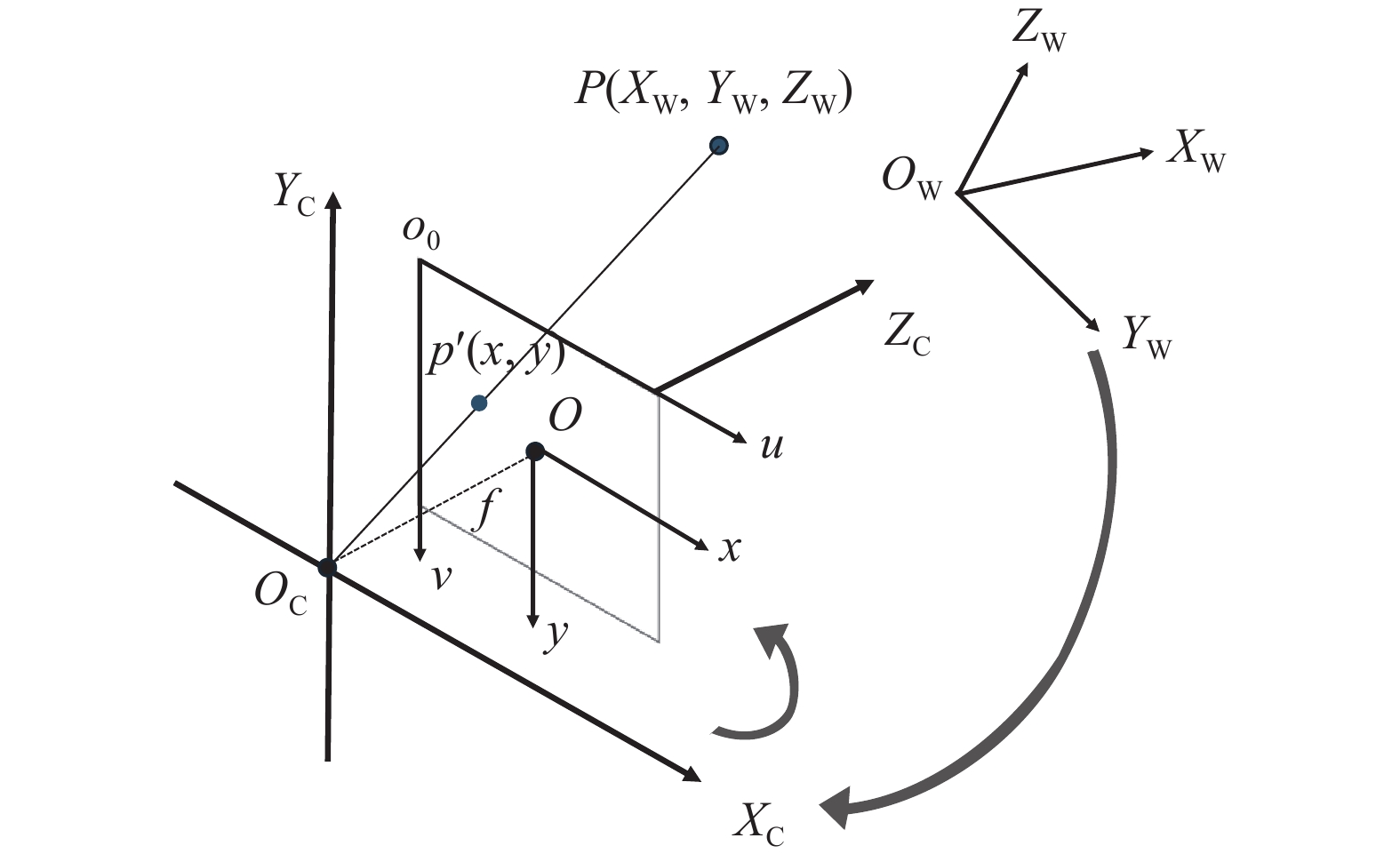
转换过程涉及世界坐标系
式中:
2.2. 车辆横纵距离几何算法
基于单目视觉成像原理,通过世界坐标系到像素坐标系的几何变换关系,建立三维场景与二维图像的投影映射模型. 利用相机标定获取的内参矩阵,结合相机外部参数,建立车辆横纵距离几何算法.
车辆横纵距离几何模型如图4所示,在SW-YOLOv8n 模型中输入视频帧图像,输出被检测车辆的类别、类别置信度、检测框左上角顶点坐标
图 4
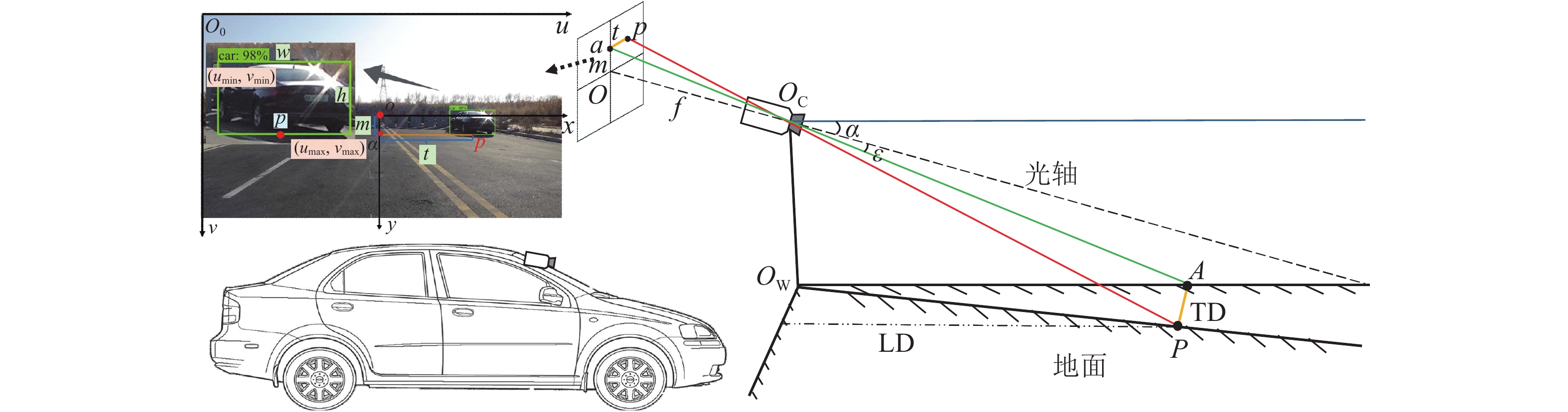
图 4 车辆横纵距离几何模型
Fig.4 Geometric model of vehicle transverse and longitudinal distance
式中:H表示相机安装高度;t 表示 a 点到 p 点的水平距离,t = (u−u0) dx;m 表示 a 点到图像中心点 O的垂直距离,m = (v−v0) dy.
2.3. 基于车辆图像特征的前方车辆测距模型
随着计算机视觉技术的发展,深度学习算法能够识别和检测图像或视频中的车辆,并精确地计算2辆车之间的实际距离. 该技术对提升驾驶安全性、优化交通流管理及自动驾驶车辆的决策具有重要意义. 在SW-YOLOv8n 模型中输入视频帧图像,输出目标车辆的检测框信息,作为车辆图像位置特征;车辆图像经预处理后,利用车辆特征提取网络提取车辆特征向量;通过横纵距离几何算法计算相对前方车辆的横纵距离特征;最后,构建基于车辆图像特征的前方车辆测距模型,将车辆图像特征串联拼接融合,车辆测距神经网络基于融合数据进行训练推理,实现前方车辆距离感知. 测距模型流程如图5所示.
图 5
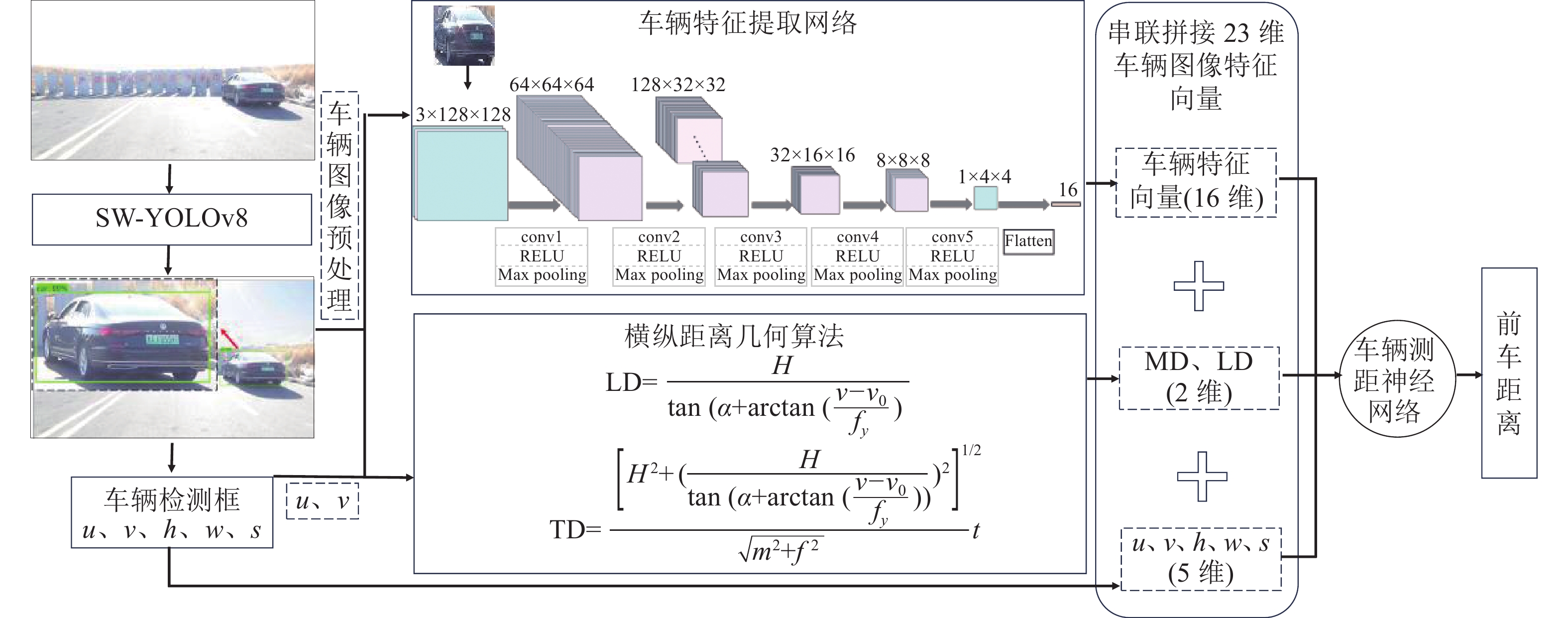
图 5 基于车辆图像特征的前方车辆测距模型流程
Fig.5 Process of front vehicle ranging model based on vehicle image features
2.3.1. 车辆特征提取网络
相机安装在车辆上的高度、角度固定,相机的内部参数保持一致. 当相对前方车辆的横、纵距离改变时,前方车辆的像素大小和呈现特征均具有差异性. 通过车辆特征提取网络获取车辆特征向量,为前车距离感知提供数据.
车辆特征提取网络为卷积神经网络,基于卷积操作和池化操作,逐层提取和组合车辆特征,形成抽象、具判别力的特征表示. 如图5所示,图像预处理后,尺寸调整为3×128×128. 经过5个卷积层进行卷积操作,提取车辆图像多层次特征. 其中,conv1、conv2、 conv3、 conv4、conv5 分别包含64、128、32、8、4个卷积核. conv1 提取图像边缘、纹理特征,帮助网络学习图像局部特征;conv2 在图像中挖掘复杂的特征,提取高级别特征;conv3、conv4 和cconv5 执行降维操作,通过降低通道数,减小网络复杂度. 卷积后应用最大池化层逐渐减小特征图的尺寸,降低计算复杂度. 采用 ReLU (Rectified Linear Unit) 激活函数引入非线性性质,对每个卷积核的输出进行非线性变换,使网络能够学习复杂特征. 最后对车辆特征图展平处理,生成16维车辆特征向量.
2.3.2. 车辆测距神经网络
车辆测距神经网络由6个全连接层组成,构造如图6所示. 将串联拼接融合后的23维车辆图像特征向量输入车辆测距神经网络,为车辆测距神经网络输入层提供原始数据. 输入层包含23个神经元,将输入数据转换为适合神经网络处理的形式. 全连接层F1、F2、F3、F4 分别包含32、48、16、8个神经元,输出层包含1个神经元,输出相机到被测车辆的实际距离. 全连接层通过权重矩阵和偏置向量对输入数据进行线性变换,每个神经元都与前一层的所有输出相连,通过对输入特征的线性组合与偏置项的叠加,实现特征的线性组合. 通过 ReLU 激活函数引入非线性性质,捕捉数据中的复杂模式,提取数据高级特征,有助于对输入数据的抽象表示.
图 6

车辆测距神经网络为前馈神经网络,用于回归任务,分为训练和推理2个阶段. 在训练阶段,将 23维车辆图像特征向量输入车辆测距神经网络,网络学习从输入数据到输出距离的复杂映射,生成最优权重参数模型. 在推理阶段,加载训练好的模型最优权重参数模型,将前方目标车辆的23维车辆图像特征数据传递给网络,完成前向传播,以获取相机相对前方目标车辆的实际距离.
针对不同类型的车辆,调整神经网络结构的层数与每层网络的深度和宽度,适应前方车辆距离感知任务和数据集需求. 通过反向传播算法,模型参数在训练数据上不断优化,获得最佳车辆距离估计.
2.4. 车辆跟踪测速模型
车辆测速技术是车辆外部环境感知的关键,为智能交通系统提供数据支持,提高道路交通的安全和效率. 基于SW-YOLOv8n-Bytetrack车辆目标检测跟踪网络,提出车辆跟踪测速模型. 通过分析视频帧的动态特性与帧间距离,估计车辆速度,保障道路安全、优化交通流、提升交通系统的整体性能. 采用视频作为输入数据,利用SW-YOLOv8n 模型获取第 i 帧和 i+n 帧图像的车辆检测结果. 将检测结果输入前方车辆测距模型中,输出第 i 帧、第 i+n 帧相机相对车辆的距离分别为 Di、Di+n. 利用Bytetrack目标跟踪算法在相邻帧之间建立车辆的运动轨迹,实现前方目标车辆的实时跟踪. 根据帧间信息,计算前方目标车辆的速度,流程如图7所示.
图 7
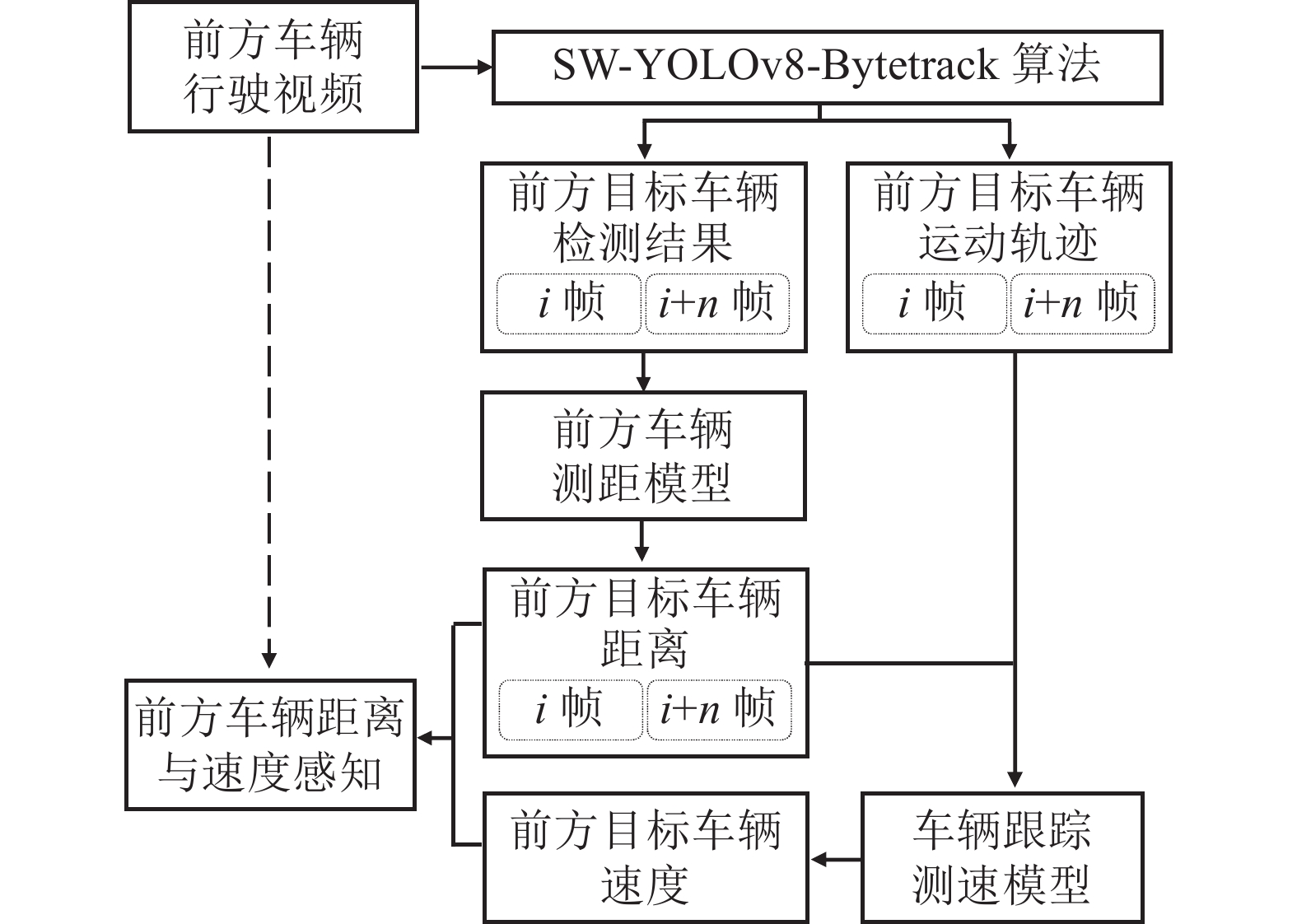
通过 OpenCV 获取视频帧帧率 F (单位为Hz或S−1),并设相机载体车辆的速度为 vz (单位为km/h).
综合所述参数,推导前方目标车辆相对平均速度表达式如下:
推导前方目标车辆实际速度表达式如下:
3. 实验及验证
实验操作系统为 Windows10 64位;实验硬件CPU 为 Intel (R) i9-10900K CPU@370 GHz,GPU 为NVIDIA GeForce RTX
车辆目标检测的输出结果为基于车辆图像特征的前车距离与速度感知模型的数据输入基础. 如图8所示,视频帧通过 SW-YOLOv8n-Bytetrack 网络,生成目标车辆的ID、车辆类别和车辆目标检测框信息. 根据第 i 帧和第 i+n 帧车辆检测框坐标位置特征,计算车辆横纵距离特征. 预处理车辆图像,输入车辆特征提取网络提取车辆特征. 将车辆图像特征串联拼接融合为23维特征向量,输入基于车辆图像特征的车辆测距模型,测定第 i 帧和第 i+n 帧的相机到前车的实际距离. 根据跟踪结果提取帧间信息,利用车辆跟踪测速模型计算前方车辆速度,实现前方车辆距离和速度感知.
图 8

图 8 基于车辆图像特征的前车距离与速度感知流程
Fig.8 Process of front vehicle distance and speed perception based on vehicle image features
3.1. 目标检测实验
3.1.1. 数据集及预处理
实验数据集由 BDD 100K图像数据集和自建数据集组成,共
图 9

为了增强模型泛化能力,随机抽取部分实验数据集进行裁剪、色彩抖动、高斯噪声等数据增强操作,将实验数据集扩充至
3.1.2. 目标检测评价指标
基于车辆图像特征的前车距离与速度感知模型的输入数据依赖于车辆图像检测输出,车辆目标检测模块须同时满足高精度和实时性的技术指标. 目标检测实验选取召回率 Recall、平均精度 mAP、每秒帧数 FPS作为评价指标. Recall 表示预测为正例的样本中,预测正确的正例样本数占实际正例样本总数的比例;AP表示单个类别平均精准度,为 P-R 曲线所占面积,mAP50为所有检测类别在IoU = 0.50时的平均精度;mAP50−90为所有检测类别在IoU从0.50到0.95的平均精度. 具体表达式如下:
式中:P 表示精确率,TP 表示真正例,FP表示假正例,FN表示假反例,K 表示类别数,FT 表示总帧数,TC 表示检测时间.
3.1.3. 实验结果及分析
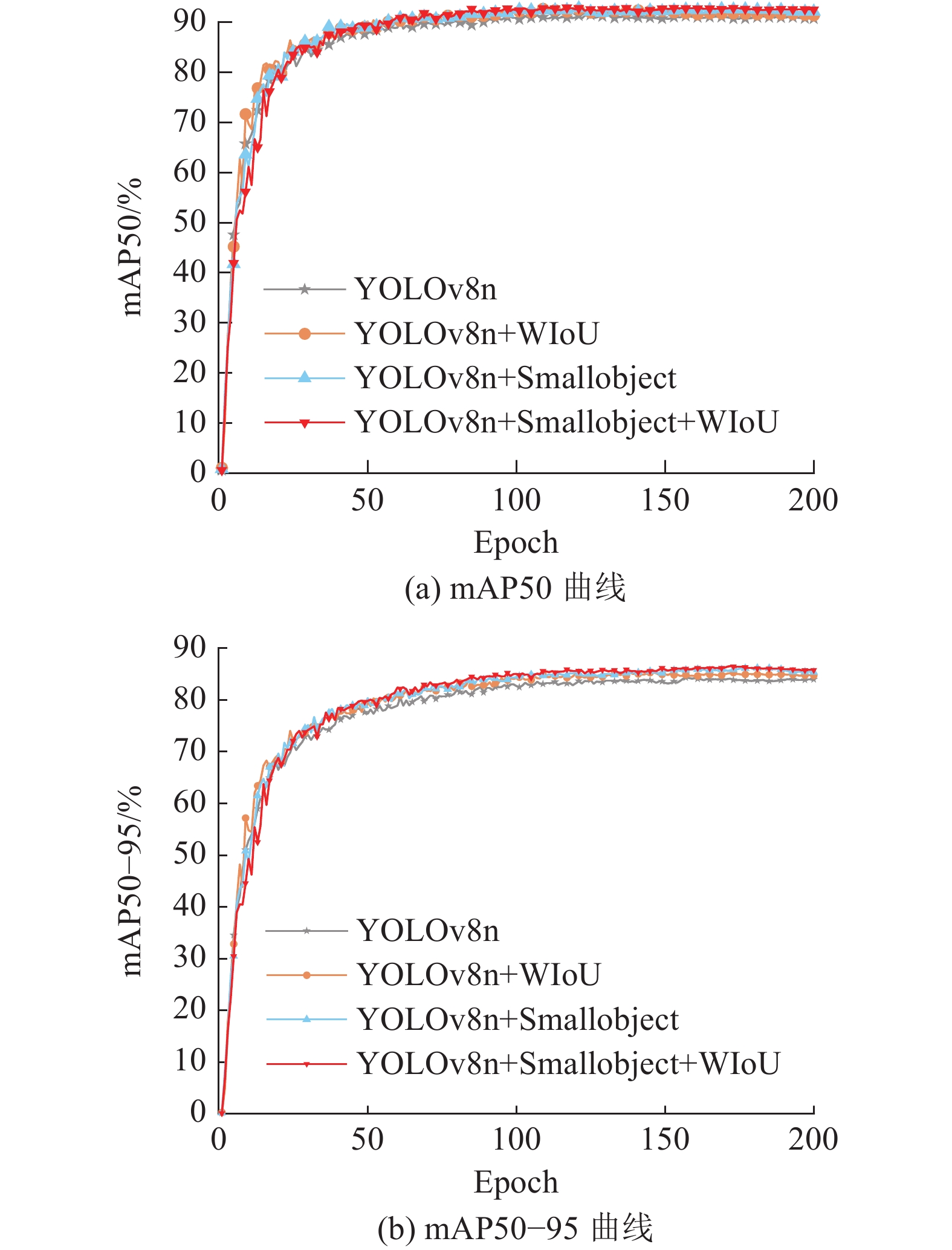
为了验证SW-YOLOv8n 车辆目标检测模型性能,将消融与对比实验中的训练超参数保持一致. 采用经验值作为模型超参数的取值,训练总轮数为 200,训练批次大小为8,图像输入尺寸为 640×640,采用随机梯度下降算法 (SGD) 优化器,初始学习率设置为 0.01,动量因子设置为0.9,重衰减学习率设置为 0.000 1.
表 1 SW-YOLOv8n模型的消融实验
Tab.1
| 模型结构 | Recall/% | mAP50/% | mAP50−95/% | FPS |
| YOLOv8n | 83.10 | 91.20 | 84.30 | 226.48 |
| YOLOv8n+WIoU | 84.40 | 92.30 | 85.40 | 229.60 |
| YOLOv8n+Smallobject | 85.30 | 92.50 | 86.10 | 258.10 |
| YOLOv8n+Smallobject+ WIoU | 87.50 | 92.80 | 86.60 | 260.11 |
图 10
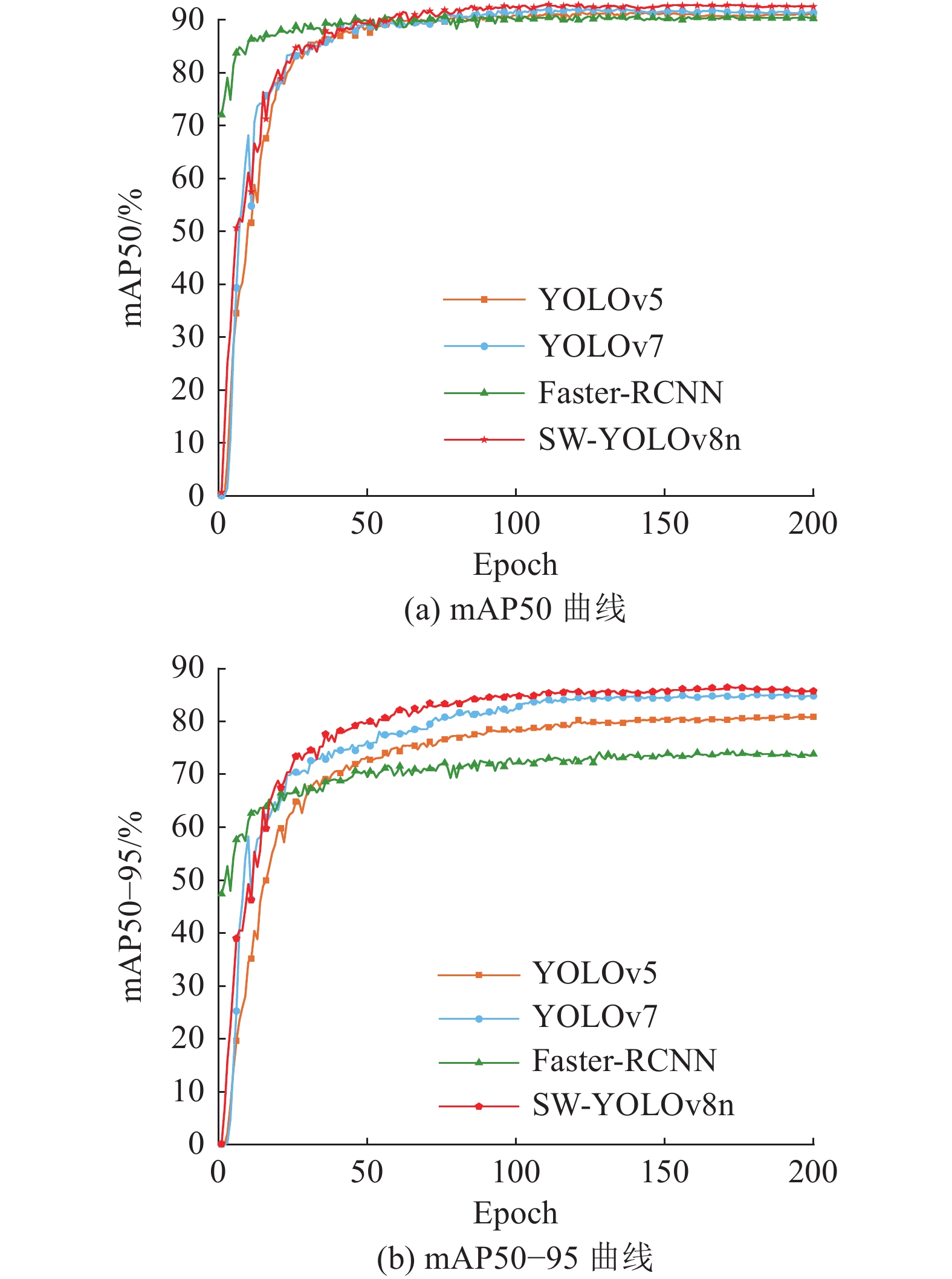
2) 对比实验. 在硬件条件、计算机环境配置、初始参数设置等实验环境相同的情况下,选取单阶段目标检测模型 YOLOv5、YOLOv7[25],两阶段目标检测模型 Faster-RCNN[26],与SW-YOLOv8n 模型进行对比实验. 实验结果如表2所示,曲线如图11所示. 可以看出,在检测精度方面,SW-YOLOv8n 模型的mAP50 分别比YOLOv5、YOLOv7、Faster-RCNN 的高1.8、1.4、2.6个百分点,mAP50−95 分别比YOLOv5、YOLOv7、Faster-RCNN的高5.6、2.0、14.0个百分点;在检测速度方面,SW-YOLOv8n 模型的 FPS 比 YOLOv5 模型的低86.67,比YOLOv7 模型的高143.8;在模型大小M方面 ,YOLOv5 模型最小,YOLOv7 、Faster-RCNN、SW-YOLOv8n模型的大小分别为74.8、521.0、6.3 MB. 车辆目标检测结果须为前车距离与速度感知提供重要数据,综合考虑实时性、准确性与轻量化因素,选取 SW-YOLOv8n 作为车辆目标识别检测模型.
表 2 SW-YOLOv8n模型的对比实验结果
Tab.2
| 模型 | Recall/% | mAP50/% | mAP50−95/% | FPS | M/MB |
| YOLOv5 | 83.80 | 91.00 | 81.00 | 346.78 | 3.9 |
| YOLOv7 | 83.90 | 91.40 | 84.60 | 116.27 | 74.8 |
| Faster-RCNN | 79.78 | 90.20 | 72.60 | 26.67 | 521.0 |
| SW-YOLOv8n | 87.50 | 92.80 | 86.60 | 260.11 | 6.3 |
图 11
3.2. 前车距离与速度感知实验
3.2.1. 相机标定
相机标定是通过建立世界坐标系三维点与成像平面二维点的映射关系,确定相机的内部参数和外部参数,实现二维图像坐标到三维世界坐标的转换. 实验相机标定采用张氏标定法,选用索尼HDR-CX680相机 (镜头焦距为1.9 mm),并采用规格为12×9 (单元格边长为30 mm) 的棋盘格标定板,通过提取棋盘格角点作为特征点完成标定过程.
固定相机位置,改变棋盘的方位、角度捕捉图像,共拍摄20张图像. 正向、上倾斜45°、下倾斜45°、旋转90°的部分图像样例如图12所示.
图 12

通过 OpenCV 标定工具箱获取内角点的坐标,并将坐标传递给 Calibrate Camera 函数,获得相机的内部参数 fx 、fy、u0、v0 分别为
3.2.2. 数据集
为了使实验过程更接近真实的交通场景, 采用静态与动态结合的方式,采集真实道路数据构建前车距离与速度感知数据集. 安装静态单目相机,高度为1.4 m,俯仰角为2°.
1) 测距数据集. 前方车辆测距实验数据来自真实道路静态采集,单目相机相对目标车辆左方横向偏移0 ~9.5 m且纵向在5 ~50 m范围内,在前车未被遮挡与有遮挡场景下分别测得80组实验数据. 其中,在前车未被遮挡场景中随机划分65组数据为训练集,15组数据为验证集. 在前车有遮挡场景中随机划分70组数据为训练集,10组数据为验证集. 每组实验数据由2部分组成:通过单目相机拍摄的车辆图像;使用激光测距仪、卷尺作为测距工具测得的相机与车辆的实际距离.
2) 测速数据集. 前方车辆测速实验场景选取真实道路动态采集,设置相机相对前车3种横向距离. 实验车辆分别以仪表盘10、20、30 km/h的速度匀速直线行驶,并在实验车辆的行驶路段进行距离标记. 实验数据由2部分组成:车辆仪表盘测得实验车辆的行驶速度;单目相机拍摄的实验车辆行驶视频. 视频帧跟踪结果示例如图13所示.
图 13

3.2.3. 实验测试及分析
为了验证基于车辆图像特征的前方车辆测距模型与车辆跟踪测速模型的有效性和可行性,在真实封闭道路开展前方车辆测距和测速实验并进行结果分析.
1) 前方车辆测距实验分析. 为了验证基于车辆图像特征的前方车辆测距模型在驾驶场景的适用性,针对前车无遮挡与前车有遮挡2种场景展开测距实验误差分析.
在前车无遮挡场景下,借鉴文献[24]的车辆测距实验结果分析,可知车辆横纵距离几何算法能够有效计算相机相对车辆的横向、纵向距离,供车辆测距神经网络训练、推理. 在前车有遮挡场景下,对车辆横纵距离几何算法进行误差分析. 训练集车辆图像经过SW-YOLOv8n模型输出车辆检测框坐标,通过式(3)~(6) 计算车辆特征点坐标 (u, v)、检测框的高 h、宽w及面积. 将特征点坐标、相机标定得到的内部参数以及外部参数代入式 (7)、(8) ,计算相机相对前方目标车辆的横向、纵向距离. 根据真实测量的横向、纵向距离计算误差. 根据实际横向距离不同,将前车有遮挡条件下的训练集分为5个实验组,相机相对车辆实际横纵距离与几何算法计算结果之间的误差如图14所示. 图中,xtra、xlon为实际横向、纵向距离,
图 14

图 14 相机相对车辆实际横纵距离与几何算法计算结果的误差图
Fig.14 Error between camera measurements and geometric calculations for vehicle transverse and longitudinal distances
车辆测距神经网络训练集和测试集数据来自真实道路场景,旨在评估模型的准确性. 基于前车无遮挡和有遮挡场景采集的测距实验数据,通过图像裁剪、特征提取及多帧融合处理,构建车辆测距数据集. 将车辆图像通过 SW-YOLOv8n 模型进行检测,得到车辆检测框角点坐标 (umin, vmin)、(umax, vmax). 将角点坐标代入式 (3)~(6) 得到车辆图像特征信息特征点坐标 (u, v)、检测框的高 h、宽 w、面积 s. 特征点坐标与相机内外参数代入式 (7)、(8) 得到相机与车辆横纵距离特征 TD 与 LD. 进行预处理,将车辆图像输入车辆特征提取网络提取车辆16维特征向量. 采用串联拼接方法,将数据融合为23维车辆图像特征向量,分别构建无遮挡和有遮挡条件下的测距数据集. 在测距神经网络模型中,创建自定义数据集类 CustomDataset 加载训练数据,并将其组织为数据加载器 DataLoader. 数据加载器同时读取车辆图像特征向量和实际测距真值,支持批量数据处理,以实现神经网络的端到端训练.
为了提升特征学习精度,采用小批量训练策略(batch_size=1),使用Adam优化器 (学习率为
图 15
如表3表示为无遮挡场景下前车距离感知模型测定距离及误差. 表中,CD表示几何算法计算的距离;AD表示使用测距工具测得的相机与车辆的实际距离;ED表示前车距离感知模型的测定距离;AE表示前车距离感知模型的测定距离与实际测得距离的绝对误差,RE表示相对误差;RE[24]表示文献[24]测距方法与实际测得距离的相对误差. 数据表明,在无遮挡条件下,前车距离感知模型测距最大误差为
表 3 无遮挡场景下前车距离感知模型的测定距离及误差
Tab.3
| No. | u | v | h | w | s | CD/m | AD/m | ED/m | AE/m | RE/% | RE[24]/% | |
| TD | LD | |||||||||||
| 1 | 962.00 | 629.00 | 170.00 | 206.0 | 6.72 | 4.45 | ||||||
| 2 | 981.00 | 574.50 | 85.00 | 102.00 | 0.32 | 0.71 | ||||||
| 3 | 962.00 | 551.00 | 58.00 | 76.00 | 1.632 | 0.60 | ||||||
| 4 | 660.50 | 162.00 | 269.00 | 0.11 | 0.91 | |||||||
| 5 | 547.50 | 88.00 | 116.50 | 0.67 | 0.93 | |||||||
| 6 | 538.50 | 48.00 | 65.50 | 2.14 | 0.61 | |||||||
| 7 | 655.50 | 167.50 | 364.00 | 6.74 | 1.13 | |||||||
| 8 | 561.00 | 74.00 | 114.00 | 2.27 | 0.36 | |||||||
| 9 | 534.50 | 42.00 | 64.00 | 0.56 | 0.49 | |||||||
| 10 | 566.00 | 71.50 | 157.50 | 0.86 | 1.40 | |||||||
| 11 | 547.00 | 58.00 | 102.00 | 1.34 | 0.61 | |||||||
| 12 | 534.00 | 47.00 | 72.00 | 1.61 | 0.64 | |||||||
| 13 | 736.00 | 242.00 | 364.00 | 0.44 | 2.03 | |||||||
| 14 | 605.00 | 109.00 | 161.00 | 2.49 | 0.12 | |||||||
| 15 | 627.00 | 137.00 | 257.00 | 0.10 | 0.51 | |||||||
| 均值 | — | — | — | — | — | — | — | — | — | 1.87 | 1.03 | |
如表4表示有遮挡条件下前车距离感知模型测定距离及误差. 数据表明,在前车存在遮挡的条件下,测试集预测距离最大误差为
表 4 有遮挡条件下前车距离感知模型测定距离及误差
Tab.4
| No. | u | v | h | w | s | CD/m | AD/m | ED/m | AE/m | RE/% | RE[24]/% | |
| TD | LD | |||||||||||
| 1 | 982.48 | 849.75 | 332.68 | 395.27 | 6.08 | 8.74 | ||||||
| 2 | 951.33 | 597.19 | 118.05 | 143.46 | 1.08 | 3.38 | ||||||
| 3 | 952.24 | 539.05 | 56.38 | 70.22 | 1.02 | 0.61 | ||||||
| 4 | 712.81 | 239.07 | 395.06 | 1.97 | 9.80 | |||||||
| 5 | 598.12 | 129.93 | 187.94 | 3.51 | 3.15 | |||||||
| 6 | 539.32 | 59.12 | 75.40 | 1.27 | 1.29 | |||||||
| 7 | 631.37 | 175.29 | 330.61 | 0.70 | 3.18 | |||||||
| 8 | 562.54 | 85.78 | 134.89 | 0.20 | 2.29 | |||||||
| 9 | 612.01 | 137.74 | 283.90 | 3.46 | 6.16 | |||||||
| 10 | 545.34 | 46.98 | 71.44 | 0.93 | 2.84 | |||||||
| 均值 | — | — | — | — | — | — | — | — | — | 2.02 | 4.28 | |
2) 前方车辆测速实验分析. 实验采用真实道路场景下的动态车辆视频数据,测试车辆分别以10、20 、30 km/h (基于仪表盘显示速度) 的恒定速度行驶,验证和评估车辆跟踪测速模型性能. 通过OpenCV 获取目标车辆测速的视频帧率为30.0 Hz. 为了保证实验车辆为稳定行驶状态,选取视频中间区域帧区间进行实验分析. 将选取帧的图像输入SW-YOLOv8n模型,获得车辆在图像中位置特征;根据检测框提取车辆图像中的车辆特征向量,计算车辆横纵距离特征TD与LD. 串联拼接融合车辆图像特征向量,将其输入基于车辆图像特征的车辆测距模型,测定第 i 帧和第 i+n 帧的相机到前车的实际距离,将测定结果代入式 (9)、(10),得到前车行驶速度,结果如表5所示. 表中,LDD表示相机相对前车的3种横向距离,MS表示车辆跟踪测速模型测定速度,AS表示平均速度,n表示间隔帧数,
表 5 车辆跟踪测速模型的测速结果
Tab.5
| vc=10 km/h | vc=20 km/h | vc=30 km/h | ||||||||||||||
| LDD/m | n | ∆s/m | MS/ (km·h−1) | AS/ (km·h−1) | LDD/m | n | ∆s/m | MS/ (km·h−1) | AS/ (km·h−1) | LDD/m | n | ∆s/m | MS/(km·h−1) | AS/ (km·h−1) | ||
| 0 | 10 | 0 | 10 | 0 | 10 | |||||||||||
| 0 | 1 | — | 0 | 1 | — | 0 | 1 | — | ||||||||
| 2.0 | 10 | 3.5 | 10 | 3.5 | 10 | |||||||||||
| 2.0 | 1 | — | 3.5 | 1 | — | 3.5 | 1 | — | ||||||||
| 6.5 | 10 | 7.0 | 10 | 7.0 | 10 | |||||||||||
| 6.5 | 1 | — | 7.0 | 1 | — | 7.0 | 1 | — | ||||||||
为了进一步评估模型测速的稳定性,以10帧为单位选取车辆相邻帧区间进行结果分析,并选取相邻2帧计算车辆瞬时速度. 结果表明,在vc=10~30 km/h的车速范围内,在横向距离与车速相同的条件下,模型测得的最大与最小速度之间的最大差值为1.10 km/h,最小差值为0.69 km/h. 通过相邻2帧测得的车辆瞬时速度与区间平均速度的最大、最小差值分别为0.07、0.90 km/h. 实验结果表明,基于多场景视频数据的测试验证,车辆跟踪测速模型能够在前方目标车辆速度测量中保持稳定的性能表现.
Yang等[19]通过使用双目立体视觉确定每帧的车辆位置,根据帧间位置和距离计算车速,误差范围为[−1.6, 1.1] km/h. Yang等[20]使用改进的ECA-YOLOv4目标检测算法检测车牌、车标、车灯3种车辆特性,并设计车辆多特征检测速度测量系统. 实验结果表明,当车辆以46 km/h行驶时,3个特征点均未遮挡时的误差范围为[−0.77, 1.65] km/h. 但3个特征点都位于车辆偏下位置,特征点被遮挡时该测速方法准确性不足. 由于本研究未使用精确测速仪器测定车辆速度,不能说明其准确性,仅可从稳定性角度分析,且实验数据最小与最大速度之差的最大值为1.1 km/h,在文献[19]、[20]的误差范围内.
4. 结 论
基于几何算法的前车距离测定方法与基于深度学习的特征点距离测定方法,均受到遮挡因素的干扰. 为了弱化遮挡条件下单一信息源产生的误差,本研究基于优化的车辆目标检测算法,融合多维车辆图像特征,提出基于车辆图像特征的前车距离与速度感知方法.
(1) 串联融合车辆在图像中的位置特征、车辆横纵距离几何特征、提取的车辆特征作为车辆图像特征,设计车辆测距神经网络,构建基于车辆图像特征的前车测距模型,实现前车距离感知.
(2) 根据前车测距模型测定的车辆距离变化与SW-YOLOv8n-Bytetrack 车辆目标检测跟踪网络提供的帧间信息,提出基于车辆距离变化的车辆跟踪测速模型,实现前车速度感知.
(3) 选取封闭道路场景,设计动态静态结合实验,验证基于车辆图像特征的前车测距模型的准确性与车辆跟踪测速模型的稳定性.
(4) 在多元复杂环境下(如恶劣天气、拥堵路段及路口),前车距离的数据采集工作面临挑战,限制了测距模型在多元化复杂场景中的泛化效能与环境适应能力的验证. 后续工作须继续完善数据缺口,增强数据多样性与质量,提升基于车辆图像特征的前车测距模型的鲁棒性.
参考文献
A review of vehicle detection techniques for intelligent vehicles
[J].DOI:10.1109/TNNLS.2021.3128968 [本文引用: 1]
An intelligent traffic detection approach for vehicles on highway using pattern recognition and deep learning
[J].DOI:10.1007/s00500-022-07375-3 [本文引用: 1]
UAV target detection algorithm based on improved YOLOv8
[J].DOI:10.1109/ACCESS.2023.3325677 [本文引用: 1]
CR-YOLOv8: multiscale object detection in traffic sign images
[J].
LAYN: lightweight multi-scale attention YOLOv8 network for small object detection
[J].DOI:10.1109/ACCESS.2024.3368848 [本文引用: 1]
基于深度学习的视觉单目标跟踪综述
[J].
Survey on visual single object tracking based on deep learning
[J].
改进YOLOv7+Bytetrack的小目标检测与追踪
[J].DOI:10.3778/j.issn.1002-8331.2311-0372 [本文引用: 1]
Improved small target detection and tracking with YOLOv7+Bytetrack
[J].DOI:10.3778/j.issn.1002-8331.2311-0372 [本文引用: 1]
YOLO-BYTE: an efficient multi-object tracking algorithm for automatic monitoring of dairy cows
[J].DOI:10.1016/j.compag.2023.107857 [本文引用: 1]
Sensing and machine learning for automotive perception: a review
[J].DOI:10.1109/JSEN.2023.3262134 [本文引用: 1]
中国汽车工程学术研究综述·2023
[J].
Review on China’s automotive engineering research progress: 2023
[J].
Vehicle detection and ranging using two different focal length cameras
[J].
Distance measurement method for obstacles in front of vehicles based on monocular vision
[J].DOI:10.1088/1742-6596/1815/1/012019 [本文引用: 3]
Monovision-based vehicle detection, distance and relative speed measurement in urban traffic
[J].DOI:10.1049/iet-its.2013.0098 [本文引用: 1]
Vehicle speed measurement based on binocular stereovision system
[J].DOI:10.1109/ACCESS.2019.2932120 [本文引用: 3]
Robust vehicle speed measurement based on feature information fusion for vehicle multi-characteristic detection
[J].DOI:10.3390/e23070910 [本文引用: 3]
A flexible new technique for camera calibration
[J].DOI:10.1109/34.888718 [本文引用: 1]
基于深度学习的车载图像车辆目标检测和测距
[J].
Vehicle target detection and ranging in vehicle image based on deep learning
[J].
Faster R-CNN: towards real-time object detection with region proposal networks
[J].DOI:10.1109/TPAMI.2016.2577031 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}