[1]
ZHANG H, YANG Z, ZHANG L, et al Super-resolution reconstruction for multi-angle remote sensing images considering resolution differences
[J]. Remote Sensing , 2014 , 6 (1 ): 637 - 657
DOI:10.3390/rs6010637
[本文引用: 1]
[2]
PAPATHANASSIOU C, PETROU M. Super resolution: an overview [C]// IEEE International Geoscience and Remote Sensing Symposium . Seoul: IEEE, 2005: 5655-5658.
[本文引用: 1]
[3]
GLASNER D, BAGON S, IRANI M. Super-resolution from a single image [C]// IEEE 12th International Conference on Computer Vision . Kyoto: IEEE, 2009: 349-356.
[本文引用: 1]
[4]
DONG C, LOY C C, HE K, et al Image super-resolution using deep convolutional networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 38 (2 ): 295 - 307
[5]
LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops . Honolulu: IEEE, 2017: 136-144.
[本文引用: 1]
[6]
BEGIN I, FERRIE F R. Blind super-resolution using a learning-based approach [C]// Proceedings of the 17th International Conference on Pattern Recognition . Cambridge: IEEE, 2004: 85-89.
[本文引用: 1]
[7]
JOSHI M V, CHAUDHURI S, PANUGANTI R A learning-based method for image super-resolution from zoomed observations
[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) , 2005 , 35 (3 ): 527 - 537
DOI:10.1109/TSMCB.2005.846647
[8]
CHAN T M, ZHANG J. An improved super-resolution with manifold learning and histogram matching [C]// Advances in Biometrics: International Conference . Hong Kong: Springer, 2005: 756-762.
[本文引用: 1]
[9]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [C]// International Conference on Learning Representations . Ethiopia: [s. n.], 2020.
[本文引用: 1]
[10]
DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// 13th European Conference on Computer Vision . Switzerland: Springer, 2014: 184-199.
[本文引用: 1]
[11]
KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1646-1654.
[本文引用: 1]
[12]
LI W, ZHOU K, QI L, et al Lapar: linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond
[J]. Advances in Neural Information Processing Systems , 2020 , 33 : 20343 - 20355
[本文引用: 1]
[13]
LIANG J, CAO J, SUN G, et al. Swinir: image restoration using swin transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 1833-1844.
[本文引用: 2]
[14]
CHEN H, WANG Y, GUO T, et al. Pre-trained image processing transformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 12299-12310.
[本文引用: 1]
[15]
LEI S, SHI Z, ZOU Z Super-resolution for remote sensing images via local–global combined network
[J]. IEEE Geoscience and Remote Sensing Letters , 2017 , 14 (8 ): 1243 - 1247
DOI:10.1109/LGRS.2017.2704122
[本文引用: 1]
[16]
PAN Z, MA W, GUO J, et al Super-resolution of single remote sensing image based on residual dense backprojection networks
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2019 , 57 (10 ): 7918 - 7933
DOI:10.1109/TGRS.2019.2917427
[本文引用: 1]
[17]
ZHANG D, SHAO J, LI X, et al Remote sensing image super-resolution via mixed high-order attention network
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2020 , 59 (6 ): 5183 - 5196
[本文引用: 1]
[18]
BAI J, YUAN L, XIA S T, et al. Improving vision transformers by revisiting high-frequency components [C]// European Conference on Computer Vision . Cham: Springer, 2022: 1-18.
[本文引用: 1]
[19]
ELAD M, FEUER A Restoration of a single superresolution image from several blurred, noisy, and undersampled measured images
[J]. IEEE Transactions on Image Processing , 1997 , 6 (12 ): 1646 - 1658
DOI:10.1109/83.650118
[本文引用: 1]
[20]
LIU C, SUN D On Bayesian adaptive video super resolution
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2013 , 36 (2 ): 346 - 360
[本文引用: 1]
[21]
ZHANG K, LIANG J, VAN GOOL L, et al. Designing a practical degradation model for deep blind image super-resolution [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 4791-4800.
[本文引用: 2]
[22]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 10012-10022.
[本文引用: 1]
[23]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. [2024-05-15]. https://arxiv.org/abs/1706.03762.
[本文引用: 1]
[24]
ZAMIR S W, ARORA A, KHAN S, et al. Restormer: efficient transformer for high-resolution image restoration [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 5728-5739.
[本文引用: 1]
[25]
XIA G, HU J, HU F, et al AID: a benchmark data set for performance evaluation of aerial scene classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2017 , 55 (7 ): 3965 - 3981
DOI:10.1109/TGRS.2017.2685945
[本文引用: 1]
[26]
DAI D, YANG W Satellite image classification via two-layer sparse coding with biased image representation
[J]. IEEE Geoscience and Remote Sensing Letters , 2010 , 8 (1 ): 173 - 176
[本文引用: 1]
[27]
TANCHENKO A Visual-PSNR measure of image quality
[J]. Journal of Visual Communication and Image Representation , 2014 , 25 (5 ): 874 - 878
DOI:10.1016/j.jvcir.2014.01.008
[本文引用: 1]
[28]
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity
[J]. IEEE Transactions on Image Processing , 2004 , 13 (4 ): 600 - 612
DOI:10.1109/TIP.2003.819861
[本文引用: 1]
[29]
ZHANG W, LI X, SHI G, et al. Real-world image super-resolution as multi-task learning [J]. Advances in Neural Information Processing Systems , 2023, 36: 21003-21022.
[本文引用: 1]
[30]
WANG X, XIE Liangbin, DONG C, et al. Real-esrgan: training real-world blind super-resolution with pure synthetic data [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 1905-1914.
[本文引用: 1]
[31]
MOU C, WU Y, WANG X, et al. Metric learning based interactive modulation for real-world super-resolution [C]// European Conference on Computer Vision . Cham: Springer, 2022: 723-740.
[本文引用: 1]
[32]
WEI P, XIE Z, LU H, et al. Component divide-and-conquer for real-world image super-resolution [C]// 16th European Conference on Computer Vision . Glasgow: Springer, 2020: 101-117.
[本文引用: 1]
[33]
HUANG Y, LI S, WANG L, et al Unfolding the alternating optimization for blind super resolution
[J]. Advances in Neural Information Processing Systems , 2020 , 33 : 5632 - 5643
[本文引用: 1]
Super-resolution reconstruction for multi-angle remote sensing images considering resolution differences
1
2014
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
1
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
1
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
Image super-resolution using deep convolutional networks
0
2015
1
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
1
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
A learning-based method for image super-resolution from zoomed observations
0
2005
1
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
1
... 遥感图像在环境监测、国防安全、资源勘探和农业等领域至关重要. 受成像传感器的限制,超分辨率技术逐渐成为提升遥感图像清晰度的可行方案,相关研究逐渐受到重视[1 -2 ] . 图像超分辨率重建技术[3 -5 ] 旨在从低分辨率图像中重建高分辨率图像(HR). 随着深度学习技术的发展[6 -8 ] ,特别是卷积神经网络(CNN)在图像处理领域产生了深远影响. 最近,自然语言处理模型Transformer[9 ] 在计算机视觉领域中获得了广泛的应用. ...
1
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
1
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
Lapar: linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond
1
2020
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
2
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...
1
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
Super-resolution for remote sensing images via local–global combined network
1
2017
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
Super-resolution of single remote sensing image based on residual dense backprojection networks
1
2019
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
Remote sensing image super-resolution via mixed high-order attention network
1
2020
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
1
... 对于传统图像的超分辨率重建,Dong等[10 ] 在CNN的基础上提出SRCNN模型. Kim等[11 ] 构建20层深度网络进行级联,在图像超分辨率任务上展示出了很有前景的实验结果. Li等[12 ] 结合预定义滤波器与CNN,通过线性组合优化重建. Liang等[13 ] 提出用于图像恢复的鲁棒基线模型Swinir. Chen等[14 ] 提出预训练的图像处理Transformer,证明预训练可以显著提升低级任务性能. 遥感图像较传统图像包含更多的高频信息,利用传统方法难以恢复图像高频细节. Lei等[15 ] 提出LGCNet来学习遥感图像的多层次表示,融合局部细节与全局环境先验. Pan等[16 ] 提出密集残差反投影网络,利用全局和局部的剩余学习. Zhang等[17 ] 提出混合高阶注意力网络(MHAN),极大地节省了计算资源. 现有的超分辨模型多基于理想的双三次下采样,而真实图像受噪声、模糊、JPEG压缩等的影响,导致这些方法在实际应用中的效果不佳. 此外,Bai等[18 ] 的研究表明,Transformer虽然擅长全局信息提取,但是高频细节的构建能力不及CNN. 目前,大多数研究仅采用CNN或Transformer单一方法,未充分结合两者的优势. ...
Restoration of a single superresolution image from several blurred, noisy, and undersampled measured images
1
1997
... 经典的超分的目标是从具有未知和复杂退化的低分辨率图像中恢复出高分辨图像. 一般是采用经典退化模型[19 -20 ] 来合成低分辨率图像. 通常采用高清HR图像$x$ $k$ $r$ $n$
On Bayesian adaptive video super resolution
1
2013
... 经典的超分的目标是从具有未知和复杂退化的低分辨率图像中恢复出高分辨图像. 一般是采用经典退化模型[19 -20 ] 来合成低分辨率图像. 通常采用高清HR图像$x$ $k$ $r$ $n$
2
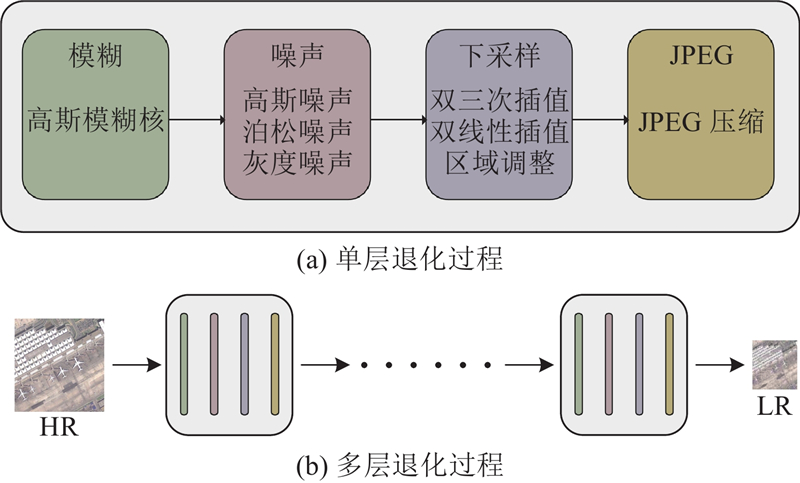
... 本文提出多层退化模型,多层退化是将传统的一层退化进行级联. 在退化过程中,使用随机洗牌策略[21 ] ,对不同的降级操作(如模糊、降采样、添加噪声等)进行随机排列,能够更大地扩展退化空间,使图像退化过程变得更加复杂. 从经验上来说,本文采用的是二层的退化过程,因为它可以解决大多数的实际情况,同时保持简洁高效. 如图1 所示为合成数据的整体过程. ...
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...
1
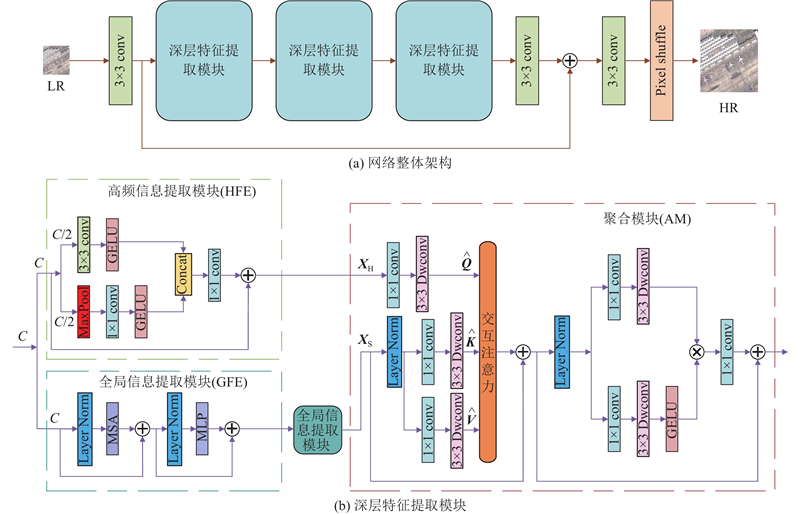
... 全局信息提取模块使用的Swin Transformer层[22 ] 是基于原始Transformer层的标准多头注意力,主要区别在于局部注意和移动窗口机制. 如图2 所示,给定输入$H \times W \times C$ $M \times M$ $({{HW}}/{{{M^2}}}) \times {M^2} \times C$ ${{HW}}/{{{M^2}}}$ ${{\boldsymbol{X}}_{\rm{in}}} \in {{\bf{R}}^{{M^2} \times C}}$ ${{\boldsymbol{Q}}_{{\mathrm{s}}}}、{{\boldsymbol{K}}_{{\mathrm{s}}}}$ ${{\boldsymbol{V}}_{{\mathrm{s}}}}$
1
... 式中:${\boldsymbol{B}}$ [23 ] . 在实践中,并行执行h 次注意函数,将结果连接到多头自注意(MSA). ...
1
... 式中:$\alpha $ ${{\boldsymbol{X}}_{{\mathrm{S}}}}$ ${{\boldsymbol{X}}_{{\mathrm{f}}}}$ . 将${{\boldsymbol{X}}_{{\mathrm{f}}}}$ [24 ] 以进一步聚合特征,细节如图2 所示. 引入门控机制,充分提取空间和通道信息,以获得更好的性能. 整个过程表述为 ...
AID: a benchmark data set for performance evaluation of aerial scene classification
1
2017
... AID数据集[25 ] 是新的大规模遥感图像数据集,通过从Google Earth图像中收集样本图像而成,在图像分类、目标检测领域都有广泛的应用. 该数据集包含机场、火车站、学校、农田、森林等30类遥感场景,共10 000张图片. 每类包含数百幅分辨率为600×600像素的图像. 在训练过程中,从每个类别中选取40张图像作为测试集,剩余图像作为训练集. ...
Satellite image classification via two-layer sparse coding with biased image representation
1
2010
... WHU-RS19[26 ] 遥感数据集是从Google Earth导出的一组卫星图像,可以提供高达0.5 m的高分辨率卫星图像. 其中包含机场、海滩、桥梁、公园等19类卫星场景,每类包含50幅左右的图像,图像分辨率为600×600像素. 在后面的对比实验中,为了证明本文模型的泛化能力,采用该数据集对模型进行测试. ...
Visual-PSNR measure of image quality
1
2014
... 目前,超分辨率的客观评价指标有很多,主要原理是将原始HR图像和重建图像SR进行对比. 采用的评价算法是PSNR[27 ] 和SSIM[28 ] . PSNR是基于像素的算法,通过均方误差损失计算2个图像之间的像素差异,PSNR越大表示图像失真度越低. 它是用于评价图像质量的最广泛使用的方法. ...
Image quality assessment: from error visibility to structural similarity
1
2004
... 目前,超分辨率的客观评价指标有很多,主要原理是将原始HR图像和重建图像SR进行对比. 采用的评价算法是PSNR[27 ] 和SSIM[28 ] . PSNR是基于像素的算法,通过均方误差损失计算2个图像之间的像素差异,PSNR越大表示图像失真度越低. 它是用于评价图像质量的最广泛使用的方法. ...
1
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...
1
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...
1
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...
1
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...
Unfolding the alternating optimization for blind super resolution
1
2020
... 将本文模型与其他先进方法进行比较,包括realHAT-TG[29 ] 、real-Esrgan[30 ] 、Swinir[13 ] 、BSRGAN[21 ] 、MM-realSR[31 ] 、CDC[32 ] 、DAN[33 ] . 实验中,在AID数据集选取6个类型的场景,飞机场、城市、农田、停车场、运动场、港口,在每个场景中选择40张图片作为测试. 具体测试结果如表1 所示. 本文方法在应对复杂退化过程和纹理细节恢复方面都优于之前方法. 当面对来自复杂未知的退化时,大多数算法不能有效地消除噪声、模糊、JPEG压缩等退化问题带来的干扰,而使用二层退化的模型可以很好地消除复杂退化带来的干扰. 本文模型相比于这些只基于CNN或Transformer的模型能够恢复逼真的纹理细节,同时能够有较好的评价指标,而利用其他方法不能很好地去除复杂退化或添加不自然的纹理. 选取6张图片,在不同的模型上对重建效果进行比较,效果如图3 所示. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}