[1]
FRIZZI S, KAABI R, BOUCHOUICHA M, et al. Convolutional neural network for video fire and smoke detection [C]// 42nd Annual Conference of the IEEE Industrial Electronics Society . Florence: IEEE, 2016: 877–882.
[本文引用: 1]
[2]
王殿伟, 赵文博, 房杰, 等 多类场景下无人机航拍视频烟雾检测算法
[J]. 哈尔滨工业大学学报 , 2023 , 55 (10 ): 122 - 129
DOI:10.11918/202205119
[本文引用: 1]
WANG Dianwei, ZHAO Wenbo, FANG Jie, et al Smoke detection algorithm for UAV aerial video in multiple scenarios
[J]. Journal of Harbin Institute of Technology , 2023 , 55 (10 ): 122 - 129
DOI:10.11918/202205119
[本文引用: 1]
[3]
马庆禄, 鲁佳萍, 唐小垚, 等 改进YOLOv5s的公路隧道烟火检测方法
[J]. 浙江大学学报: 工学版 , 2023 , 57 (4 ): 784 - 794
[本文引用: 1]
MA Qinglu, LU Jiaping, TANG Xiaoyao, et al Improved YOLOv5s flame and smoke detection method in road tunnels
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (4 ): 784 - 794
[本文引用: 1]
[4]
谢康康, 朱文忠, 谢林森, 等 基于改进YOLOv7的火焰烟雾检测算法
[J]. 国外电子测量技术 , 2023 , 42 (7 ): 41 - 49
[本文引用: 1]
XIE Kangkang, ZHU Wenzhong, XIE Linsen, et al Improved YOLOv7-based flame smoke detection algorithm
[J]. Foreign Electronic Measurement Technology , 2023 , 42 (7 ): 41 - 49
[本文引用: 1]
[5]
王晨灿, 李明 基于YOLOv8的火灾烟雾检测算法研究
[J]. 北京联合大学学报 , 2023 , 37 (5 ): 69 - 77
[本文引用: 1]
WANG Chencan, LI Ming Research on fire smoke detection algorithms based on YOLOv8
[J]. Journal of Beijing Union University , 2023 , 37 (5 ): 69 - 77
[本文引用: 1]
[6]
HUO Y, ZHANG Q, JIA Y, et al A deep separable convolutional neural network for multiscale image-based smoke detection
[J]. Fire Technology , 2022 , 58 (7 ): 1445 - 1468
[本文引用: 1]
[7]
WANG Y, HUA C, DING W, et al Real-time detection of flame and smoke using an improved YOLOv4 network
[J]. Signal, Image and Video Processing , 2022 , 16 (4 ): 1109 - 1116
DOI:10.1007/s11760-021-02060-8
[本文引用: 1]
[8]
金程拓, 赵永智, 王涛, 等 基于改进YOLOX轻量级的烟雾火焰目标检测方法
[J]. 滁州学院学报 , 2023 , 25 (5 ): 40 - 45
DOI:10.3969/j.issn.1673-1794.2023.05.008
[本文引用: 1]
JIN Chengtuo, ZHAO Yongzhi, WANG Tao, et al Improved YOLOX-based lightweight fire object detectiion algorithm
[J]. Journal of Chuzhou University , 2023 , 25 (5 ): 40 - 45
DOI:10.3969/j.issn.1673-1794.2023.05.008
[本文引用: 1]
[9]
屠恩美, 杨杰 半监督学习理论及其研究进展概述
[J]. 上海交通大学学报 , 2018 , 52 (10 ): 1280 - 1291
[本文引用: 1]
TU Enmei, YANG Jie A review of semi-supervised learning theories and recent advances
[J]. Journal of Shanghai Jiaotong University , 2018 , 52 (10 ): 1280 - 1291
[本文引用: 1]
[10]
XU B, CHEN M, GUAN W, et al. Efficient teacher: semi-supervised object detection for YOLOv5 [EB/OL]. (2023-02-15). https://arxiv.org/pdf/2302.07577.pdf.
[本文引用: 1]
[11]
周明非, 汪西莉 弱监督深层神经网络遥感图像目标检测模型
[J]. 中国科学: 信息科学 , 2018 , 48 (8 ): 1022 - 1034
[本文引用: 1]
ZHOU Mingfei, WANG Xili Object detection models of remote sensing images using deep neural networks with weakly supervised training method
[J]. Scientia Sinica: Informationis , 2018 , 48 (8 ): 1022 - 1034
[本文引用: 1]
[12]
LIU Y C, MA C Y, HE Z, et al. Unbiased teacher for semi-supervised object detection [EB/OL]. (2021-02-18). https: //arxiv. org/abs/2102.09480. pdf.
[13]
ZHANG Y, YAO X, LIU C, et al. S4OD: semi-supervised learning for single-stage object detection [EB/OL]. [2023-12-16]. https://arxiv.org/abs/2204.04492.pdf.
[14]
XU M, ZHANG Z, HU H, et al. End-to-end semi-supervised object detection with soft teacher [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3060–3069.
[本文引用: 1]
[15]
CHEN B, LI P, CHEN X, et al. Dense learning based semi-supervised object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 4815–4824.
[本文引用: 1]
[16]
MEETHAL A, PEDERSOLI M, ZHU Z, et al. Semi-weakly supervised object detection by sampling pseudo ground-truth boxes [EB/OL]. (2022-07-26). https://arxiv.org/abs/2204.00147.pdf.
[17]
YANG Q, WEI X, WANG B, et al. Interactive self-training with mean teachers for semi-supervised object detection [C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . Nashville: IEEE, 2021: 5941–5950.
[本文引用: 1]
[18]
LIN T Y, DOLLAR P, GRISHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Xiamen: IEEE, 2017: 2117–2125.
[本文引用: 1]
[19]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
[本文引用: 1]
[20]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1904 - 1916
DOI:10.1109/TPAMI.2015.2389824
[本文引用: 1]
[21]
WANG C Y, BOCHKOVSKIY A, LIAO H Y. YOLOv8: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464–7475.
[本文引用: 1]
[22]
CHEN J, KAO S, HE H, et al. Run, don’t walk: chasing higher flops for faster neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 12021–12031.
[本文引用: 1]
[23]
LIU Y, SHAO Z, HOFFMANN N. Global attention mechanism: retain information to enhance channel-spatial interactions [EB/OL]. (2021-12-10). https://arxiv.org/pdf/2112.05561v1.pdf.
[本文引用: 1]
[25]
ZHAN J, HU Y, ZHOU G, et al A high-precision forest fire smoke detection approach based on ARGNet
[J]. Computers and Electronics in Agriculture , 2022 , 196 : 106874
DOI:10.1016/j.compag.2022.106874
[本文引用: 1]
[26]
YUAN F, ZHANG L, XIA X, et al A gated recurrent network with dual classification assistance for smoke semantic segmentation
[J]. IEEE Transactions on Image Processing , 2021 , 30 : 4409 - 442
DOI:10.1109/TIP.2021.3069318
[本文引用: 1]
[27]
PEDRO V, ADRIANO C, ADRIANO V An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices
[J]. Neural Computing and Applications , 2022 , 30 : 15349 - 15368
[本文引用: 1]
[28]
JIE H, LI S, ALBANIE S, et al. Squeeze-and-excitation networks. [EB/OL]. (2019-05-16). https://arxiv.org/pdf/1709.01507.pdf.
[本文引用: 1]
[29]
WOO S, PARK J, LEE J, et al. CBAM: convolutional block attention module. [EB/OL]. (2018-07-18). https://arxiv.org/abs/1807.06521.
[本文引用: 1]
[30]
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks. [EB/OL]. (2016-01-06). https://arxiv.org/pdf/1506.01497.pdf.
[本文引用: 1]
[31]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector. [EB/OL]. (2015-12-08). https://arxiv.org/abs/1512.02325.
[本文引用: 1]
[32]
QIAO S, CHEN L, ALAN Y. DetectoRS: detecting objects with recursive feature pyramid and switchable atrous convolution. [EB/OL]. (2020-06-03). https://arxiv.org/abs/2006.02334.pdf.
[本文引用: 1]
[33]
CARION N, MASSA F, GABRIEL S, et al. End-to-end object detection with transformers. [EB/OL]. (2020-05-26). https://arxiv.org/abs/2005.1287.
[本文引用: 1]
1
... 火灾极具破坏力和危险性,早期检测是公认的降低危害的有效手段. 烟雾作为火灾的主要伴生物,早于明火发生且易于被显著发现[1 ] ,因此可以通过检测烟雾来更早地发现火灾,这对于消防减灾具有重要意义[2 ] . 根据燃烧物和燃烧条件的不同,火灾初期的烟雾常见为黑色浓烟和小规模稀薄烟雾2类. 其中,黑色浓烟因对比于背景具有更明显的视觉特征而易于发现,相比而言,检测小规模稀薄烟雾仍是一项颇具挑战的任务. ...
多类场景下无人机航拍视频烟雾检测算法
1
2023
... 火灾极具破坏力和危险性,早期检测是公认的降低危害的有效手段. 烟雾作为火灾的主要伴生物,早于明火发生且易于被显著发现[1 ] ,因此可以通过检测烟雾来更早地发现火灾,这对于消防减灾具有重要意义[2 ] . 根据燃烧物和燃烧条件的不同,火灾初期的烟雾常见为黑色浓烟和小规模稀薄烟雾2类. 其中,黑色浓烟因对比于背景具有更明显的视觉特征而易于发现,相比而言,检测小规模稀薄烟雾仍是一项颇具挑战的任务. ...
多类场景下无人机航拍视频烟雾检测算法
1
2023
... 火灾极具破坏力和危险性,早期检测是公认的降低危害的有效手段. 烟雾作为火灾的主要伴生物,早于明火发生且易于被显著发现[1 ] ,因此可以通过检测烟雾来更早地发现火灾,这对于消防减灾具有重要意义[2 ] . 根据燃烧物和燃烧条件的不同,火灾初期的烟雾常见为黑色浓烟和小规模稀薄烟雾2类. 其中,黑色浓烟因对比于背景具有更明显的视觉特征而易于发现,相比而言,检测小规模稀薄烟雾仍是一项颇具挑战的任务. ...
改进YOLOv5s的公路隧道烟火检测方法
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
改进YOLOv5s的公路隧道烟火检测方法
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
基于改进YOLOv7的火焰烟雾检测算法
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
基于改进YOLOv7的火焰烟雾检测算法
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
基于YOLOv8的火灾烟雾检测算法研究
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
基于YOLOv8的火灾烟雾检测算法研究
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
A deep separable convolutional neural network for multiscale image-based smoke detection
1
2022
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
Real-time detection of flame and smoke using an improved YOLOv4 network
1
2022
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
基于改进YOLOX轻量级的烟雾火焰目标检测方法
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
基于改进YOLOX轻量级的烟雾火焰目标检测方法
1
2023
... 随着深度学习技术的不断发展,针对黑色浓烟的检测研究已经取得了良好进展. 这些研究主要侧重2个方面:一是算法的检测准确率,二是算法的轻量化以能够灵活部署于无人机之类的边缘设备上. 针对算法的检测准确率,马庆禄等[3 ] 通过在YOLOv5s中引入注意力机制,提高了算法在公路隧道场景下的检测精度,但采用的数据集内多为中后期火灾烟雾图像,其算法对早期火灾烟雾的检测准确率还有待考量;谢康康等[4 ] 通过改进YOLOv7的骨干网络并在训练阶段采用Mosaic数据增强,降低了算法在动态场景下的漏检率,但使用的自建数据集规模较小,算法在多场景下的适应性还有待提升;王晨灿等[5 ] 在YOLOv8n的基础上增加一个更小的目标检测层,提高了算法对小规模烟雾的检测精度,但算法没有考虑到稀薄烟雾的检测,针对早期火灾的预警工作还有待进一步提升. 针对算法的轻量化,Huo等[6 ] 提出基于深度可分离卷积的单场景烟雾检测算法,有效降低了模型复杂度,但深度可分离卷积是在二维平面内进行的,难以充分利用通道间相同空间位置上的特征信息;Wang等[7 ] 通过改进YOLOv4算法结构,实现了对视频烟雾的实时检测,但改进后的结构特征提取效率下降,算法结构还可进一步完善;金程拓等[8 ] 提出轻量化的YOLOX算法,改善了模型在嵌入式设备下实时性差的问题,但算法定位准确性还可进一步提升. 总的来说,小规模稀薄烟雾与上述研究中的黑色浓烟图像特征存在着显著差别,因此上述算法对火灾初期烟雾的检测性能和对应的算法轻量化处理方法尚欠佳. ...
半监督学习理论及其研究进展概述
1
2018
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
半监督学习理论及其研究进展概述
1
2018
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
1
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
弱监督深层神经网络遥感图像目标检测模型
1
2018
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
弱监督深层神经网络遥感图像目标检测模型
1
2018
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
1
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
1
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
1
... 上述算法均属于全监督模型,检测精度和适应能力受制于训练样本的规模和多样性,而这些样本需要人工收集整理和标注. 因此,降低标注成本、增加样本规模和拓展样本多样性成为提升模型性能的紧迫任务. 相比而言,半监督学习利用有限标注数据和大量未标注数据来训练模型[9 ] ,能够大幅降低对标注数据的需求,在同等成本下,半监督模型的适应能力更强[10 ] . 不过,当前的半监督学习策略仍存在局限性,虽然其分为一致性学习[11 -14 ] 和伪标签[15 -17 ] 2类,但本质上均为基于伪标签的学习,而伪标签一般由教师模型产生,在生成过程中会掺杂大量的噪声标签和偏移标签,这在训练过程中会对算法检测精度带来不利影响. ...
1
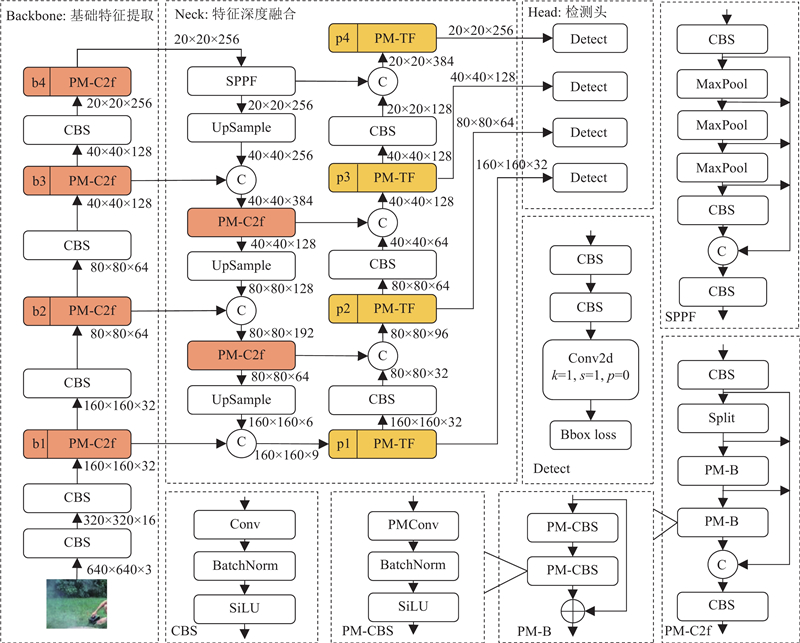
... 所构建的火灾烟雾检测网络DeepSmoke的具体结构如图1 所示,由用于提取图像特征的基础骨干网络Backbone、用于实现图像特征深度融合的颈部网络Neck和用于实现烟雾目标检测的Head三大部分组成. 其中,骨干网络的核心部分由CBS模块和自主设计的特征聚合模块PM-C2f组成,并且重复堆叠了4次,以提取出图中b1、b2、b3、b4位置的4个不同深度和尺度的基础特征. 颈部网络总体借鉴了特征金字塔网络(feature pyramid network, FPN)[18 ] 和路径聚合网络(path aggregation network, PAN)[19 ] 的架构,并使用快速空间金字塔池化(spatial pyramid pooling fast, SPPF)[20 ] 和自主设计的部分混合最相关区域自注意力模块PM-TF. 在DeepSmoke中引入FPN有利于将烟雾图像的深层语义特征传递到浅层,达到增强多尺度语义表达的目的;引入PAN能够将浅层位置信息传递至深层,获得更强的目标定位能力. SPPF能够有效融合不同尺度特征,扩大烟雾目标检测的感受野. PM-TF将最相关区域注意力应用于PM-C2f上,起到增强小规模稀薄烟雾特征和降低背景干扰的作用. 通过这些模块,颈部网络最终输出4个不同尺寸的特征图,用以检测不同大小的烟雾目标. ...
1
... 所构建的火灾烟雾检测网络DeepSmoke的具体结构如图1 所示,由用于提取图像特征的基础骨干网络Backbone、用于实现图像特征深度融合的颈部网络Neck和用于实现烟雾目标检测的Head三大部分组成. 其中,骨干网络的核心部分由CBS模块和自主设计的特征聚合模块PM-C2f组成,并且重复堆叠了4次,以提取出图中b1、b2、b3、b4位置的4个不同深度和尺度的基础特征. 颈部网络总体借鉴了特征金字塔网络(feature pyramid network, FPN)[18 ] 和路径聚合网络(path aggregation network, PAN)[19 ] 的架构,并使用快速空间金字塔池化(spatial pyramid pooling fast, SPPF)[20 ] 和自主设计的部分混合最相关区域自注意力模块PM-TF. 在DeepSmoke中引入FPN有利于将烟雾图像的深层语义特征传递到浅层,达到增强多尺度语义表达的目的;引入PAN能够将浅层位置信息传递至深层,获得更强的目标定位能力. SPPF能够有效融合不同尺度特征,扩大烟雾目标检测的感受野. PM-TF将最相关区域注意力应用于PM-C2f上,起到增强小规模稀薄烟雾特征和降低背景干扰的作用. 通过这些模块,颈部网络最终输出4个不同尺寸的特征图,用以检测不同大小的烟雾目标. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2015
... 所构建的火灾烟雾检测网络DeepSmoke的具体结构如图1 所示,由用于提取图像特征的基础骨干网络Backbone、用于实现图像特征深度融合的颈部网络Neck和用于实现烟雾目标检测的Head三大部分组成. 其中,骨干网络的核心部分由CBS模块和自主设计的特征聚合模块PM-C2f组成,并且重复堆叠了4次,以提取出图中b1、b2、b3、b4位置的4个不同深度和尺度的基础特征. 颈部网络总体借鉴了特征金字塔网络(feature pyramid network, FPN)[18 ] 和路径聚合网络(path aggregation network, PAN)[19 ] 的架构,并使用快速空间金字塔池化(spatial pyramid pooling fast, SPPF)[20 ] 和自主设计的部分混合最相关区域自注意力模块PM-TF. 在DeepSmoke中引入FPN有利于将烟雾图像的深层语义特征传递到浅层,达到增强多尺度语义表达的目的;引入PAN能够将浅层位置信息传递至深层,获得更强的目标定位能力. SPPF能够有效融合不同尺度特征,扩大烟雾目标检测的感受野. PM-TF将最相关区域注意力应用于PM-C2f上,起到增强小规模稀薄烟雾特征和降低背景干扰的作用. 通过这些模块,颈部网络最终输出4个不同尺寸的特征图,用以检测不同大小的烟雾目标. ...
1
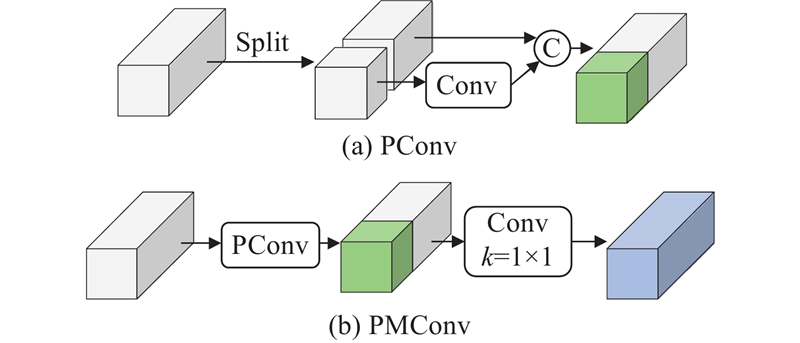
... 传统特征聚合模块C2f [21 ] 通过堆叠多个Bottleneck结构融合上下文残差特征,以充分学习不同维度的特征信息,但这不可避免会造成通道信息的过度冗余,进而导致运算量过大. 针对该问题,设计更为轻量化的残差结构PM-B替换C2f中的Bottleneck,得到更为高效的特征聚合模块PM-C2f. 其关键在于采用部分混合卷积PMConv来降低冗余计算. PMConv的原理如图2 所示,是在部分卷积PConv[22 ] 的基础上改进获得的一种新型卷积. PConv通常用于减少残差网络中多个通道携带相同或相似信息的冗余计算,具体过程如下:首先将输入特征采样为2部分,一部分直接前向传输以保留原始梯度信息,另一部分经过卷积运算获得深层梯度信息,然后将两者直接进行拼接. 虽然此方法有效提升了运算效率,但实验发现这种仅对部分通道进行计算的做法会导致未参与计算的层间信息缺乏交互,从而影响信息融合的效果. 针对该不足,在PConv的基础上进一步采用核大小为1×1的卷积对原始输入特征和中间滤波特征进行错层运算,这样相较于普通卷积既能降低计算量又能提取出更丰富的梯度流. ...
1
... 传统特征聚合模块C2f [21 ] 通过堆叠多个Bottleneck结构融合上下文残差特征,以充分学习不同维度的特征信息,但这不可避免会造成通道信息的过度冗余,进而导致运算量过大. 针对该问题,设计更为轻量化的残差结构PM-B替换C2f中的Bottleneck,得到更为高效的特征聚合模块PM-C2f. 其关键在于采用部分混合卷积PMConv来降低冗余计算. PMConv的原理如图2 所示,是在部分卷积PConv[22 ] 的基础上改进获得的一种新型卷积. PConv通常用于减少残差网络中多个通道携带相同或相似信息的冗余计算,具体过程如下:首先将输入特征采样为2部分,一部分直接前向传输以保留原始梯度信息,另一部分经过卷积运算获得深层梯度信息,然后将两者直接进行拼接. 虽然此方法有效提升了运算效率,但实验发现这种仅对部分通道进行计算的做法会导致未参与计算的层间信息缺乏交互,从而影响信息融合的效果. 针对该不足,在PConv的基础上进一步采用核大小为1×1的卷积对原始输入特征和中间滤波特征进行错层运算,这样相较于普通卷积既能降低计算量又能提取出更丰富的梯度流. ...
1
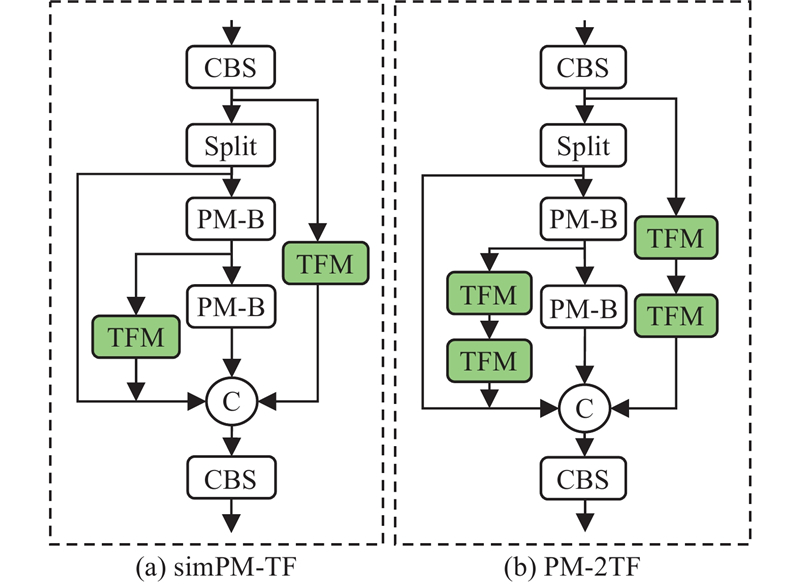
... 火灾初期的小规模稀薄烟雾在视频图像中一般具有像素比例小、特征模糊的特点,导致提取出的烟雾特征容易被背景特征所淹没,造成算法漏检. 通常采用注意力机制来提高算法对此类稀疏特征的敏感度以解决该问题,其中全局注意力机制(global attention mechanism, GAM)[23 ] 被证明是一种相对有效的方法,但会带来巨大的计算负担. 为此,提出仅计算最相关区域且对小规模稀薄烟雾敏感的最相关区域自注意力机制(top former mechanism, TFM),如图3 所示. 不同于常规注意力机制直接对整幅图像进行运算,TF首先对图像进行局部区域窗口划分,然后分别计算注意力关联权重,据此收集前k 个最相关窗口的键值对,跳过其他窗口的计算,实现选择性学习输入特征的目的. 这种运算机制既能减少自注意力计算中的冗余运算又能有效滤除小规模稀薄烟雾图像中广泛存在的干扰信息,提升算法对这2类特殊烟雾的检测性能. ...
Exponential moving average versus moving exponential average
1
2011
... 半监督学习框架一般包含教师Teacher和学生Student这2个已经过预训练的模型. 教师模型从未标注的图像样本中自动生成标注信息,据此构建出用于学生模型训练所需的标注样本. 这些标注信息并不一定准确,因此将其称为伪标签. 在启用半监督学习策略后,首先将经过数据增强后的未标注图像传入教师模型DeepSmoke-T,生成烟雾图像伪标签;然后利用伪标签分类器PLC进行噪声评估和分类,自动将评分较高的伪标签制作成训练样本用来辅助训练学生模型DeepSmoke-S;接着结合已标注样本和对应的2类伪标签训练样本再结合预设的权重参数分别计算对应的损失函数,据此更新学生模型;最后再以学生模型为基础通过指数移动平均算法(exponential moving average, EMA)[24 ] 对教师模型进行权值更新. 如此反复循环,直至达到预设训练轮次或总训练损失不再明显降低为止,具体结构如图5 所示. ...
A high-precision forest fire smoke detection approach based on ARGNet
1
2022
... 早期研究使用的数据集主要采样于CVPR-KMU实验室公开的4段火灾烟雾视频[25 ] 和Yuan等[26 ] 公开的3段火灾烟雾视频,因此数据集中的火灾场景相对单一且小规模稀薄烟雾图像样本较少,这限制了算法在不同场景下的适应性和对小规模稀薄烟雾的检测能力. 近期,Pedro等[27 ] 在GitHub上公开了包含21527 张火灾烟雾图像的D-Fire数据集,数据规模更大且场景更丰富,较好地缓解了上述问题. 本研究进一步通过网络收集筛选和自行拍摄的方式,将图像规模扩充到约50000 张,构建了前文所述的火灾初期烟雾数据集MSIFSD,其中标注图像与未标注图像比例约为2∶3. 将20000 张已标注图像按场景归纳为9类,并根据烟雾特征进一步区分为3类:烟雾面积占比小于视野图像1/32的小规模烟雾集Hard_1、烟雾区域中可见背景像素占比大于1/2的稀薄烟雾集Hard_2以及不符合上述定义的普通烟雾集Easy. 须指出的是,火灾初期的烟雾经常同时拥有小规模和稀薄2种特征,本研究将此类烟雾图像随机分配于Hard_1和Hard_2中. 如图7 所示为几种常见场景下的典型火灾烟雾样本图像示例,MSIFSD数据集内已标注的20000 张图像划分的样本数量如表1 所示. 表中,N 为各数据集中各场景类别的图像的具体数量. ...
A gated recurrent network with dual classification assistance for smoke semantic segmentation
1
2021
... 早期研究使用的数据集主要采样于CVPR-KMU实验室公开的4段火灾烟雾视频[25 ] 和Yuan等[26 ] 公开的3段火灾烟雾视频,因此数据集中的火灾场景相对单一且小规模稀薄烟雾图像样本较少,这限制了算法在不同场景下的适应性和对小规模稀薄烟雾的检测能力. 近期,Pedro等[27 ] 在GitHub上公开了包含21527 张火灾烟雾图像的D-Fire数据集,数据规模更大且场景更丰富,较好地缓解了上述问题. 本研究进一步通过网络收集筛选和自行拍摄的方式,将图像规模扩充到约50000 张,构建了前文所述的火灾初期烟雾数据集MSIFSD,其中标注图像与未标注图像比例约为2∶3. 将20000 张已标注图像按场景归纳为9类,并根据烟雾特征进一步区分为3类:烟雾面积占比小于视野图像1/32的小规模烟雾集Hard_1、烟雾区域中可见背景像素占比大于1/2的稀薄烟雾集Hard_2以及不符合上述定义的普通烟雾集Easy. 须指出的是,火灾初期的烟雾经常同时拥有小规模和稀薄2种特征,本研究将此类烟雾图像随机分配于Hard_1和Hard_2中. 如图7 所示为几种常见场景下的典型火灾烟雾样本图像示例,MSIFSD数据集内已标注的20000 张图像划分的样本数量如表1 所示. 表中,N 为各数据集中各场景类别的图像的具体数量. ...
An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices
1
2022
... 早期研究使用的数据集主要采样于CVPR-KMU实验室公开的4段火灾烟雾视频[25 ] 和Yuan等[26 ] 公开的3段火灾烟雾视频,因此数据集中的火灾场景相对单一且小规模稀薄烟雾图像样本较少,这限制了算法在不同场景下的适应性和对小规模稀薄烟雾的检测能力. 近期,Pedro等[27 ] 在GitHub上公开了包含21527 张火灾烟雾图像的D-Fire数据集,数据规模更大且场景更丰富,较好地缓解了上述问题. 本研究进一步通过网络收集筛选和自行拍摄的方式,将图像规模扩充到约50000 张,构建了前文所述的火灾初期烟雾数据集MSIFSD,其中标注图像与未标注图像比例约为2∶3. 将20000 张已标注图像按场景归纳为9类,并根据烟雾特征进一步区分为3类:烟雾面积占比小于视野图像1/32的小规模烟雾集Hard_1、烟雾区域中可见背景像素占比大于1/2的稀薄烟雾集Hard_2以及不符合上述定义的普通烟雾集Easy. 须指出的是,火灾初期的烟雾经常同时拥有小规模和稀薄2种特征,本研究将此类烟雾图像随机分配于Hard_1和Hard_2中. 如图7 所示为几种常见场景下的典型火灾烟雾样本图像示例,MSIFSD数据集内已标注的20000 张图像划分的样本数量如表1 所示. 表中,N 为各数据集中各场景类别的图像的具体数量. ...
1
... 为了验证TFM的有效性,将网络中所有的TFM移除并依次替换为:通道注意力机制(channel attention mechanism, CAM)[28 ] 、通道-空间注意力机制(convolutional block attention module, CBAM)[29 ] 和全局注意力机制GAM这3种典型的注意力机制进行对比实验,结果如表3 所示. 可以看出:1)在不引入注意力机制时,模型的AP和R 在4种烟雾集下均为最低值. 2)在引入CAM、CBAM、GAM这3种经典注意力机制后,模型的AP和R 在4种烟雾集下均有不同程度的提升,且在Easy集下的提升效果最为明显. 3)在引入本研究提出的TFM后,模型的AP和R 在4种烟雾集下都达到了当前最佳. 与次优的GAM组进行对比后发现,在Easy烟雾集下,2组实验的AP和R 相差相对较小,均小于0.1%;在Hard_1烟雾集下,2组实验的AP和R 的差异为0.9%、0.9%;在Hard_2烟雾集下,2组实验的AP和R 的差异为0.9%、0.8%. 相较而言,TFM在Hard_1与Hard_2烟雾集下带来的指标差异更为明显. 这证明了TFM仅计算最相关区域的运算机制对小规模稀薄烟雾的检测是更为有效的;4)在保证精度最佳的前提下,TFM带来的计算开销相对较小,相较于无注意力机制的对照组仅增加0.8×109 ,最终为9.3×109 . ...
1
... 为了验证TFM的有效性,将网络中所有的TFM移除并依次替换为:通道注意力机制(channel attention mechanism, CAM)[28 ] 、通道-空间注意力机制(convolutional block attention module, CBAM)[29 ] 和全局注意力机制GAM这3种典型的注意力机制进行对比实验,结果如表3 所示. 可以看出:1)在不引入注意力机制时,模型的AP和R 在4种烟雾集下均为最低值. 2)在引入CAM、CBAM、GAM这3种经典注意力机制后,模型的AP和R 在4种烟雾集下均有不同程度的提升,且在Easy集下的提升效果最为明显. 3)在引入本研究提出的TFM后,模型的AP和R 在4种烟雾集下都达到了当前最佳. 与次优的GAM组进行对比后发现,在Easy烟雾集下,2组实验的AP和R 相差相对较小,均小于0.1%;在Hard_1烟雾集下,2组实验的AP和R 的差异为0.9%、0.9%;在Hard_2烟雾集下,2组实验的AP和R 的差异为0.9%、0.8%. 相较而言,TFM在Hard_1与Hard_2烟雾集下带来的指标差异更为明显. 这证明了TFM仅计算最相关区域的运算机制对小规模稀薄烟雾的检测是更为有效的;4)在保证精度最佳的前提下,TFM带来的计算开销相对较小,相较于无注意力机制的对照组仅增加0.8×109 ,最终为9.3×109 . ...
1
... Performance comparison of each model with different smoke sets
Tab.7 算法 Easy Hard_1 Hard_2 MSIFSD D-Fire FLOPs/109 FPS AP/% R /%AP/% R /%AP/% R /%AP/% R /%AP/% R /%Faster R-CNN[30 ] 83.6 73.2 73.6 65.7 77.1 68.7 79.1 69.3 73.2 62.9 40.3 25.3 SSD[31 ] 75.4 62.8 67.3 57.7 68.2 58.4 71.3 59.4 68.5 64.3 27.6 51.1 YOLOv5n[32 ] 89.5 81.3 78.2 72.0 82.1 75.5 84.9 77.2 80.3 74.2 1.7 57.8 YOLOv8n 95.0 88.4 82.3 77.3 83.4 78.3 89.9 83.7 86.2 81.4 8.2 103.0 DETR[33 ] 75.6 85.4 69.9 77.6 71.3 79.2 72.2 81.6 69.3 76.6 8.7 52.1 DeepSmoke 96.3 89.6 86.4 81.0 87.8 82.3 92.0 85.6 88.3 84.1 9.3 85.3 DeepSmoke_SST 98.3 91.4 88.2 82.7 90.0 84.3 94.2 87.6 92.6 88.3 9.3 85.3
为了更直观地对比各算法的检测性能,如图11 所示展示了DeepSmoke_SST算法与之前取得最高准确率的YOLOv8n算法在6种常见火灾场景下的检测结果对比,其中上图和下图分别对应为YOLOv8n和DeepSmoke_SST的结果. 可以看出,针对停车场场景左图和住宅场景下的易检测烟雾,2种算法检测效果良好,本研究算法置信度略高且定位更为准确;针对停车场场景右图和森林场景右图下的存在干扰的图像,YOLOv8n算法出现了错检的情况,将光照和云朵与烟雾混杂,但本研究算法得益于半监督训练中伪标签分类器对噪声伪标签进行识别并丢弃的优势,能够较好地分辨出此类干扰;针对森林场景左图和农场场景下的小规模和稀薄烟雾,YOLOv8n算法出现了明显的漏检情况,但本研究算法由于引入了TFM,对此类难存在稀疏特征信息的烟雾针对性地计算注意力机制,因此能够准确识别和定位此类目标;针对工厂场景和仓库场景下的混杂烟雾,YOLOv8n算法出现了缺检的情况,检测框中仅包含部分烟雾而本研究算法能对该类目标进行完整检测. 以上实验数据与检测性能对比,验证了本研究算法在不同场景下的适应能力和对小规模稀薄烟雾的检测能力. ...
1
... Performance comparison of each model with different smoke sets
Tab.7 算法 Easy Hard_1 Hard_2 MSIFSD D-Fire FLOPs/109 FPS AP/% R /%AP/% R /%AP/% R /%AP/% R /%AP/% R /%Faster R-CNN[30 ] 83.6 73.2 73.6 65.7 77.1 68.7 79.1 69.3 73.2 62.9 40.3 25.3 SSD[31 ] 75.4 62.8 67.3 57.7 68.2 58.4 71.3 59.4 68.5 64.3 27.6 51.1 YOLOv5n[32 ] 89.5 81.3 78.2 72.0 82.1 75.5 84.9 77.2 80.3 74.2 1.7 57.8 YOLOv8n 95.0 88.4 82.3 77.3 83.4 78.3 89.9 83.7 86.2 81.4 8.2 103.0 DETR[33 ] 75.6 85.4 69.9 77.6 71.3 79.2 72.2 81.6 69.3 76.6 8.7 52.1 DeepSmoke 96.3 89.6 86.4 81.0 87.8 82.3 92.0 85.6 88.3 84.1 9.3 85.3 DeepSmoke_SST 98.3 91.4 88.2 82.7 90.0 84.3 94.2 87.6 92.6 88.3 9.3 85.3
为了更直观地对比各算法的检测性能,如图11 所示展示了DeepSmoke_SST算法与之前取得最高准确率的YOLOv8n算法在6种常见火灾场景下的检测结果对比,其中上图和下图分别对应为YOLOv8n和DeepSmoke_SST的结果. 可以看出,针对停车场场景左图和住宅场景下的易检测烟雾,2种算法检测效果良好,本研究算法置信度略高且定位更为准确;针对停车场场景右图和森林场景右图下的存在干扰的图像,YOLOv8n算法出现了错检的情况,将光照和云朵与烟雾混杂,但本研究算法得益于半监督训练中伪标签分类器对噪声伪标签进行识别并丢弃的优势,能够较好地分辨出此类干扰;针对森林场景左图和农场场景下的小规模和稀薄烟雾,YOLOv8n算法出现了明显的漏检情况,但本研究算法由于引入了TFM,对此类难存在稀疏特征信息的烟雾针对性地计算注意力机制,因此能够准确识别和定位此类目标;针对工厂场景和仓库场景下的混杂烟雾,YOLOv8n算法出现了缺检的情况,检测框中仅包含部分烟雾而本研究算法能对该类目标进行完整检测. 以上实验数据与检测性能对比,验证了本研究算法在不同场景下的适应能力和对小规模稀薄烟雾的检测能力. ...
1
... Performance comparison of each model with different smoke sets
Tab.7 算法 Easy Hard_1 Hard_2 MSIFSD D-Fire FLOPs/109 FPS AP/% R /%AP/% R /%AP/% R /%AP/% R /%AP/% R /%Faster R-CNN[30 ] 83.6 73.2 73.6 65.7 77.1 68.7 79.1 69.3 73.2 62.9 40.3 25.3 SSD[31 ] 75.4 62.8 67.3 57.7 68.2 58.4 71.3 59.4 68.5 64.3 27.6 51.1 YOLOv5n[32 ] 89.5 81.3 78.2 72.0 82.1 75.5 84.9 77.2 80.3 74.2 1.7 57.8 YOLOv8n 95.0 88.4 82.3 77.3 83.4 78.3 89.9 83.7 86.2 81.4 8.2 103.0 DETR[33 ] 75.6 85.4 69.9 77.6 71.3 79.2 72.2 81.6 69.3 76.6 8.7 52.1 DeepSmoke 96.3 89.6 86.4 81.0 87.8 82.3 92.0 85.6 88.3 84.1 9.3 85.3 DeepSmoke_SST 98.3 91.4 88.2 82.7 90.0 84.3 94.2 87.6 92.6 88.3 9.3 85.3
为了更直观地对比各算法的检测性能,如图11 所示展示了DeepSmoke_SST算法与之前取得最高准确率的YOLOv8n算法在6种常见火灾场景下的检测结果对比,其中上图和下图分别对应为YOLOv8n和DeepSmoke_SST的结果. 可以看出,针对停车场场景左图和住宅场景下的易检测烟雾,2种算法检测效果良好,本研究算法置信度略高且定位更为准确;针对停车场场景右图和森林场景右图下的存在干扰的图像,YOLOv8n算法出现了错检的情况,将光照和云朵与烟雾混杂,但本研究算法得益于半监督训练中伪标签分类器对噪声伪标签进行识别并丢弃的优势,能够较好地分辨出此类干扰;针对森林场景左图和农场场景下的小规模和稀薄烟雾,YOLOv8n算法出现了明显的漏检情况,但本研究算法由于引入了TFM,对此类难存在稀疏特征信息的烟雾针对性地计算注意力机制,因此能够准确识别和定位此类目标;针对工厂场景和仓库场景下的混杂烟雾,YOLOv8n算法出现了缺检的情况,检测框中仅包含部分烟雾而本研究算法能对该类目标进行完整检测. 以上实验数据与检测性能对比,验证了本研究算法在不同场景下的适应能力和对小规模稀薄烟雾的检测能力. ...
1
... Performance comparison of each model with different smoke sets
Tab.7 算法 Easy Hard_1 Hard_2 MSIFSD D-Fire FLOPs/109 FPS AP/% R /%AP/% R /%AP/% R /%AP/% R /%AP/% R /%Faster R-CNN[30 ] 83.6 73.2 73.6 65.7 77.1 68.7 79.1 69.3 73.2 62.9 40.3 25.3 SSD[31 ] 75.4 62.8 67.3 57.7 68.2 58.4 71.3 59.4 68.5 64.3 27.6 51.1 YOLOv5n[32 ] 89.5 81.3 78.2 72.0 82.1 75.5 84.9 77.2 80.3 74.2 1.7 57.8 YOLOv8n 95.0 88.4 82.3 77.3 83.4 78.3 89.9 83.7 86.2 81.4 8.2 103.0 DETR[33 ] 75.6 85.4 69.9 77.6 71.3 79.2 72.2 81.6 69.3 76.6 8.7 52.1 DeepSmoke 96.3 89.6 86.4 81.0 87.8 82.3 92.0 85.6 88.3 84.1 9.3 85.3 DeepSmoke_SST 98.3 91.4 88.2 82.7 90.0 84.3 94.2 87.6 92.6 88.3 9.3 85.3
为了更直观地对比各算法的检测性能,如图11 所示展示了DeepSmoke_SST算法与之前取得最高准确率的YOLOv8n算法在6种常见火灾场景下的检测结果对比,其中上图和下图分别对应为YOLOv8n和DeepSmoke_SST的结果. 可以看出,针对停车场场景左图和住宅场景下的易检测烟雾,2种算法检测效果良好,本研究算法置信度略高且定位更为准确;针对停车场场景右图和森林场景右图下的存在干扰的图像,YOLOv8n算法出现了错检的情况,将光照和云朵与烟雾混杂,但本研究算法得益于半监督训练中伪标签分类器对噪声伪标签进行识别并丢弃的优势,能够较好地分辨出此类干扰;针对森林场景左图和农场场景下的小规模和稀薄烟雾,YOLOv8n算法出现了明显的漏检情况,但本研究算法由于引入了TFM,对此类难存在稀疏特征信息的烟雾针对性地计算注意力机制,因此能够准确识别和定位此类目标;针对工厂场景和仓库场景下的混杂烟雾,YOLOv8n算法出现了缺检的情况,检测框中仅包含部分烟雾而本研究算法能对该类目标进行完整检测. 以上实验数据与检测性能对比,验证了本研究算法在不同场景下的适应能力和对小规模稀薄烟雾的检测能力. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}