Most of the existing graph neural network models for forecasting multivariate time series capture the time series characteristics in a static way based on predefined graphs, and may be lack of capturing the dynamic adaptation of the system and some potential dynamic relationships between time series samples. A graph neural network model for multivariate time series prediction (MTSGNN) was proposed. In a graph learning module, the static and dynamic evolution graphs of time series data were learned in a data-driven way to capture the complex relationships between time series samples. The information interaction between the static and dynamic graphs was realized by the graph interaction module, and the convolution operation was used to extract the dependency in the interaction information. A multi-layer perceptron was used to forecast the multivariate time series. Experimental results on six real multivariate time series datasets showed that the forecasting effect of the proposed model was significantly better than those of the current state-of-the-art methods, and it had the advantages of small parameter quantity and fast operation speed.
Keywords:multivariate time series
;
graph neural network
;
static graph
;
dynamic graph
;
graph interaction
ZHANG Han. Graph neural network model for multivariate time series forecasting. Journal of Zhejiang University(Engineering Science)[J], 2024, 58(12): 2500-2509 doi:10.3785/j.issn.1008-973X.2024.12.009
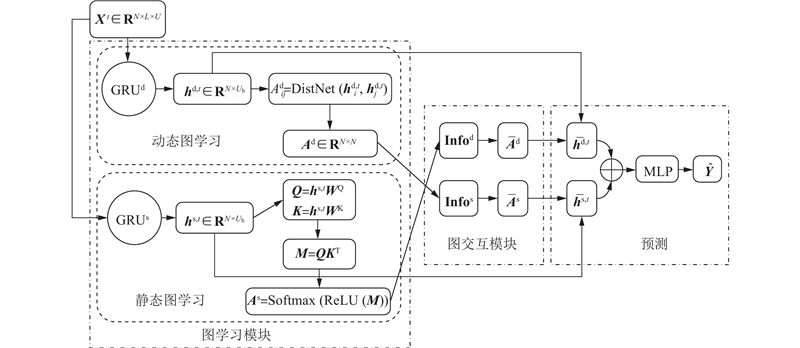
长短期记忆(long short term memory, LSTM)网络和门控循环单元(gated recurrent unit, GRU)在捕捉长序列语义关联时,都能有效抑制传统RNN中存在的梯度消失或爆炸问题;并且,相对于LSTM,GRU参数量更少,训练速度更快,更适用于构建较大的网络[27]. 因此,使用GRU对时序的历史数据进行编码.
考虑到静态图的结构是固定的,而动态图的结构是可变的,因此,式(9)计算动态图中不同节点间的相关信息,并以此对静态图不同节点间连接强度(边权重)进行调整,从而在静态图结构不变的情况下,达到信息交互的目的. 动态图中不同节点之间的连接是可以动态变化的,并受到重要邻居节点的影响,因此,根据静态图排名前$ k $位的节点,更新动态图里不同节点间的连接强度.
首先,使用式(9),即$ \mathrm{S}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}\;\left( \cdot \right) $函数对动态图的邻接矩阵$ {\boldsymbol{A}}^{\mathrm{d}} $中的第$ i $行${\boldsymbol{A}}_i^{\mathrm{d}} $归一化,利用式(11)对静态图$ {\boldsymbol{A}}^{\mathrm{s}} $中节点i到j的相关强度进行更新:如果$ {\boldsymbol{A}}^{\mathrm{d}} $中2个节点i到j的相关性越弱,归一化后的数值就越接近于0,则静态图$ {\boldsymbol{A}}^{\mathrm{s}} $中i到j更新后的连接强度就越弱. 其次,使用式(10)计算$ {\boldsymbol{A}}^{\mathrm{s}} $中第$ i $行的信息,利用式(12)修改动态图$ {\boldsymbol{A}}^{\mathrm{d}} $上的边:如果$ {\boldsymbol{A}}^{\mathrm{s}} $中节点i到j的相关强度和i与其所有相邻节点的相关强度相比,不能排在前$ k $位,则将$ {\boldsymbol{A}}^{\mathrm{d}} $中i到j的边删除. 计算过程如式(9)~(12)所示.
如表1所示为在实验中使用的基准数据集的统计量. 表中,$ I $为时序数据的采集间隔;$ H $为预测的时间跨度,即所预测的未来时间点与当前时间点之间的时间跨度. 多步预测任务中使用公共交通数据集PEMS-BAY和METR-LA;单步预测中使用4个数据集Traffic、Solar-Energy、Electricity和Exchange-Rate.
HASANI R, LECHNER M, AMINI A, et al. Liquid time-constant networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [s.l.]: AAAI, 2021(35): 7657–7666.
SHAO Z, ZHANG Z, WANG F, et al. Pre-training enhanced spatial-temporal graph neural network for multivariate time series forecasting [C]// Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . Washington DC: ACM, 2022: 1567–1577.
WU Z, PAN S, LONG G, et al. Connecting the dots: multivariate time series forecasting with graph neural networks [C]/ / Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . New York: ACM, 2020: 753–763.
SEN R, YU H F, DHILLON I. Think globally, act locally: a deep neural network approach to high-dimensional time series forecasting [C]// Advances in Neural Information Processing Systems . Vancouver: MIT Press, 2019: 32.
JIN W, MA Y, LIU X, et al. Graph structure learning for robust graph neural networks [C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . New York: ACM, 2020: 66–74.
PAREJA A, DOMENICONI G, CHEN J, et al. Evolvegcn: evolving graph convolutional networks for dynamic graphs [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020(34): 5363–5370.
CHEN Y, SEGOVIA I, GEL Y R. Z-gcnets: time zigzags at graph convolutional networks for time series forecasting [C]// International Conference on Machine Learning . [s.l.]: PMLR, 2021: 1684–1694.
BAI L, YAO L, LI C, et al. Adaptive graph convolutional recurrent network for traffic forecasting [C]// Advances in Neural Information Processing Systems . [s.l.]: MIT Press, 2020, 33: 17804–17815.
CAO D, WANG Y, DUAN J, et al. Spectral temporal graph neural network for multivariate time-series forecasting [C]// Advances in Neural Information Processing Systems . [s.l.]: MIT Press, 2020, 33: 17766–17778.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 30.
WU Z, PAN S, LONG G, et al. Graph wavenet for deep spatial-temporal graph modeling [C]// Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence . Macao: Morgan Kaufmann, 2019: 1907–1913.
LAI G, CHANG W C, YANG Y, et al. Modeling long-and short-term temporal patterns with deep neural networks [C]// The 41st International ACM SIGIR Conference on Research and Development in Information Retrieval . Ann Arbor: ACM, 2018: 95–104.
ZIVOT E, WANG J. Vector autoregressive models for multivariate time series [M]// Modeling financial time series with S-PLUS ®. Berlin: Springer, 2006: 385–429.
HUANG S, WANG D, WU X, et al. Dsanet: dual self-attention network for multivariate time series forecasting [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management . Beijing: ACM, 2019: 2129–2132.
YU B, YIN H, ZHU Z. Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence . Stockholm: Morgan Kaufmann, 2018: 3634–3640.
GUO S, LIN Y, FENG N, et al. Attention based spatialtemporal graph convolutional networks for traffic flow forecasting [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Honolulu: AAAI, 2019(33): 922–929.
SONG C, LIN Y, GUO S, et al. Spatial-temporal synchronous graph convolutional networks: a new framework for spatial-temporal network data forecasting [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020(34): 914–921.
RASUL K, SEWARD C, SCHUSTER I, et al. Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting [C]// International Conference on Machine Learning . [s.l.]: PMLR, 2021: 8857–8868.
A review of recurrent neural networks: LSTM cells and network architectures
1
2019
... 长短期记忆(long short term memory, LSTM)网络和门控循环单元(gated recurrent unit, GRU)在捕捉长序列语义关联时,都能有效抑制传统RNN中存在的梯度消失或爆炸问题;并且,相对于LSTM,GRU参数量更少,训练速度更快,更适用于构建较大的网络[27]. 因此,使用GRU对时序的历史数据进行编码. ...



{kind=link}
{kind=link}