[1]
CAO B, ARAUJO A, SIM J. Unifying deep local and global features for image search [C]// European Conference on Computer Vision . Glasgow: Springer, 2020: 726−743.
[本文引用: 1]
[2]
DOU Z, CUI H, ZHANG L, et al. Learning global and local consistent representations for unsupervised image retrieval via deep graph diffusion networks [EB/OL]. (2020-06-11)[2023-08-22]. https://arxiv.org/abs/2001.01284.
[本文引用: 1]
[3]
ZHUANG P, WANG Y, QIAO Y. Learning attentive pairwise interaction for fine-grained classification [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020: 13130−13137.
[本文引用: 2]
[4]
BEHERA A, WHARTON Z, HEWAGE P R P G, et al. Context-aware attentional pooling for fine-grained visual classification [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2021: 929−937.
[本文引用: 3]
[5]
HU T, QI H, HUANG Q, et al. See better before looking closer: weakly supervised data augmentation network for fine-grained visual classification [EB/OL]. (2019-03-23)[2023-8-22]. https://arxiv.org/abs/1901.09891.
[本文引用: 2]
[6]
王波, 黄冕, 刘利军, 等 基于多层聚焦Inception-V3卷积网络的细粒度图像分类
[J]. 电子学报 , 2022 , 50 (1 ): 72 - 78
[本文引用: 1]
WANG Bo, HUANG Mian, LIU Lijun, et al Multi-layer focused Inception-V3 models for fine-Grained visual recognition
[J]. Acta Electronica Sinica , 2022 , 50 (1 ): 72 - 78
[本文引用: 1]
[7]
DU R, CHANG D, BHUNIA A K, et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches [C]// European Conference on Computer Vision . Glasgow: Springer, 2020: 726−743.
[本文引用: 3]
[8]
SONG J, YANG R. Feature boosting, suppression, and diversification for fine-grained visual classification [C]// 2021 International Joint Conference on Neural Networks . Shenzhen: IEEE, 2021: 1−8.
[本文引用: 2]
[9]
RAO Y, CHEN G, LU J, et al. Counterfactual attention learning for fine-grained visual categorization and reidentification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 1025−1034.
[本文引用: 2]
[10]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [C]// Proceedings of the International Conference on Learning Representations . Washington DC: ICLR, 2021: 1−22.
[本文引用: 1]
[11]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . New York: Curran Associates, 2017: 6000−6010.
[本文引用: 1]
[12]
WANG J, YU X, GAO Y. Feature fusion vision transformer for fine-grained visual categorization [C]// Proceedings of the British Machine Vision Conference . Durham: BMVA, 2021: 685−698.
[本文引用: 3]
[13]
HE J, CHEN J N, LIU S, et al. Transfg: a transformer architecture for fine-grained recognition [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2022: 852−860.
[本文引用: 4]
[14]
SUN H, HE X, PENG Y. Sim-trans: structure information modeling transformer for fine-grained visual categorization [C]// Proceedings of the 30th ACM International Conference on Multimedia . Ottawa: ACM, 2022: 5853−5861.
[本文引用: 2]
[15]
LI S, WANG Z, LIU Z, et al. Efficient multi-order gated aggregation network [EB/OL]. (2023-03-20)[2023-8-22]. https://arxiv.org/abs/2211.03295.
[本文引用: 3]
[16]
DO T, TRAN H, TJIPUTRA E, et al. Fine-grained visual classification using self assessment classifier [EB/OL]. (2022-05-21)[2023-8-22]. https://arxiv.org/abs/2205.10529.
[本文引用: 3]
[17]
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: ACL, 2014: 1532−1543.
[本文引用: 1]
[18]
KIM J H, JUN J, ZHANG B T. Bilinear attention networks [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . New York: Curran Associates, 2018: 1571−1581.
[本文引用: 1]
[19]
BERA A, WHARTON Z, LIU Y, et al Sr-gnn: spatial relation-aware graph neural network for fine-grained image categorization
[J]. IEEE Transactions on Image Processing , 2022 , 31 : 6017 - 6031
DOI:10.1109/TIP.2022.3205215
[本文引用: 1]
[20]
ZHU H, KE W, LI D, et al. Dual cross-attention learning for fine-grained visual categorization and object reidentification [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 4692−4702.
[本文引用: 3]
[21]
ZHAO Y, LI J, CHEN X, et al Part-guided relational transformers for fine-grained visual recognition
[J]. IEEE Transactions on Image Processing , 2021 , 30 : 9470 - 9481
DOI:10.1109/TIP.2021.3126490
[本文引用: 1]
1
... 目前,深度学习在图像分类领域已经广泛应用,并在建筑图像识别领域取得了显著进展. Cao等[1 ] 提出统一局部和全局特征的模型,使用全局特征有效筛选相似图像,并利用局部特征重新排序,从而提高识别精度. Dou等[2 ] 通过图扩散网络以无监督的方式利用建筑图像流形的局部和全局结构来学习语义表示,保留建筑图像的全局信息,实现了可拓展的训练. 然而,相较于一般建筑图像分类任务,古塔建筑图像的类间差异小,类内差异大,不同古塔的差异主要体现在局部细节上,同一古塔本身也会因为拍摄角度、光照、遮挡等因素产生巨大的差异. 因此,在一般建筑图像识别任务上表现良好的方法,对古塔建筑图像分类的帮助非常有限. 如何准确定位到分类目标的判别性区域,获得更多不易被提取的关键特征,是更细地划分不同古塔图像的核心问题,本研究认为很适合引入细粒度分类的方法进行研究与探索. ...
1
... 目前,深度学习在图像分类领域已经广泛应用,并在建筑图像识别领域取得了显著进展. Cao等[1 ] 提出统一局部和全局特征的模型,使用全局特征有效筛选相似图像,并利用局部特征重新排序,从而提高识别精度. Dou等[2 ] 通过图扩散网络以无监督的方式利用建筑图像流形的局部和全局结构来学习语义表示,保留建筑图像的全局信息,实现了可拓展的训练. 然而,相较于一般建筑图像分类任务,古塔建筑图像的类间差异小,类内差异大,不同古塔的差异主要体现在局部细节上,同一古塔本身也会因为拍摄角度、光照、遮挡等因素产生巨大的差异. 因此,在一般建筑图像识别任务上表现良好的方法,对古塔建筑图像分类的帮助非常有限. 如何准确定位到分类目标的判别性区域,获得更多不易被提取的关键特征,是更细地划分不同古塔图像的核心问题,本研究认为很适合引入细粒度分类的方法进行研究与探索. ...
2
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
3
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
2
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
基于多层聚焦Inception-V3卷积网络的细粒度图像分类
1
2022
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
基于多层聚焦Inception-V3卷积网络的细粒度图像分类
1
2022
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
3
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
2
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
2
... 传统的细粒度分类方法通过增强卷积神经网络中提取的特征图,挖掘潜在的判别性特征. Zhuang等[3 -4 ] 通过相互特征向量来捕获输入对中的语义差异,使得网络能够通过2幅图像之间的成对交互来专注地捕获对比线索. Hu等[5 -6 ] 借助注意力机制增强图像,根据特征图的响应裁剪原始图像并重新输入到网络. Du等[7 ] 提出渐进式训练策略,引导网络逐步从小粒度到大粒度的特征学习,并有效地将多粒度特征融合在一起. Song等[8 ] 引入特征增强和抑制模块,提取特征图中最显著的部分以获得特定的零件表示,并在后续训练中抑制该区域,迫使网络挖掘其他潜在的零件. Rao等[9 ] 提出反事实的注意力学习方法,通过最大化真实注意力图和反事实因果推理得到注意力图之间的差异,促使网络学习更有效的注意力图. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
1
... 传统基于卷积神经网络的细粒度分类方法存在特征提取不充分和关键特征利用率低的问题. ViT[10 ] 将Transformer[11 ] 应用到图像领域,其自注意力机制被一致认为可以自动搜索图像中有助于识别的重要部分,在此基础上,Wang等[12 ] 通过提取重要标记和设计新的选择模块有效引导网络选择鉴别性特征. He等[13 ] 聚合网络各层级上重要零件的信息,并设计注意力权重来筛选判别性的区域,进一步提高了网络捕获细微差异的能力. Sun等[14 ] 利用多尺度特征之间的互补关系和类间差异进行对比学习,提取包含外观信息和结构信息的判别性表示. ...
1
... 传统基于卷积神经网络的细粒度分类方法存在特征提取不充分和关键特征利用率低的问题. ViT[10 ] 将Transformer[11 ] 应用到图像领域,其自注意力机制被一致认为可以自动搜索图像中有助于识别的重要部分,在此基础上,Wang等[12 ] 通过提取重要标记和设计新的选择模块有效引导网络选择鉴别性特征. He等[13 ] 聚合网络各层级上重要零件的信息,并设计注意力权重来筛选判别性的区域,进一步提高了网络捕获细微差异的能力. Sun等[14 ] 利用多尺度特征之间的互补关系和类间差异进行对比学习,提取包含外观信息和结构信息的判别性表示. ...
3
... 传统基于卷积神经网络的细粒度分类方法存在特征提取不充分和关键特征利用率低的问题. ViT[10 ] 将Transformer[11 ] 应用到图像领域,其自注意力机制被一致认为可以自动搜索图像中有助于识别的重要部分,在此基础上,Wang等[12 ] 通过提取重要标记和设计新的选择模块有效引导网络选择鉴别性特征. He等[13 ] 聚合网络各层级上重要零件的信息,并设计注意力权重来筛选判别性的区域,进一步提高了网络捕获细微差异的能力. Sun等[14 ] 利用多尺度特征之间的互补关系和类间差异进行对比学习,提取包含外观信息和结构信息的判别性表示. ...
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
4
... 传统基于卷积神经网络的细粒度分类方法存在特征提取不充分和关键特征利用率低的问题. ViT[10 ] 将Transformer[11 ] 应用到图像领域,其自注意力机制被一致认为可以自动搜索图像中有助于识别的重要部分,在此基础上,Wang等[12 ] 通过提取重要标记和设计新的选择模块有效引导网络选择鉴别性特征. He等[13 ] 聚合网络各层级上重要零件的信息,并设计注意力权重来筛选判别性的区域,进一步提高了网络捕获细微差异的能力. Sun等[14 ] 利用多尺度特征之间的互补关系和类间差异进行对比学习,提取包含外观信息和结构信息的判别性表示. ...
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
... Comparison of parameters numbers and calculation volume of different methods
Tab.6 方法 分辨率 Para/M Cal/G P /%TransFG[13 ] 448×448 86.2 62.0 95.4 Vit-SAC[15 ] 448×448 106.0 92.5 95.6 DCAL[20 ] 384×384 88.0 47.0 95.7 本研究算法 224×224 100.8 31.9 96.3
如图6 所示展示了本研究方法的不同结构在古塔建筑数据集上的可视化结果,以观察网络在提取特征时关注点的变化. 一个地区的颜色越深表明网络对其关注度越高,即越重要. 图6 (a)表示从测试数据集中随机抽取的2幅图像. 首先,测试了原始主干网络,图6 (b)表示经过主干网络MogaNet训练后的注意力图,原始主干网络倾向于生成大的预测区域,无法准确识别目标地边界,且模型会错误地关注到遮挡物和背景,表明原始主干并不是为检测细粒度数据中的细节而设计的. 其次,在主干中分别加入了CIE模块和FES策略,图6 (c)、(d)分别表示主干网络加入CIE和FES后训练得到的注意力图. 可以看出,单独使用CIE或FES均能使网络生成较为精细的预测区域. CIE模块引导深层特征关注到更多的局部细节信息和空间上下文信息,并且丢弃了冗余的特征,能起到初步抑制背景噪声的作用;FES策略可以去除模糊类特征点和背景特征点,模型可以捕捉到更精确、更具判别性的区域. 然而,FES策略限制了注意力区域,丢弃的特征点会导致最终用于分类的特征缺失部分空间上下文信息和全局视角,从而使精度的提升非常有限. 最后,本研究在主干网络上同时添加了CIE模块和FES策略,图6 (e)表示同时使用CIE和FES训练得到的注意力图,使用CIE模块得到包含空间上下文信息的特征后,再加入FES策略,使得整体注意力图能精确地映射整个待测目标的判别性区域,模型在捕捉更广泛的区域的同时保持了细节. 结果表明,本研究方法实现了更好的准确性. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
2
... 传统基于卷积神经网络的细粒度分类方法存在特征提取不充分和关键特征利用率低的问题. ViT[10 ] 将Transformer[11 ] 应用到图像领域,其自注意力机制被一致认为可以自动搜索图像中有助于识别的重要部分,在此基础上,Wang等[12 ] 通过提取重要标记和设计新的选择模块有效引导网络选择鉴别性特征. He等[13 ] 聚合网络各层级上重要零件的信息,并设计注意力权重来筛选判别性的区域,进一步提高了网络捕获细微差异的能力. Sun等[14 ] 利用多尺度特征之间的互补关系和类间差异进行对比学习,提取包含外观信息和结构信息的判别性表示. ...
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
3
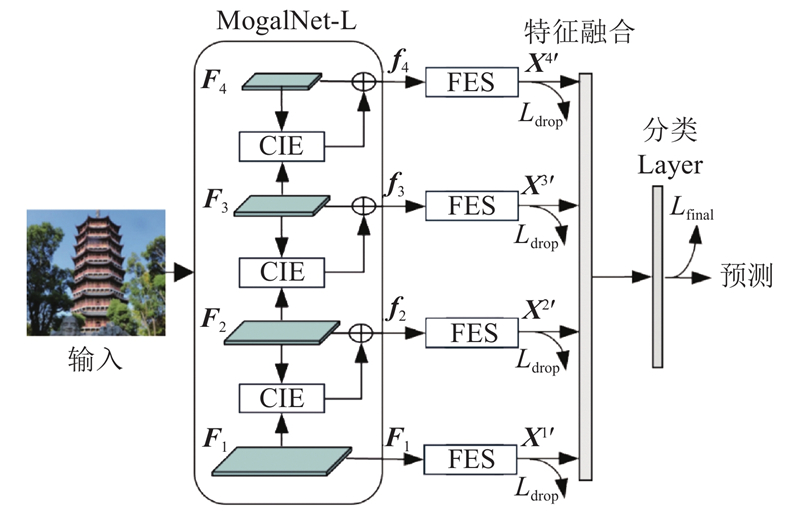
... 根据上述分析,本研究提出多尺度上下文信息引导特征消除的古塔建筑图像分类方法. 首先,使用MogaNet (efficient multi-order gated aggregation network)[15 ] 作为主干网络,在训练阶段提取多尺度的特征,设计上下文信息提取器(contextual information extractor,CIE)去除上下文的冗余信息,从深层特征中提取具有空间上下文的细粒度局部特征,捕捉每个区域的细微变化;其次,设计特征消除策略(feature elimination strategy,FES),减少模糊类特征和背景对分类的影响,提高处理不明确目标和复杂背景的质量;最后,融合不同深度的特征以生成精细的预测区域. 同时,建立了自然场景下的中国古塔建筑图像数据集,为细粒度图像分类领域内针对复杂背景和模糊边界的研究提供数据支撑,并结合本研究方法实现对古塔建筑的精确分类. ...
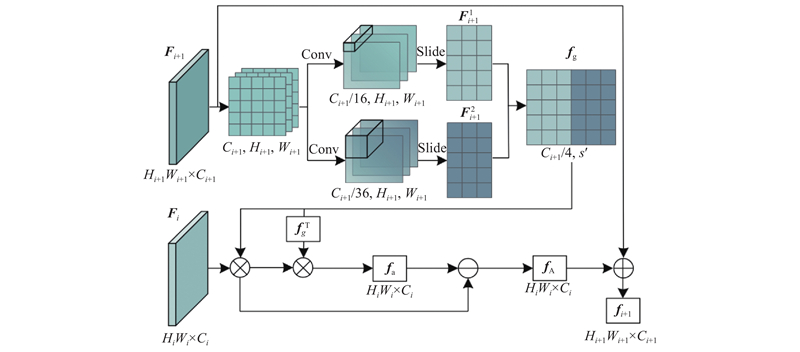
... 主干网络决定了算法的特征提取能力及在下游任务中的应用潜力,选择优秀的主干可以帮助网络聚焦在细粒度问题的改进上. 最近的研究表明,通过先进的训练设置和更新后的结构,卷积神经网络也可以在不增加计算量的情况下得到媲美ViT甚至更优的性能. Li等[15 ] 设计的MogaNet采用改进的卷积宏架构和优化策略,在相同的参数量下得到了更快的推理速度以及更高的准确率. MogaNet在纯卷积网络中进行信息挖掘和通道聚合,在一般图像分类、图像检索和语义分割方面以较低的计算成本显著优于当前主流主干网络. 这一巨大成功表明,MogaNet网络可以提取出非常强大的特征,其在下游任务中的迁移学习潜能十足. 本研究选择的MogaNet-L包含4个阶段,输入图像经过不同阶段后可得到不同尺度下的特征图$ {{\boldsymbol{F}}_i} ,\;{{\boldsymbol{F}}_i}\in {{\mathbf{R}}^{{H_i} {W_i}\times{C_i}}} $ i 表示主干网络的阶段数,$ i \in [1,4] $ ${H_i}、{W_i}、{C_i}$
... Comparison of parameters numbers and calculation volume of different methods
Tab.6 方法 分辨率 Para/M Cal/G P /%TransFG[13 ] 448×448 86.2 62.0 95.4 Vit-SAC[15 ] 448×448 106.0 92.5 95.6 DCAL[20 ] 384×384 88.0 47.0 95.7 本研究算法 224×224 100.8 31.9 96.3
如图6 所示展示了本研究方法的不同结构在古塔建筑数据集上的可视化结果,以观察网络在提取特征时关注点的变化. 一个地区的颜色越深表明网络对其关注度越高,即越重要. 图6 (a)表示从测试数据集中随机抽取的2幅图像. 首先,测试了原始主干网络,图6 (b)表示经过主干网络MogaNet训练后的注意力图,原始主干网络倾向于生成大的预测区域,无法准确识别目标地边界,且模型会错误地关注到遮挡物和背景,表明原始主干并不是为检测细粒度数据中的细节而设计的. 其次,在主干中分别加入了CIE模块和FES策略,图6 (c)、(d)分别表示主干网络加入CIE和FES后训练得到的注意力图. 可以看出,单独使用CIE或FES均能使网络生成较为精细的预测区域. CIE模块引导深层特征关注到更多的局部细节信息和空间上下文信息,并且丢弃了冗余的特征,能起到初步抑制背景噪声的作用;FES策略可以去除模糊类特征点和背景特征点,模型可以捕捉到更精确、更具判别性的区域. 然而,FES策略限制了注意力区域,丢弃的特征点会导致最终用于分类的特征缺失部分空间上下文信息和全局视角,从而使精度的提升非常有限. 最后,本研究在主干网络上同时添加了CIE模块和FES策略,图6 (e)表示同时使用CIE和FES训练得到的注意力图,使用CIE模块得到包含空间上下文信息的特征后,再加入FES策略,使得整体注意力图能精确地映射整个待测目标的判别性区域,模型在捕捉更广泛的区域的同时保持了细节. 结果表明,本研究方法实现了更好的准确性. ...
3
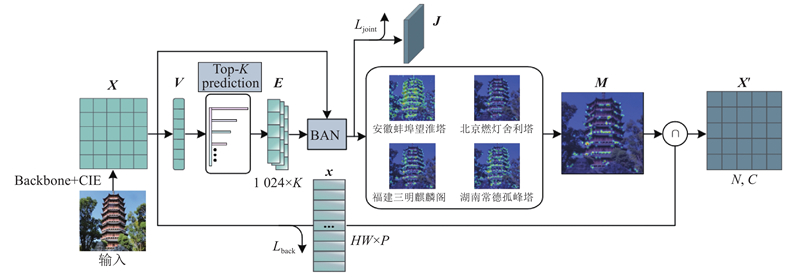
... 模糊类别是指预测的分类分数相近的结果,这是导致错误分类的主要原因之一. 通过上述CIE得到包含上下文信息的特征后,为了进一步消除背景及模糊类对网络的影响,帮助网络关注到更具判别性的特征,设计了特征消除策略,通过消除类间相似区域和背景特征,迫使网络关注到其他判别性特征. ViT-SAC(self assessment classifier)[16 ] 研究了前K 个预测类中的模糊性,并利用图像和前K 个的预测结果来重新评估分类. 本研究方法受其启发,不过,与它不同的是,1)本研究方法无须通过生成的特征图裁剪原始图片并重新输入进网络,实现了端到端的训练,避免了前一阶段的训练误差和错误对后一阶段网络训练的影响;2)本研究方法利用预测分数将特征图划分为对象候选区域和背景候选区域,在像素级上直接删掉对应的模糊类特征点和背景特征点. 由于CIE的输出${{\boldsymbol{f}}_{i+1}}$
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
1
... 模糊类特征消除分支用于消除前K 项模糊类共同关注的特征点. 首先,借助全连接层提取可视化特征${\boldsymbol{V}} \in {{\mathbf{R}}^{{d_{\rm{v}}}}}$ K 个预测结果,其中${d_{\rm{v}}}$ ${\boldsymbol{V}}$ [17 ] 的单词嵌入方法来学习类标签的语言模态信息$ {\boldsymbol{E}} = \left[ {{\boldsymbol{E}}_{\text{1}}}{\text{,}}\cdots\right. \left.{{\boldsymbol{E}}_k}{\text{,}}\cdots{\text{,}}{{\boldsymbol{E}}_K} \right] $ $ {{\boldsymbol{E}}_k} \in {{\mathbf{R}}^{{d_{\rm{e}}}}} $ ${d_{\rm{e}}}$ 1024 来表示每个类标签信息的维度. 通过双线性注意力网络 (bilinear attention network,BAN)[18 ] 来融合2种模态信息$ {\boldsymbol{X}} $ ${\boldsymbol{E}}$ ${{\boldsymbol{J}}} \in {{\mathbf{R}}^{{d_{\rm{e}}}}}$ $ {{\boldsymbol{M}}} \in {{\mathbf{R}}^{H \times W}} $
1
... 模糊类特征消除分支用于消除前K 项模糊类共同关注的特征点. 首先,借助全连接层提取可视化特征${\boldsymbol{V}} \in {{\mathbf{R}}^{{d_{\rm{v}}}}}$ K 个预测结果,其中${d_{\rm{v}}}$ ${\boldsymbol{V}}$ [17 ] 的单词嵌入方法来学习类标签的语言模态信息$ {\boldsymbol{E}} = \left[ {{\boldsymbol{E}}_{\text{1}}}{\text{,}}\cdots\right. \left.{{\boldsymbol{E}}_k}{\text{,}}\cdots{\text{,}}{{\boldsymbol{E}}_K} \right] $ $ {{\boldsymbol{E}}_k} \in {{\mathbf{R}}^{{d_{\rm{e}}}}} $ ${d_{\rm{e}}}$ 1024 来表示每个类标签信息的维度. 通过双线性注意力网络 (bilinear attention network,BAN)[18 ] 来融合2种模态信息$ {\boldsymbol{X}} $ ${\boldsymbol{E}}$ ${{\boldsymbol{J}}} \in {{\mathbf{R}}^{{d_{\rm{e}}}}}$ $ {{\boldsymbol{M}}} \in {{\mathbf{R}}^{H \times W}} $
Sr-gnn: spatial relation-aware graph neural network for fine-grained image categorization
1
2022
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
3
... Accuracy comparison of different methods on ancient tower dataset
Tab.5 方法 主干网络 分辨率 P /%PMG[7 ] Resnet50 448×448 94.2 FBSD[8 ] Densenet161 448×448 94.5 TransFG[13 ] ViT-B_16 448×448 94.5 FFVT[12 ] ViT-B_16 448×448 94.8 SIM-Trans[14 ] ViT-B_16 448×448 94.8 CAP[4 ] Xception 224×224 94.9 ViT-SAC[16 ] ViT-B_16 448×448 95.4 SR-GNN[19 ] Xception 224×224 95.6 DCAL[20 ] R50-ViT-Base 448×448 95.7 本研究算法 MogaNet-L 224×224 96.3
如表6 所示,本研究模型总参数量达到100.8 M,计算量为31.9 G. 列举几种已公开源码方法的参数量和计算量,可以看出,在参数量相差不多的前提下,由于使用了更小的图像分辨率 (224×224),模型的计算量相较其他方法有明显的下降,同时获得了更高的准确率. ...
... Comparison of parameters numbers and calculation volume of different methods
Tab.6 方法 分辨率 Para/M Cal/G P /%TransFG[13 ] 448×448 86.2 62.0 95.4 Vit-SAC[15 ] 448×448 106.0 92.5 95.6 DCAL[20 ] 384×384 88.0 47.0 95.7 本研究算法 224×224 100.8 31.9 96.3
如图6 所示展示了本研究方法的不同结构在古塔建筑数据集上的可视化结果,以观察网络在提取特征时关注点的变化. 一个地区的颜色越深表明网络对其关注度越高,即越重要. 图6 (a)表示从测试数据集中随机抽取的2幅图像. 首先,测试了原始主干网络,图6 (b)表示经过主干网络MogaNet训练后的注意力图,原始主干网络倾向于生成大的预测区域,无法准确识别目标地边界,且模型会错误地关注到遮挡物和背景,表明原始主干并不是为检测细粒度数据中的细节而设计的. 其次,在主干中分别加入了CIE模块和FES策略,图6 (c)、(d)分别表示主干网络加入CIE和FES后训练得到的注意力图. 可以看出,单独使用CIE或FES均能使网络生成较为精细的预测区域. CIE模块引导深层特征关注到更多的局部细节信息和空间上下文信息,并且丢弃了冗余的特征,能起到初步抑制背景噪声的作用;FES策略可以去除模糊类特征点和背景特征点,模型可以捕捉到更精确、更具判别性的区域. 然而,FES策略限制了注意力区域,丢弃的特征点会导致最终用于分类的特征缺失部分空间上下文信息和全局视角,从而使精度的提升非常有限. 最后,本研究在主干网络上同时添加了CIE模块和FES策略,图6 (e)表示同时使用CIE和FES训练得到的注意力图,使用CIE模块得到包含空间上下文信息的特征后,再加入FES策略,使得整体注意力图能精确地映射整个待测目标的判别性区域,模型在捕捉更广泛的区域的同时保持了细节. 结果表明,本研究方法实现了更好的准确性. ...
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...
Part-guided relational transformers for fine-grained visual recognition
1
2021
... Comparison of accuracy of different algorithms on fine-grained datasets
Tab.7 方法 主干网络 分辨率 P /%CUB-200-2011 Stanford Cars Aircraft WS-DAN[5 ] Inception v3 448×448 89.4 94.5 93.0 PMG[7 ] ResNet-50 550×550 89.6 95.1 93.4 API-Net[3 ] DenseNet-161 512×512 90.0 95.3 93.9 PART[21 ] ResNet-101 448×448 90.1 95.3 94.6 CAL[9 ] ResNet-101 448×448 90.6 95.5 94.2 FFVT[12 ] ViT-B_16 448×448 91.6 94.1 94.3 TransFG[13 ] ViT-B_16 448×448 91.7 94.8 94.1 CAP[4 ] Xception 224×224 91.8 95.7 94.5 ViT-SAC[16 ] ViT-B_16 448×448 91.8 95.0 93.1 DCAL[20 ] R50-ViT-Base 448×448 92.0 95.3 93.3 本研究方法 MogaNet-L 224×224 92.4 95.3 94.6
Stanford Cars数据集按照不同品牌、型号和年份进行划分,包含了196类汽车的16 185张图像,本研究方法在该数据集上取得了95.3%的准确率性能,取得了与大多数对比方法非常相似的结果,具有一定的优越性. 所提方法性能不如CAP及CAL方法,不过总体上相差较小. 其原因在于Stanford Cars比其他数据集具有更分明的轮廓边界和更简单的背景,同一类别的样本之间的差异很小,本研究针对模糊边界和复杂背景的改进未有明显体现. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}