

控制单元的数量和变量复杂,因此传统的多参数监测方法对早期故障的检测效果不理想. 分布式方法避免了直接从复杂的全厂流程中检测早期故障,能够提高检测的准确性[6]. 分布式方案通常包括3个步骤:子空间划分、子空间模型的建立和信息融合决策. 1)多子空间划分一般分为2种方法:知识型和数据驱动型. 知识型方法通常根据过程知识或专家经验将过程变量划分成块. 数据驱动型方法分为2类,一类根据变量之间的相关性划分子空间,如Wang等[7]使用负载矩阵的广义骰子系数来划分过程变量,形成多子空间监控框架;另一类根据故障类型区分过程变量[8],如Jiang等[9]提出基于故障相关变量选择的分布式PCA监控方法,可根据工业流程中的故障类型划分过程变量. 知识型或数据驱动型方法进行子空间划分忽略了过程信息与相应操作单元物理位置之间的相关性,分布式方案中子空间可能不是最佳划分. 2)子空间监测领域的现有方法包括常规分析方法[10]、统计方法[11-12]和智能方法[13]. 其中基于统计分析的检测方法完全依赖系统的过程数据,无需深入了解系统的内部结构,使用效率高,是早期故障检测领域应用较广泛的技术. Deng等[14]提出基于核PCA的两步局部信息挖掘框架,用于非线性的早期故障检测和隔离. Pilario等[15]提出典型变量分析(canonical variate analysis, CVA)的扩展,利用典型变量相异分析(canonical variate dissimilarity analysis, CVDA)来检测早期故障. 早期故障特征微弱,增大故障断层偏移量有助于检测工作的开展,滑动窗口法是被证明的有效方法. Qin等[16]提出将相关统计分析和滑动窗口技术相结合的新算法,增强了早期故障的微弱特征,实现了早期故障的检测. 关注数据的局部特征也可以增强早期故障的检测能力,其中基于密度的异常检测方法能够在确定置信区域时避免过程数据服从正态分布的假设,并在确定置信区域时减少训练数据中离群值的影响[17]. 3)在信息融合决策方面,一般采用贝叶斯推理方法对所有子空间的检测结果进行融合,实现全厂过程检测结果的集成[18].
本研究提出基于多子空间加权移动窗主成分分析的分布式故障检测模型,用于全厂流程的早期故障检测. 1)使用基于过程知识和数据驱动的双层子空间划分框架划分过程变量,将早期故障检测的视角从全局转向局部,提前发现早期故障;2)使用加权移动窗口法实现窗口内数据的差异化处理;3)考虑数据集的局部和全局属性,采用局部离群因子(local outlier factor, LOF)算法结合主成分分析法构建统计量.
1. 多子空间加权移动窗主成分分析
1.1. 两层子空间划分框架
1.1.1. 基于过程知识的子空间划分
分布式方案须将过程变量划分为不同的相关区块. 基于过程知识划分,过程变量可以保留同一区块内变量之间的依赖关系,准确反映实际的物理和化学关系,使子空间划分更具针对性. 为此根据工艺知识划分得到一级子空间. 为了解决连接变量的子空间划分问题,将连接2个单元的过程变量归纳至相邻的区块,进行粗略划分,以便在不使用完整过程知识的情况下指定数据驱动划分的区域[19]. 根据该策略,过程变量
式中:
1.1.2. 基于互信息和谱聚类算法的子空间划分
为了更好地表示变量之间的线性和非线性关系,使用互信息(mutual information, MI)和谱聚类算法划分一级子空间[20]. MI是用于测量2个变量之间的线性和非线性关系的统计技术;谱聚类算法通常考虑变量之间的相似性,特别是在涉及空间或位置相关性的问题上,提高划分的合理性. 过程变量划分工作结束后,变量被初步划分为B块. 通过计算每个区块内每对变量之间的互信息,将这些互信息值合并成矩阵形式,称为互信息矩阵:
式中:
式中:
列向量
子空间中
1.2. 结合局部离群因子的加权移动窗PCA子空间建模
划分子空间后,基于PCA结合加权移动窗和LOF,在二层子空间的所有子块中建立故障模型.
1.2.1. 加权移动窗口重建数据
将数据标准化后,确定长度为d的移动窗口,为窗口中的数据分配不同的权重. 在时间k−d+1之前引入故障的数据处理:
式中:
1.2.2. PCA及主元素概率密度函数计算
式中:
h的近似值由平均综合平方误差MISE决定,即最小化L2损失函数.
1.2.3. 结合局部离群因子计算控制限
降秩矩阵由LOF处理,得到 LOF值后,将LOF值作为统计量使用,结合概率密度函数得到相应的控制限值TC. 数据
式中:k为数据个数,
1.3. 贝叶斯统计融合决策
使用贝叶斯推断对所有子空间的统计数据进行统计合并,得出监测结果. 与J相对应的子空间
条件概率
式中:N、F分别表示正常状态和故障状态;
当
1.4. 离线建模和在线监测程序
1.4.1. 离线建模
1)训练数据标准化. 2)根据粗略获得的过程知识将过程变量划分为第一层子空间,通过MI谱聚类算法进一步划分第二层子空间,选择最优聚类数. 3)对经过预处理的数据使用加权移动窗进行重构. 在划定的第二层子空间中构建PCA-LOF(缩写为PL)检测模型,得到各子空间的检测结果. 4)通过贝叶斯推理融合得到联合统计量
1.4.2. 在线监测
将标准化后的测试数据输入,根据离线建模阶段生成的模型,生成联合统计量
图 1

图 1 基于多子空间加权移动窗主成分分析模型示意图
Fig.1 Schematic diagram of multiple subspace weighted moving window PCA model
2. 案例分析
2.1. 田纳西-伊斯曼过程简介与仿真设置
为了验证所提算法的通用性,针对早期故障的准确性和及时性,选取属于工业过程中不同类型的故障(阶跃类型的故障4、随机振荡类型的故障8、慢漂移类型的故障13和未知类型的故障18)作为一组实验数据,尽量包含更多实际的数据类型. 实验数据分别使用4种对照算法检测,分析故障的检测结果. 对照组算法按照多元统计分析针对早期故障检测的性能增强逻辑选择,即常规多元统计分析算法、引入滑动窗口的早期故障增强多元统计分析算法、使用分布式的多元统计分析算法以及综合性算法. 4种算法分别是主成分分析、局部离群因子的加权移动窗主成分分析(W-PL)、结合局部离群因子的多子空间主成分分析(M-PL)、多子空间加权移动窗主成分分析(M-WP). 在对照组算法中,分布式方案通常选取TEP的前52个变量建立模型. 过程变量经过双层子空间划分后的分布结果如表1所示. 第一层的初级子空间依据粗略获得的过程知识划分,无法准确划分的连接变量被直接同时划分到不同子空间中;随后由MI与谱聚类算法对第一层的初级子空间再次划分,得到第二层子空间划分结果.
表 1 田纳西-伊斯曼过程的双层子空间划分结果
Tab.1
| 区块 | 第一层 | 子区块 | 第二层 |
| 1 | 1.1 | ||
| 1.2 | |||
| 1.3 | |||
| 1.4 | |||
| 2 | 2.1 | ||
| 2.2 | |||
| 3 | 3.1 |
2.2. 仿真结果与分析
针对故障4,4种故障检测模型的仿真结果如图2所示. TEP的采样点共960个,纵轴代表各模型的实时统计量,其中T2衡量样本在主成分空间中的位置,反映投影相对于总体平均的偏差;SPE衡量样本在残差空间的位置,反映样本中未被主成分模型捕获部分的偏差;lof为模型在线检测时某一时刻各变量的LOF参数之和,lof越大代表样本点与正常样本差异越大;BIC取值范围为[0, 1.0],取值越接近1.0代表该采样时刻各子空间中的数据超限越多,故障越明显. 图中虚线为对应检测模型的控制限,当曲线超过控制限时,检测模型会发出警报. 可以看出,PCA 的T2统计量漏报率过高,SPE 统计量虽然漏报率为0,但误报率明显高于其他模型;W-PL的误报、漏报率相较PCA都有明显改善,M-PL的误报率相较PCA有明显降低; M-WP的误报率和漏报率在W-PL的基础上进一步降低,该方法的性能明显优于其他方法. 由于故障4是阶跃型故障,4种算法的故障检出点基本一致,没有明显变化.
图 2
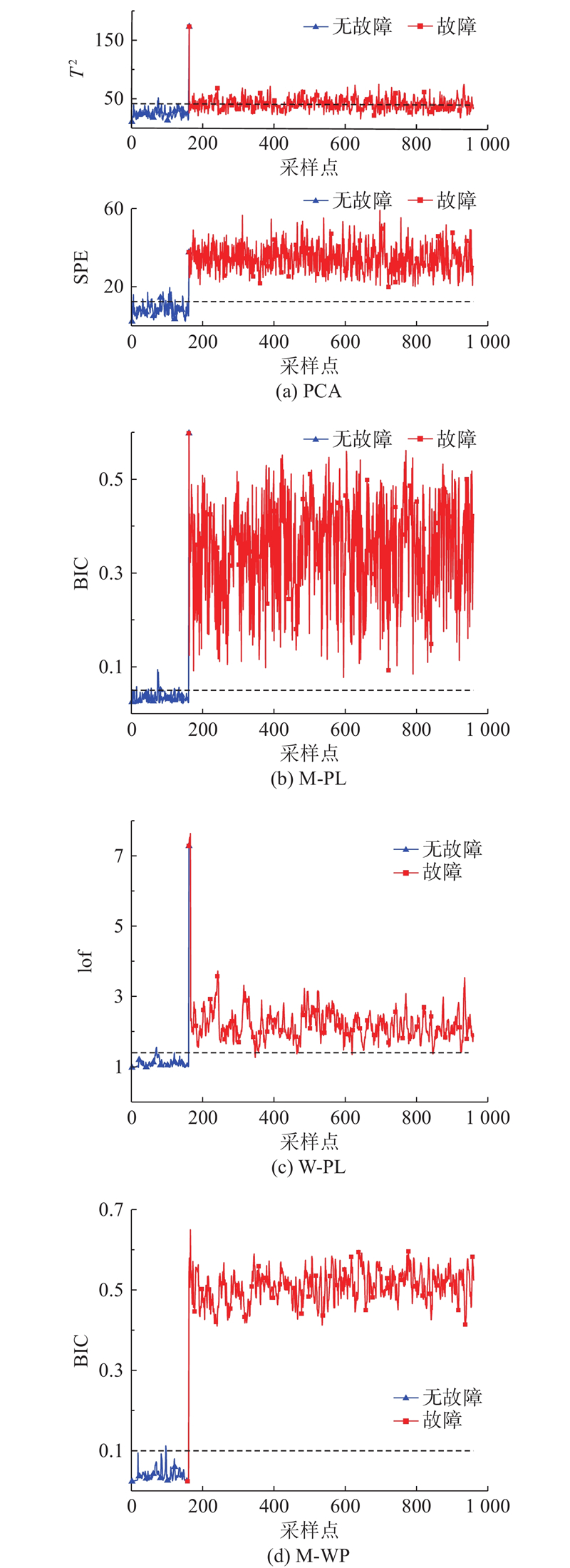
图 2 故障4基于不同算法的仿真结果
Fig.2 Simulation results of fault 4 based on different algorithms
针对故障13,4种故障检测模型的仿真结果如图3 所示. 可以看出,PCA 的 SPE 统计量漏报率较低,但误报率明显高于其他模型;W-PL误报率为0,同时漏报率也有所降低,M-PL漏报率再次降低,误报却有所提升;M-WP在漏报率结果相对优秀的情况下,有效降低了误报率,综合精度最优. 故障13的检出点显示,PCA的T2统计量和SPE 统计量分别为第211和205个检测点,W-PL和M-PL的检测点分别为第190和199个检测点,M-WP的故障检测点为第187个. 由检测点对比可以看出,所提方法的灵敏度明显优于对照组算法.
图 3
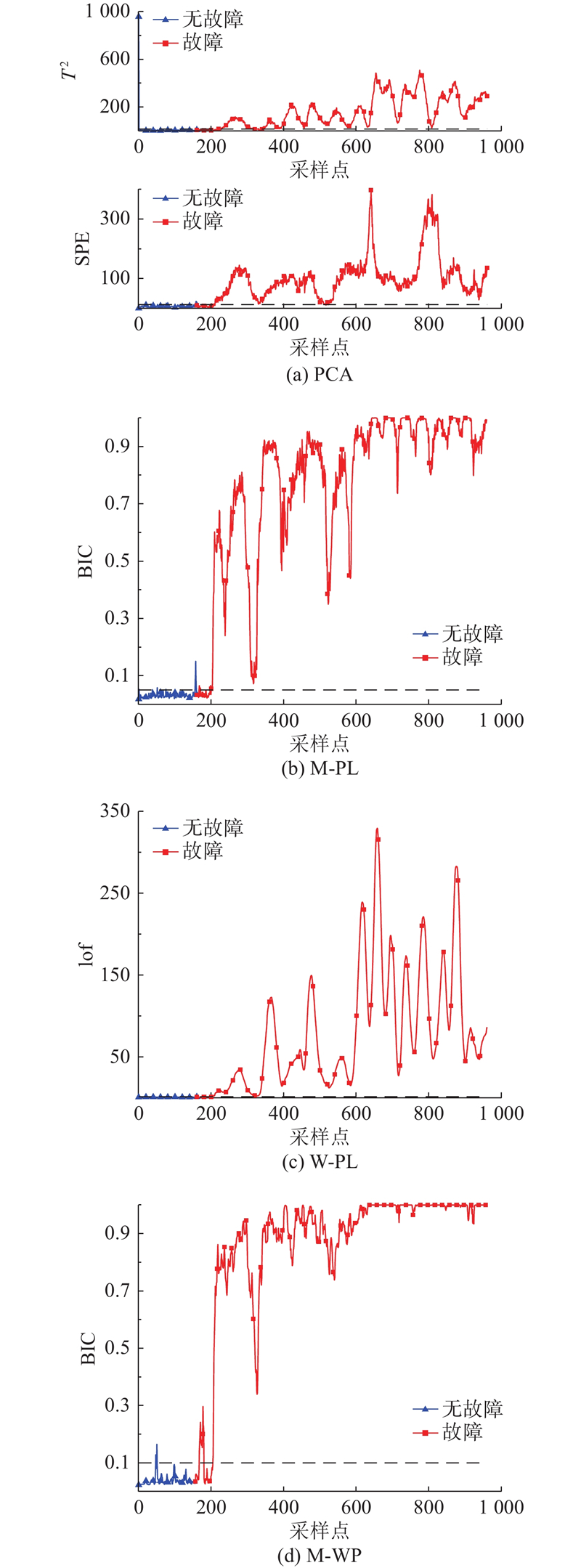
图 3 故障13基于不同算法的仿真结果
Fig.3 Simulation results of fault 13 based on different algorithms
图 4

图 4 故障8基于不同算法的仿真结果
Fig.4 Simulation results of fault 8 based on different algorithms
图 5

图 5 故障18基于不同算法的仿真结果
Fig.5 Simulation results of fault 18 based on different algorithms
故障误报率(false alarm rate, FAR)是指在引入故障之前的正常工况下(采样点1~160),统计量超过控制限导致错误报警的比例;故障检测率(fault detection rate,FDR)是指在故障工况下(采样点161~960),统计量超出控制限时系统正常预警的比例. 故障检测模型的FAR越小,代表误报警次数越少;FDR越大,代表模型的检测效果越好. 故障4、8、13、18检测的详细数据结果如表2所示,4种算法对21种故障检测的平均准确率如下:PCA的T2和SPE统计量分别为64.1%与75.4%,W-PL为75.2%,M-PL为76.1%,所提算法M-WP为82.3%. 所提方法的平均准确率远高于PCA、W-PL和M-PL. M-WP在任意测试集上的故障检出点都比对照组算法的提前数个至数十个点位. 综上所述,所提方法在检测早期故障方面具有很大优势,能够在保证算法通用性的前提下,有效提高算法针对早期故障的检测性能.
表 2 故障工况的误报率和故障检测率
Tab.2
| 算法 | 统计 参数 | 故障4 | 故障8 | 故障13 | 故障18 | |||||||
| FAR | FDR | FAR | FDR | FAR | FDR | FAR | FDR | |||||
| PCA | 2.50 | 49.63 | 1.25 | 97.37 | 1.87 | 90.03 | 3.12 | 87.52 | ||||
| PCA | 13.13 | 100 | 16.87 | 97.75 | 10.04 | 92.64 | 12.52 | 89.89 | ||||
| W-PL | 2.76 | 99.25 | 3.45 | 97.25 | 0 | 94.28 | 6.21 | 89.27 | ||||
| M-PL | BIC | 8.13 | 100 | 7.50 | 97.88 | 5.00 | 95.21 | 5.62 | 89.14 | |||
| M-WP | BIC | 0.70 | 99.88 | 1.92 | 99.11 | 1.92 | 95.93 | 3.20 | 91.61 | |||
3. 结 语
为了有效提升全流程过程中早期故障检测的性能,提出基于多子空间加权移动窗主成分分析的监测方法,用于全厂过程的早期故障检测. 基于过程知识和数据驱动的双层子空间划分框架将早期故障的监测视角从全局变为局部;在处理数据时使用加权滑动窗口,实现了窗口中数据的信号增强和差异化处理;考虑数据集的局部和全局属性,构建基于PL的统计量,比较检测数据与参考模型之间的差异;在TEP中测试所提方法的性能. 所提方法能够针对全厂流程中的早期故障进行有效检测. 相比传统多元统计分析方法,所提方法在准确率提升的前提下,检测的灵敏度大幅提升. 所提模型对某些特定的微小故障的检测率欠佳,原因可能在于无法分离出导致微小故障发生的因果变量与受到耦合作用影响的其他变量,导致因果变量的变化被掩盖. 下一步研究计划针对微小早期故障的因果变量分离、减弱耦合作用影响,实现全类型早期故障的高准确率检测.
参考文献
In-depth evaluation of data collected during a continuous pharmaceutical manufacturing process: a multivariate statistical process monitoring approach
[J].DOI:10.1016/j.xphs.2018.07.033 [本文引用: 1]
A distributed adaptive monitoring method for performance indicator in large-scale dynamic process
[J].
Principal component analysis-based ensemble detector for incipient faults in dynamic processes
[J].DOI:10.1109/TII.2020.3031496 [本文引用: 1]
金矿生产全流程控制系统设计与实现
[J].
Design and implementation of whole process control system for gold ore production
[J].
A dual robustness projection to latent structure method and its application
[J].DOI:10.1109/TIE.2020.2970664 [本文引用: 1]
Progress of process monitoring for the multi-mode process: a review
[J].DOI:10.3390/app12147207 [本文引用: 1]
Generalized dice’s coefficient-based multi-block principal component analysis with bayesian inference for plant-wide process monitoring
[J].DOI:10.1002/cem.2687 [本文引用: 1]
Complex system monitoring based on distributed least squares method
[J].
Performance-driven distributed PCA process monitoring based on fault-relevant variable selection and bayesian inference
[J].
Extraction of reduced fault subspace based on KDICA and its application in fault diagnosis
[J].
基于集成学习传递熵的化工过程微小故障检测方法
[J].
Incipient fault detection method for chemical process based on ensemble learning transfer entropy
[J].
A cumulative canonical correlation analysis-based sensor precision degradation detection method
[J].
Real-time fault diagnosis for gas turbine generator systems using extreme learning machine
[J].
Two-step localized kernel principal component analysis based incipient fault diagnosis for nonlinear
[J].DOI:10.1021/acs.iecr.9b06826 [本文引用: 1]
Canonical variate dissimilarity analysis for process incipient fault detection
[J].DOI:10.1109/TII.2018.2810822 [本文引用: 1]
Recursive correlative statistical analysis method with sliding windows for incipient fault detection
[J].DOI:10.1109/TIE.2021.3070521 [本文引用: 1]
Process monitoring of abnormal working conditions in the zinc roasting process with an ALD-based LOF-PCA method
[J].DOI:10.1016/j.psep.2022.03.064 [本文引用: 1]
Mutual information-based sparse multiblock dissimilarity method for incipient fault detection and diagnosis in plant-wide process
[J].DOI:10.1016/j.jprocont.2019.09.004 [本文引用: 1]
Hierarchical hybrid distributed PCA for plant-wide monitoring of chemical processes
[J].DOI:10.1016/j.conengprac.2021.104784 [本文引用: 1]
Conditional likelihood maximisation: a unifying framework for information theoretic feature selection
[J].
A data-driven Bayesian network learning method for process fault diagnosis
[J].DOI:10.1016/j.psep.2021.04.004 [本文引用: 1]
Data-driven and deep learning-based detection and diagnosis of incipient faults with application to electrical traction systems
[J].DOI:10.1016/j.neucom.2018.07.103 [本文引用: 1]
Detecting anomalies in sequential data augmented with new features
[J].DOI:10.1007/s10462-018-9671-x [本文引用: 1]
Nonlinear plant-wide process monitoring using MI-spectral clustering and Bayesian inference-based multiblock KPCA
[J].DOI:10.1016/j.jprocont.2015.04.014 [本文引用: 1]
A plant-wide industrial process control problem
[J].DOI:10.1016/0098-1354(93)80018-I [本文引用: 1]
Novel discriminant locality preserving projection integrated with Monte Carlo sampling for fault diagnosis
[J].DOI:10.1109/TR.2021.3115108 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}