[1]
YAO A C. Protocols for secure computations [C]// Proceedings of 23rd Annual Symposium on Foundations of Computer Science . Chicago: IEEE, 1982: 160–164.
[本文引用: 1]
[2]
GOLDREICH O, MICALI S, WIGDERSON A. How to play any mental game [C]// Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing . New York: [s.n.], 1987: 218–229.
[4]
KONEČNÝ J, MCMAHAN H B, RAMAGE D, et al. Federated optimization: distributed machine learning for on-device intelligence [EB/OL]. (2016−10−08) [2022−12−01]. https://arxiv.org/pdf/1610.02527.
[本文引用: 1]
[5]
TAN Y, LONG G, LIU L, et al. FedProto: federated prototype learning across heterogeneous clients [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S.l.]: AAAI Press, 2022: 8432−8440.
[本文引用: 2]
[6]
LI D, WANG J. FedMD: heterogenous federated learning via model distillation [EB/OL]. (2019−10−08)[2022−12−01]. https://arxiv.org/pdf/1910.03581.
[本文引用: 3]
[7]
MCMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [EB/OL]. (2023−01−26) [2023−12−01]. https://arxiv.org/pdf/1602.05629.
[本文引用: 1]
[8]
HANZELY F, RICHTÁRIK P. Federated learning of a mixture of global and local models [EB/OL]. (2021−02−12)[2022−12−01]. https://arxiv.org/pdf/2002.05516.
[本文引用: 1]
[9]
HUANG L, YIN Y, FU Z, et al. LoAdaBoost: loss-based AdaBoost federated machine learning with reduced computational complexity on IID and non-IID intensive care data [J]. PLoS ONE , 2020, 15(4): e0230706.
[本文引用: 1]
[10]
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network [EB/OL]. (2015−03−09)[2022−12−01]. https://arxiv.org/pdf/1503.02531.
[本文引用: 1]
[11]
FURLANELLO T, LIPTON Z C, TSCHANNEN M, et al. Born-again neural networks [EB/OL]. (2018−06−29)[2022−12−01]. https://arxiv.org/pdf/1805.04770.
[本文引用: 1]
[12]
KIMURA A, GHAHRAMANI Z, TAKEUCHI K, et al. Few-shot learning of neural networks from scratch by pseudo example optimization [EB/OL]. (2018−07−05)[2022−12−01]. https://arxiv.org/pdf/1802.03039.
[本文引用: 1]
[13]
LOPES R G, FENU S, STARNER T. Data-free knowledge distillation for deep neural networks [EB/OL]. (2017−11−23)[2022−12−01]. https://arxiv.org/pdf/1710.07535.
[本文引用: 1]
[14]
NAYAK G K, MOPURI K R, SHAJ V, et al. Zero-shot knowledge distillation in deep networks [EB/OL]. (2019−05−20) [2022−12−01]. https://arxiv.org/pdf/1905.08114.
[本文引用: 1]
[15]
CHEN H, WANG Y, XU C, et al. Data-free learning of student networks [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 3514–3522.
[本文引用: 1]
[16]
FANG G, SONG J, SHEN C, et al. Data-free adversarial distillation [EB/OL]. (2020−03−02) [2022−12−01]. https://arxiv.org/pdf/1912.11006.
[本文引用: 1]
[17]
JEONG E, OH S, KIM H, et al. Communication-efficient on-device machine learning: federated distillation and augmentation under non-IID private data [EB/OL]. (2023−10−19)[2023−12−01]. https://arxiv.org/pdf/1811.11479.
[本文引用: 1]
[18]
ITAHARA S, NISHIO T, KODA Y, et al Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-IID private data
[J]. IEEE Transactions on Mobile Computing , 2021 , 22 (1 ): 191 - 205
[本文引用: 1]
[19]
LIN T, KONG L, STICH S U, et al. Ensemble distillation for robust model fusion in federated learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . [S.l.]: CAI, 2020: 2351−2363.
[本文引用: 1]
[20]
CHANDRAKALA S, JAYALAKSHMI S L Generative model driven representation learning in a hybrid framework for environmental audio scene and sound event recognition
[J]. IEEE Transactions on Multimedia , 2019 , 22 (1 ): 3 - 14
[本文引用: 1]
[21]
ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers [EB/OL]. (2019−12−02) [2022−12−01]. https://arxiv.org/pdf/1912.00818.
[本文引用: 1]
[22]
ZHU Z, HONG J, ZHOU J. Data-free knowledge distillation for heterogeneous federated learning [EB/OL]. (2021−06−09) [2022−12−01]. https://arxiv.org/pdf/2105.10056.
[本文引用: 2]
[23]
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2022−12−01]. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
[本文引用: 1]
[24]
YAN G, PEI J, REN P, et al. ReMeDi: resources for multi-domain, multi-service, medical dialogues [EB/OL]. (2022−03−01) [2022−12−01]. https://arxiv.org/pdf/2109.00430.
[本文引用: 1]
[25]
LIU W, TANG J, CHENG Y, et al. MedDG: an entity-centric medical consultation dataset for entity-aware medical dialogue generation [C]// Natural Language Processing and Chinese Computing . [S.l.]: Springer, 2022: 447−459.
[本文引用: 1]
[26]
LEWIS M, LIU Y, GOYAL N, et al. Bart: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [S.l.]: ACL, 2020: 7871−7880.
[本文引用: 1]
1
... 隐私计算[1 -3 ] 是在数据隐私保护下由多个参与方联合计算的技术. 谷歌基于隐私计算提出联邦学习(federated learning,FL)的概念[4 ] . 传统FL区分对待共有数据和私有数据,无法在联邦学习框架下统一. 另外,传统FL通常假设不同客户端的数据和模型同质(假设不同客户端的局部模型结构一致,不同客户端的数据分布相似),而真实场景中数据和模型异质性常见,这样的假设限制了FL在复杂真实环境中的应用:客户端设备与所收集数据可能存在很大差异,导致在各种设备上训练的本地模型性能不理想[5 ] ;不同设备的内存和计算能力不同,一些设备限于训练少量参数的小型网络,导致不同本地设备的模型结构差异很大,通过传统的FL直接聚合不同本地模型不现实[6 ] . ...
How to share a secret
1
1979
... 隐私计算[1 -3 ] 是在数据隐私保护下由多个参与方联合计算的技术. 谷歌基于隐私计算提出联邦学习(federated learning,FL)的概念[4 ] . 传统FL区分对待共有数据和私有数据,无法在联邦学习框架下统一. 另外,传统FL通常假设不同客户端的数据和模型同质(假设不同客户端的局部模型结构一致,不同客户端的数据分布相似),而真实场景中数据和模型异质性常见,这样的假设限制了FL在复杂真实环境中的应用:客户端设备与所收集数据可能存在很大差异,导致在各种设备上训练的本地模型性能不理想[5 ] ;不同设备的内存和计算能力不同,一些设备限于训练少量参数的小型网络,导致不同本地设备的模型结构差异很大,通过传统的FL直接聚合不同本地模型不现实[6 ] . ...
1
... 隐私计算[1 -3 ] 是在数据隐私保护下由多个参与方联合计算的技术. 谷歌基于隐私计算提出联邦学习(federated learning,FL)的概念[4 ] . 传统FL区分对待共有数据和私有数据,无法在联邦学习框架下统一. 另外,传统FL通常假设不同客户端的数据和模型同质(假设不同客户端的局部模型结构一致,不同客户端的数据分布相似),而真实场景中数据和模型异质性常见,这样的假设限制了FL在复杂真实环境中的应用:客户端设备与所收集数据可能存在很大差异,导致在各种设备上训练的本地模型性能不理想[5 ] ;不同设备的内存和计算能力不同,一些设备限于训练少量参数的小型网络,导致不同本地设备的模型结构差异很大,通过传统的FL直接聚合不同本地模型不现实[6 ] . ...
2
... 隐私计算[1 -3 ] 是在数据隐私保护下由多个参与方联合计算的技术. 谷歌基于隐私计算提出联邦学习(federated learning,FL)的概念[4 ] . 传统FL区分对待共有数据和私有数据,无法在联邦学习框架下统一. 另外,传统FL通常假设不同客户端的数据和模型同质(假设不同客户端的局部模型结构一致,不同客户端的数据分布相似),而真实场景中数据和模型异质性常见,这样的假设限制了FL在复杂真实环境中的应用:客户端设备与所收集数据可能存在很大差异,导致在各种设备上训练的本地模型性能不理想[5 ] ;不同设备的内存和计算能力不同,一些设备限于训练少量参数的小型网络,导致不同本地设备的模型结构差异很大,通过传统的FL直接聚合不同本地模型不现实[6 ] . ...
... 异质性是FL研究的主要方向,研究趋势是实现非独立同分布数据的个性化本地模型. Tan等[5 ] 提出神经网络框架FedProto,使每个本地模型的基础层通过FedAvg[7 ] 集中在全局数据上训练,高级层(个性化层)在本地数据上独立训练. Hanzely等[8 ] 认为FedAvg是元学习,为此提出基于元学习的个性化方法. 它只将局部模型的训练作为任务,全局模型在训练开始时须寻找合适的初始化参数. Huang等[9 ] 基于FedAvg和数据共享策略提出提高医学数据FL效率的自适应增强方法. 异构模型FL通过改进传统的联邦学习框架使FL支持工业模型训练. Li等[6 ] 提出的新型联邦学习框架FedMD允许客户端独立设计自己的模型体系结构,服务端只须实现有限的黑盒访问来完成训练. ...
3
... 隐私计算[1 -3 ] 是在数据隐私保护下由多个参与方联合计算的技术. 谷歌基于隐私计算提出联邦学习(federated learning,FL)的概念[4 ] . 传统FL区分对待共有数据和私有数据,无法在联邦学习框架下统一. 另外,传统FL通常假设不同客户端的数据和模型同质(假设不同客户端的局部模型结构一致,不同客户端的数据分布相似),而真实场景中数据和模型异质性常见,这样的假设限制了FL在复杂真实环境中的应用:客户端设备与所收集数据可能存在很大差异,导致在各种设备上训练的本地模型性能不理想[5 ] ;不同设备的内存和计算能力不同,一些设备限于训练少量参数的小型网络,导致不同本地设备的模型结构差异很大,通过传统的FL直接聚合不同本地模型不现实[6 ] . ...
... 异质性是FL研究的主要方向,研究趋势是实现非独立同分布数据的个性化本地模型. Tan等[5 ] 提出神经网络框架FedProto,使每个本地模型的基础层通过FedAvg[7 ] 集中在全局数据上训练,高级层(个性化层)在本地数据上独立训练. Hanzely等[8 ] 认为FedAvg是元学习,为此提出基于元学习的个性化方法. 它只将局部模型的训练作为任务,全局模型在训练开始时须寻找合适的初始化参数. Huang等[9 ] 基于FedAvg和数据共享策略提出提高医学数据FL效率的自适应增强方法. 异构模型FL通过改进传统的联邦学习框架使FL支持工业模型训练. Li等[6 ] 提出的新型联邦学习框架FedMD允许客户端独立设计自己的模型体系结构,服务端只须实现有限的黑盒访问来完成训练. ...
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... 异质性是FL研究的主要方向,研究趋势是实现非独立同分布数据的个性化本地模型. Tan等[5 ] 提出神经网络框架FedProto,使每个本地模型的基础层通过FedAvg[7 ] 集中在全局数据上训练,高级层(个性化层)在本地数据上独立训练. Hanzely等[8 ] 认为FedAvg是元学习,为此提出基于元学习的个性化方法. 它只将局部模型的训练作为任务,全局模型在训练开始时须寻找合适的初始化参数. Huang等[9 ] 基于FedAvg和数据共享策略提出提高医学数据FL效率的自适应增强方法. 异构模型FL通过改进传统的联邦学习框架使FL支持工业模型训练. Li等[6 ] 提出的新型联邦学习框架FedMD允许客户端独立设计自己的模型体系结构,服务端只须实现有限的黑盒访问来完成训练. ...
1
... 异质性是FL研究的主要方向,研究趋势是实现非独立同分布数据的个性化本地模型. Tan等[5 ] 提出神经网络框架FedProto,使每个本地模型的基础层通过FedAvg[7 ] 集中在全局数据上训练,高级层(个性化层)在本地数据上独立训练. Hanzely等[8 ] 认为FedAvg是元学习,为此提出基于元学习的个性化方法. 它只将局部模型的训练作为任务,全局模型在训练开始时须寻找合适的初始化参数. Huang等[9 ] 基于FedAvg和数据共享策略提出提高医学数据FL效率的自适应增强方法. 异构模型FL通过改进传统的联邦学习框架使FL支持工业模型训练. Li等[6 ] 提出的新型联邦学习框架FedMD允许客户端独立设计自己的模型体系结构,服务端只须实现有限的黑盒访问来完成训练. ...
1
... 异质性是FL研究的主要方向,研究趋势是实现非独立同分布数据的个性化本地模型. Tan等[5 ] 提出神经网络框架FedProto,使每个本地模型的基础层通过FedAvg[7 ] 集中在全局数据上训练,高级层(个性化层)在本地数据上独立训练. Hanzely等[8 ] 认为FedAvg是元学习,为此提出基于元学习的个性化方法. 它只将局部模型的训练作为任务,全局模型在训练开始时须寻找合适的初始化参数. Huang等[9 ] 基于FedAvg和数据共享策略提出提高医学数据FL效率的自适应增强方法. 异构模型FL通过改进传统的联邦学习框架使FL支持工业模型训练. Li等[6 ] 提出的新型联邦学习框架FedMD允许客户端独立设计自己的模型体系结构,服务端只须实现有限的黑盒访问来完成训练. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-IID private data
1
2021
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
Generative model driven representation learning in a hybrid framework for environmental audio scene and sound event recognition
1
2019
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
1
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
2
... Hinton等[10 ] 提出深度神经网络的知识蒸馏;Furlanello等[11 ] 认为知识的转移发生在多代学生之间,每一代都从上一代学习;Kimura等[12 ] 提出的知识蒸馏使用从少量训练数据中“伪训练示例”增强的样本;Lopes等[13 ] 将教师模型训练后的各层数据作为元数据,重构训练样本,用于训练学生模型;Nayak等[14 ] 选择将教师模型的数据合成为数据样本进行训练;Chen等[15 ] 引入生成器,通过将教师模型作为固定鉴别器进行训练,生成与原始数据集分布相似样本;Fang等[16 ] 提出无数据对抗蒸馏方案,为学生模型生成“硬样本”. 为了解决异构性问题,有研究在FL中引入联邦蒸馏(federated knowledge distillation,FKD)[17 ] . Itahara等[18 ] 提出半监督的联邦蒸馏算法,使用未标记的开放数据在各移动设备间交换本地模型输出. 一些学者专注于研究FKD中异构性问题. FedMD[6 ] 是基于迁移学习和知识蒸馏的通用框架,允许客户端有不同模型,解决了FL中的异构性问题. Lin等[19 ] 提出集成蒸馏进行模型融合,能够有效减少模型收敛的训练轮次. FedDF在服务器端进行知识蒸馏,对蒸馏数据集的选择具有鲁棒性. Chandrakala等[20 ] 针对非独立同分布数据,提出在半监督场景下基于知识蒸馏的入侵检测算法. 蒸馏是单向过程,全局硬标签用来蒸馏每个本地模型. Arivazhagan等[21 ] 提出个性化层表示客户端模型. Zhu等[22 ] 提出无数据方法以提高联邦蒸馏的效率,服务器学习轻量级生成器来取代全局共享数据集并广播给所有参与方. 这些方法没有充分考虑云-端的互动和异质模型/数据,也没有区分共有数据和私有数据. ...
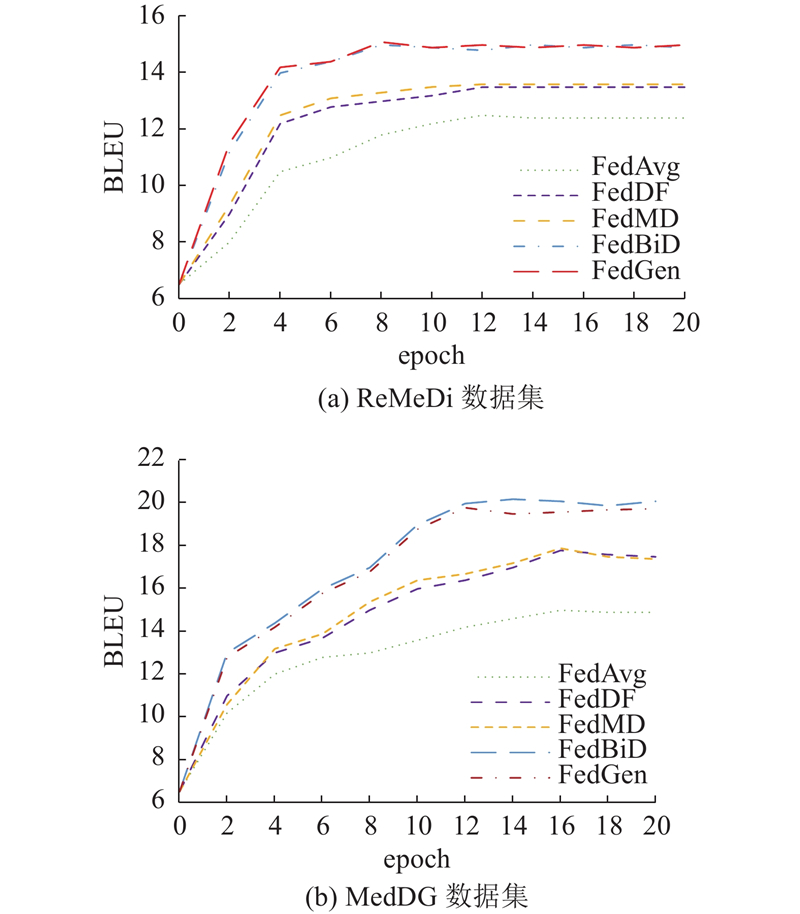
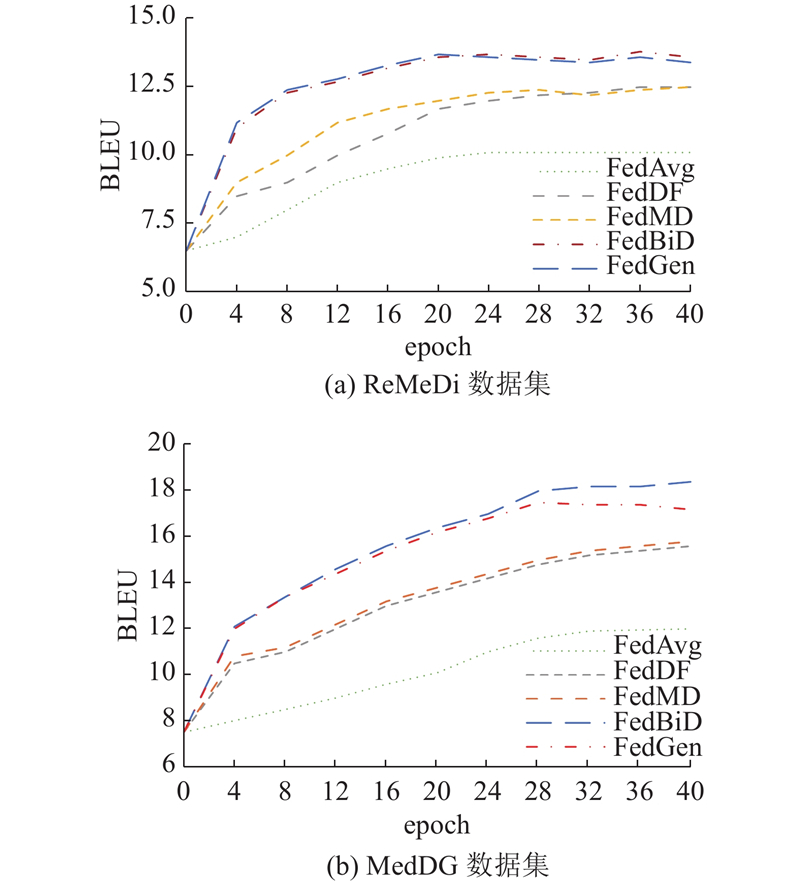
... 对比模型为4种FL框架:FedAvg、FedMD、FedDF和FedGen[22 ] . FedAvg为经典FL算法,另外3种为联邦蒸馏方式. FedAvg每轮训练后都随机选取一些客户端将模型参数信息上传至服务器端,服务器聚合参数信息后下发给各客户端,每个客户端用聚合好后的模型参数更新本地模型. FedMD利用存储在云服务器上的合成数据集进行知识蒸馏,利用合成数据集训练能够区分全局类别的全局模型,将异构局部模型和全局模型得到的logits平均,有效解决模型异质性问题. FedDF是基于集成蒸馏的联邦学习框架,即通过来自客户端模型输出的未标记数据训练中央分类器,能够灵活聚合不同异构客户端模型. FedGen为每个客户端部署额外模型,使用优先知识为每个局部模型训练额外的输入特征,以局部模型提供额外训练样本的方式提高性能. ...
1
... 设置默认情况下有4个客户端,云和端上的模型选择标准版本的GPT-2[23 ] . 当客户端蒸馏到服务器时,设置T 1 =20;当服务器对客户端进行反蒸馏时,设置T 2 =1. ...
1
... 实验采用公开的高质量医疗对话数据集:ReMeDi[24 ] 和MedDG[25 ] . ReMeDi包括1 557次使用精细标签的对话,涵盖843种疾病,5228 家医疗实体,40个领域. MedDG是以实体为中心的医疗对话数据集,包含17 864个中文对话,385 951个话语和217 205个实体. 该文本标注方法:从原始文本中提取与实体相关的文本跨度,对相应的规范化实体进行注释. ...
1
... 实验采用公开的高质量医疗对话数据集:ReMeDi[24 ] 和MedDG[25 ] . ReMeDi包括1 557次使用精细标签的对话,涵盖843种疾病,5228 家医疗实体,40个领域. MedDG是以实体为中心的医疗对话数据集,包含17 864个中文对话,385 951个话语和217 205个实体. 该文本标注方法:从原始文本中提取与实体相关的文本跨度,对相应的规范化实体进行注释. ...
1
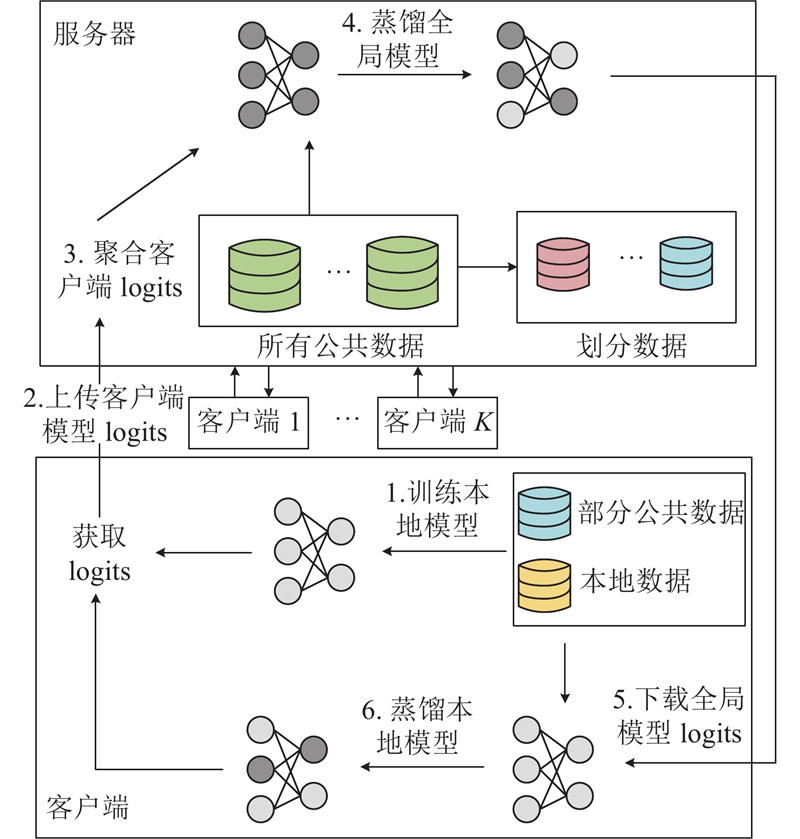
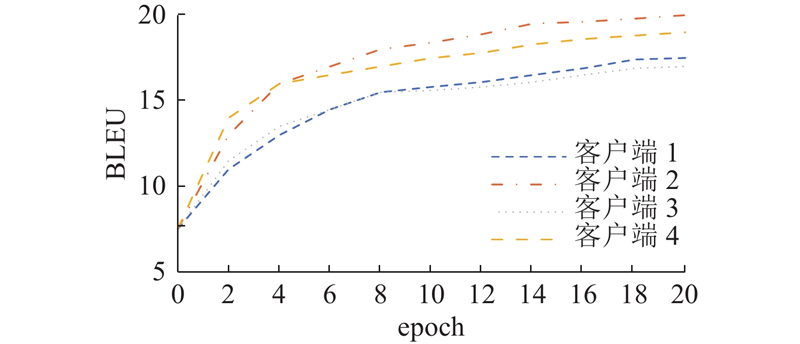
... 在传统FL中,每轮训练交换的是模型参数,因此各个客户端模型须保持一致. 在实际场景中,各客户端上模型结构往往存在差异. 异构模型包括经典的基于自回归GPT-2,基于自回归和非自回归混合模型BART[26 ] ,各客户端上模型参数如表2 所示. 表中,n p 为参数量. 各客户端在单独训练时的BLEU分别为18.96、22.34、19.12、23.19. 如图4 所示为各客户端上异构对话生成模型的BLEU随通信轮数变化的情况. 可以看到,大约在第 15轮通信后,4个客户端模型都已经逐渐收敛,证明FedBiD能够在客户端模型异构场景下成功收敛,且收敛速度较快. 与此同时,与单个客户端独自训练对比,BLEU仅下降2.21~2.65. BART模型在联邦蒸馏场景中性能损失大于GPT-2. 实验结果表明,在客户端模型异构场景中,本研究所提方法能够快速收敛并保持较高精度. FedBiD在模型性能方面相比FedAvg、FedMD和FedDF有明显提升,略微高于FedGen. 其中FedAvg在异构数据场景下模型性能与同构数据相比有明显下降,这是由于FedAvg在训练过程中直接传递模型参数或梯度,导致在异构场景下各种信息存在较大差异,难以聚合,联邦蒸馏传导的是模型输出logits,很大程度上缓解了异构性带来的问题. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}